
AI人工智能(调包侠)速成之路六(mnist手写数字识别2:全连接层实现)
AI人工智能(调包侠)速成之路五(mnist手写数字识别1:如何调用模型)https://blog.csdn.net/askmeaskyou/article/details/108674860上次是直接叙述如何调用训练好的模型,这次就来看看神奇的神经网络是如何设计和训练导出的。我把代码,模型,测试图片一起打包下载地址:https://download.csdn.net/前面的文章介绍过单层感知机只
AI人工智能(调包侠)速成之路五(mnist手写数字识别1:如何调用模型)
https://blog.csdn.net/askmeaskyou/article/details/108674860
上次是直接叙述如何调用训练好的模型,这次就来看看神奇的神经网络是如何设计和训练导出的。
我把代码,模型,测试图片一起打包
下载地址:https://download.csdn.net/download/askmeaskyou/12876950
前面的文章介绍过单层感知机只能处理线性分类问题,多层感知机加上非线性激活函数可以解决复杂的分类问题。
AI人工智能(调包侠)速成之路一(人工智能极简史)
下面就用tensorflow2来实现一个全连接多层神经网络的代码。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
首先引入tensorflow2的库,然后引入keras。Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。目前Keras已经集成到了Tensorflow里面,keras的设计是把大量内部运算都隐藏了,使用起来非常方便。
通过Keras引入datasets(训练数据集管理), layers(网络模型层搭建), optimizers(网络优化器), Sequential(网络层打包的容器), metrics(测试度量器)。通过Keras引入5个工具进行模型搭建训练导出也是非常经典的套路。
(x, y), (x_test, y_test) = datasets.mnist.load_data()
这一行代码是把训练用的数据集打包下载(如果已经下载过会自动从缓存中加载),然后分为两个部分(x, y)用于训练模型,(x_test, y_test) 用于测试训练后的模型,当测试成功率满足要求后就停止训练。因为我们是学习经典案例所以一行代码轻松搞定了数据集的全部工作。如果是要开发一个其他应用的神经网络,要花费很大的时间精力来准备数据集和对应的标签数据。
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
batchsz = 128
db = tf.data.Dataset.from_tensor_slices((x,y))
db = db.map(preprocess).shuffle(10000).batch(batchsz)
这里的代码是构造数据集并对数据集预处理,preprocess(x, y) 就是预处理函数。将读取的训练数据转换到tensorflow变量中,x表示图片像素的值0到255,除与255就转换成0到1之间的小数,y表示的是图片对应的标签值。
shuffle(10000).batch(batchsz)的作用是把数据随机打散然后选一个batch。
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test = db_test.map(preprocess).batch(batchsz)
测试的数据集也做同样的处理
到这里训练和测试用的数据集都准备好了,下面通过容器来构造一个5层的全连接神经网络
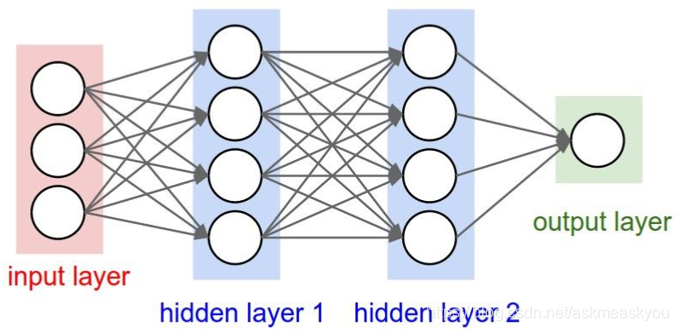
model = Sequential([
layers.Dense(256, activation=tf.nn.relu), # [b, 784] => [b, 256]
layers.Dense(128, activation=tf.nn.relu), # [b, 256] => [b, 128]
layers.Dense(64, activation=tf.nn.relu), # [b, 128] => [b, 64]
layers.Dense(32, activation=tf.nn.relu), # [b, 64] => [b, 32]
layers.Dense(10) # [b, 32] => [b, 10], 330 = 32*10 + 10
])
看到构建神经网路模型的代码也是非常简洁,每一行就对应一层网络,网络的节点数大小原则上是逐层减少,只需要注意输入和输出的维度要设计好。除了最后一层外,其他层都加上了激活函数”activation=tf.nn.relu“,这个函数也很简单,但它是一个非线性函数,这样几层网络堆叠起来就可以求解复杂的分类问题了。
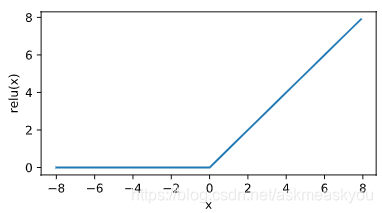
relu函数:
model.build(input_shape=[None, 28*28])
model.summary()
model.build是构建模型输入的维度,我们输入的是28*28像素的维度,model.summary()可以将设计好的网络结构打印出来。
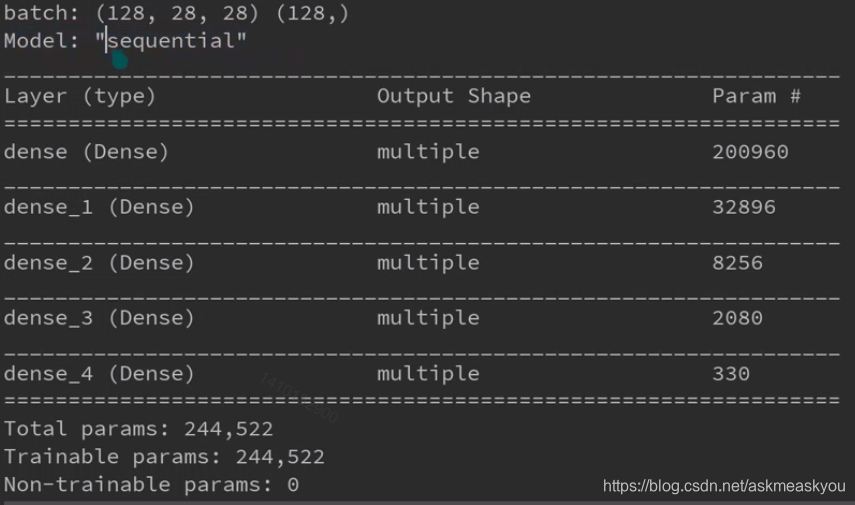
可以看到上面的5层网络包含的连接数已经非常多了,每个节点都有需要训练的权值,总的参数量是244522个。
optimizer = optimizers.Adam(lr=1e-3)
设置优化器和学习率。
到这里神经网络模型也准备好了,下面就是不断循环的抽取训练数据进行前向传播获得反馈结果,然后用反馈的结果和标签数据比较,使用优化器不断更新节点参数,让神经网络反馈的结果和标签数据的结果越来越接近(误差越来越小)。在训练的过程中用测试数据统计成功率,成功率超过预期后就可以停止训练了。
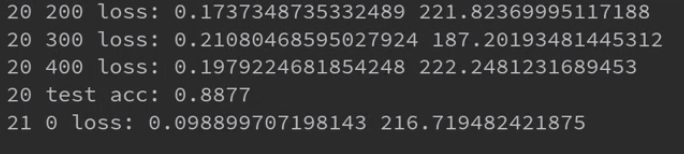
训练代码还涉及到一些tensorflow2知识点,如果有疑问还是要系统补充下相关知识。Tensorflow2.0的使用方法参照Tensroflow官方教程。下面对几个关键内容简单做个解释。
logits = model(x) #前向传播获得结果就只需要这样一行代码,非常简单。
y_onehot = tf.one_hot(y, depth=10) #onehot编码也是非常常用的,这里就是把数字变成[0,0,0,0,0,0,0,0,1,0]格式。
loss_mse = tf.reduce_mean(tf.losses.MSE(y_onehot, logits))
loss_ce = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss_ce = tf.reduce_mean(loss_ce)
误差函数的选取也是非常经典的问题,一般数值回归的问题选择MSE均方误差函数,多分类问题选择crossentropy交叉熵损失函数。
完整代码,模型,测试图片一起打包
下载地址:https://download.csdn.net/download/askmeaskyou/12876950
这里用了最基础的全连接层堆叠,可以看出来层数的增加会增加很多的节点连接,神经网络的训练就是要不断修改每个连接节点的权值参数,有没有办法让节点之间的连接共享参数,这样就能大大减少需要训练的权值参数。下一篇文章,我们用CNN卷积神经网络来实现模型。

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)