
人工智能-基础篇-16-什么是向量数据库?(向量是什么?向量数据库的作用)
向量数据库主要用于处理高维向量数据的存储和检索任务,而知识库则是企业内部信息的重要载体。*两者结合起来,可以极大地提升AI系统的性能,特别是在需要快速定位相关信息并生成高质量回复的应用场景中。这种组合使得AI不仅能理解用户的意图,还能根据最新、最权威的知识提供精准的答案。将结构化和非结构化数据转化为向量后,通过语义相似性搜索,解决传统数据库无法处理的模糊匹配问题。向量数据库是知识库的一种高效存储和
向量数据库(Vector Database)是一种专门用于高效存储和检索高维向量数据的数据库系统。
向量数据库中的这些向量,通常代表了实体或对象在多维空间中的特征表示,广泛应用于机器学习、自然语言处理(NLP)、计算机视觉等领域。例如,在文本处理中,每个词或者句子可以通过嵌入(Embedding)技术转换为一个固定长度的向量,这个向量捕捉了该词或句子的语义信息。
1、核心特性
- 高维向量支持:向量数据库能处理数百到数千维的向量数据(例如,一段文本通过BERT模型生成的768维向量)。
- 相似性搜索:
支持基于语义的模糊匹配,例如:- 输入“猫”,找到语义相近的“喵”“宠物”;
- 输入一张图片,找到视觉相似的图片。
- 高效索引:使用近似最近邻(ANN)算法(如HNSW、IVF、LSH)加速查询,避免暴力计算所有向量距离。能够快速地从大量向量中找到与给定查询向量最相似的那些向量。
- 元数据管理:允许存储与向量关联的元数据(如文本内容、时间戳、标签),便于结合语义和传统条件查询。
- 动态更新:支持实时插入、更新和删除向量,适应动态变化的数据需求。
- 扩展性强:可以轻松扩展以处理数百万甚至数十亿个向量的数据集。
2、工作原理
向量数据库的工作流程分为三个核心步骤。
1、向量生成:
通过机器学习模型(如BERT、ResNet)将结构化和非结构化数据转换为向量。
- 文本:使用NLP模型生成语义嵌入(如“苹果”的向量可能接近“水果”和“iPhone”)。
- 图像:通过CNN模型提取特征向量(如猫的图片向量与狗的图片向量距离较远)。
2、向量存储:
将高维向量及其关联的元数据(如原始文本、ID、标签)存储到数据库,并构建索引以加速查询。
3、相似性搜索:
用户输入查询(如一段文本或图片),数据库将其转换为向量后,在索引中快速找到最相似的向量,并返回对应的结果。
示例:
用户输入“红色运动轿车”,向量数据库会找到与之语义最相似的图片或文本(如“跑车”“赛车”)。
3、向量的作用
(1)向量的本质:语义索引,不包含原始内容
- 核心功能:
向量数据库存储的向量仅用于语义相似性检索,相当于传统数据库的“索引”。它不包含原始知识的完整内容,而是通过数学表示捕捉语义特征。 - 与传统索引的区别:
- 传统索引:基于关键词(如倒排索引),只能匹配精确或模糊的字符。
- 向量索引:基于语义(如余弦相似度),能匹配“意思相近”的内容(例如“报销”匹配“差旅费用”)。
(2)详细内容的存储方式
- 分离存储:
原始文本或文件(如PDF原文)通常存储在传统数据库(如MySQL、PostgreSQL)或文件系统中,向量数据库仅存储向量和元数据(如文档ID、段落位置)。 - 检索流程:
1、用户提问 → 大模型将问题转为向量。
2、向量数据库检索最相似的向量 → 返回关联的元数据(如文档ID)。
3、根据元数据从传统数据库或文件系统中提取原文内容。
4、大模型结合检索到的原文生成最终答案。
4、应用场景
- 推荐系统:
将用户行为或商品特征向量化,快速匹配相似用户或商品(如“喜欢科幻电影的用户可能也喜欢《星际穿越》”)。 - 图像检索:
输入一张图片,找到视觉相似的图片(如搜索“泰坦尼克号海报”找到其他电影海报)。 - 自然语言处理:
语义搜索(如输入“如何申请退款”找到“退货流程”文档)。 - 生物信息学:
基因序列或蛋白质结构的相似性匹配。 - 智能客服:
结合RAG技术,从知识库中检索与用户问题语义相似的解答。
5、常见的向量数据库
- Faiss:由Facebook AI Research开发的一个库,特别擅长于大规模向量的相似性搜索。
- Milvus:一款开源的向量数据库管理系统,支持多种类型的向量数据,并提供强大的搜索功能。
- Pinecone:云服务形式提供的向量数据库,专注于高性能和易用性。
- Weaviate:另一个开源向量搜索引擎,除了基本的向量操作外,还提供了RESTful API接口和GraphQL查询支持。
6、知识库与向量数据库的关系
知识库(Knowledge Base)是存储结构化或非结构化知识的集合,而向量数据库是知识库的一种存储和检索工具。
1、角色分析
知识库的角色:
- 信息存储:知识库主要负责存储结构化或非结构化的信息,如文档、FAQ、政策文件等。
- 内容管理:它包含了企业内部的所有重要资料,用于支持决策制定、客户服务、员工培训等多种用途。
向量数据库的角色:
- 特征表示:当我们将文本或其他类型的数据输入到AI模型中时,通常会先将其转换成向量形式。这一步骤称为嵌入(Embedding),生成的向量可以更好地反映原始数据的语义特征。
- 相似度匹配:通过向量数据库,我们可以迅速找到与当前问题最为相关的已有答案或文档片段,从而提高响应速度和准确性。
2、内容形式
- 传统知识库:
存储文本、表格、PDF等非结构化数据(如产品手册、FAQ、政策文件)。 - 向量化知识库:
将知识库中的内容通过Embedding模型转换为向量,并存储到向量数据库中。
3、向量数据库在知识库中的作用
- 解决传统知识库的局限性:
- 关键词匹配的缺陷:传统数据库基于字符匹配(如“年假”只能匹配“年假”,无法匹配“带薪休假”)。
- 语义匹配的优势:向量数据库通过余弦相似度匹配语义(如“年假”和“带薪休假”的向量距离较近)。
- 高效检索大规模数据:
传统数据库在海量数据中逐条匹配效率低,而向量数据库通过ANN索引可实现毫秒级检索。
4、协同生成-RAG技术
在检索增强生成(RAG, Retrieval-Augmented Generation)技术中,知识库和向量数据库的结合至关重要。
1、知识库构建:
- 将企业内部的文档(如PDF、数据库表)拆分为小块(Chunk),并通过Embedding模型生成向量。
- 向量数据库存储这些向量及对应的元数据(如文档原文)。
2、在线检索:
- 用户提问时,模型将问题转换为向量,在向量数据库中找到最相关的知识片段。
- 模型基于检索到的知识生成答案,避免胡编乱造。
示例:
用户问“公司最新的差旅报销标准”,RAG系统会从向量数据库中检索《2025年差旅政策》文档,再让大模型总结答案。
5、结合使用示例
(1)文本嵌入:首先对知识库中的所有文档进行预处理,提取出关键词汇并转化为向量形式。对于新来的用户查询也做同样的处理。
(2)向量存储与检索:将这些向量存入向量数据库中。每当有新的查询到来时,系统会在向量数据库中执行相似度搜索,找出最接近的几个结果。
(3)整合回答:基于检索到的结果,大模型可以根据上下文进一步加工,生成最终的回答返回给用户。
示例流程:
假设你有一个客服机器人,其背后的知识库包含了大量的产品手册和常见问题解答。
- 当客户询问“如何更换电池?”时,
- 客服机器人首先将这个问题转换为向量形式。
- 然后利用向量数据库查找与该问题最相关的FAQ条目。
- 最后,结合查找到的信息,客服机器人给出详细的步骤指导用户更换电池。
这种方式不仅提高了搜索效率,还能确保提供的答案是最准确和最新的,因为它直接来源于企业的官方知识库。
7、知识库vs向量数据库
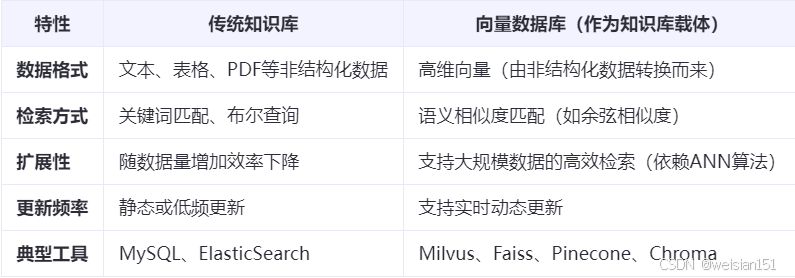
8、向量数据库是什么时候将知识库的数据转为向量并存储的?
答案:
向量数据库通常在“创建知识库”或“更新知识库”的时候就完成文本到向量的转换和存储,这个过程叫做预处理(Preprocessing)或索引构建(Indexing)。
具体流程如下:
(1)上传原始文档
- 比如 PDF、Word、TXT 文件等。
- 这些文件被导入系统后,会进行解析和清洗。
(2)切分内容(Chunking)
- 将文档分成小块(chunks),比如每段话、每个句子或固定长度(如 500 字符)。
- 目的是为了提高检索精度和效率。
(3)生成向量(Embedding)
- 使用一个嵌入模型(如 OpenAI 的 text-embedding-ada-002、本地的 BERT、BGE、Sentence-BERT 等)将每一个 chunk 转换为一个高维向量(例如 768 维或 1536 维)。
(4)存入向量数据库
- 把这些向量连同对应的原始文本一起存入向量数据库中。
- 此时就完成了知识库的“向量化索引”。
总结时间点:
向量是在知识库创建/更新时就创建存储的,而不是用户提问时才处理的。
9、总结
*向量数据库主要用于处理高维向量数据的存储和检索任务,而知识库则是企业内部信息的重要载体。*两者结合起来,可以极大地提升AI系统的性能,特别是在需要快速定位相关信息并生成高质量回复的应用场景中。这种组合使得AI不仅能理解用户的意图,还能根据最新、最权威的知识提供精准的答案。
向量数据库的核心价值:
- 将结构化和非结构化数据转化为向量后,通过语义相似性搜索,解决传统数据库无法处理的模糊匹配问题。
- 向量数据库是知识库的一种高效存储和检索方式,尤其适合需要语义匹配的场景(如RAG、推荐系统)。
实际应用:
企业可通过向量数据库+知识库构建智能客服、个性化推荐、文档搜索等系统,大幅提升效率和准确性。
一句话总结:
向量数据库是知识库的“智能引擎”,让知识的存储和检索从“关键词匹配”升级为“语义理解”。
向阳而生,Dare To Be!!!

一站式 AI 云服务平台
更多推荐



 13
13 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)