
毕业设计选题-基于深度学习的护理对象跌倒人物目标检测算法系统 YOLO python 卷积神经网络 人工智能
毕业设计-基于深度学习的跌倒人物目标检测算法系统的毕业设计。该系统利用先进的深度学习模型和大规模的训练数据,实现了高效准确的跌倒人物目标检测和识别。我们采用了目前流行的Faster R-CNN模型,结合经典的图像数据集进行模型训练,并通过GPU加速提高处理速度。该系统能够自动识别图像中的跌倒人物,并给出其精确的位置和分类结果。还探讨了训练过程中的优化方法和技巧,以提高目标检测的准确性和鲁棒性。通过
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的护理对象跌倒人物目标检测算法系统
设计思路
一、课题背景与意义
在医院、养老院或家庭中,护理对象的跌倒事件是一个常见但危险的情况。跌倒可能导致严重的身体伤害,甚至危及生命。由于护工无法时刻监视护理对象的活动,因此开发一种基于深度学习的护理对象跌倒检测系统可以准确识别护理对象的跌倒动作,并迅速通知护工或相关人员进行救援和干预。及时的援助可以最大程度地减少伤害,提高护理对象的生活质量和安全性。
二、算法理论原理
YOLOv5s模型的结构由4部分组成:①基于卷积网络的Backbone主干网络,主要提取图像的特征信息;②Head检测头,主要预测目标框和预测目标的类别;③主干网络和检测头之间的Neck颈部层;④预测层输出检测结果,预测出目标检测框和标签类别。
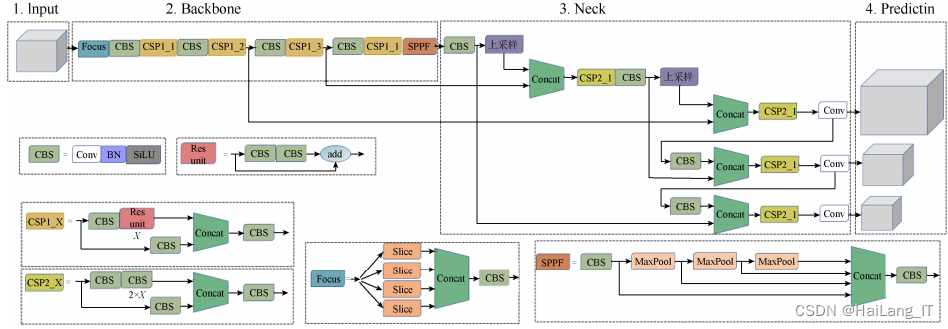
YOLOv5s模型主要工作流程:
- (1) 原始图像输入部分加入了图像填充、自适应锚框计算、Mosaic数据增强来对数据进行处理,以增加检测的辨识度和准确度。
- (2) 主干网络中采用Focus结构和CSP1_X(X个残差结构,下同)结构进行特征提取。在特征生成部分,使用基于SPP优化后的SPPF结构来完成。
- (3) 将颈部层应用路径聚合网络(PANet)与CSP2_X进行特征融合。
- (4) 使用GIOU_Loss作为损失函数。
2.1 注意力机制
在目标检测模型中用CBAM注意力机制替换SE-Net模块来优化目标检测精度,使目标特征提取更完全,从而改善人物姿势剧烈变化时出现的目标丢失问题。
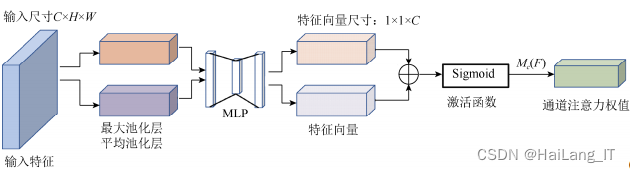
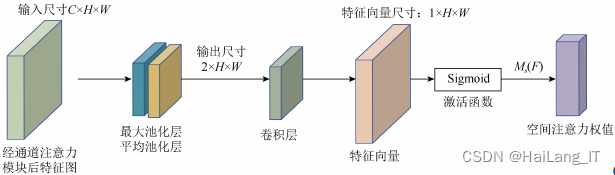
在目标检测模型中用CBAM注意力机制替换SE-Net模块来优化目标检测精度,使目标特征提取更完全,从而改善人物姿势剧烈变化时出现的目标丢失问题。CBAM作为一种轻量级的注意力模型,综合考虑了不同通道像素和同一通道不同位置像素在重要性上的区别,是一种简单、高效的注意力机制设计实现,计算消耗极小,且能与卷积网络无缝集成并用于端到端的训练。通道注意力模块、空间注意力模块共同构成CBAM,输入特征会沿着顺序结构依次推断输入中所含的注意力特征,然后再将注意力特征向量和输入特征向量相乘来实现自适应特征优化。
2.2 特征融合网络优化
颈部层可使主干网络提取的特征更充分地被利用,通常对各阶段直接增加由自底向上和自顶向下的路径,对各阶段的特征图进行再处理,实现各阶段特征图的多尺度融合,该方式主要用于生成FPN,FPN会增强模型对于不同缩放尺度对象的检测能力。鉴于移动端或边缘设备上的资源约束,以优化模型大小和延迟导向来重新考虑YOLOv5s模型中的多尺度融合策略。FPN为底层特征图提供了更多的语义信息,提高了小尺寸目标的检测效果。在FPN的基础上设计实现了更多的跨尺度特征融合网络。YOLOv5s的颈部结构部分采用了PANet结构。
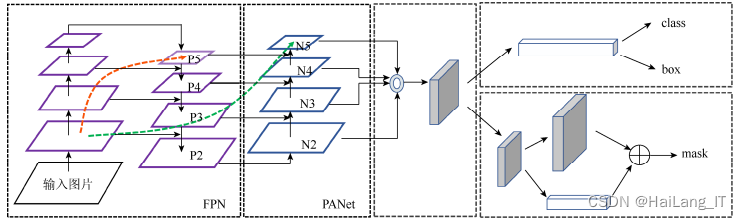
FPN是普通的特征金字塔,包含自底向上和自顶向下双向通道特征提取路径,从而融合高分辨率的低层和语义信息丰富的高层。PANet结构是在FPN的基础上引入了自底向上路径增强结构,使得高层特征直接获取低层更多的位置信息,另外从结构中也能看到其特点是反复的特征提取,因此需要更多的计算消耗,模型体积也更大。为优化YOLOv5s-FPD的结构,利用加权双向特征金字塔网络BiFPN。
相关代码:
self.num_channels = num_channels
# 定义底层特征融合的卷积层
self.conv_down = nn.Conv2d(num_channels, num_channels, kernel_size=1)
# 定义顶层特征融合的卷积层
self.conv_up = nn.Conv2d(num_channels, num_channels, kernel_size=1)
# 定义横向连接的卷积层
self.conv_lateral = nn.Conv2d(num_channels, num_channels, kernel_size=1)
# 定义特征融合的权重
self.w = nn.Parameter(torch.ones(5))
def forward(self, inputs):
# 解包输入特征
p3, p4, p5, p6, p7 = inputs
# 上采样和下采样
p7_td = self.conv_down(p7)
p6_td = F.interpolate(p7_td, scale_factor=2, mode='nearest')
p6_td = self.conv_down(p6_td)
p5_td = F.interpolate(p6_td, scale_factor=2, mode='nearest')
p5_td = self.conv_down(p5_td)
p4_td = F.interpolate(p5_td, scale_factor=2, mode='nearest')
p4_td = self.conv_down(p4_td)
p3_td = F.interpolate(p4_td, scale_factor=2, mode='nearest')
p3_td = self.conv_down(p3_td)三、检测的实现
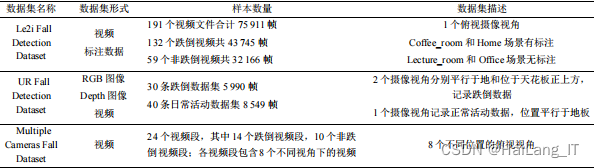
3.1 数据集
由于网络上没有现有的合适的数据集,我决定自己去医院、养老院等地进行拍摄,再从视频中截取图片,收集图片并制作了一个全新的数据集。这个数据集包含了各种生活场景的照片,其中包括老年人摔倒的情况以及其他相关姿势。通过现场拍摄,我能够捕捉到真实的场景和多样的生活环境,这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为护理行业的跌倒检测研究提高护理对象的安全性、减轻护工工作负担,并为护理质量的改进提供了有力的支持。

对于无标注的数据集部分,使用LabelImg标注。利用多种方式的图像转换,对所用的跌倒目标数据集进行扩充操作,分别使用对称翻转、运动模糊、高斯模糊、亮度对比度变换、图像旋转来处理原始数据集。
3.2 实验环境搭建

YOLOv5s-FPD采用了多尺度训练方式迭代300轮,初始学习率0.0001,输入图像大小为640×640,批处理大小16。另外设交并比(intersection over union,IoU)等于0.5以区分正、负样本。
3.3 实验及结果分析
选取了反映目标检测模型检测水平的6种常用评价指标,对改进后的检测网络模型进行评价。
- (1)精确度(Precision,P)、召回率(Recall,R)和F1分数
- (2)平均精度(average precision,AP)
- (3)帧速(frames per second,FPS):通常用来衡量目标检测模型的实时性,其表示神经网络每秒能处理图片的数量。
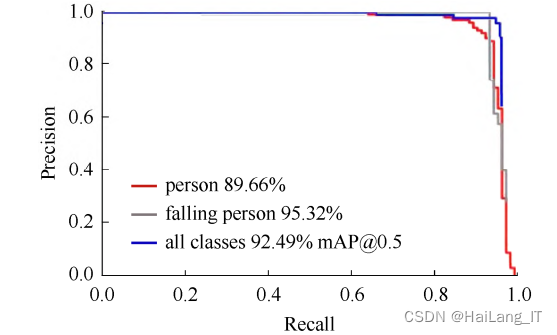
P-R曲线可知,绝大部分时,灰色曲线表示的falling person类别都比红色曲线表示的person类别更靠近坐标(1,1)位置,表示前者的准确性更高,同时蓝色曲线表示的全部类别平均精度,也比person类别曲线更高,YOLOv5s-FPD模型精度提升明显。
对YOLOv5s模型的特征提取、注意力机制和特征融合方法进行了改进,同时引入了焦点损失函数。为评估不同模块改动和不同模块组合对于算法性能优化的程度,设计了消融实验。

使用MobileNetV3进行特征提取来改善原生YOLOv5s的轻量化方法对模型准确性的影响,并引入CBAM轻量化注意力机制和焦点损失函数来提升检测模型的特征提取能力。实验结果表明,使用YOLOv5s-FPD模型的目标漏检率大大降低,同时模型体积和检测速度均有了一定程度的优化,泛化能力和鲁棒性更强,更易于作为智能看护系统的基础模型部署在移动设备和边缘设备上,具有一定的实际意义和社会价值。

相关代码如下:
# 数据预处理和增强
transform = transforms.Compose([
transforms.ToTensor(),
])
# 加载数据集
dataset = torchvision.datasets.VOCDetection(dataset_path, year='2007', image_set='train', download=True, transform=transform)
# 创建数据加载器
batch_size = 32
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 加载预训练的模型
model = fasterrcnn_resnet50_fpn(pretrained=True)
model = model.cuda() # 将模型移动到GPU(如果可用)
# 定义优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criterion = torch.nn.CrossEntropyLoss()
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for images, targets in dataloader:
images = images.cuda()
targets = [target.cuda() for target in targets]
# 前向传播
outputs = model(images)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后

一站式 AI 云服务平台
更多推荐
 21
21 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)