
【Redis 开发与运维】总结篇
Redis 是什么?简述它的优缺点?Redis 为什么这么快?Redis 相比 memcached 有哪些优势?说说 Redis 的数据类型和使用场景
文章目录
- Redis 是什么?简述它的优缺点?
- Redis 为什么这么快?
- Redis 相比 memcached 有哪些优势?
- 说说 Redis 的数据类型和使用场景
- 如何通过 Redis 实现分布式锁
- 如何使用 Redis 做异步队列
- 使用 Pipeline 的好处
- Redis 过期键的删除策略?
- Redis 内存淘汰机制?
- Redis 持久化机制
- 说说缓存设计中会出现的问题和解决方案
- 高并发场景下,如何解决数据库与缓存双写的时候数据不一致的情况?
- Redis 中跳跃表 skiplist 实现原理
- Redis 为什么用 skiplist 而不用红黑树?
- 假如 Redis 里面有 1 亿个key,其中有 10w 个 key 是以某个固定的已知前缀开头的,如何将它们全部找出来?
- Redis6.0 为什么要引入多线程?
- Redis 集群方案应该怎么做?都有哪些方案?
- 讲一讲位图 Bitmap
- 讲一讲 HyperLogLog
- Redis 单线程如何处理那么多的并发客户端连接?
- 布隆过滤器的原理
- 慢查询场景有哪些?
- 如何保证 redis/mysql 的一致性?
Redis 是什么?简述它的优缺点?
- Redis 本质上是一个 Key-Value 类型的内存数据库,很像 memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据 flush 到硬盘上进行保存。
- 因为是纯内存操作,Redis 的性能非常出色,
每秒可以处理超过 10 万次读写操作,是已知性能最快的 Key-Value DB。 - Redis 的出色之处不仅仅是性能,Redis 最大的魅力是支持保存多种数据结构,此外单个 value 的最大限制是 1GB,不像 memcached 只能保存 1MB 的数据,因此
Redis 可以用来实现很多有用的功能。 - Redis 的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上。
Redis 为什么这么快?
纯内存访问,Redis 将所有数据都放在内存中;- 采用的是
基于非阻塞的 IO 多路复用机制,避免了网络 IO 上浪费过多时间; - 单线程
避免了线程切换和竞态产生的消耗。
Redis 相比 memcached 有哪些优势?
- 数据类型:Redis 支持更丰富的数据类型(支持更复杂的应用场景),Redis 不仅仅支持简单的 key/value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。memcache 只支持简单的数据类型 String。
- 持久化:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。
- 集群模式:memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 原生支持集群模式。
- 线程模型:Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。
说说 Redis 的数据类型和使用场景
Redis 支持五种数据类型:string( 字符串),hash( 哈希),list( 列表),set( 集合)及 zset(sorted set:有序集合)。
- string:redis 中字符串 value 最大可为 512M。可以用来做一些计数功能的缓存(也是实际工作中最常见的)。常规计数:微博数,粉丝数等。
- hash:键值对集合,是一个字符串类型的 Key 和 Value 的映射表,也就是说其存储的 Value 是一个键值对(Key- Value),hash 特别适合用于存储对象,后续操作的时候,可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
- list:简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边),Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。可以实现一个简单消息队列功能,做基于 redis 的分页功能等。还可以通过 lrange 命令做(微博、朋友圈)文章列表分页,就是从某个元素开始读取多少个元素,可以基于 list 实现高性能分页。
- set:是一个字符串类型的无序集合。可以用来进行全局去重等,比如:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合,Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能,这个过程也就是求交集的过程。
- sorted set:是一个字符串类型的有序集合,给每一个元素一个固定的分数 score 来保持顺序。可以用来做排行榜应用或者进行范围查找等。
我们实际项目中比较常用的是 string、hash。 如果你是 Redis 的高级用户,还需要加上下面几种数据结构 HyperLogLog、Geo、Pub/Sub。
如果你说还玩过 Redis Module,像 BloomFilter,RedisSearch,Redis-ML,面试官得眼睛就开始发亮了。
如何通过 Redis 实现分布式锁
分布式锁需要解决的问题
- 互斥性
- 安全性
- 死锁
- 容错
利用 SETNX key value:如果 key 不存在,则创建并赋值;设置成功,返回 1。设置失败,返回 0。
问题一:如何解决 SETNX 长期有效的问题
- EXPIRE key seconds:设置 key 的生存时间,当 key 过期时(生存时间为0),会自动被删除
- 缺点:原子性得不到满足,因为 SETNX 和 EXPIRE 命令是两个操作不满足原子性。
答:可以利用:SET key value [EX seconds] [PX milliseconds] [NX|XX]
- Ex second:设置键的过期时间为 second 秒
- PX milliseconds:设置键的过期时间为 millisecond 毫秒
- NX:只在键不存在时,才对键进行设置操作
- XX:只在键已经存在时,才对键进行设置操作
- SET 操作成功完成时,返回 OK,否则返回 nil
- 例如:
set lock 12345 ex 10 nx,表示设置了一个 key 为 lock 的锁,锁的过期时间为 10 秒
问题二:怎么处理别人把我的锁释放(删除)的问题
- 因为锁的释放无非就是删除掉,那个 key 嘛,删了锁就释放了。
答:
- 可以把锁的值设为用户 ID,删除之前比对用户 ID 和锁的值是否相等,只有相等才能删除。
- 因为判断锁相等和删除锁是两个操作,不满足原子性,于是可以利用 Lua 做到原子性。例如:
/**
* 解锁
*
* @param id
* @return
*/
public boolean unlock(String id) {
String script =
"if redis.call('get',KEYS[1]) == ARGV[1] then" +
" return redis.call('del',KEYS[1]) " +
"else" +
" return 0 " +
"end";
try {
String result = jedis.eval(script, Collections.singletonList(LOCK_KEY), Collections.singletonList(id)).toString();
return "1".equals(result) ? true : false;
} finally {
jedis.close();
}
}
大量的 key 同时过期的注意事项
- 集中过期,由于清除大量的 key 很耗时,
会出现短暂的卡顿现象 - 解决方案:在设置 key 的过期时间的时候,
给每个 key 加上随机值
问题三:锁过期时间到了业务没执行完怎么办?
- 默认情况下,加锁的时间是 30 秒,如果加锁的业务没有执行完,那么到 30-10 = 20 秒的时候,就会进行一次续期,把锁重置成 30 秒,那这个时候可能又有同学问了,那业务的机器万一宕机了呢?宕机了定时任务跑不了,就续不了期,那自然30秒之后锁就解开了呗。
如何使用 Redis 做异步队列
使用 Redis 的 List 作为队列,RPUSH 生产消息,LPOP 消费消息
- 缺点:没有等待队列里有值就直接消费
- 弥补:可以通过在应用层引入 Sleep 机制去调用 LPOP 重试
BLPOP key [key ...] timeout:阻塞直到队列有消息或者超时
- 缺点:只能供一个消费者消费
pub/sub:主题订阅者模式
- 发送者(pub)发送消息,如:
publish myTopic hello,表示向 myTopic 发布消息 hello - 订阅者(sub)接收消息,如:
subscribe myTopic,表示订阅 myTopic 的消息 - 订阅者可以订阅任意数量的频道
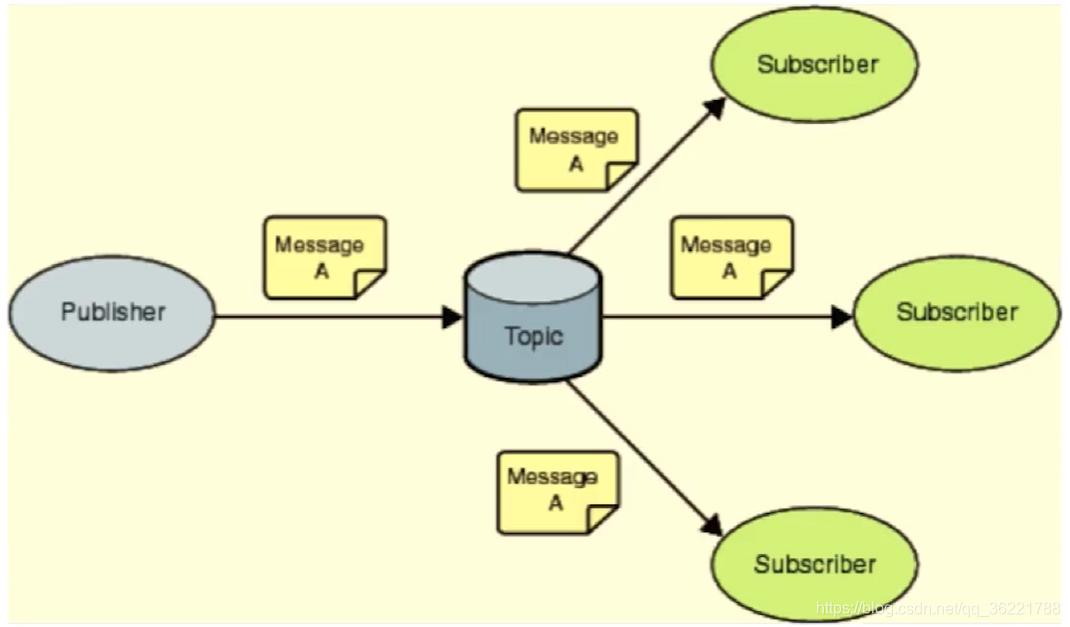
缺点:消息的发布是无状态的,无法保证可达,消息还是即发即失的
使用 Pipeline 的好处
- Redis 提供了批量操作命令(例如 mget、mset 等),
有效地节约 RTT(Round Trip Time,往返时间)。但大部分命令是不支持批量操作的,例如要执行 n 次 hset 命令,并没有 mhset 命令存在,需要消耗 n 次 RTT。 - Pipeline(流水线)机制能改善上面这类问题,它能将一组 Redis 命令进行组装,通过一次 RTT 传输给 Redis,再将这组 Redis 命令的执行结果按顺序返回给客户端。
详情请参考:Redis 一些超好用的功能特性
Redis 过期键的删除策略?
- 定时删除:超时时间到达时,删除
- 惰性删除:再次访问过期数据时,删除
- 定期删除:每隔一定周期,删除
- 对于定时删除:由于数据库可能同时接受成千上万个用户的访问,那么可能有大量的 key 需要删除,如果我们为每一个 key 的超时时间都设置一个定时器,每次超时就进行删除操作,那么会导致系统性能非常低。
- 对于惰性删除:如果一个过期 key 长期没有被访问,那么该 key-value 对将会一直存储在数据库中,会一直占有内存。而 redis 又是一个基于内存的数据库,这样很容易导致内存被耗尽。
- 对于定期删除 :redis 难以确定执行删除操作的时长和频率
- 因此 redis 采用
惰性删除和定期删除相结合的方式,来删除系统中的过期键
Redis 内存淘汰机制?
- Redis v4.0 前提供 6 种数据淘汰策略:
- volatile-lru:利用 LRU 算法移除设置过期时间的 key(LRU:最近最少使用,Least Recently Used )
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,从数据集中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。
- Redis v4.0 后增加以下 2 种:
- volatile-lfu:从已设置过期时间的数据集中挑选最不经常使用的数据淘汰(LFU,Least Frequently Used)算法,也就是最频繁被访问的数据将来最有可能被访问到。
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key。
Redis 持久化机制
说说缓存设计中会出现的问题和解决方案
详情请参考:《【Redis 开发与运维】缓存设计》
高并发场景下,如何解决数据库与缓存双写的时候数据不一致的情况?
Redis 中跳跃表 skiplist 实现原理
跳表(skiplist)是一个特殊的链表,相比一般的链表,有更高的查找效率,其效率可比拟于二叉查找树。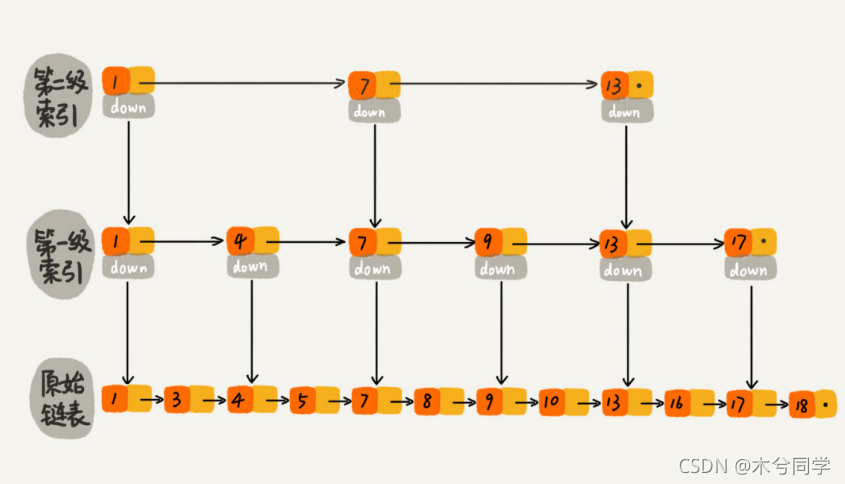
跳表的性质:
- 由很多层结构组成
- 每一层都是一个有序的链表
- 最底层(Level 1)的链表包含所有元素
- 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
随机层数的设计:
- Redis 使用随机层数,解决插入、删除时,时间复杂度重新蜕化成 O(n) 的问题
- 它不要求上下相邻两层链表之间的节点个数有严格的对应关系,而是为每个节点随机出一个层数(level)。比如,一个节点随机出的层数是 3,那么就把它链入到第 1 层到第 3 层这三层链表中。
随机层数的计算方式:
- 执行插入操作时计算随机数的过程,是一个很关键的过程,它对 skiplist 的统计特性有着很重要的影响。这并不是一个普通的服从均匀分布的随机数,它的计算过程如下:
- 首先,每个节点肯定都有第 1 层指针(每个节点都在第 1 层链表里)。
- 如果一个节点有第 i 层(i >= 1)指针(即节点已经在第 1 层到第 i 层链表中),那么它有第(i + 1)层指针的概率为 p。
- 节点最大的层数不允许超过一个最大值,记为 MaxLevel。
- 这个计算随机层数的伪码如下所示:
randomLevel()
level := 1
// random()返回一个[0...1)的随机数
while random() < p and level < MaxLevel do
level := level + 1
return level
- randomLevel() 的伪码中包含两个参数,一个是 p,一个是 MaxLevel。在 Redis 的 skiplist 实现中,这两个参数的取值为:
p = 1/4
MaxLevel = 32
- 所以,根据前面 randomLevel() 的伪码,我们很容易看出,产生越高的节点层数,概率越低。
- 当 skiplist 中有 n 个节点的时候,它的总层数的概率均值是多少。这个问题直观上比较好理解。根据节点的层数随机算法,容易得出:
- 第 1 层链表固定有
n个节点; - 第 2 层链表平均有
n*p个节点; - 第 3 层链表平均有
n*p*p个节点;
- 第 1 层链表固定有
Redis 为什么用 skiplist 而不用红黑树?
- 插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,
按照区间来查找数据这个操作,红黑树的效率没有跳表高,跳表可以做到 O(logn) 的时间复杂度; - 比起红黑树来说,跳表更容易代码实现;
- 跳表更加灵活,它可以通过改变索引构建策略有效平衡执行效率和内存消耗。
假如 Redis 里面有 1 亿个key,其中有 10w 个 key 是以某个固定的已知前缀开头的,如何将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。
追问:如果这个 redis 正在给线上的业务提供服务, 那使用 keys 指令会有什么问题?
keys 指令会导致线程阻塞一段时间, 线上服务会停顿, 直到指令执行完毕, 服务才能恢复。
可以使用 SCAN cusor [MATCH patten] [COUNT count],每次只返回少量元素
- 基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程
- 以 0 作为游标开始一次新的迭代,直到命令返回游标 0 完成一次遍历,记得
将上次返回的游标作为下次 SCAN 的游标 - 不保证每次执行都返回某个给定数量的元素,只能是大概率符合 count 参数,支持模糊查询
- 可能会
获取到重复 key 的问题,需要在客户端进行去重,比如用 HashSet 接收 - 如:
scan 0 match k1* count 10,表示将键为 k1 开头的从 0 开始的游标数 10 个(10 个以内,不一定是 10 个)返回
Redis6.0 为什么要引入多线程?
- Redis6.0 的多线程是指,将网络数据读写和协议解析通过多线程的方式来处理,对于命令执行来说,仍然使用单线程操作。也就是说,Redis6.0 的多线程是为了解决其网络 IO 的瓶颈。
Redis 集群方案应该怎么做?都有哪些方案?
讲一讲位图 Bitmap
详情请参考:【Redis 开发与运维】小功能大用处
讲一讲 HyperLogLog
HyperLogLog,它是 LogLog 算法的升级版,作用是能够提供不精确的去重计数。存在以下的特点:
- 能够使用
极少的内存来统计巨量的数据,在 Redis 中实现的 HyperLogLog,只需要 12K 内存就能统计 2^64 个数据 - 计数存在一定的误差,误差率整体较低,标准误差为 0.81%
- 误差可以被设置辅助计算因子进行降低
为什么用 HyperLogLog,例如以下场景:
统计 APP 或网页的一个页面,每天有多少用户点击进入的次数,同一个用户的反复点击进入记为 1 次。
这种场景用 HashMap 这种数据结构也可以,但是假设 APP 中日活用户达到百万或千万以上级别的话,采用 HashMap 的做法就会导致程序中占用大量的内存。
Redis 单线程如何处理那么多的并发客户端连接?
因为 Redis 的线程模型:基于非阻塞的 IO 多路复用机制。多路指的是多个 Socket 连接,复用指的是复用一个线程。
Redis 采用 IO 多路复用机制同时监听多个 Socket,多个 Socket 会产生不同的事件,不同的事件对应着不同的操作,当这些 Socket 产生了事件,IO 多路复用程序会将这些事件放到一个队列中,通过这个队列,以有序、同步、每次一个事件的方式向文件时间分派器中传送。当事件处理器处理完一个事件后,IO 多路复用程序才会继续向文件分派器传送下一个事件。
布隆过滤器的原理
首先需要 k 个 hash 函数,每个函数可以把 key 散列成为 1 个整数;
初始化时,需要一个长度为 n 比特的数组,每个比特位初始化为 0;
某个 key 加入集合时,用 k 个 hash 函数计算出 k 个散列值,并把数组中对应的比特位置为 1;
判断某个 key 是否在集合时,用 k 个 hash 函数计算出 k 个散列值,并查询数组中对应的比特位,如果所有的比特位都是 1,则命中,但不一定在集合中,如果存在比特位为 0,则未命中,一定不在集合中。
优点:不需要存储 key,节省空间
缺点:
- 算法判断 key 在集合中时,有一定的概率 key 其实不在集合中
- 无法删除
慢查询场景有哪些?
- 使用 O(n) 复杂度的命令,比如 keys *
- 大对象的查询也有可能造成慢查询
- 关于阻塞的原因,请参考:Redis 的噩梦:阻塞
如何保证 redis/mysql 的一致性?
巨人的肩膀:https://github.com/cosen1024/Java-Interview/blob/main/Redis/Redis.md

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)