
Redis入门完整教程:集群运维
Redis集群由于自身的分布式特性,相比单机场景在开发和运维方面存在一些差异。本节我们关注于常见的问题进行分析定位。10.7.1 集群完整性为了保证集群完整性,默认情况下当集群16384个槽任何一个没有指派到节点时整个集群不可用。执行任何键命令返回(error)CLUSTERDOWNHash slot not served错误。这是对集群完整性的一种保护措施,保证所有的槽都指派给在线的节点。但是当
Redis集群由于自身的分布式特性,相比单机场景在开发和运维方面存
在一些差异。本节我们关注于常见的问题进行分析定位。
10.7.1 集群完整性
为了保证集群完整性,默认情况下当集群16384个槽任何一个没有指派
到节点时整个集群不可用。执行任何键命令返回(error)CLUSTERDOWN
Hash slot not served错误。这是对集群完整性的一种保护措施,保证所有的
槽都指派给在线的节点。但是当持有槽的主节点下线时,从故障发现到自动
完成转移期间整个集群是不可用状态,对于大多数业务无法容忍这种情况,
因此建议将参数cluster-require-full-coverage配置为no,当主节点故障时只影
响它负责槽的相关命令执行,不会影响其他主节点的可用性。
10.7.2 带宽消耗
集群内Gossip消息通信本身会消耗带宽,官方建议集群最大规模在1000
以内,也是出于对消息通信成本的考虑,因此单集群不适合部署超大规模的
节点。在之前节点通信小节介绍到,集群内所有节点通过ping/pong消息彼此
交换信息,节点间消息通信对带宽的消耗体现在以下几个方面:
·消息发送频率:跟cluster-node-timeout密切相关,当节点发现与其他节
点最后通信时间超过cluster-node-timeout/2时会直接发送ping消息。
·消息数据量:每个消息主要的数据占用包含:slots槽数组(2KB空
间)和整个集群1/10的状态数据(10个节点状态数据约1KB)。
·节点部署的机器规模:机器带宽的上线是固定的,因此相同规模的集
群分布的机器越多每台机器划分的节点越均匀,则集群内整体的可用带宽越
高。
例如,一个总节点数为200的Redis集群,部署在20台物理机上每台划分
10个节点,cluster-node-timeout采用默认15秒,这时ping/pong消息占用带宽
达到25Mb。如果把cluster-node-timeout设为20,对带宽的消耗降低到15Mb以
下。
集群带宽消耗主要分为:读写命令消耗+Gossip消息消耗。因此搭建
Redis集群时需要根据业务数据规模和消息通信成本做出合理规划:
1)在满足业务需要的情况下尽量避免大集群。同一个系统可以针对不
同业务场景拆分使用多套集群。这样每个集群既满足伸缩性和故障转移要
675
求,还可以规避大规模集群的弊端。如笔者维护的一个推荐系统,根据数据
特征使用了5个Redis集群,每个集群节点规模控制在100以内。
2)适度提高cluster-node-timeout降低消息发送频率,同时cluster-node-
timeout还影响故障转移的速度,因此需要根据自身业务场景兼顾二者的平
衡。
3)如果条件允许集群尽量均匀部署在更多机器上。避免集中部署,如
集群有60个节点,集中部署在3台机器上每台部署20个节点,这时机器带宽
消耗将非常严重。
10.7.3 Pub/Sub广播问题
Redis在2.0版本提供了Pub/Sub(发布/订阅)功能,用于针对频道实现
消息的发布和订阅。但是在集群模式下内部实现对所有的publish命令都会向
所有的节点进行广播,造成每条publish数据都会在集群内所有节点传播一
次,加重带宽负担,如图10-44所示:
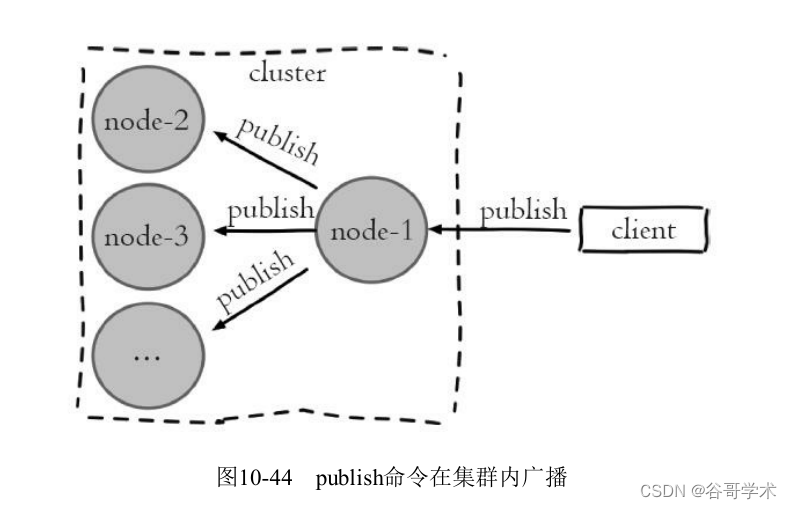
通过命令演示Pub/Sub广播问题,如下所示:
1)对集群所有主从节点执行subscribe命令订阅cluster_pub_spread频
道,用于验证集群是否广播消息:
127.0.0.1:6379> subscribe cluster_pub_spread
127.0.0.1:6380> subscribe cluster_pub_spread
127.0.0.1:6382> subscribe cluster_pub_spread
127.0.0.1:6383> subscribe cluster_pub_spread
127.0.0.1:6385> subscribe cluster_pub_spread
127.0.0.1:6386> subscribe cluster_pub_spread
2)在6379节点上发布频道为cluster_pub_spread的消息:
127.0.0.1:6379> publish cluster_pub_spread message_body_1
3)集群内所有的节点订阅客户端全部收到了消息:
127.0.0.1:6380> subscribe cluster_pub_spread
1) "message"
2) "cluster_pub_spread"
3) "message_body_1
127.0.0.1:6382> subscribe cluster_pub_spread
1) "message"
2) "cluster_pub_spread"
3) "message_body_1
...
针对集群模式下publish广播问题,需要引起开发人员注意,当频繁应用
Pub/Sub功能时应该避免在大量节点的集群内使用,否则会严重消耗集群内
网络带宽。针对这种情况建议使用sentinel结构专门用于Pub/Sub功能,从而
规避这一问题。
10.7.4 集群倾斜
集群倾斜指不同节点之间数据量和请求量出现明显差异,这种情况将加
大负载均衡和开发运维的难度。因此需要理解哪些原因会造成集群倾斜,从
而避免这一问题。
1.数据倾斜
数据倾斜主要分为以下几种:
·节点和槽分配严重不均。
·不同槽对应键数量差异过大。
·集合对象包含大量元素。
·内存相关配置不一致。
1)节点和槽分配严重不均。针对每个节点分配的槽不均的情况,可以
使用redis-trib.rb info{host:ip}进行定位,命令如下:
#redis-trib.rb info 127.0.0.1:6379
127.0.0.1:6379 (cfb28ef1...) -> 33348 keys | 5461 slots | 1 slaves.
127.0.0.1:6380 (8e41673d...) -> 33391 keys | 5461 slots | 1 slaves.
127.0.0.1:6386 (475528b1...) -> 33263 keys | 5462 slots | 1 slaves.
[OK] 100002 keys in 3 masters.
6.10 keys per slot on average.
以上信息列举出每个节点负责的槽和键总量以及每个槽平均键数量。当
节点对应槽数量不均匀时,可以使用redis-trib.rb rebalance命令进行平衡:
#redis-trib.rb rebalance 127.0.0.1:6379
...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.0% threshold.
2)不同槽对应键数量差异过大。键通过CRC16哈希函数映射到槽上,
正常情况下槽内键数量会相对均匀。但当大量使用hash_tag时,会产生不同
的键映射到同一个槽的情况。特别是选择作为hash_tag的数据离散度较差
时,将加速槽内键数量倾斜情况。通过命令:cluster countkeysinslot{slot}可
以获取槽对应的键数量,识别出哪些槽映射了过多的键。再通过命令cluster
getkeysinslot{slot}{count}循环迭代出槽下所有的键。从而发现过度使用
hash_tag的键。
3)集合对象包含大量元素。对于大集合对象的识别可以使用redis-cli--
bigkeys命令识别,具体使用见12.5节。找出大集合之后可以根据业务场景进
行拆分。同时集群槽数据迁移是对键执行migrate操作完成,过大的键集合如
几百兆,容易造成migrate命令超时导致数据迁移失败。
4)内存相关配置不一致。内存相关配置指hash-max-ziplist-value、set-
max-intset-entries等压缩数据结构配置。当集群大量使用hash、set等数据结构
时,如果内存压缩数据结构配置不一致,极端情况下会相差数倍的内存,从
而造成节点内存量倾斜。
2.请求倾斜
集群内特定节点请求量/流量过大将导致节点之间负载不均,影响集群
均衡和运维成本。常出现在热点键场景,当键命令消耗较低时如小对象的
get、set、incr等,即使请求量差异较大一般也不会产生负载严重不均。但是
当热点键对应高算法复杂度的命令或者是大对象操作如hgetall、smembers
680
等,会导致对应节点负载过高的情况。避免方式如下:
1)合理设计键,热点大集合对象做拆分或使用hmget替代hgetall避免整
体读取。
2)不要使用热键作为hash_tag,避免映射到同一槽。
3)对于一致性要求不高的场景,客户端可使用本地缓存减少热键调
用。
10.7.5 集群读写分离
1.只读连接
集群模式下从节点不接受任何读写请求,发送过来的键命令会重定向到
负责槽的主节点上(其中包括它的主节点)。当需要使用从节点分担主节点
读压力时,可以使用readonly命令打开客户端连接只读状态。之前的复制配
置slave-read-only在集群模式下无效。当开启只读状态时,从节点接收读命
令处理流程变为:如果对应的槽属于自己正在复制的主节点则直接执行读命
令,否则返回重定向信息。命令如下:
// 默认连接状态为普通客户端 :flags=N
127.0.0.1:6382> client list
id=3 addr=127.0.0.1:56499 fd=6 name= age=130 idle=0 flags=N db=0 sub=0 psub=0 multi=-1
qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
// 命令重定向到主节点
127.0.0.1:6382> get key:test:3130
(error) MOVED 12944 127.0.0.1:6379
// 打开当前连接只读状态
127.0.0.1:6382> readonly
OK
// 客户端状态变为只读 :flags=r
127.0.0.1:6382> client list
id=3 addr=127.0.0.1:56499 fd=6 name= age=154 idle=0 flags=r db=0 sub=0 psub=0 multi=-1
qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
// 从节点响应读命令
127.0.0.1:6382> get key:test:3130
"value:3130"
readonly命令是连接级别生效,因此每次新建连接时都需要执行readonly
开启只读状态。执行readwrite命令可以关闭连接只读状态。
2.读写分离
集群模式下的读写分离,同样会遇到:复制延迟,读取过期数据,从节
点故障等问题,具体细节见6.5复制运维小节。针对从节点故障问题,客户
端需要维护可用节点列表,集群提供了cluster slaves{nodeId}命令,返回
nodeId对应主节点下所有从节点信息,数据格式同cluster nodes,命令如下:
// 返回 6379 节点下所有从节点
127.0.0.1:6382> cluster slaves cfb28ef1deee4e0fa78da86abe5d24566744411e
1) "40622f9e7adc8ebd77fca0de9edfe691cb8a74fb 127.0.0.1:6382 myself,slave cfb28e
f1deee4e0fa78da86abe5d24566744411e 0 0 3 connected"
2) "2e7cf7539d076a1217a408bb897727e5349bcfcf 127.0.0.1:6384 slave,fail cfb28ef1
deee4e0fa78da86abe5d24566744411e 1473047627396 1473047622557 13 disconnected"
解析以上从节点列表信息,排除fail状态节点,这样客户端对从节点的
故障判定可以委托给集群处理,简化维护可用从节点列表难度。
开发提示
集群模式下读写分离涉及对客户端修改如下:
1)维护每个主节点可用从节点列表。
2)针对读命令维护请求节点路由。
3)从节点新建连接开启readonly状态。
集群模式下读写分离成本比较高,可以直接扩展主节点数量提高集群性
能,一般不建议集群模式下做读写分离。
集群读写分离有时用于特殊业务场景如:
1)利用复制的最终一致性使用多个从节点做跨机房部署降低读命令网
络延迟。
2)主节点故障转移时间过长,业务端把读请求路由给从节点保证读操
作可用。
以上场景也可以在不同机房独立部署Redis集群解决,通过客户端多写
来维护,读命令直接请求到最近机房的Redis集群,或者当一个集群节点故
障时客户端转向另一个集群。
10.7.6 手动故障转移
Redis集群提供了手动故障转移功能:指定从节点发起转移流程,主从
节点角色进行切换,从节点变为新的主节点对外提供服务,旧的主节点变为
它的从节点,如图10-45所示。
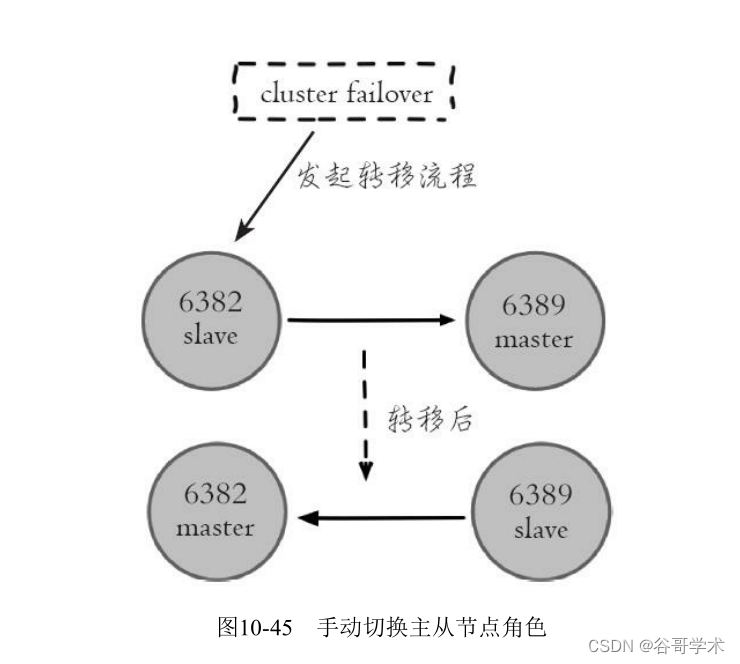
在从节点上执行cluster failover命令发起转移流程,默认情况下转移期
间客户端请求会有短暂的阻塞,但不会丢失数据,流程如下:
1)从节点通知主节点停止处理所有客户端请求。
2)主节点发送对应从节点延迟复制的数据。
3)从节点接收处理复制延迟的数据,直到主从复制偏移量一致为止,
保证复制数据不丢失。
4)从节点立刻发起投票选举(这里不需要延迟触发选举)。选举成功
后断开复制变为新的主节点,之后向集群广播主节点pong消息,故障转移细
节见10.6故障恢复部分。
5)旧主节点接受到消息后更新自身配置变为从节点,解除所有客户端
请求阻塞,这些请求会被重定向到新主节点上执行。
6)旧主节点变为从节点后,向新的主节点发起全量复制流程。
运维提示
主从节点转移后,新的从节点由于之前没有缓存主节点信息无法使用部
分复制功能,所以会发起全量复制,当节点包含大量数据时会严重消耗CPU
和网络资源,线上不要频繁操作。Redis4.0的Psync2将有效改善这一问题。
手动故障转移的应用场景主要如下:
1)主节点迁移:运维Redis集群过程中经常遇到调整节点部署的问题,
如节点所在的老机器替换到新机器等。由于从节点默认不响应请求可以安全
下线关闭,但直接下线主节点会导致故障自动转移期间主节点无法对外提供
服务,影响线上业务的稳定性。这时可以使用手动故障转移,把要下线的主
节点安全的替换为从节点后,再做下线操作操作,如图10-46所示。
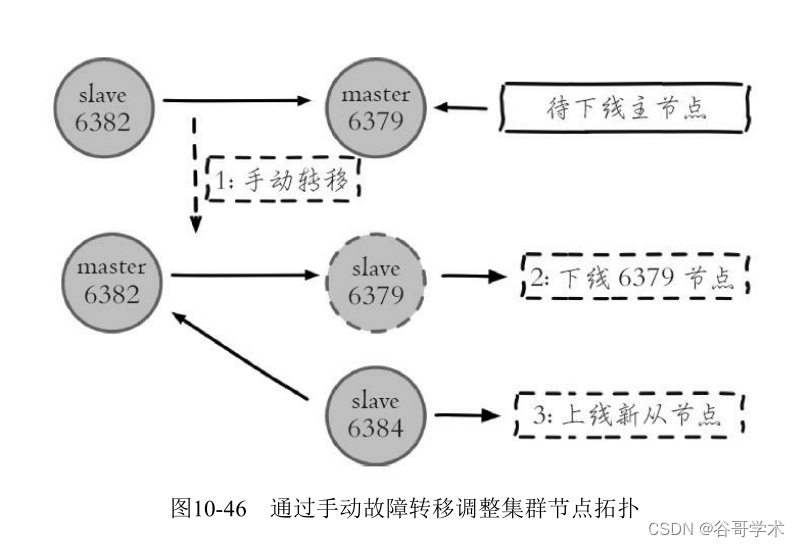
2)强制故障转移。当自动故障转移失败时,只要故障的主节点有存活
的从节点就可以通过手动转移故障强制让从节点替换故障的主节点,保证集
群的可用性。自动故障转移失败的场景有:
·主节点和它的所有从节点同时故障。这个问题需要通过调整节点机器
部署拓扑做规避,保证主从节点不在同一机器/机架上。除非机房内大面积
故障,否则两台机器/机架同时故障概率很低。
·所有从节点与主节点复制断线时间超过cluster-slave-validity-
factor*cluster-node-tineout+repl-ping-slave-period,导致从节点被判定为没有
故障转移资格,手动故障转移从节点不做中断超时检查。
·由于网络不稳定等问题,故障发现或故障选举时间无法在cluster-node-
timeout*2内完成,流程会不断重试,最终从节点复制中断时间超时,失去故
障转移资格无法完成转移。
·集群内超过一半以上的主节点同时故障。
根据以上情况,cluster failover命令提供了两个参数force/takeover提供支
持:
·cluster failover force——用于当主节点宕机且无法自动完成故障转移情
况。从节点接到cluster failover force请求时,从节点直接发起选举,不再跟
主节点确认复制偏移量(从节点复制延迟的数据会丢失),当从节点选举成
功后替换为新的主节点并广播集群配置。
·cluster failover takeover——用于集群内超过一半以上主节点故障的场
景,因为从节点无法收到半数以上主节点投票,所以无法完成选举过程。可
以执行cluster failover takeover强制转移,接到命令的从节点不再进行选举流
程而是直接更新本地配置纪元并替换主节点。takeover故障转移由于没有通
过领导者选举发起故障转移,会导致配置纪元存在冲突的可能。当冲突发生
时,集群会以nodeId字典序更大的一方配置为准。因此要小心集群分区后,
手动执行takeover导致的集群冲突问题。如图10-47所示。
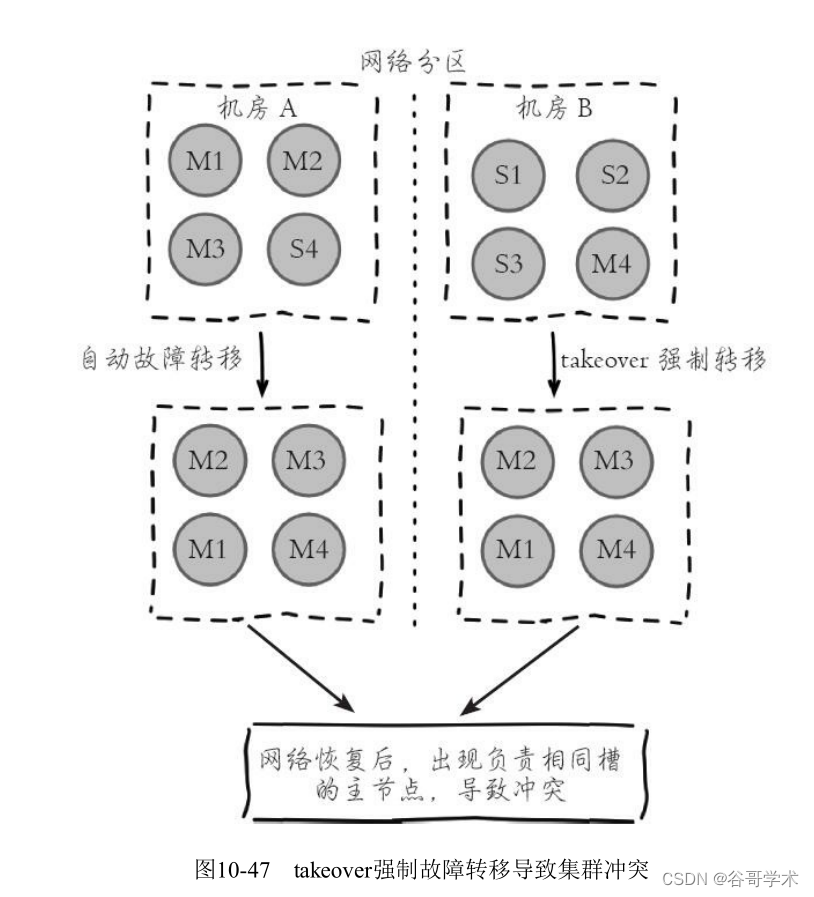
图中Redis集群分别部署在2个同城机房,机房A部署节点:master-1、
master-2、master-3、slave-4。机房B部署节点:slave-1、slave-2、slave-3、
master-4。
·当机房之间出现网络中断时,机房A内的节点持有半数以上主节点可
以完成故障转移,会将slave-4转换为master-4。
·如果客户端应用都部署在机房B,运维人员为了快速恢复对机房B的
Redis访问,对slave-1,slave-2,slave-3分别执行cluster failover takeover强制
故障转移,让机房B的节点可以快速恢复服务。
·当机房专线恢复后,Redis集群会拥有两套持有相同槽信息的主节点。
这时集群会使用配置纪元更大的主节点槽信息,配置纪元相等时使用nodeId
更大的一方,因此最终会以哪个主节点为准是不确定的。如果集群以机房A
的主节点槽信息为准,则这段时间内对机房B的写入数据将会丢失。
综上所述,在集群可以自动完成故障转移的情况下,不要使用cluster
failover takeover强制干扰集群选举机制,该操作主要用于半数以上主节点故
障时采取的强制措施,请慎用。
运维提示
手动故障转移时,在满足当前需求的情况下建议优先级:cluster
failver>cluster failover force>cluster failover takeover。
10.7.7 数据迁移
应用Redis集群时,常需要把单机Redis数据迁移到集群环境。redis-
trib.rb工具提供了导入功能,用于数据从单机向集群环境迁移的场景,命令
如下:
redis-trib.rb import host:port --from <arg> --copy --replace
redis-trib.rb import命令内部采用批量scan和migrate的方式迁移数据。这
种迁移方式存在以下缺点:
1)迁移只能从单机节点向集群环境导入数据。
2)不支持在线迁移数据,迁移数据时应用方必须停写,无法平滑迁移
数据。
3)迁移过程中途如果出现超时等错误,不支持断点续传只能重新全量
导入。
4)使用单线程进行数据迁移,大数据量迁移速度过慢。
正因为这些问题,社区开源了很多迁移工具,这里推荐一款唯品会开发
的redis-migrate-tool,该工具可满足大多数Redis迁移需求,特点如下:
·支持单机、Twemproxy、Redis Cluster、RDB/AOF等多种类型的数据迁
移。
·工具模拟成从节点基于复制流迁移数据,从而支持在线迁移数据,业
务方不需要停写。
·采用多线程加速数据迁移过程且提供数据校验和查看迁移状态等功
能。
更多细节见GitHub:https://github.com/vipshop/redis-migrate-tool。
10.8 本章重点回顾
1)Redis集群数据分区规则采用虚拟槽方式,所有的键映射到16384个
槽中,每个节点负责一部分槽和相关数据,实现数据和请求的负载均衡。
2)搭建集群划分三个步骤:准备节点,节点握手,分配槽。可以使用
redis-trib.rb create命令快速搭建集群。
3)集群内部节点通信采用Gossip协议彼此发送消息,消息类型分为:
ping消息、pong消息、meet消息、fail消息等。节点定期不断发送和接受
ping/pong消息来维护更新集群的状态。消息内容包括节点自身数据和部分其
他节点的状态数据。
4)集群伸缩通过在节点之间移动槽和相关数据实现。扩容时根据槽迁
移计划把槽从源节点迁移到目标节点,源节点负责的槽相比之前变少从而达
到集群扩容的目的,收缩时如果下线的节点有负责的槽需要迁移到其他节
点,再通过cluster forget命令让集群内其他节点忘记被下线节点。
5)使用Smart客户端操作集群达到通信效率最大化,客户端内部负责计
算维护键→槽→节点的映射,用于快速定位键命令到目标节点。集群协议通
过Smart客户端全面高效的支持需要一个过程,用户在选择Smart客户端时建
议review下集群交互代码如:异常判定和重试逻辑,更新槽的并发控制等。
节点接收到键命令时会判断相关的槽是否由自身节点负责,如果不是则返回
重定向信息。重定向分为MOVED和ASK,ASK说明集群正在进行槽数据迁
移,客户端只在本次请求中做临时重定向,不会更新本地槽缓存。MOVED
重定向说明槽已经明确分派到另一个节点,客户端需要更新槽节点缓存。
6)集群自动故障转移过程分为故障发现和故障恢复。节点下线分为主
观下线和客观下线,当超过半数主节点认为故障节点为主观下线时标记它为
客观下线状态。从节点负责对客观下线的主节点触发故障恢复流程,保证集
群的可用性。
7)开发和运维集群过程中常见问题包括:超大规模集群带宽消耗,
pub/sub广播问题,集群节点倾斜问题,手动故障转移,在线迁移数据等。

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)