
Excel + Python办公自动化:CPK计算与正态分布显示
Cpk(过程能力指数,Process Capability Index)是一种用于评估过程在特定规格限内稳定地生产产品的能力的统计量。Cpk 综合考虑了过程的中心位置和变异情况,是评估过程性能的一种重要工具。Cpk 的计算假定数据是正态分布的,因此在实际应用中,应先对数据进行正态性检验。
CPK计算公式
Cpk(过程能力指数,Process Capability Index)是一种用于评估过程在特定规格限内稳定地生产产品的能力的统计量。Cpk 综合考虑了过程的中心位置和变异情况,是评估过程性能的一种重要工具。Cpk 的计算公式如下:
-
首先计算过程的均值(X̅)和标准差(σ):
均值(X̅)是所有测量值的平均值。
Xˉ=1n∑i=1nXi\bar{X} = \frac{1}{n} \sum_{i=1}^{n} X_iXˉ=n1∑i=1nXi标准差(σ)是衡量数据分散程度的一个统计量,计算公式为:
σ=∑i=1n(Xi−Xˉ)2n−1\sigma = \sqrt{\frac{\sum_{i=1}^{n} (X_i - \bar{X})^2}{n-1}}σ=n−1∑i=1n(Xi−Xˉ)2其中,XiX_iXi 是每个测量值,Xˉ\bar{X}Xˉ 是均值,nnn 是测量值的数量。
注意是基于部分样本的标准差,上式中分母是n-1。 -
确定规格限:
上规格限(USL, Upper Specification Limit)
下规格限(LSL, Lower Specification Limit)
这里的上下限规格需要用户提前指定给出。 -
计算 Cpu 和 Cpl:
Cpu(Upper Capability Index)衡量过程均值相对于上规格限的位置,计算公式为:
Cpu=USL−Xˉ3σCpu = \frac{USL - \bar{X}}{3\sigma}Cpu=3σUSL−Xˉ
Cpl(Lower Capability Index)衡量过程均值相对于下规格限的位置,计算公式为:
Cpl=Xˉ−LSL3σCpl = \frac{\bar{X} - LSL}{3\sigma}Cpl=3σXˉ−LSL
-
计算 Cpk:
Cpk 是 Cpu 和 Cpl 中的较小值,即:
Cpk=min(Cpu,Cpl)Cpk = \min(Cpu, Cpl)Cpk=min(Cpu,Cpl)Cpk 的值越大,表示过程在规格限内的能力越强。Cpk 的常见解释如下:
CPK≥1.67: 过程能力非常高。
1.33≤CPK<1.67: 过程能力较强,需保持。
1.0 ≤ Cpk < 1.33:过程能力尚可,但需要注意和改进。
Cpk < 1.0:过程能力不足,需要采取措施改进。
请注意,Cpk 的计算假定数据是正态分布的,因此在实际应用中,应先对数据进行正态性检验。
使用Python读取数据计算CPK,并显示正态分布图
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 设置 Seaborn 样式和字体
# 支持中文和负号,设置字体为SimHei,对全局的绘图样式生效
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
file_path = r"a.xlsx"
try:
# 读取 Excel 文件
xls = pd.ExcelFile(file_path)
sheet_names = xls.sheet_names
for sheet_name in xls.sheet_names:
try:
df = pd.read_excel(file_path, sheet_name=sheet_name)
# 验证 USL 和 LSL 的位置
if len(df) < 14 or len(df.columns) < 3:
raise ValueError("Excel 文件格式不正确,缺少 USL 或 LSL 数据")
USL = df.iloc[13, 1]
LSL = df.iloc[13, 2]
# 获取数据并检查数据完整性
data = df.iloc[6:12, 0:5].to_numpy().flatten()
if len(data) == 0:
raise ValueError("数据为空,无法计算")
mean = np.mean(data)
std = np.std(data, ddof=1) # 使用样本标准差ddof=1
CMU = (USL - mean) / (3 * std)
CML = (mean - LSL) / (3 * std)
CPK = min(CMU, CML)
print(f"{sheet_name}---- USL:{USL}, LSL:{LSL}, mean:{mean:.3f}, std:{std:.3f}")
print(f"{sheet_name}---- CMU:{CMU:.3f}, CML:{CML:.3f}, CPK:{CPK:.3f}")
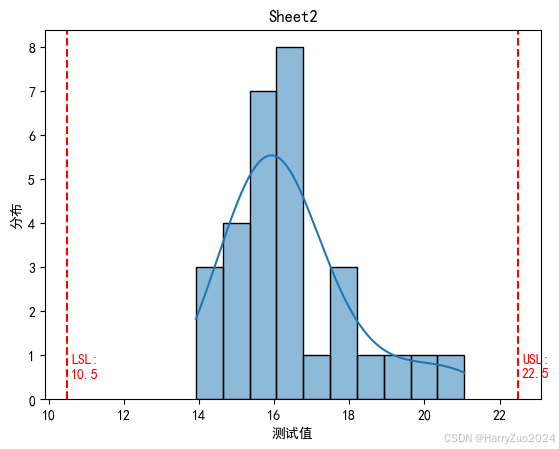
# 绘制直方图和核密度估计曲线
sns.histplot(data, kde=True, bins=10)
plt.title(f'{sheet_name}')
plt.xlabel('测试值')
plt.ylabel('分布')
# 在直方图中添加 USL 和 LSL 分界线与标签
plt.axvline(x=USL, color='r', linestyle='--')
plt.axvline(x=LSL, color='r', linestyle='--')
plt.text(USL + 0.1, 0.5, f'USL:\n{USL:.1f}', color='r')
plt.text(LSL + 0.1, 0.5, f'LSL:\n{LSL:.1f}', color='r')
plt.show()
except Exception as e:
print(f"处理 {sheet_name} 表时发生错误: {e}")
except Exception as e:
print(f"读取 Excel 文件时发生错误: {e}")
-
读取Excel文件:使用pandas库的ExcelFile功能来读取指定路径(file_path)的Excel文件。这个路径需要在代码中预先定义,但在给出的代码片段中未显示。
-
遍历工作表:通过sheet_names属性获取Excel文件中所有工作表的名称,并遍历这些名称。
-
读取和处理每个工作表的数据:
对于每个工作表,使用pd.read_excel读取数据。 -
验证数据格式:检查工作表是否至少有14行和3列,这是基于代码中后续处理需要访问第14行和第2、3列的数据(假设为USL和LSL值)以及第6到12行、第0到4列的数据(作为分析数据)。
-
提取上规格限(USL)和下规格限(LSL):从第14行的第2列和第3列获取。
-
数据提取和验证:从第6到12行、第0到4列提取数据,并将这些数据展平为一维数组。检查这个数组是否为空。
-
计算统计量:计算数据的均值(mean)和标准差(std)。
-
计算过程能力指数(Cpk):首先计算CMU和CML(分别是相对于USL和LSL的过程能力指数的上限和下限),然后取两者中的最小值作为Cpk值。Cpk是衡量过程满足规格限能力的指标。
-
打印结果:打印出每个工作表的USL、LSL、均值、标准差、CMU、CML和Cpk值。
-
数据可视化:使用seaborn库的histplot函数为每个工作表的数据绘制直方图和核密度估计曲线,以直观地展示数据的分布情况。
-
异常处理:
在处理每个工作表的数据时,如果遇到任何异常(如数据格式不正确、读取错误等),则捕获异常并打印错误信息。
在尝试读取Excel文件时,如果遇到任何异常(如文件不存在、路径错误等),也会捕获异常并打印错误信息。
注意:
这段代码依赖于pandas、numpy和seaborn库,以及matplotlib库(因为plt.show()用于显示图表)。
在实际使用前,需要确保file_path变量已正确定义,并指向一个有效的Excel文件。
代码假设每个工作表的数据格式是固定的,且特定的行和列包含USL、LSL和需要分析的数据。如果Excel文件的格式与此假设不符,代码将抛出异常。

一站式 AI 云服务平台
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)