
用pytest,读取excel中的值,完成自动化
1.excel列表----根据robotframe复制来。import openpyxlclass ReadExcel(object):def __init__(self, filename):self.filename = filenamedef read(self, sheetname):wb = openpyxl.load_workbook(self.filename)#打开文件(工作簿)s
·
1.excel列表----根据robotframe复制来。
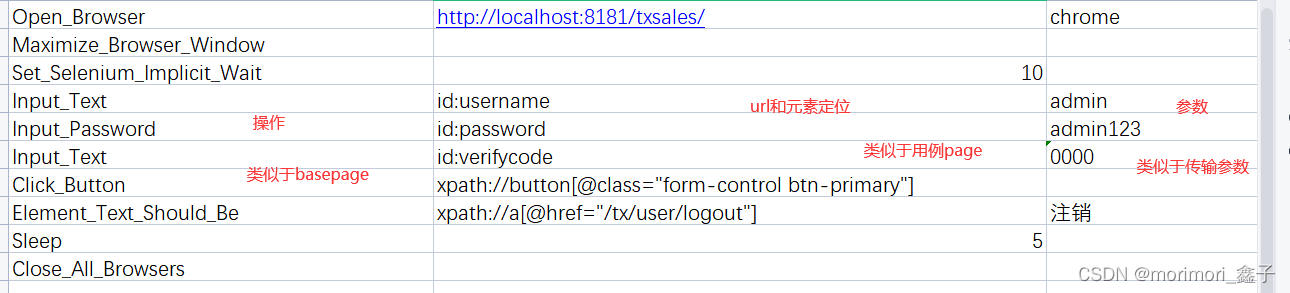
import openpyxl
class ReadExcel(object):
def __init__(self, filename):
self.filename = filename
def read(self, sheetname):
wb = openpyxl.load_workbook(self.filename) #打开文件(工作簿)
sheet = wb[sheetname] #打开里面的工作表
values = [list(i) for i in sheet.values] # 把生成器中的每个值读取出来,并且转为列表类型
#取出无效的列值 None
for row in values:
while None in row:
row.remove(None)
return values
if __name__ == '__main__':
data= ReadExcel("test_login.xlsx").read("testlogin")
print(data)
import time
import allure
from selenium import webdriver
class MySeleniumLibrary(object):
@allure.step("打开浏览器 【{browser}】 【{url}】 ")
def Open_Browser(self, url, browser: str):
if browser.lower() in ("firefox", "ff"):
self.dr = webdriver.Firefox()
elif browser.lower() in ("googlechrome", "chrome", "gc"):
self.dr = webdriver.Chrome()
else:
raise TypeError(f"你输入的浏览器类型【 {browser} 】不支持~~")
self.dr.get(url)
@allure.step("最大化浏览器")
def Maximize_Browser_Window(self):
self.dr.maximize_window()
@allure.step("设置隐式等待 【{value}】 ")
def Set_Selenium_Implicit_Wait(self, value: int):
self.dr.implicitly_wait(value)
@allure.step("输入文本 【{locator}】 【{text}】 【{clear}】")
def Input_Text(self, locator: str, text, clear=True):
element = self.dr.find_element(*locator.split(":", maxsplit=1))
if clear is True:
element.clear()
elif clear is False:
pass
element.send_keys(text)
@allure.step("输入密码 【{locator}】 【{password}】 【{clear}】")
def Input_Password(self, locator, password, clear=True):
element = self.dr.find_element(*locator.split(":", maxsplit=1)) #maxsplit=1,表示最多根据":”切割一次。
if clear is True:
element.clear()
elif clear is False:
pass
element.send_keys(password)
@allure.step("点击按钮 【{locator}】 ")
def Click_Button(self, locator):
self.dr.find_element(*locator.split(":", maxsplit=1)).click() #属性和属性值用逗号分开
@allure.step("判断元素文本存在 【{locator}】 【{expected}】 【{message}】")
def Element_Text_Should_Be(self, locator, expected, message=""):
element = self.dr.find_element(*locator.split(":", maxsplit=1)) #原始的写法是'id':'name';改成('id','name')
assert element.text == expected, message
@allure.step("设置超时时间 【{time_}】")
def Sleep(self, time_: [float, int]):
time.sleep(time_)
@allure.step("关闭浏览器")
def Close_All_Browsers(self):
self.dr.quit()
# 跑用例,如果出错要有日志,并且能生成html报告?
import pytest
from myseleniumlibrary import MySeleniumLibrary
from readexcel import ReadExcel
import subprocess
class Test():
def setup(self):
self.mySL = MySeleniumLibrary()
self.teststeps = ReadExcel("test_login.xlsx").read("testlogin")
def test(self):
# self.mySL.Open_Browser("http://localhost:8181/tx","chrome")
# self.mySL.Sleep(5)
# self.mySL.Close_All_Browsers()
# 遍历每一个步骤,运行步骤
for step in self.teststeps:
# 把步骤跑起来 ---> 反射?
method = getattr(self.mySL, step[0]) # 拿命令
method(*step[1:]) # 运行命令
if __name__ == '__main__':
allure_data_path = "report/allure_data"
allure_report_path = "report/allure_report"
pytest.main(["-v", "-s", f"--alluredir={allure_data_path}", "--clean-alluredir", __file__])
subprocess.run(f"allure generate {allure_data_path} --clean -o {allure_report_path}", shell=True,
universal_newlines=True)

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)