
大语言模型---第一章 绪论
探索不针对单一任务进行微调的情况下如何能够发挥大规模语言模型的能力,从直接利用大规模语言模型进行零样本和少样本学习的基础上,逐渐扩展到利用生成式框架针对大量任务进行有监督微调的方法,有效提升了模型的性能。缩放法则(Scaling Laws)指出模型的性能依赖于模型的规模,包括:参数数量,数据集大小,和计算量,模型的效果会随着三者指数增加而线性提高,模型损失(Loss)值伴随着模型规模指数增大而线性
数学符号,特有名词解释
1)基本概念
语言模型(Language Model,LM)目标就是建模自然语言的概率分布
首先Q1要解决词的全面分布概率,不能全量计算
出现了:n元语法或n元文法(n-gram)模型:可以进一步假设任意单词wi 出现的概率只与过去n − 1 个词相
然后Q2为了避免训练语料中的零频率,对所有可能出现的字符串都分配一个非零的概率值,从而避免零概率问题,
出现了:SLM:平滑处理的基本思想是提高低概率,降低高概率,使整体概率分布趋于均匀。平滑是为了产生更合理的概率,对最大似然估计及逆行调整的一类方法,数据平滑。
又然后Q3基于稀疏的表示n元语言模型有3个明显缺点
a无法建模长度超过n的上下文,
b依赖人工设计规则的平滑技术
c当n增大时,数据稀疏性随着增大,参数量成指数级增加,并且模型收到数据稀疏问题影响,其参数难以被准确学习
词的独热编码被映射为一个低维稠密的实数向量,词向量(Word Embedding)
出现了:神经语言模型NLM(Netrual Language Models)使用标注数据进行训练(有监督方法)
再然后Q4 NLM需要标注数据进行训练
出现了:语言模型成了自监督学习任务,以GPT和BERT为代表的基于Transformer模型的大规模预训练语言模型出现,使得自然语言处理全面进入了预训练微调范式新时代
预训练语言模型(PLM,Pre-trained Language Models)将预训练模型应用于下游任务
时,不需要了解太多的任务细节,不需要设计特定的神经网络结构,只需要“微调”预训练模型,
即使用具体任务的标注数据在预训练语言模型上进行监督训练,就可以取得显著的性能提升。
最后Q5 大规模语言模型出现,由于参数量据擦,如果在不同任务上都进行微调需要消耗大量的计算资源,因此预训练微调范式不再适用于大规模语言模型。
出现了:通过语境学习(Incontext Learning ICL)直接使用大规模语言模型就可以在很多任务的少样本场景取得很好效果 ,提示词(prompt)学习方法,模型即服务范式MaaS,指令微调(Instruction Tuning)等各种方法
缩放法则(Scaling Laws)指出模型的性能依赖于模型的规模,包括:参数数量,数据集大小,和计算量,模型的效果会随着三者指数增加而线性提高,模型损失(Loss)值伴随着模型规模指数增大而线性降低
2)大规模语言模型发展历程
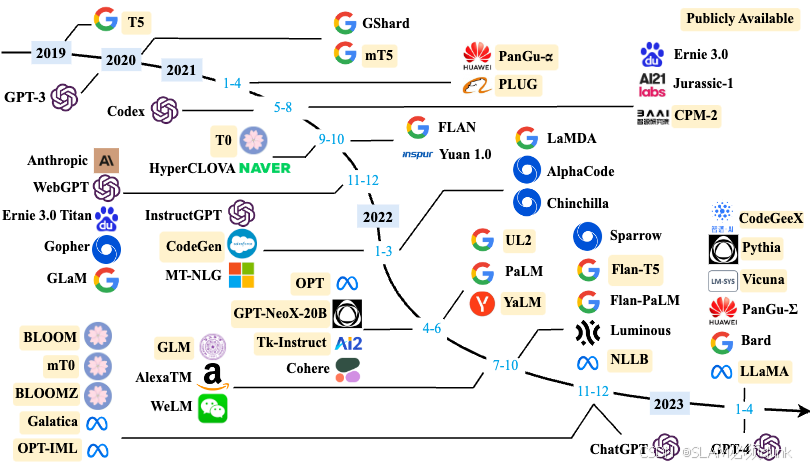
基础模型、
这个阶段研究主要集中语言模型本身,包括仅编码器(Encoder Only)、编码器-解码器(Encoder-Decoder)、仅解码器(Decoder Only)等各种类型的模型结构都有相应的研究。模型大小与BERT 相类似的算法,通常采用预训练微调范式,针对不同下游任务进行微调。但是模型参数量在10 亿以上时,由于微调的计算量很高,这类模型的影响力在当时相较BERT 类模型有不小的差距。
能力探索、
探索不针对单一任务进行微调的情况下如何能够发挥大规模语言模型的能力,从直接利用大规模语言模型进行零样本和少样本学习的基础上,逐渐扩展到利用生成式框架针对大量任务进行有监督微调的方法,有效提升了模型的性能。
突破发展
从简单对话框进行多模态理解能力
3)大规模语言模型构建流程

预训练-->有监督微调-->奖励建模-->强化学习
四个阶段需要不同规模数据集合,不同类型的算法,产出不同类型的模型
Step1:训练数据---由于训练过程需要消耗大量的计算资源,并很容易受到超参数影响,如何能够提升分布式计算效率并使得模型训练稳定收敛是本阶段的重点研究内容
Step2:有监督微调---如何构造少量并且高质量的训练数据是本阶段有监督微调阶段的研究重点
Step3:奖励建模---如果RM 模型的目标是针对所有提示词系统所生成输出都能够高质量的进行判断,该问题所面临的难度在某种程度上与文本生成等价,因此如何限定RM 模型应用的泛化边界也是本阶段难点问题。
Step4:强化学习---由于强化学习方法稳定性不高,并且超参数众多,使得模型收敛难度大,再叠加RM 模型的准确率问题,使得在大规模语言模型如何能够有效应用强化学习非常困难。
Step5:大语言模型应用,大语言模型评估

一站式 AI 云服务平台
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)