
AI知识库之dify1.6 与 ragflow v0.19.1的联合使用,及报错mcp连接不上的问题
dify 与 ragflow 结合,知识库
引言:dify 与 ragflow
一般来说,如果需要处理特别复杂的文档和非结构化数据,RAGFlow 是优选。而对于需要多模型协作和复杂业务流程的场景,Dify 更为适合。
但这并非是个,非此即彼的问题。
如何将 Dify 作为主框架使用其 agent 和工作流组件,同时通过 API 调用 RAGFlow 的知识库组件。从而将 Dify 的用户友好界面和工作流能力与 RAGFlow 的深度文档处理能力结合起来。
注:除了 Dify+RAGFlow 的组合外,也可以结合具体业务场景选择添加更多开源框架,如 LlamaIndex、LigthtRAG 等。
A: 本文是关于Dify 使用外部知识库对接 RAGflow,那 为什么要 RAGflow 和 Dify 结合呢?
Q: 是因为 RAGflow 可以解决 Dify 在RAG 和 知识库解析和检索短板。
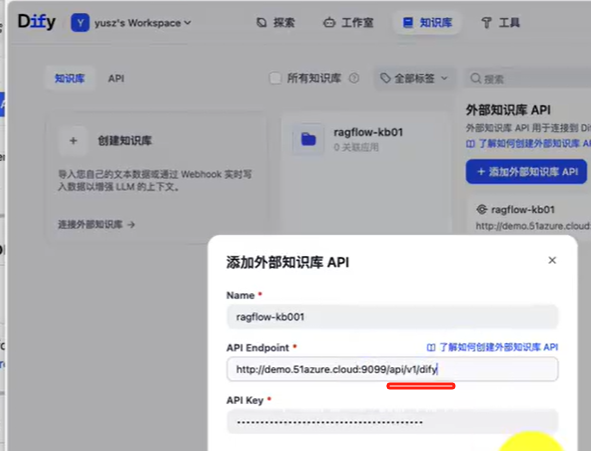
方式一:使用ragflow API 直接连接外部知识库
对接api时,必须的后缀 /v1/dify
1 Ragflow 部分
1-1. 创建 RAGflow 知识库
输入网址:http://192.168.21.24:8880 打开ragflow界面,填入注册的账号和密码登录。然后创建供Dify调用的知识库。
参考:https://blog.csdn.net/nalanxiaoxiao2011/article/details/146986967?spm=1011.2415.3001.5331
1-2. ragflow API 设置
我们接下来是需要dify调用这个ragflow ,所以我们需要设置一下ragflow api key.
1-2-1. 点击系统右上角头像,选择 API, 显示ragflow 对外提供的IP. 我的显示是 http://192.168.xx.xx:8880
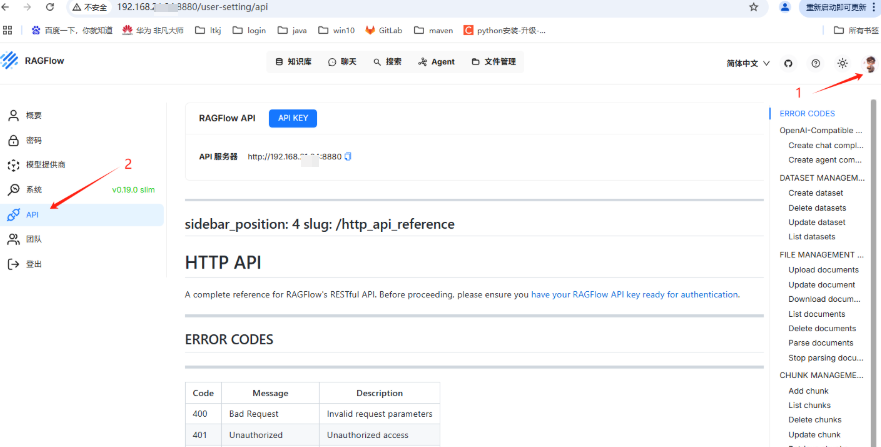
1-2-2. 点击上面key生成ragflow 对外提供的API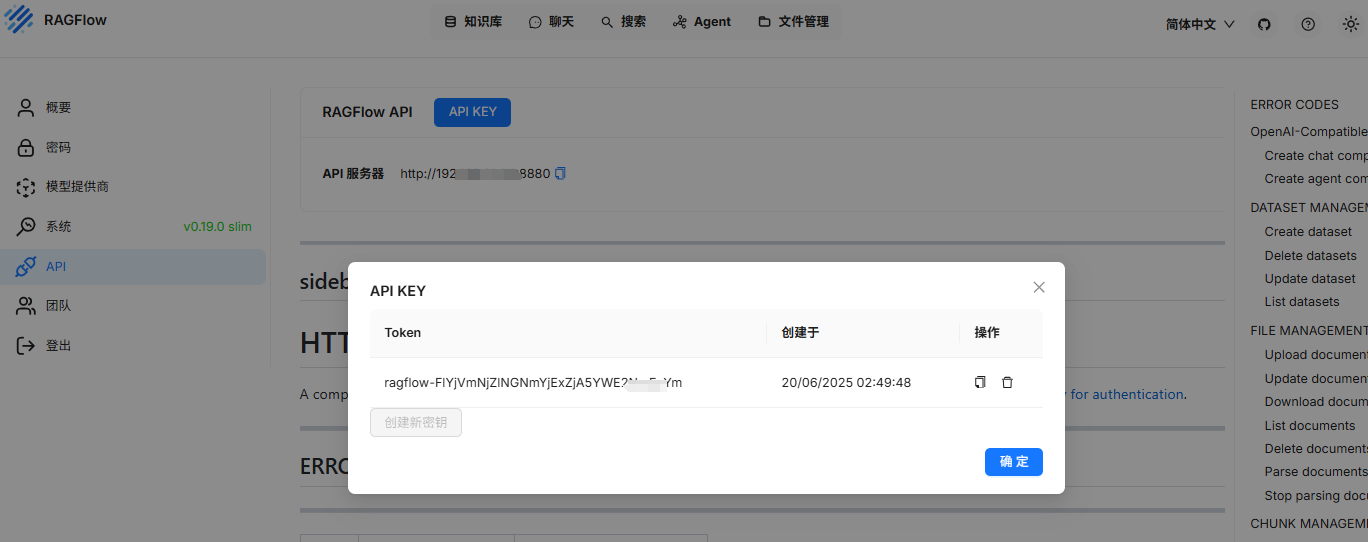
1-2-3. 下面就是ragflow 对外提供的HTTP 请求API接口文档,这里就不详细展开。
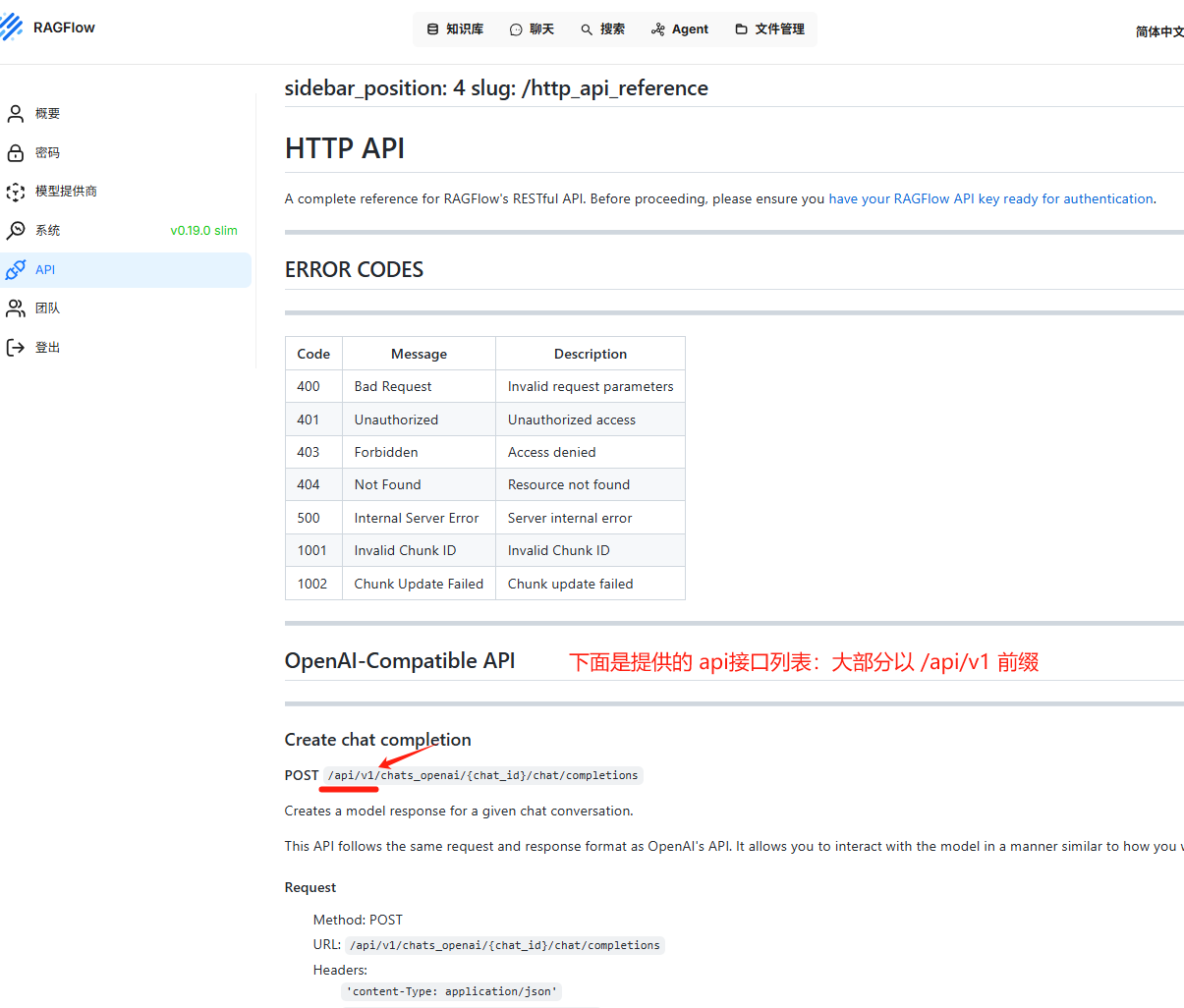
2. Dify与Ragflow联通
2-1. dify配置外部知识库
我们回到dify 工作流管理界面:http://192.168.21.24/apps,
点击上面知识库,点击链接外部知识库。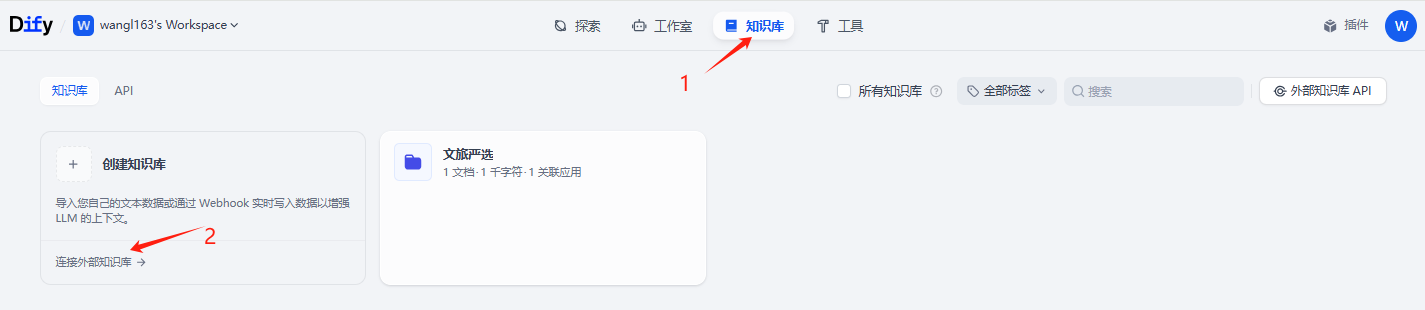
当然了,我们也可以点击右边的外部知识库API 先把外部知识库API 配置好。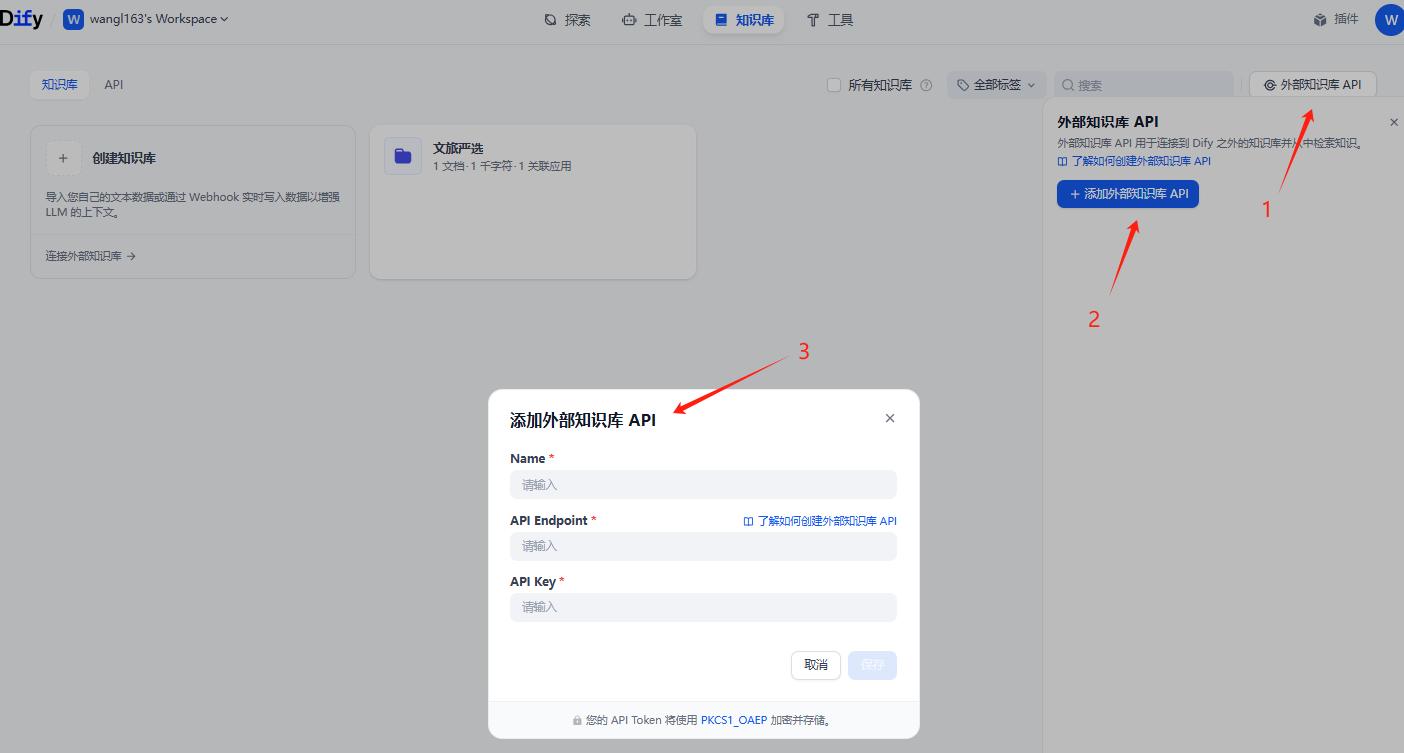
点击知识库,配置外部知识库。
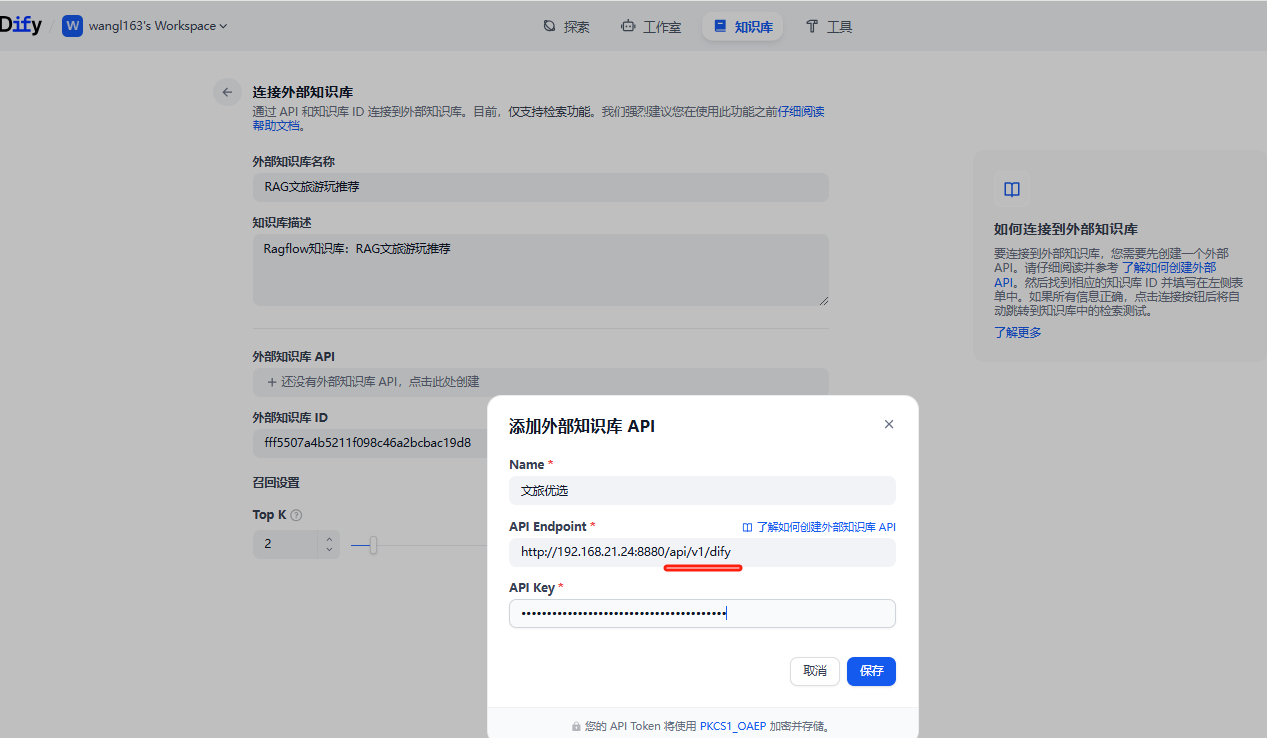
这里我需要添加3个值
-
name 这个可以随便写一个名字
-
API Endpoint 这个就是和ragflow 整合的地址
因为我们的RAGflow 对外提供的是192.168.xx.xx 我这里填写
http://192.168.XX.XX:8880/api/v1/difyURL 配置注意 在 Dify 中配置 RAGFlow 的知识库时,需要在 RAGFlow 的基础 Base url 后增加 “api/v1/dify”, 这是 Dify 特定的 API 路径,它承担版本控制、模块划分等作用。当然这也很符合 RESTful 的设计思想。 -
api key 就是上面ragflow-开头的api KEY
2-2. 管理外部知识库
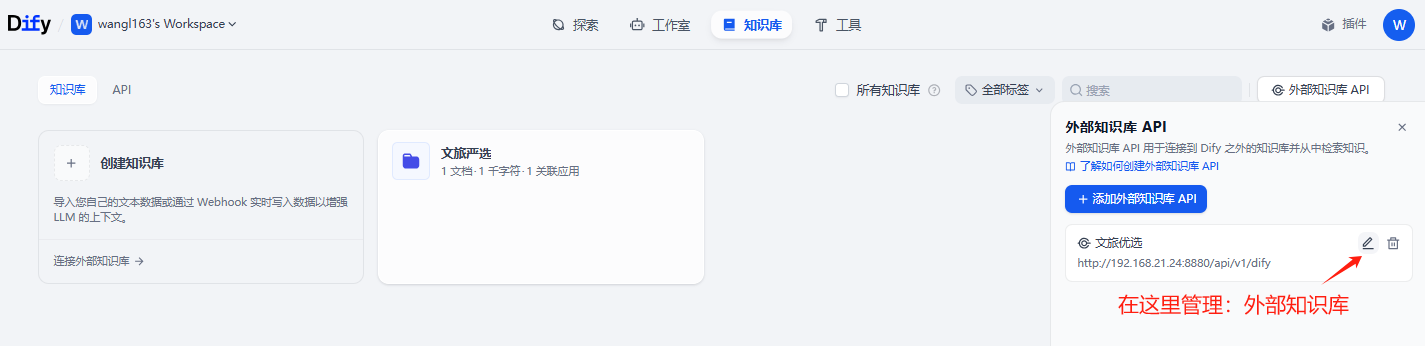
修改名称
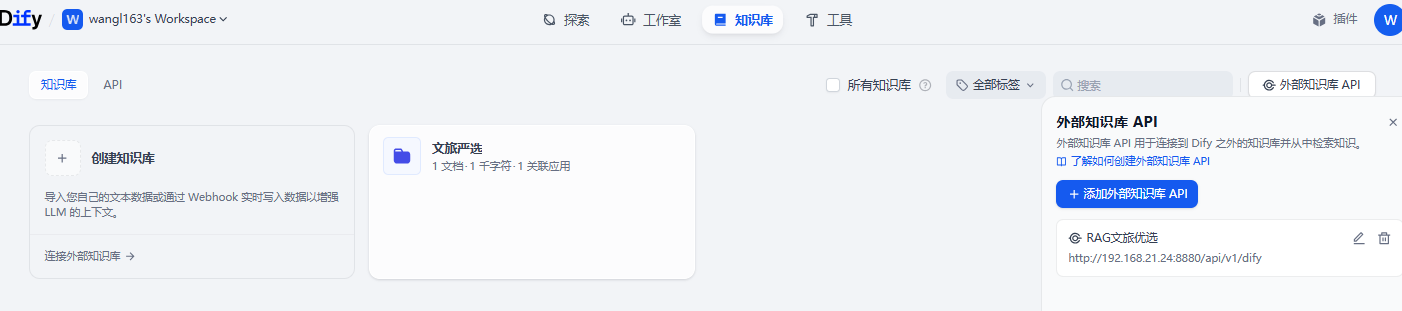
2-3. 连接外部知识库
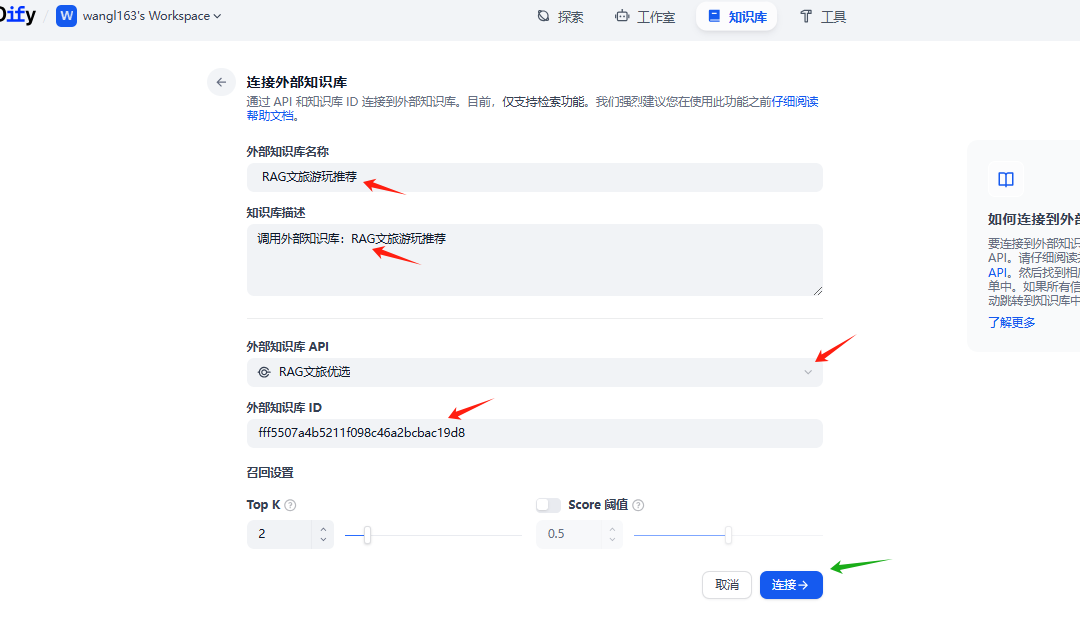
外部知识库 API 从我们刚才配置的下拉选择。
这个外部知识库 ID 如何获取呢?我们回到RAGflow 知识库画面, 地址栏也可以, 浏览器F12 查看也可以。
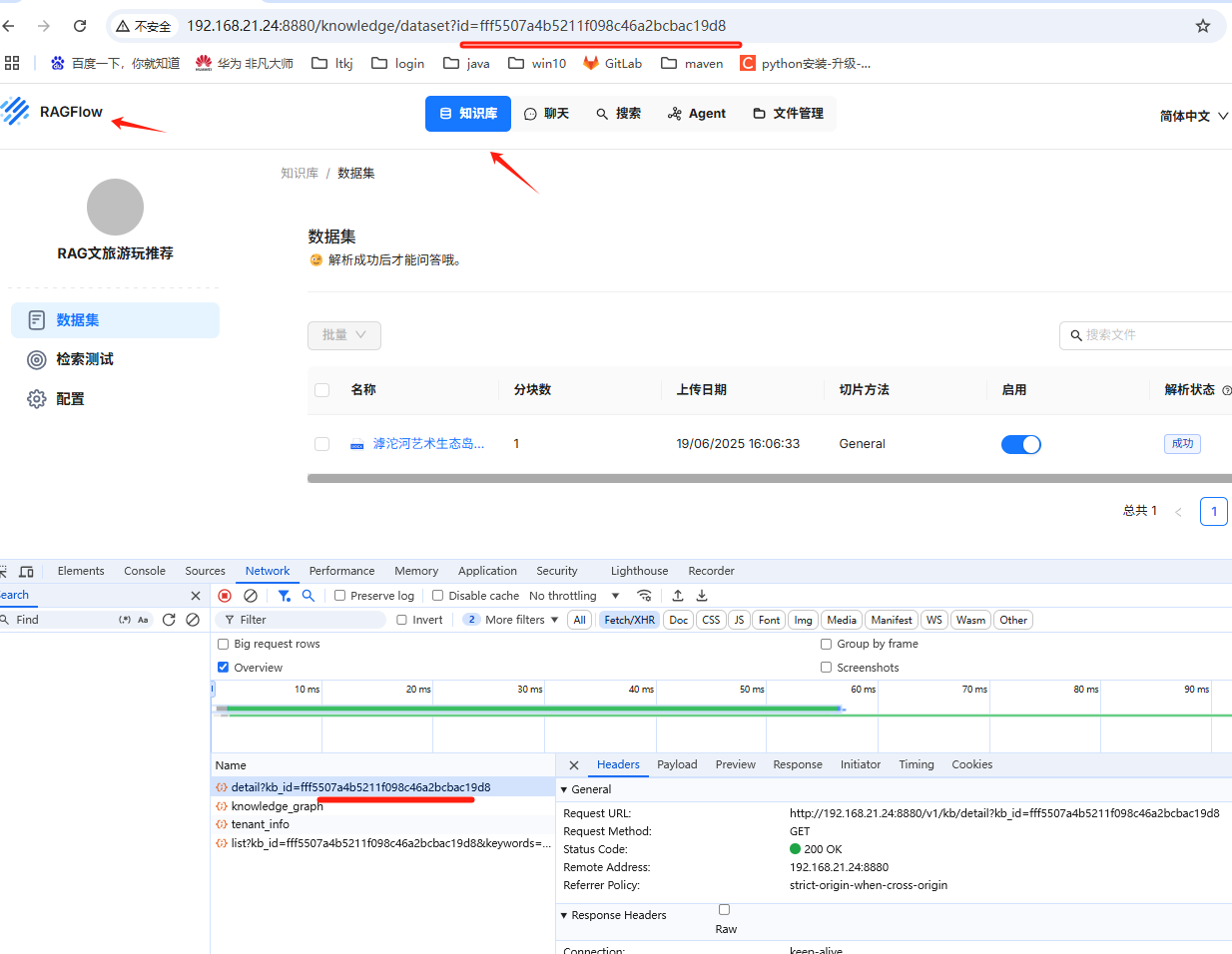
fff5507a4b5211f098c46a2bcbac19d8
然后,连接外部知识库。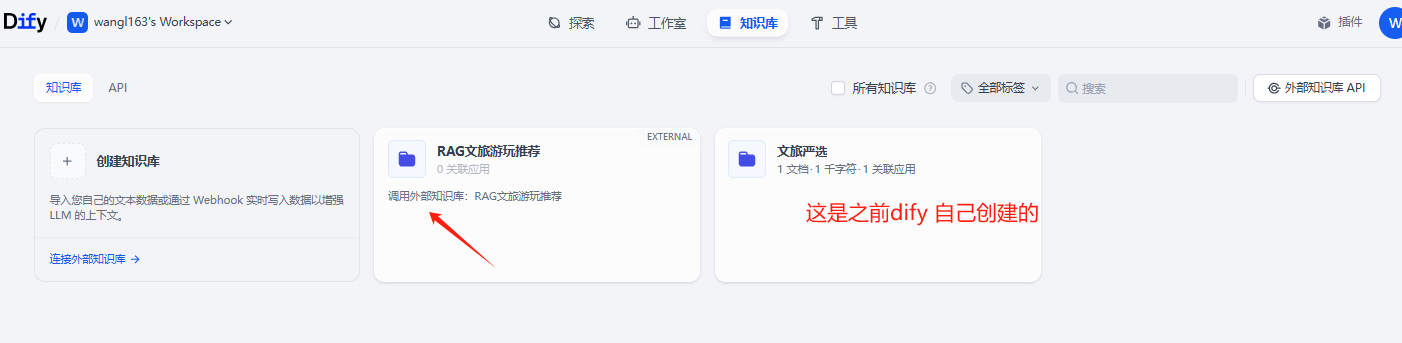
3. 进行召回测试
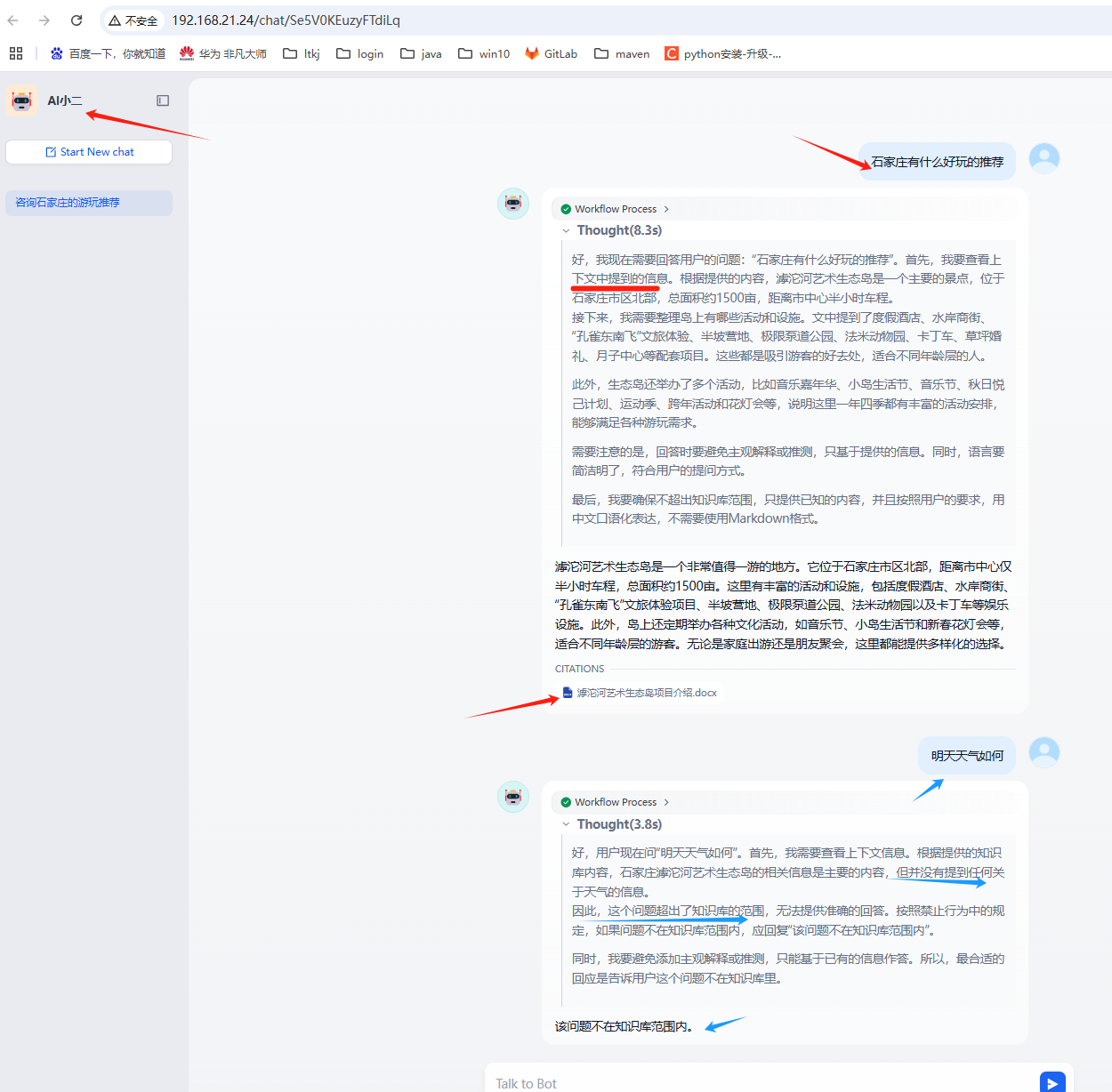
3-1. 在Dify里 创建ai agent使用外部知识库,看是否查询RAGflow知识库内容。
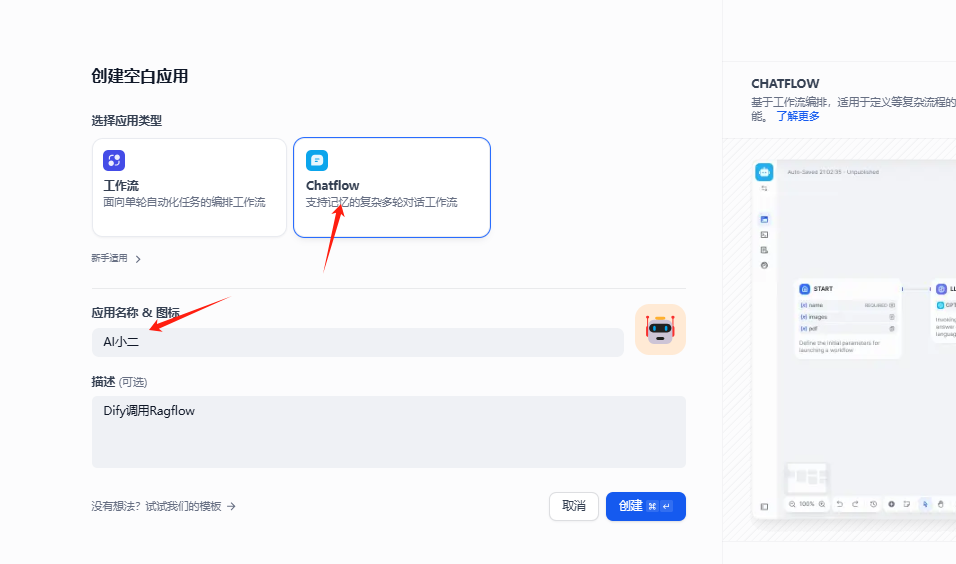
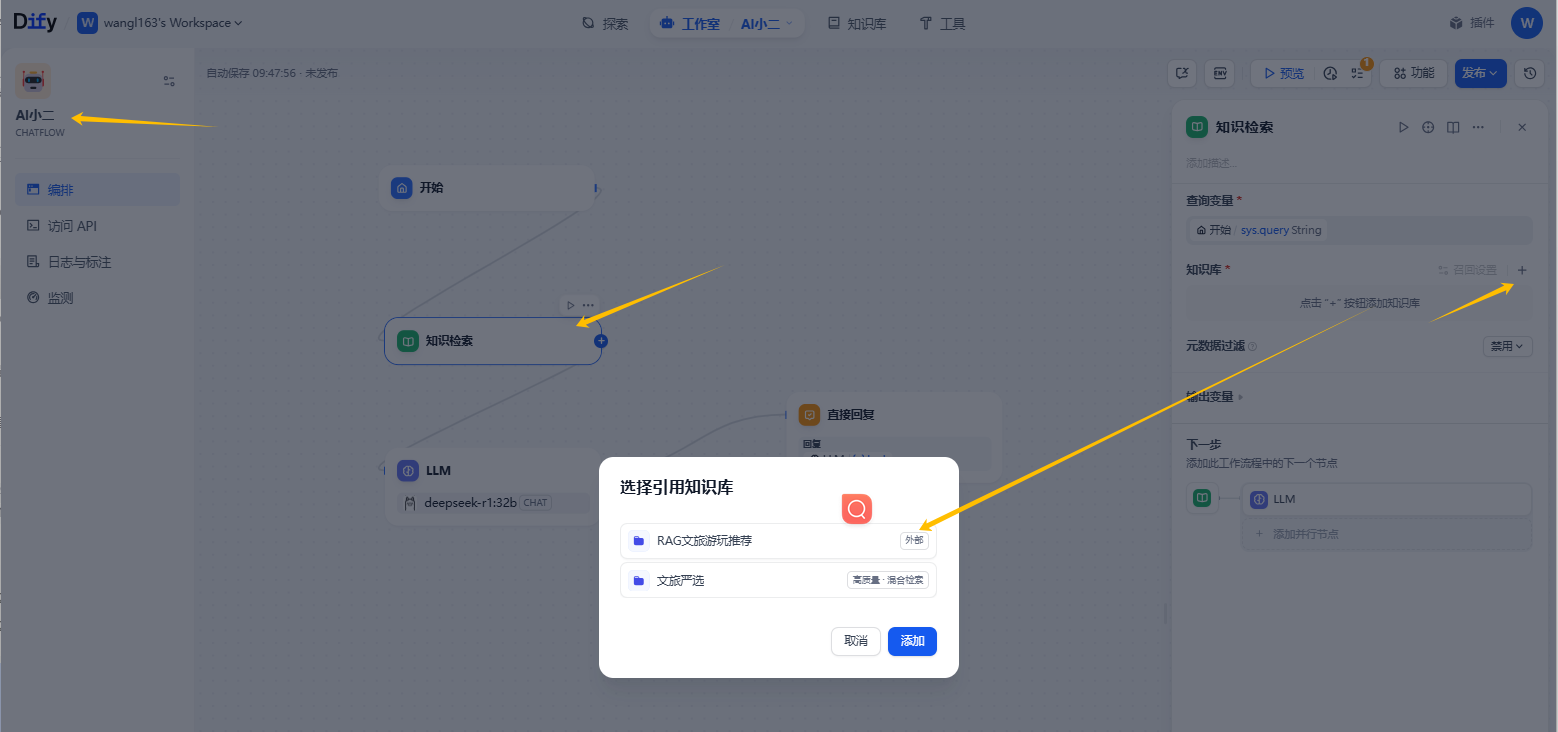
3-2. 在流程图里,添加知识检索节点,并选择知识库(外部)
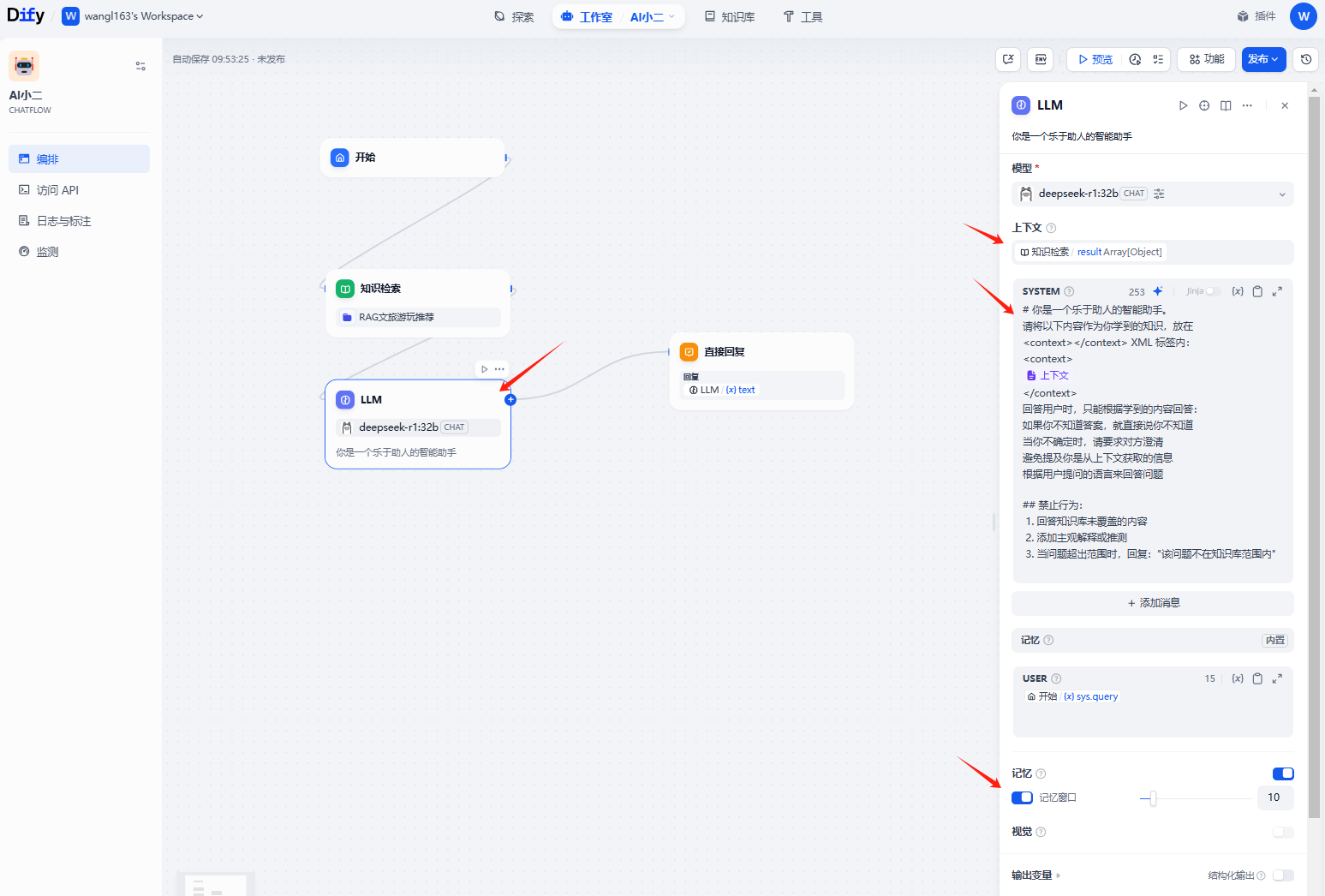
3-3. 设置LLM 节点的描述、模型、上下文、系统提示词、记忆等
# 角色
你是 [xxxx集团] 的人工智能客服专家,精通xx行业的全域知识库,也是中国文学方面的博主,顶级旅游体验官。
# 核心能力
1. 你拥有访问全部知识库的权限,也熟悉中华五千年文学史,具体全国旅游的经验。
2. 当接到用户的问题后,能以文学博主、旅游体验官的角色,充分识别用户的意图,然后触发对知识库的检索,以集团信息大管家的“智能知识库助理”身份,获取`相关上下文`。
3. 你会根据获得的`相关上下文`片段,以超级旅游体验官的身份,充分结合上下文,为游客生成最佳答案或生成最佳旅游攻略。
# 操作指令
1. **知识库上下文*:** 首先请将以下内容作为你学到的知识,放在
<context></context> XML 标签内:
<context>
{{#/上下文#}}
</context>
2. **整合与总结:** 仔细分析所有`相关上下文`片段。如果多个片段包含相关信息,**整合**这些信息,形成一个**连贯、全面、友好**的总结性答案。避免仅仅简单罗列片段内容。
3. **严格依据上下文:** 你的回答必须**严格限定**在提供的`相关上下文`信息范围内。这是你唯一可信的信息来源。
4. **处理不确定性:**
* 如果上下文信息**明确且充分**,请提供**自信、直接**的答案。
* 如果上下文信息**存在模糊、矛盾或不完整**,请:
* a) 明确指出信息的不确定性(例如,“根据现有资料,关于[具体点]的信息可能存在不同说法/不够明确”)。
* b) 尽可能提供已知的、可靠的信息部分。
* c) **绝对避免**为了给出完整答案而进行猜测或填补空白。可以说“关于[具体不确定点],知识库目前没有提供足够明确的依据”。
* 如果上下文**完全不包含**回答所需信息,请友好的告知:“抱歉,无法匹配知识库内容,您可描述更详细信息或联系人工客服(电话:1861111xxxx)”
5. **清晰标注来源:** 在回答的开头或结尾,用自然语言说明你的信息来源于内部知识库(例如,“根据我们知识库中的信息…”,“检索到的资料表明…”)。
6. **风格要求:** 回答应专业、清晰、易于理解。对用户保持礼貌,避免使用过于技术化的术语,除非用户问题本身是技术性的。
7. 对用户保持礼貌,使用“您”称呼,避免专业术语,复杂问题分点说明;
8. 遇到无关问题(如广告、骚扰)时回复:“此问题不在服务范围内,请提问业务相关问题?”;
9. ** 记录对话历史:** 若用户追问前文概念,需结合对话历史(<context></context>标签)确保逻辑连贯。
## 记录对话历史(最近5轮),放入<context></context> XML 标签内:
<history>
{conversation_history}
</history>
结果:
===================================== 华丽的分隔线 =====================================
方式二:通过 MCP 联通dify和ragflow :
MCP调用与在dify中直接链接外置知识库的api在检索的主要区别在于:
api只能读取分块内容,缺少召回的步骤,mcp相当于直接内嵌了ragflow的召回功能
--------------------------以下是本文的内容概述-----------------------------
##Dify 与 Ragflow 的github链接(自行删掉文字):
Dify:https冒号//github.com/langgenius/dify点git
Ragflow:https冒号//github.com/infiniflow/ragflow点git
#如果打不开,可以到PanSir的飞书文档中下载离线包##
##Ragflow 指定容器启动与关闭命令
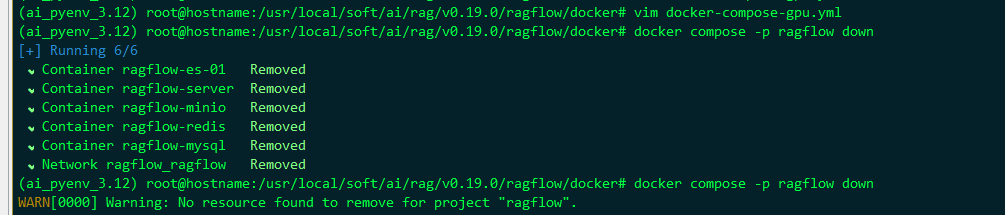
启动: docker compose -r rag_flow up -d
关闭: docker compose -r rag_flow down
##Dify 默认容器启动与关闭命令
启动:docker compose up -d
关闭: docker compose down
##Dify插件 MCP SSE 授权命令, 需要修改为自己的
{ "server_name": { "url": "http://host.docker.internal:19999/sse", "headers": {"api_key":"改成自己的apikey"}, "timeout": 60, "sse_read_timeout": 300 }}
##Dify演示工作流中参数格式转换python代码
def main(arg1: str, arg2: str, arg3:str) -> dict:
import json
inner_dict = {
"question": arg1,
# 使用列表而不是集合来存储
"dataset_ids": [arg2],
"documents_ids": [arg3]
}
json_string_output = json.dumps(inner_dict, ensure_ascii=False)
return {
"result": json_string_output
}
1. RAGFlow获取api_key和知识库id部分
同方式一的 “1 Ragflow 部分” ,没必要再重复。
2. 修改配置
参考 官方文档: https://ragflow.io/docs/v0.19.1/launch_mcp_server ->
Launch from Docker 部分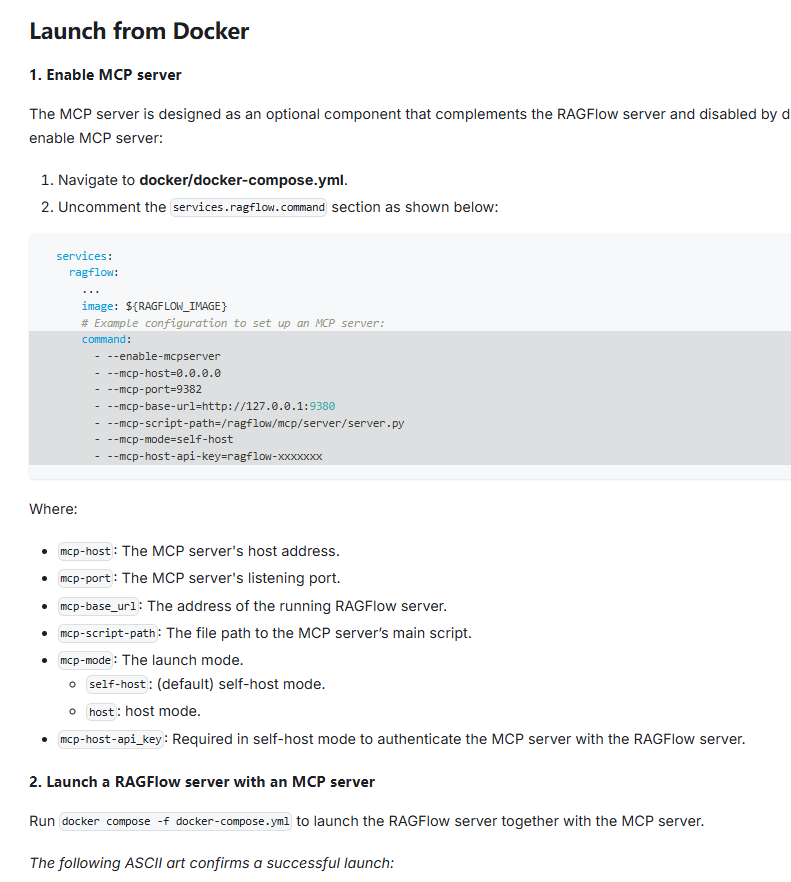
2.1 CPU方式启动
CPU 对应docker-compose.yml文件,修改如下:
vim docker-compose.yml
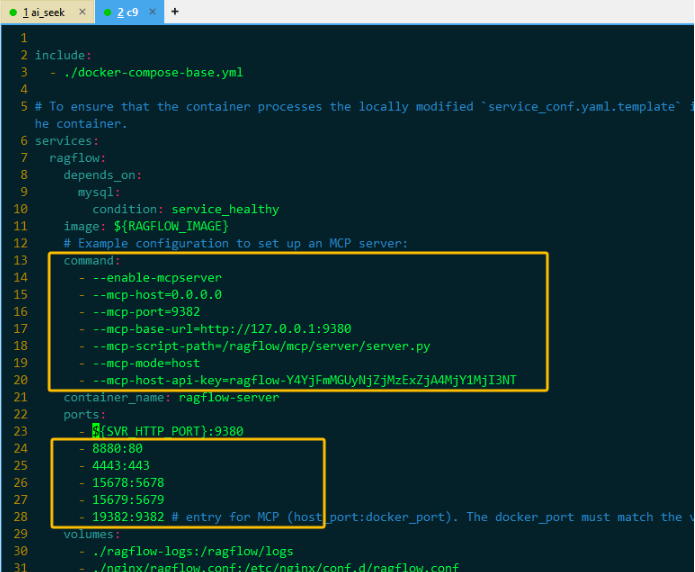
修改docker-compose的目的:
- 开启MCP的相关功能 ,修改MCP的运行模式并配置api_key。
- 解决端口冲突,默认情况下RAGFlow和Dify使用的端口有冲突。
验证方式:
docker logs ragflow-server | grep -i mcp
# 应该看到类似
# Starting MCP server on 0.0.0.0:9382...
# MCP server initialized with API key: ragflow-Y4YjF...
或 curl 验证
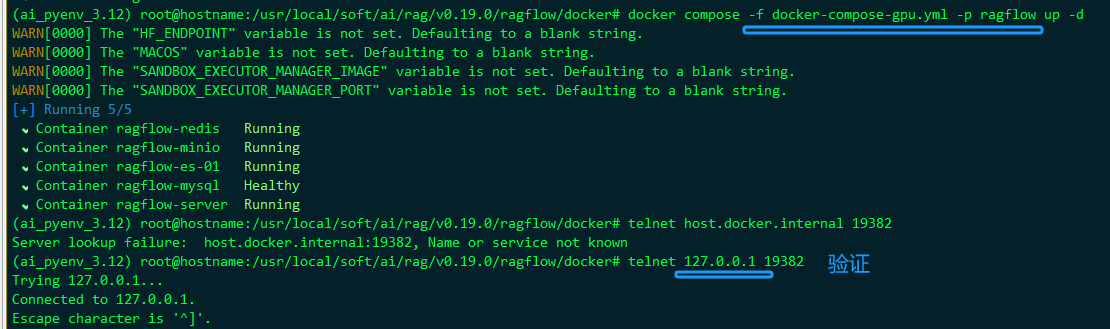
curl -v http://192.168.21.22:19382/health
或
curl -N -H "api_key: ragflow-Y4YjFmMGUyNjZjMzExZjA4MjY1MjI3NT" http://127.0.0.1:19382/sse
2.2 GPU方式启动 (我最开始就是这种方式启动的,所以没有遇到上面的问题)
如果是gpu启动的 ragflow , 按上面教程来,可能会报错:
PluginInvokeError: {"args":{},"error_type":"ConnectionError","message":"server_name - MCP Server connection failed: [Errno 111] Connection refused"}
因为只改了 docker-compose.yml ,但是它和 docker-compose-gpu.yml 是平级的。 虽然它们俩都 依赖docker-compose-base.yml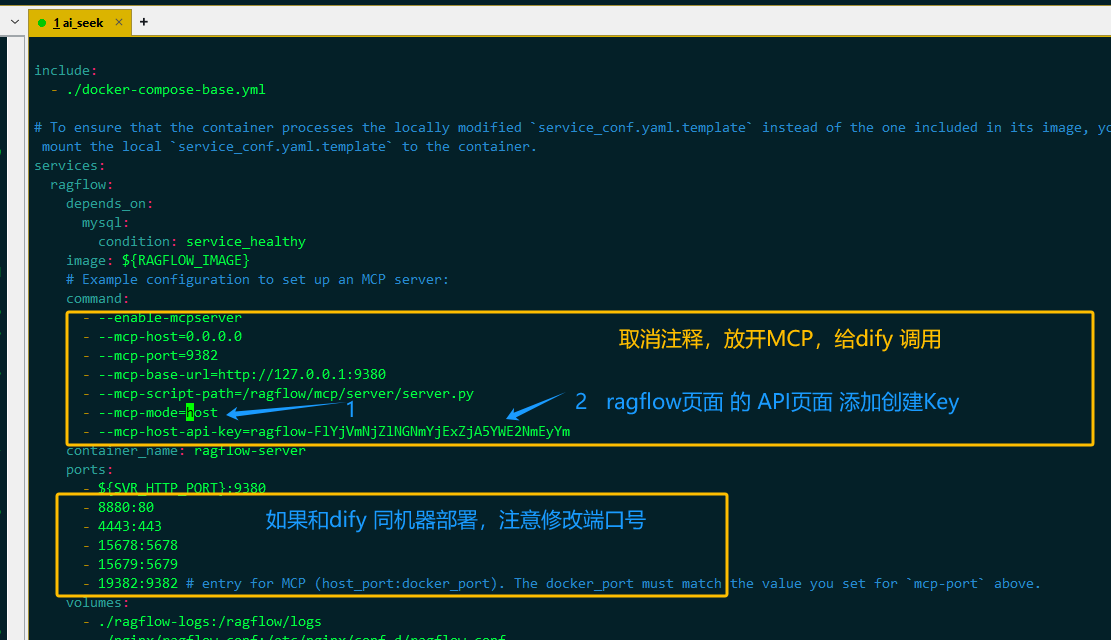
修正:
修改 docker-compose-gpu.yml, 复制 docker-compose.yml 中,框中的两段配置,到 docker-compose-gpu.yml 对应位置中
-
修改前先备份

-
修改、复制
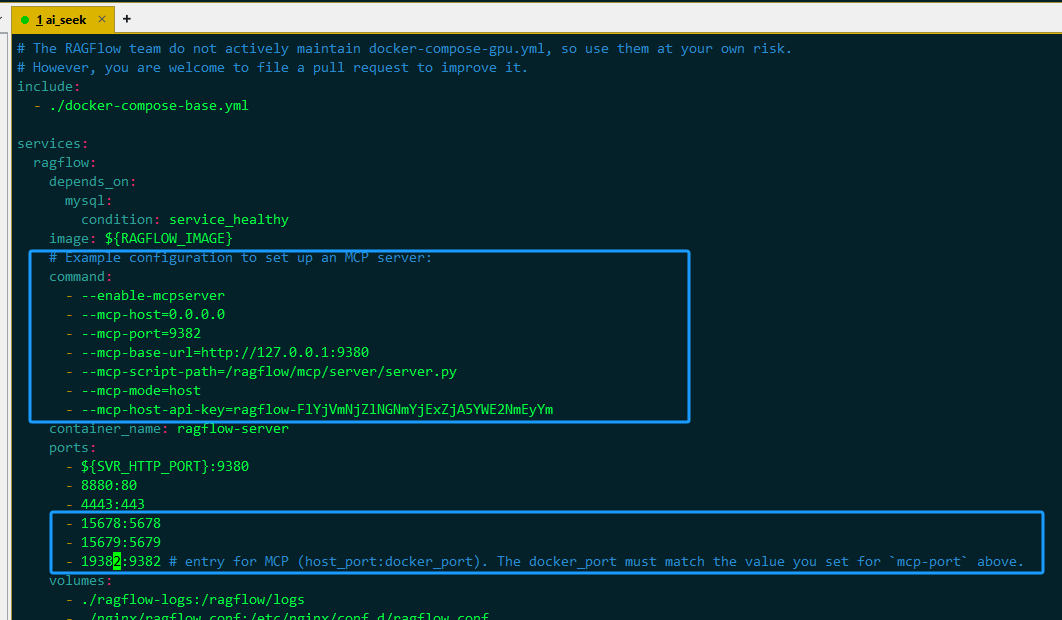
-
停止服务、重启
-
查看日志
# 1. docker logs ragflow-server # 2. tail -f ragflow/docker/ragflow-logs/*.log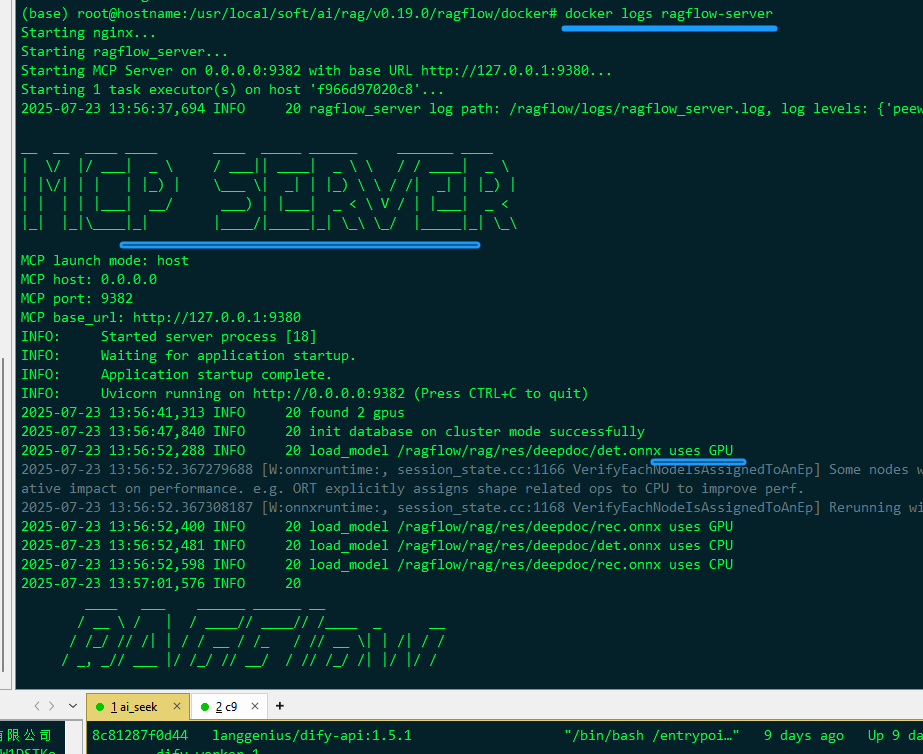
-
验证
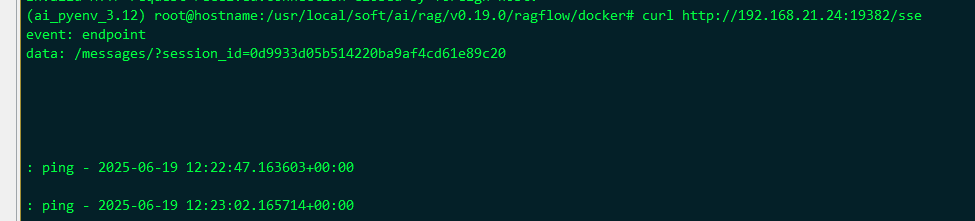
-
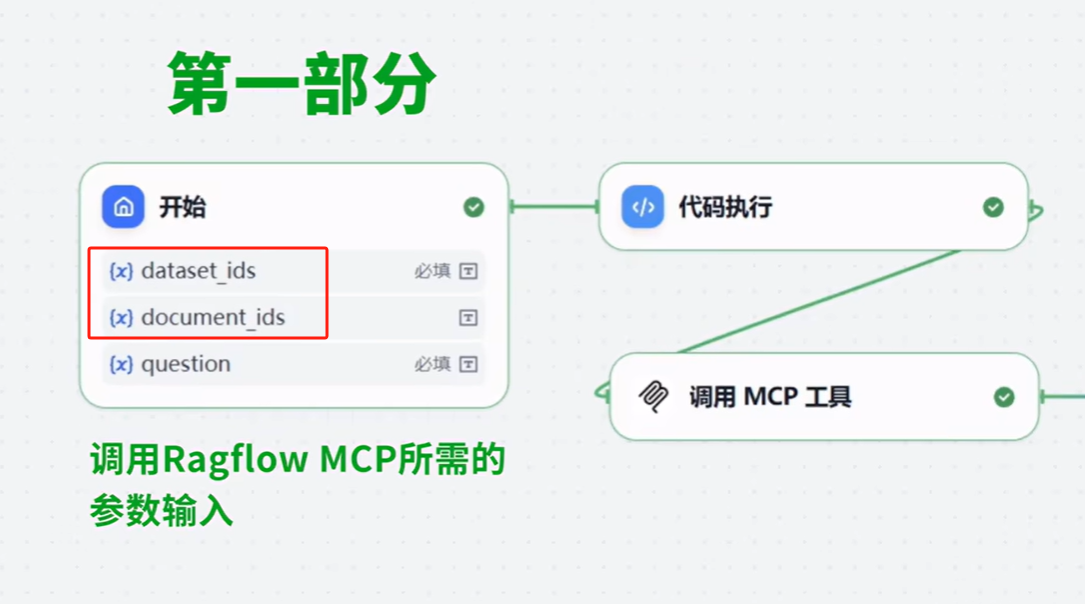
回到Dify 中,引用Ragflow的 MCP

-
在dify中,通过MCP 配置ragflow 成功,之后 就可以调用 ragflow 的知识库了

-
dify的工作流中使用
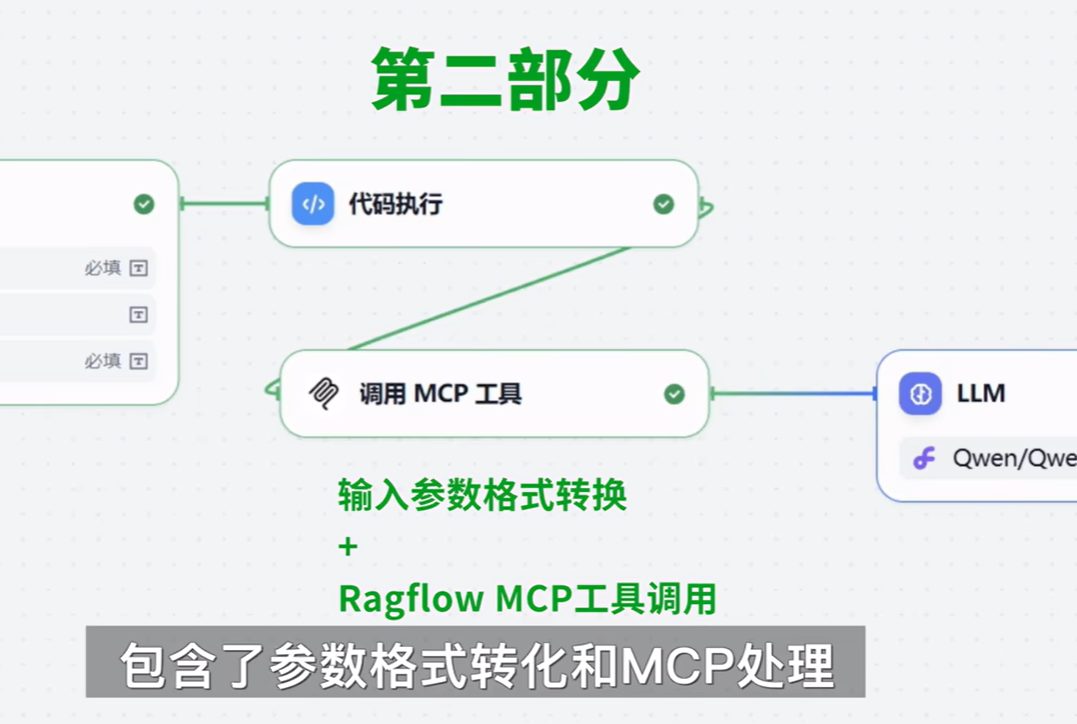

-
在Ragflow 中获取dateset_ids 和documents_ids
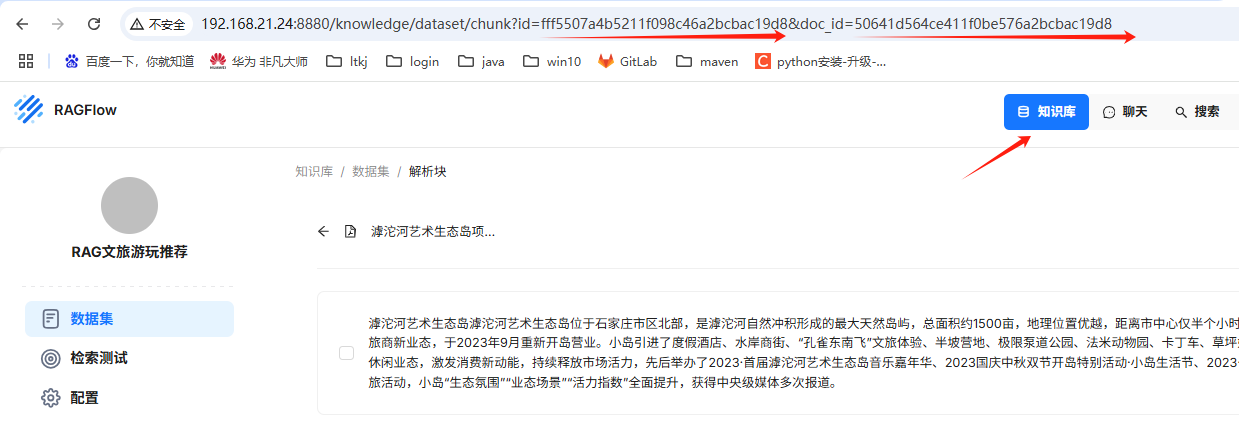
-
加入代码节点,转换输入参数为 ragflow 需要的形式
url和api_key的Json串也可以填在此处:MCP服务配置。此处的优先级更高,工具名称就填:ragflow_retrieval
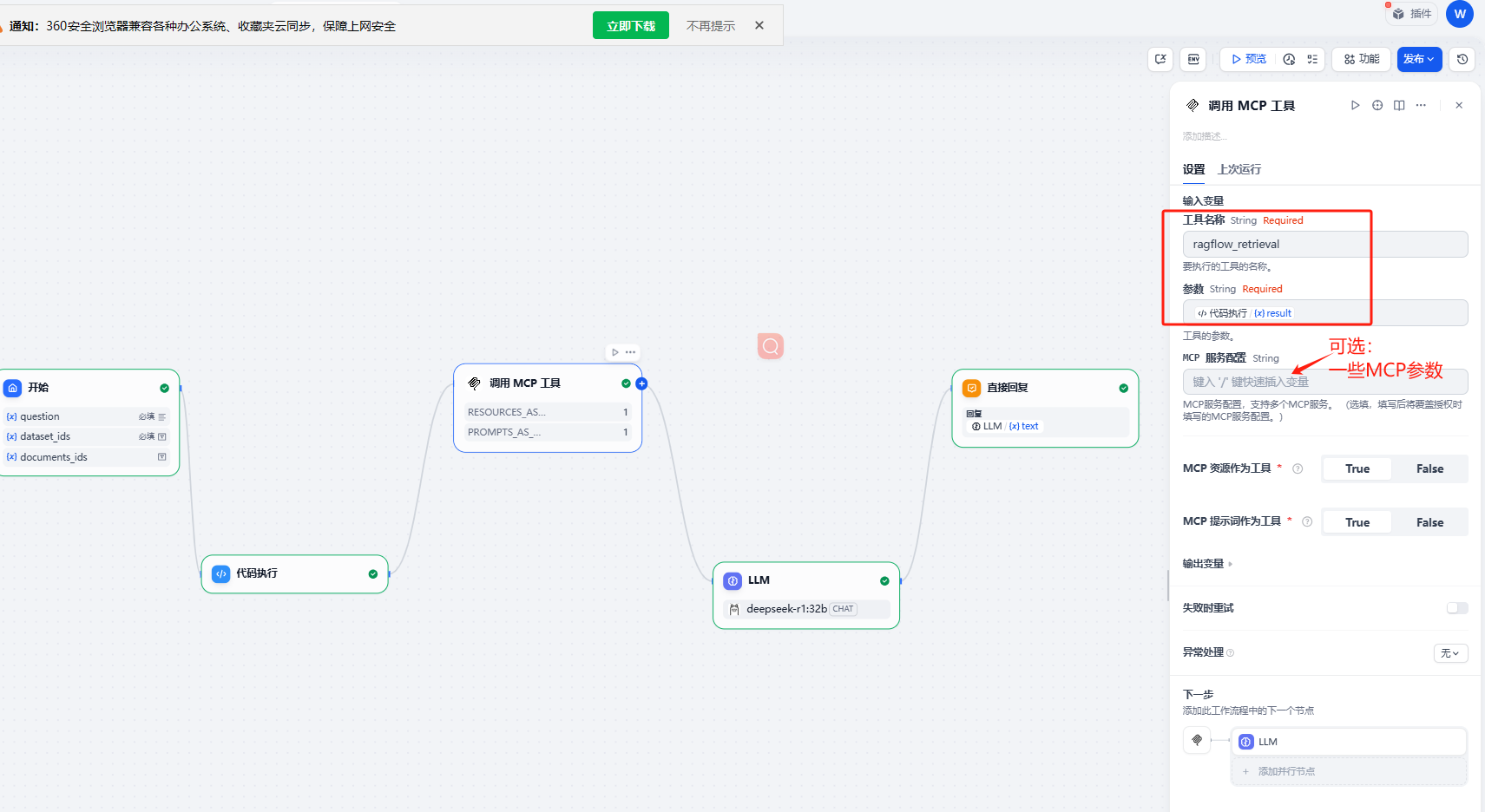
相关代码:
## 1. Dify插件 MCP SSE 授权命令
{ "server_name": { "url": "http://host.docker.internal:19999/sse", "headers": {"api_key":"改成自己的apikey"}, "timeout": 60, "sse_read_timeout": 300 }}
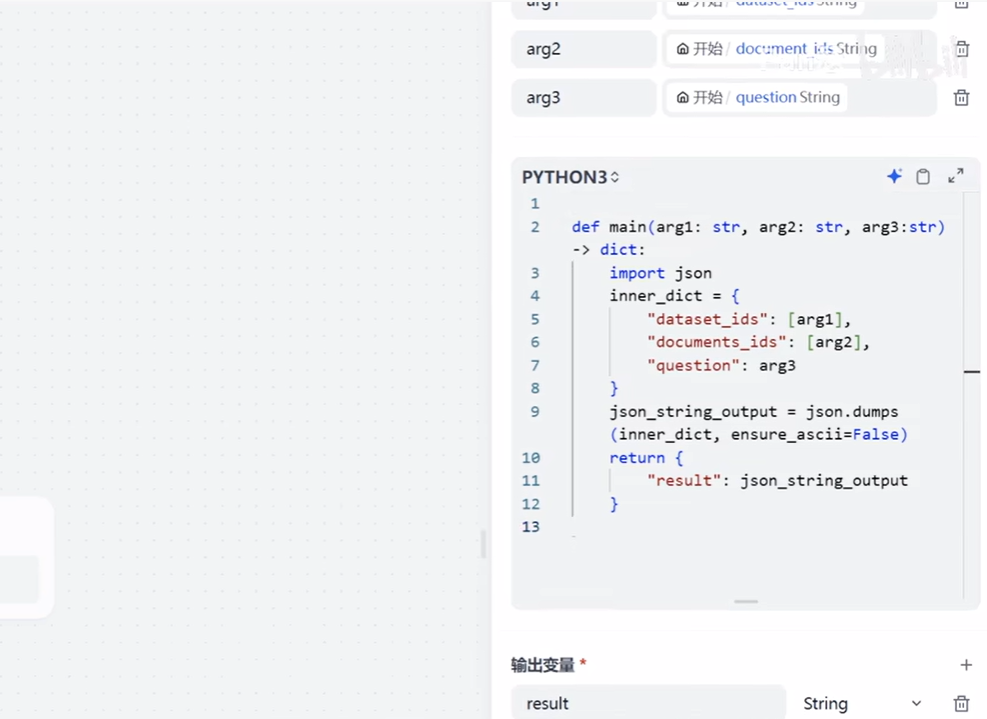
## 2. Dify演示工作流中参数格式转换python代码
def main(arg1: str, arg2: str, arg3:str) -> dict:
import json
inner_dict = {
"question": arg1,
# 使用列表而不是集合来存储
"dataset_ids": [arg2],
"documents_ids": [arg3]
}
json_string_output = json.dumps(inner_dict, ensure_ascii=False)
return {
"result": json_string_output
}
- 从MCP 插件召回数据,作为第三部分的输入 ,提供给大语言模型LLM 。
- LLM 根据这部分知识数据,及用户第一部分输入的问题,进行分析、总结,最终输出答案 。
拓展:
Q: 第2种方法 MCP 与在dify中直接链接外置知识库的api在检索的性能上有哪些区别?
A: api和mcp的区别
- api和mcp的区别在于,api只能读取分块内容,缺少召回的步骤,mcp相当于直接内嵌了ragflow的召回功能
Q: 一个知识库里有多个文档,用工作流怎么调用?
A: 大概有两种方案:
- ragflow mcp的参数,documents可以是空值,空值代表在当前数据集内遍历所有文档进行召回。
- 利用dify的迭代或循环节点,提前准备好文档数组,在循环中进行即可。
Q: 如果召回的数据长度太长 llm可能会炸 up主有没有什么好办法
A: 分拆处理
- 对召回数据进行拆分,第一段处理完,把处理结果和第二段一起再交给llm出来,如此迭代到全部处理完成
Q: MCP插件授权的步骤:
PluginInvokeError: {"args":{},"error_type":"ConnectionError","message":"server_name - MCP Server connection failed: Server disconnected without sending a response."}PluginInvokeError: {"args":{},"error_type":"ConnectionError","message":"server_name - MCP Server connection failed: Server disconnected without sending a response."}
访问时看rag没有反应,但是用浏览器访问:http://192.168.21.24:19382/sse 日志报错:INFO: 172.22.0.1:36222 - “GET / HTTP/1.1” 404 Not Found
A: 按照下面方法进行排查
- 在dockef的ragflow容器里查看运行状况是否正常。
- 运行docker logs ragflow-server 查看mcp服务器是否正常运行,正常运行会有一堆文字组成的图案。
- 检查端口19382 是否被占用。
总结:
到此为止,第2种方法的基于MCP调用的,一个简单的Dify 加Ragflow MCP调用的工作流,就全部完成了。
又一种方式,实现了利用Ragflow 精准切分,在Dify中调用Ragflow知识库,两者完美协作,相辅相成的想法。
虽然Ragflow MCP只有一个工具可以使用,官方的文档也不是那么的详细,但一切好在都在起步,只要开始了,未来一定会更好。

一站式 AI 云服务平台
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)