
使用GPT-Sovits模型训练ai声音 小白向教程
gpt-sovits是一个相对而言体量较小,具备完整的图形化ui,学习门槛极低的模型,只需要约5分钟的声音原始数据,就可以获得效果不错的训练结果,训练过程很快,等待时间少,不容易出错。
引言
随着ai对我们生活的影响越来越深,使用ai来便利我们的生活也变得越来越常见。其中,ai声音作为应用技术比较成熟,使用门槛比较低的技术,值得大家花一点时间学习使用。
q:我学会这个能干什么?
a:可以自定声音模型,接入unity游戏中和chat实现对话等,也可以在做视频等时提供方便的免费配音,也可以自娱自乐搞二次元老婆。
模型介绍
gpt-sovits是一个相对而言体量较小,具备完整的图形化ui,学习门槛极低的模型,只需要约5分钟的声音原始数据,就可以获得效果不错的训练结果,训练过程很快,等待时间少,不容易出错。
模型下载:
由于模型需要和自己的显卡型号匹配,且版本众多,因此本教程不提供模型的下载,可以去百度贴吧或bilibili等寻找合适的模型。
使用UVR5进行降噪处理
下载原始素材
在训练之前,我们需要先准备好一定的原始素材,常见的声音格式都可以。这里我以明日方舟wiki上下载的声音集作为展示。把下载好的声音放在新建文件夹里,这个文件夹就是我们训练每一个步骤的结果集,因此每一个步骤都需要设置一个文件夹来区分。
原始素材需要单独放一个文件夹:
这样就算下载好了。
使用uvr5模型进行背景音乐分离、去混响处理
打开gpt-sovits模型的文件夹,找到go-webui.bat这个文件,打开。唤出终端后会稍微卡一段时间,然后ui界面就会出现在你的浏览器里。
一旦打开web界面,就绝对不能关闭终端,接下来的整个流程都需要保证你的终端是挂在后台的!
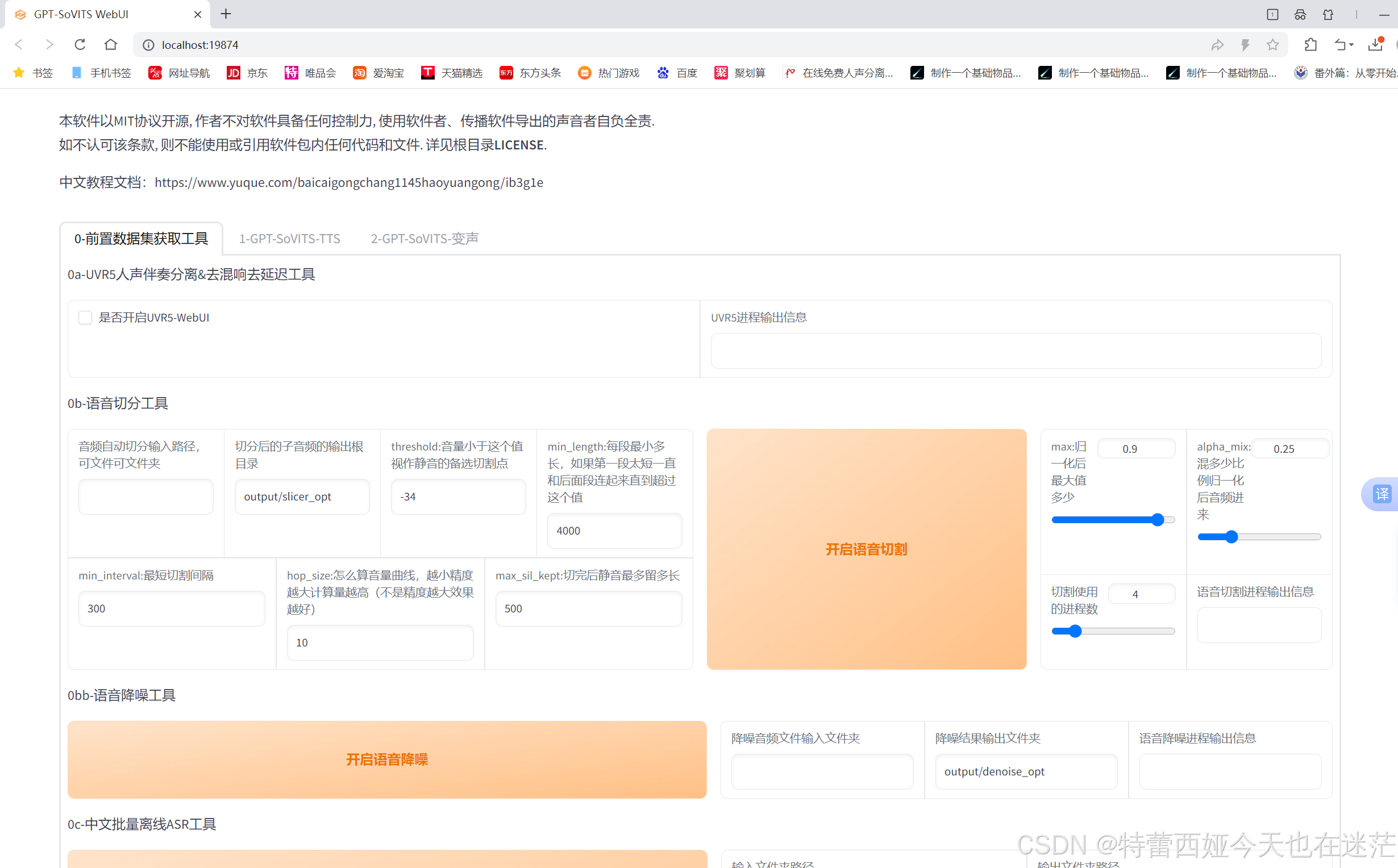
我们的前置工作还没有做完。虽然我在wiki下载的声音很纯净,但如果你用的是录音机或是其他方式,例如从动漫中截取的带有音乐的人声等,就需要利用uvr5模型来做处理。此外,也需要对素材进行切分。
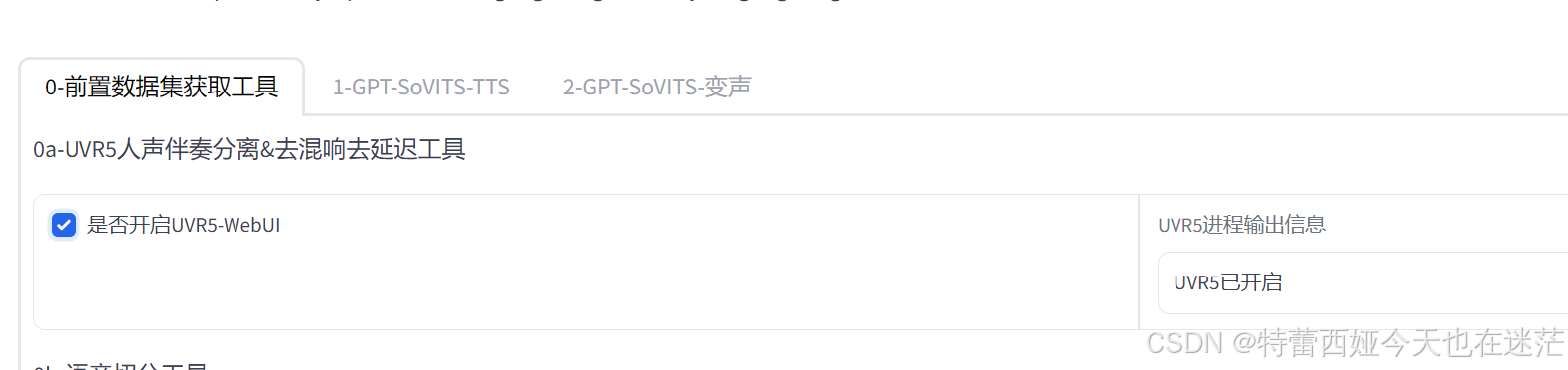
点击开启uvr5-webui,稍微等一段时间后,就会出现一个新的界面:
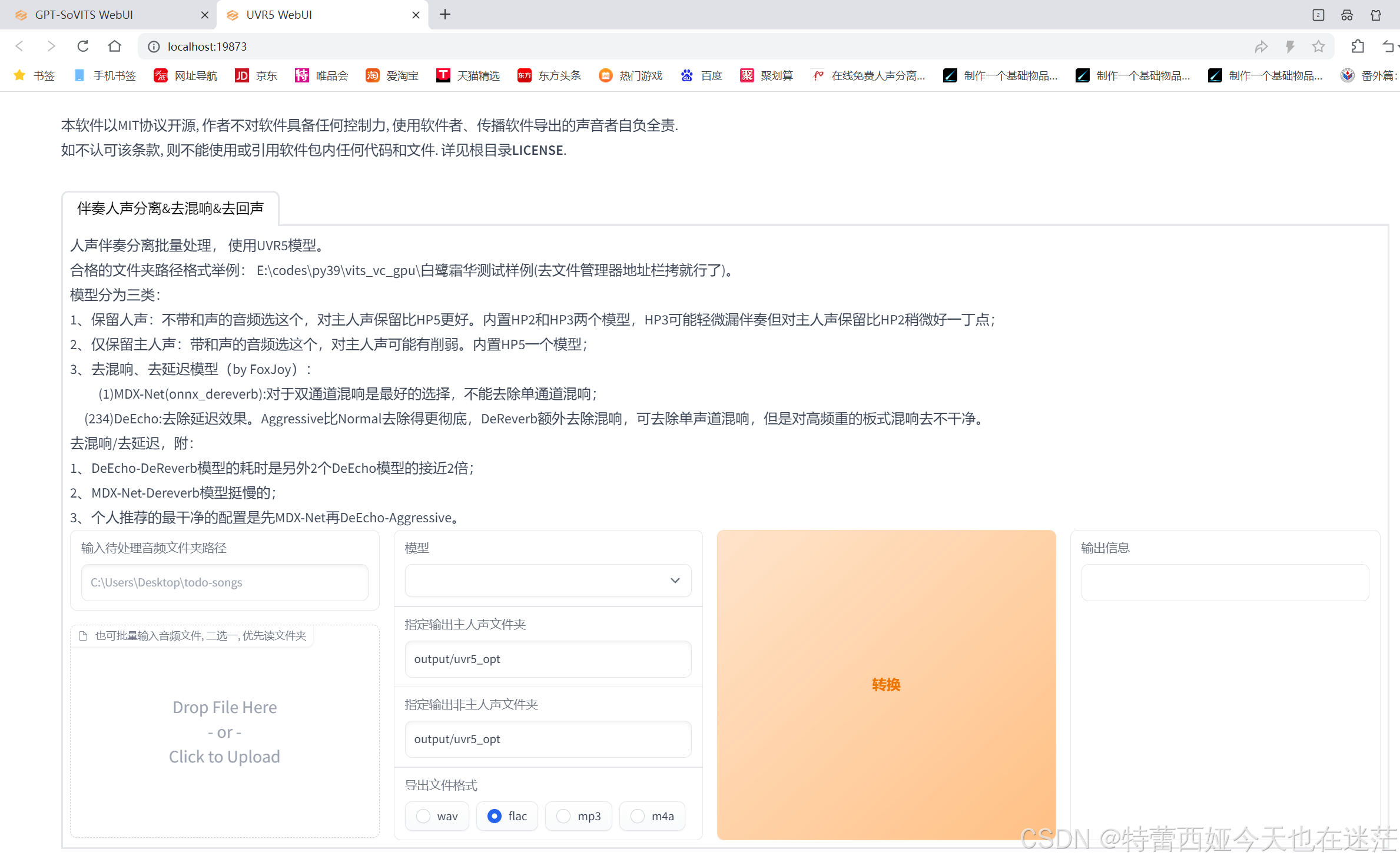
如果你的原始素材只有几个,可以直接拖拽进去。否则的话还是需要输入文件夹的路径。
q:我不会输入文件夹路径怎么半
a:以上述的路径为例,打开chengshan文件夹,然后对wav文件夹右键,选择复制文件路径,然后粘贴上去,然后删除引号即可。
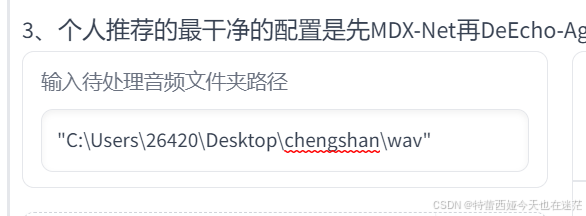
↑引号需要去掉。
模型选择和保存地址
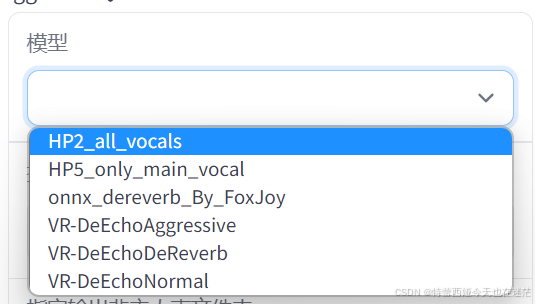
默认提供了这些模型,具体模型的优劣区别已经在网页上描述的很清楚了,这里不作赘述。
去混响处理结果需要单独新建一个文件夹储存,这里我们在chengshan文件夹里新建uvr5-1文件夹来储存去混响结果(如果需要多次分离,可以按步骤设置成-2,-3,方便回溯追踪和区分)
保存格式选择flac就行。
接着点击转化,等待右侧输出信息显示完毕后,去混响处理就结束了。
语音切分
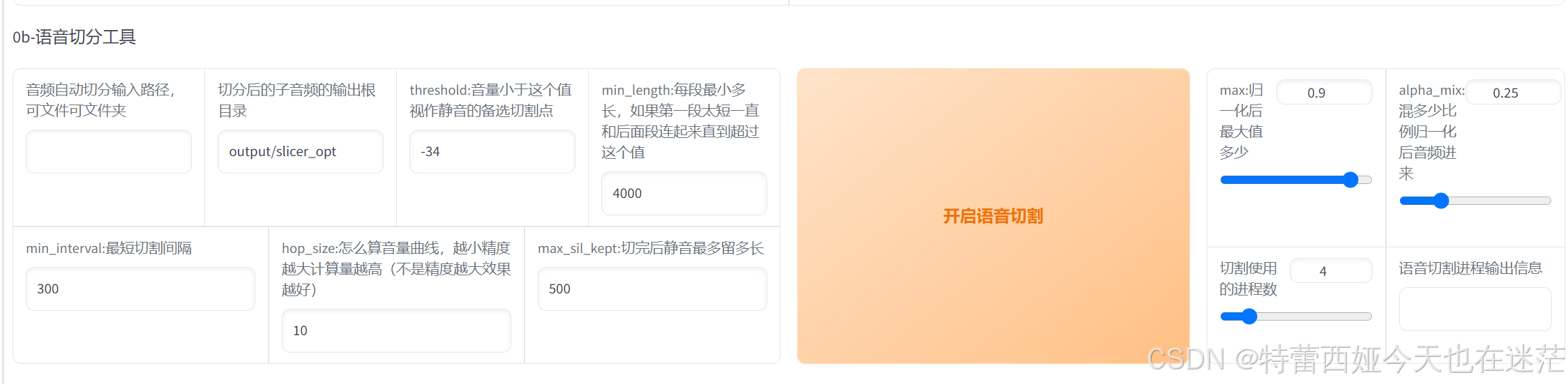
回到刚才打开的页面,右侧的默认参数不用改动,输入文件夹路径和urv5的处理一样,需要去掉复制的引号。
文件夹路径:不要选择wav!选择你在uvr5里处理最后结果的文件夹,例如我这里填的是uvr5-1。导出文件夹路径可以新建一个0bout,其余信息不需要改动,点击语音切割后等待右侧输出信息显示完成后就可以进行下一步。
这个过程很快,大概几秒,如果卡住了可以试试重启。
语音降噪
在上一步,我们已经获得了完整的切分结果,0bout文件夹如下:
当然,如果你的原始材料和我一样是来自wiki的纯净配音,那么这一步也不需要处理。
反之,则把0bout文件夹填进去,然后新建0bbout文件夹来获得处理结果。
这一步也很简单,只需要点一下就可以了。
批量ASR工具
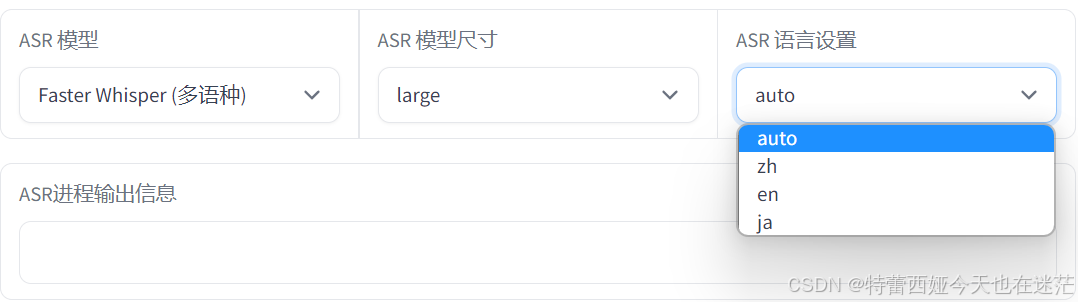
这一步会麻烦一些,输入材料文件夹和输出文件夹后,需要选择你的模型语言:
q:我能让日漫角色的日配训练出来说中文吗?
a:可以,但效果并不好,而且不同语言发声方式有区别,就算音色接近,实际感觉也会差很多,因此这里只推荐原始素材和最终输出声音一样的语言。
如果你想训练中文模型,在asr中选择达摩asr(中文)即可,英语或日语可以选择多语种,语言设置中需要选择对应的语言(也可以auto自动识别)
这一步也很快,大约一分钟就好了,0cout的结果是一个list文件
文本校对
list文件是一种文本文件,储存了asr的识别结果。但如果追求更好的精度,就需要检查list有没有错误的文本,或是试听一下有没有明显尖锐的声音(这种不适合作为训练参考),需要修改或删除这些东西。

我们填写list文件所在的路径,点击开启校对,等一段时间后,浏览器会弹出新的打标界面:

例如这里的text4,wiki提供的文本是“最后都只会以指向我收尾”,我们需要填写正确的文本。

还有例如这里的text15,是战斗时的战吼(咿呀...这也算战吼吗...),明显尖锐,也不能用现有的词汇套进去,因此需要在右侧选择yes忽略掉这个音频。
每一页更改后,都需要点击上面的submit text,直接切换页面会被刷掉哦。
等每一页都处理好后,就可以关闭这个页面,进行下一步操作了。
GPT-Sovits模型训练
完成之后,我们就点击进入gpt-sovits-tts的页面:
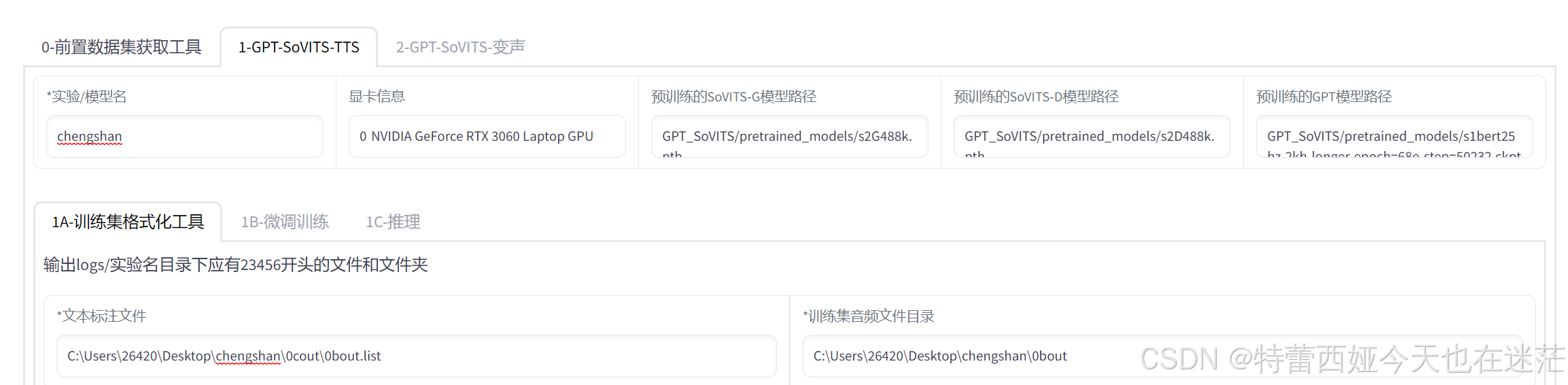
随便填写一个模型名,下面的文本标注文件就是我们处理过的list文件的路径,右侧则是降噪处理过的文件夹(这就是最开始要分好文件夹的原因!)
填写好后直接开启一键三连:
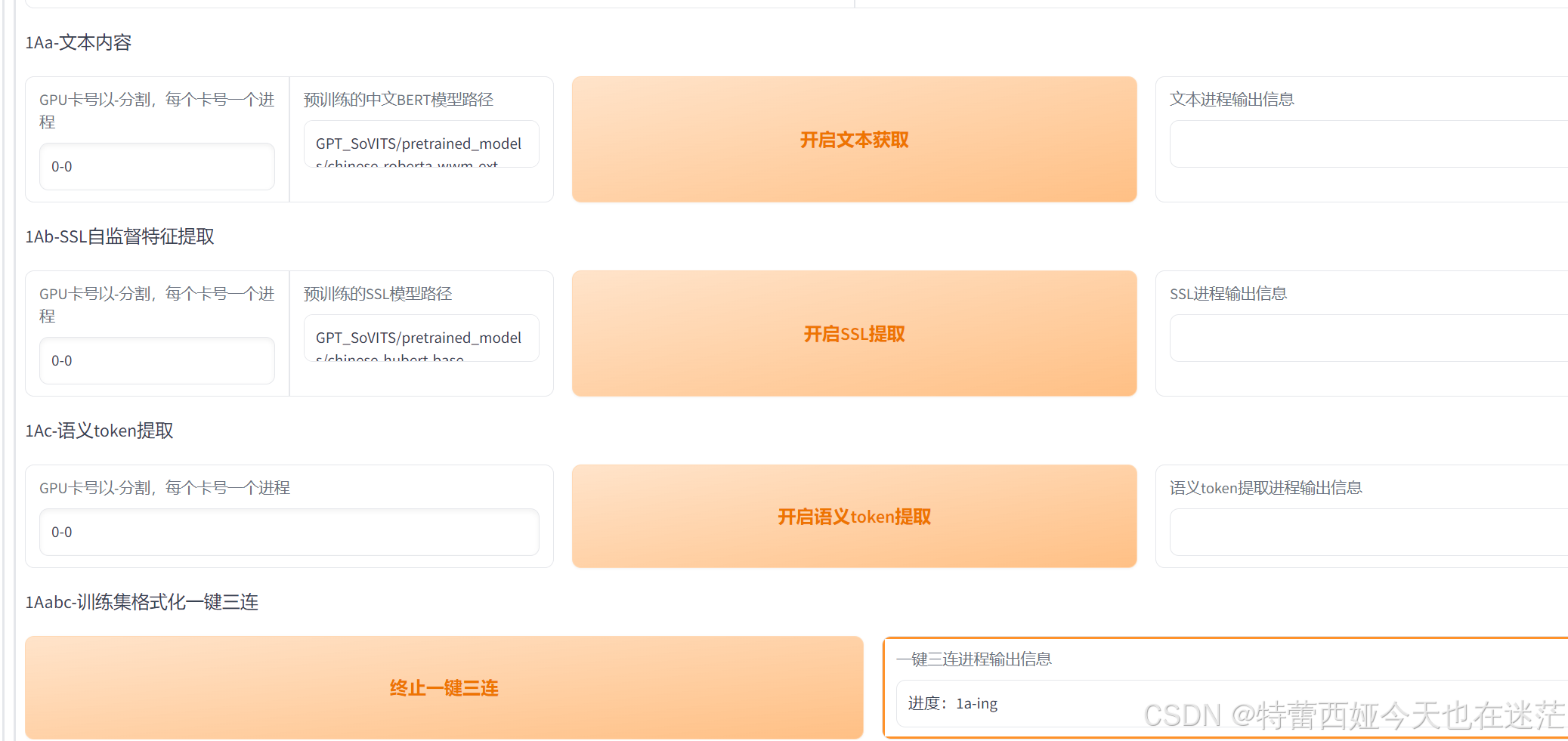
开启后要等一段时间,具体等多久取决于你的电脑,这里给你一个参考时间:
我的电脑是3050n卡,数据集在5分钟内,跑满不到两分钟就结束了。
微调处理
sovits训练
在页面顶部点击1b微调处理,进入微调处理的页面:
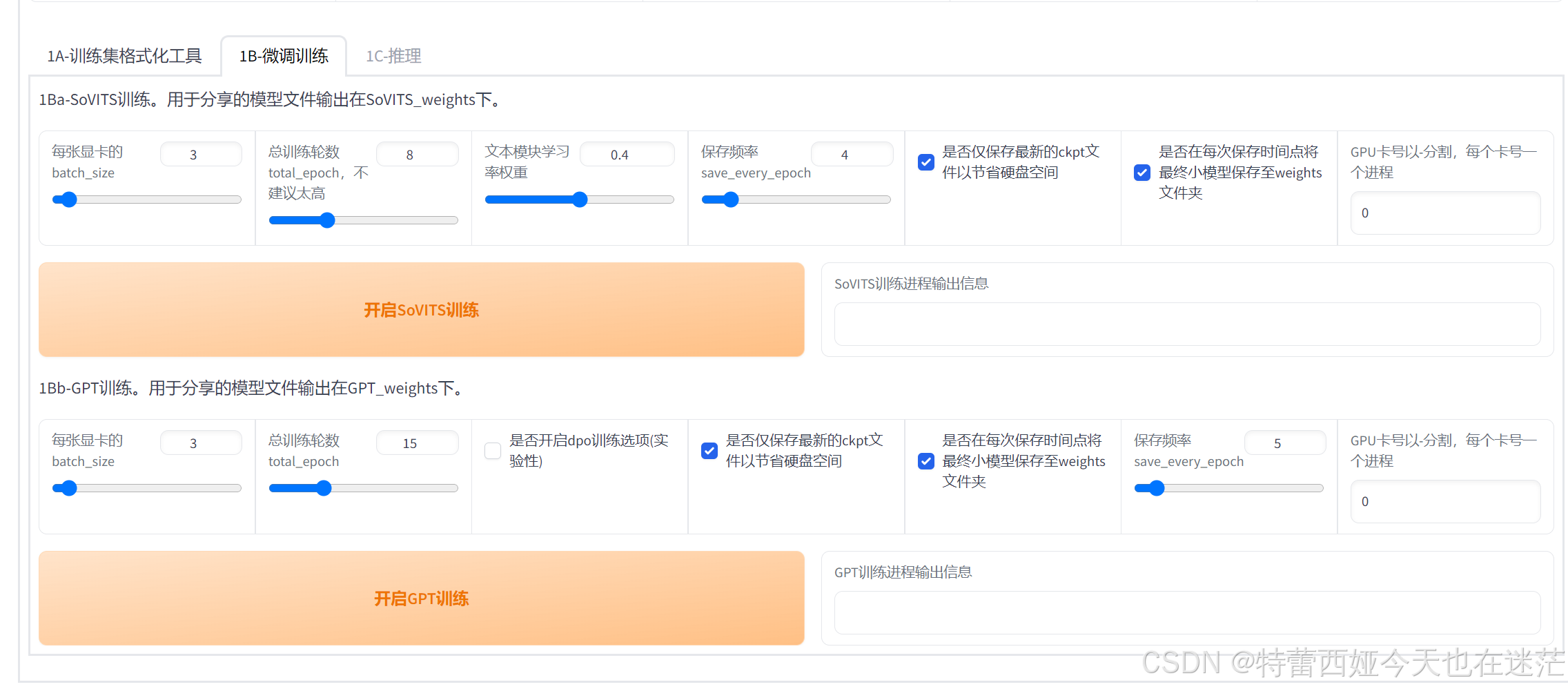
sovits训练比较玄学,默认参数不动比较好点,每张显卡的size数取决于你的显存有多少,例如我的显存最大是6g,那么这里填3就行。训练轮数在10-20比较好,高了低了效果都不好,学习权重建议不要动。保存频率就是每几轮保存一次。
填写完毕后直接开启训练就可以了,训练对性能消耗会很大,你的风扇转的会比较响,嗯,所以不要在图书馆玩这个(
等待一段时间(约10分钟)训练完毕,就可以进行下一步操作了。
gpt训练
batch size同上,总轮数在10-20左右即可,然后点击训练等等就好了!
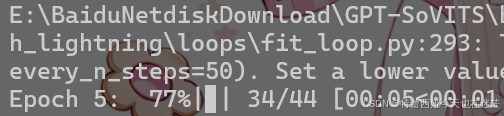
你的终端会有实时进度,无聊的话可以看看还剩多久,这个步骤也差不多不到十分钟就能搞定的样子。
推理
到这一步,你已经完成了全部的训练过程,现在只需要输入文本就可以获得声音了,我们点击1c推理,等待几秒来到推理界面:
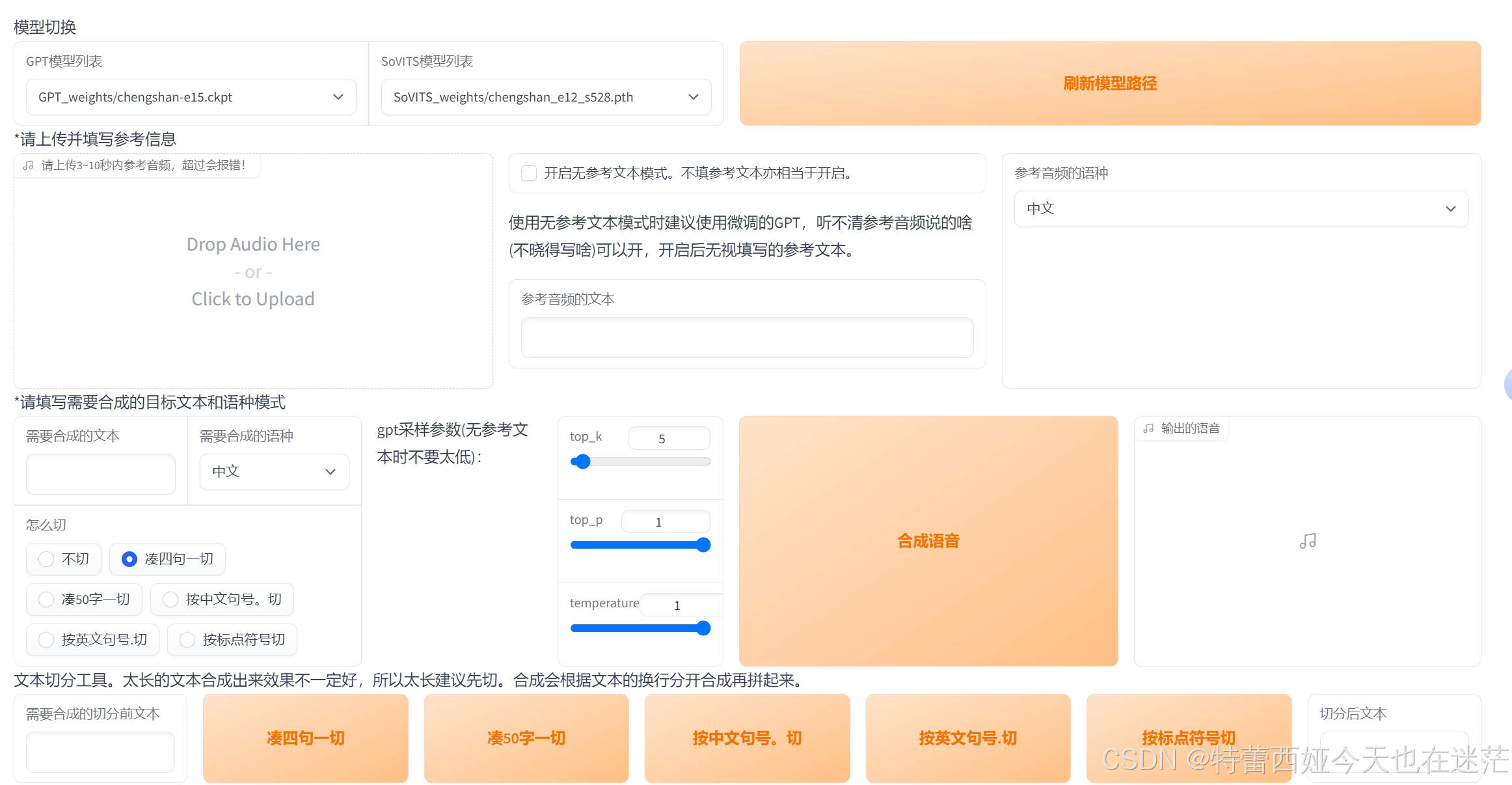
在模型列表选择你设置的模型名,然后上传参考音频(也就是0bout的文件夹里随便的一个,这个参考音频会决定生成结果的语气,选择的音频需要是3-10s内的)
其他部分不用动就行,top_k很玄学,如果你的模型质量不错就放低一点,如果模型质量不好可以适当拉高一点,10-60都行。top_p及以下的不要动。切字按50字切就行。
接着输入文本,右侧就能推理出音频了!
不过需要主意的是,中文文本是会忽略其他语言的,例如你想获得“我是秦始皇,v我50”的音频,你需要输入“我是秦始皇,微我五十”。
有问题请在评论区说,我看到了会帮忙看看。

一站式 AI 云服务平台
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)