
运维必知必会AI大模型知识之五:RAG
RAG 的核心可以理解为“检索+生成”。* 与预训练对比:RAG 成本较低,且可以利用外部知识源来获取更广泛、更准确的信息,而预训练成本较高,需要较长时间和计算资源。* 与语义搜索对比:语义搜索是 RAG 的一个元素,RAG 在检索向量数据库的步骤中利用语义搜索来生成符合语境且最新的结果。* 与微调对比:RAG 可以从单个文档中检索信息,所需的计算资源较少,且可以有效减少幻觉,而微调需要大量数据和
声明:让所有运维人一起拥抱AI,拥抱大模型,拥抱变化!公众号全新改版升级【互联网及大模型运维】
RAG (检索增强生成) 是一种优化大型语言模型 (LLM) 输出的技术,通过在生成响应之前引用外部知识库。它通过检索相关信息并将其融入提示(Prompt),使大模型能够参考相关知识,从而给出合理的回答。
RAG 的核心可以理解为“检索+生成”。检索利用向量数据库的高效存储和检索能力,召回目标知识;生成则利用大模型和 Prompt 工程,合理利用召回的知识,生成目标答案。
-
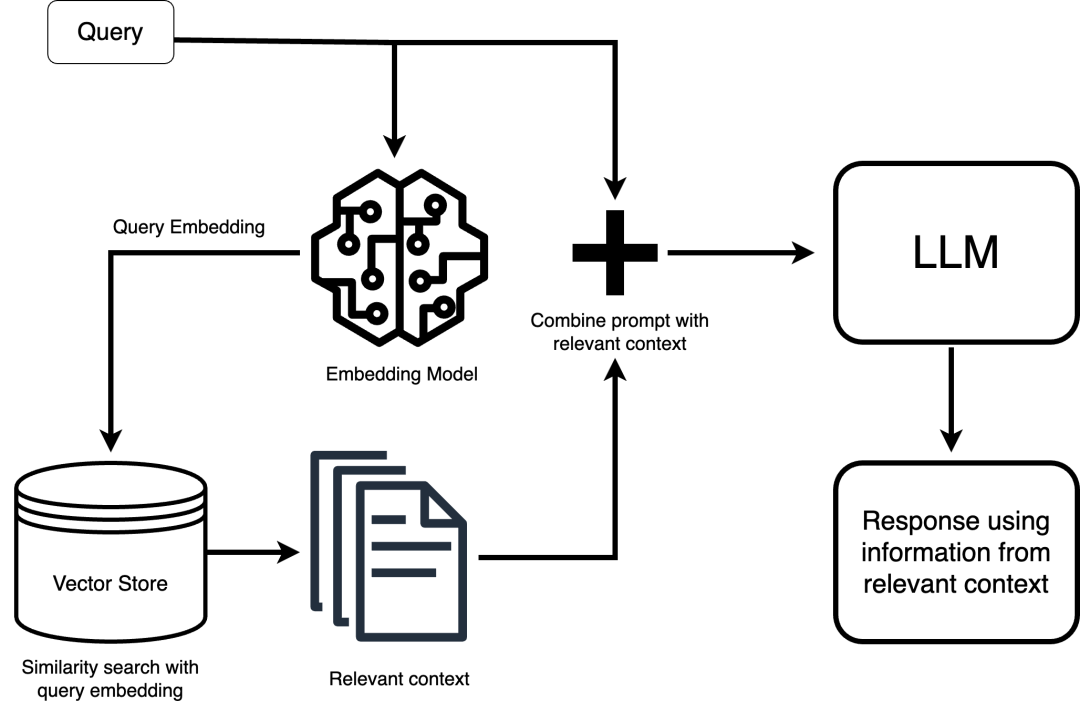
一、RAG 的工作原理主要包括以下步骤:
1. 数据准备:
* 数据提取:从各种数据源(如 API、数据库或文档存储库)提取数据。
* 文本分割:将文本分割成更小的块,以便更好地进行检索。
* 向量化:将文本数据转换为向量矩阵,以便进行相似性计算。
* 数据入库:将向量化的数据构建索引并存入向量数据库。
2. 检索:根据用户的问题,通过相似性检索、全文检索等方法,从数据库中召回与问题最相关的知识。
3. 生成:将检索到的相关知识融入 Prompt,LLM 参考当前问题和相关知识,生成相应的答案。
-
二、RAG 的主要优势包括:
* 提高准确性:通过提供外部知识来源,减少 LLM 产生虚假或过时信息的可能性。
* 降低成本:避免了重新训练 LLM 的高额成本,并降低了推理成本。
* 更多开发者控制:开发人员可以更高效地测试和改进聊天应用程序,控制和更改 LLM 的信息来源。
* 数据主权和隐私:允许将敏感数据保留在本地,同时用于为 LLM 提供信息。
-
三、RAG 与其他数据训练和处理方法有所不同:
* 与提示词工程对比:RAG 可以基于最新信息或不断变化的信息生成输出,而提示词工程依赖于预训练数据。
* 与语义搜索对比:语义搜索是 RAG 的一个元素,RAG 在检索向量数据库的步骤中利用语义搜索来生成符合语境且最新的结果。
* 与预训练对比:RAG 成本较低,且可以利用外部知识源来获取更广泛、更准确的信息,而预训练成本较高,需要较长时间和计算资源。
* 与微调对比:RAG 可以从单个文档中检索信息,所需的计算资源较少,且可以有效减少幻觉,而微调需要大量数据和计算资源。
-
四、以下是其典型应用场景及案例解析:
A、知识密集型场景
1. 智能客服与问答系统
- 痛点
:传统生成模型容易产生“幻觉”(虚构答案),且无法实时更新知识库。
- RAG解决方案
-
-
客服对话中,实时检索企业知识库(产品文档、FAQ)生成精准回答;
-
案例:银行客服回答“信用卡年费政策”,RAG优先检索最新条款,再生成用户可理解的解释。
-
2. 专业领域咨询(医疗、法律、金融)
- 场景价值:确保回答符合行业规范,规避风险
-
- 医疗
输入症状描述,RAG检索权威医学文献生成诊断建议,标注参考文献;
- 法律
输入案件描述,检索相关法条和判例生成法律意见书;
- 金融
分析财报时,RAG自动关联历史数据和行业报告,生成投资风险评估。
- 医疗
B、动态数据依赖场景
1. 新闻与舆情分析
- 应用逻辑
-
-
生成新闻摘要时,实时检索最新报道(如突发事件)补充背景;
-
案例:生成“某公司财报解读”,RAG自动抓取当日股价、同行对比数据,避免信息滞后。
-
2. 个性化推荐与营销
- 场景
:电商、内容平台
-
-
用户提问“适合冬季的护肤品推荐”,RAG先检索用户历史购买记录、肤质数据,再生成个性化产品列表;
-
营销文案生成时,结合实时热点(如节日、趋势话题)调整话术。
-
C、复杂决策支持场景
1. 企业知识管理
- 痛点
员工难以快速获取分散在多个系统(CRM、ERP、邮件)中的信息。
- RAG应用
-
-
构建企业级知识引擎,输入问题如“去年Q3北美市场销售额”,RAG自动检索内部数据库、会议纪要生成分析报告;
-
案例:Salesforce Einstein GPT 使用RAG整合CRM数据生成销售策略。
-
2. 科研与文献分析
- 场景
-
-
输入研究假设,RAG检索arXiv、PubMed等论文库生成文献综述;
-
药物研发中,跨数据库检索化学分子属性、临床试验数据生成合成路径建议。
-
D、多模态与跨模态场景
1. 跨模态内容生成
- 应用:图文/音视频创作
-
-
输入文字“生成一幅赛博朋克风格的城市夜景”,RAG先检索类似风格的图片库,再生成更符合用户预期的图像;
-
视频脚本创作时,检索历史爆款视频数据优化叙事结构。
-
2. 多语言场景
- 案例
-
-
小语种翻译(如斯瓦希里语→中文),RAG优先检索现有双语语料库,补充生成模型的低频语言知识;
-
跨境电商客服中,RAG支持跨语言检索商品手册生成本地化回答。
-
E、安全与合规场景
1. 风险内容过滤
- 逻辑:
-
-
生成内容前,先检索合规数据库(如广告法、隐私条款)进行风险校验
-
案例:生成营销文案时,自动屏蔽禁用词(如“最优惠”“保证疗效”)。
-
2. 事实核查与纠错
- 应用
-
-
生成文本后,RAG二次检索权威信源(如政府公开数据)验证关键数据;
-
自动修正生成内容中的过时信息(如“2023年人口数据”替换为最新统计)。
-
适用行业:金融、医疗、法律、教育、电商、媒体、智能制造等数据驱动且容错率低的领域。随着多模态技术的发展,RAG将进一步渗透到图像、音视频等复杂场景中。
附:References:
* [1] 什么是RAG?— 检索增强生成AI 详解 - AWS - https://aws.amazon.com/cn/what-is/retrieval-augmented-generation/
* [2] 一文读懂:大模型RAG(检索增强生成)含高级方法 - 知乎专栏 - https://zhuanlan.zhihu.com/p/675509396
* [3] 什么是检索增强生成? - Red Hat - https://www.redhat.com/zh/topics/ai/what-is-retrieval-augmented-generation

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)