
[爬虫实战] 使用 DrissionPage 自动化采集小红书笔记
本文介绍了一个基于DrissionPage框架的小红书笔记自动化采集方案。通过模拟扫码登录、直接构造搜索URL、监听API接口等方式,高效获取笔记数据。
相关爬虫知识点:[爬虫知识] DrissionPage:强大的自动化工具
相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例 逆向知识点合集
引言:
自动化工具我们选择DrissionPage,因为它以其简洁的操作和高效的性能脱颖而出,成为自动化爬虫的理想框架。它不仅大幅简化了复杂的浏览器交互,更在数据获取效率上带来了质的飞跃。
一、自动化登录
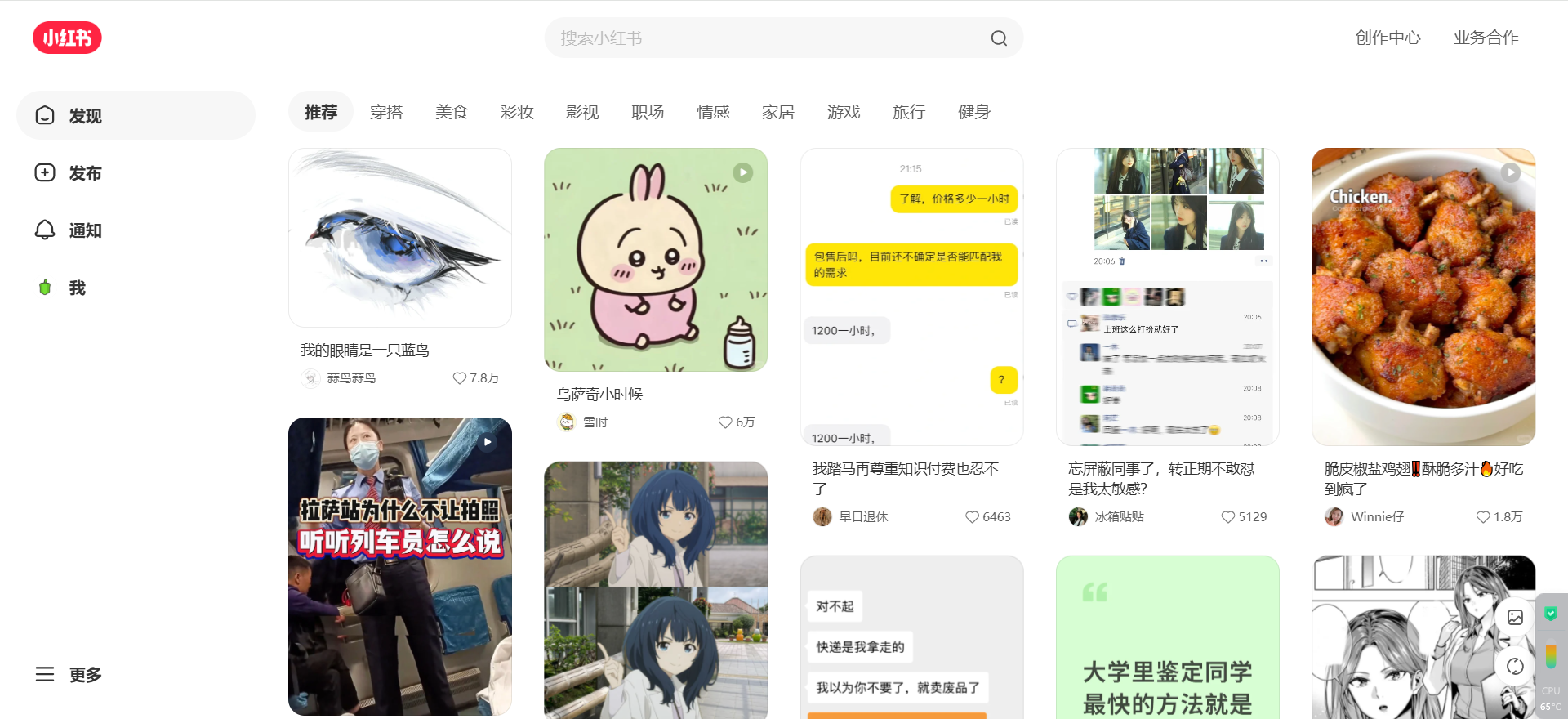
要开始小红书的笔记采集,首先必须解决登录问题。对于这类高度重视用户行为的平台,模拟人工扫码登录是最稳定可靠的方式。
此处选择让用户在程序启动时手动完成扫码登录,登录成功后,只需轻轻敲击回车键,程序便会自动进入后续的爬取逻辑。
在小红书主页点击登录后就会弹出对应窗口,所以我们可以要求使用者在这里自己完成扫码登录,登录成功后按enter自动进入之后的爬取逻辑。
# ========== 初始化浏览器 ==========
from DrissionPage import ChromiumPage
import os
import time
page = ChromiumPage()
# 访问小红书探索页
page.get('https://www.xiaohongshu.com/explore')
# 等待用户扫码登录
input('请扫码登录,登录成功后按回车继续\n如已登录请直接按回车')登录成功:
二、爬取自动化
1. Excel 文件初始化
在开始数据采集之前,我们需要为每个关键词准备一个干净的 Excel 文件来存储数据。我们使用 DrissionPage 推荐的 DataRecorder 库来实现这一功能。create_xlsx 函数会检查同名文件是否存在,若存在则先删除,确保每次运行都是从零开始收集数据。
from DataRecorder import Recorder
def create_xlsx(keyword):
"""
为每个关键词创建一个新的 Excel 文件,如果文件已存在则先删除。
"""
filename = f'{keyword.strip()}.xlsx'
# 如果文件已存在,先删除它
if os.path.exists(filename):
os.remove(filename)
print(f'已清除旧文件: {filename}')
# 创建新的recorder实例
recorder = Recorder(filename)
recorder.set.show_msg(False) # 移除多余打印信息
return recorder2.深度数据提取
小红书笔记详情接口返回的数据通常是嵌套的 JSON 结构。为了方便地从这些复杂结构中提取我们需要的特定字段(如昵称、标题等),我们编写了一个 find_want 辅助函数。它能够递归遍历字典和列表,精准定位并返回目标键的值。
# 辅助函数:递归查找字典或列表中指定键的值
def find_want(data, target_key):
"""
递归地从嵌套的字典或列表中查找指定键的值。
"""
# 处理数据为字典的递归遍历
if isinstance(data, dict):
for key, val in data.items():
if key == target_key:
return val
# 递归遍历子元素
ret = find_want(val, target_key)
if ret:
return ret
elif isinstance(data, list):
for i in data:
ret = find_want(i, target_key)
if ret:
return ret
else:
return None3. 关键词搜索
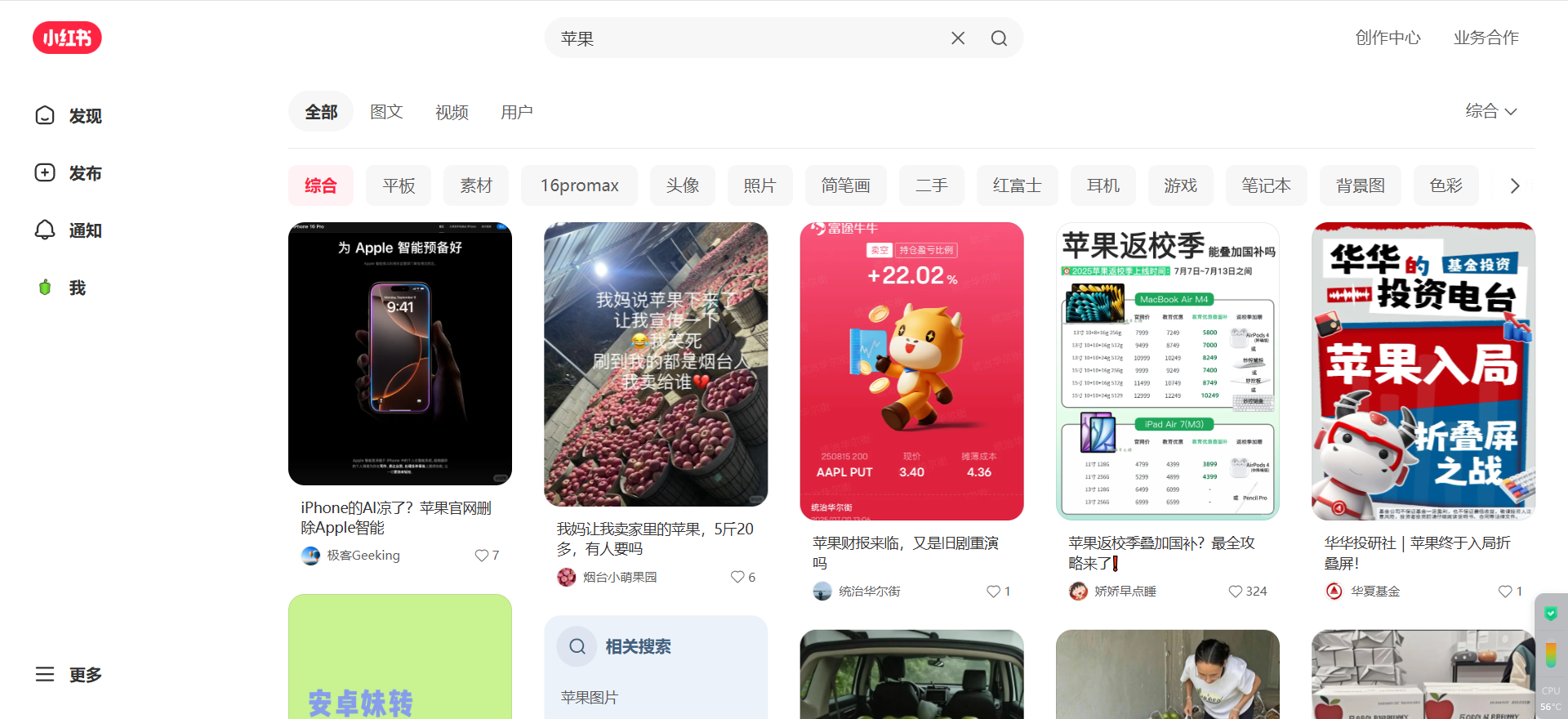
与其模拟在搜索框中输入关键词再点击搜索,我们有更高效的方式:直接构造带有关键词的搜索结果页 URL 并访问。这样不仅节省了交互步骤,也更加稳定。
# 假设 keyword 已定义,比如 '苹果'
# 直接访问搜索结果页,keyword 即意图搜索的关键字
page.get(f'https://www.xiaohongshu.com/search_result?keyword={keyword}&source=web_profile_page')
# 等待页面加载完成
page.wait.load_start()4. 笔记数据采集:点击、监听与去重
进入搜索结果页后,页面会展示大量笔记卡片。我们的下一步逻辑是:遍历这些卡片,依次点击它们,进入笔记详情页获取数据,然后返回。同时,为了获取更多内容,我们还需要模拟下拉滚动条。
DrissionPage 在这里展现了它的强大之处:
-
智能点击:我们通过
card.ele('xpath:./div/a[2]/img').click(by_js=True)利用 JavaScript 模拟点击,有效避免了因图层遮蔽导致的点击失败。 -
请求监听:最关键的是
page.listen.start('web/v1/feed')。小红书的笔记详情数据通常是通过 API 异步加载的。DrissionPage 允许我们监听特定的网络请求(例如web/v1/feed接口),直接捕获到后端返回的 JSON 数据。这意味着我们无需解析复杂的 HTML 结构,直接从数据源获取nickname、title、desc、comment_count、liked_count等信息,极大提高了数据获取的效率和准确性。
为了避免重复采集,我们使用一个 set 集合 (s) 来存储已处理的笔记 data-index,确保每条笔记只被处理一次。同时,每采集一定数量的笔记(例如5条),我们会模拟页面滚动 page.scroll.down(1000),触发新内容的加载。
# 核心数据获取逻辑片段
# ...
# 点击卡片并获取数据
card.ele('xpath:./div/a[2]/img').click(by_js=True)
# 监听并等待数据接口返回,获取响应体
res = page.listen.wait(count=1, timeout=3, fit_count=True)
data = res.response.body
# 数据提取与存储
nickname = find_want(data, 'nickname')
title = find_want(data, 'title')
desc = find_want(data, 'desc')
comment_count = find_want(data, 'comment_count')
liked_count = find_want(data, 'liked_count')
# 基于 DataRecorder 将采集数据写入 Excel
map_ = {
'博主昵称': nickname,
'标题': title,
'详情': desc,
'评论数': comment_count,
'点赞数': liked_count,
}
recorder.add_data(map_)
recorder.record()
# 关闭详情页,准备下一条
page.ele('xpath:/html/body/div[5]/div[2]/div').click()
page.wait.load_start()
# ...
三、完整逻辑构建与代码实现
将上述登录、Excel 初始化、搜索、数据采集和去重逻辑整合,再加上日志输出,配合 DataRecorder 库进行数据存储,就构成了我们的完整自动化爬虫脚本。该自动化爬虫可以批量爬取20条数据,并将其保存数据到excel。(爬取的数量可以自己更改)
其中需要在同目录下创建一个关键字.txt,里面写上想要搜索的关键字即可。如果希望获取多个关键字搜索的批量数据,直接换行再写另一个关键字就行。
import os
import time
from loguru import logger
from DrissionPage import ChromiumPage
from DataRecorder import Recorder
def create_xlsx(keyword):
filename = f'{keyword.strip()}.xlsx'
# 如果文件已存在,先删除它
if os.path.exists(filename):
os.remove(filename)
logger.info(f'已清除旧文件: {filename}')
# 创建新的recorder实例
recorder = Recorder(filename)
recorder.set.show_msg(False) # 移除多余打印信息
return recorder
# 对返回的数据进行处理,用以获得希望返回的字符
def find_want(data, target_key):
# 处理数据为字典的递归遍历
if isinstance(data, dict):
for key, val in data.items():
if key == target_key:
return val
# 递归遍历子元素
ret = find_want(val, target_key)
if ret:
return ret
elif isinstance(data, list):
for i in data:
ret = find_want(i, target_key)
if ret:
return ret
else:
return None
# dp自动化抓取
def handler(page, keyword):
recorder = create_xlsx(keyword)
# 监听数据接口 -- 尽量写在最前面
page.listen.start('web/v1/feed') # 形如这种格式的会被抓取
page.get(f'https://www.xiaohongshu.com/search_result?keyword={keyword}&source=web_profile_page')
page.wait.load_start()
s = set()
logger.info(f'开始爬取{keyword}项...\n')
# 爬取二十条数据
data_count = 0
max_count = 20
error_count = 0
scroll_interval = 5 # 每采集五条滚动一次
while data_count < max_count:
try:
cards = page.eles('xpath://*[@id="global"]/div[2]/div[2]/div/div/div[3]/div[1]/section')
for card in cards:
if data_count >= max_count:
break
# 去重
index = card.attr('data-index')
if index in s:
continue
s.add(index)
logger.info(f'正在爬取第{data_count+1}条数据...')
# 点击卡片并获取数据
card.ele('xpath:./div/a[2]/img').click(by_js=True) # 用js点击,如用默认的False,则是模拟点击,可能会被因为图层遮蔽无法点到
res = page.listen.wait(count=1, timeout=3, fit_count=True) # 匹配数量/超时等待时间/是否严格匹配
data = res.response.body
# 数据提取
nickname = find_want(data, 'nickname')
title = find_want(data, 'title')
desc = find_want(data, 'desc')
comment_count = find_want(data, 'comment_count')
liked_count = find_want(data, 'liked_count')
# 基于recorder将采集数据写入excel
map_ = {
'博主昵称': nickname,
'标题': title,
'详情': desc,
'评论数': comment_count,
'点赞数': liked_count,
}
recorder.add_data(map_)
recorder.record()
# 关闭卡片+等待
page.ele('xpath:/html/body/div[5]/div[2]/div').click()
page.wait.load_start()
# time.sleep(3)
data_count+=1
# 每采集一定数量滚动一次
if data_count % scroll_interval == 0:
logger.info('页面正进行滚动以加载更多内容...')
page.scroll.down(1000)
page.wait.load_start()
# break
except Exception as e:
logger.warning(f'数据查找异常,跳过当前轮:{e}')
error_count += 1
if error_count > max_count:
logger.info(f'错误超过{max_count}次,停止采集!')
break
continue
if data_count >= max_count:
logger.info(f'已爬取{data_count}条数据,{keyword}项打印完成!')
else:
logger.info(f'{keyword}项采集未完成,共采集到{data_count}条数据')
# 主执行
def main():
with open('关键字.txt', 'r', encoding='utf8') as f:
keywords = f.readlines()
# 浏览器驱动对象
page = ChromiumPage()
page.get('https://www.xiaohongshu.com/explore')
# 等待操作(登录)
input('请扫码登录,登录成功后按回车继续\n如已登录请直接按回车')
for keyword in keywords:
handler(page, keyword.strip())
main()

一站式 AI 云服务平台
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)