
Pytest自动化测试框架详解
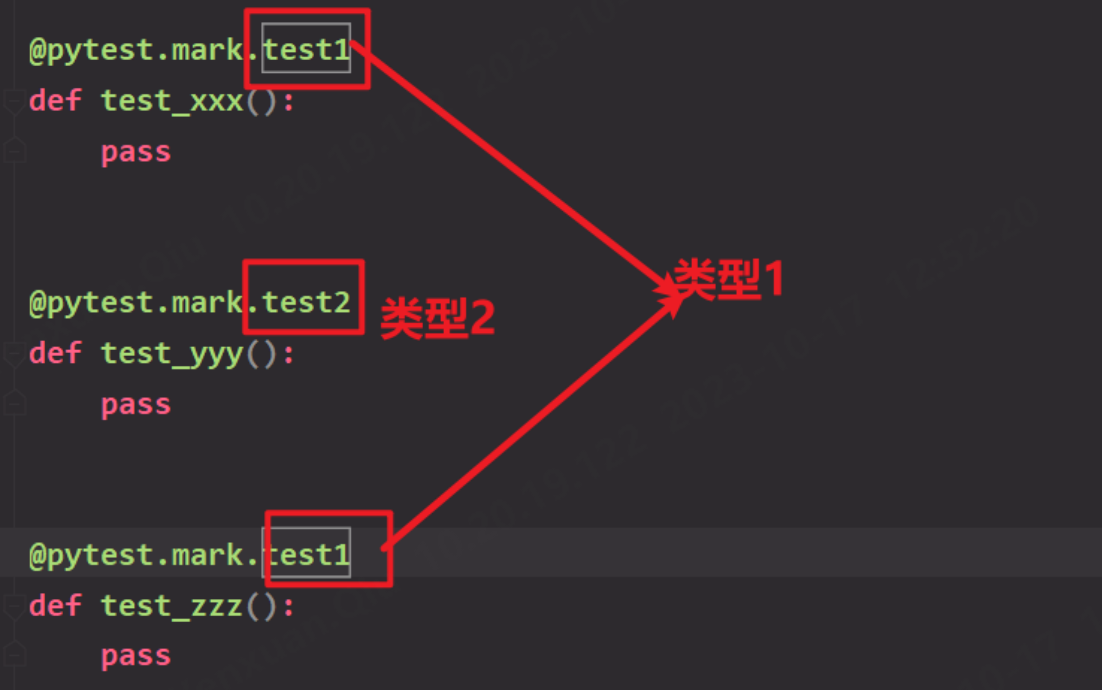
mark首先在pytest.ini配置文件里面定义,才可以使用定义mark配置信息:将mark自定义分为三类:test1、test2、test3,即markers = 类型名 : 类型注释你可以用mark标记不同的测试用例,通过 pytest -m 类型名 筛选需要执行哪类测试用例。
三、Pytest框架
Pytest是什么?
- pytest能够支持简单的单元测试和复杂的功能测试;
- pytest可以结合Requests实现接口测试;
- 结合Selenium、Appium实现自动化功能测试;
- 使用pytest结合Allure集成到Jenkins中可以实现持续集成。
- pytest支持315种以上的插件;
1、安装pytest及其插件
pytest生态是由pytest本身和pytest插件共同构成的
- pytest:框架本体
- pytest-html:生成HTML测试报告
- pytest-xdist:并行话执行测试用例
- pytest-rerunfailures:失败重跑
- pytest-ordering:为用例排序
- allure-pytest:生成allure测试报告
1.安装pytest
pip是Python包管理工具,使用pip工具进行安装
pip install pytest
2.安装pytest插件
pip install pytest pytest-html pytest-xdist pytest-rerunfailures pytest-ordering allure-pytest
2、Pytest规范
1.pytest用例规范
1. 文件:必须以test_ 开头或_test结尾
2. 类:以Test开头或者继承unittest.TestCase的任意名称的类
3. 方法:以test_开头的方法
4. 注意:测试类中不可添加__init()__构造函数,pytest不识别含__init()__的类内的测试方法

2.pytest输出规范
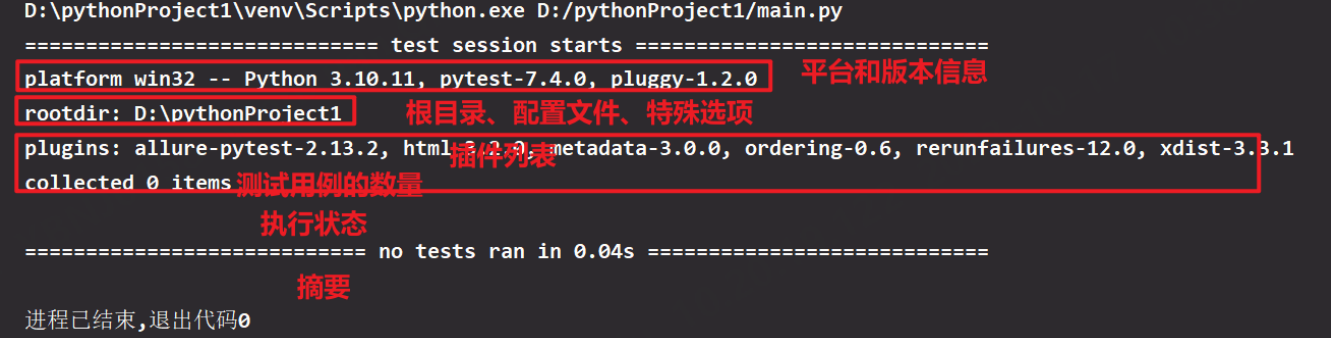
Text测试报告-》HTML测试报告
1. 报告头
1. 平台和版本信息
2. 根目录、配置文件、特殊选项
3. 插件列表
2. 收集情况
1. 测试用例的数量
3. 执行状态
1. 用例的执行结果
2. 测试执行进度
3、python运行pytest
-
pthon解释器
-
- 使用python test_*文件名.py 执行方法当中的pytest.main()
- 使用python -m pytest test_*文件名.py方式执行pytest.main()
-
使用pytest方法执行p
对于一个简单的测试用例
def inc(x):
return x + 1
def test_anwer():
assert inc(4)
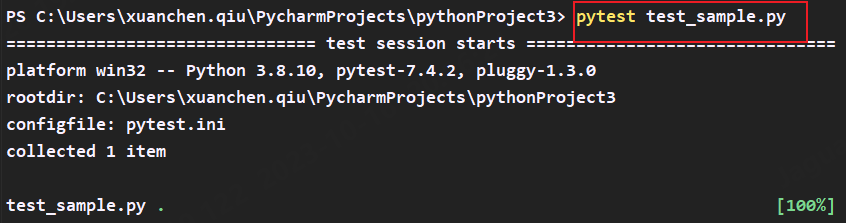
1.使用pytest执行
pytest test_sample.py
2.使用python解释器执行
方法1:python test_*文件名.py
方法2:python -m pytest test_*文件名.py
在使用这两个命令之前,我们先来熟悉一下pytest.main()函数及其模块
使用python解释器执行文件,系统会以main()函数作为入口执行代码程序,调用pytest.main()执行所有的满足pytest规则的方法。
为了确保测试用例只在本模块调用执行,我们需将pytest.main()方法放在if __name__ == '__main__':模块内
pytest.main()也可以传入命令行参数达到在终端使用pytest命令行一样的效果,如下:
if __name__ == '__main__': # 只在本模块运行
pytest.main() # 1、直接调用,运行当前目录下所有满足pytest条件的用例
pytest.main(['test_command_param.py::test_function', '-vs']) # 2、运行子模块下的方法,并使用标签,每个值需要用引号隔开 相当于 pytest test_command_param.py::test_function -vs
pytest.main(['test_command_param.py', '-vs', '-m', 'double']) # 3、运行某个标签下的所有用例 相当于 pytest test_command_param.py -vs -m=double
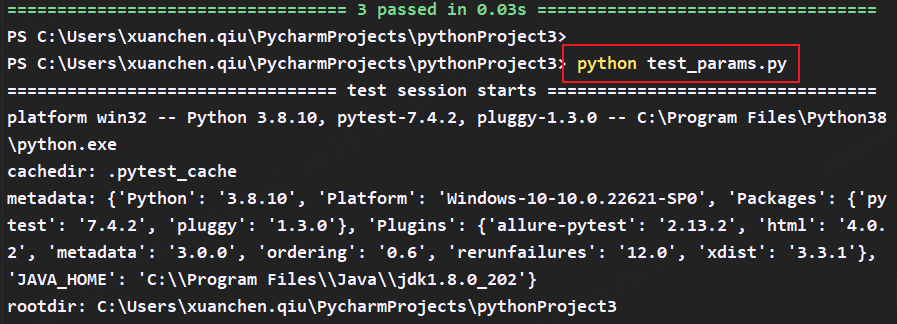
2.1 使用python test_*文件名.py
首先,在代码中添加一个模块,将命令和标签以列表的形式传到pytest.main(参数)内
if __name__ == '__main__': # 只在本模块运行
pytest.main() # 1、直接调用,运行当前目录下所有满足pytest条件的用例
pytest.main(['test_command_param.py::test_function', '-vs']) # 2、运行子模块下的方法,并使用标签,每个值需要用引号隔开
pytest.main(['test_command_param.py', '-vs', '-m', 'double']) # 3、运行某个标签下的所有用例
调用python解释器
python +文件名.py
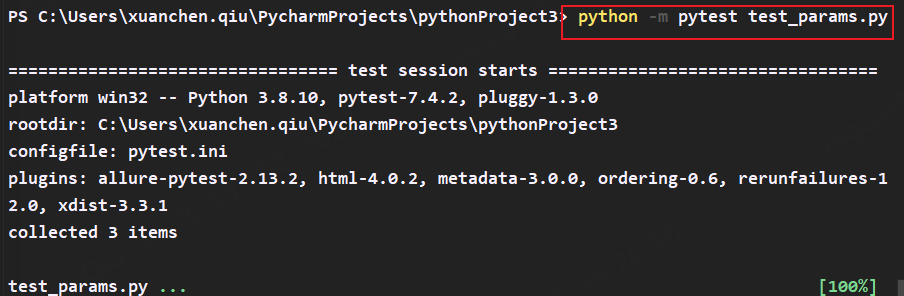
2.2 使用python -m pytest test_*文件名.py
我们还可以使用以下命令去实现,效果等价于python + test_*.py文件名方式
python -m pytest test_*.py
综上所述,实际执行用例环境是在python环境下,因此常用python解释器去执行测试用例,及python -m pytest test或python +文件名.py的方式,因为而不常用pytest框架的方式,使用python解释器方便指定版本。
3.pytest运行多条用例

- 执行包下面所有的用例:pytest
- 执行单独一个pytest模块:pytest 文件名.py

- 运行某个模块里面的某个类:pytest 文件名.py::类名 (-v显示细节)
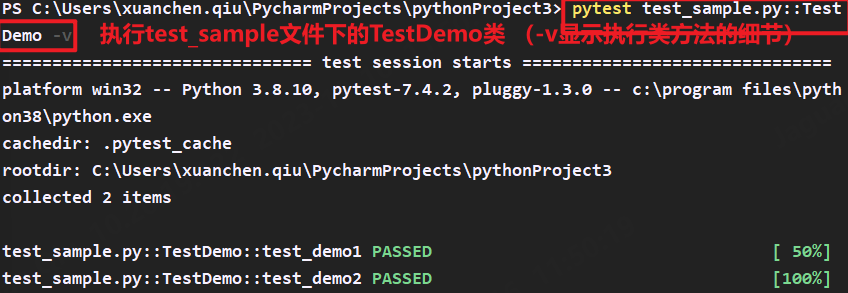
- 运行某个模块里面某个类的方法:pytest 文件名.py::类名::方法名(模块其实就是一个文件里面有很多类)

pytest常见提示关键字:
PASSED :表示断言通过
FAILED:表示断言失败
ERROR:表示代码命名等不符合规范,且不能运行
WARNING :警告,不影响正常运行
4、setup和teardown

setup/teardown与setup_method/teardown_method功能相同,相当于一个简单的缩写。
这里注意函数与方法的区别:函数(function)相对于方法(method)而言函数定义在类外,方法定义在类里面作为类独有的方法。这里setup_function和setup_method就是属于在函数或方法范围上的不同。
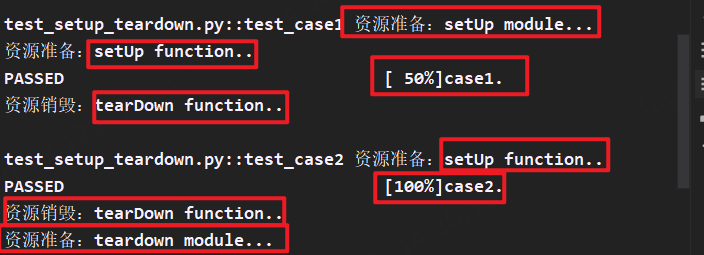
def test_case1():
print("case1")
def setup_function():
print("资源准备:setUp function...")
def teardown_function():
print("资源销毁:tearDown function...")
运行结果:

及最高级是setup_module与teardown_module(模块级)整个程序只前后运行一次,最低级别的是setup、teardown(方法级)每个方法前后调用。
def test_case1():
print("case1.")
def test_case2():
print("case2.")
def setup_module():
print("资源准备:setUp module...")
def teardown_module():
print("资源准备:teardown module...")
def setup_function():
print("资源准备:setUp function..")
def teardown_function():
print("资源销毁:tearDown function..")
运行结果:
5、pytest基本命令行参数
更多筛选用例参数
Pytest脚本的运行_pytest怎么执行指定文件或目录-CSDN博客

--help 查看帮助
-x 用例一旦失败(fail/error),就立即停止执行。一般用在冒烟测试(单独测试几个核心的功能的测试,一旦发现错误,版本立即打回给开发)
--maxfail=mun 允许失败的个数=mun,当失败个数超过num停止执行。相比较-x没有那么苛刻
-m 标记用例
-k 执行包含某个关键字的测试用例
-v 显示用例执行详细信息
-s 打印输出日志(-vs一块使用)
-collection-only 测试平台,pytest自动导入功能
-h 显示所有参数帮助
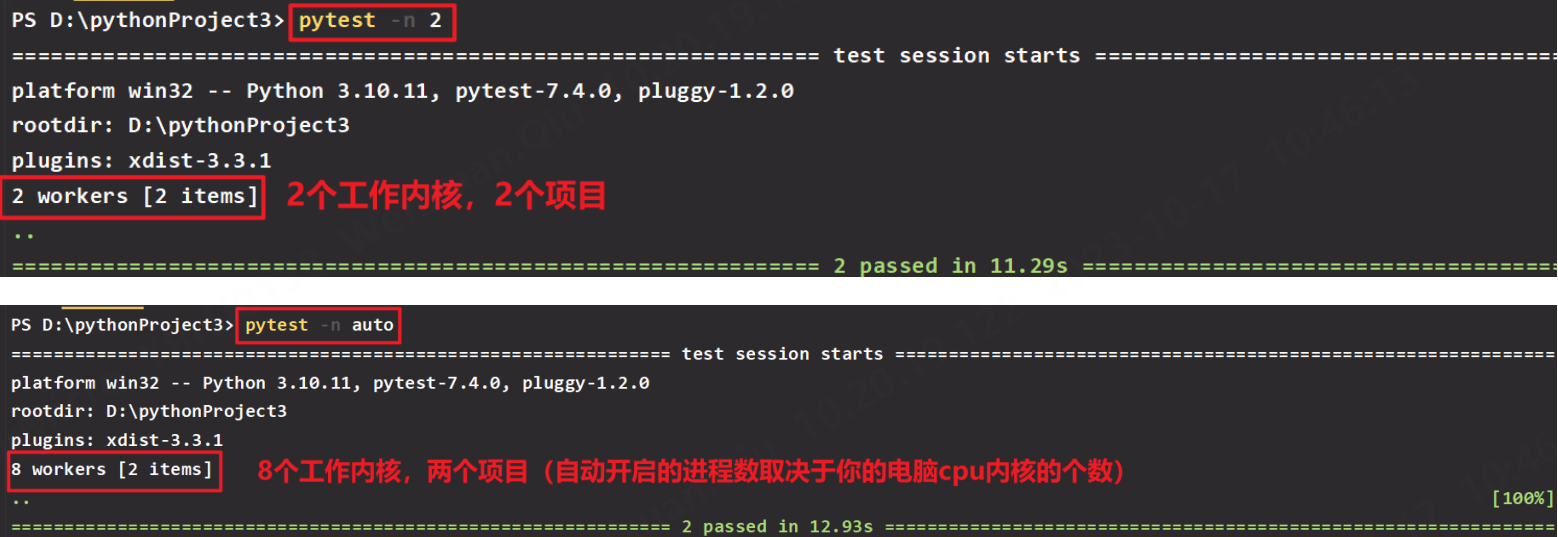
-n X 使用X个进程,并行化执行用例(1核执行时间为10s,两核执行时间缩短一半5s)/-n auto 自动选择进程数执行用例(取决于你的电脑cpu)
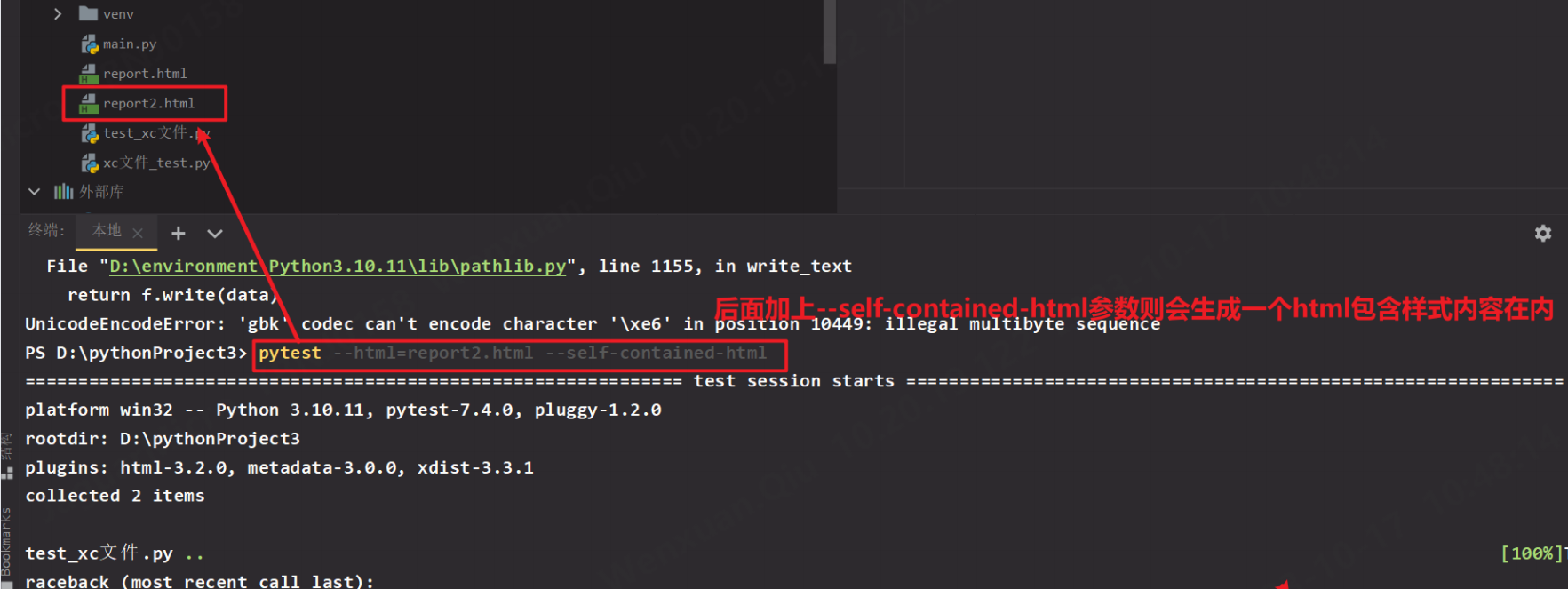
--html=Path 生成HTML测试报告和一个样式文件,并保存在Path路径下/--html=Path --self-contained-html HTML文件自包含样式文件,只会生成一个HTML文件
reruns X 测试用例失败后,重新X次
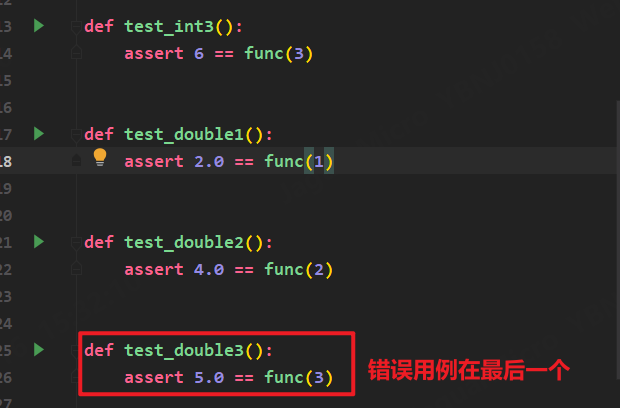
1.-x 用例失败停止执行
用例一旦执行错误,立刻停止执行
错误用例在最后一个:

错误用例在第一个:


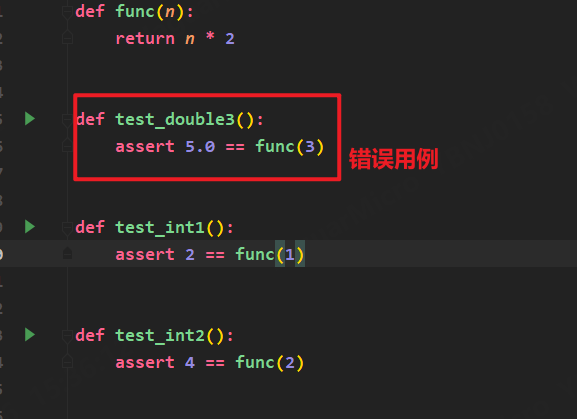
2.–maxfail=mun 设置允许失败的用例个数num
当我们使用–maxfail=mun命令设置最大允许失败的用例个数为2,我们把失败的用例放在第一条时,发现不再和-x一样直接退出,而是完整的执行完整个测试类,直到找到两个失败的用例才退出。
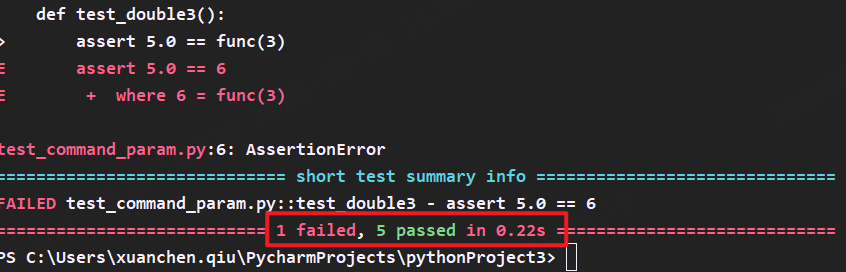
而我们将失败次数改为1时,本质上和-x没区别,当第一条用例失败时直接退出

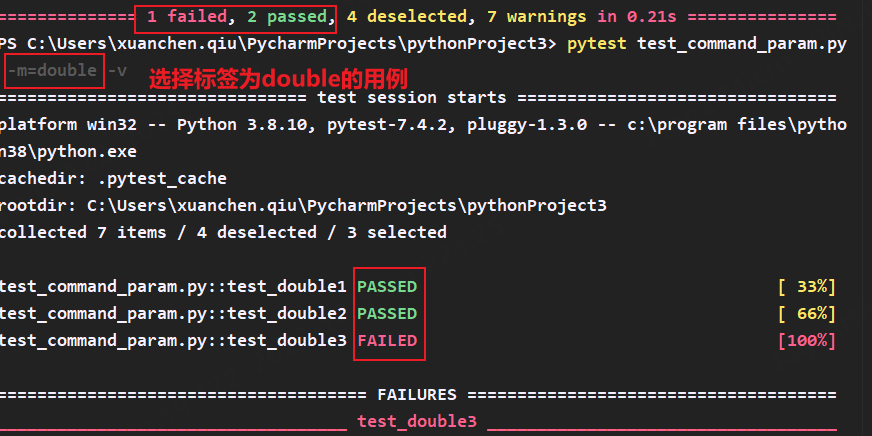
3.-m 标记用例
用例用mark分组后,使用-m标签选择指定组执行用例
-m=double
-m double
-m "double"
-m 'double'
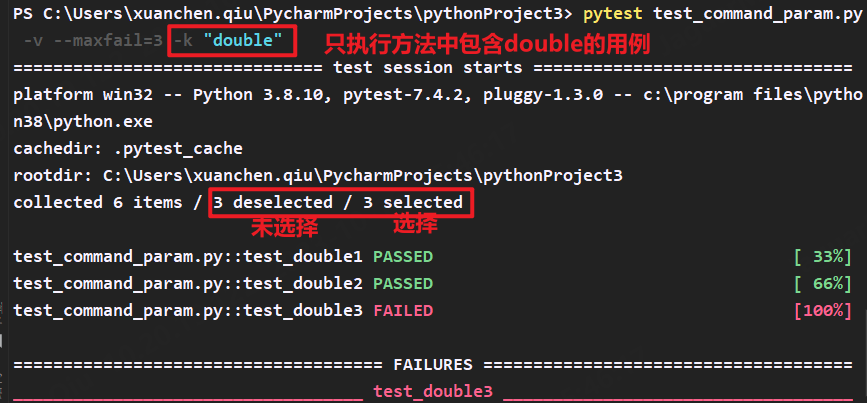
4.-k 执行方法名包含某个关键字的用例
pytest test_command_param.py -v --maxfail=3 -k "double"
执行一个测试文件内的两个方法
pytest -k "test_method1 or test_method2"
# 这个命令将运行 test_method1 和 test_method2,无论它们位于哪个文件中。
如果你的测试方法分布在不同的类中,你也可以在 -k 表达式中包含类名。例如:
pytest -k "TestClass1 and test_method1 or TestClass2 and test_method2"
# 这将运行 TestClass1 中的 test_method1 和 TestClass2 中的 test_method2
5.-v 输出测试详情
如果不使用-v,则用例成功用"."标识,失败用"F"表示,不方便阅读
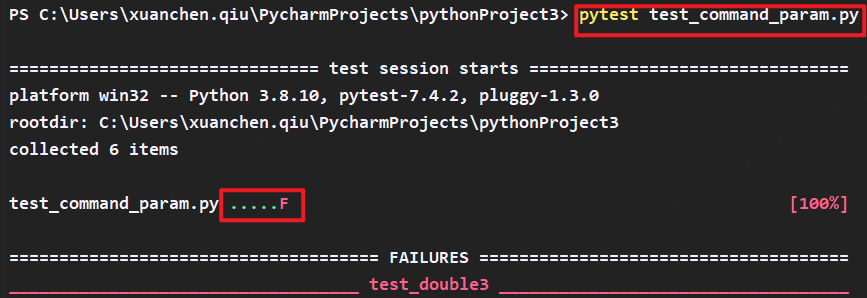
使用-v,会显示详细的用例方法是否通过

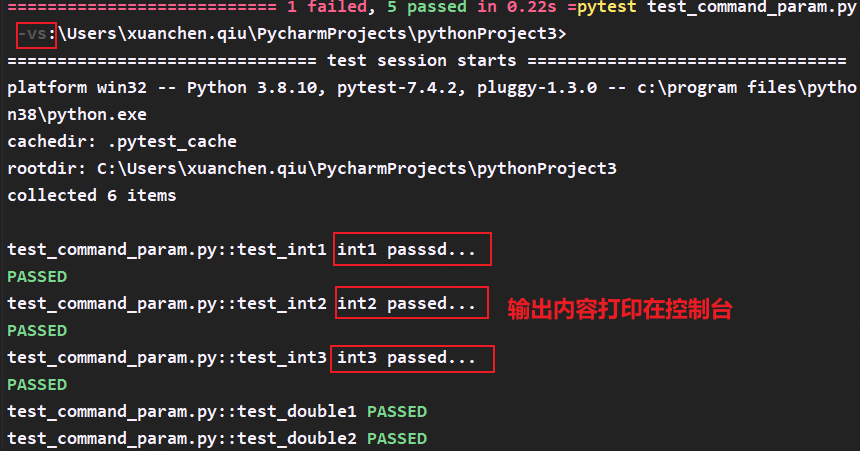
6.-s 开启内容输出
pytest框架采用终端的方法默认关闭测试用例的输出内容,使用-s会打开并输出内容到控制台,一般与-v一起使用用于调试代码
pytest test_command_param.py -vs
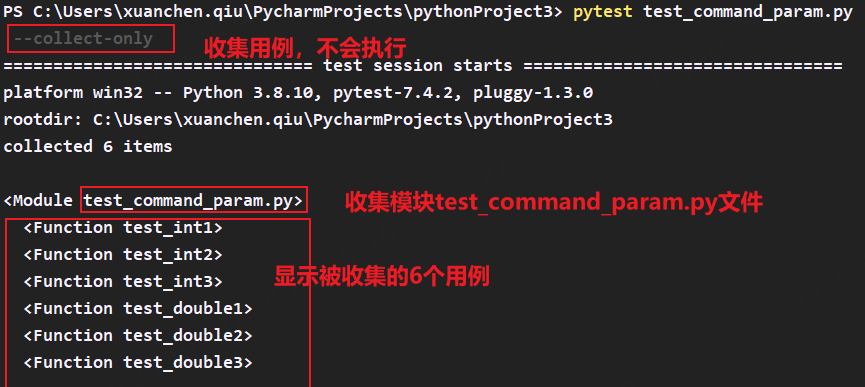
7.–collected-only 只收集用例
8.–help显示帮助
pytest --help
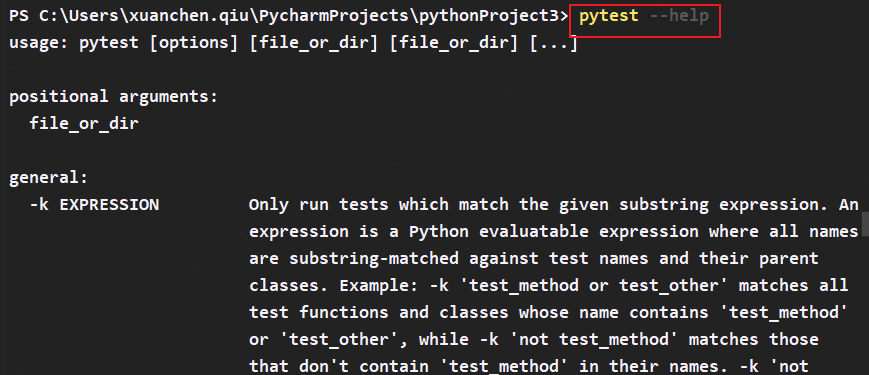
我们还可以使用过滤符grep来选择目的标签查找帮助:
pytest --help|findstr 标签 # windows的过滤关键字为findstr
pytest --help|grep 标签 # linux和mac系统
使用help来查找mark帮助文档:
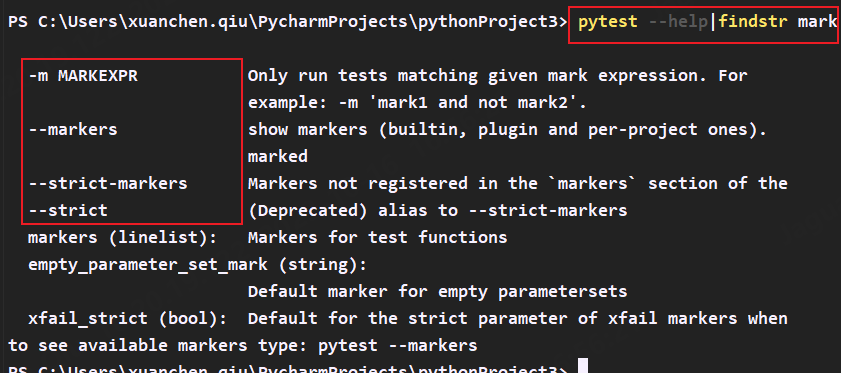
9.–lf(–last-failed) 只执行上次失败的用例

我们先执行一条失败的用例
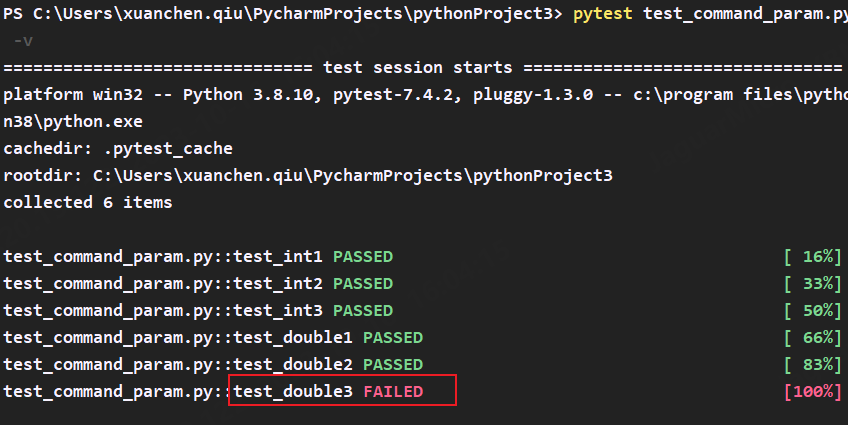
然后使用命令–lf -v,发现只执行了上次失败的那条用例test_double3

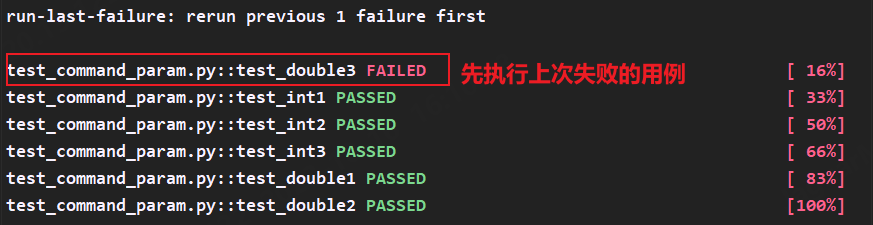
10.–ff(–failed-first) 先执行上次失败的用例,再执行剩余的用例
11.-n X 使用X个进程,并行化执行用例
(1核执行时间为10s,两核执行时间缩短一半5s),-n auto 自动选择进程数执行用例(取决于你的电脑cpu,四核n=4 8核n=8)
pytest多进程/多线程执行测试用例 - 网名余先生 - 博客园 (cnblogs.com)
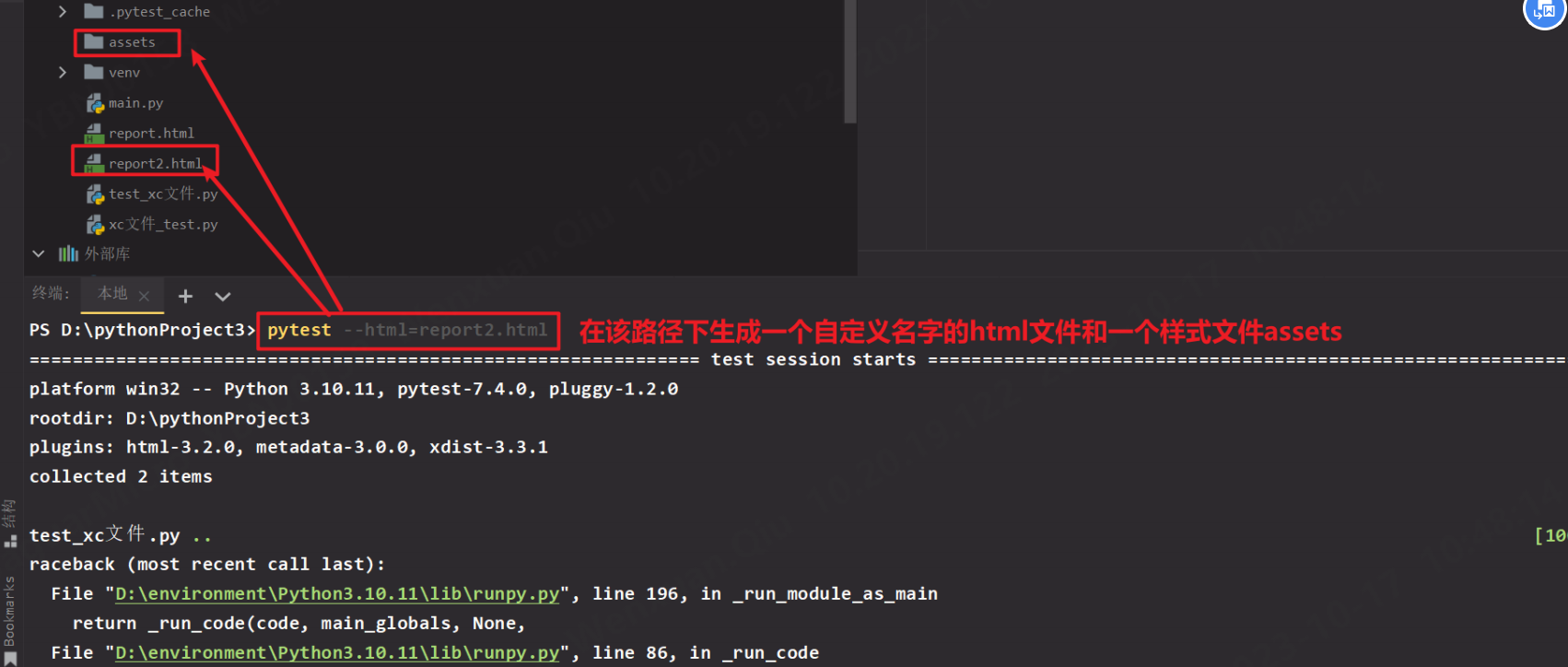
12.–html=Path 生成HTML测试报告和一个样式文件
–html=Path 生成HTML测试报告和一个样式文件,并保存在Path路径下
–html=Path --self-contained-html HTML文件自包含样式文件,只会生成一个HTML文件
6、pytest.ini配置化文件
在执行测试用例时会先执行pytest.ini配置文件,我们可以把所有的命令都统一放在pytest.ini文件进行配置,当执行命令pytest时候,会先自动加载pytest.ini文件并执行里面的配置
[pytest]
addopts = -v -s -n 1 --html=report.html --self-contained-html
下次执行直接使用pytest命令,系统自动加载pytest.ini配置文件里的命令,无需在命令行中额外加命令
7、Mark标签

1.Mark.标签名 设置标签组
首先我们要再测试用例上使用解释器定义mark标签
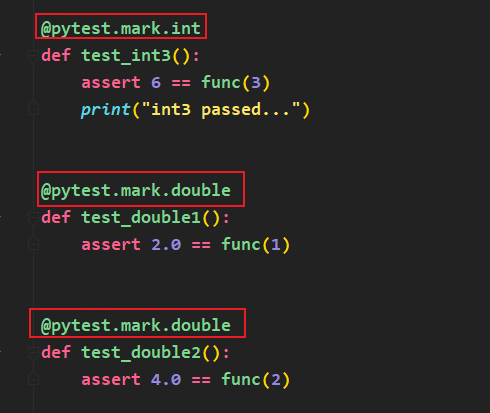
然后,再使用-m标签进行标签选择执行,有三种选择方式都可
-m=double
-m double
-m "double"
-m 'double'
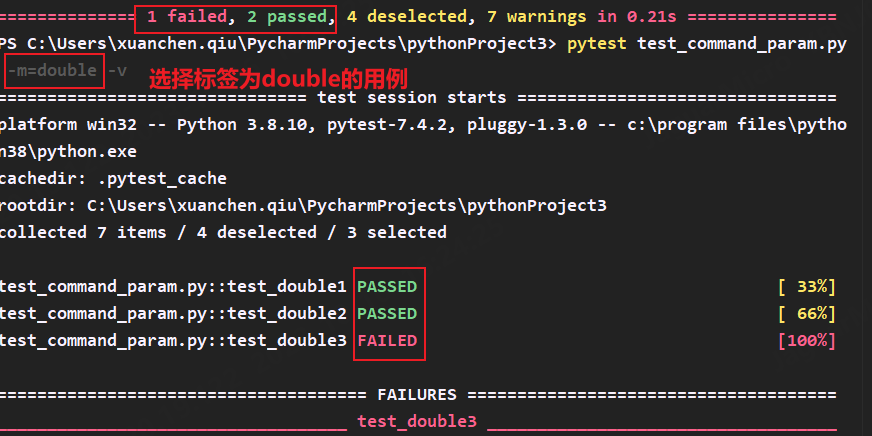
另外,以上都是我们自定义的一个标记,pytest识别不出会给我们抛出警告,并不影响运行

我们可以在pytest.ini配置文件中配置标签名,这样pytest就能自动识别出我们的标签不会给警告了
在pytest.ini配置标签名
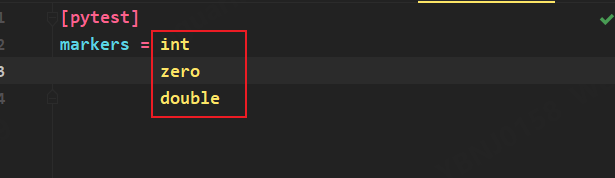
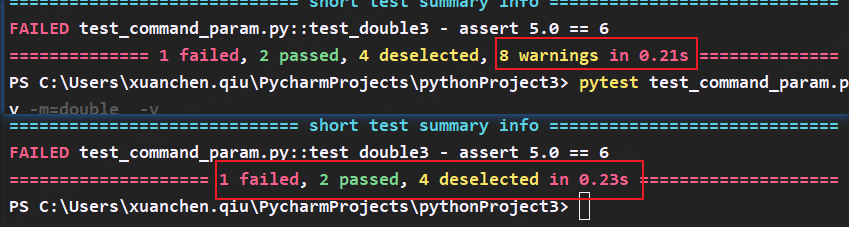
再执行用例发现不再报警告
2.自定义mark
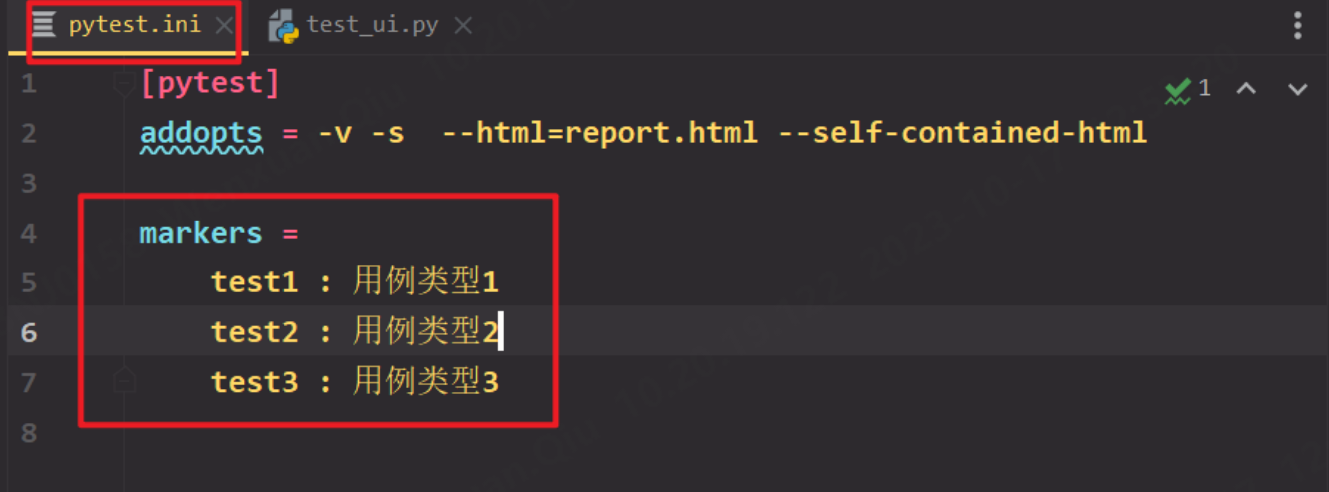
mark首先在pytest.ini配置文件里面定义,才可以使用
定义mark配置信息:将mark自定义分为三类:test1、test2、test3,
即markers = 类型名 : 类型注释
你可以用mark标记不同的测试用例,通过 pytest -m 类型名 筛选需要执行哪类测试用例
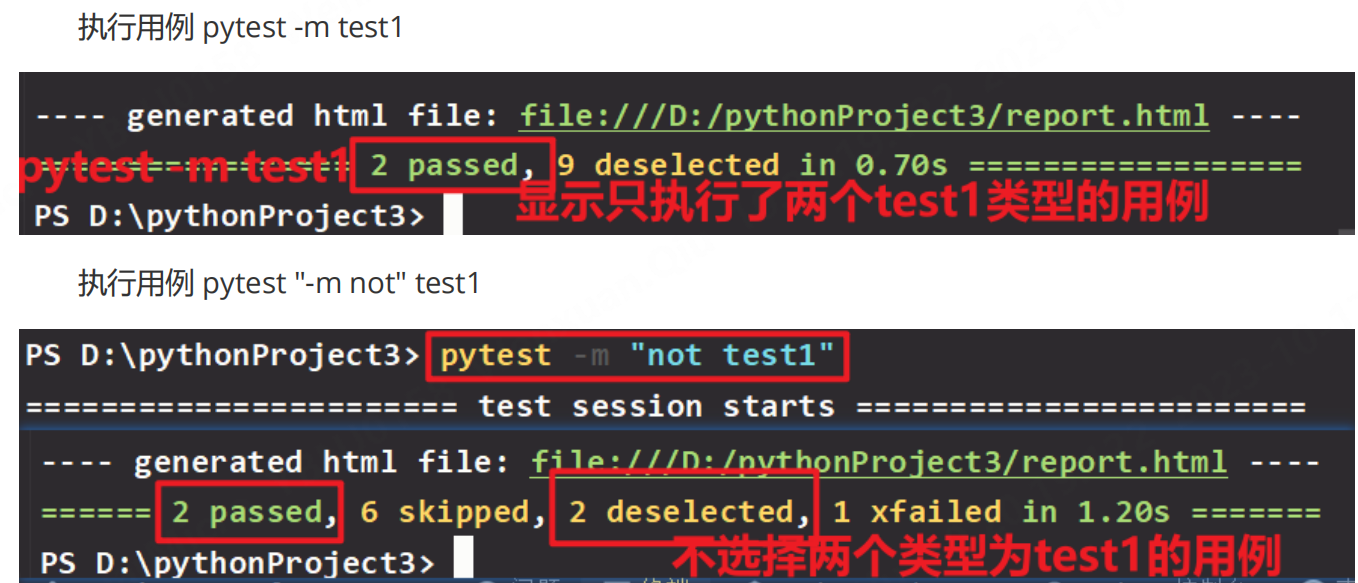
- 选择这类测试用例: pytest -m 类型名
- 不选择这类测试用例: pytest “-m not” 类型名 由于not会当成类型名,因此我们要用” “包裹
执行标签用例
3.Mark.skip 跳过测试用例

使用场景

方法1:添加装饰器:
@pytest.mark.skip 为方法级别的跳过,也可以用作类级别的跳过
@pytest.mark.skipif 为方法级别的跳过,也可以用作类级别的跳过
方法2:代码中添加跳过后面的代码
pytest.skip(reason)
3.1 skip跳过
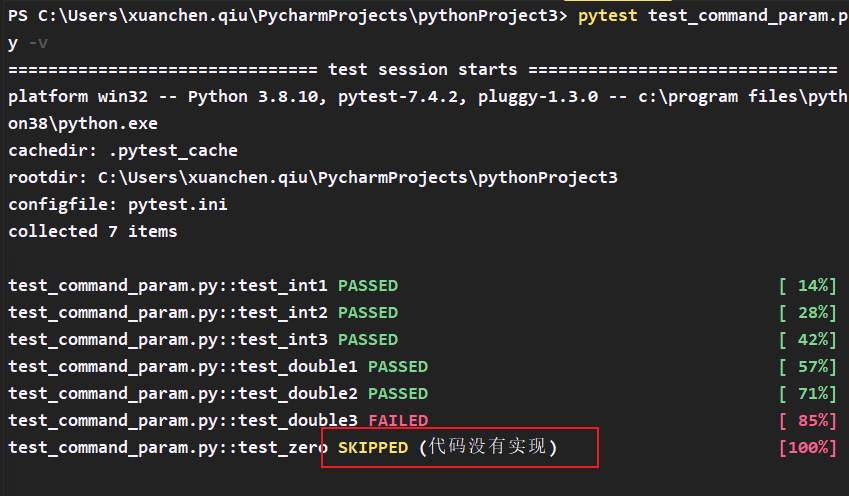
@pytest.mark.skip(reason="代码没有实现") # 在用例前面添加skip装饰器,reason上输出跳过提示
def test_zero():
assert 0 == func(0)
3.2 skipif代码跳过
# skipif的用法
@pytest.mark.skipif(条件表达式, reason="")
# 当条件表达式返回True时,会跳过用例
@pytest.mark.skipif(1 == 1,reason='满足条件跳过此用例') # 跳过用例并输出reason信息
def test_pytest_1():
print('case4')
@pytest.mark.skipif(1 == 2,reason='不满足条件不会跳过此用例')
def test_pytest_2():
print('case5')
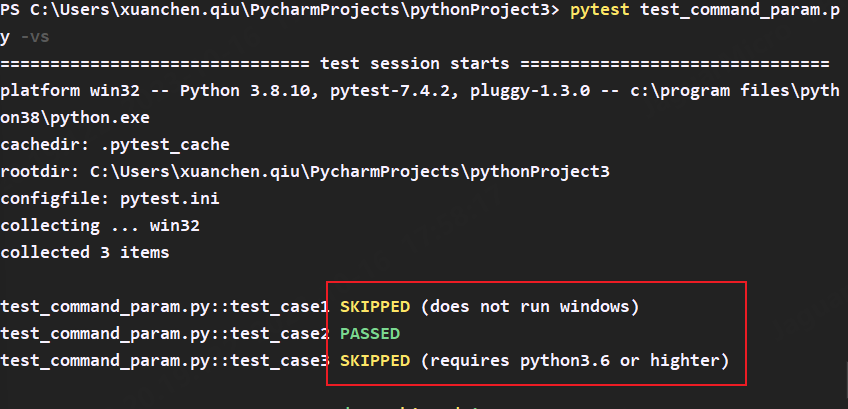
实例,当平台操作系统为win,且python版本高于3.6时跳过用例
print(sys.platform) # 输出操作系统平台 win为windows,darwin为mac
# 判断如果为win操作系统,跳过该用例并输出信息
@pytest.mark.skipif(sys.platform == 'win32', reason="does not run windows")
def test_case1():
assert True
# 判断如果为mac操作系统,跳过该用例并输出信息
@pytest.mark.skipif(sys.platform == 'darwin', reason="does not run mac")
def test_case2():
assert True
# 判断python版本信息小于3.6,跳过用例给出信息
@pytest.mark.skipif(sys.version_info < (3, 6), reason="requires python3.6 or lower")
def test_case3():
assert True
3.3 skip代码内判断跳过
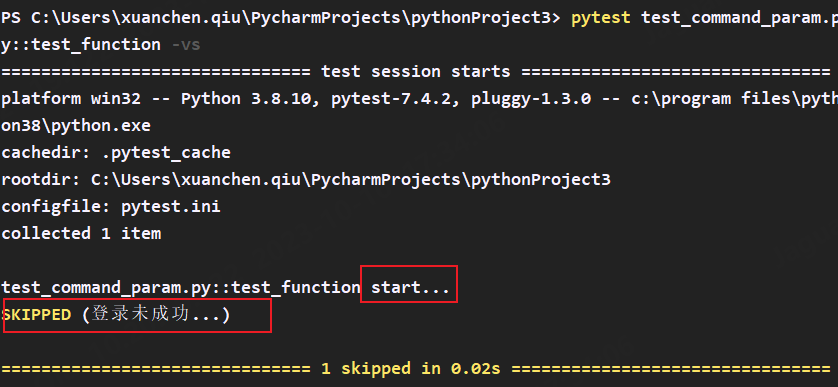
创建一个检查登录方法,和一个测试方法
def check_login(): # 检查登录方法
return False
def test_function(): # 测试方法
print("start...")
if not check_login(): # 如果登录不成功,跳过后续步骤,并返回reason信息
pytest.skip("登录未成功...") # 用代码实现步骤跳过
print("end...")
执行测试用例:当if判断错误时调用pytest.skip跳过后续代码,并输出跳过reason
4.Mark.xfail 标签
期望测试用例为失败并标记,失败不会影响其他测试用例执行

xfail相比较于skip来说,虽然使用的格式类似,但是xfail不会跳过用例而是执行测试用例,成功输出xpass,失败输出xfail
xfail相比于skip,reason任何时候都会输出
# 用法1:加上装饰器@pytest.mark.xfail
@pytest.mark.xfail(reason="bug case1")
def test_case1():
print("test_xfail1方法执行...")
assert 1 == 2
# 我们也可以定义xfail变量为pytest.mark.xfail,下次调用直接使用@xfail便捷调用
xfail = pytest.mark.xfail
@xfail(reason="bug case2")
def test_case2():
print("test_xfail方法执行...")
assert 1 == 1

xfail内部代码跳过,与skip跳过不同的是,xfail没有判断条件,执行完xfail无论如何都会跳过后面的代码
def test_xfail():
print("*****开始测试*****")
pytest.xfail(reason="该功能尚未完成") # xfail在代码内会暂停继续执行下面的代码
print("测试过程")
assert 1 == 1

5.Mark标签的参数传递
@pytest.mark.parametrize标签具有给测试用例传递参数的作用,如:
@pytest.mark.parametrize('username,password,result', [('qwx13057573527', 'qwx#125617', 'qwx13057573527'),('qwx', 'qwx#125617', '用户名错误'),('qwx13057573527', 'qwx', '密码错误')],ids=('test_login_001', 'test_login_002', 'test_login_003'))
def test_login(username, password, result, open_page):
mark.parametrize标签传递的参数如username,password,result都会一一传入测试用例的参数username,password,result当中。ids表示测试用例的名称。
当你使用 pytest.mark.parametrize 并传入多个参数时,pytest 会自动遍历并匹配它们的元素。如果你传递的 login_success_data 和 login_ids 的长度相等且元素顺序一一对应,pytest 会在运行测试时,将它们按对应的顺序进行匹配。且每组测试数据都会跑一次用例。
将以上的案例的测试数据封装在类当中,如下所示
class LoginData(object):
"""用户登录测试数据"""
login_success_data = [("qwx13057573527", "qwx#125617", "qwx13057573527")]
封装之后再调用测试数据如下
class TestLogin(object):
"""登录用例"""
login_data = LoginData()
@pytest.mark.parametrize(
"username, password, expect", login_data.login_success_data,ids=LoginData.login_ids
)
def test_login_success(self, ini_page, username, password, expect):
login_page = ini_page
login_page.login(username, password)
account = login_page.get_account_text()
assert expect in account
7、Fixture
fixture是pytest中特殊的一部分,也是必须掌握的核心用法
fixture的作用是: 使测试用例执行更加可靠,结果也更加稳定 可以称之为软件测试的装置、夹具、脚手架,作用和目的: 将多个用例里面的重复部分提取到fixture方法内 ,因此很适合用来做自动化准备测试环境,参数化多个测试用例的数据
作用:
1. 在测试用例执行之前,自动化准备相关的测试环境
2. 在测试执行之后,将相关内容进行销毁
1.fixture案例
案例:断言"百度",“阿里”,"腾讯"网站标题是否包含关键字

访问baidu.com,标题中应该有"百度"
-
- 打开浏览器
- 输入https://baidu.com
- 获取标题
- 断言"百度"出现在标题当中
""" -打开浏览器 -输入https://baidu.com -获取标题 -断言“百度”出现在标题中 :return: """
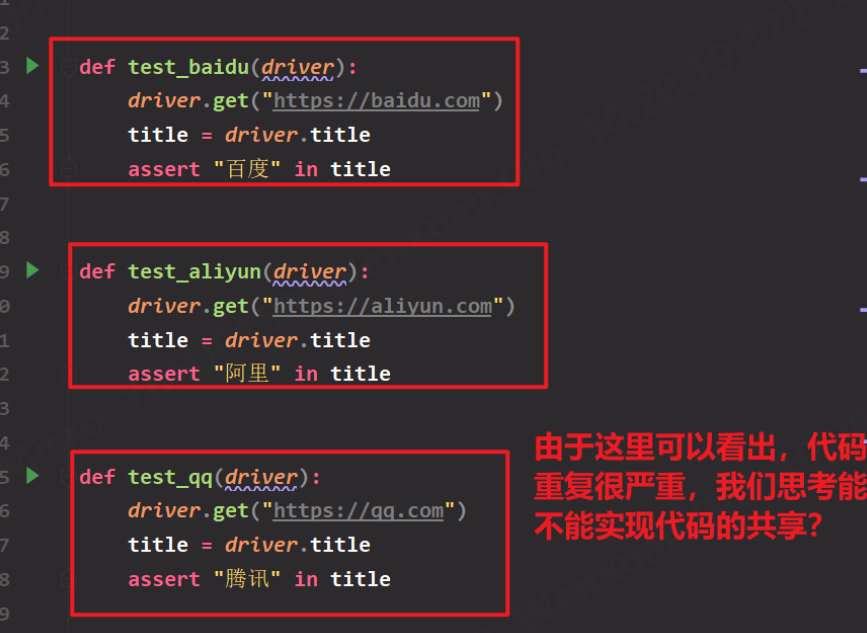
def test_baidu():
# 自动安装webdriver
_path = ChromeDriverManager(url="https://npm.taobao.org/mirrors/chromedriver").install()
# 启动浏览器
driver = webdriver.Chrome(service=Service(_path))
# 输入网址
driver.get("https://baidu.com")
# 获取标题
title = driver.title
# 断言标题
assert "百度" in title
def test_aliyun():
# 自动安装webdriver
_path = ChromeDriverManager(url="https://npm.taobao.org/mirrors/chromedriver").install()
# 启动浏览器
driver = webdriver.Chrome(service=Service(_path))
# 输入网址
driver.get("https://aliyun.com")
# 获取标题
title = driver.title
# 断言标题
assert "阿里" in title
def test_qq():
# 自动安装webdriver
_path = ChromeDriverManager(url="https://npm.taobao.org/mirrors/chromedriver").install()
# 启动浏览器
driver = webdriver.Chrome(service=Service(_path))
# 输入网址
driver.get("https://qq.com") # 获取标题
title = driver.title # 断言标题
assert "腾讯" in title
由于我们写的案例目的是断言网站标题含有目的文字,而打开浏览器等操作不属于我们设计用例的一部分,属于测试用例的准备工作。
- 对于 测试用例的准备工作 ,挪出测试用例代码
- 对于重复性的代码, 使用函数进行重用
- 这样的工作应该交给 fixture 完成
我们可以使用装饰器 @pytest.fixture 创建一个fixture方法
import pytest
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
@pytest.fixture # 定义一个fixture夹具名driver
def driver():
_path = ChromeDriverManager().install() # 自动安装webdriver
return webdriver.Chrome(service=Service(_path)) # 启动浏览器
def test_baidu(driver): # 将fixture夹具名传入测试用例
driver.get("https://baidu.com")
title = driver.title
assert "百度" in title
def test_aliyun(driver): # 将fixture方法传入函数
driver.get("https://aliyun.com")
title = driver.title
assert "阿里" in title
def test_qq(driver): # 将fixture方法传入函数
driver.get("https://qq.com")
title = driver.title
assert "腾讯" in title
以上的网站都是打开之后关闭再打开,所有的用例之间fixture不能共用,我们可以创建一个fixture完成浏览器启动的共用。
2.fixture范围
我们可以在创建fixture夹具装饰器的时候添加一个范围
@pytest.fixture(scope='session') # fixture范围为一个会话
fixture范围:
1. function:同一个函数中的测试用例**(最小/默认值)**
2. class:同一个类中的测试用例
3. module:同一个模块(文件)中的测试用例
4. package:同一个包(文件夹)中的测试用例
5. session:整个测试活动**(最大)**
3.fixture参数 request
fixture标签参数autouse=True 表示在该fixture影响范围内每个测试函数都无需显示调用便可使用这个fixture,如实现失败截图的fixture。
@pytest.fixture(scope="function", autouse=True)
def screenshot_on_failure(request, driver):
"""在测试失败时自动截图"""
yield # 继续执行测试
if request.node.rep_call.failed: # 检查测试是否失败
timestamp = time.strftime("%Y%m%d_%H%M%S")
test_name = request.node.name
screenshot_path = f"screenshots/{test_name}_{timestamp}.png"
driver.save_screenshot(screenshot_path)
print(f"截图已保存: {screenshot_path}")
scope="function" 和 autouse=True 是 pytest 中 fixture 的两个不同参数,它们分别用于不同的目的,并不会冲突。scope="function", autouse=True表示在每个测试用例的函数级别都会显示调用screenshot_on_failure方法
request参数是pytest当中的一个特殊对象,提供对测试上下文和测试执行信息的访问,如通过 request 对象,你可以获取测试函数的元数据、访问当前的测试用例名称、控制测试执行过程、动态添加清理操作等。request.node.rep_call.failed用于获取测试是否失败
autouse=True 允许 pytest 在每个测试执行时自动调用该 fixture,但它只会自动执行和应用其中的副作用(如执行一些初始化或清理工作),而不会将返回值自动注入到测试用例中。
如果 fixture 有返回值,并且你想在测试用例中使用这个返回值(比如 ValidationHandler 对象),你仍然需要通过测试函数的参数来显式传递它。
@pytest.fixture(scope="class", autouse=True)
def validator():
# 该 fixture 将返回 ValidationHandler 对象
return ValidationHandler()
def test_example_case(validator: ValidationHandler):
# 显式传入 validator
response = requests.Response() # 假设这是某个请求返回的响应
validation_data = {"access_token": "some_value"}
# 使用 validator 的方法
validator.validate_response(response, validation_data)
访问测试函数名称: 你可以通过 request.node.name 获取当前测试函数的名称,在日志记录或截图文件命名时使用。
def screenshot_on_failure(request, driver):
test_name = request.node.name # 获取当前测试函数的名称
print(f"当前测试用例: {test_name}")
访问测试结果: request.node 对象中包含了 rep_call,它提供了测试的执行结果,尤其是在需要判断测试是否失败时很有用。
request.node.rep_call.outcome:表示测试的执行结果('passed'、'failed'或'skipped')。request.node.rep_call.failed:一个布尔值,表示测试是否失败。
def screenshot_on_failure(request, driver):
yield
if request.node.rep_call.failed:
print("测试失败,将截图。")
# 截图逻辑...
访问 fixture 参数: 如果你有带参数的 fixture,request.param 可以用来访问传入的参数值。
@pytest.fixture(params=["chrome", "firefox"])
def driver(request):
if request.param == "chrome":
driver = webdriver.Chrome()
elif request.param == "firefox":
driver = webdriver.Firefox()
return driver
request 对象的属性
-
request.node: 代表当前测试函数的节点,提供了对测试函数的名称、所属模块、类等信息的访问。 -
request.cls: 如果测试在类中定义,可以通过request.cls访问当前测试类。 -
request.function: 访问当前正在执行的测试函数。 -
request.module: 访问当前测试所在的模块。 -
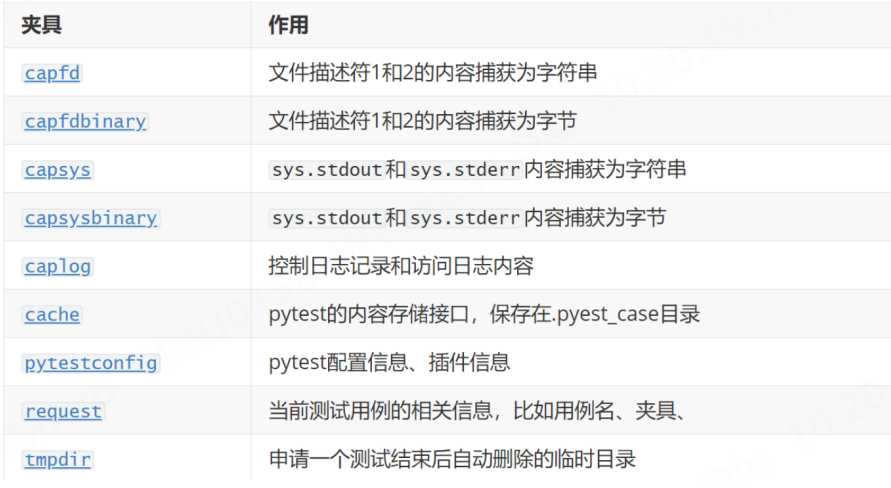
request.session: 访问测试会话对象,包含整个测试运行的信息。3.内置fixture
8、conftest.py和pytest.ini
1.conftest.py
configtest.py文件是定义在pytest全局下的python文件,用于定义全局fixture和一些钩子函数,常量,配置测试环境等
-
pytest会在fixture被第一次调用时才初始化,fixture可以自定义在fixture文件夹内,如scope=“session”表示全局fixture会在执行测试用例前调用,一般定义在configtest.py内(直接将fixture定义在configtest.py内而不需要显示的调用)@pytest.fixture(scope="class") def login(logger): """初始化Chrome浏览器驱动""" chrome_options = webdriver.ChromeOptions() chrome_options.add_argument("--incognito") # 启用隐私模式 driver = webdriver.Chrome(options=chrome_options) # 登录网易163浏览器 driver.get(ENV.url) logger.info("启用隐私模式打开浏览器") driver.maximize_window() logger.info("最大化窗口") driver.implicitly_wait(20) logger.info("设置隐式等待时间为20s") yield driver driver.quit() logger.info("关闭浏览器") -
可以在
conftest.py中定义全局的setup和teardown操作@pytest.fixture(scope="session", autouse=True) def setup_teardown(): print("Setup before tests") yield print("Teardown after tests") -
可以用于定义全局常量,如文件路径、环境变量等,供测试用例和其他函数使用。
-
pytest通过了一些钩子函数,通常定义在configtest.py内,常见的有自定义参数函数
pytest_addoption,初始化钩子函数pytest_configure(pytest_configure是在 整个测试会话开始之前 调用的,这意味着它比任何fixture的执行顺序要早)# 用于添加自定义命令行选项,允许用户在运行测试时指定额外的参数 def pytest_addoption(parser): # config参数由pytest自动传入 parser.addoption("--env", action="store", default="dev", help="Specify environment: dev, test, or prod") def pytest_configure(config): # config参数由pytest自动传入 # 在 pytest 开始执行测试之前,调用自定义的初始化函数 custom_initialization()
2.pytest.ini
pytest.ini 是配置 pytest 的重要工具,通过它可以全局设置测试的行为、日志管理、路径和标记等。它帮助开发者减少在命令行中重复输入参数,提高测试的自动化和管理效率。
-
简化命令行参数:通过
addopts设置默认命令行选项,避免每次执行pytest时重复输入相同参数。[pytest] addopts = -vs --alluredir=report/TestReport/ -
指定测试路径:使用
testpaths指定默认的测试文件目录,方便测试文件的管理。[pytest] testpaths = tests -
定义标记:通过
markers定义自定义标记,便于分类和过滤测试用例。[pytest] markers = smoke: 标记烟雾测试 regression: 标记回归测试 -
控制日志输出:可以设置日志的输出级别和输出方式,如将日志输出到文件或控制台。
-
过滤警告:使用
filterwarnings配置忽略特定的警告信息。 -
设置文件和类的命名规则:通过
python_files、python_classes和python_functions指定哪些文件、类和函数被视为测试用例。
9、参数化和数据驱动
在实现参数化之前我们先来了解一下什么是数据驱动
数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。
简单来说,就是参数化的应用,数据量小的测试用例可以使用代码的参数化来实现数据驱动,数据量大的情况可以使用结构化文件(cvs、yaml、json等)对数据进行存储和在测试用例中进行读取。
CSV(逗号分隔值)文件是一种简单的文本格式,用于存储表格数据,如数字和文本。CSV文件由纯文本组成,每行一个数据记录。每个记录由字段组成,字段之间通常由逗号分隔。这种格式通常用于表示表格数据(比如数据库、电子表格)。
一个典型的CSV文件可能看起来是这样的:
Copy codeColumn1,Column2,Column3
Data1,Data2,Data3
Data4,Data5,Data6
在这个示例中:
- 第一行是标题行,包含每列的名称。
- 随后的每一行代表一条记录。
- 每一行中的每个值(字段)用逗号分隔。
CSV文件的关键特性包括:
- 简单性:它们是纯文本文件,可以由任何文本编辑器查看和编辑。
- 通用性:几乎所有的表格处理软件都能识别和处理CSV文件,例如Microsoft Excel、Google Sheets和各种编程语言的库。
- 灵活性:尽管“CSV”代表逗号分隔值,但实际上可以使用其他字符作为分隔符,如制表符(生成所谓的TSV文件)或分号。
根据您的应用程序和地区设置,CSV文件的确切格式可能略有不同。例如,在一些欧洲地区,分号(;)而不是逗号(,)用作字段分隔符,因为逗号已用作小数点。
CSV文件格式
优点:
1. **简单性和可读性**: CSV文件结构简单,易于理解和编辑,即使是非技术人员也能轻松使用。
2. **广泛支持**: 几乎所有编程语言和数据处理工具都支持CSV格式,无需特殊的解析库。
3. **高效处理大量数据**: 对于大量的行式数据,CSV可以高效处理。
缺点:
1. **结构限制**: CSV不适合复杂的数据结构。它难以表示层次化或嵌套的数据。
2. **缺乏类型信息**: CSV中的所有数据都是文本格式,需要在解析时进行类型转换。
3. **标准不一致**: CSV的格式(如分隔符)可能因地区和用户而异,这可能导致解析问题。
JSON文件格式
优点:
1. **灵活的数据结构**: JSON能够轻松表示嵌套或层次化的数据结构,适合复杂的数据需求。
2. **数据类型识别**: JSON支持基本的数据类型(如数字、字符串、布尔值),因此数据类型在解析时保持不变。
3. **易于解析**: 许多编程语言提供了原生的JSON解析支持,使得读取和写入JSON数据变得简单。
缺点:
1. **文件大小**: 对于同样的数据,JSON文件通常比CSV文件大,因为它包含更多的格式化文本(如键名和括号)。
2. **解析成本**: 解析JSON通常比解析CSV更耗费资源,尤其是在大文件的情况下。
3. **可读性**: 对于非技术人员来说,复杂的JSON结构可能不如CSV那样直观易读。
而参数化的设计方法就是将模型中的定量信息变量化,使之成为任意调整的参数。对于变量化参数赋予不同的数值,就可以得到不同的模型。
参数化可以分为mark标签参数化和fixture参数化
1.mark参数化
mark参数化一般是使用mark.parametrize()进行传参
- 单参数
- 多参数
- 用例重命名
- 笛卡尔积
@pytest.mark.parametrize('参数1,参数2...', [列表1/元组1,列表2/元组2...]) # 参数与数值要一一对应,如果需要传递多个参数,要放在列表当中嵌套列表/元组
def func(参数1,参数2...) # 形参与参数化的参数要一一对应
1.1 单参数化
由于search_list是一个列表有三个单参数,因此会生成三条用例

1.2 多参数化
多参数化相对于单参数,解释器参数传入多个,值需要传入列表-列表嵌套或列表-元组嵌套
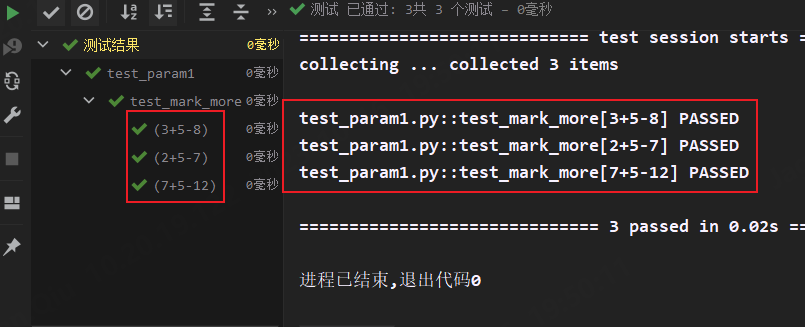
@pytest.mark.parametrize("test_input,expected", [("3+5", 8), ("2+5", 7), ("7+5", 12)]) # 传多个参数,数值里列表需要再嵌套列表/元组
def test_mark_more(test_input, expected): # 形参与参数一一对应,参数与列表值一一对应
assert eval(test_input) == expected # eval()方法,将字符串转换成无字符串的表达式,如"3+5"转化成3+5并执行
多参数化mark.parametrize(参数…,值),格式比较宽松
@pytest.mark.parametrize("test_input,expected", [("3+5", 8), ("2+5", 7), ("7+5", 12)]) # 使用一个字符串包裹多个参数,值用列表-元组嵌套
@pytest.mark.parametrize("test_input","expected", [("3+5", 8), ("2+5", 7), ("7+5", 12)]) # 使用多个字符串表示参数,值用列表-元组嵌套
@pytest.mark.parametrize("test_input,expected", [["3+5", 8], ["2+5", 7], ["7+5", 12]]) # 使用一个字符串包裹多个参数,值用列表-列表嵌套

1.3 参数重命名
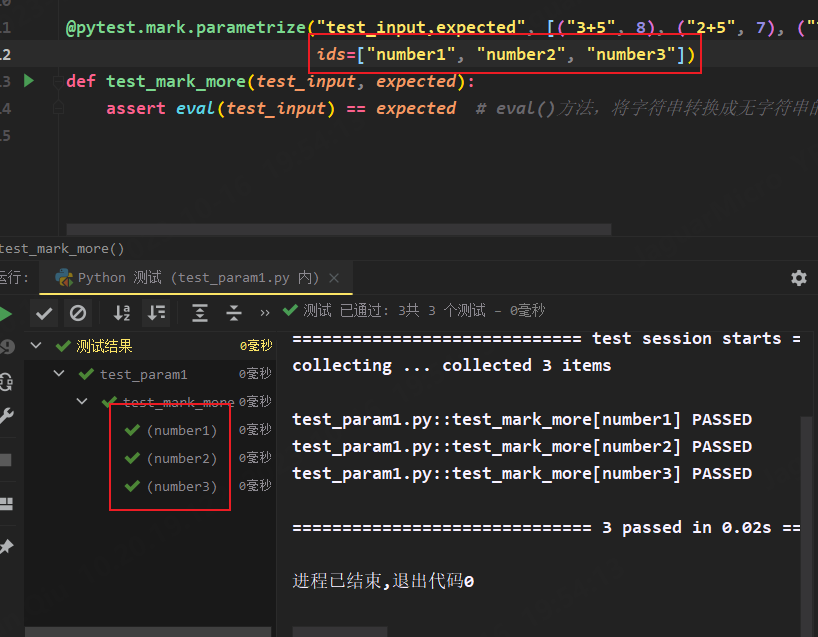
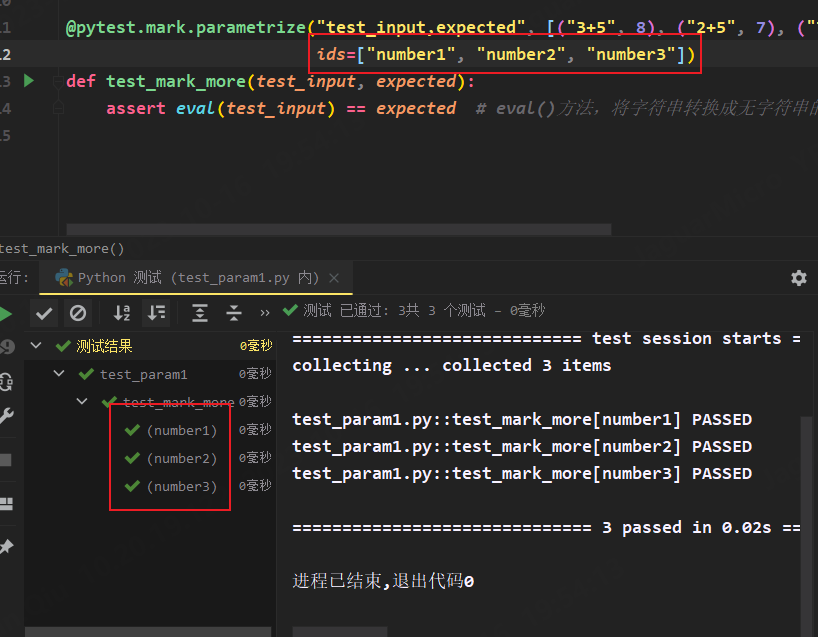
我们运行以上例子时,发现参数化的默认测试用例命名是以参数的值来命名的,不具有理解性,我们可以使用ids对参数化的用例进行命名,其中ids个数与传递的数据个数要完全一致
@pytest.mark.parametrize("test_input,expected", [("3+5", 8), ("2+5", 7), ("7+5", 12)],
ids=["number1", "number2", "number3"])
def test_mark_more(test_input, expected):
assert eval(test_input) == expected # eval()方法,将字符串转换成无字符串的表达式,如"3+5"转化成3+5并执行
命名之后运行
1.4 笛卡尔积
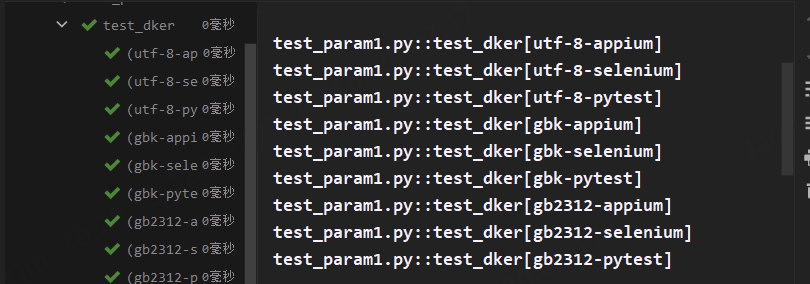
两个解释器参数化一起出现在一个用例上时,系统将对其进行笛卡尔积传递参数

@pytest.mark.parametrize('wd', ['appium', 'selenium', 'pytest'])
@pytest.mark.parametrize('code', ['utf-8', 'gbk', 'gb2312'])
def test_dker(wd, code):
print(f"wd:{wd},code:{code}")
2.fixture实现参数化
测试代码的共享我们采用数据驱动的方式实现
数据驱动=数据局管理+参数化测试
接着以上的案例,我们可以发现代码重复很严重
参数化测试: 一份代码,传递参数执行多个用例
fixture支持参数化,于是可以进行参数化测试
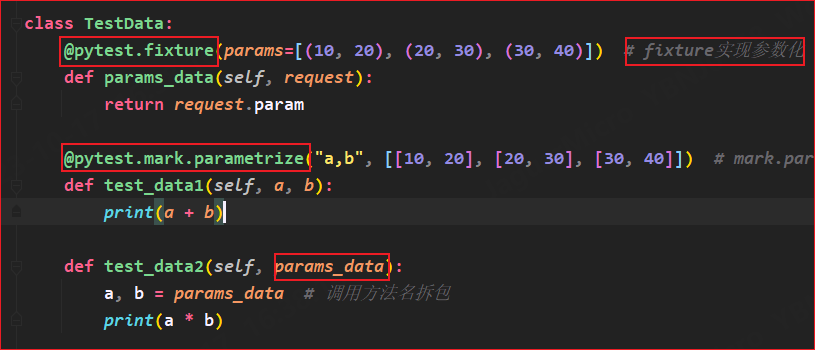
@pytest.fixture(
params=[("https://baidu.com", "百度"),
("https://aliyun.com", "阿里"),
("https://qq.com", "腾讯")])
def test_data(request):
return request.param # 将参数化的参数返回给测试用例
def test_ceshi(driver, test_data):
url, tit = test_data # 拆包
driver.get(url)
title = driver.title
assert tit in title
创建一个夹具test_data用于返回参数param,将参数化数据存放在fixture关键字params内,夹具test_data使用request关键字接收

测试类使用fixture传入参数,当fixture的params为多参数时,需要对传入参数进行拆包;
这种通过将@pytest.fixture函数传递给测试方法的方式称为`pytest依赖注入`
简单实例:
```python
@pytest.fixture
def driver():
"""初始化浏览器驱动"""
driver = webdriver.Chrome()
yield driver
driver.quit()
def test_example(driver):
# `driver` 参数在调用时由 pytest 提供,并由 `driver` fixture 返回的实例赋值
driver.get("https://www.example.com")
assert "Example Domain" in driver.title
以上函数当中driver()会返回一个webdriver对象,将driver传入到test_example()方法当中,相当于给test_example()方法内所有的driver注入webdriver对象,具体实现步骤如下:
- 当 Pytest 运行
test_01_Check_autopatch_devices_monitor_view()时,它会检查函数的参数。 - 发现
driver这个参数时,Pytest 会去寻找一个名为driver的fixture,然后执行这个fixture的函数。 - 执行完
fixture后,Pytest 会将fixture的返回值(即在这里是初始化好的浏览器驱动实例driver)传递给测试函数test_01_Check_autopatch_devices_monitor_view()中的driver参数。
3.fixture传参和mark传参的区别
1.fixture是在fixture方法内直接传参,而mark是使用mark.parametrize关键字传参
2.fixture是一个全局方法,其他测试方法只需要调用fixture就可以使用参数化;而mark标签只定义在测试方法上,只能对某一测试用例参数化
3.多参数传值可以使用元组或列表,使用fixture传值需要拆包
4.yaml数据参数化
4.1 yaml实现list
list
- 10
- 20
- 30
4.2 yaml实现dict
dict
by:id
locator:name
action:click
4.3 yaml嵌套
列表字典嵌套:
-
- by:id
- locator:name
-action:click
对象列表字典嵌套:对象companiens:[{id:1,name:company1,price:200w},{id:2,name:company2,price:500w}]
companiens
-
id:1
name:company1
price:200w
-
id:2
name:company2
price:500w
4.4 加载yaml文件
# yaml文件加载
yaml.safe_load(open("./data.yaml"))
# pytest与yaml连用
@pytest.mark.parametrize(["a", "b"], yaml.safe_load(open("./data.yaml")))
def test_param(self, a, b):
print(a + b)
4.5 导入yaml文件参数化传递数据
首先,我们先下载yaml插件
pip install pyyaml
也可以在python包中直接导入
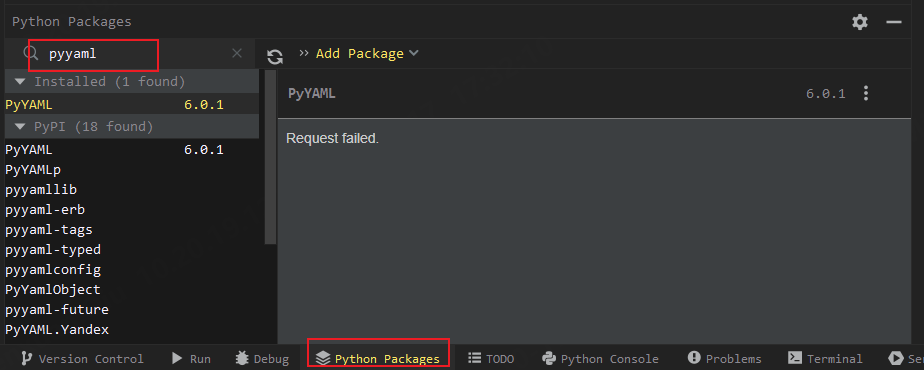
在项目里创建一个.yaml文件,使用yaml语法在文件中写好数据
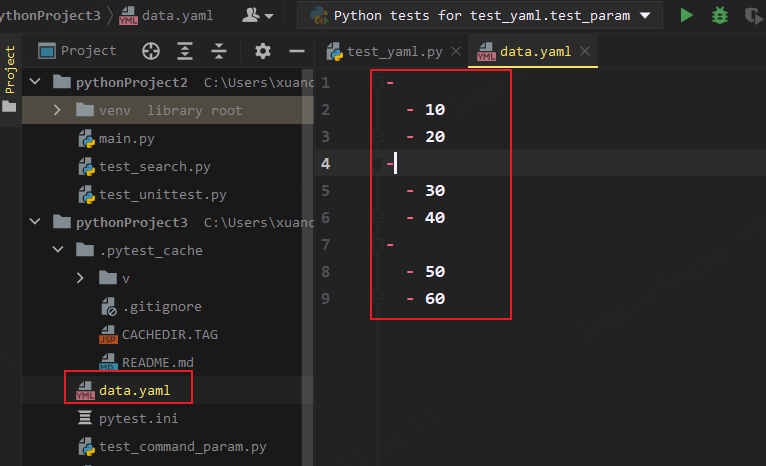
然后在测试类当中传入yaml文件路径,加载yaml文件
import pytest
import yaml
@pytest.mark.parametrize(["a", "b"], yaml.safe_load(open("./data.yaml"))) # 传入yaml文件路径并加载
def test_param(a, b):
print(a + b)
4.6 yaml数据驱动案例
首先创建一个env.yml文件,内容为dict类型如下:
test: 127.0.0.1
在用例中我们引入env.yml文件判断文件内容
@pytest.mark.parametrize("env", yaml.safe_load(open("env.yml")))
def test_yaml(env):
if "test" in env:
print("这是测试环境")
elif "dev" in env:
print("这是开发环境")
print(env) # 只输出key值 test
输出结果:这是测试环境
test
输出env.yml全部内容
def test_case1(self):
print(yaml.safe_load(open("env.yml"))) # test: 127.0.0.1
以上代码只读取到了key值test,而使用print(yaml.safe_load(open("env.yml")))打印输出的却是全部值,由此发现我们使用一个参数env读取dict类型yml文件时@pytest.mark.parametrize("env", yaml.safe_load(open("env.yml")))只能读取到第一个key值。
为了让我们能够读取dict类型的yml文件,我们可以在yml文件中使用列表包裹key-value,如下
-
test: 127.0.0.1
这个时候执行以上代码,就可以输出整个key-value数据
输出:
{‘test’: ‘127.0.0.1’}
我们对这个代码进行升级,采用列表嵌套的方式打印value值
@pytest.mark.parametrize("env", yaml.safe_load(open("env.yml")))
def test_yaml(env):
if "test" in env:
print("这是测试环境")
print("测试环境的ip是:" + env["test"])
elif "dev" in env:
print("这是开发环境")
print("开发环境的ip是:" + env["dev"])
输出结果:
测试环境的ip是:127.0.0.1
10、request 内置fixture
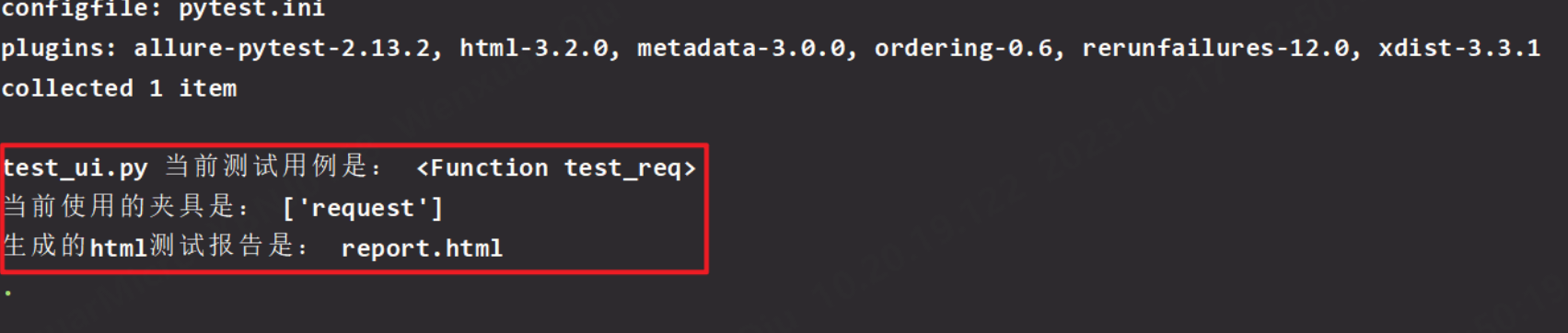
request:获取当前测试用例的相关信息
- request.node (当前测试用例名称)
- request.fixturenames (当前测试用例使用的fixture名称)
- request.config.getoption(“htmlpath”) 生成的html测试报告
11、pytest处理异常

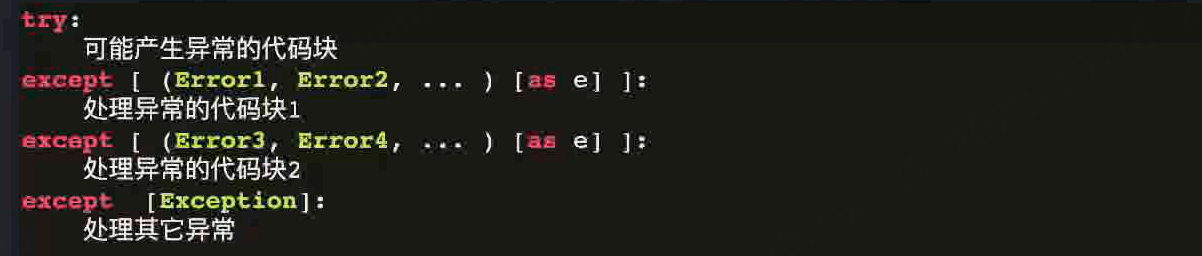
1.try…except捕获异常

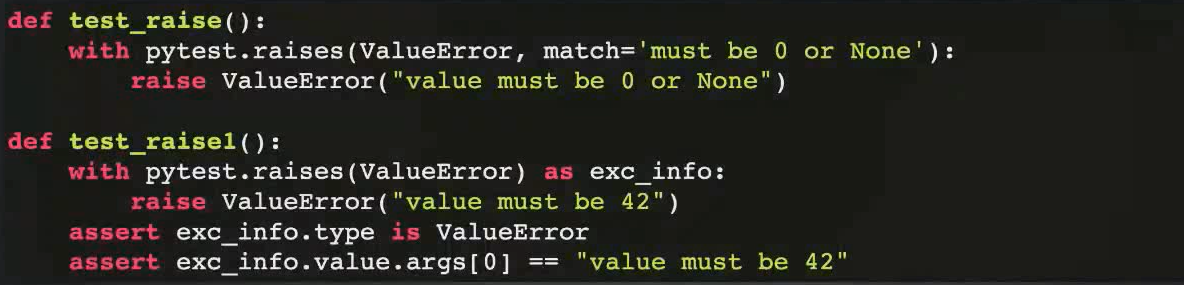
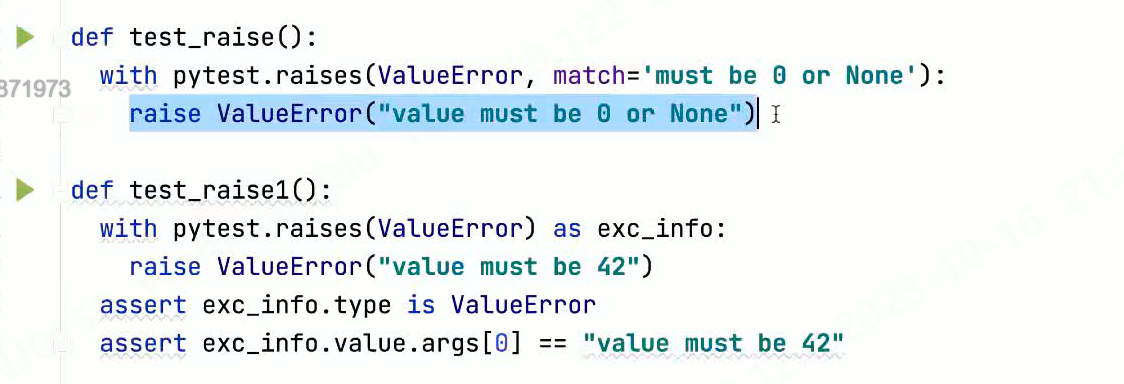
2.pytest.raise()
pytest异常处理框架pytest.raise()底层还是封装了python的try…except方法

12、pytest常见报错
1.pytest显示空套件
AttributeError: module ‘allure‘ has no attribute ‘severity_level‘
卸载allure-pytest
pip uninstall pytest-allure-adaptor
重新下载pytest-allure
pip insatll allure-pytest

一站式 AI 云服务平台
更多推荐



 48
48 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)