
【大数据存储系统搭建】一站式教你搭建大数据存储系统(适合收藏)包含Hadoop分布式集群、HBase、Hive的部署和运维。
大家好,我是摇光~全文共2w字;包含了Hadoop、HBase、Hive、HDFS的内容。教你真正理解到什么是大数据存储,如何搭建一套大数据存储系统。
前言
大家好,我是摇光~
全文共2w字;包含了对
大数据存储系统的介绍、搭建、运用的内容。
教你真正理解到什么是大数据存储,如何搭建一套大数据存储系统。
- 我是一个已经工作6年的数据工程师,主要负责就是对数据系统的搭建、数据建模、数据清洗、数据运维等工作;我觉得我是有一些经验的,嘿嘿~
- 现在我将自己所学的内容总结出来,都是一些大白话,简单易懂;整理出来给大家学习,如果有什么不对的地方,可以后台私聊我,请各位多多指教啦~
那么废话不多说,接下来我用几个问题来解释这篇文章的用途。
1、大数据存储系统是什么?
大数据通常指数量巨大、类型多样、增长迅速的数据集;大数据存储系统就是来存储和管理这些大规模的数据集系统。
2、为什么要搭建大数据存储系统?
因为大规模的数据集在传统基础设备无法进行长期保存、且处理十分困难;从而引进了大数据存储系统,大数据存储系统具备分布式存储、高可用性、高可靠性、高容错性的特点;所以我们需要搭建大数据存储系统来处理大规模的数据集。
3、常见的大数据存储系统有哪些?
- HDFS:HDFS是Hadoop生态系统中的核心组件,是Hadoop生态系统中的一个分布式文件系统,它可以将数据分块并分布到多个节点上,实现高可用性和容错能力。
- Apache HBase:HBase是一个基于HDFS的分布式、列存储的数据库,主要处理大规模结构化数据,提供高性能的随机读写访问能力。HBase特点是:高可扩展性、低延迟、强一致性。
- Apache Hive:Hive是一个基于Hadoop的数据仓库工具,用于处理和分析大规模数据集。它提供了类似SQL的查询语言,适合进行复杂的数据分析和报表生成。
- Cassandra:Cassandra是一个分布式数据库,适用于处理大量数据和高并发访问场景。它提供了高可用性和无单点故障,适合分布式系统中的大规模数据存储。
因为我们主要搭建Hadoop分布式集群,所以我们重新了解下HDFS是什么?
HDFS是一种分布式文件系统(Distributed File System,DFS)是Hadoop下的一种文件系统,其管理的物理存储资源不一定直接连接在本地节点上,而是通过网络与多个节点相连。这种系统允许多台主机上的多用户共享文件和存储空间,用户可以通过网络访问这些共享文件,就像使用本地文件系统一样。
他最大的特点就是高容错性,因为分布式文件系统具有数据复制功能,及时部分节点故障,系统也能继续运行而不会容易丢失数据。
HDFS大致框架图: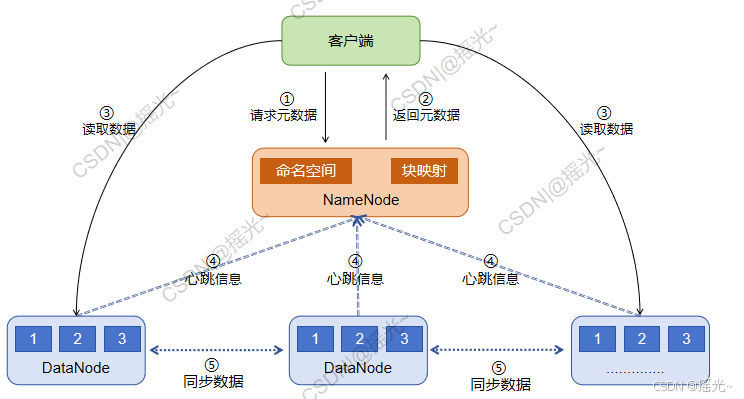
①请求元数据:客服端向NameNode发起请求,获取元数据信息,元数据信息包括命名空间、块映射信息及DataNode的位置
②返回元数据:NameNode根据请求,返回元数据信息。
③读取数据:客户端根据得到的元数据信息,到 DataNode 上读/写信息
④心跳信息:DataNode会定期向NameNode发送心跳信息,将自身节点的信息传递给 NameNode
⑤同步数据:相互关联的 DataNode之间会复制数据,以达到数据复制
上面三个问题,我相信大家应该都知道什么是大数据存储系统了,接下来我将逐步介绍怎么去搭建大数据存储系统。
零、环境准备
首先我们需要一些环境基础,在上面我们已经知道,HDFS需要一个 Namenode,和多个DataNode,所以我们下面就用一个 NameNode和两个DataNode来进行搭建。
1、需具备环境
三台安装centos7.6操作系统,可以用虚拟机搭建三个操作系统,再使用XShell、SecureCRT等软件连接到三台机子。
- 如果不会用虚拟机搭建操作系统,可以评论@我,有需求的话我之后会出相关详细简单教程~
2、软件包准备
需要以下软件,可以自己在官网下载。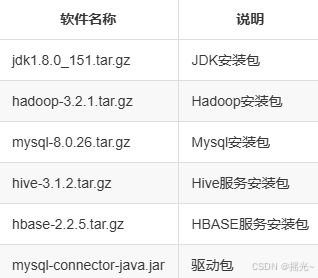
一、部署Hadoop环境
首先我们需要部署Hadoop的环境,以便之后进行HDFS、HBase、Hive的搭建。
1、集群规划
1、集群规划如下表所示,IP地址仅作为参考根据自己情况配置,可以根据具体情况进行配置: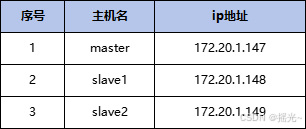
2、存储目录规划:
2、安装前的准备
2.1 配置目录
- 为了存放软件和地址,所以创建相应的目录
- 创建softwares和data文件(
在三个节点上操作,以master为例)
[hadoop@master ~]$ sudo mkdir /softwares
[hadoop@master ~]$ sudo mkdir /data
2.2 配置 /etc/hosts 文件
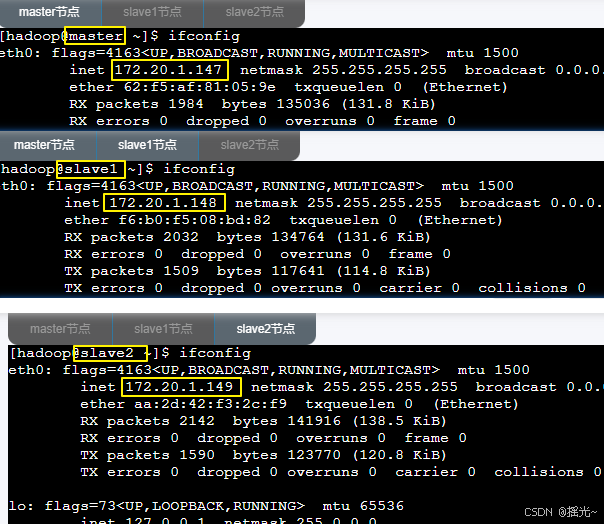
1、打开终端,查看master\slave1\slave2主机IP地址
[hadoop@master ~]$ ifconfig
- 可以从下图看出主机IP地址:
master:172.20.1.147
slave1:172.20.1.148
slave2:172.20.1.149
2、修改主机的 /ect/hosts 文件(在三个节点上操作,以master为例)
[hadoop@master ~]$ sudo vim /etc/hosts
进入界面后,鼠标单击屏内框,按键盘 i 键,进入编辑模式。如果所示: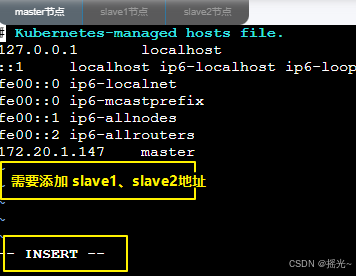
需要将以下内容都贴入 /ect/hosts 文件内
172.20.1.147 master
172.20.1.148 slave1
172.20.1.149 slave2
上述代码贴入文件后,按 esc 退出,再输入 :wq! 再回车 (注意需要输入冒号)
2.3 配置JDK
1、上传 jdk 压缩包到 /softwares 目录并解压(在三个节点上操作,以master为例)
[hadoop@master ~]$ cd /softwares
[hadoop@master softwares]$ sudo tar -zxvf jdk1.8.0_151.tar.gz # 解压jdk压缩包
2、配置 Java 环境变量(在三个节点上操作,以master为例)
[hadoop@master softwares]$ sudo vim /etc/profile
- 进入界面后,按下键盘 i ,进入编辑模式,在
文件末尾添加如下内容:
export JAVA_HOME=/softwares/jdk1.8.0_151
export PATH=$PATH:$JAVA_HOME/bin
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
3、刷新环境变量(在三个节点上操作,以master为例)
[hadoop@master softwares]$ source /etc/profile
4、测试Java环境是否生效(在三个节点上操作,以master为例)
[hadoop@master softwares]$ java -version
2.4 配置防火墙
- 检查防火墙状态
[hadoop@master softwares]$ sudo systemctl status firewalld.service
- 关闭防火墙(
在三个节点上操作,以master为例)
[hadoop@master softwares]$ sudo systemctl stop firewalld.service
[hadoop@master softwares]$ sudo systemctl disable firewalld.service
3、Hadoop集群配置
3.1 集群用户及目录创建
- 创建hadoop组、hdfs、yarn用户,并创建文件夹,且修改权限(
在三个节点上操作,以master为例)
[hadoop@master softwares]$ sudo groupadd hadoop # hadoop用户组
[hadoop@master softwares]$ sudo useradd -g hadoop hdfs # hdfs 用户
[hadoop@master softwares]$ sudo useradd -g hadoop yarn # yarn 用户
[hadoop@master softwares]$ sudo mkdir -p /var/log/hadoop/hdfs # 文件夹
[hadoop@master softwares]$ sudo mkdir -p /data/hadoop/hdfs # 文件夹
[hadoop@master softwares]$ sudo mkdir -p /var/log/hadoop/yarn # 文件夹
[hadoop@master softwares]$ sudo chown -R hdfs:hadoop /data/hadoop/hdfs # 赋权
[hadoop@master softwares]$ sudo chown -R hdfs:hadoop /var/log/hadoop/hdfs # 赋权
[hadoop@master softwares]$ sudo chown -R yarn:hadoop /var/log/hadoop/yarn # 赋权
3.2 Hadoop安装及配置
1、解压文件
- 解压Hadoop压缩包到指定目录(
在三个节点上操作,以master为例)
[hadoop@master softwares]$ sudo tar -zxvf hadoop-3.2.1.tar.gz
2、配置环境变量
- (
在三个节点上操作,以master为例)
[hadoop@master softwares]$ sudo vim /etc/profile
- 进入界面后,按下键盘 i ,进入编辑模式,在
文件末尾添加如下内容:
export HADOOP_HOME=/softwares/hadoop-3.2.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
- 刷新环境变量:
[hadoop@master softwares]$ source /etc/profile
3、修改 Hadoop 配置文件
注:以下的修改配置文件只在master节点做,slave1/slave2 之后拷贝 master 就行- 进入 /softwares/hadoop-3.2.1/etc/hadoop/ 目录下,修改 Hadoop配置文件
[hadoop@master softwares]$ cd /softwares/hadoop-3.2.1/etc/hadoop/
(1)修改 hadoop-env.sh 文件
[hadoop@master hadoop]$ vim hadoop-env.sh
- 进入界面后,按下键盘 i ,进入编辑模式,在
末尾处添加如下内容:
export HADOOP_LOG_DIR=/var/log/hadoop/hdfs
export HADOOP_NAMENODE_OPTS="-server -Djava.net.preferIPv6Addresses=false -Djava.net.preferIPv4Stack=true -XX:+UseG1GC -Xmx128m"
export HADOOP_DATANODE_OPTS="-server -Djava.net.preferIPv6Addresses=false -Djava.net.preferIPv4Stack=true -Xms128m -Xmx128m"
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
(2)修改 yarn-env.sh 文件
[hadoop@master hadoop]$ vim yarn-env.sh
- 进入界面后,按下键盘 i ,进入编辑模式,添加如下内容:
export HADOOP_LOG_DIR=/var/log/hadoop/yarn
export YARN_NODEMANAGER_OPTS="-Djava.net.preferIPv6Addresses=false -Djava.net.preferIPv4Stack=true -XX:+UseG1GC -Xmx256m"
export YARN_RESOURCEMANAGER_OPTS="-Djava.net.preferIPv6Addresses=false -Djava.net.preferIPv4Stack=true -XX:+UseG1GC -Xmx256m"
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
(3)修改 mapred-env.sh 文件
[hadoop@master hadoop]$ vim mapred-env.sh
- 进入界面后,按下键盘 i ,进入编辑模式,添加如下内容:
export MAPRED_HISTORYSERVER_OPTS="-Djava.net.preferIPv6Addresses=false -Djava.net.preferIPv4Stack=true -XX:+UseG1GC -Xmx64m"
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
(4)修改 core-site.xml 文件
[hadoop@master hadoop]$ vim core-site.xml
- 进入界面后,按下键盘 i ,进入编辑模式,修改configuration里面内容:
<!--注:修改configuration里面的内容-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
(5)修改 hdfs-site.xml 文件
[hadoop@master hadoop]$ vim hdfs-site.xml
- 进入界面后,按下键盘 i ,进入编辑模式,修改configuration内容:
<!--注:修改configuration里面的内容-->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/hdfs/datanode</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>hadoop</value>
</property>
</configuration>
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
(6)修改 yarn-site.xml 文件
[hadoop@master hadoop]$ vim yarn-site.xml
- 进入界面后,按下键盘 i ,进入编辑模式,修改内容:
<!--注:修改configuration里面的内容-->
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
(7)修改 mapred-site.xml 文件
[hadoop@master hadoop]$ vim mapred-site.xml
- 进入界面后,按下键盘 i ,进入编辑模式,修改内容:
<!--注:修改configuration里面的内容-->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/softwares/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/softwares/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/softwares/hadoop-3.2.1</value>
</property>
</configuration>
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
(8)添加 workers 文件
[hadoop@master hadoop]$ vim workers
- 进入界面后,按下键盘 i ,进入编辑模式,修改内容:
master
slave1
slave2
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
4、拷贝集群信息
- 将master上面的配置信息、集群信息都拷贝到 slave1、slave2(
在master节点操作)
#hadoop安装包分别拷贝到slave1/slave2的/softwares/目录下(以slave1为例)
[hadoop@master hadoop]$ cd /softwares
[hadoop@master softwares]$ scp -r hadoop-3.2.1/ slave1:/softwares/
[hadoop@master softwares]$ scp -r hadoop-3.2.1/ slave2:/softwares/
5、格式化集群
注:
- 集群
第一次启动之前需先进行格式化,该命令只需要执行一次,后续启停集群也无需执行- 只用在
master节点执行
[hadoop@master softwares]$ sudo su - root -c 'cd /softwares/hadoop-3.2.1/bin/;hdfs namenode -format'
[hadoop@master softwares]$ sudo chown -R hdfs:hadoop /data/hadoop/hdfs/namenode
3.3 集群启动
1、登录master节点,使用hdfs用户启动HDFS
[hadoop@master ~]$ sudo su - hdfs
[hdfs@master ~]$ cd /softwares/hadoop-3.2.1/sbin/
[hdfs@master sbin]$ ./hadoop-daemon.sh start namenode #只需要在master节点上执行
[hdfs@master sbin]$ ./hadoop-daemon.sh start datanode #需要在master/slave1/slave2三个节点上都执行
2、登录master节点,使用yarn用户启动YARN
[hadoop@master ~]$ sudo su - yarn
[yarn@master ~]$ cd /softwares/hadoop-3.2.1/sbin/
[yarn@master sbin]$ ./yarn-daemon.sh start resourcemanager #只需要在master节点上执行
[yarn@master sbin]$ ./mr-jobhistory-daemon.sh start historyserver #只需要在master节点上执行
[yarn@master sbin]$ ./yarn-daemon.sh start nodemanager #需要在master/slave1/slave2三个节点上都执行
3、查看master上运行的程序(用hdfs用户查看hdfs进程,查看yarn进程切换yarn用户):
[hdfs@master ~]$ jps
4、查看slave1和slave2上运行的程序:
[hdfs@slave1 ~]$ jps
5、运行 wordcount 案例测试:
[hadoop@master ~]$ sudo su - hdfs
[hdfs@master ~]$ vim wordcount.txt
- 进入界面后,按下键盘 i ,进入编辑模式,添加以下内容:
123456788
ABCDEFGHIJ
0101010101
- 粘贴完后,按下键盘 ESC ,再输入 :wq! 再按 enter (注意需要输入冒号)
[hdfs@master ~]$ cd /softwares/hadoop-3.2.1
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -put /home/hdfs/wordcount.txt /
[hdfs@master hadoop-3.2.1]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /wordcount.txt /out
6、查看结果
(1)在浏览器中输入:http://master:50070,查看HDFS管理页面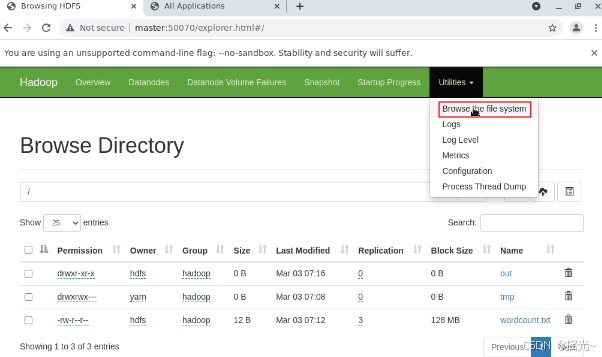
(2)、在浏览器中输入 http://master:8088,查看YARN管理页面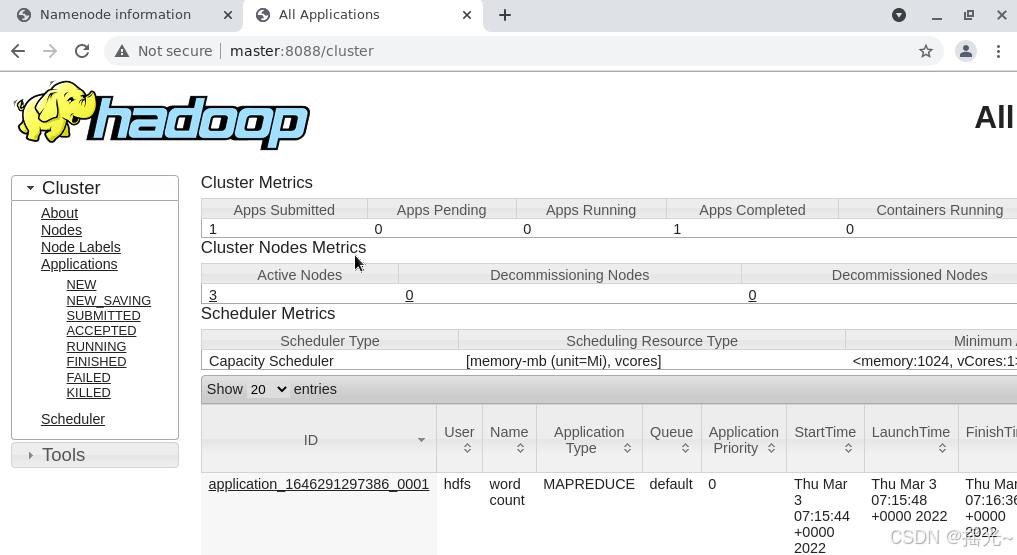
二、HDFS-分布式文件系统操作
1、使用HDFS shell进行文件资源管理
- HDFS文件系统提供了基于shell操作命令来管理HDFS上的数据。
1.1 列出文件目录
[hadoop@master ~]$ sudo su - hdfs # 切换到 hdfs 目录
[hdfs@master ~]$ cd /softwares/hadoop-3.2.1 # 进入hadoop 目录
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -ls / # 查看HDFS根目录下的文件
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -ls -R /tmp # 递归查询目录上的目录及文件
1.2 HDFS创建文件夹
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -mkdir /bigdata # 创建文件夹 bigdata
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -ls / # 查看根目录下的文件目录
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -mkdir -p /bigdata/mr/input # 级联创建文件夹
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -ls -R /bigdata # 查看目录
1.3 上传文件到HDFS
# 将/home/hdfs/test.txt 上传到 /bigdata/mr/input
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -put /home/hdfs/test.txt /bigdata/mr/input
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -ls -R /bigdata
1.4 从HDFS上下载文件
# 将 /bigdata/mr/input/test.txt 文件下载到 /home/hdfs/test/ 中
[hdfs@master hadoop-3.2.1]$ mkdir -p /home/hdfs/test
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -get /bigdata/mr/input/test.txt /home/hdfs/test/
[hdfs@master hadoop-3.2.1]$ ls /home/hdfs/test
1.5 查看HDFS文件内容
# 查看 /bigdata/mr/input/test.txt 文件
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -cat /bigdata/mr/input/test.txt
1.6 统计HDFS文件大小
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -du /bigdata/mr/input
1.7 删除文件
# 创建文件夹 /bigdata/mr/input/profile
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -touchz /bigdata/mr/input/profile
# 删除文件夹 /bigdata/mr/input/profile
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -rm /bigdata/mr/input/profile
1.7 查看help帮助命令
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -help mkdir
2、使用文件管理工具进行文件资源管理
2.1 配置回收站,对删除文件进行管理
[hadoop@master hadoop]$ vim /softwares/hadoop-3.2.1/etc/hadoop/core-site.xml
- 进入界面后,按下键盘 i ,进入编辑模式,修改内容:
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
- 修改完之后需要重启yarn
[hadoop@master ~]$ sudo su - yarn
[yarn@master ~]$ cd /softwares/hadoop-3.2.1/sbin/
[yarn@master sbin]$ ./yarn-daemon.sh start resourcemanager # 只需要在master节点上执行
[yarn@master sbin]$ ./mr-jobhistory-daemon.sh start historyserver # 只需要在master节点上执行
[yarn@master sbin]$ ./yarn-daemon.sh start nodemanager # 需要在master/slave1/slave2三个节点上都执行
2.2 创建缓存,对缓存文件管理
在Hadoop中,如果有一些数据经常被访问,可以创建缓存池,数据被标记为常用,这样就可以加快访问速度。
- 如果创建缓存池失败,可以看配置文件hdfs-site.xml中的dfs.cachepool.enabled 是否为true
# 创建缓存池
[hdfs@master bin]$ hdfs cacheadmin -addPool testPool # 创建缓存池
[hdfs@master bin]$ hdfs cacheadmin -addPool testPool -maxCacheSize 10% # 设置缓存池的大小,总内存的10%
[hdfs@master bin]$ hdfs cacheadmin -listPools # 列出缓存池

# 把文件放入缓存池中,提高读取速度
[hdfs@master hadoop-3.2.1]$ hdfs cacheadmin -addDirective -path /bigdata/mr/input -pool testPool
# 查看缓存池内容
[hdfs@master hadoop-3.2.1]$ hdfs cacheadmin -listDirectives -pool testPool
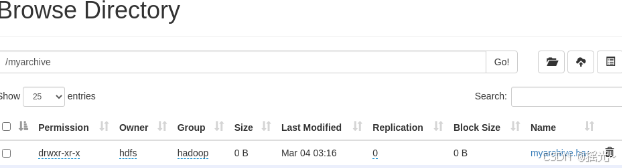
2.3 小文件归档
在Hadoop中,小文件通常是体积较小但数量比较多的文件,这些小文件会占据Namenode大量的内存,对HDFS性能造成影响。所以将小文件进行归档可以提高效率。
- 以下使用Hadoop Archives(HAR files)进行小文件归档
# 创建
[hdfs@master hadoop-3.2.1]$ hdfs dfs -mkdir /myarchive
[hdfs@master hadoop-3.2.1]$ hadoop archive -archiveName myarchive.har -p /newland/mr/input -r 1 /myarchive
# 查看小文件归档结果
[hdfs@master hadoop-3.2.1]$ bin/hdfs dfs -ls -R har:///myarchive/myarchive.har
三、mysql-部署大数据关系型数据库
3.1 mysql服务安装和配置
1、获取及解压压缩包
[hadoop@master softwares]$ sudo cp -rf /media/toolPackages/mysql-8.0.26.tar.gz /softwares/
[hadoop@master softwares]$ sudo tar -zxvf mysql-8.0.26.tar.gz
2、创建mysql用户及用户组
[hadoop@master softwares]$ sudo groupadd mysql
[hadoop@master softwares]$ sudo useradd -g mysql mysql
3、创建mysql存放源数据的data文件夹,修改mysql安装包用户和用户组
[hadoop@master softwares]$ sudo mkdir -p /softwares/mysql-8.0.26/data
[hadoop@master softwares]$ sudo chown -R mysql:mysql /softwares/mysql-8.0.26
4、修改my.conf文件内容
[hadoop@master softwares]$ sudo vim /etc/my.cnf
- 进入界面后,鼠标单击屏内框,按键盘 i 键,进入编辑模式。
[mysqld]
basedir=/softwares/mysql-8.0.26
datadir=/softwares/mysql-8.0.26/data
socket=/softwares/mysql-8.0.26/mysql.sock
log-error=/softwares/mysql-8.0.26/mysqld.log
symbolic-links=0
secure_file_priv=''
[mysqld_safe]
log-error=/softwares/mysql-8.0.26/mysqld.log
pid-file=/softwares/mysql-8.0.26/mysqld.pid
[client]
port=3306
socket=/softwares/mysql-8.0.26/mysql.sock
5、修改profile文件,在文件末尾追加以下内容
[hadoop@master softwares]$ sudo vim /etc/profile
- 添加以下内容
export MYSQL_HOME=/softwares/mysql-8.0.26/
export PATH=$PATH:$MYSQL_HOME/bin
- 刷新环境
[hadoop@master softwares]$ source /etc/profile
6、初始化mysql
[hadoop@master softwares]$ sudo su - root -c '/softwares/mysql-8.0.26/bin/mysqld --initialize --user=mysql --basedir=/softwares/mysql-8.0.26/ --datadir=/softwares/mysql-8.0.26/data/'
7、启动mysql
[hadoop@master softwares]$ sudo su - mysql -c '/softwares/mysql-8.0.26/bin/mysqld_safe --user=mysql &'

8、获取mysql初始密码,并修改密码,登录mysql
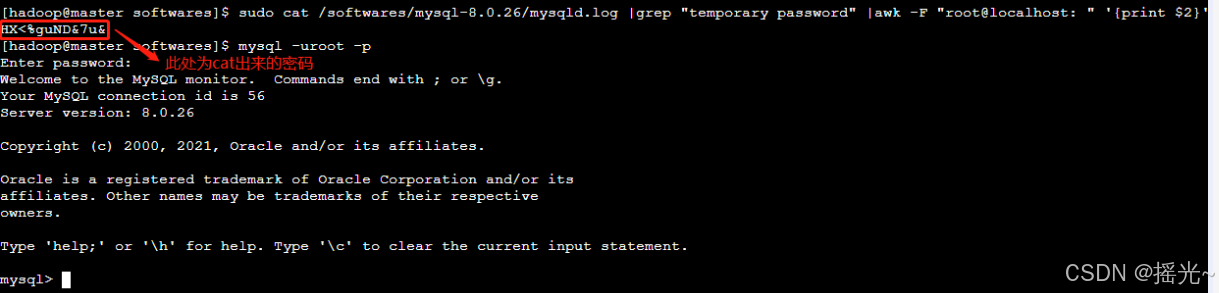
[hadoop@master softwares]$ sudo cat /softwares/mysql-8.0.26/mysqld.log |grep "temporary password" |awk -F "root@localhost: " '{print $2}'
[hadoop@master softwares]$ mysql -uroot -p # 此处输入回车
Enter password: # 此处输入mysql的初始密码
9、在mysql终端中,依次输入以下命令,修改初始密码
mysql> alter user root@localhost identified by 'Bigdata_123';
mysql> create user 'root'@'%' identified by 'Bigdata_123';
mysql> GRANT ALL PRIVILEGES on *.* to 'root'@'%';
mysql> GRANT ALL PRIVILEGES on *.* to 'root'@'localhost';
mysql> flush privileges;
10、退出mysql终端
mysql> exit
11、使用新密码登录mysql
[hadoop@master softwares]$ mysql -uroot -pBigdata_123
3.2 sql语句基本语法
1、创建库、表、及外键
- 创建数据库
mysql> create database test_db character set utf8;
mysql> show databases;
- 创建表,并插入数据
mysql> use test_db;
mysql> CREATE TABLE grade(
gradeid INT(10) PRIMARY KEY AUTO_INCREMENT,
gradename VARCHAR(50) NOT NULL
);
mysql> CREATE TABLE student (
studentno INT(4) PRIMARY KEY,
studentname VARCHAR(20) NOT NULL DEFAULT '匿名',
sex TINYINT(1) DEFAULT 1,
gradeid INT(10) ,
phone VARCHAR(50) NOT NULL,
address VARCHAR(255) ,
borndate DATETIME,
email VARCHAR(50) ,
identityCard VARCHAR(18) NOT NULL,
CONSTRAINT FK_gradeid FOREIGN KEY (gradeid) REFERENCES grade (gradeid)
);
mysql> CREATE TABLE result (
StudentNo int(4) NOT NULL COMMENT '学号',
SubjectNo int(4) NOT NULL COMMENT '课程编号',
ExamDate datetime NOT NULL COMMENT '考试日期',
StudentResult int(4) NOT NULL COMMENT '考试成绩',
KEY SubjectNo (SubjectNo)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
mysql> insert into result (StudentNo, SubjectNo, ExamDate,StudentResult) values
(1111,1,'2019-11-11 16:00:00',94),
(1111,2,'2020-11-10 0:00:00',75),
(1112,3,'2019-12-19 10:00:00',76),
(1113,4,'2020-11-18 11:00:00',93),
(1113,5,'2019-11-11 14:00:00',97),
(1112,6,'2019-09-13 15:00:00',87),
(1112,7,'2020-10-16 16:00:00',79),
(1111,8,'2010-11-11 16:00:00',74),
(1113,9,'2019-11-21 10:00:00',69);
mysql> CREATE TABLE subject (
SubjectNo int(11)NOT NULL AUTO_INCREMENT COMMENT '课程编号',
SubjectName varchar(50) DEFAULT NULL COMMENT '课程名称',
ClassHour int(4) DEFAULT NULL COMMENT '学时',
GradeID int(4) DEFAULT NULL COMMENT '年级编号',
PRIMARY KEY (SubjectNo )
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8;
mysql> show tables;
- DML操作
(1)增
mysql> insert into grade (GradeID,GradeName) values (1,'大一'),(2,'大二'),(3,'大三'),(4,'大四');
mysql> insert into subject (SubjectNo,SubjectName,ClassHour,GradeID) values
(1,'高等数学-1',110,1),
(2,'C语言-1',110,1),
(3,'JAVA第一学年',110,1),
(4,'数据库结构-1',110,1),
(5,'C#基础',130,1),
(6,'高等数学-2',110,2),
(7,'C语言-2',110,2),
(8,'JAVA第二学年',110,2),
(9,'数据库结构-2',110,2),
(10,'高等数学-3',100,3),
(11,'C语言-3',100,3),
(12,'JAVA第三学年',100,3),
(13,'数据库结构-3',100,3),
(14,'高等数学-4',130,4),
(15,'C语言-4',130,4),
(16,'JAVA第四学年',130,4),
(17,'数据库结构-4',130,4);
mysql> insert into student (StudentNo,StudentName,Sex,GradeId,Phone,Address,Email,IdentityCard) values
(1111,'张小备',1,1,'13600000001','福州市新大陆1号','liuxiaob@newland.com','133323198612111541'),
(1112,'孙小权',1,2,'13900000002','福州市马尾西路1号','sunxiaoq@newland.com','632323198512311762'),
(1113,'曹小操',2,3,'13800000015','上海卢湾区','caocao@newland.com','15223198412311438');
mysql> select * from grade;
(2)更新
mysql> update student set borndate='1977-07-07' where studentno='1111';
mysql> update student set borndate='1978-08-08' where gradeid>1;
mysql> select * from student;
(3)删除
mysql> create table ss select * from student;
mysql> delete from ss where studentno=1111;
mysql> select * from ss;
mysql> delete from ss;
mysql> select * from ss;
mysql> DROP TABLE IF EXISTS demo_delete;
mysql> CREATE TABLE IF NOT EXISTS demo_delete(
id INT(10) NOT NULL AUTO_INCREMENT,
title VARCHAR(32) NOT NULL,
PRIMARY KEY(id)
) AUTO_INCREMENT = 5;
mysql> INSERT INTO demo_delete (title)VALUES ('aaaaa'),('bbbbb'),('cccccc'),('ddddd');
2、查询操作
(1)建单查询
# 查询表
mysql> SELECT * FROM student;
# 查询指定列
mysql> SELECT studentno,studentname FROM student;
# 为列取别名
mysql> SELECT studentno AS 学号,studentname AS 姓名 FROM student;
mysql> SELECT studentno 学号,studentname 姓名 FROM student;
# 为表取别名
mysql> SELECT studentno 学号,studentname 姓名 FROM student AS s;
mysql> SELECT studentno 学号,studentname 姓名 FROM student s;
# 去除重复值
mysql> SELECT DISTINCT studentno FROM result;
(2)表达式查询
mysql> SELECT @@auto_increment_increment;
mysql> SELECT VERSION();
mysql> SELECT 100*3-1 AS 计算结果;
mysql> SELECT studentno,studentresult+1 AS '提分后' FROM result;
(3)连接查询
msyql> SELECT SubjectName,ClassHour,GradeName FROM subject as s left join grade as g ON g.GradeID = s.GradeID;
(4)排序操作
mysql> select * from result order by studentresult desc;
(5)分页查询
mysql> select * from result order by studentresult desc limit 0,5;
(6)分组查询
mysql> SELECT s.SubjectName as '课程名',MAX(StudentResult) as '最高分',MIN(StudentResult) as '最低分',AVG(StudentResult) AS '平均分'
FROM result as r LEFT JOIN subject as s ON s.SubjectNo = r.SubjectNo
GROUP BY r.SubjectNo HAVING AVG(StudentResult) >= 60;
3、事物索引操作
(1)事物操作
/*创建shop数据库*/
mysql> CREATE DATABASE IF NOT EXISTS shop;
/*创建账户表*/
mysql> CREATE TABLE IF NOT EXISTS account (
id int(11) not null auto_increment,
name varchar(32) not null,
cash decimal(9,2) not null,
PRIMARY KEY (id)
) ENGINE=InnoDB;
mysql> INSERT INTO account (name,cash) VALUES ('A',1500.00) ;
mysql> INSERT INTO account (name,cash) VALUES ('B',2000.00) ;
/*事务处理*/
mysql> select * from account;
mysql> set autocommit= 0;
mysql> START TRANSACTION;
mysql> update account set cash = cash - 500 where name = 'A';
mysql> select * from account;
mysql> ROLLBACK;
mysql> set autocommit = 1;
mysql> select * from account;
(2)索引操作
# 查看索引
mysql> show index from student;
# 增加约束,创建新索引
mysql> alter table student add unique index(IdentityCard) ;
mysql> alter table student add index (Email) ;
mysql> show index from student;
(3)数据备份
# 进入mysql终端
[hadoop@master ~]$ sudo su - mysql -c 'mysqldump -uroot -pBigdata_123 test_db student result>/softwares/mysql-8.0.26/test_db.sql'
# 删除数据
mysql> use test_db;
mysql> drop table student;
mysql> drop table result;
# 查看student表和result表是否删除
mysql> show tables;
mysql> exit
#备份数据
[hadoop@master ~]$ mysql -uroot -pBigdata_123 test_db</softwares/mysql-8.0.26/test_db.sql;
#重新登陆mysql
[hadoop@master ~]$ mysql -uroot -pBigdata_123
[hadoop@master ~]$ mysql -uroot -pBigdata_123 test_db</softwares/mysql-8.0.26/test_db.sql;
#重新登陆mysql
[hadoop@master ~]$ mysql -uroot -pBigdata_123
# 导入导出数据
[hadoop@master ~]$ mysql -uroot -pBigdata_123 test_db</softwares/mysql-8.0.26/test_db.sql;
#重新登陆mysql
[hadoop@master ~]$ mysql -uroot -pBigdata_123
# 恢复文件mytest.sql中的数据到tes_db数据库的t2表中
[hadoop@master ~]$ mysql -uroot -pBigdata_123
mysql> use test_db;
mysql> create table t2(id int(4),sname varchar(20));
mysql> LOAD DATA INFILE '/softwares/mysql-8.0.26/mytest.sql' INTO TABLE t2(id,sname) ;
mysql> select * from t2;
mysql> exit
四、HBase-部署大数据非关系型数据库
HDFS提供高容量、分布式文件存储,可以处理PB级别的数据。但是HDFS并不适用于高速读写的场景,所以引入了HBase,HBase具有更低的延迟和更高的吞吐量,可以进行高速读写,适合实时读写大量数据。
其实HBase实际上是构建在 HDFS 上的一层数据库系统,HBase适用HDFS作为底层存储,将数据存储在HDFS的数据块中,HBase通过HDFS提供高容量和可靠性,实现数据的持久性。
4.1 HBase用户及目录创建
[hadoop@master softwares]$ sudo useradd -g hadoop hbase # 创建用户
[hadoop@master softwares]$ sudo mkdir -p /var/log/hbase # 创建log目录
[hadoop@master softwares]$ sudo chown -R hbase:hadoop /var/log/hbase # 授权
4.2 HBase配置
1、解压压缩包
[hadoop@master softwares]$ sudo tar -zxf hbase-2.2.5.tar.gz
[hadoop@master softwares]$ sudo chown -R hadoop:hadoop /softwares/hbase-2.2.5
2、修改配置
(1)进入配置文件目录
[hadoop@master softwares]$ cd /softwares/hbase-2.2.5/conf
(2)修改 hbase-env.sh 文件
[hadoop@master softwares]$ cd /softwares/hbase-2.2.5/conf/
[hadoop@master conf]$ vim hbase-env.sh
- 添加以下内容:
export JAVA_HOME=/softwares/jdk1.8.0_151
export HBASE_CONF_DIR=/softwares/hbase-2.2.5/conf
export HBASE_LOG_DIR=/var/log/hbase
export HBASE_MANAGES_ZK=true
export HBASE_MASTER_OPTS="-XX:+UseG1GC -Xmx256m"
export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC -Xms256m -Xmx256m"
(3)修改 hbase-site.xml 文件
[hadoop@master conf]$ vim hbase-site.xml
- 修改以下内容:
<!--configuration标记中替换为以下内容,保存退出-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
(4)修改 regionservers 文件
[hadoop@master conf]$ vim regionservers
- 增加以下内容:
master
slave1
slave2
(5)将集群信息拷贝到 slave1和slave2
[hadoop@master conf]$ cd /softwares
[hadoop@master softwares]$ scp -r hbase-2.2.5/ slave1:/softwares/
[hadoop@master softwares]$ scp -r hbase-2.2.5/ slave2:/softwares/
[hadoop@master softwares]$ sudo chown -R hbase:hadoop /softwares/hbase-2.2.5
[hadoop@slave1 softwares]$ sudo chown -R hbase:hadoop /softwares/hbase-2.2.5
[hadoop@slave2 softwares]$ sudo chown -R hbase:hadoop /softwares/hbase-2.2.5
4.3 启动HBase
(1)登录master节点,启动zookeeper
[hadoop@master softwares]$ sudo su - hbase
[hbase@master ~]$ cd /softwares/hbase-2.2.5/bin
[hbase@master bin]$ ./hbase-daemon.sh start zookeeper
(2)分别登录slave1和slave2,启动 zookeeper
[hadoop@slave1 ~]$ sudo su - hbase
[hbase@slave1 ~]$ cd /softwares/hbase-2.2.5/bin
[hbase@slave1 bin]$ ./hbase-daemon.sh start zookeeper
(3)登陆master,启动HBase服务
[hbase@master bin]$ ./hbase-daemon.sh start master
[hbase@master bin]$ ./hbase-daemon.sh start regionserver
(4)登陆slave1和slave2,启动HBase服务
[hbase@slave1 bin]$ ./hbase-daemon.sh start regionserver
(5)查看服务启动情况
[hbase@master bin]$ jps
(6)查看服务
地址:http://master:1610/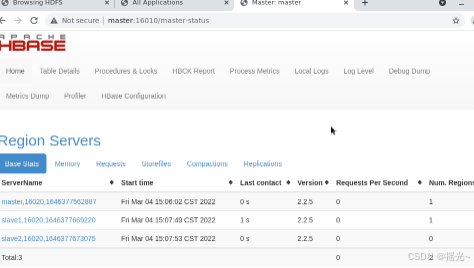
3.4 HBase shell操作
(1)进入Hbase
[hbase@master ~]$ cd /softwares/hbase-2.2.5
[hbase@master hbase-2.2.5]$ bin/hbase shell
hbase(main):001:0> help
(2)建表
hbase(main):008:0> create 'user','info'
(3)写入记录
hbase(main):011:0> put 'user','id0001','info:name','liubei'
hbase(main):012:0> put 'user','id0002','info:name','guanyu'
hbase(main):013:0> put 'user','id0003','info:name','zhangfei'
(4)查看数据
hbase(main):018:0> scan 'user'
(5)查看表信息
hbase(main):023:0> get 'user','id0001'
(6)删除表
hbase(main):027:0> disable 'user'
hbase(main):035:0> drop 'user'
(7)列出表
hbase(main):039:0> list
(8)退出
hbase(main):039:0> exit
五、Hive-数据仓库的使用
5.1 解压安装文件并配置环境变量
(1)解压文件
[hadoop@master softwares]$ sudo cp /media/toolPackages/hive-3.1.2.tar.gz /softwares/
[hadoop@master softwares]$ sudo tar -zxvf hive-3.1.2.tar.gz
(2)创建用户
[hadoop@master softwares]$ sudo useradd -g hadoop hive
[hadoop@master softwares]$ sudo chown -R hive:hadoop /softwares/hive-3.1.2
[hadoop@master softwares]$ hdfs dfs -mkdir /tmp
[hadoop@master softwares]$ sudo su - hive
[hive@master ~]$ hdfs dfs -mkdir -p /user/hive/warehouse
[hive@master ~]$ hdfs dfs -chmod g+w /tmp
[hive@master ~]$ hdfs dfs -chmod g+w /user/hive/warehouse
5.2 配置元数据
(1)下载MySQL驱动‘mysql-connector-java.jar’,放在hive/lib下
[hive@master ~]$ cp /media/toolPackages/mysql-connector-java.jar /softwares/hive-3.1.2/lib/
(2)进入 /softwares/hive-3.1.2/conf 目录,修改配置文件
[hive@master ~]$ cd /softwares/hive-3.1.2/conf/
(3)修改 hive-site.xml 文件
[hive@master conf]$ vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
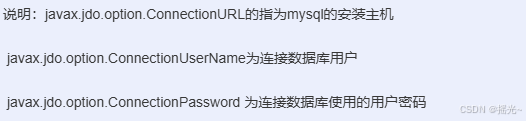
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Bigdata_123</value>
<description>password to use against metastore database</description>
</property>
</configuration>
(4)数据库配置
- 登录Mysql创建Hive元数据库
mysql> create database hive;
mysql> create user 'hive'@'%' identified by 'Bigdata_123';
mysql> GRANT ALL PRIVILEGES on *.* to 'hive'@'%';
mysql> flush privileges;
mysql> exit
(5)初始化mySQL
[hadoop@master ~]$ sudo su - root -c '/softwares/hive-3.1.2/bin/schematool -initSchema -dbType mysql'
[hadoop@master ~]$ mysql -uroot -pBigdata_123
mysql> use hive;
mysql> show tables;
mysql> exit
5.3 hive数据模型及实现方式
1、启动hive
[hadoop@master ~]$ sudo su - hive
[hive@master ~]$ cd /softwares/hive-3.1.2
[hive@master hive-3.1.2]$ bin/hive
2、创建表
hive> CREATE TABLE stu (id INT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
hive> show tables;
3、加载数据
- 注:hive表的默认分隔符为tab,因此在创建stu.txt文件时,字段分隔符要使用tab,否则会出现load数据为NULL的情况。
[hive@master ~]$ vim /home/hive/stu.txt
1 张三
2 李四
3 王五
4 赵六
- 切换hive窗口,加载数据,查看数据
[hive@master hive-3.1.2]$ bin/hive
hive> load data local inpath '/home/hive/stu.txt' into table stu;
hive> select * from stu;
4、mysql关联元数据
mysql> use hive;
mysql> select * from TBLS;
- 创建外部表
hive> create external table if not exists employee_external (
name string,
work_place array<string>,
sex_age struct<sex:string,age:int>,
skill_score map<string,int>,
depart_title map<string,array<string>>
)
comment 'this is an external table'
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by':'
stored as textfile
location '/user/hive/warehouse/employee';
hive> show tables;
5、查询表结构
hive> desc employee_external;
6、HDFS加载数据
[hive@master ~]$ vim employee.txt
Michael|Montreal,Toronto|Male,30|DB:80|Product:DeveloperLead
Will|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shelley|New York|Female,27|Python:80|Test:Lead,COE:Architect
Lucy|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
[hive@master ~]$ cd /softwares/hadoop-3.2.1/bin
[hive@master bin]$ hdfs dfs -put /home/hive/employee.txt /user/hive/warehouse/employee
- 查询外部表
hive> select * from employee_external;
- 查询复杂数据类型
hive> select work_place from employee_external;
- 按数组下标查询
hive> select work_place,work_place[0] from employee_external;
- struct查询
hive> select sex_age from employee_external;
- map查询
hive> select skill_score from employee_external;

一站式 AI 云服务平台
更多推荐



 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)