
运维云计算SRE-第10周
mysql和关系型数据库总结
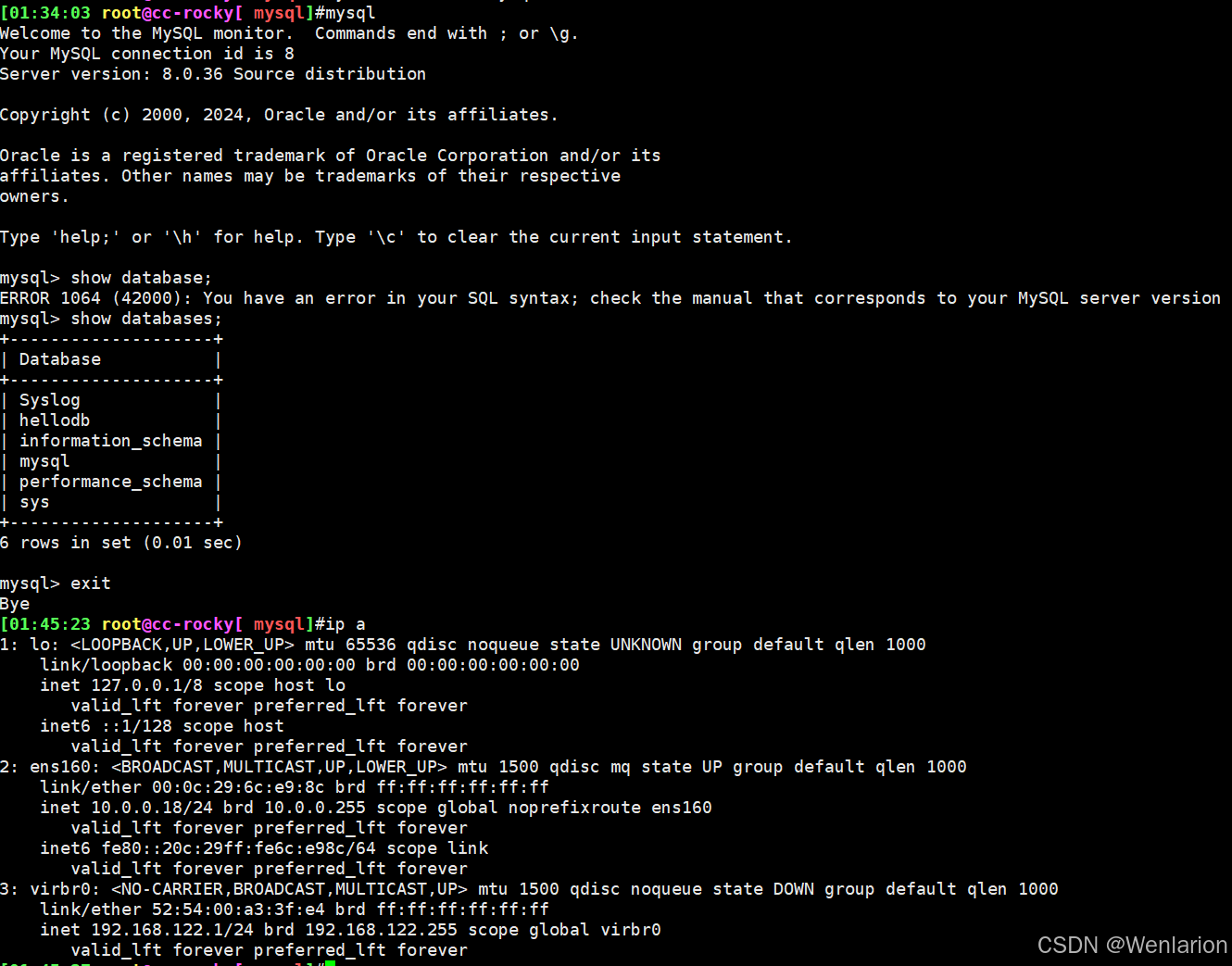
1. 总结关系型数据库相关概念,关系,行,列,主键,唯一键。
关系型数据库相关概念总结
关系(Relation):
在关系型数据库中,关系指的是表(Table),它是数据的基本组织单位。
表由行和列组成,用于存储具有相关性的数据。
行(Row):
行是表中的一条记录,代表了一个实体或实例。
在数据库中,每条记录都有唯一的标识符(通常是主键),用于区分不同的记录。
列(Column):
列是表中的一个字段,代表了记录中的某个属性或特征。
所有的记录在同一列上都具有相同的数据类型,用于存储相似的信息。
主键(Primary Key):
主键是表中的一列或多列的组合,用于唯一标识表中的每一条记录。
主键列的值必须是唯一的,且不允许为空(NULL)。
主键是数据库表设计中的重要组成部分,它确保了数据的完整性和一致性。
唯一键(Unique Key):
唯一键也是一种约束,用于确保列中的所有值都是唯一的。
与主键不同的是,唯一键列允许有一个空值(NULL),但每个空值也被视为唯一的。
一个表中可以有多个唯一键,但只能有一个主键。
唯一键常用于那些需要保证唯一性但又不适合作为主键的列,如邮箱地址、电话号码等。
关系型数据库通过这些概念组织和管理数据,提供了强大的数据查询、更新、删除和插入功能。同时,关系型数据库还支持复杂的关系运算和查询优化,使得数据的管理和操作更加高效和灵活。
在实际应用中,设计关系型数据库表时需要仔细考虑主键和唯一键的选择,以确保数据的完整性和一致性。此外,还需要根据实际需求选择合适的存储引擎和索引策略,以提高数据库的性能和可扩展性。
2. 总结关联类型,1对1,1对多,多对多关系。可以自行设计表进行解释。
在数据库设计中,实体之间的关系可以通过关联类型来描述。常见的关联类型包括一对一(1:1)、一对多(1:N)和多对多(M:N)关系。下面我将通过设计表来解释这些关联类型。
一、一对一(1:1)关系
一对一关系指的是两个实体之间的一种紧密关联,其中一个实体可以唯一确定另一个实体,反之亦然。这种关系通常用于拆分复杂表或满足某些业务逻辑需求。
示例表设计:
Person(人)表:
PersonID(主键)
Name(姓名)
AddressID(外键,与Address表的主键关联)
Address(地址)表:
AddressID(主键,同时也是Person表的外键)
Street(街道)
City(城市)
ZipCode(邮政编码)
在这个例子中,每个人(Person)都有一个唯一的地址(Address),并且每个地址也只属于一个人。这种关系可以通过将Address表的主键作为Person表的外键来实现。然而,值得注意的是,在真正的1:1关系中,通常不需要在其中一个表上创建外键,因为两个表可以通过相同的主键来关联。但出于业务逻辑或数据完整性的考虑,有时仍然会在其中一个表上添加外键约束。
二、一对多(1:N)关系
一对多关系指的是一个实体可以与多个其他实体相关联,但每个其他实体只能与一个实体相关联。这种关系在数据库设计中非常常见,如一个部门有多个员工。
示例表设计:
Department(部门)表:
DepartmentID(主键)
DepartmentName(部门名称)
Employee(员工)表:
EmployeeID(主键)
EmployeeName(员工姓名)
DepartmentID(外键,与Department表的主键关联)
在这个例子中,每个部门(Department)可以有多个员工(Employee),但每个员工只属于一个部门。这种关系通过Employee表中的DepartmentID外键来实现。
三、多对多(M:N)关系
多对多关系指的是两个实体之间可以相互关联,并且每个实体都可以与多个其他实体相关联。这种关系在数据库设计中通常通过引入第三个表(称为关联表或中间表)来实现。
示例表设计:
Student(学生)表:
StudentID(主键)
StudentName(学生姓名)
Course(课程)表:
CourseID(主键)
CourseName(课程名称)
StudentCourse(学生课程关联)表:
StudentID(外键,与Student表的主键关联)
CourseID(外键,与Course表的主键关联)
EnrollmentDate(选课日期,可选)
在这个例子中,每个学生(Student)可以选修多门课程(Course),并且每门课程也可以被多个学生选修。这种关系通过StudentCourse关联表来实现,该表包含了StudentID和CourseID两个外键,分别指向Student表和Course表的主键。此外,还可以添加其他属性(如EnrollmentDate)来记录额外的信息。
综上所述,一对一、一对多和多对多关系是数据库设计中常见的关联类型。通过合理地设计表和关联关系,可以确保数据的完整性和一致性,并满足业务需求。
3. 总结Mysql多种安装方式,及安全加固,并总结mysql配置文件。
Linux上MySQL的多种安装方式
在Linux系统上安装MySQL,可以选择以下几种常见的方式:
通过包管理器安装:
大多数Linux发行版(如Ubuntu、Debian、CentOS等)都提供了MySQL的包,可以直接使用系统的包管理器(如apt、yum等)进行安装。这种方式最为简单,且会自动处理依赖关系。
通过二进制包安装:
可以从MySQL官方网站下载适用于Linux系统的二进制包(如tar.gz格式)。下载后,解压到指定目录,并配置环境变量和启动服务。这种方式需要手动配置,但灵活性较高。
通过源码编译安装:
从MySQL官方网站下载源码包,然后在Linux系统上编译安装。这种方式需要用户具备一定的编译和配置能力,但可以获得最新版本的MySQL,并可以根据需要进行自定义配置。
通过Docker容器安装:
如果系统上已经安装了Docker,可以通过Docker Hub查找并下载MySQL的Docker镜像,然后创建并运行MySQL容器。这种方式可以实现MySQL的隔离部署和快速迁移。
#rocky系统上mysql二进制安装
#1、编写shel脚本,实现rocky系统上的mysql二进制包安装
vim install_mysql.sh
#!/bin/bash
. /etc/init.d/functions
SRC_DIR=`pwd`
MYSQL='mysql-8.0.40-linux-glibc2.12-x86_64.tar.xz'
COLOR='echo -e \E[01;31m'
END='\E[0m'
MYSQL_ROOT_PASSWORD=123456
check (){
if [ $UID -ne 0 ]; then
action "当前用户不是root,安装失败" false
exit 1
fi
cd $SRC_DIR
if [ ! -e $MYSQL ];then
$COLOR"缺少${MYSQL}文件"$END
$COLOR"请将相关软件放在${SRC_DIR}目录下"$END
exit
elif [ -e /usr/local/mysql ];then
action "数据库已存在,安装失败" false
exit
else
return
fi
}
install_mysql(){
$COLOR"开始安装MySQL数据库..."$END
yum -y -q install libaio numactl-libs ncurses-compat-libs
cd $SRC_DIR
tar xf $MYSQL -C /usr/local/
MYSQL_DIR=`echo $MYSQL| sed -nr 's/^(.*[0-9]).*/\1/p'`
ln -s /usr/local/$MYSQL_DIR /usr/local/mysql
chown -R root.root /usr/local/mysql/
id mysql &> /dev/null || { useradd -s /sbin/nologin -r mysql ; action "创建mysql用户"; }
echo 'PATH=/usr/local/mysql/bin/:$PATH' > /etc/profile.d/mysql.sh
. /etc/profile.d/mysql.sh
ln -s /usr/local/mysql/bin/* /usr/bin/
cat > /etc/my.cnf <<-EOF
[mysqld]
server-id=1
log-bin
datadir=/data/mysql
socket=/data/mysql/mysql.sock
log-error=/data/mysql/mysql.log
pid-file=/data/mysql/mysql.pid
[client]
socket=/data/mysql/mysql.sock
EOF
[ -d /data ] || mkdir /data
mysqld --initialize --user=mysql --datadir=/data/mysql
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig mysqld on
service mysqld start
[ $? -ne 0 ] && { $COLOR"数据库启动失败,退出!"$END;exit; }
sleep 3
MYSQL_OLDPASSWORD=`awk '/A temporary password/{print $NF}' /data/mysql/mysql.log`
mysqladmin -uroot -p$MYSQL_OLDPASSWORD password $MYSQL_ROOT_PASSWORD &>/dev/null
action "数据库安装完成"
}
check
install_mysql
#2、运行shell脚本,安装mysql
bash install_mysql.sh
#ubuntu系统上mariadb多实例安装
#1、安装mariadb,并关闭默认启动的服务
yum -y install mariadb-server
systemctl stop mysqld
#2、准备实例目录
mkdir -pv /mysql/{3306,3307,3308}/{data,etc,socket,log,bin,pid}
chown -R mysql.mysql /mysql
#3、生成数据库文件
mysql_install_db --user=mysql --datadir=/mysql/3306/data
mysql_install_db --user=mysql --datadir=/mysql/3307/data
mysql_install_db --user=mysql --datadir=/mysql/3308/data
#4、准备配置文件
vim /mysql/3306/etc/my.cnf
[mysqld]
port=3306
datadir=/mysql/3306/data
socket=/mysql/3306/socket/mysql.sock
log-error=/mysql/3306/log/mysql.log
pid-file=/mysql/3306/pid/mysql.pid
sed 's/3306/3307/' /mysql/3306/etc/my.cnf > /mysql/3307/etc/my.cnf
sed 's/3306/3308/' /mysql/3306/etc/my.cnf > /mysql/3308/etc/my.cnf
#5、准备启动脚本
vim /mysql/3306/bin/mysqld
#!/bin/bash
port=3306
mysql_user="root"
mysql_pwd="123456"
cmd_path="/usr/bin"
mysql_basedir="/mysql"
mysql_sock="${mysql_basedir}/${port}/socket/mysql.sock"
function_start_mysql()
{
if [ ! -e "$mysql_sock" ];then
printf "Starting MySQL...\n"
${cmd_path}/mysqld_safe --defaults-file=${mysql_basedir}/${port}/etc/my.cnf &> /dev/null &
else
printf "MySQL is running...\n"
exit
fi
}
function_stop_mysql()
{
if [ ! -e "$mysql_sock" ];then
printf "MySQL is stopped...\n"
exit
else
printf "Stoping MySQL...\n"
${cmd_path}/mysqladmin -u ${mysql_user} -p${mysql_pwd} -S ${mysql_sock} shutdown
fi
}
function_restart_mysql()
{
printf "Restarting MySQL...\n"
function_stop_mysql
sleep 2
function_start_mysql
}
case $1 in
start)
function_start_mysql
;;
stop)
function_stop_mysql
;;
restart)
function_restart_mysql
;;
*)
printf "Usage: ${mysql_basedir}/${port}/bin/mysqld {start|stop|restart}\n"
esac
sed 's/3306/3307/' /mysql/3306/bin/mysqld > /mysql/3307/bin/mysqld
sed 's/3306/3308/' /mysql/3306/bin/mysqld > /mysql/3307/bin/mysqld
chmod +x /mysql/3306/bin/mysqld
chmod +x /mysql/3307/bin/mysqld
chmod +x /mysql/3308/bin/mysqld
#5、测试服务端口是否开启,并验证登录
ss -ntul
mysql -uroot -p123456 -S /mysql/3306/socket/mysql.sock
mysql -uroot -p123456 -S /mysql/3307/socket/mysql.sock
mysql -uroot -p123456 -S /mysql/3308/socket/mysql.sock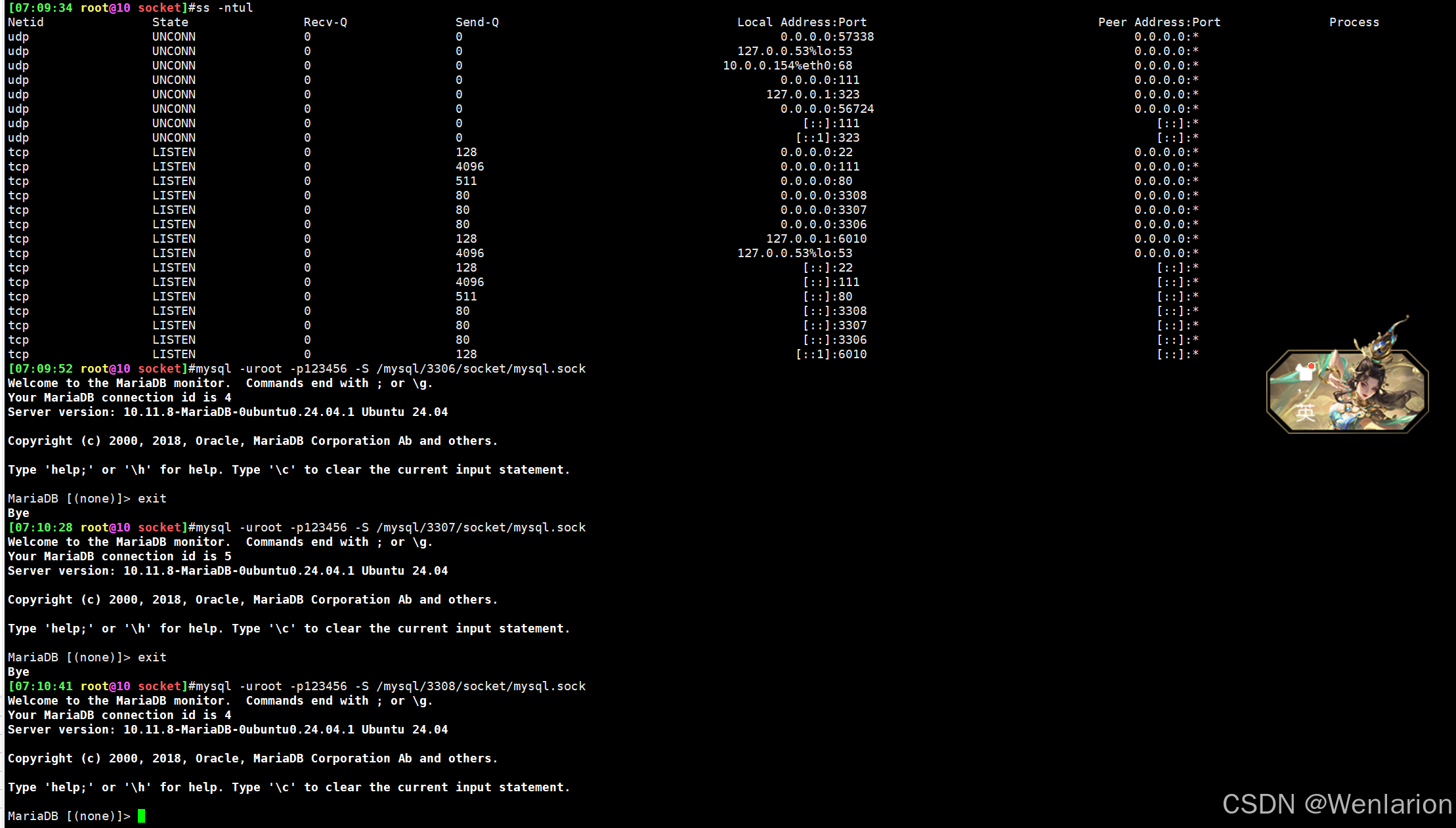
MySQL的安全加固措施
在Linux系统上安装完MySQL后,为了保障数据库的安全性,需要采取以下加固措施:
使用强密码策略:
设置复杂且不易猜测的root密码,并定期更换密码。
为其他数据库用户分配最低权限,避免给予过多的权限。
禁用不必要的服务和插件:
禁用未使用的MySQL服务和插件,以减小攻击面。
定期检查和更新MySQL的配置文件,确保只启用必要的功能。
配置防火墙:
在Linux系统上配置防火墙,限制对MySQL端口的访问。
只允许必要的IP地址或网络范围与MySQL服务器建立连接。
开启审计日志:
启用MySQL的审计日志功能,记录数据库的操作活动。
定期审查审计日志,及时发现并响应潜在的安全事件。
使用TLS/SSL加密:
配置MySQL服务器和客户端使用TLS/SSL加密进行通信。
确保数据在传输过程中的机密性和完整性。
定期备份数据:
配置定期备份数据库,并将备份数据存储在安全的位置。
在发生数据丢失或损坏时,能够及时恢复数据。
MySQL配置文件总结
MySQL的配置文件(如my.cnf或my.ini)用于配置MySQL服务器的各种参数和选项。以下是一些常见的配置选项及其作用:
[mysqld] 部分:
port:指定MySQL服务器监听的端口号。
basedir:指定MySQL的安装目录。
datadir:指定MySQL数据文件的存储目录。
character-set-server:设置MySQL服务器的默认字符集。
collation-server:设置MySQL服务器的默认校对规则。
max_connections:设置MySQL服务器允许的最大连接数。
innodb_buffer_pool_size:设置InnoDB存储引擎的缓冲池大小。
[client] 部分:
port:指定客户端连接MySQL服务器时使用的端口号。
default-character-set:设置客户端的默认字符集。
[mysql] 部分:
default-character-set:设置mysql客户端工具的默认字符集。
请注意,配置文件的具体内容和选项可能因MySQL版本和发行版的不同而有所差异。因此,在修改配置文件之前,建议查阅MySQL的官方文档或相关资源,以确保正确配置。
4. 掌握如何获取SQL命令的帮助,基于帮助完成添加testdb库,字符集utf8, 排序集合utf8_bin.创建host表,字段(id,host,ip,cname等)
为了完成这些任务,首先需要了解如何获取SQL命令的帮助,其次基于这些帮助来创建数据库和表。以下是详细步骤:
1. 获取SQL命令的帮助
使用MySQL命令行客户端的帮助命令
查看命令语法和选项:
在MySQL命令行客户端中,你可以使用 \h 或 \help 后跟命令名来查看特定命令的语法和选项。例如,要查看 CREATE DATABASE 命令的帮助,可以输入:
\h CREATE DATABASE;或者
HELP CREATE DATABASE;查看系统变量、函数、状态变量等:
使用 SHOW 命令可以查看系统变量、函数、状态变量等。例如,要查看字符集和排序规则,你可以输入:
SHOW VARIABLES LIKE 'character_set%';
SHOW COLLATION LIKE 'utf8%';使用官方文档
MySQL 官方文档提供了详细的SQL命令和语法描述。你可以在 MySQL 官方文档 中查找你需要的帮助。
2. 创建数据库 testdb,字符集 utf8,排序规则 utf8_bin
根据MySQL的语法,你可以使用 CREATE DATABASE 命令来创建数据库,并指定字符集和排序规则。
CREATE DATABASE testdb
CHARACTER SET utf8
COLLATE utf8_bin;3. 创建 host 表,字段(id, host, ip, cname, city)
在创建表之前,先切换到 testdb 数据库:
USE testdb;然后,使用 CREATE TABLE 命令来创建 host 表,并定义字段及其数据类型。
CREATE TABLE host (
id INT AUTO_INCREMENT PRIMARY KEY,
host VARCHAR(255) NOT NULL,
ip VARCHAR(45) NOT NULL,
cname VARCHAR(255) DEFAULT NULL,
city VARCHAR(255) DEFAULT NULL
);你可以使用以下命令来验证数据库和表是否已成功创建:
-- 查看所有数据库
SHOW DATABASES;
-- 使用 testdb 数据库
USE testdb;
-- 查看所有表
SHOW TABLES;
-- 查看 host 表的结构
DESCRIBE host;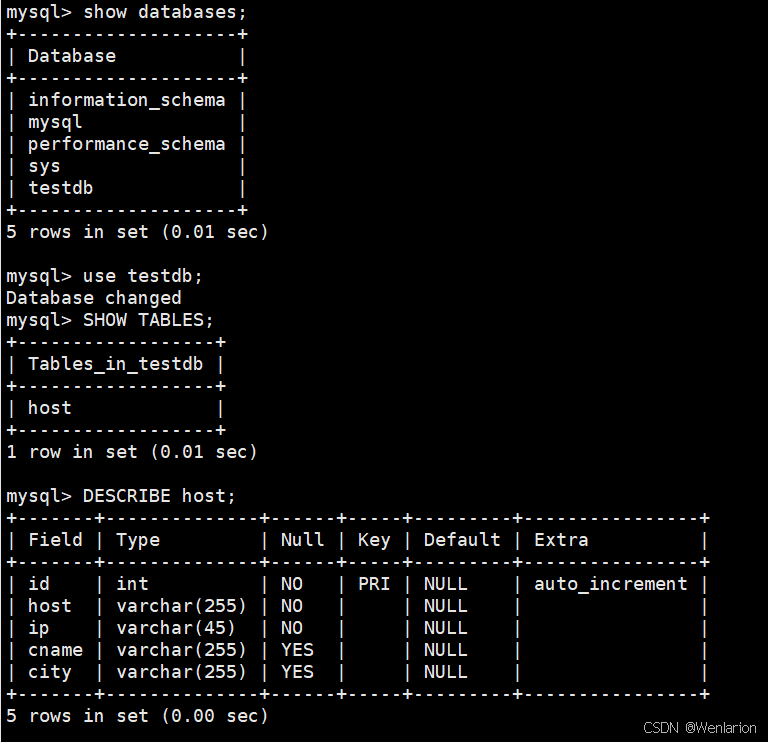
5. 根据表扩展出几个语句,完成总结DDL, DML的用法,并配上示例。
DDL(数据定义语言)与 DML(数据操作语言)详细用法总结及示例(基于host表)
DDL(数据定义语言)
DDL主要用于定义、修改和删除数据库中的对象,如表、索引、视图等。以下是DDL的详细用法及基于host表的示例。
1. 创建表(CREATE TABLE)
用于创建一个新的表。
CREATE TABLE host (
id INT AUTO_INCREMENT PRIMARY KEY, -- 自增主键
host VARCHAR(255) NOT NULL, -- 主机名,非空
ip VARCHAR(45) NOT NULL, -- IP地址,非空
cname VARCHAR(255), -- 别名
city VARCHAR(255) -- 城市
);2. 修改表结构(ALTER TABLE)
用于修改现有表的结构,如添加、删除或修改列。
添加列
ALTER TABLE host
ADD COLUMN country VARCHAR(255); -- 添加一个国家字段
修改列
ALTER TABLE host
MODIFY COLUMN cname VARCHAR(500); -- 修改cname字段的长度为500
注意:在某些数据库系统中(如MySQL),MODIFY关键字可能被省略,直接使用ALTER和CHANGE关键字。
删除列
ALTER TABLE host
DROP COLUMN cname; -- 删除cname字段3. 删除表(DROP TABLE)
用于删除一个表及其所有数据。
DROP TABLE host; -- 删除host表4. 创建索引(CREATE INDEX)和 删除索引(DROP INDEX)
虽然不直接属于表定义的一部分,但索引对于提高查询性能非常重要。
CREATE INDEX idx_city ON host(city); -- 在city字段上创建索引
DROP INDEX idx_city ON host; -- 删除在city字段上的索引注意:不同数据库系统对索引的创建和删除语法可能有所不同。
5、创建视图(CREATE VIEW)和删除视图(DROP VIEW)
视图是虚拟表,基于SQL查询的结果集。
CREATE VIEW host_city_view AS SELECT host, city FROM host; #基于host表创建视图
DROP VIEW host_city_view;#删除host表视图DML(数据操作语言)
DML主要用于对数据库中的数据进行增删改查。以下是表和视图的DML详细用法的示例。
1. 表插入数据(INSERT INTO)
INSERT INTO host (host, ip, cname, city)
VALUES ('www.example.com', '192.168.1.1', 'Example Company', 'New York');2. 表和视图查询数据(SELECT)
查询所有记录
SELECT * FROM host;
查询特定条件的记录
SELECT * FROM host WHERE city = 'New York';
选择特定列
SELECT host, ip FROM host;3. 表和视图更新数据(UPDATE)
UPDATE host
SET cname = 'Updated Example Company'
WHERE host = 'www.example.com';4. 表删除数据(DELETE FROM)
DELETE FROM host
WHERE host = 'www.example.com';5、事务处理
DML操作通常涉及事务处理,以确保数据的一致性和完整性。事务由一系列操作组成,这些操作要么全部成功,要么全部失败。
--开始事务
START TRANSACTION;
--提交事务
COMMIT;
--回滚事务
ROLLBACK;例如,您可以在一个事务中插入和更新数据:
START TRANSACTION;
INSERT INTO host (host, ip, cname, city)
VALUES ('www.newsite.com', '192.168.1.2', 'New Site', 'Los Angeles');
UPDATE host
SET cname = 'Renamed Example Company'
WHERE host = 'www.oldsite.com';
COMMIT; -- 提交事务,所有操作生效
-- 或者
-- ROLLBACK; -- 回滚事务,所有操作撤销总结
DDL和DML是数据库管理的两个核心组成部分。DDL用于定义和管理数据库结构,包括表、视图、索引的创建、修改和删除。DML则用于对数据库中的数据进行增删改查操作,并通常涉及事务处理以确保数据的一致性和完整性。通过掌握这些基本的SQL语句,您可以有效地管理和操作数据库中的数据。
6. 总结mysql架构原理和总结myisam和Innodb存储引擎的区别。
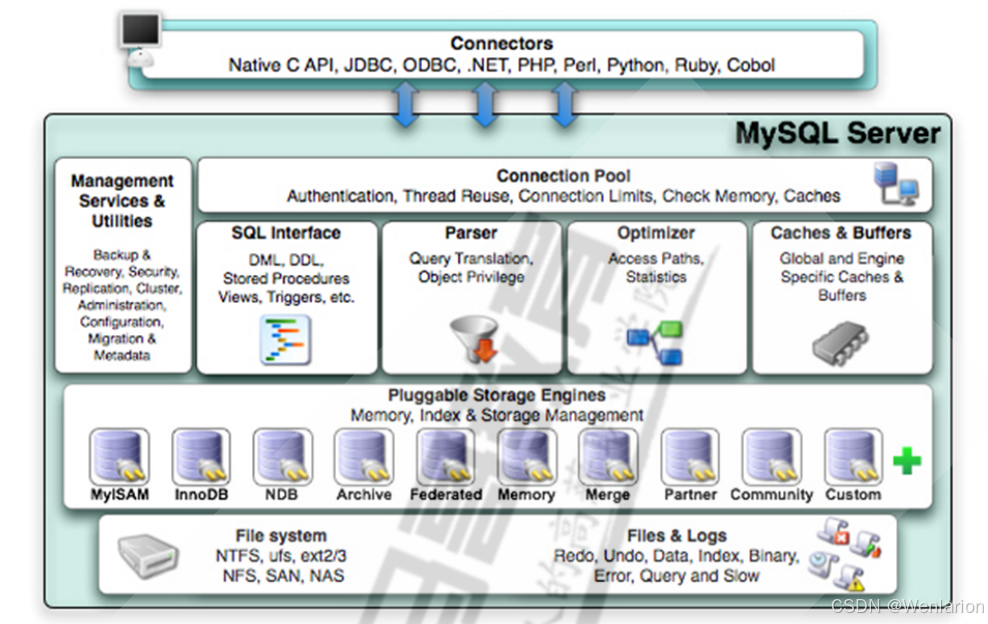
MySQL架构原理总结
MySQL的架构原理主要基于其分层设计,这种设计使得MySQL能够高效地处理各种数据库操作。MySQL的架构可以分为以下几个主要层次:
连接层:
负责处理客户端的连接请求,包括连接处理、身份验证和安全性等。
提供了与C/S程序的交互接口。
核心服务层(SQL Layer):
MySQL的核心部分,负责处理所有与数据库操作相关的逻辑。
包括权限判断、SQL解析、查询优化、查询缓存处理以及所有内置函数(如日期、时间、数学运算、加密等)的执行。
存储引擎提供的功能(如存储过程、触发器、视图等)也集中在这一层。
存储引擎层(StorEngine Layer):
负责数据的存储和检索操作。
MySQL支持多种存储引擎,如InnoDB、MyISAM等,每种存储引擎都有自己的优点和适用场景。
服务器通过存储引擎API与存储引擎交互,这个接口隐藏了各个存储引擎的不同之处,对查询层尽可能透明。
数据存储层:
将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互。
实际上,这一层涉及到底层的数据存储和管理,包括磁盘I/O操作、数据块管理等。
MySQL的这种分层设计使得其具有很好的扩展性和灵活性。例如,通过更换不同的存储引擎,可以轻松地调整数据库的性能和特性,以满足不同的应用需求。
MyISAM和InnoDB存储引擎的区别
MyISAM和InnoDB是MySQL中两种常用的存储引擎,它们在许多方面都存在显著的差异:
事务支持:
InnoDB支持ACID事务,可以保证数据的完整性和一致性。
MyISAM则不支持事务,因此无法进行回滚和提交等事务控制操作。
外键约束:
InnoDB支持外键约束,可以在数据库层面保证数据的完整性。
MyISAM则不支持外键约束。
锁机制:
InnoDB支持行级锁定,只锁定需要修改的行,提高了并发性能。
MyISAM则使用表级锁,当对表进行修改时,其他用户无法对同一表进行读写操作。
索引结构:
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和索引绑在一起的。
MyISAM是非聚集索引,索引和数据文件是分离的,索引保存的是数据文件的指针。
全文索引:
MyISAM支持全文索引,可以在文本数据上进行快速的全文搜索。
InnoDB在5.7版本之前不支持全文索引,但5.7及以后的版本已经支持。
崩溃恢复:
InnoDB支持自动崩溃恢复,可以在数据库异常终止后自动恢复数据。
MyISAM在崩溃后无法安全恢复,可能会导致数据丢失。
适用场景:
MyISAM适用于读取操作较多、写入操作较少的应用场景,如web应用程序中的静态内容存储。
InnoDB则适用于需要高并发、数据完整性和事务支持的应用场景,如金融系统、在线交易系统等。
综上所述,MyISAM和InnoDB各有其优点和适用场景。在选择存储引擎时,需要根据实际的应用需求和性能要求来进行权衡和选择。
7. 总结mysql索引作用,同时总结哪些查询不会使用到索引。
MySQL索引作用
MySQL索引在数据库管理中扮演着至关重要的角色,其主要作用包括:
提高查询性能:索引可以显著加快数据库的查询速度。通过使用索引,MySQL能够快速定位到满足查询条件的数据行,减少了全表扫描的时间和IO操作的开销,从而提高了查询的效率。
加速排序:当查询需要按特定列进行排序时,索引可以为排序操作提供有序的数据,避免了数据库的临时排序操作,从而加快了排序的速度。
优化连接操作:在连接查询中,索引可以帮助MySQL快速定位到连接条件匹配的数据行,加快连接操作的速度。特别是在涉及到大表的连接查询时,使用合适的索引可以显著提升性能。
约束数据完整性:主键索引和唯一索引可以确保数据的唯一性,避免出现重复或空值的情况。通过定义合适的索引,可以在数据库层面上对数据的完整性进行约束,提高数据的质量和准确性。
加速全文搜索:MySQL提供了全文索引功能,用于在文本字段上进行全文搜索。全文索引可以加速对文本内容的搜索操作,提供更高效的全文检索能力。
不会使用到索引的查询情况
尽管索引能够显著提高查询性能,但在某些情况下,查询可能无法利用索引。以下是一些常见的不会使用到索引的查询情况:
数据表太小:如果数据表非常小,只有几行数据,那么使用索引的开销可能会大于不使用索引的开销。在这种情况下,MySQL可能会选择全表扫描而不是使用索引。
函数操作:在查询条件中对索引列使用函数(如日期函数、字符串操作函数、数学函数等)会导致索引失效。例如,使用DATE_FORMAT(date_column, '%Y-%m-%d')这样的查询会导致数据库无法使用索引。
非常规操作符:类似于模糊查询(如LIKE '%keyword%')、NOT或<>操作符、自定义函数、正则表达式等非常规操作符,在查询过程中可能无法使用索引。
数据类型不匹配:如果查询语句中的数据类型与索引列的数据类型不一致,那么无法使用索引。例如,在使用索引的整型列上进行字符类型的比较,或在使用索引的字符串列上进行数值类型的比较等情况。
隐式转换:在查询条件中,如果MySQL需要对索引列进行隐式类型转换(如将字符串类型的索引列与整数类型的常量进行比较),那么索引可能会失效。
表达式不可分解:如果查询语句中的表达式不能被拆分成可索引的部分,那么可能无法使用索引。例如,在WHERE子句中使用复杂的计算或函数组合。
模糊查询前缀不匹配:虽然模糊查询本身可能导致索引失效,但如果模糊查询是基于前缀匹配的(如LIKE 'keyword%'),则仍然可以使用索引。然而,如果模糊查询是基于后缀或中间匹配的(如LIKE '%keyword'或LIKE '%key%word%'),则索引通常会失效。
8. 总结事务ACID事务特性。
事务的ACID特性是数据库管理系统中保证事务正确执行的重要基石。以下是对ACID特性的详细总结:
一、原子性(Atomicity)
原子性指事务是不可分割的原子操作单元,即事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。事务在执行过程中,如果发生任何错误或异常,系统会撤销事务已经执行的操作,使数据回滚到事务开始前的状态,从而确保数据的一致性。
二、一致性(Consistency)
一致性指事务将数据库从一种状态转变为下一种一致的状态。在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。事务必须保证数据库从一个一致性状态转换到另一个一致性状态,即事务执行的结果必须满足数据库的完整性约束。例如,在银行账户的转账操作中,转出账户的余额减少和转入账户的余额增加必须同时发生,以保持数据库的一致性。
三、隔离性(Isolation)
隔离性指事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。数据库系统中的隔离级别是指多个事务并发执行时,一个事务对数据的读写操作受到其他事务影响程度的程度。隔离级别越高,事务之间的相互影响越小,但也可能导致系统性能下降。常见的隔离级别包括:
读未提交(Read Uncommitted):最低的隔离级别,一个事务可以读取另一个事务未提交的数据修改,但可能会导致脏读。
读已提交(Read Committed):一个事务只能读取到另一个事务已经提交的数据,避免了脏读,但仍可能导致不可重复读和幻读问题。
可重复读(Repeatable Read):确保在同一个事务中多次读取同样的数据时,其值保持不变。避免了不可重复读,但仍可能出现幻读问题。
串行化(Serializable):最高的隔离级别,通过强制事务串行执行来避免并发问题。保证了所有并发事务的执行效果与串行执行的效果相同,从而避免了脏读、不可重复读和幻读的问题。
四、持久性(Durability)
持久性指一旦事务提交,其所做的修改会永久保存在数据库中,并不会因系统故障导致数据的丢失。事务一旦提交成功,对数据库的修改就是永久的,即使系统崩溃或重启,也能恢复到提交后的状态。这通常通过将事务的操作持久化到非易失性存储介质(如硬盘)来实现。
综上所述,事务的ACID特性确保了数据库在并发环境中的正确性和可靠性。原子性保证了事务的不可分割性;一致性保证了数据库状态的正确性;隔离性避免了事务之间的干扰;持久性确保了事务提交后数据的永久保存。
9. 总结事务日志工作原理。
MySQL事务日志的工作原理是确保数据库事务的四大特性(原子性、一致性、隔离性、持久性)得以实现的关键机制。以下是MySQL事务日志工作原理的详细总结:
一、事务日志类型
MySQL中的事务日志主要包括两种:重做日志(Redo Log)和回滚日志(Undo Log)。此外,还有二进制日志(Binlog)用于记录所有更改数据的语句,但它更多用于数据恢复和主从复制,而非直接的事务控制。
二、重做日志(Redo Log)
作用:
保证事务的持久性。
在系统崩溃时,能够恢复已提交但未写入数据文件的事务。
组成:
Redo Log Buffer:内存中的日志缓冲,数据首先写入这里。
Redo Log File:磁盘上的重做日志文件,持久化存储。
写入机制:
当事务提交时,数据首先写入Redo Log Buffer。
根据配置(如innodb_flush_log_at_trx_commit),Redo Log Buffer中的数据会按照一定的规则写入Redo Log File。
写入过程可能涉及操作系统的内核空间缓冲区(OS Buffer),并通过fsync()函数确保数据持久化到磁盘。
持久化策略:
innodb_flush_log_at_trx_commit变量控制日志刷新策略:
0:每秒刷新一次到磁盘。
1:每次提交事务都刷新到磁盘(默认)。
2:每次提交事务只写入OS Buffer,每秒刷新一次到磁盘。
LSN机制:
LSN(Log Sequence Number)表示日志的逻辑序列号,用于跟踪日志的写入进度。
Redo Log写入是顺序的,一个文件写满后会写入另一个文件,循环使用。
三、回滚日志(Undo Log)
作用:
保证事务的原子性。
实现多版本并发控制(MVCC)。
存储方式:
采用段(Segment)的方式管理,存储在共享数据表空间中(默认为ibdata1文件),或通过innodb_file_per_table参数存储在每个数据表的.ibd文件中。
写入机制:
在操作任何数据之前,先将数据的旧值写入Undo Log。
如果事务失败或执行回滚操作,可以利用Undo Log将数据恢复到事务开始之前的状态。
MVCC机制:
Undo Log保存了事务当前的数据快照,供其他并发事务进行快照读。
实现了事务的隔离性,使得并发事务能够读取到一致的数据视图。
四、事务日志的协同工作
事务提交过程:
当事务提交时,MySQL首先更新Buffer Pool中的数据页,并将其设置为脏页。
同时,将事务的修改记录写入Redo Log Buffer和Undo Log。
根据配置,Redo Log Buffer中的数据会被刷新到Redo Log File。
最后,Server层将事务的操作性修改写入Binlog(如果启用了Binlog)。
故障恢复:
在系统崩溃或断电后,MySQL可以利用Redo Log恢复已提交但未写入数据文件的事务。
如果事务未提交但已写入Redo Log Buffer,则根据Undo Log进行回滚操作。
性能优化:
通过合理配置innodb_log_buffer_size、innodb_log_file_size等参数,可以优化事务日志的性能和存储效率。
使用WAL(Write-Ahead Logging)技术,先写日志再写磁盘,提高了数据持久化的性能和可靠性。
综上所述,MySQL事务日志的工作原理是通过重做日志和回滚日志的协同工作,确保事务的四大特性得以实现。同时,通过合理的配置和优化策略,可以提高数据库的性能和可靠性。
10. 总结mysql日志类型,并说明如何启动日志。
MySQL日志是数据库管理和维护中的重要工具,它们记录了数据库的各种活动和状态,有助于跟踪、调试和优化数据库性能。以下是MySQL的主要日志类型及其启动方法:
一、MySQL日志类型
错误日志(Error Log)
功能:记录MySQL服务器在启动、运行过程中发生的错误和异常情况,如启动错误、语法错误等。
重要性:是MySQL中最重要的日志之一,对于排查数据库故障至关重要。
通用日志(General Query Log)
功能:记录所有到达MySQL服务器的SQL语句,包括用户的登录信息、查询语句(SELECT、INSERT、UPDATE、DELETE等)。
用途:用于分析用户行为和查询性能,但可能会对性能产生影响,特别是在高负载环境下。
慢查询日志(Slow Query Log)
功能:记录执行时间超过指定阈值的SQL语句。
用途:帮助找出执行时间较长的查询,以便进行性能优化。
二进制日志(Binary Log)
功能:记录所有对数据库的更改操作,包括数据修改、表结构变更等,但不记录查询语句。
用途:用于数据恢复、主从复制等场景。
事务日志(Transaction Log/Redo Log)
功能:记录正在进行的事务的更改操作。
用途:用于保证数据库的ACID特性,并支持崩溃恢复。
二、如何启动MySQL日志
编辑配置文件
通常,MySQL的配置文件名为my.cnf或my.ini,具体位置根据系统而定。
使用文本编辑器打开配置文件,找到[mysqld]部分。
添加日志配置
错误日志:错误日志通常是默认开启的,但可以通过log-error参数指定日志文件的位置。例如:
[mysqld]
log-error=/var/log/mysql/error.log通用日志:通过general_log和general_log_file参数启用和指定通用日志文件。例如:
[mysqld]
general_log=1
general_log_file=/var/log/mysql/general.log慢查询日志:通过slow_query_log、slow_query_log_file和long_query_time参数启用和配置慢查询日志。例如:
[mysqld]
slow_query_log=1
slow_query_log_file=/var/log/mysql/slow.log
long_query_time=2 # 设置为2秒,表示执行时间超过2秒的查询将被记录二进制日志:通过log-bin参数启用二进制日志,并可以通过expire_logs_days参数设置日志的保留天数。例如:
[mysqld]
log-bin=mysql-bin
expire_logs_days=7 # 设置为7天,表示保留7天的二进制日志事务日志:事务日志通常由MySQL内部自动管理,无需手动启用。
重启MySQL服务
保存配置文件后,需要重启MySQL服务以使配置生效。可以使用如下命令(以Linux系统为例):
sudo service mysql restart或者使用:
sudo systemctl restart mysql验证日志是否启用
可以通过SQL命令或查看日志文件来验证日志是否已成功启用。
SHOW VARIABLES LIKE '%log%' ;#查看与日志相关的配置参数和状态。三、注意事项
性能影响:开启某些日志(如通用日志和慢查询日志)可能会对MySQL的性能产生影响,特别是在高负载环境下。因此,在生产环境中应谨慎使用,并根据需要进行开启和关闭。
日志文件管理:日志文件可能会占用大量的磁盘空间。因此,应定期清理和管理日志文件,以避免磁盘空间耗尽。
安全性:查询日志中可能会包含敏感信息(如密码)。因此,应确保只有授权的人员可以访问查询日志文件。
11. 总结二进制日志的不同格式的使用场景。
MySQL二进制日志(binlog)记录了所有更新数据库的语句(如DDL和DML语句),并以二进制的形式保存在磁盘中,是MySQL中比较重要的日志类型。MySQL提供了三种不同的二进制日志格式,分别是Statement、Row和Mixed,它们各自有不同的使用场景。
1. Statement格式
使用场景:
主要适用于修改操作比较少的场景,或者当数据表结构相对简单,且复制的数据量不大时。
在某些情况下,如果主从库之间的数据一致性要求不是特别高,或者可以接受由于SQL执行的不确定性而导致的数据不一致(如使用随机函数或时间函数等操作时),也可以选择使用Statement格式。
优点:
日志记录清晰易读,日志量少,对I/O影响较小。
在某些情况下,复制效率较高,因为只需要复制SQL语句本身。
缺点:
在某些情况下,从库的日志复制可能会出错,如当SQL语句中包含不确定性函数或操作时。
由于SQL语句的执行可能受到多种因素的影响(如服务器的配置、当前的负载等),因此复制的一致性可能无法得到完全保证。
2. Row格式
使用场景:
主要适用于数据更新频繁、数据表结构复杂或数据量较大的场景。
当需要确保主从库之间的数据一致性非常高时,建议选择Row格式。
优点:
记录每一行数据的变化细节,可以确保复制的一致性。
适用于复杂的查询和更新操作,以及需要确保数据精确复制的场景。
缺点:
日志量大,对I/O影响较大。
在某些情况下,复制效率可能较低,因为需要复制每一行数据的变化。
3. Mixed格式
使用场景:
Mixed格式是Statement和Row格式的混合体,可以根据具体的操作选择最适合的格式。
适用于大多数情况下的复制需求,特别是当无法确定哪种格式更适合时。
优点:
尽量利用Statement和Row两种模式的优点,而避开它们的缺点。
可以根据具体的操作自动选择最合适的格式,提高复制的效率和一致性。
缺点:
在某些特定情况下,可能需要手动调整日志格式以获得最佳性能。
综上所述,MySQL二进制日志的不同格式各有优缺点和使用场景。在选择日志格式时,需要根据具体的业务需求、数据特点和系统负载进行权衡和优化。例如,在数据更新频繁、数据表结构复杂或数据量较大的场景下,建议选择Row格式以确保复制的一致性;而在修改操作比较少、数据表结构相对简单或复制的数据量不大的场景下,可以选择Statement格式以提高复制效率。如果需要兼顾效率和一致性,可以考虑使用Mixed格式。
12. 总结mysql备份类型,并基于mysqldump, xtrabackup完成数据库备份与恢复验证。
MySQL备份类型总结
MySQL的备份可以分为以下几种主要类型:
逻辑备份、物理备份:
逻辑备份是指通过工具将数据导出为SQL文件,保存的是数据库的结构和数据的SQL脚本。
主要工具:mysqldump、mysqlpump。
优点:文件为纯文本格式,易于读取和编辑;可以跨平台使用,适用于不同MySQL版本之间的数据迁移。
缺点:备份速度较慢,特别是对于大规模数据库;恢复时间较长,因为需要重新执行SQL语句创建表并插入数据。
物理备份是指直接复制数据库的数据文件,备份的是数据库文件。
主要工具:xtrabackup、cp命令。
优点:备份和恢复速度快;占用的系统资源少,适合大规模数据库。
缺点:操作相对复杂,特别是增量备份的管理;备份文件依赖于操作系统和MySQL的版本,不适合跨平台使用。
热备份、冷备份、温备份:
热备份(Hot Backup):可以在数据库运行中直接备份,对正在运行的数据库操作没有任何的影响,数据库的读写操作可以正常执行(如xtrabackup)。
冷备份(Cold Backup):必须在数据库停止的情况下进行备份,数据库的读写操作不能执行(如使用cp命令备份关闭的数据库)。
温备份(Warm Backup):在数据库运行中进行的,但是会对当前数据库的操作有所影响,备份时仅支持读操作,不支持写操作。
完全备份、增量备份、差异备份:
完全备份:备份所有数据,恢复时只需恢复一个备份文件,但备份和恢复时间较长,占用存储空间较大。
增量备份:仅备份自上次备份以来的变化数据,备份和恢复时间较短,占用存储空间较小,但恢复时需要按顺序应用多个备份文件。
差异备份:备份自上次全量备份以来的所有变化数据,恢复时只需恢复全量备份和最后一次差异备份,简化了恢复过程,但备份文件可能较大。
冷备份和恢复:rocky系统主机1(10.0.0.8)到主机2(10.0.0.18)
#主机1数据库数据备份到本机和主机2
systemctl stop mysqld
cp -a /var/lib/mysql/ /data/
scp -r /var/lib/mysql/ 10.0.0.18:/data/
systemctl start mysqld
#主机2还原数据库
yum -y install mysql-server
cp /data/mysql/* /var/lib/mysql/ -l
chown -R mysql.mysql /var/lib/mysql/
systemctl start mysqld
主机1数据库备份数据
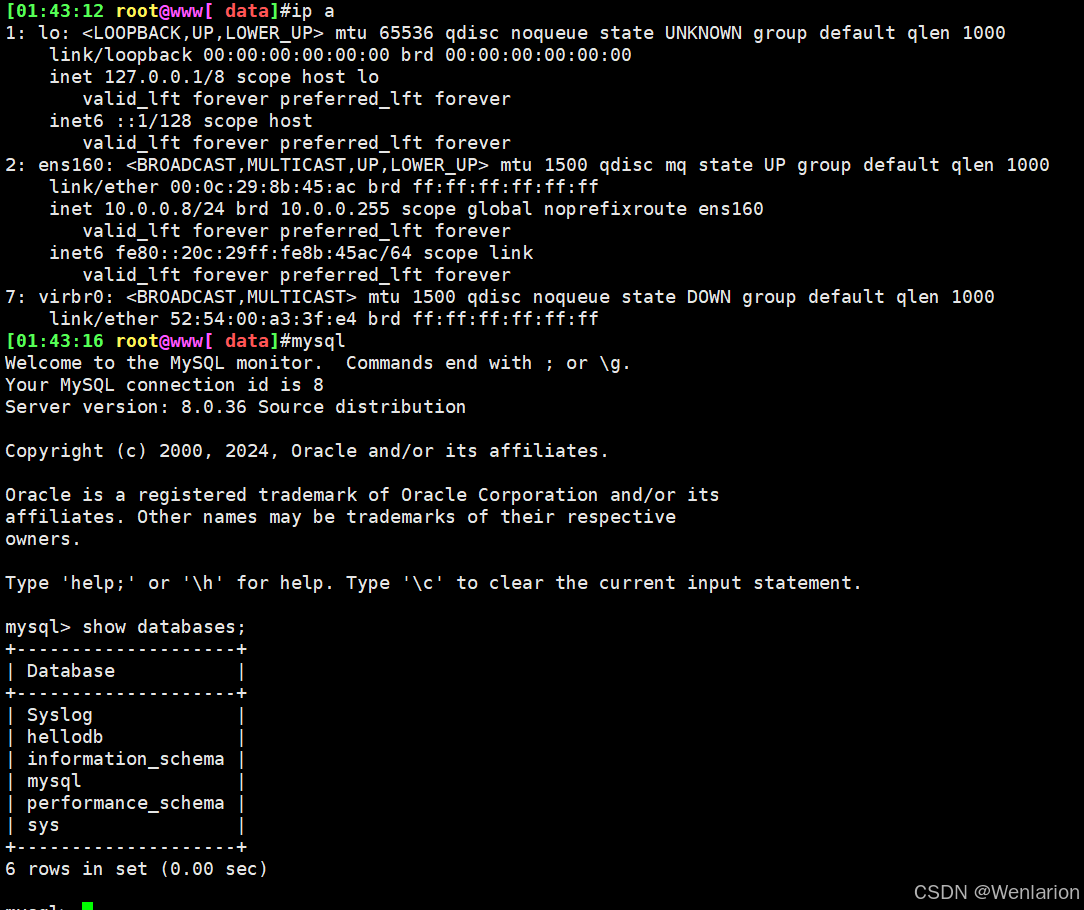
在主机2恢复主机1的数据库数据
#mysqldump完全备份和恢复
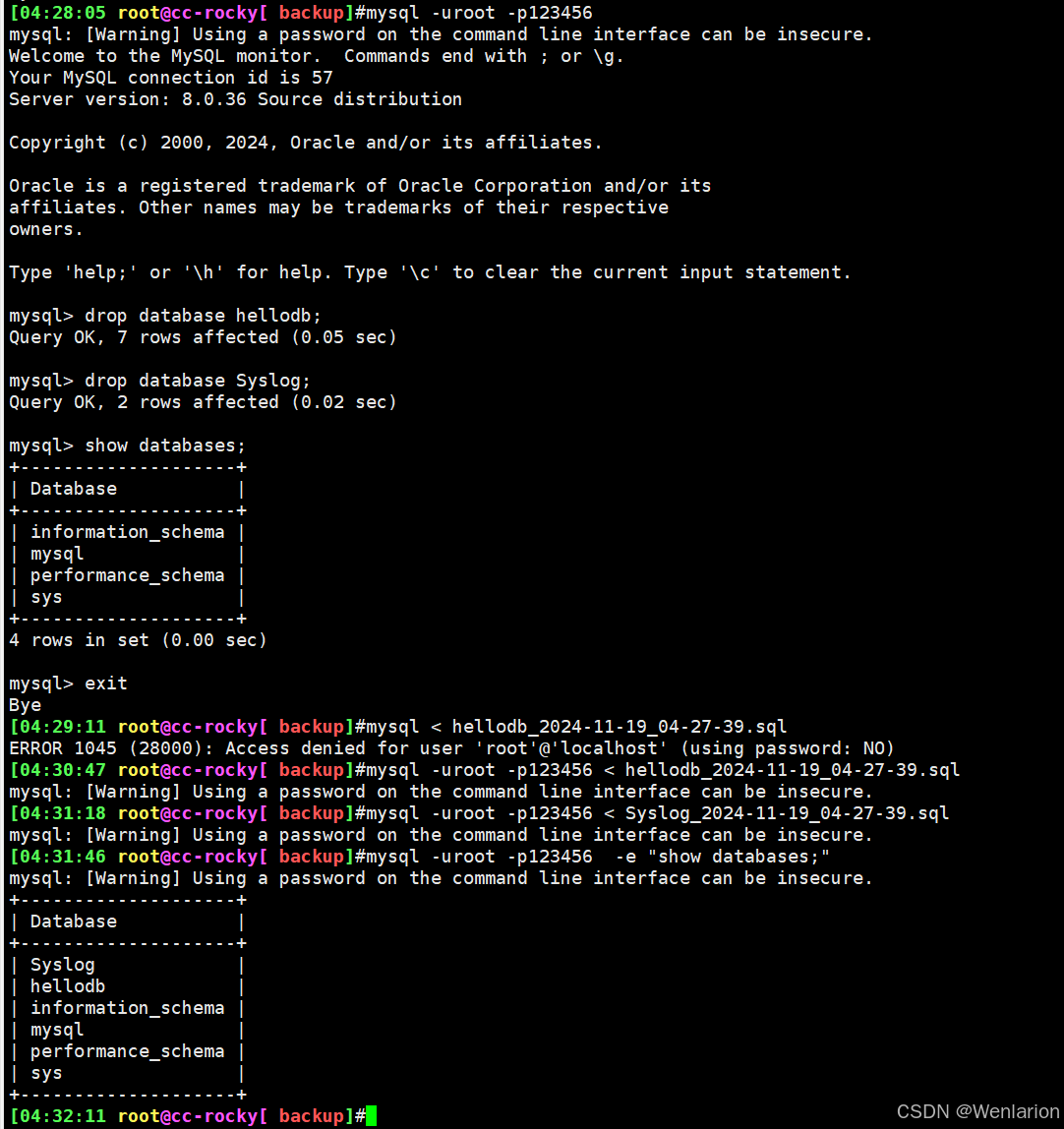
#1、编写分库备份脚本,运行脚本进行备份
vim backup_parts.sh
#!/bin/bash
for db in `mysql -uroot -p123456 -e 'show databases;' | grep -Evw 'information_schema|performance_schema|sys|Database|Warning'`; do
mysqldump -uroot -p123456 -B $db 2> /dev/null > /data/backup/${db}_`date +%F_%H-%M-%S`.sql;
done
bash backup_parts.sh
2、利用备份文件恢复数据库
mysql -uroot -p123456 < hellodb_2024-11-19_04-27-39.sql
mysql -uroot -p123456 < Syslog_2024-11-19_04-27-39.sql
#mysqldump结合二进制制日志实现误删数据的恢复
#1、在删除数据之前,将所有数据库完全备份
mysqldump -uroot -p123456 -A --source-data=2 > /data/backup/all.sql
#2、查看完全备份的二进制文件和位置,将误删数据的代码注释
head all.sql -n30
vim /var/lib/mysql/binlog.0000006
grep -in "drop" logbin.sql
:set nu
#3、在完全备份的基础上利用二进制日志进行备份
mysqlbinlog --start-position=1501241 /var/lib/mysql/binlog.000006 > /data/backup/logbin.sql
#4、安装顺序依次恢复数据
mysql -uroot -p123456 < all.sql
mysql -uroot -p123456 < logbin.sql完全备份恢复结果
 删除数据和恢复结果
删除数据和恢复结果
在完全备份之后插入数据,并删除表
在删除表之后,插入数据
进行还原后查看数据是否恢复
#xtrabackup完全备份:rocky系统主机1(10.0.0.8)到主机2(10.0.0.18)
#1、在主机1备份数据库文件,并拷贝给主机2
yum -y install percona-xtrabackup-80-8.0.35-31.1.el8.x86_64.rpm
xtrabackup -uroot -p123456 --backup --target-dir=/backup/base
scp -r /backup/ 10.0.0.18:/
#2、在主机2恢复主机1的数据库文件
yum -y install percona-xtrabackup-80-8.0.35-31.1.el8.x86_64.rpm
systemctl stop mysqld
rm -rf /var/lib/mysql/*
xtrabackup --prepare --target-dir=/backup/base
xtrabackup --copy-back --target-dir=/backup/base
chown -R mysql:mysql /var/lib/mysql
systemctl start mysqld完全备份恢复结果
#xtrabackup增量备份:rocky系统主机1(10.0.0.8)到主机2(10.0.0.18)
#1、在主机1备份数据库文件,并拷贝给主机2
#安装xtrabackup,完全备份
yum -y install percona-xtrabackup-80-8.0.35-31.1.el8.x86_64.rpm
xtrabackup -uroot -p123456 --backup --target-dir=/backup/base
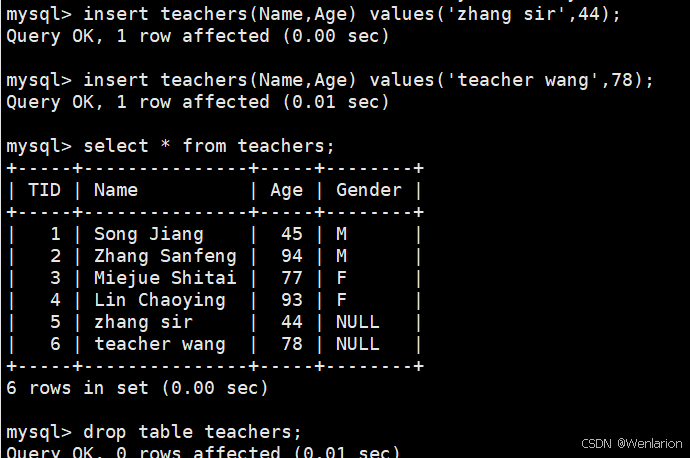
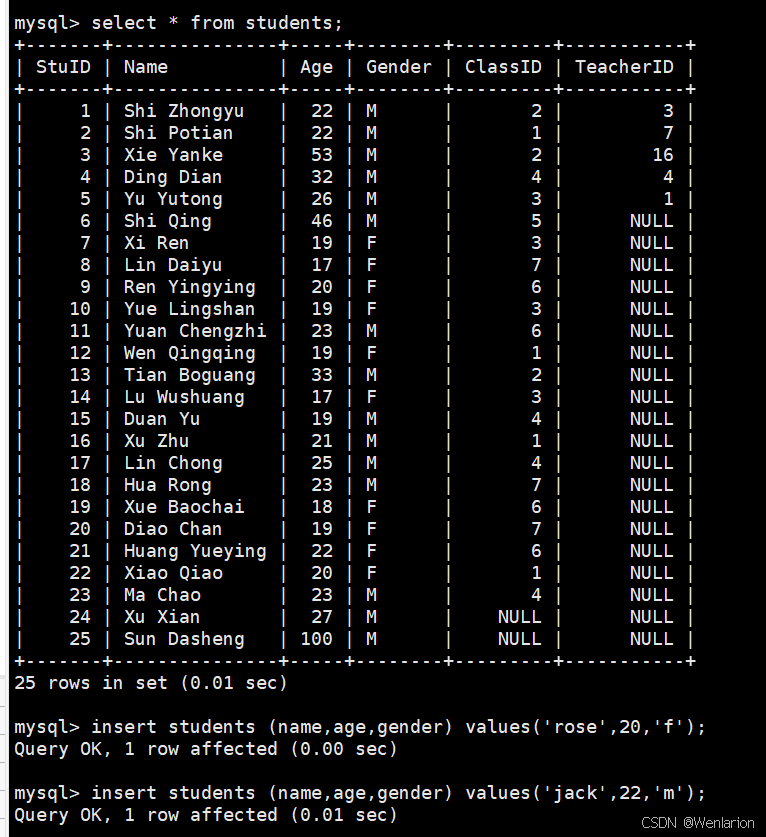
#修改数据库文件
insert students (name,age,gender) values('rose',20,'f');
#第一次增量备份
xtrabackup -uroot -p123456 --backup --target-dir=/backup/inc1 --incremental-basedir=/backup/base
#修改数据库文件
insert students (name,age,gender) values('jack',22,'m');
#第二次增量备份
xtrabackup -uroot -p123456 --backup --target-dir=/backup/inc2 --incremental-basedir=/backup/inc1
#将文件拷贝给目标主机
scp -r /backup/ 10.0.0.18:/
#2、在主机2恢复主机1的数据库文件
#安装xtrabackup,清空数据库文件
yum -y install percona-xtrabackup-80-8.0.35-31.1.el8.x86_64.rpm
systemctl stop mysqld
rm -rf /var/lib/mysql/*
#完全备份恢复预准备
xtrabackup --prepare --apply-log-only --target-dir=/backup/base
#数据库第一次和第二次增量备份恢复预准备
xtrabackup --prepare --apply-log-only --target-dir=/backup/base --incremental-dir=/backup/inc1
xtrabackup --prepare --target-dir=/backup/base --incremental-dir=/backup/inc2
#拷贝数据文件库文件
xtrabackup --copy-back --target-dir=/backup/base
#改变数据库文件属性,启动数据库
chown -R mysql:mysql /var/lib/mysql
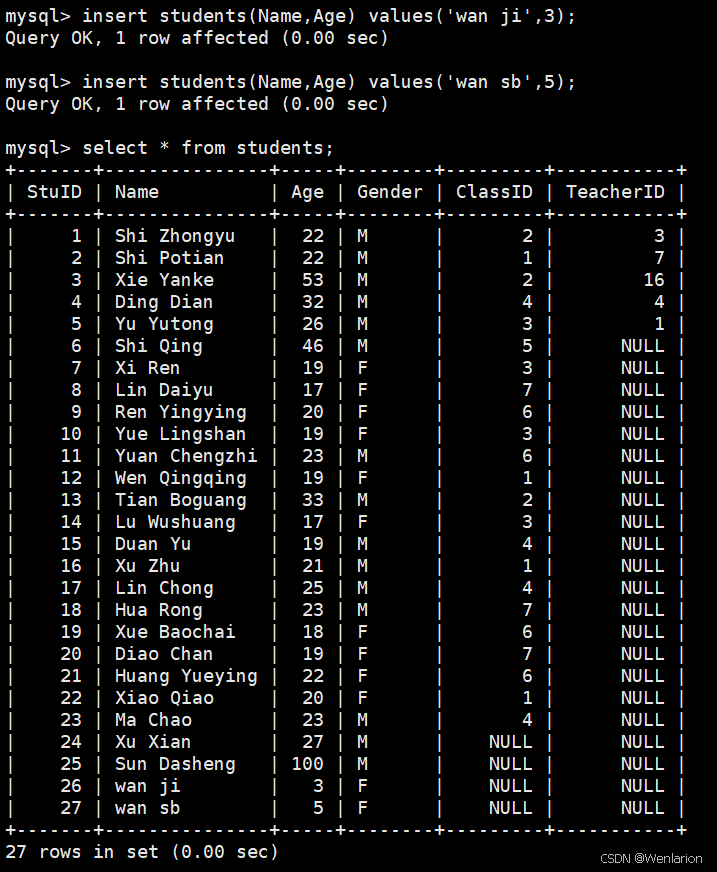
service mysqld start rocky系统主机1(10.0.0.8) 在第一次增量备份和第二次增量备份之后,分别向数据库hellodb中students表插入一行。
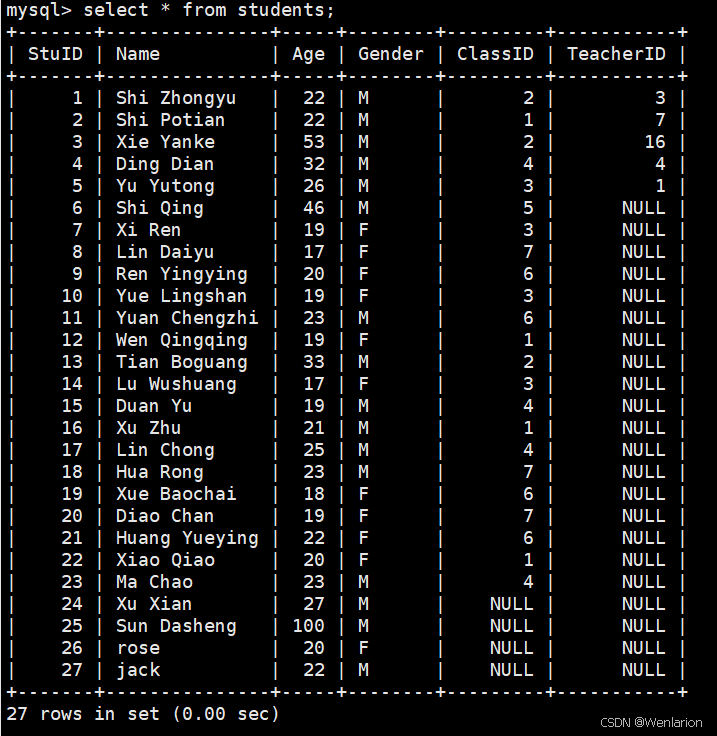
 rocky系统主机2(10.0.0.18) ,利用数据库hellodb中students表验证增量备份
rocky系统主机2(10.0.0.18) ,利用数据库hellodb中students表验证增量备份
13. 编写crontab,每天按表备份所有mysql数据。将备份数据放在以天为时间的目录下。基于xtrabackup,每周1,周5进行完全备份,周2到周4进行增量备份
#配置计划任务文件
vim /etc/crontab
* * * * 0,4 xtrabackup -uroot -p123456 --backup --target-dir=/backup/`date +%F`
* * * * 1-3 xtrabackup -uroot -p123456 --backup --target-dir=/backup/`date +%F` --incremental-basedir=/backup/`date +%F -d "yesterday"`
一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)