
mysql管理员运维指南
这样一来,非发起事务提交的客户端在查询数据时,所看到的数据就能够和发起事务提交的客户端保持一致,从而解决了在主库故障转移之后可能出现的幻读问题。在老主机上OFFLINE VIP,关闭数据库,卸载共享磁盘,然后在备机上挂载共享磁盘,启动数据库,ONLINE VIP ,对外提供服务。MGR 架构为MySQL 官方提供的原生高可用解决方案,主备库之间的事务日志通过改进的Paxos协议进行传输,通过相关参
一、mysql体系架构
- mysql体系架构情况
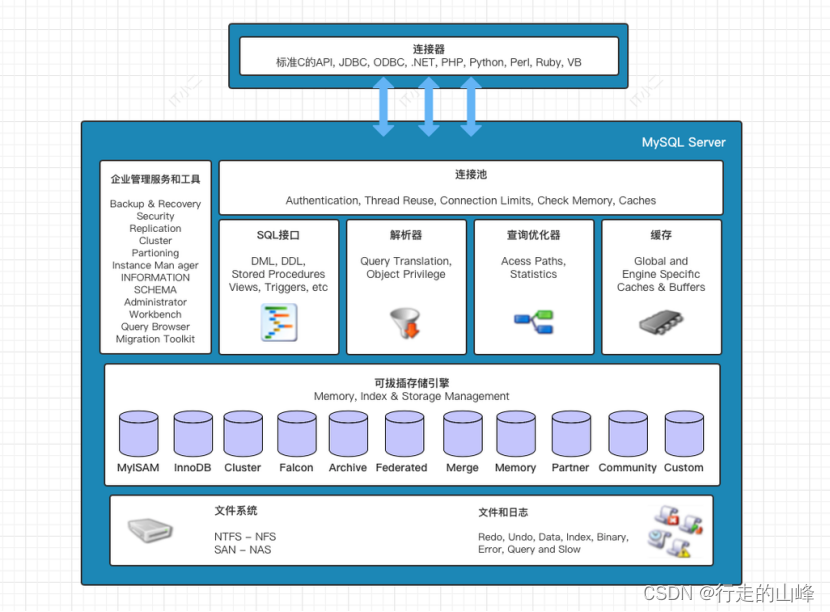
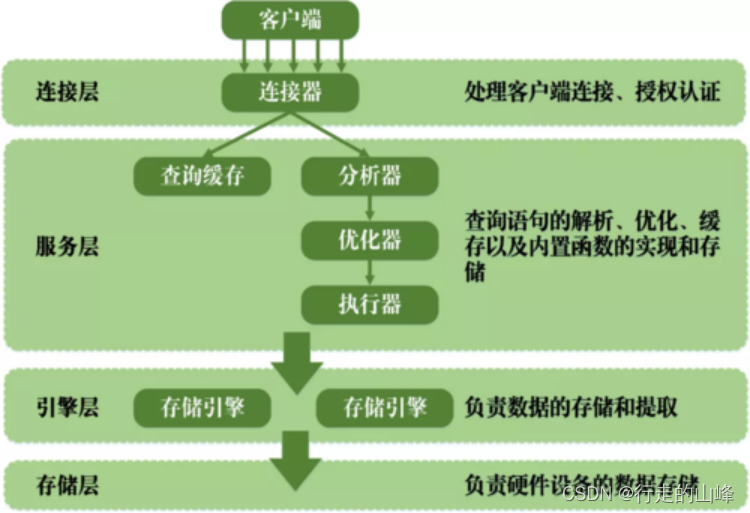
PS:mysql8.0移除查询缓存
- 主要mysql架构
单节点
RHCS架构基于红帽本地HA 软件、共享磁盘实现MySQL 数据库的本地高可用,可提供故障自动切换、数据切换前后一致性等功能。该架构底层基于VMWARE 虚拟机或物理机进行构建,需要使用共享存储。
主备机共享所有的数据,包括MySQL 数据库软件、数据库数据文件、数据库Binlog日志文件,数据只存储一份在共享存储中,对共享存储空间要求较大。
主机故障发生时,RHCS HA 软件可以通过状态判感知MySQL 实例异常,触发故障切换动作。在老主机上OFFLINE VIP,关闭数据库,卸载共享磁盘,然后在备机上挂载共享磁盘,启动数据库,ONLINE VIP ,对外提供服务。
由于是所有数据库是共享的,所以主备时无数据补齐过程,切换速度较快。
适用于OLTP,性能要求高,无异地容灾要求的业务场景。
一主一从,基于容器平台架构,可实现数据库快速交付、版本滚动升级、容量在线伸缩等功能要求。提供故障自动切换、读写分离等功能。且该架构支持多种数据库版本:5.6,5.7,8.0等,可根据业务需求进行版本灵活部署。通过分布式Zookeeper解耦各MySQL 组件间的通信交互过程,Gateway读写分离中间件作为业务访问的统一入口,可实现透明或非透明的读写分离功能。使用mysql半同步复制插件,配置为增强半同步。
适用于OLTP,无超大事务的业务场景。
一主两从,基于容器平台架构,可实现数据库快速交付、版本滚动升级、容量在线伸缩等功能要求。提供故障自动切换、读写分离(通过MySQL Router 中间件实现)等功能。该架构当前只支持MySQL 8.0 版本。使用mysql mgr组复制插件。
MGR 架构为MySQL 官方提供的原生高可用解决方案,主备库之间的事务日志通过改进的Paxos协议进行传输,通过相关参数配置可用实现主备库之间数据的强一致性,无脑裂、无数据丢失风险,RTO/RPO时间最短。
适用于OLTP,无大事务、对RTO/RPO要求高时间短,数据库可靠性要求高的业务场景。使用该架构时必须保证所有的业务表采用Innodb事务型存储引擎,数据表必须存在主键或非空唯一索引。
- mysql使用
- 数据库启停
方式1:
#保证事前进入数据目录cp support-files/mysql.server /etc/init.d/mysqld
Shell>service mysqld start #实际查看/etc/init.d,或使用systemctl start mysqld
Shell>service mysqld stop
方式2:
#进入mysql软件目录bin目录
Shell>./mysqld_safe --defaults-file=/etc/my.cnf --user=mysql &
Shell>mysqladmin -uroot -p shutdown
2.常见日志及其清理方式
mysql常用日志:
错误日志,查看相关错误,分三种级别,info,warning,error
慢日志:记录超过指定阈值(long_query_time)的sql
Binlog:记录数据变更,row,mixed,statment
通用日志:记录ip,用户及其操作sql,消耗大量磁盘空间及影响性能
清理方式:
日志目录使用率高问题处理
shell>df -h #查看目录使用率
#查看哪些日志较大,再清那些日志
Shell>du -sh /data/mysql-log/
Shell>ls -lh /data/mysql-log/binlog/
Shell>ls -lh /data/mysql-log/error/
Shell>ls -lh /data/mysql-log/slow/
#当发现日志占用较大,需经接口人确认再清理日志
#清理错误日志
Shell>cd /data/mysql-log/error/
shell> ll -lh
shell> mv mysql.err mysql.err-old --重命名错误日志
mysql>ll -lh --mysql.err-old依旧写入数据
#ps -ef|grep mysqld #记录sock路径
shell> mysqladmin -uroot -p -S /apps/run/mysql_3306/mysql.sock flush-logs #实际sock,刷新日志
shell> ll -lh #生成新mysql.err日志
Shell>tail -10f mysql.err #开始写入信息
#ll -lh #有mysql.err-old
#清空旧错误日志
shell>echo ""> mysql.err-old #清空旧错误日志
shell> ll #无mysql.err-old
Shell>df -h #空间释放
#清理binlog日志
Shell>mysql -uroot -p
#方式1
Sql>show global variables like '%expire%'; #查看binlog保留时间
Sql>set global expire_logs_days=需保留的时间天数; #查看binlog及其pos,待刷满一个自动清理保留时间前的binlog
Sql>show global variables like '%expire%'; #日期已修改
#方式2
Sql>purge master logs to 'binlog.000010'; 清理该binlog前得所有binlog
Sql>show master status\G
Sql>exit
Shell>df -h #日志目录使用率减少
#如果binlog日志100%,手动rm掉binlog文件,然后修改binlog.index文件,去除已删除的binlog记录
#清理slow日志
shell>ip a
shell>df -h #查看磁盘挂载信息
shell>ls -lh /data/mysql-log/slow/slow.log #慢日志较大
shell>mysql -uroot -p
sql>show processlist; #查看连接情况
#验证慢日志是否启动slow_query_log:on,路径是否为/data/mysql-log/slow/slow.log
sql>show global variables like '%slow%';
sql>set global slow_query_log=off;
sql>show global variables like '%slow%'; #slow_query_log:off
sql>show processlist; #查看连接情况
sql>exit
shell>ls -lh /data/mysql-log/slow/slow.log #多观察几次,不再写入
shell>echo "" > /data/mysql-log/slow/slow.log #将慢日志清空
shell>ls -lh /data/mysql-log/slow/slow.log #多观察几次,不再写入
shell>cat /data/mysql-log/slow/slow.log #空
shell>mysql -uroot -p
sql>show global variables like '%slow%'; #slow_query_log:off,且存在/data/mysql-log/slow/slow.log
sql>set global slow_query_log=on;
sql>show global variables like '%slow%'; #slow_query_log:on且存在/data/mysql-log/slow/slow.log
sql>exit
shell> ls -lh /data/mysql-log/slow/ #查看慢日志目录信息,只有一个小的slow.log
shell>df -h #查看磁盘挂载信息,日志目录使用率减低
#若开启通用日志,清理方式同慢日志
三.mysql主从同步
1、主服务器把数据更改记录到二进制日志中。(主binlog)
2、从服务器把主服务器的二进制日志拷贝到自己的中继日志中。(主binlog-->从relay)
3、从服务器重放中继日志中的事件,把更改应用到自己的数据上。(从relay-->从binlog)
- 同步复制分类
异步复制,Mysql默认同步方式
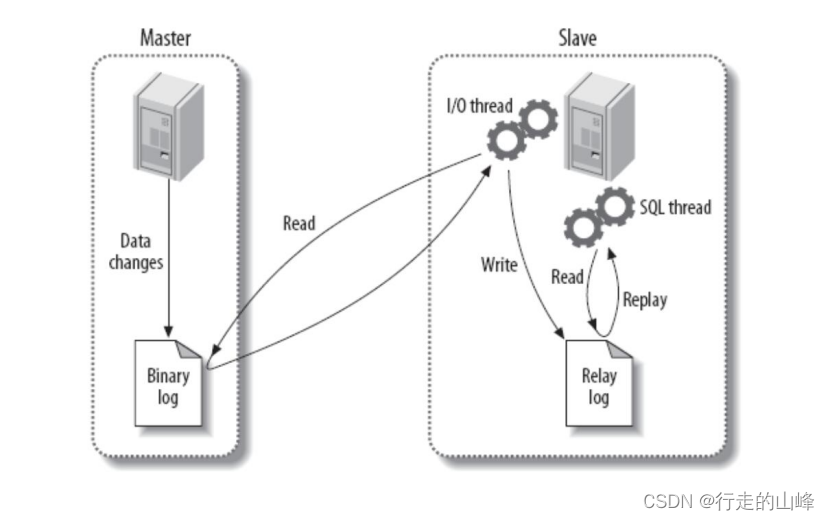
-
- 半同步复制(semi-sync)
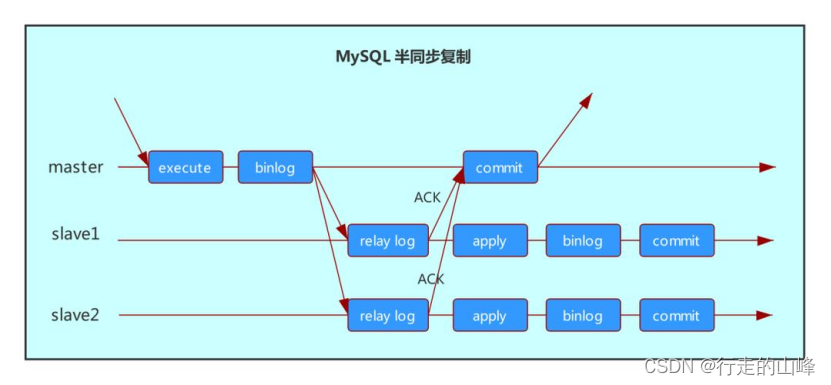
-
半同步复制(after_commit)
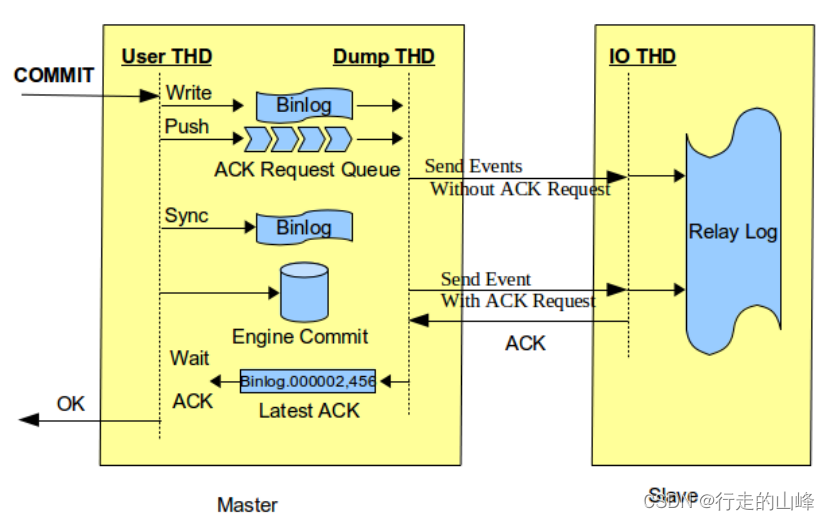 主库在等待ACK,InnoDB存储引擎内部已经提交事务,只是阻塞了返回给发起事务提交的客户端消息而已。此时如果有其他会话对该事务修改的数据进行查询,将会查询到最新数据,引起幻读
主库在等待ACK,InnoDB存储引擎内部已经提交事务,只是阻塞了返回给发起事务提交的客户端消息而已。此时如果有其他会话对该事务修改的数据进行查询,将会查询到最新数据,引起幻读 -
增强半同步复制(after_sync)
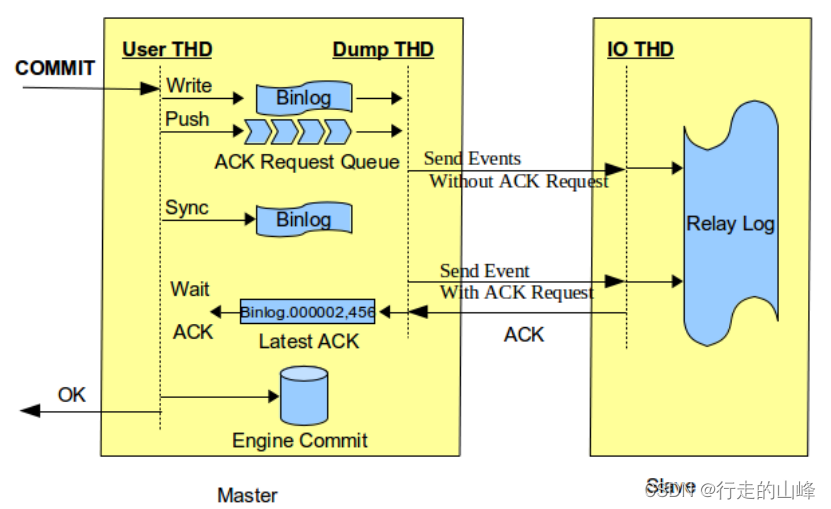 增强半同步复制下,一个事务在存储引擎内部提交之前,必须要先收到从库的ACK确认,否则不进行事务最后的提交。这样一来,非发起事务提交的客户端在查询数据时,所看到的数据就能够和发起事务提交的客户端保持一致,从而解决了在主库故障转移之后可能出现的幻读问题。
增强半同步复制下,一个事务在存储引擎内部提交之前,必须要先收到从库的ACK确认,否则不进行事务最后的提交。这样一来,非发起事务提交的客户端在查询数据时,所看到的数据就能够和发起事务提交的客户端保持一致,从而解决了在主库故障转移之后可能出现的幻读问题。 -
全复制(组复制mgr)
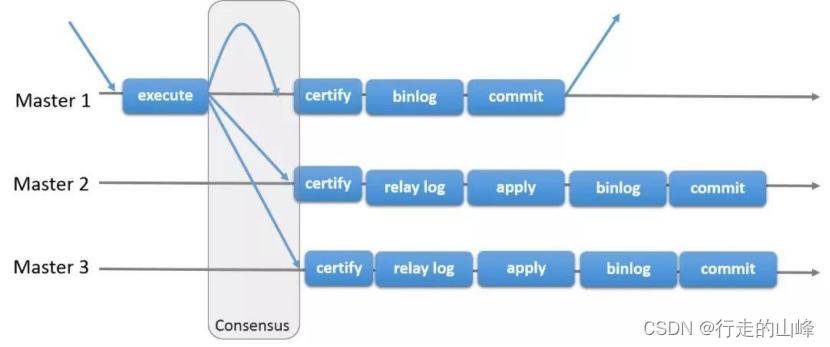
本地事务提交时(prepare之后,写binlog之前),将事务信息发送至通信模块,然后等待认证结果。通信模块将事务信息发送给全局认证模块做冲突检测后,唤醒该事务执行执行(提交或回滚)
远端机器中通信模块收到事务信息后,将其排序后发送给本地的全局认证模块做冲突检测,认证成功后将BinlogEvent 事件写入Relaylog 日志,最后由group-Replication-applier 进行重放应用。若认证失败,则丢弃该BinlogEvent事件。
-
四.性能排查
排查思路:
操作系统层面:1.cpu负载--》2.消耗高进程(pid)--》3.消耗高线程(THREAD_OS_ID)--》4.数据库层面:thread_id,processlist_id--》5.sql定位--》6.sql解析--》7.sql优化
- CPU负载高
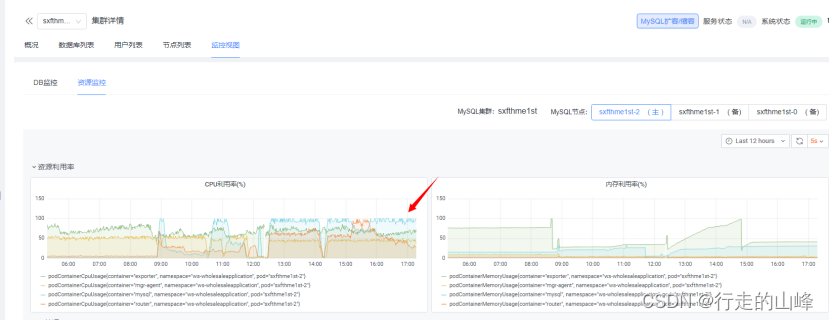
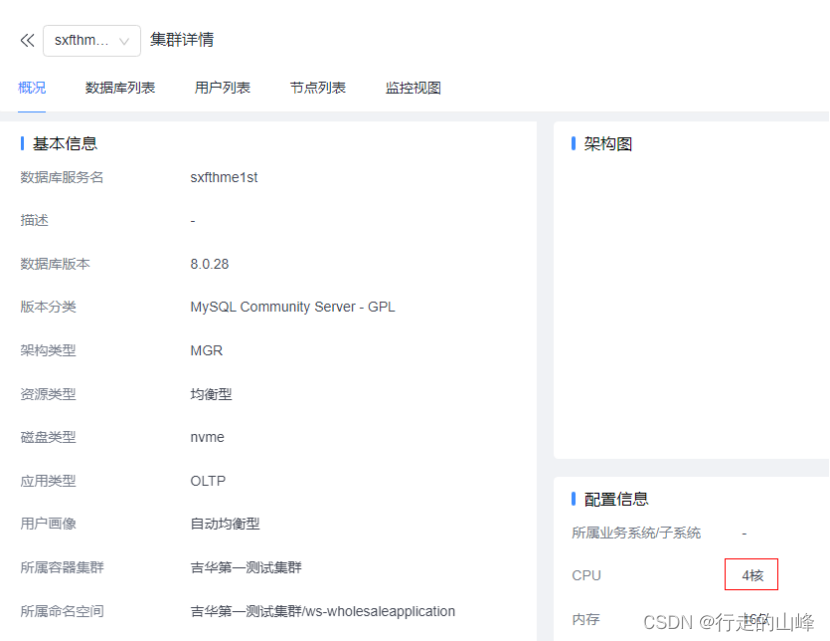
- 消耗高进程(pid)查看
-
shell>top
-
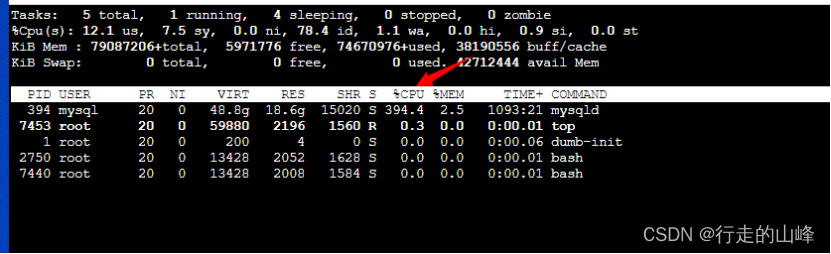
- 消耗高线程(THREAD_OS_ID)
-
shell>top -H -p 394
-
- thread_id,processlist_id查看
-
sql>SELECT a.THREAD_OS_ID,a.thread_id,b.id,b.user,b.host,b.db,b.command,b.time,b.state,b.info FROM performance_schema.threads a,information_schema.processlist b WHERE b.id = a.processlist_id and a.THREAD_OS_ID in (5977,6628,5532,5995,6678);
Sql>select THREAD_OS_ID,THREAD_ID,PROCESSLIST_ID,PROCESSLIST_USER,PROCESSLIST_HOST,PROCESSLIST_DB,PROCESSLIST_COMMAND,PROCESSLIST_STATE,PROCESSLIST_TIME,PROCESSLIST_INFO from performance_schema.threads where THREAD_OS_ID in (5977,6628,5532,5995,6678);
并发查询,且有同条件查询问题,后续排查应用逻辑
- sql定位
-
#记录当前线程执行的sql,若瞬时执行的,前面可能无法定位到sql,info为null
Sql>select * from performance_schema.events_statements_current where Thread_ID in (151091,109894,106359,170072,109880);
#记录当前线程执行的sql,10条记录
Sql>select * from performance_schema.events_statements_history where Thread_ID in (151091,109894,106359,170072,109880);
- sql解析
-
进行sql解析,可以看到使用了usr_prjSeqHrm_idx索引,但是使用效率不高,预计需检索45978行,命中率44%。

-
使用usr_prjSeqHrm_idx索引检出24632行,进一步检索,返回一行(后续可考虑添加联合索引)

-
根据实际查询,只使用usr_prjSeqHrm_idx索引,最左边的一个列
- sql优化
-
添加联合索引,排查该应用逻辑,并发重复发起了查询,之后添加索引出现锁问题,kill后释放。后续应用决定从sxfthme1st迁到xftorgst,sxfthme1st性能负载恢复。xftorgst负载高,创建联合索引或问题解决。
查看高频sql:
#方式一,视图记录sql平均执行时间前5%,默认按平均执行时间降序,执行sql条件模糊统计信息及省略信息,统计信息较友好
Sql>select * from sys.statements_with_runtimes_in_95th_percentile order by exec_count desc limit 10\G
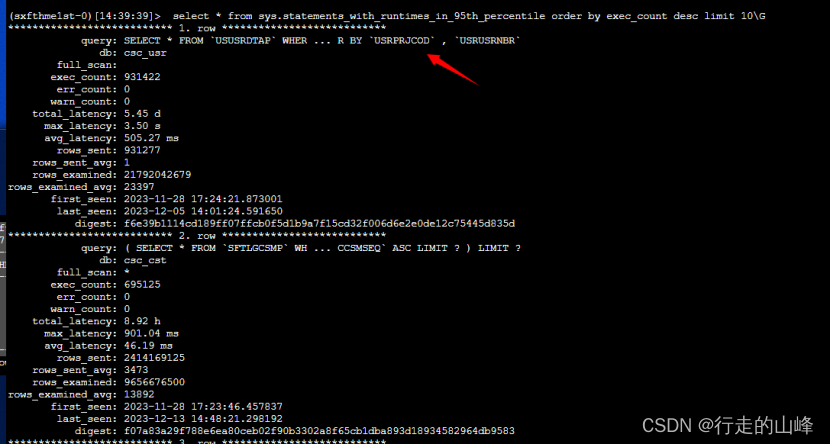
视图含义:
query:经过标准化转换的语句字符串
db:语句对应的默认数据库,如果没有默认数据库,该字段为NULL
full_scan:语句全表扫描查询的总次数
exec_count:语句执行的总次数
err_count:语句发生的错误总次数
warn_count:语句发生的警告总次数
total_latency:语句执行的总延迟时间(执行时间)
max_latency:单个语句的最大延迟时间(执行时间)
avg_latency:每个语句的平均延迟时间(执行时间)
rows_sent:语句执行从表返回给客户端的总数据行数
rows_sent_avg:每个语句执行从表中返回客户端的平均数据行数
rows_examined:语句执行从存储引擎检查的总数据行数
rows_examined_avg:每个语句执行从存储引擎检查的平均数据行数
first_seen:该语句第一次出现的时间
last_seen:该语句最近一次出现的时间
digest:语句摘要计算的md5 hash值
- 锁问题
-
1.排查手段:
select * from sys.schema_table_lock_waits; #表级锁等待
show open tables where In_use>0; #当前使用的表
show status like 'innodb_row_lock%'; #行所情况
select * from information_schema.innodb_trx; #当前事务
select * from information_schema.innodb_locks; #锁情况,8.0不存在这个表
- 锁问题示例
- 半同步复制(semi-sync)
-
元数据锁问题:
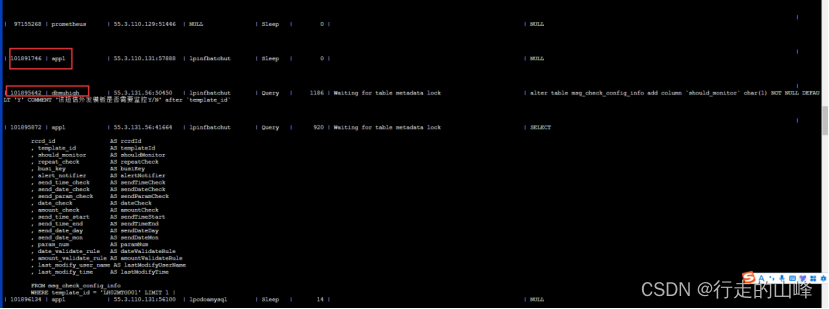
长事务A与ddl事务B,锁等待问题,事务A执行堵塞B操作,事务B堵塞该表后续所有操作
查询sql:101891746
DDL操作:101895642
select * from sys.schema_table_lock_waits; #查看锁等待信息
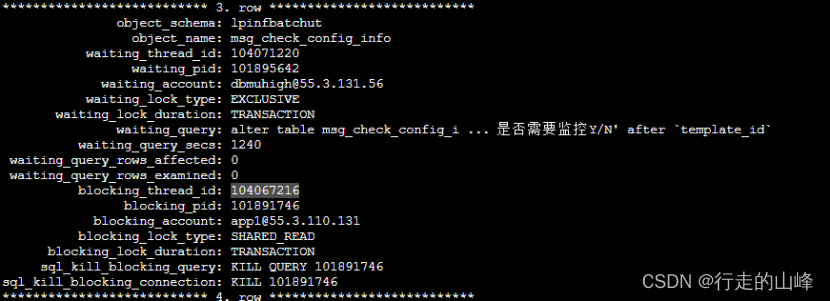
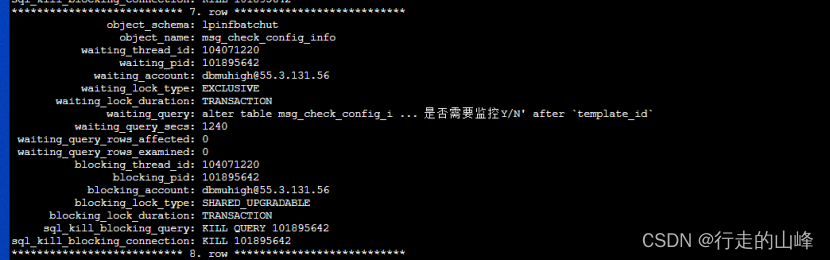
解决方法:kill长连接或者kill ddl事务
MDL最常用的类型包括:
MDL_SHARED(S),可以共享访问对象的元数据,比如 SHOW CREATE TABLE 语句
MDL_SHARED_READ(SR),可以共享访问对象的数据,比如 SELECT 语句
MDL_SHARED_WRITE(SW),可以修改对象的数据,比如 INSERT UPDATE 语句
MDL_SHARED_UPGRADABLE(SU),可升级的共享锁,后面可升级到更强的锁(比如 X 锁,阻塞并发访问),比如 DDL 的第一阶段
MDL_EXCLUSIVE(X),独占锁,阻塞其他线程对该对象的并发访问,可以修改对象的元数据,比如 DDL 的第二阶段
兼容性矩阵:
Request | Granted requests for lock |
type | S SH SR SW SWLP SU SRO SNW SNRW X |
----------+---------------------------------------------+
S | + + + + + + + + + - |
SH | + + + + + + + + + - |
SR | + + + + + + + + - - |
SW | + + + + + + - - - - |
SWLP | + + + + + + - - - - |
SU | + + + + + - + - - - |
SRO | + + + - - + + + - - |
SNW | + + + - - - + - - - |
SNRW | + + - - - - - - - - |
X | - - - - - - - - - - |
Request | Pending requests for lock |
type | S SH SR SW SWLP SU SRO SNW SNRW X |
----------+--------------------------------------------+
S | + + + + + + + + + - |
SH | + + + + + + + + + + |
SR | + + + + + + + + - - |
SW | + + + + + + + - - - |
SWLP | + + + + + + - - - - |
SU | + + + + + + + + + - |
SRO | + + + - + + + + - - |
SNW | + + + + + + + + + - |
SNRW | + + + + + + + + + - |
X | + + + + + + + + + + |同步死锁问题:
并行复制下,从库同步数据,存在锁争用情况,因为是同步回放阶段,堵塞无法取消,无法回放数据。
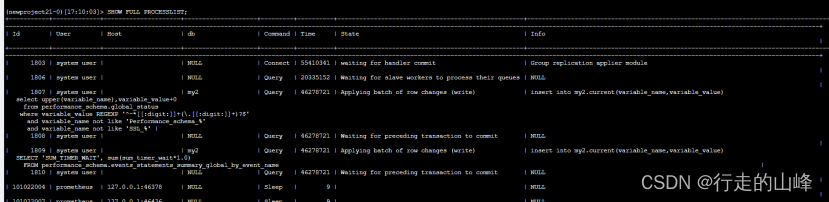
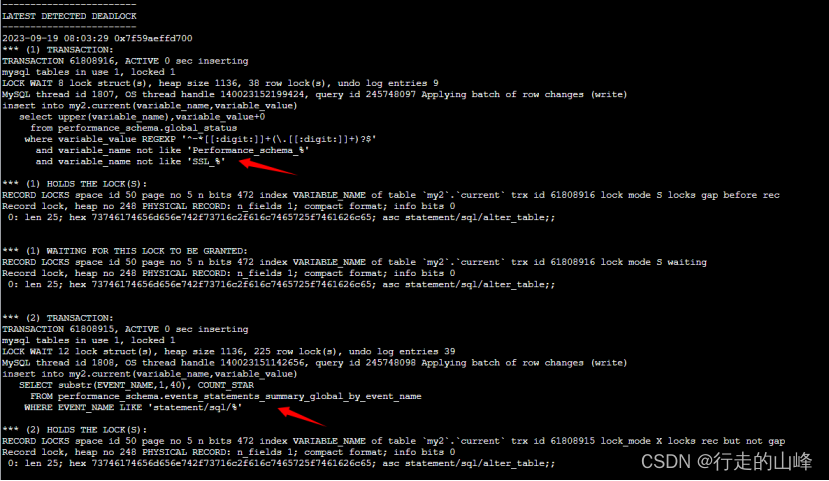
解决方法:优化sql逻辑,或者关闭并行复制

一站式 AI 云服务平台
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)