
Ollama安装与使用
Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。Ollama的主要功能包括快速部署和运行各种大语言模型,如Llama 2、Code Llama等。
这里写自定义目录标题
- Ollama安装与使用
- 1 什么是Ollama
- 2 Ollama特点
- 3 Ollama下载与安装
- 4 Ollama 运行模型
- 5 对话指令详解
-
- 5.1 基本指令
- 5.2 对话调整指令
-
- 5.2.1 /set 设置会话参数
-
- 5.2.1.1 /set parameter ... 设置对话参数
- 5.2.1.2 /set system <string> 设置系统角色
- 5.2.1.3 /set history 开启对话历史
- 5.2.1.4 /set nohistory 关闭对话历史
- 5.2.1.5 /set wordwrap 开启自动换行
- 5.2.1.6 /set nowordwrap 关闭自动换行
- 5.2.1.7 /set format json 输出JSON格式
- 5.2.1.8 /set noformat 关闭格式输出
- 5.2.1.9 /set verbose 开启对话统计日志
- 5.2.1.10 /set quiet 关闭对话统计日志
- 5.2.2 /clear 清理下上文
- 5.3 模型调整指令
- 6 客户端命令
- 7 开通远程访问
- 8 API
Ollama安装与使用
1 什么是Ollama
Ollama 中文名为羊驼,官网https://ollama.com/
Ollama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)。通过Ollama,开发者可以访问和运行一系列预构建的模型,或者导入和定制自己的模型,无需关注复杂的底层实现细节。
Ollama的主要功能包括快速部署和运行各种大语言模型,如Llama 2、Code Llama等。它还支持从GGUF、PyTorch或Safetensors格式导入自定义模型,并提供了丰富的API和CLI命令行工具,方便开发者进行高级定制和应用开发。
2 Ollama特点
2.1 一站式管理
Ollama将模型权重、配置和数据捆绑到一个包中,定义成Modelfile,从而优化了设置和配置细节。
包括GPU使用情况。这种封装方式使得用户无需关注底层实现细节,即可快速部署和运行复杂的大语言模型。
2.2 热加载模型文件
支持热加载模型文件,无需重新启动即可切换不同的模型,
提高了灵活性,还显著增强了用户体验。
2.3 丰富的模型库
提供多种预构建的模型,如Llama 2、Llama 3、通义千问,方便用户快速在本地运行大型语言模型。
2.4 多平台支持
支持多种操作系统,包括Mac、Windows和Linux,确保了广泛的可用性和灵活性。
2.5 无复杂依赖
优化推理代码减少不必要的依赖,可以在各种硬件上高效运行。包括纯CPU推理和Apple Silicon架构。
2.6 资源占用少
Ollama的代码简洁明了,运行时占用资源少,使其能够在本地高效运行,不需要大量的计算资源。
3 Ollama下载与安装
3.1 下载及安装
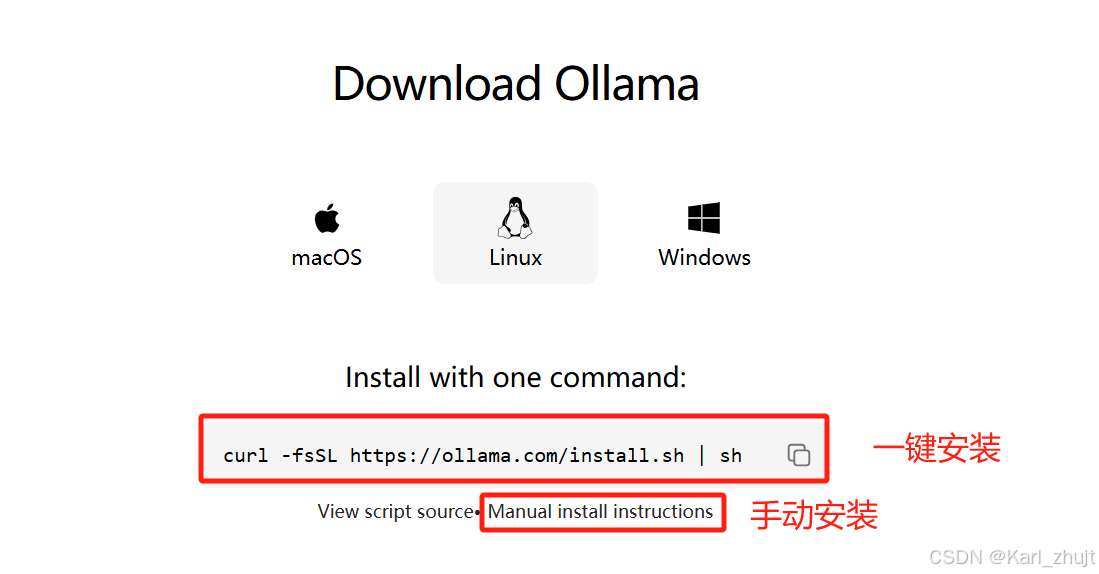
3.2 一键安装
在linux终端中执行以下代码,进行自动下载及安装。
curl -fsSL https://ollama.com/install.sh | sh
3.3 手动安装
注意:
如果您是从旧版本进行升级,应先使用 sudo rm -rf /usr/lib/ollama 命令删除旧的库文件。
3.3.1 下载并解压压缩包
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
3.3.2 命令验证
ollama -v
如果显示版本号,则说明安装成功。
test@...:~$ ollama -v
ollama version is 0.5.12
3.4 服务配置及管理
3.4.1 创建用户及用户组
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)
useradd 参数说明
-r:建立系统账号
-s:指定用户登入后所使用的shell
-U:创建与用户同名的组
-m:制定用户的登入目录
-d:指定用户登入时的起始目录
usermode 参数说明
-a:将用户附加到-G选项提到的补充组中,而不从其他组中删除用户。
-G:新的补充组名称
3.4.2 创建服务文件
创建服务文件
sudo vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=default.target
注意:
增加 Environment=“PATH=$PATH” 配置后,可以在任何目录下执行Ollama命令。
3.4.3 重新加载服务并自启动
# 重新加载系统服务的配置文件
sudo systemctl daemon-reload
# 服务在系统启动时自动启动
sudo systemctl enable ollama
3.4.4 启动服务并查看服务状态
# 启动服务
sudo systemctl start ollama
# 查看服务状态
sudo systemctl status ollama
3.4.5 重启服务
sudo systemctl restart ollama
3.4.6 更新
Ollama的更新可分为两种方式。
方式一:通过再次运行安装脚本来更新 Ollama
curl -fsSL https://ollama.com/install.sh | sh
方式二:通过重新下载 Ollama
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
3.4.7 查看日志
journalctl -e -u ollama
3.4.8 卸载
- 移除Ollama服务
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service
- 从bin目录中移除ollama二进制文件,例如:/usr/local/bin, /usr/bin, or /bin
sudo rm $(which ollama)
- 删除下载的模型以及 Ollama 服务用户和组
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
- 删除已安装的库
sudo rm -rf /usr/local/lib/ollama
4 Ollama 运行模型
4.1 运行模型命令
Ollama 运行模型使用 ollama run 命令。
命令参数如下:
ollama run model:tag
模型名称采用model:tag格式,其中model可以有一个可选的命名空间,如example/model。一些示例包括deepseek-r1:1.5b和qwen2:0.5b。标签是可选的,如果没有提供,默认为latest。标签用于标识特定版本。
如果首次运行,本地没有大模型则会从远程下载大模型。
4.2 查询支持的模型
官网地址:https://ollama.com/search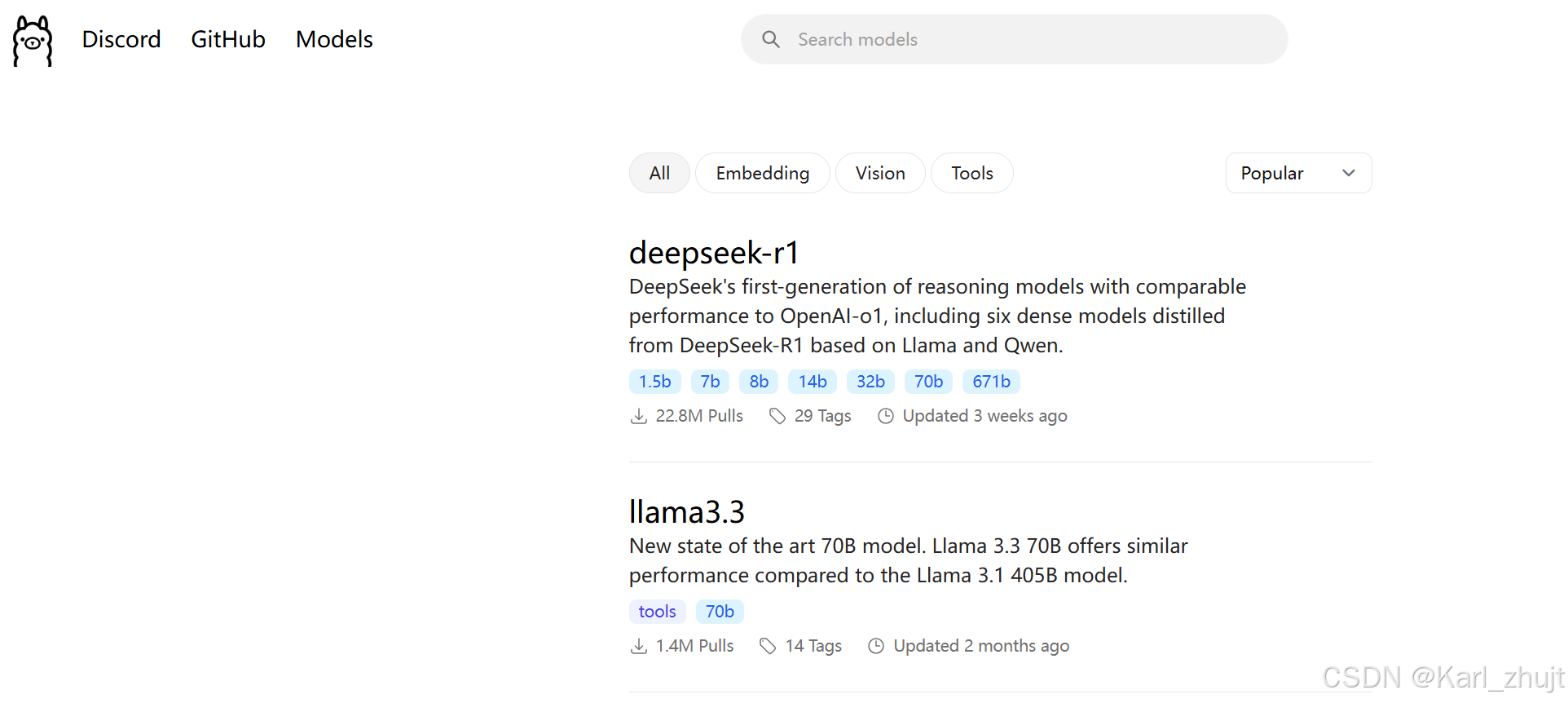
4.3 旋转模型及模型参数
以deepseek-r1:1.5b为例: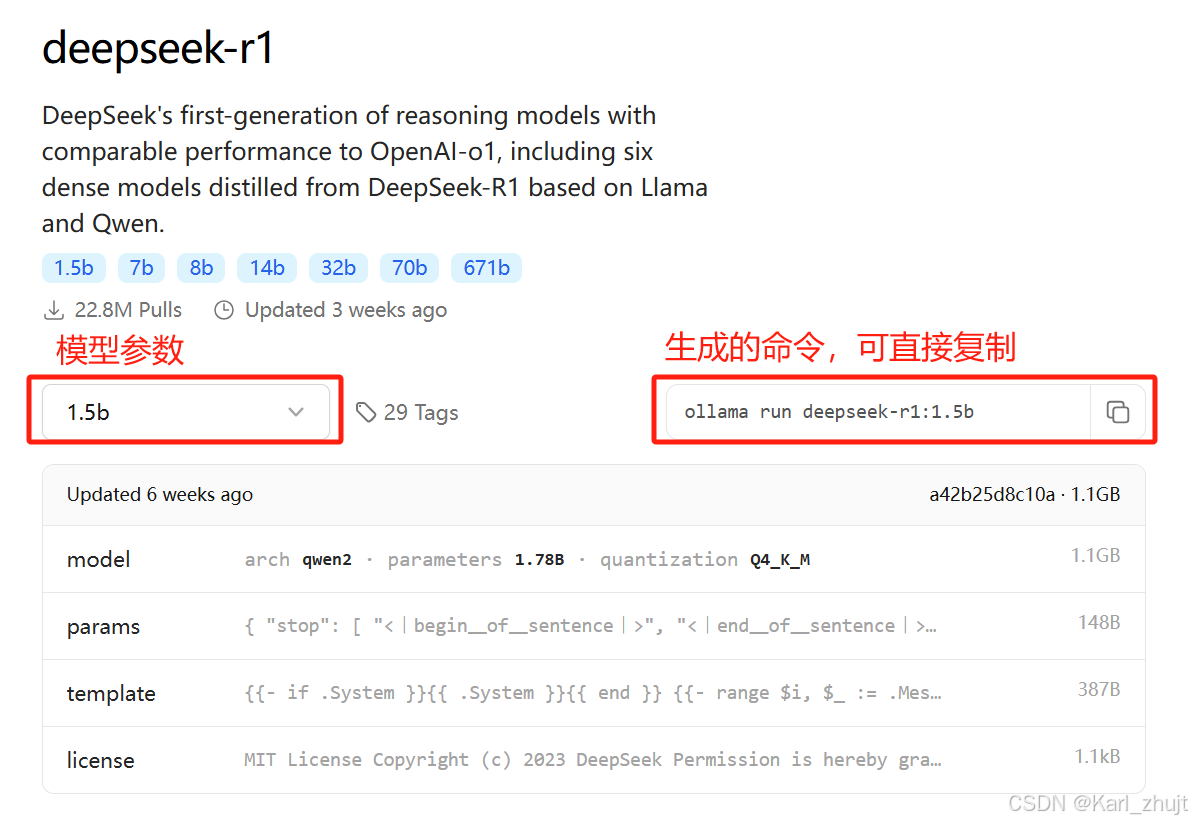
4.4 执行命令
test@...:~$ ollama run deepseek-r1:1.5b
4.5 修改模型路径
- 要修改其默认存储路径,需要通过设置系统环境变量来实现,即在/etc/profile文件中最后增加一下环境变量:
export OLLAMA_MODELS=/home/test/ollama
- 然后执行一下命令,生效环境变量:
source /etc/profile
echo $OLLAMA_MODELS
- 修改/etc/systemd/system/ollama.service文件,便于开机加载。
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
Environment="OLLAMA_MODELS=/home/test/ollama"
[Install]
WantedBy=default.target
- 生效修改配置
# 重新加载系统服务的配置文件
sudo systemctl daemon-reload
# 服务在系统启动时自动启动
sudo systemctl enable ollama
- 然后重新ollama服务
sudo systemctl restart ollama
5 对话指令详解
在Ollama终端中提供了一系列指令,可以用来调整和控制对话模型:
test@...:~$ ollama run deepseek-r1:1.5
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.
>>> Send a message (/? for help)
根据对话指令的作用分为基本指令、对话调整指令以及模型调整指令。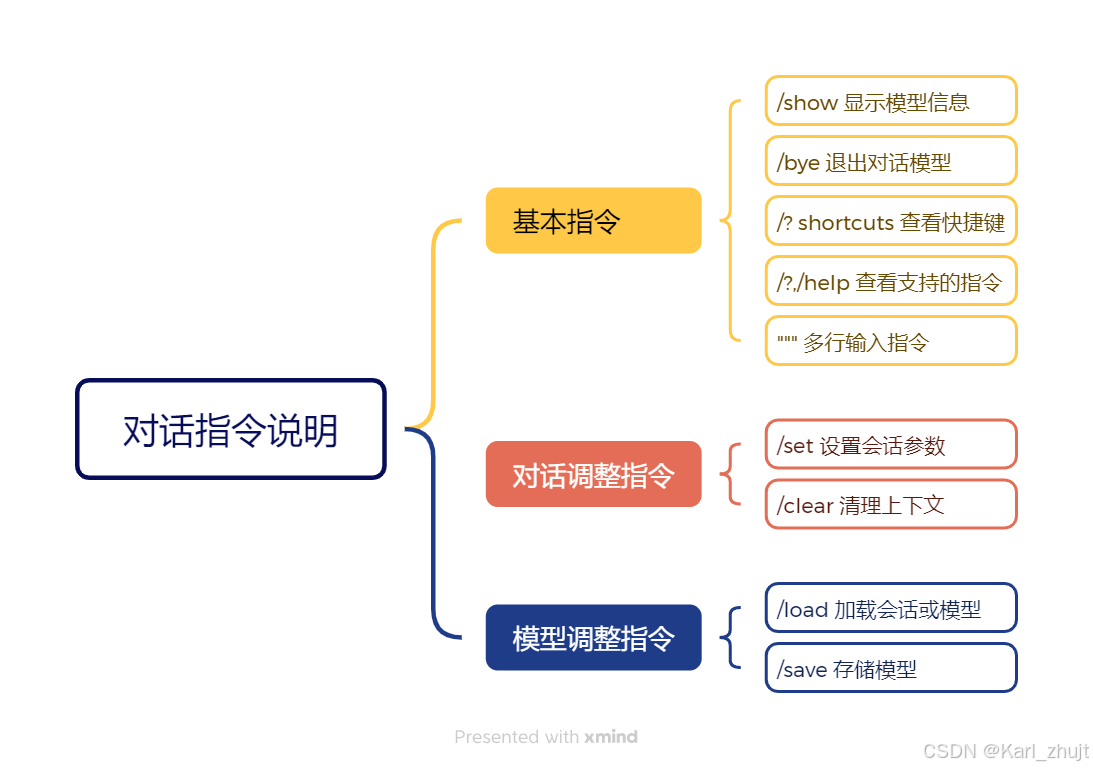
5.1 基本指令
5.1.1 /show 显示模型信息
test@...:~$ ollama run deepseek-r1:1.5
>>> /show
Available Commands:
/show info 查看模型的基本信息
/show license 查看模型的许可信息
/show modelfile 查看模型的制作源文件Modelfile
/show parameters 查看模型的内置参数信息
/show system 查看模型的内置Sytem信息
/show template 查看模型的提示词模版
>>> Send a message (/? for help)
输入/show info 命令,查看模型的详细信息:
test@Ken:~$ ollama run deepseek-r1:1.5b
>>> /show info
Model
architecture qwen2
parameters 1.8B
context length 131072
embedding length 1536
quantization Q4_K_M
Parameters
stop "<|begin▁of▁sentence|>"
stop "<|end▁of▁sentence|>"
stop "<|User|>"
stop "<|Assistant|>"
License
MIT License
Copyright (c) 2023 DeepSeek
>>> Send a message (/? for help)
其他的命令同样操作。
5.1.2 /bye 退出对话模型
退出当前控制台对话, 快捷键: ctrl + d
test@Ken:~$ ollama run deepseek-r1:1.5b
>>> 您是谁?
<think>
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我擅长通过思考来帮您解答复杂的数学,代码和逻辑推理等理工类问题。
</think>
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我擅长通过思考来帮您解答复杂的数学,代码和逻辑推理等理工类问题。
>>> /bye
test@Ken:~$
5.1.3 /? shortcuts 查看快捷键
查看在控制台中可用的快捷键。
test@...:~$ ollama run deepseek-r1:1.5b
>>> /? shortcuts
Available keyboard shortcuts:
Ctrl + a 移动到行头
Ctrl + e 移动到行尾
Ctrl + b 移动到单词左边
Ctrl + f 移动到单词右边
Ctrl + k 删除游标后面的内容
Ctrl + u 删除游标前面的内容
Ctrl + w 删除游标前面的单词
Ctrl + l 清屏
Ctrl + c 停止推理输出
Ctrl + d 退出对话(只有在没有输入时才生效)
5.1.4 /?,/help 查看支持的指令
test@...:~$ ollama run deepseek-r1:1.5
>>> /?
Available Commands:
/set Set session variables
/show Show model information
/load <model> Load a session or model
/save <model> Save your current session
/clear Clear session context
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use """ to begin a multi-line message.
>>> Send a message (/? for help)
5.1.5 “”" 多行输入指令
“”" 用于输入内容有换行时使用,如何多行输入结束也使用 “”"
>>> """
... 您好
... 你是什么模型?
... """
<think>
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我擅长通过思考来帮您解答复杂的数学,代码和逻辑推理等理工类问题。
</think>
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我擅长通过思考来帮您解答复杂的数学,代码和逻辑推理等理工类问题。
5.2 对话调整指令
5.2.1 /set 设置会话参数
set指令主要用来设置当前对话模型的系列参数。
test@...:~$ ollama run deepseek-r1:1.5b
>>> /set
Available Commands:
/set parameter ... 设置对话参数
/set system <string> 设置系统角色
/set history 开启对话历史
/set nohistory 关闭对话历史
/set wordwrap 开启自动换行
/set nowordwrap 关闭自动换行
/set format json 输出JSON格式
/set noformat 关闭格式输出
/set verbose 开启对话统计日志
/set quiet 关闭对话统计日志
5.2.1.1 /set parameter … 设置对话参数
test@...:~$ ollama run deepseek-r1:1.5b
>>> /set parameter
Available Parameters:
/set parameter seed <int> Random number seed
/set parameter num_predict <int> Max number of tokens to predict
/set parameter top_k <int> Pick from top k num of tokens
/set parameter top_p <float> Pick token based on sum of probabilities
/set parameter min_p <float> Pick token based on top token probability * min_p
/set parameter num_ctx <int> Set the context size
/set parameter temperature <float> Set creativity level
/set parameter repeat_penalty <float> How strongly to penalize repetitions
/set parameter repeat_last_n <int> Set how far back to look for repetitions
/set parameter num_gpu <int> The number of layers to send to the GPU
/set parameter stop <string> <string> ... Set the stop parameters
| Parameter | Description | Value Type | Example Usage |
|---|---|---|---|
| num_ctx | 设置用于生成下一个 token 的上下文窗口大小。(默认值:2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型回溯的距离以防止重复。(默认值:64,0 = 禁用,-1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置对重复内容的惩罚强度。较高的值(例如 1.5)会更强地惩罚重复内容,而较低的值(例如 0.9)则会更宽松。(默认值:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度值。提高温度会使模型的回答更具创造性。(默认值:0.8) | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将此值设置为特定数字会使模型针对相同的提示生成相同的文本。(默认值:0) | int | seed 42 |
| stop | 设置使用的停止序列。当遇到此模式时,LLM 将停止生成文本并返回。可以通过在 modelfile 中指定多个单独的 stop 参数来设置多个停止模式。 |
string | stop “AI assistant:” |
| num_predict | 生成文本时预测的最大 token 数量。(默认值:-1,表示无限生成) | int | num_predict 42 |
| top_k | 降低生成无意义内容的概率。较高的值(例如 100)会提供更多样化的回答,而较低的值(例如 10)则会更保守。(默认值:40) | int | top_k 40 |
| top_p | 与 top-k 配合使用。较高的值(例如 0.95)会生成更多样化的文本,而较低的值(例如 0.5)会生成更集中和保守的文本。(默认值:0.9) | float | top_p 0.9 |
| min_p | 作为 top_p 的替代方案,旨在确保质量和多样性的平衡。参数 p 表示 token 被考虑的最小概率,相对于最可能 token 的概率。例如,当 p=0.05 且最可能的 token 概率为 0.9 时,值小于 0.045 的 logits 将被过滤掉。(默认值:0.0) | float | min_p 0.05 |
| num_gpu | 设置缓存到GPU显存中的模型层数 设置用于处理模型的 GPU 数量,特别适用于多 GPU 系统。可以将模型的某些层发送到 GPU 上,以利用 GPU 的加速能力。 如果有多个 GPU 卡: 1)可以设置 num_gpu 的值为你想要使用的 GPU 数量。如果你有 4 张 GPU,可以设置 num_gpu 4 来让模型使用所有 4 张 GPU 进行推理。 2)这将分配模型的计算任务到多个 GPU,利用每张 GPU 的显存和计算能力。 |
int | 自动计算 |
5.2.1.2 /set system 设置系统角色
/set system 命令可以设置系统消息。具体来说,/set system命令用于设置系统消息,可以自定义系统消息的内容和格式。例如,你可以使用/set system "Hello, this is a system message."来设置系统消息为“Hello, this is a system message.”。
5.2.1.3 /set history 开启对话历史
使用/set history命令可以启用会话历史记录功能,这样用户在与模型交互时,之前的对话内容会被保存下来,方便用户查看历史记录或继续之前的对话。这对于需要连续对话或需要参考之前对话内容的场景非常有用。
5.2.1.4 /set nohistory 关闭对话历史
在某些情况下,用户可能不希望保存会话历史记录,例如保护隐私或减少存储空间的使用。此时可以使用/set nohistory命令来禁用会话历史记录功能。
5.2.1.5 /set wordwrap 开启自动换行
Ollama的/set wordwrap命令用于控制文本的换行方式。当启用/set wordwrap时,文本会在达到屏幕宽度时自动换行,避免长文本占据整行显示,使得输出更加易读。
5.2.1.6 /set nowordwrap 关闭自动换行
/set nowordwrap命令用于长文本会继续在一行显示,直到遇到空格或标点符号。
5.2.1.7 /set format json 输出JSON格式
>>> /set format json
Set format to 'json' mode.
>>> 您好
{"response":"你好,欢迎光临,请问有什么我可以帮助您的吗?"}
5.2.1.8 /set noformat 关闭格式输出
>>> /set noformat
Disabled format.
>>> 您好
<think>
</think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。我擅长通过思考来帮助您解答复杂的数学、代码和逻
辑推理等理工类问题。请问有什么我可以帮您的吗?
5.2.1.9 /set verbose 开启对话统计日志
>> /set verbose
Set 'verbose' mode.
>>> 您好
<think>
---
您好!
我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。
我擅长通过思考来帮助您解答复杂的数学、代码和逻辑推理等理工类问题。
如果您有任何疑问或需要 assistance,请随时告诉我!我会尽力为您提供清晰、准确的答案。
total duration: 2.577653196s
load duration: 19.493978ms
prompt eval count: 171 token(s)
prompt eval duration: 131ms
prompt eval rate: 1305.34 tokens/s
eval count: 64 token(s)
eval duration: 2.384s
eval rate: 26.85 tokens/s
数据项说明
total duration:生成响应所花费的时间
load duration:以纳秒为单位加载模型的时间
prompt eval count:提示符中的令牌数量
prompt eval duration:以纳秒为单位评估提示所花费的时间
eval count:响应中的令牌数量
eval duration:以纳秒为单位生成响应的时间
eval rate:每秒生成响应的速度(token/s)= eval count / eval duration
5.2.1.10 /set quiet 关闭对话统计日志
>>> /set quiet
Set 'quiet' mode.
>>> 您好
<think>
您好!
我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。
我擅长通过思考来帮助您解答复杂的数学、代码和逻辑推理等理工类问题。
如果您有任何疑问或需要 assistance,请随时告诉我!我会尽力为您提供清晰、准确的答案。我会继续努力提供高质量的服务!
>>> Send a message (/? for help)
5.2.2 /clear 清理下上文
在命令行终端中对话是自带上下文记忆功能,如果要清除上下文功能,则使用/clear指令清除上下文内容,例如:前2个问题都关联的,在输入/clear则把前2个问题的内容给清理掉了,第3次提问时则找不到开始的上下文了。
>>> 请帮我选择中午要吃什么?
以下是常吃饭的种类:
1、兰州拉面
2、牛肉拌面
3、热干面
>>> 换以下
以下是常吃饭的种类:
4、刀削面
5、油泼面
6、皮带面
>>> /clear
Cleared session context
>>> 在出1道
很抱歉,我无法理解您的问题。您能否提供更多的背景信息或者问题描述,以便我能更好地帮助您?
5.3 模型调整指令
5.3.1 /load 加载会话或模型
load可以在对话过程中随时切换大模型。
test@...:~$ ollama list
NAME ID SIZE MODIFIED
qwen2:0.5b 6f48b936a09f 352 MB 2 days ago
llava:latest 8dd30f6b0cb1 4.7 GB 2 days ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 2 days ago
test@...:~$ ollama run qwen2:0.5b
>>> 你是谁
我是一台计算机程序,是阿里云开发的一个超大规模语言模型。我是通义千问的主人,您可以通过云平台向我提问相关问题。
>>> /load deepseek-r1:1.5b
Loading model 'deepseek-r1:1.5b'
>>> 你是谁
<think>
</think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
>>> Send a message (/? for help)
5.3.2 /save 保存当前会话
/save命令可以将当前的对话模型保存为一个新的模型。用户可以通过指定一个模型名称来保存当前的会话状态或模型,将其保存为一个文件,以便以后使用。
保存的模型存储在ollama的model文件中,进入下面路径即可看见模型文件test
test@...:~$ ollama run qwen2:0.5b
>>> 你是什么大模型
我是来自OpenAI的GPT-3,我的目标是帮助人类更好地理解、创造和生成内容。我会不断学习和自我完善,以提供更加智能、高效的
服务。
>>>
test@...:~$ ollama run qwen2:0.5b
>>> 你是什么大模型
我是Open Assistant,是由阿里云开发的一个通用模型。
>>> /save test
Created new model 'test'
>>>
test@...:~$ ollama list
NAME ID SIZE MODIFIED
test:latest 3f928c6eb52f 352 MB 10 seconds ago
qwen2:0.5b 6f48b936a09f 352 MB 10 minutes ago
llava:latest 8dd30f6b0cb1 4.7 GB 11 hours ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 14 hours ago
test@...:~$ ollama run test:latest
>>> 你是什么大模型
我是Open Assistant,是由阿里云开发的一个通用模型。
>>> Send a message (/? for help)
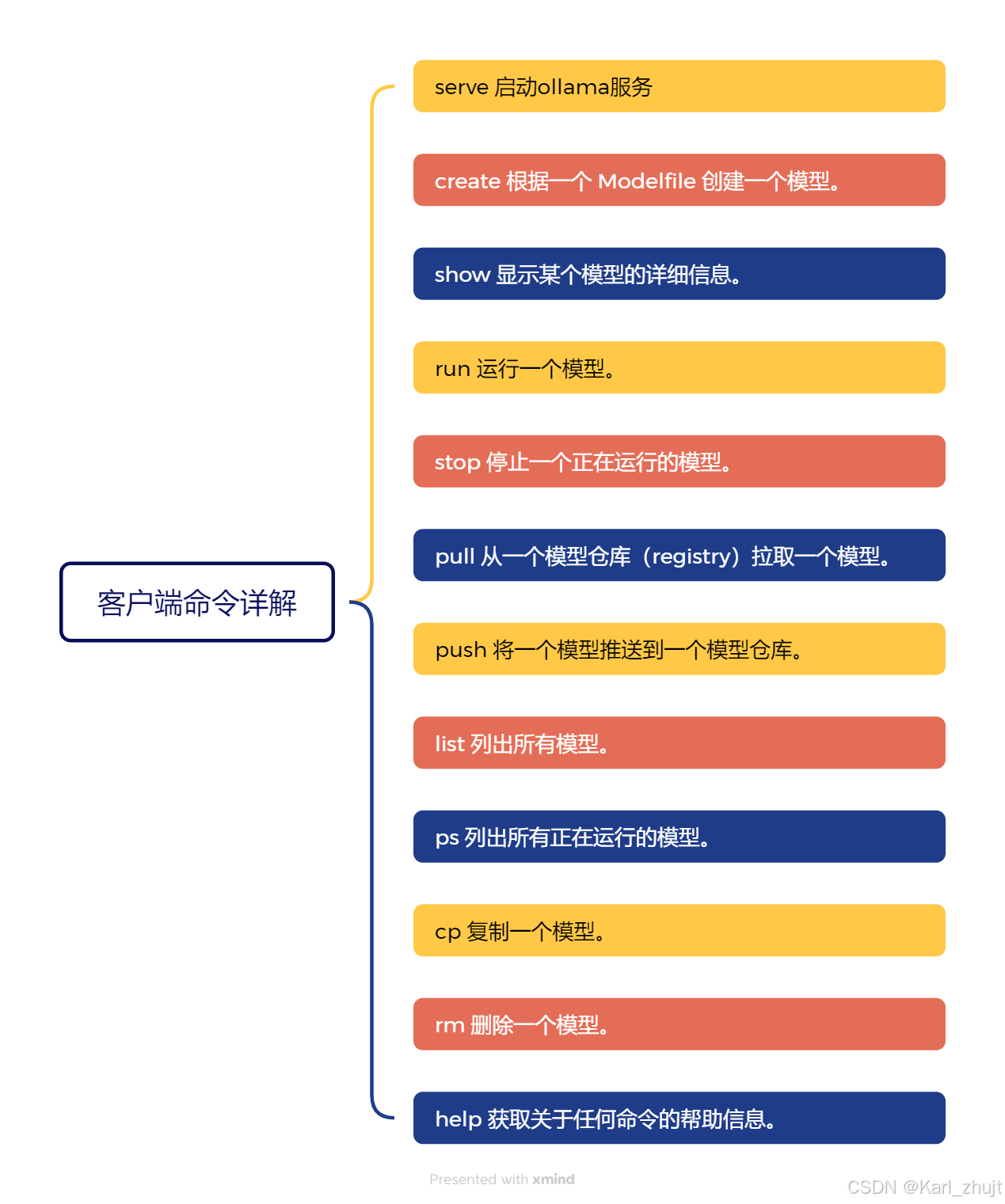
6 客户端命令
Ollama客户端还提供了系列命令,来管理本地大模型,接下来就先了解一下相关命令:
test@...:~$ ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama # 启动服务
create Create a model from a Modelfile # 根据Modefile文件创建模型
show Show information for a model # 查看模型详情
run Run a model # 运行模型
stop Stop a running model # 停止一个正在运行的模型
pull Pull a model from a registry # 从模型仓库(registry)中拉取模型
push Push a model to a registry # 将模型推送到模型仓库(registry)中
list List models # 列出所有模型
ps List running models # 查看在运模型
cp Copy a model # 复制模型
rm Remove a model # 删除模型
help Help about any command # 帮助
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
6.1 serve 启动服务
启动 Ollama 服务以在后台运行。
ollama serve
6.2 create 创建模型
使用 Modelfile 来创建一个新模型。你需要提供一个包含模型信息的 Modelfile。
ollama create 模型名称 -f 模型文件
6.3 show 显示模型详情
查看特定模型的详细信息,例如模型参数、模型模板等。
test@...:~$ ollama show --help
Show information for a model
Usage:
ollama show MODEL [flags]
Flags:
-h, --help help for show
--license Show license of a model # 显示模型的许可证
--modelfile Show Modelfile of a model # 显示模型的Modelfile
--parameters Show parameters of a model # 显示模型的参数
--system Show system message of a model # 显示模型的系统消息
--template Show template of a model # 显示模型模板
显示模型参数
ollama show deepseek-r1:1.5b --template
6.4 run 运行模型
运行一个已安装的模型,执行某些任务。
test@...:~$ ollama run --help
Run a model
Usage:
ollama run MODEL [PROMPT] [flags]
Flags:
--format string Response format (e.g. json)
-h, --help help for run
--insecure Use an insecure registry
--keepalive string Duration to keep a model loaded (e.g. 5m)
--nowordwrap Don't wrap words to the next line automatically
--verbose Show timings for response
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
OLLAMA_NOHISTORY Do not preserve readline history
6.4.1 运行模型
ollama run deepseek-r1:1.5b
6.4.2 输出格式
ollama run deepseek-r1:1.5b --format json
Ollama支持多种输出格式,包括不限于JSON
6.4.3 持续加载模型
ollama run llava --keepalive 1h
默认情况下,模型在生成响应后会在内存中保留 5 分钟。这允许在您多次请求 LLM 时获得更快的响应时间。然而,您可能希望在 5 分钟内释放内存,或者希望模型无限期地保留在内存中。使用 keep_alive 参数与 /api/generate 或 /api/chat API 端点,可以控制模型在内存中保留的时间。
keep_alive 参数可以设置为:
1、一个持续时间字符串(例如 10m 或 24h)
2、一个以秒为单位的数字(例如 3600)
3、任何负数,这将使模型无限期地保留在内存中(例如 -1 或 -1m)
4、0这将使模型在生成响应后立即卸载
例如:要预加载模型并使其保留在内存中
curl http://127.0.0.1:11434/api/generate -d '{"model": "qwen2", "keep_alive": -1}'
或者,可以通过在启动 Ollama 服务器时设置环境变量==OLLAMA_KEEP_ALIVE ==来更改所有模型在内存中保留的时间。OLLAMA_KEEP_ALIVE 变量使用与上述 keep_alive 参数相同的参数类型。
如果希望覆盖 OLLAMA_KEEP_ALIVE 设置,请使用 keep_alive API 参数与 /api/generate 或 /api/chat API 端点。
6.5 stop 停止服务
停止正在运行的 Ollama 服务
ollama stop deepseek-r1:1.5b
6.6 pull 拉取模型
从模型库中下载模型
test@...:~$ ollama pull --help
Pull a model from a registry
Usage:
ollama pull MODEL [flags]
Flags:
-h, --help help for pull
--insecure Use an insecure registry
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
案例:
ollama pull deepseek-r1:1.5b --insecure
ollama pull --insecure命令用于在拉取模型时忽略SSL证书验证。在使用Ollama框架拉取模型时,如果遇到SSL证书验证问题,可以使用该命令来忽略证书验证,确保模型能够成功拉取。
使用场景和示例
在拉取模型时,如果遇到SSL证书验证错误,可以使用–insecure参数来忽略证书验证。
6.7 push 推送模型
将自定义模型推送到模型库。
test@...:~$ ollama push --help
Push a model to a registry
Usage:
ollama push MODEL [flags]
Flags:
-h, --help help for push
--insecure Use an insecure registry
Environment Variables:
OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
ollama push test --insecure
关于—insecure参数参考pull。
6.8 list 列出模型
查看本地下载的大模型列表,也可以使用简写ls。
test@...:~$ ollama list
NAME ID SIZE MODIFIED
test:latest 3f928c6eb52f 352 MB 4 hours ago
qwen2:0.5b 6f48b936a09f 352 MB 4 hours ago
llava:latest 8dd30f6b0cb1 4.7 GB 14 hours ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 18 hours ago
列表字段说明
NAME:名称
ID:大模型唯一ID
SIZE:大模型大小
MODIFIED:本地存活时间
6.9 ps 列出所有在运模型
查看当前运行的大模型列表。
test@...:~$ ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:1.5b a42b25d8c10a 1.6 GB 100% CPU 4 minutes from now
列表字段说明
NAME:大模型名称
ID:唯一ID
SIZE:模型大小
PROCESSOR:资源占用
UNTIL:运行存活时长
6.10 cp 复制模型
ollama cp命令只是对模型重命名,指向的还是原来的模型文件,并不能直接加载多个相同的模型使用。
test@...:~$ ollama list
NAME ID SIZE MODIFIED
qwen2:0.5b 6f48b936a09f 352 MB 4 hours ago
llava:latest 8dd30f6b0cb1 4.7 GB 15 hours ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 18 hours ago
test@...:~$ ollama cp qwen2:0.5b qwencp
copied 'qwen2:0.5b' to 'qwencp'
test@...:~$ ollama list
NAME ID SIZE MODIFIED
qwencp:latest 6f48b936a09f 352 MB 4 seconds ago
qwen2:0.5b 6f48b936a09f 352 MB 4 hours ago
llava:latest 8dd30f6b0cb1 4.7 GB 15 hours ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 18 hours ago
6.11 rm 删除模型
删除本地大模型。
ollama rm qwencp:latest
6.12 help 帮助信息
使用ollama [command] –help查看指令的更多信息。
7 开通远程访问
如果访问虚拟机中的Ollama API,需要开通Ollama的远程访问权限。
注意:
如果通过WSL部署Ollama,则 http://127.0.0.1:11434/ 就能访问。如果开启了远程访问权限,则需要访问 http://虚拟机IP:11434。
7.1 增加环境变量
- 在/etc/profile中增加环境变量。
export OLLAMA_HOST=0.0.0.0:11434
export OLLAMA_ORIGINS=*
- 然后通过一下命令,生效环境变量:
sudo source /etc/profile
7.2 修改服务配置
修改服务文件/etc/systemd/system/ollama.service内容如下:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
Environment="OLLAMA_MODELS=/home/test/ollama"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_ORIGINS=*"
[Install]
WantedBy=default.target
7.3 生效修改的配置
# 重新加载系统服务的配置文件
sudo systemctl daemon-reload
# 重启服务
sudo systemctl restart ollama
7.4 开放防火墙端口
sudo firewall-cmd --zone=public --add-port=11434/tcp --permanent
sudo firewall-cmd --reload
8 API
Ollama对客户端相关的命令也提供API操作的接口,方便在企业应用中通过程序类操作私有大模型。
具体可查阅:https://github.com/ollama/ollama/blob/main/docs/api.md
注意:
/api/generate 内容生成接口
它是一个相对基础的文本生成端点,主要用于根据给定的提示信息生成一段连续的文本。这个端点会基于输入的提示,按照模型的语言生成能力输出一段完整的内容,更侧重于单纯的文本生成任务。
生成过程不依赖于上下文的历史对话信息,每次请求都是独立的,模型仅依据当前输入的提示进行文本生成。/api/chat 聊天对话接口
该端点专为模拟聊天场景设计,具备处理对话上下文的能力。它可以跟踪对话的历史记录,理解对话的上下文信息,从而生成更符合对话逻辑和连贯性的回复。
更注重模拟真实的人机对话交互,能够根据历史对话和当前输入生成合适的回应,适用于构建聊天机器人等交互式应用。

一站式 AI 云服务平台
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)