
机器学习学习笔记——第一章:绪论
了解一下什么是机器学习
·
机器学习
机器学习学习笔记——第一章:绪论
文章目录
机器学习即为构建一个机器调参的映射函数。 要进行机器学习,先要有数据。
一、基础术语
1.1、数据准备阶段
- 数据集:数据的集合
- 示例:对一个事件或对象的描述
- 样本:示例或数据集
- 属性(/特征):反映事件或对象在某方面的表现或性质
- 属性/样本/输入空间:以属性为轴,张开的空间,每一个示例都可以找到自己的坐标位置。
- 特征向量:示例(空间中每个点对应一个坐标向量)
1.2、学得模型阶段
- 期间数据的相关称呼为:训练数据,训练样本(/示例/例),训练集
- 学习(/训练):通过执行某个学习算法来从数据中学得模型
- 设置不同的参数值(学习算法)和(或)使用不同的训练数据将产生不同的结果
- 标记:示例的结果
- 标记/输出空间:标记的集合
- 学习任务有两类:
- 监督学习:训练数据有标记,主要有分类与回归
- 分类:标记为离散值
- 二分类:只有两个值(其中一个类别为:正类,另一个为:反/负类),二分类问题是最基础的问题。
- 通常我们假设正负类,是可以交换的,这就意味着这两类的很多性质相差不大(例如两类在总数中占比相差不大)
- 多分类:有三个及以上的分类,其可以被拆分为多个二分类问题。
- 二分类:只有两个值(其中一个类别为:正类,另一个为:反/负类),二分类问题是最基础的问题。
- 回归:标记为连续值
- 分类:标记为离散值
- 监督学习:训练数据有标记,主要有分类与回归
- 模型:对训练集进行学习,建立一个从输入空间X到输出空间Y的映射,对于二分类任务,通常令Y={-1,+1}或{0,1},对于多分类任务,|Y|>2,对回归任务,Y=实数集
- 无监督学习 :训练数据无标记,主要为聚类
- 聚类:将训练集中的示例分为若干组,每一组称为一个簇,其可能对应我们不知道的潜在概念
- 无监督学习 :训练数据无标记,主要为聚类
1.3、测试模型阶段
- 期间数据的相关称呼为:测试数据,测试样本(/示例/例)
- 泛化:使学得模型适用于新样本
- 独立同分布:通常假设样本空间中全体样本服从一个未知的分布,我们获得的每个样本都是独立地从这个分布上采样获得的
1.4、典型的机器学习过程
- 机器学习的目的是为了获得正确的模型,模型由学习算法直接获得,所以机器学习主要是对学习算法进行研究
- 由于训练数据的不同,即使使用相同的学习算法也可能得出不同的模型
- 为了学得想要的模型,需要判断训练数据的特征,选择合适的学习算法
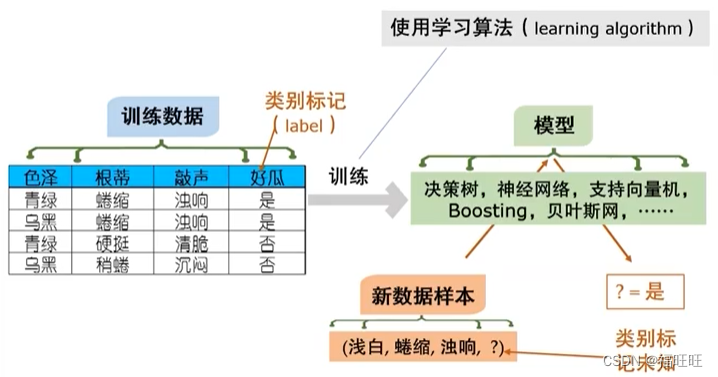
1.5、总结
- 一般而言,训练样本越多,得到关于独立同分布的信息越多,越可能通过学习获得具有强泛化能力的模型。
二、假设空间
科学推理的两大基础手段:
- 归纳:从特殊到一般的泛化过程,从具体事件归纳出一般性质
- 演绎:从一般到特殊的特化过程,从基础原理推演出具体状况
模型的构建是从样例中学习得到的,属于归纳的过程,亦称为归纳学习
-
分类
- 广义:从样例中学习
- 狭义:从训练数据中学得概念,亦称为概念学习/形成(实现难度高,研究少)
-
假设空间:学习过程可以看作一个利用许多策略在所有假设组成的空间中进行搜索的过程,搜索目标是找到与训练集匹配的假设(既对所有训练样本能够进行正确的判断)。
- 模型对应了假设空间中的一个假设。
- 示例:假设空间由三种属性,每个属性有三种属性值,还需要考虑到任何属性值都符合此概念的情况(用通配符 * 表示),与概念不存在的极端情况,则该假设空间的大小为4 * 4 * 4 + 1 = 65
-
版本空间:现实问题中假设空间很大,但学习过程是基于有限样本训练集进行的,可能存在多个假设与训练集已知,既存在着与训练集一致的假设集合,称之为版本空间
- 示例:若训练集为
| 编号 | 颜色 | 根蒂 | 敲声 | 好瓜 |
|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 是 |
| 2 | 乌黑 | 蜷缩 | 浊响 | 是 |
| 3 | 青绿 | 硬挺 | 清脆 | 否 |
| 4 | 乌黑 | 稍蜷 | 沉闷 | 否 |
则对应的版本空间为(色泽= * ;根蒂=蜷缩;敲声=浊响),(色泽= * ;根蒂= * ;敲声=浊响),(色泽= * ;根蒂=蜷缩;敲声= * )
三、归纳偏好
- 学得的模型对应假设空间中的一个假设,但上述例子中的版本空间有三个假设空间,当面临新的样本时却会产生不同的结果,若仅有训练集,则无法推测哪个假设最优,但对于一个具体的学习算法,必须要产生一个模型,这时候就需要有一个偏好。
- 示例:学习算法本身偏好“尽可能特殊的”模型,就会选择(色泽= * ;根蒂=蜷缩;敲声=浊响)
- 归纳偏好:机器算法在学习过程中对某种类型假设的偏好
- 任何一个有效的机器学习算法必有其归纳偏好。
- 归纳偏好本身可以看作学习算法自身在假设空间对假设进行选择的“价值观”
- 在机器学习的过程中会运用一般性的原则(例如奥卡姆剃刀:若有多个假设与观察一致,则选最简单的那个)来引导算法确立“正确的”偏好
- 没有免费的午餐(No Free Lunch Theorem,NFL)定理:很可惜,即使机器学习有”正确的“偏好产生的算法,与“非正确的”偏好产生的算法,两者的期望性能是相同的,算法A在某些问题上优于算法B,那就一定存在另一些问题,在那里算法B要优于算法A
- 既所谓的“正确的”偏好,是相对正确,是针对某些问题而言的
- 当然,这里的NFL定理有个很重要的前提,那就是所有的问题出现的机会是相同的,或同等重要。但是实际问题中,我们更关心自己正在解决的问题,其他问题我们并不关心。
- NFL定理的意义:具体问题,具体分析。针对具体的问题,去考虑学习算法的归纳偏好是否与之匹配,才是关键。若考虑所有潜在问题,则所有的学习算法都一样的好。
- 问题:这里指代的问题需要指明详细的输入域X和输出域Y
四、机器学习理论
- 其中最重要的理论为:PAC(Probably Approximately Correct,概率近似正确)learning model
- P ( | f ( x ) - y | ≤ ε ) ≥ 1 - δ
- 算法推导:假设我们存在一个数据集x,通过机器学习获得的模型f,计算获得结果为f ( x ),我们拿这个结果去和真实结果y进行比较,期望两者的结果相似乃至相同,既| f ( x ) - y | ≤ ε ,ε无限接近于0,但是这里的模型f并不是每次都会得到想要的结果,于是我们期望发生上述这件事的概率P尽可能的大,既P ( | f ( x ) - y | ≤ ε ) ≥ 1 - δ,如果这里的δ无限接近于0,那发生的概率P就无限接近于1,那说明我们的模型就越好。
- 问题:知道这个算式的意思后就有两个问题。
- 问题一:既然它是为了判断机器学习获得的模型的好坏,为什么不能直接根据 f ( x ) - y 的结果判断,反而引入了概率P的概念
- 问题二:既然我们期望获得一个好模型, f ( x ) - y 的结果判断为什么不直接等于0,这样意味着我们的模型绝对可以获得一个正确的结果
- 回答:上述的两个问题其实可以归纳为一点,学得的模型能否每一次都绝对获得正确的答案
- 从机器学习的角度:
- 机器学习所解决的问题具有高度的不确定性,复杂性,有时候甚至不知道怎么做,所以我们才期望机器学习从数据中找到答案,所以不可能存在绝对的可能性。
- 从代数算法的角度:
- 如果算法中的ε和δ都等于0,那就相当于在讨论P问题和NP问题时,需要P=NP才能使得算法成立,既所有能在多项式时间内验证得出正确解的问题(NP),都是具有多项式时间算法(P)的问题,换个说法就是,要是成立,那所有的NP问题都可以通过计算机来解决,你在进行goole搜索时,每次它都可以在有限的时间内提供最优的解,至少目前还无法解决P=NP?的问题。
- 从机器学习的角度:
- 所以这个理论告诉我们,机器学习期望学得的模型,是能够高概率下获得较好的预测结果。
五、机器学习的现实应用
机器学习的内容不像是数学,从最基础的知识进行衍生,最终习得高深的知识。它是一块一块的,例如线性模型,决策树,神经网络这些。所以有些人就提出将这些典型算法学会后,遇到问题往上套,是不是就可以习得模型。
很可惜,上面刚刚提到了NFL定理,没有算法是万能的,我们也不可能指望用这几个算法去解决所有问题。最优的方案往往是,提出具体的需求后,量身定制。
例如采用决策树的形式,运用了支持向量机中的某种思想等。
所以在建模之前,一定要搞清楚具体需求,机器学习只关心这部分需求。

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)