
AI 大模型中的 Token,不同模型对 Token 的处理
在进行 AI 大模型应用开发时,很多人接触到的第一个相对陌生的概念,就是 token。但是 token 又是绕不开的名词,token 是大模型输入和输出的计量单位,更重要的,token 也是使用大模型时的计费单位。token 是大模型对文本进行编码的一种方式。计算机理解的不是文本,而是数值。不管是文本,还是图像和视频,在计算机内部的编码方式都是数值。更具体的来说,是数值的数组,也就是向量。以文本来
在进行 AI 大模型应用开发时,很多人接触到的第一个相对陌生的概念,就是 token。但是 token 又是绕不开的名词,token 是大模型输入和输出的计量单位,更重要的,token 也是使用大模型时的计费单位。
token 是大模型对文本进行编码的一种方式。计算机理解的不是文本,而是数值。不管是文本,还是图像和视频,在计算机内部的编码方式都是数值。更具体的来说,是数值的数组,也就是向量。
以文本来说,token 是文本分割的最小单位。不同模型有各自的切分方法。一个 token 可以是一个单词、一个词组、一个标点符号、一个字符。
下面通过几个具体的例子来演示一下,以通义千问和 OpenAI 的 GPT-4o 为例。
首先是简单的句子:This is an apple. 两个模型都把这句话切分成 5 个 token,4 个英文单词和句号,每个都是一个 token。相同单词所对应的 token,内部的 ID 可能不一样。token 的 id 就是 token 的数值表示。
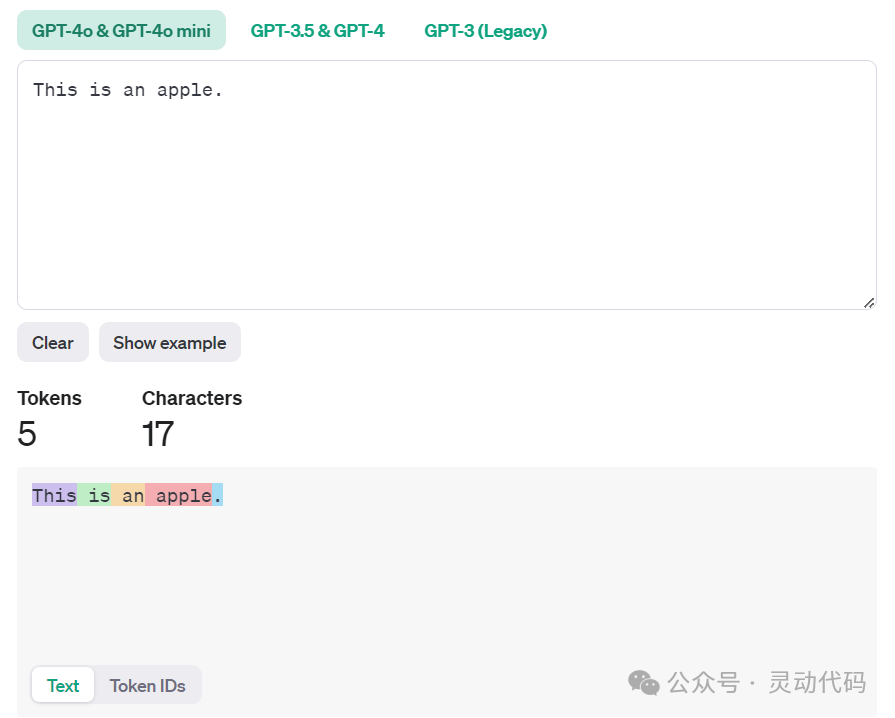

下面是一段更长的文本,是林肯著名的葛底斯堡演讲。通义千问切分成 313 个 token,GPT-4o 切分成 314 个 token。这里比较特别的是,对第一个单词 Fourscore(八十年) 的处理。这一个单词被切分成了3个token,依次是 F,ours 和 core,两个模型都是一样的处理方式。

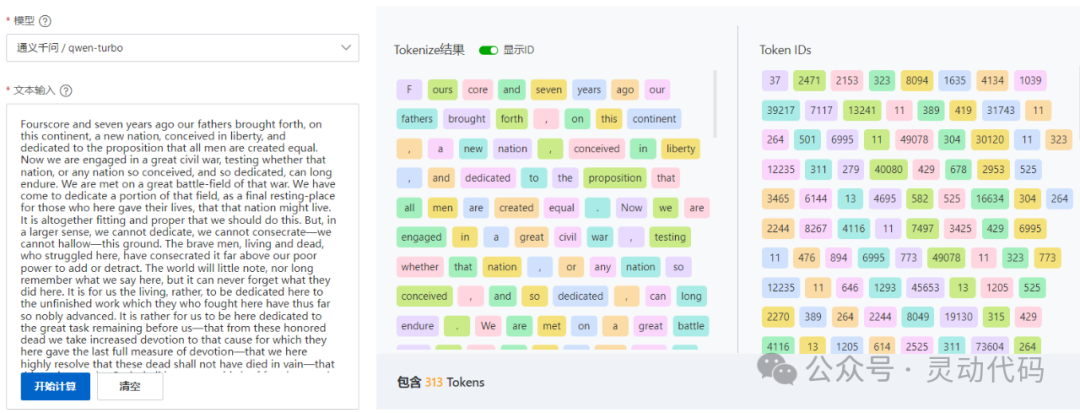
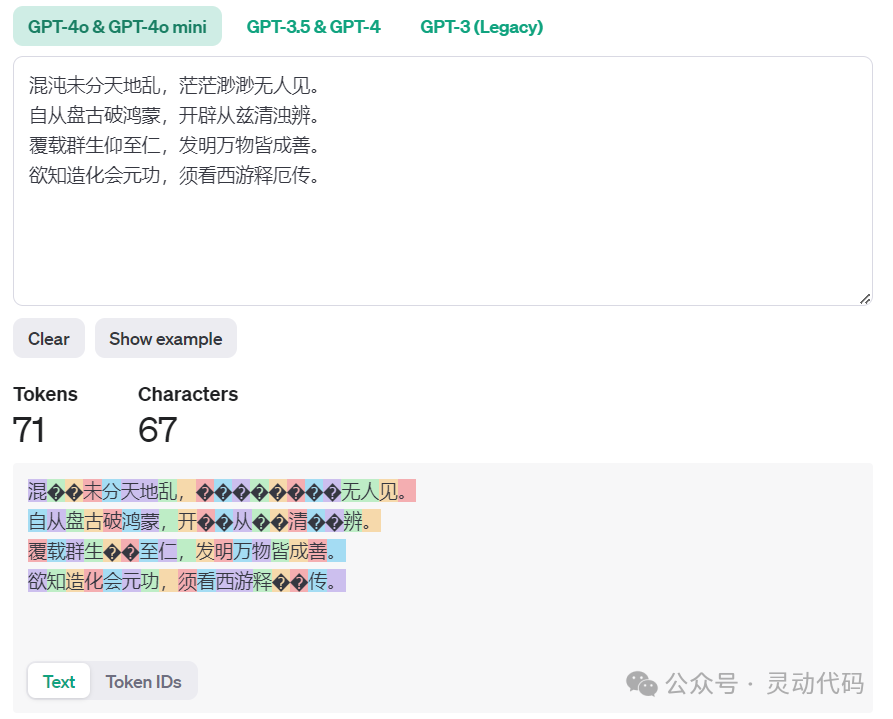
最后看一下中文的处理。用的例子是西游记开头的诗,通义千问切分成 56 个 token,GPT-4o 切分成 71 个 token。从 token 数量可以看出,同样的 token 数量限制,通义千问可以编码更多的中文字符。

在实际的大模型应用开发中,具体接触到 token 的机会并不多。一个具体的场景是对文本进行切分。这也是检索增强生成应用中的重要一环。对一段文本进行切分时,可以按 token 来进行切分,这样更符合大模型的使用方式。Spring AI 内置提供了 TokenTextSplitter,按照 token 来切分文本。TokenTextSplitter 对文本进行编码时,使用的是 jtokkit 库,编码方式与 OpenAI 的模型兼容。
很多模型服务都提供了 token 化的 API,可以调用 API 来获取 token 化的结果。比如,通义千问就有相关的 API,调用时不收取费用。


一站式 AI 云服务平台
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)