
深度学习的多个loss如何平衡?
前言问题:在一个端到端训练的网络中,如果最终的loss = a*loss1+b*loss2+c*loss3...,对于a,b,c这些超参的选择,有没有什么方法?整理自丨知乎链接丨深度学习的多个loss如何平衡? - 知乎回答1作者:Evan链接:https://www.zhihu.com/question/375794498/answer/1052779937来源:知乎著作权归作者所有。商业转载请
前言
问题:在一个端到端训练的网络中,如果最终的loss = a*loss1+b*loss2+c*loss3...,对于a,b,c这些超参的选择,有没有什么方法?
整理自丨知乎
回答1
作者:Evan
链接:https://www.zhihu.com/question/375794498/answer/1052779937
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
其实这是目前深度学习领域被某种程度上忽视了的一个重要问题,在近几年大火的multi-task learning,generative adversarial networks, 等等很多机器学习任务和方法里面都会遇到,很多paper的做法都是暴力调参结果玄学……这里偷偷跟大家分享两个很有趣的研究视角
- 从预测不确定性的角度引入Bayesian框架,根据各个loss分量当前的大小自动设定其权重。有代表性的工作参见Alex Kendall等人的CVPR2018文章 Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics,文章的二作Yarin Gal是Zoubin Ghahramani的高徒,近几年结合Bayesian思想和深度学习做了很多solid的工作。
- 构建所有loss的Pareto,以一次训练的超低代价得到多种超参组合对应的结果。有代表性的工作参见Intel在2018年NeurIPS(对,就是那个刚改了名字的机器学习顶会)发表的Multi-Task Learning as Multi-Objective Optimization 因为跟文章的作者都是老熟人,这里就不尬吹了,大家有兴趣的可以仔细读一读,干货满满。
回答2
作者:杨奎元
链接:https://www.zhihu.com/question/375794498/answer/1050963528
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 一般都是多个loss之间平衡,即使是单任务,也会有weight decay项。比较简单的组合一般通过调超参就可以。
- 对于比较复杂的多任务loss之间平衡,这里推荐一篇通过网络直接预测loss权重的方法[1]。以两个loss为例,
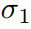 和
和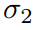 由网络输出,由于整体loss要求最小,所以前两项希望
由网络输出,由于整体loss要求最小,所以前两项希望 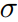 越大越好,为防止退化,最后第三项则希望
越大越好,为防止退化,最后第三项则希望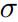 越小越好。当两个loss中某个比较大时,其对应的
越小越好。当两个loss中某个比较大时,其对应的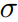 也会取较大值,使得整体loss最小化,也就自然处理量纲不一致或某个loss方差较大问题。
也会取较大值,使得整体loss最小化,也就自然处理量纲不一致或某个loss方差较大问题。
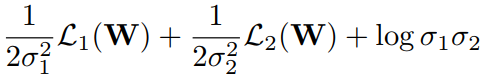
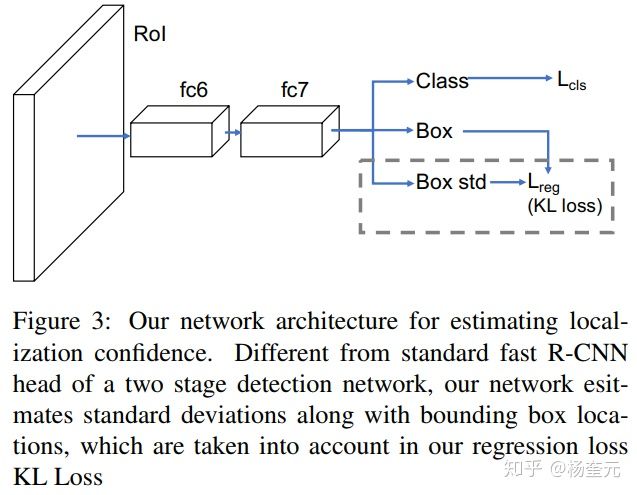
该方法后来被拓展到了物体检测领域[2],用于考虑每个2D框标注可能存在的不确定性问题。
[1] Alex Kendall, Yarin Gal, Roberto Cipolla. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. CVPR, 2018.
[2] Yihui He, Chenchen Zhu, Jianren Wang, Marios Savvides, Xiangyu Zhang. Bounding Box Regression with Uncertainty for Accurate Object Detection. CVPR, 2019.
回答3
作者:牛油果博士
链接:https://www.zhihu.com/question/375794498/answer/2291842390
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
对于多任务的loss,最简单的方式是直接将这两个任务的loss直接相加,得到整体的loss,这种loss计算方式的不合理之处是显而易见的,不同任务loss的量级很有可能不一样,loss直接相加的方式有可能会导致多任务的学习被某个任务所主导或学偏。当模型倾向于去拟合某个任务时,其他任务的效果往往可能受到负面影响,效果会相对变差(这是不是有一种零和博弈的感觉,当然也有跷跷板的感觉)。
相对于loss直接相加的方式,这个loss函数对于每个任务的loss进行加权。这种方式允许我们手动调整每个任务的重要性程度;但是固定的w会一直伴随整个训练周期。这种loss权重的设置方式可能也是存在问题的,不同任务学习的难易程度也是不同的;且,不同任务可能处于不同的学习阶段,比如任务A接近收敛,任务B仍然没训练好等。这种固定的权重在某个阶段可能会限制了任务的学习。
其实这是目前深度学习领域被某种程度上忽视了的一个重要问题,在近几年大火的multi-task learning,generative adversarial networks,等等很多机器学习任务和方法里面都会遇到,很多paper的做法都是暴力调参结果玄学。
极端情况下,当某个任务的loss非常的大而其它任务的loss非常的小,此时多任务近似退化为单任务目标学习,网络的权重几乎完全按照大loss任务来进行更新,逐渐丧失了多任务学习的优势。
对于如何解决多个loss平衡的问题,可以查看以下几篇论文:
1、Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics(基于任务不确定性)
2、GradNorm:Gradient Normalization for Adaptive(基于梯度更新)
3、另外还有研究将该问题看做多目标优化问题,这样做的好处是:在优化时将任务之间看做竞争关系,,而不是看作简单的线性组合,这样扩展了模型的适用范围。一个代表性的工作:Multi-Task Learning as Multi-Objective Optimization
4、Efficient Continuous Pareto Exploration in Multi-Task Learning
回答4
作者:hzwer
链接:https://www.zhihu.com/question/375794498/answer/2292320194
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这也是个困扰了我多年的问题:
loss = a * loss1 + b * loss2 + c * loss3 怎么设置 a,b,c?
我的经验是 loss 的尺度一般不太影响性能,除非本来主 loss 是 loss1,但是因为 b,c 设置太大了导致其他 loss 变成了主 loss。
实践上有几个调整方法:
- 手动把所有 loss 放缩到差不多的尺度,设 a = 1,b 和 c 取 10^k,k 选完不管了;
- 如果有两项 loss,可以 loss = a * loss1 + (1 - a) * loss2,通过控制一个超参数 a 调整 loss;
- 我试过的玄学躺平做法 loss = loss1 / loss1.detach() + loss2 / loss2.detach() + loss3 loss3.detach(),分母可能需要加 eps,相当于在每一个 iteration 选定超参数 a, b, c,使得多个 loss 尺度完全一致;进一步更科学一点就 loss = loss1 + loss2 / (loss2 / loss1).detach() + loss3 / (loss3 / loss1).detach(),感觉比 loss 向 1 对齐合理
某大佬告诉我,loss 就像菲涅尔透镜,纵使你能设计它的含义,也很难设计它的梯度。所以暴力一轮就躺平了。我个人见解,很多 paper 设计一堆 loss 只是为了让核心故事更完整,未必强过调参。
回答5
作者:郑泽嘉
链接:https://www.zhihu.com/question/375794498/answer/1056695768
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Focal loss 会根据每个task的表现帮你自动调整这些参数的。
我们的做法一般是先分几个stage 训练。stage 0 : task 0, stage 1: task 0 and 1. 以此类推。 在stage 1以后都用的是focal loss。
========== 没想到我也可以二更 ===============
是这样的。
首先对于每个 Task,你有个 Loss Function,以及一个映射到 [0, 1] 的 KPI (key performance indicator) 。比如对于分类任务, Loss function 可以是 cross entropy loss,KPI 可以是 Accuracy 或者 Average Precision。对于 regression 来说需要将 IOU 之类的归一化到 [0, 1] 之间。KPI 越高表示这个任务表现越好。
对于每个进来的 batch,每个Task_i 有个 loss_i。 每个Task i 还有个不同的 KPI: k_i。那根据 Focal loss 的定义,FL(k_i, gamma_i) = -((1 - k_i)^gamma_i) * log(k_i)。一般来说我们gamma 取 2。
于是对于这个 batch 来说,整个 loss = sum(FL(k_i, gamma_i) * loss_i)
在直观上说,这个 FL,当一个任务的 KPI 接近 0 的时候会趋于无限大,使得你的 loss 完全被那个表现不好的 task 给 dominate。这样你的back prop 就会让所有的权重根据那个kpi 不好的任务调整。当一个任务表现特别好 KPI 接近 1 的时候,FL 就会是0,在整个 loss 里的比重也会变得很小。
当然根据学习的速率不同有可能一开始学的不好的task后面反超其他task。 http://svl.stanford.edu/assets/papers/guo2018focus.pdf 这篇文章里讲了如何像momentum 一样的逐渐更新 KPI。
由于整个 loss 里现在也要对 KPI 求导,所以文章里还有一些对于 KPI 求导的推导。
当然我们也说了,KPI 接近 0 时,Loss 会变得很大,所以一开始训练的时候不要用focal loss,要确保网络的权重更新到一定时候再加入 focal loss。
希望大家训练愉快。
回答6
作者:nowhere
链接:https://www.zhihu.com/question/375794498/answer/1234726061
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
补充:最近看到了一篇关于多任务学习的综述,3.1章里针对多种优化方法做了分类和总结,包括了回答中的大多数文献,因此在最前面附上链接:
2004.13379.pdf (arxiv.org)arxiv.org/pdf/2004.13379.pdf
小白刚开始研究MTL相关的内容,回答和评论区很多都看不懂,先占个坑,慢慢记录自己的思考和实验。欢迎一起交流进步
下面是我看了最高赞提到的和其他的相关论文,加了一些自己的理解,做了一个相对详细的介绍
1、Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics(基于任务不确定性)
https://arxiv.org/abs/1705.07115arxiv.org/abs/1705.07115
在多任务学习中,任务依赖不确定性能够表示不同任务间的相对难度,而通过任务难度可以给各损失加权。因此基于任务不确定性,通过对回归/分类任务做高斯似然估计/softmax函数估计,再将各任务的估计相加作为多任务估计,最终得到具有同方差任务不确定性的多任务目标函数。
实际上就是作者分别对两个回归任务和两个分类任务作为多任务的情况进行了推导,得出这种情况下的单任务对应的公式,回归和分类任务混合的情况就是简单的线性相加。
这篇的思路很棒,但是应用时具有一定的局限性
2、GradNorm:Gradient Normalization for Adaptive(基于梯度更新)
https://arxiv.org/abs/1711.02257v4arxiv.org/abs/1711.02257v4
这篇的核心思想是:多任务学习中的不平衡实际上是各任务训练梯度的不平衡,因此论文关注各损失函数权重的梯度,利用梯度更新公式动态更新权重ω。即ω(t+1)=ω(t)+λβ(t)。由于目的是平衡各任务的训练梯度,所以式中β(t)是各任务梯度对ω的导数,λ沿用全局神经网络的学习率,为此设计了一种梯度损失(Grad Loss)。(参考https://blog.csdn.net/Leon_winter/article/details/105014677,侵删)
感觉这篇应该会比较好复现一些,因为没有对任务类型的限制,不需要进一步的公式推导,等实验室的服务器开了尝试一下。
3、另外还有研究将该问题看做多目标优化问题,这样做的好处是:在优化时将任务之间看做竞争关系,,而不是看作简单的线性组合,这样扩展了模型的适用范围。
一个代表性的工作:Multi-Task Learning as Multi-Objective Optimization
Multi-Task Learning as Multi-Objective Optimizationarxiv.org/abs/1810.04650
这篇的核心思想是:将多任务学习看做多目标优化,将问题转化为求取Pareto最优解(从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕累托改进或帕累托最优化)。(由于这方面的数学知识并不具备,我无法很好地具体描述方法,可参考https://blog.csdn.net/icylling/article/details/86249462)
另外今天在知乎上看到一篇文章,也是利用Pareto来实现多任务学习,链接如下:

一站式 AI 云服务平台
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)