
【Python原创毕设|课设】基于Flask(机器学习)的农作物产量预测与可视化分析系统(xgboost)-文末附下载方式以及往届优秀论文,原创项目其他均为抄袭
基于Flask的农作物产量预测分析与可视化系统,旨在帮助农民和相关从业者更好地预测农作物产量,以优化农业生产。该系统主要包括四个功能模块。首先,农作物数据可视化模块利用Echarts、Ajax、Flask、PyMysql技术实现了可视化展示农作物产量相关数据的功能。其次,产量预测模块使用pandas、numpy等技术,通过对气象和农作物产量关系数据集的分析和训练,实现了对农作物产量的预测功能。该模
一、项目简介
基于Flask的农作物产量预测分析与可视化系统,旨在帮助农民和相关从业者更好地预测农作物产量,以优化农业生产。该系统主要包括四个功能模块。
首先,农作物数据可视化模块利用Echarts、Ajax、Flask、PyMysql技术实现了可视化展示农作物产量相关数据的功能。
其次,产量预测模块使用pandas、numpy等技术,通过对气象和农作物产量关系数据集的分析和训练,实现了对农作物产量的预测功能。该模块可以对当前或未来某一时间段的农作物产量进行预测,并提供预测结果的可视化展示。
然后,用户登录与用户注册模块使用layui、Flask、PyMysql技术实现了用户登录和注册功能。用户可以通过登录系统后,利用该系统提供的预测和可视化功能,更好地规划和管理自己的农业生产。
最后,数据管理模块使用layui、Flask、PyMysql技术,实现了用户管理、公告管理和农作物数据管理等功能。系统管理员可以通过后台界面对用户信息、公告信息和农作物数据进行管理和维护,保证系统的正常运行和信息安全。
本系统的实现对农业生产的优化具有积极的意义。通过对气象和农作物产量关系数据的分析和训练,该系统可以帮助用户更好地了解不同作物产量随时间变化的趋势和规律,提高农作物的产量和品质,促进农业生产的可持续发展。
二、开发环境
| 开发环境 | 版本/工具 |
|---|---|
| PYTHON | 3.6.8 |
| 开发工具 | PyCharm |
| 操作系统 | Windows 10 |
| 内存要求 | 8GB 以上 |
| 浏览器 | Firefox (推荐)、Google Chrome (推荐)、Edge |
| 数据库 | MySQL 8.0 (推荐) |
| 数据库工具 | Navicat Premium 15 (推荐) |
| 项目框架 | FLASK |
三、项目技术
后端:Flask、sklearn、PyMySQL、MySQL、urllib
前端:Jinja2、Jquery、Ajax、layui
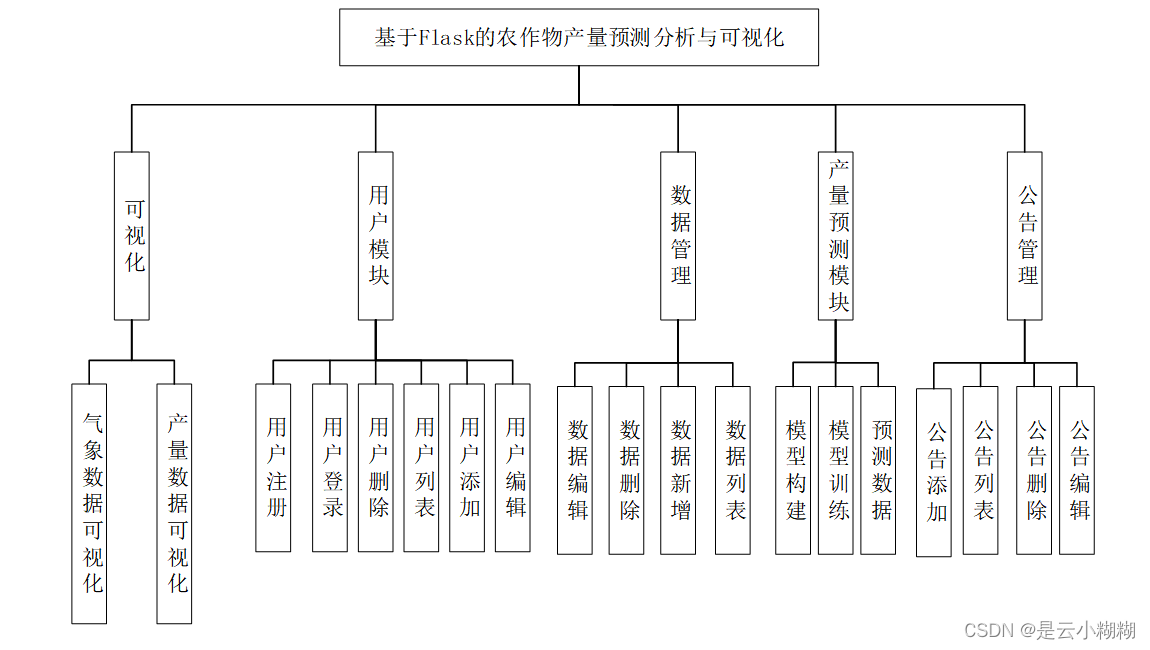
四、功能结构
农作物产量大屏数据可视化模块:通过ECharts实现数据可视化,展示农作物产量的趋势、关联因素等。
机器学习预测农作物产量模型构建与训练:使用Scikit-learn、Pandas、NumPy构建机器学习模型,对农作物产量进行预测(数据集来自阿里云AI竞赛课题)。
用户登录与注册:通过Flask、PyMySQL、LAYUI实现用户登录和注册功能。
系统后台管理模块:
-
用户模块:管理用户信息,权限等。
-
公告模块:发布和管理系统相关公告信息。
-
农作物数据管理模块:存储和管理与农作物产量预测相关的数据集。
-
预测可视化后台交互:提供用户与预测数据的交互界面,使用Ajax请求后端数据接口展示数据可视化结果。
五、运行截图
首页可视化: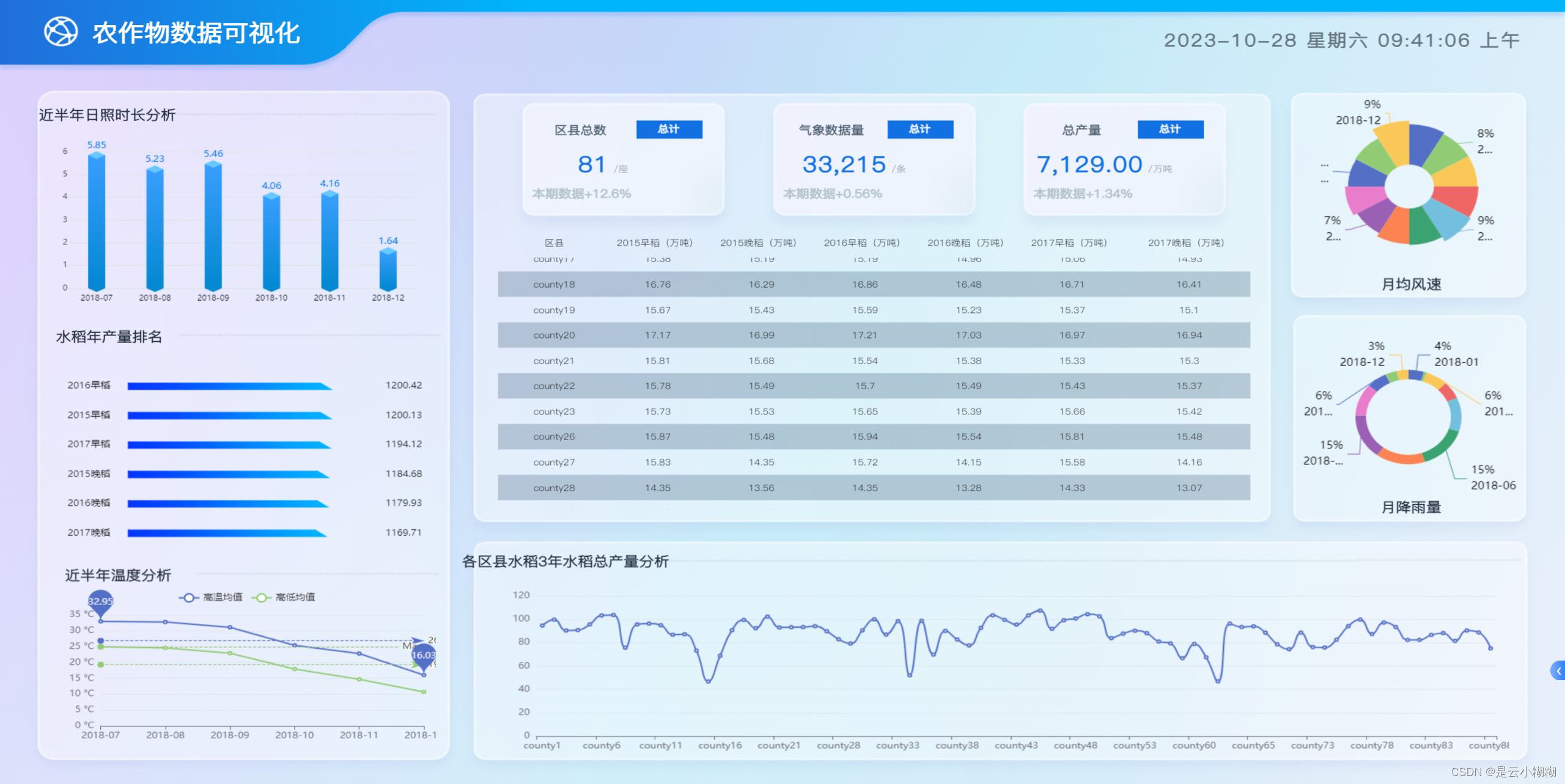
登录页面:
注册页面:
后台管理首页:
用户管理: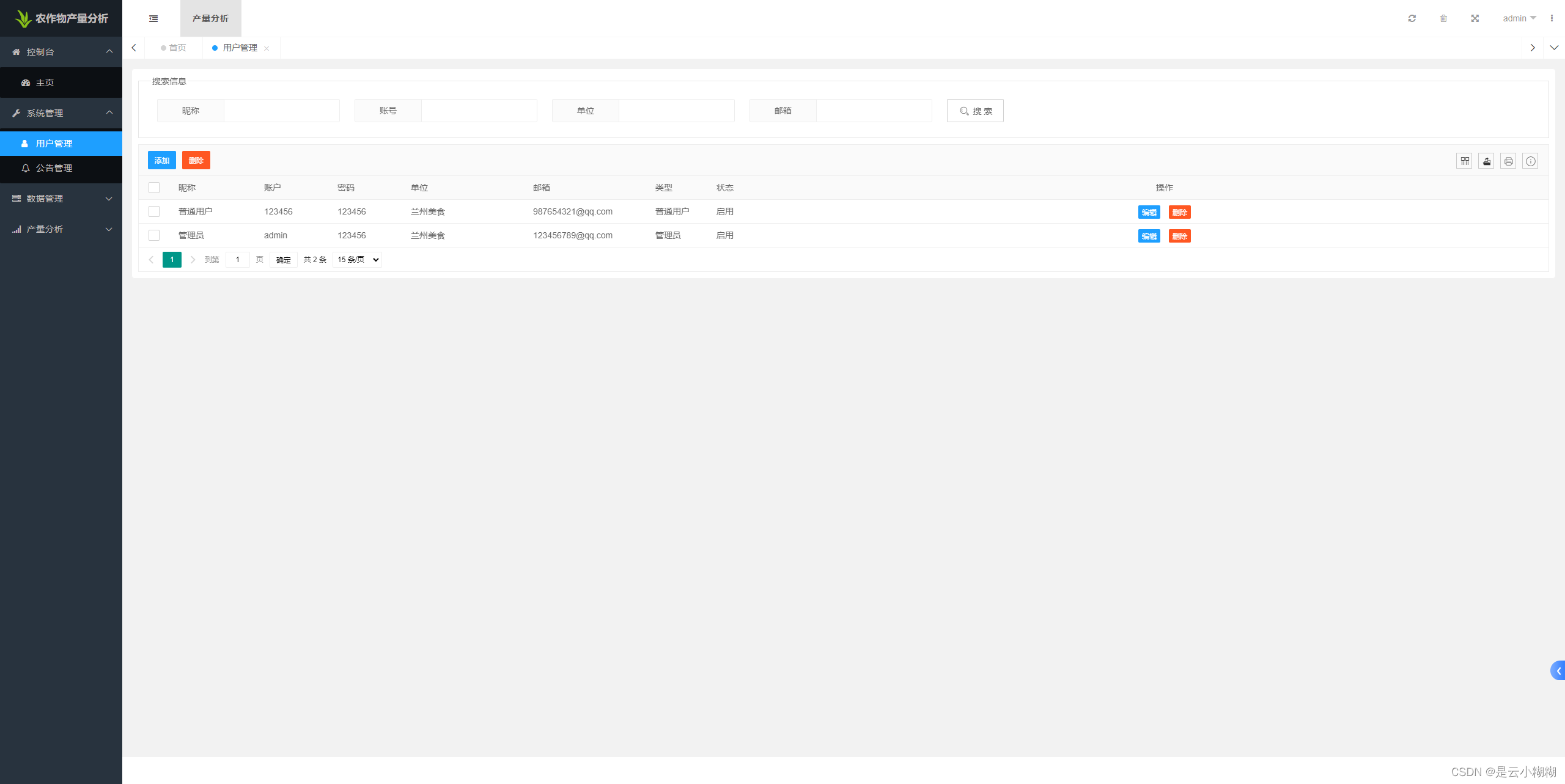
公告管理:
产量数据管理:
气象数据管理:
产量预测管理: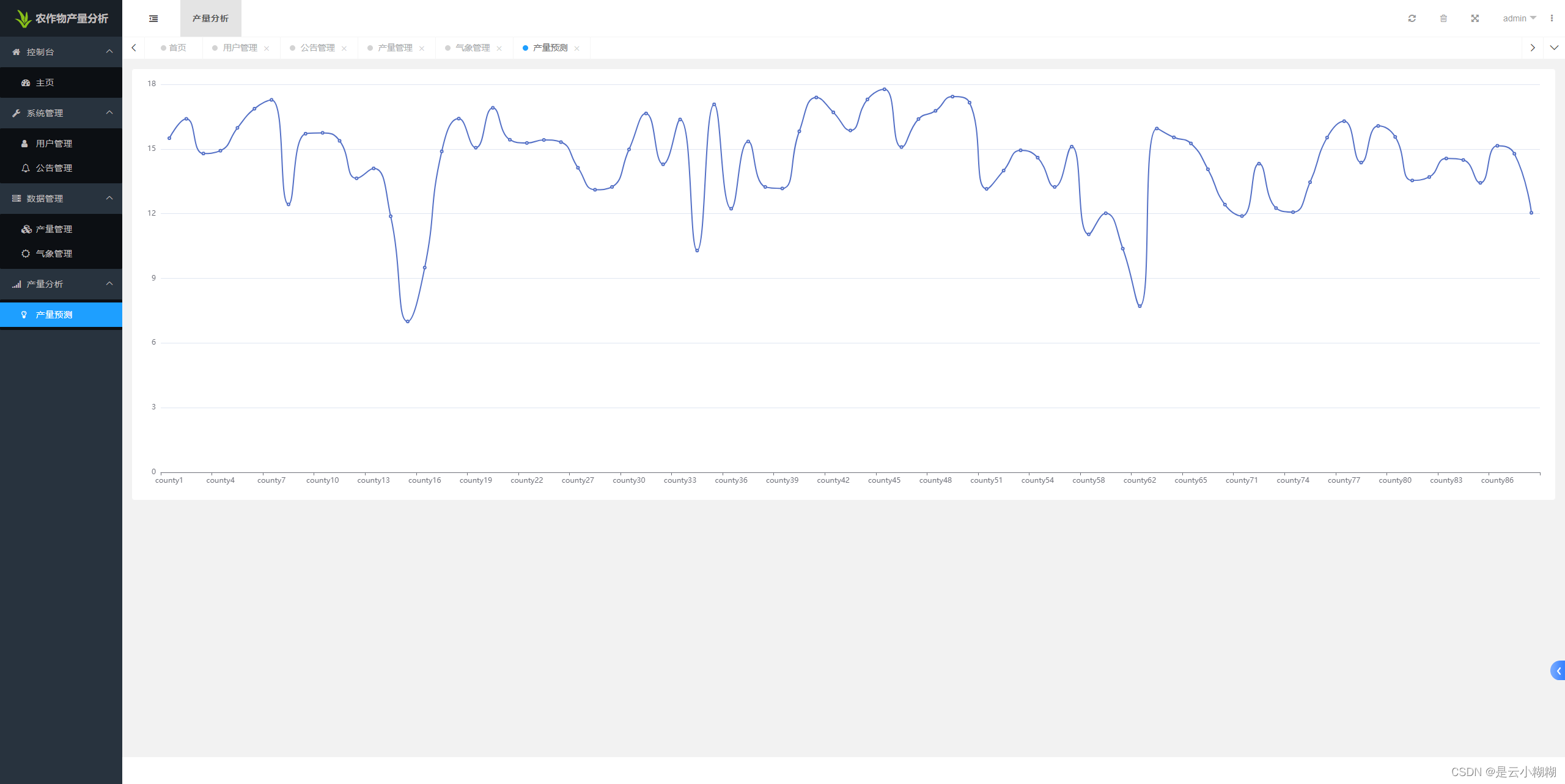
六、功能实现
*模型构建*
def model(X_data,y_label,testst,prediction):
"""
模型搭建
"""
global params_xgb #模型参数,设置全局变量便于调参
n_splits = 25
res = []
kf = KFold(n_splits = n_splits, shuffle=True, random_state=520)
for i, (train_index, test_index) in enumerate(kf.split(X_data)):
print('第{}次训练...'.format(i+1))
train_data = X_data.iloc[train_index]
train_label = y_label.iloc[train_index]
valid_data = X_data.iloc[test_index]
valid_label = y_label.iloc[test_index]
xgb_train = xgb.DMatrix(train_data, label=train_label)
xgb_valid = xgb.DMatrix(valid_data, valid_label)
evallist = [(xgb_valid, 'eval'), (xgb_train, 'train')]
cgb_model = xgb.train(params_xgb, xgb_train, num_boost_round=500 , evals=evallist, verbose_eval=500, early_stopping_rounds=300, feval=myFeval)
valid = cgb_model.predict(xgb_valid, ntree_limit=cgb_model.best_ntree_limit)
valid_score = mean_squared_error(valid_label,valid)*0.5
if valid_score > 0.01:
\#验证集分数不好的模型丢弃
continue
xgb_test = xgb.DMatrix(testst)
preds = cgb_model.predict(xgb_test, ntree_limit=cgb_model.best_ntree_limit)
res.append(preds)
print("\n")
训练模型
if __name__ == "__main__":
deal_loss()
change()
change_week()
params_xgb = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'eval_metric': 'rmse', # 对于回归问题,默认值是rmse,对于分类问题,默认值是error
'gamma': 0.1, #损失下降多少才分裂
'max_depth': 4,
'lambda': 1.2, #控制模型复杂度的权重值的L2曾泽化参数,参数越大越不容易过拟合
'subsample': 0.9, #随机采样的训练样本
'colsample_bytree': 0.9, #生成树时特征采样比例
'min_child_weight': 3, # 6
'silent': 0, #信息输出设置成1则没有信息输出
'eta': 0.12, #类似学习率
'seed': 1000,
'nthread': 9,
}
X_data,y_label,testst,prediction = get_data()
model(X_data,y_label,testst,prediction)
df = pd.read_csv("result.csv",encoding="gbk")
df["区县id"] = df["columns"].apply(arr)
df1 = pd.read_csv(path+"train_rice.csv",encoding="gbk")
d = df1[["区县id","2017年晚稻"]]
la = pd.merge(df,d,on="区县id")
score = mean_squared_error(la["pre_xgboost"],la["2017年晚稻"])*0.5
print(score)
s = la[["区县id","pre_xgboost"]]
s.to_csv('x_prediction.csv', index=False,encoding='gbk',header=True)
可视化核心业务
# 获取各个区县3年产量
def get_times_selling():
sqlManager = SQLManager()
sql = "SELECT round(SUM(early2015 + late2015 + early2016 + late2016 + early2017 + late2017), 2) as `value`, county as number, '产量分析' as name FROM `output` GROUP BY county, `name`;"
res = sqlManager.get_list(sql)
return res
# 近半年日照时常统计
def get_months_sun():
times = ['2018-07', '2018-08', '2018-09', '2018-10', '2018-11', '2018-12'] # 半年
data = []
sqlManager = SQLManager()
sql = "SELECT ROUND(avg(sun_time),2) as `value` FROM `weather` where date_format(rec_time,'%%Y-%%m')=%s;"
for t in times:
res = sqlManager.get_one(sql, t)
if not res or not res['value']:
res['value'] = 0
data.append({"time": t, "value": float(res['value']), "name": "近半年日照时常统计"})
return data
# 近半年高低温统计
def get_months_temp():
times = ['2018-07', '2018-08', '2018-09', '2018-10', '2018-11', '2018-12'] # 半年
data_max = []
data_min = []
sqlManager = SQLManager()
sql = "SELECT ROUND(avg(temp_max),2) as `value1` ,ROUND(avg(temp_min),2) as `value2` FROM `weather` where date_format(rec_time,'%%Y-%%m')=%s;"
for t in times:
res = sqlManager.get_one(sql, t)
if not res or not res['value1']:
res['value1'] = 0
if not res or not res['value2']:
res['value2'] = 0
data_max.append(float(res['value1']))
data_min.append(float(res['value2']))
return {'time': times, 'max': data_max, 'min': data_min}
七、数据库设计
数据库:agricultural_analysis
表名:notice
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(11) | 是 | |
| title | varchar(255) | 否 | 公告标题 |
| content | longtext | 否 | 公告内容 |
| user_name | varchar(50) | 否 | 发布人 |
| create_time | datetime | 否 | 发布时间 |
表名:output
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(11) | 是 | 产量 |
| county | varchar(20) | 否 | 县区 |
| early2015 | double(12,8) | 否 | 2015早稻 |
| early2016 | double(12,8) | 否 | 2016早稻 |
| early2017 | double(12,8) | 否 | 2017早稻 |
| late2015 | double(12,8) | 否 | 2015晚稻 |
| late2016 | double(12,8) | 否 | 2016晚稻 |
| late2017 | double(12,8) | 否 | 2017晚稻 |
表名:user
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(11) | 是 | |
| name | varchar(255) | 否 | 用户名称(供应商名称) |
| account | varchar(255) | 否 | 用户账号 |
| password | varchar(255) | 否 | 用户密码 |
| company | varchar(255) | 否 | 企业名称 |
| varchar(255) | 否 | 邮箱 | |
| type | int(11) | 否 | 0管理员,1普通用户 |
| status | int(11) | 否 | 0禁用1启用 |
表名:weather
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(11) | 是 | |
| county | varchar(20) | 否 | 区县 |
| rec_time | date | 否 | 记录日期 |
| sun_time | double(10,2) | 否 | 日照时数(单位:h) |
| wind | double(10,2) | 否 | 日平均风速(单位:m/s) |
| rain | double(10,2) | 否 | 日降水量(mm) |
| temp_max | double(10,2) | 否 | 日最高温度(单位:℃) |
| temp_min | double(10,2) | 否 | 日最低温度(单位:℃) |
| temp_ave | double(10,2) | 否 | 日平均温度(单位:℃) |
| humidity | double(10,2) | 否 | 日相对湿度(单位:%) |
| hpa | double(10,2) | 否 | 日平均气压(单位:hPa) |
八、源码获取
源码、安装教程文档、项目简介文档以及其它相关文档已经上传到是云猿实战官网,可以通过下面官网进行获取项目!

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)