
getvalue函数怎么使用_机器学习实战之决策树使用sklearn01
前面我们已经从头到尾敲了一遍决策树的代码,不得不说实在是繁琐得很。今天就来介绍简洁方便的方法,使用sklearn来构造决策树。决 策 树1、sklearn.tree简介 使用sklearn库中的sklearn.tree模块就可以构造决策树了。其具体的函数如下:使用其中的 DecisionTreeClassifier 函数就可以创建决策树的实例对象了。当然,使用sklearn建模的...
 使用sklearn库中的sklearn.tree模块就可以构造决策树了。其具体的函数如下:
使用sklearn库中的sklearn.tree模块就可以构造决策树了。其具体的函数如下:


-
criterion:用于设置属性的选取准则,设为“gini”则表示用CART算法,设为“entropy”则表示用最优特征选择法,默认为gini。
-
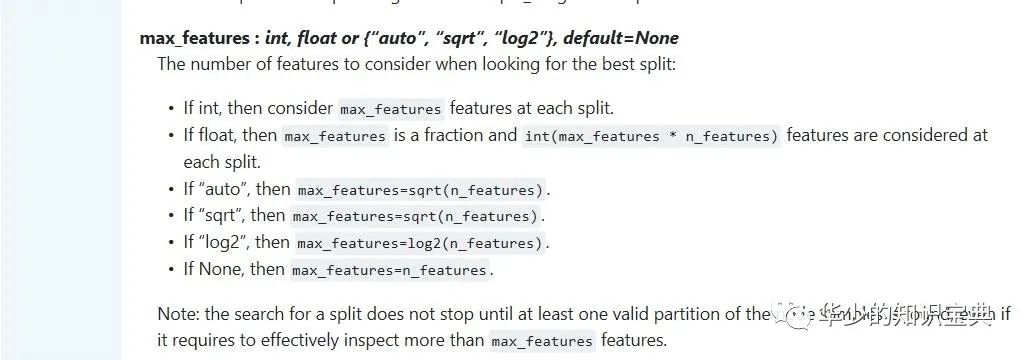
max_features:表示在结点分裂的过程中,从多少个属性中选取最好的属性,特征小于50的时候一般使用所有的,设为默认值即从所有的属性中进行选取。
-
max_depth:设置决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。

2.1 准备数据这里我们使用书上隐形眼镜的数据,使用决策树来预测隐形眼镜的类型。数据如下:

# 导入所有需要的模块from sklearn.preprocessing import LabelEncoder, OneHotEncoderfrom sklearn.externals.six import StringIOfrom sklearn import treeimport pandas as pdimport numpy as npimport pydotplus# 这里偷个懒,就不定义函数了,直接都写到一起,因为程序也比较简单if __name__ == '__main__': #打开文件 with open('lenses.txt') as f: #读取所有的行,然后分别去除两端空格和以制表符分割 lenses = [inst.strip().split('\t') for inst in f.readlines()] lenses_target = [] # 用于存储 分类 for each in lenses: # 获得 每一行的分类 lenses_target.append(each[-1]) #构建特征标签 lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate']2.2 出现的问题
导入数据后,直接对数据进行使用,构造决策树。#引入决策树训练方法,其中最大深度为4 clf = tree.DecisionTreeClassifier(max_depth=4) #进行数据拟合 clf.fit(lenses,lenses_target)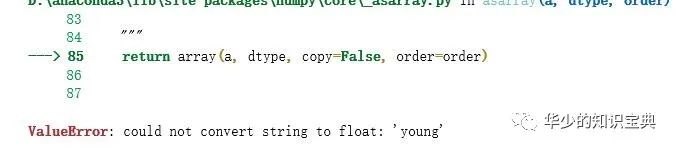
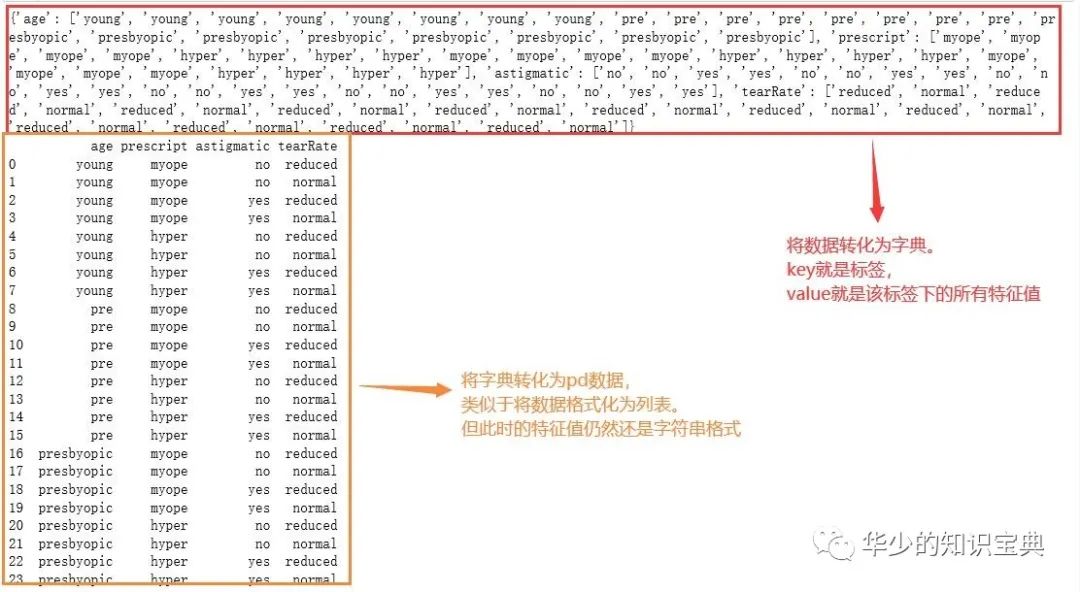
LabelEncoder函数是 将字符串转换为增量值,适用于字符以及混合类型的编码 # 将读取到的数据按标签分成字典的形式 #初始化特征列表和特征字典 lenses_list = [] lenses_dict = {} #遍历lenses列表,再遍历lensesLabels for each_label in lensesLabels: for each in lenses: #这段代码就是指 每一个each_label对应的元素都从lenses提取出来 lenses_list.append(each[lensesLabels.index(each_label)]) #然后处理完第一个eachlabel后把循环来的所有对应的元素组成的列表一起组成字典 lenses_dict[each_label] = lenses_list #清除lenses_list,使得lenses_list重新为空,重新接收 lenses_list = [] print(lenses_dict) #转化成pandas中的DataFrame格式 lenses_pd = pd.DataFrame(lenses_dict) print(lenses_pd) #sklearn中的LabelEncoder,可以将字符串转化为增量数字 le = LabelEncoder() #以列标签进行序列化---整理数据 for col in lenses_pd.columns: #方法fit_transform可以将fit和transform结合在一起处理 lenses_pd[col] = le.fit_transform(lenses_pd[col]) print(lenses_pd)结果:
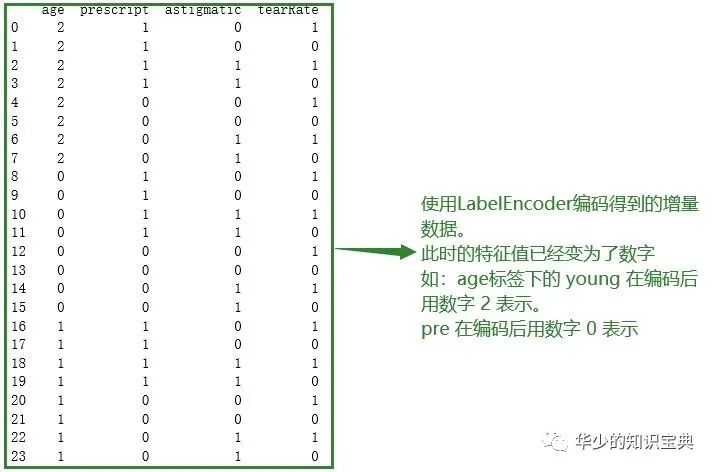
这里对于 fit_transform 函数 和 fit,transform 函数的区别,想要了解的可以到下面的这个链接里看,这里就不赘述了,太多了。https://blog.csdn.net/anshuai_aw1/article/details/82498374?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare #创建决策树对象,引入决策树训练方法,其中最大深度为4 clf = tree.DecisionTreeClassifier(max_depth=4) #进行数据拟合 clf.fit(lenses_pd.values.tolist(),lenses_target) # 注意,这里要将得到的 #输出决策树图像 #创建绘图对象 dot_data = StringIO() #输出图像数据 tree.export_graphviz(clf, out_file = dot_data, feature_names = lenses_pd.keys(), # 特征 标签 class_names = clf.classes_, # 分类的类别标签 filled = True, # 填充 rounded = True, # 画的图形边缘是否美化 special_characters = True ) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_pdf('树结构.pdf')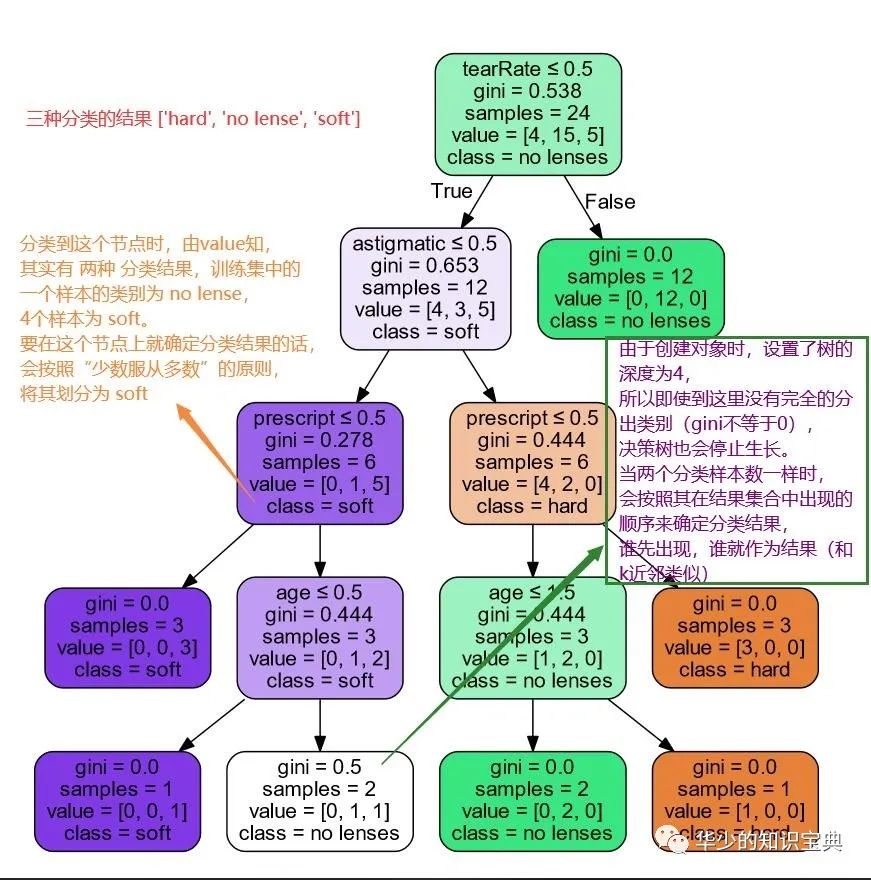
-
方框左下方剪头指向的方框代表根部方框条件成立时的情况,右下方指向的方框代表根部方框条件不成立时的情况
-
每个判断节点的第一行:是进行分类的判断条件
-
gini:表示数据集在决策树的这个地方计算得到的基尼系数。可以看到,随着分类,gini值不断地变小,在叶子节点上达到最小值。当使用信息增益划分数据集时,这里就会变成信息熵(entropy)的大小。
-
samples:训练集中符合当前分类的样本数
-
value:训练集中在当前节点的分类情况,其里面的三个值对应三种分类的结果 ['hard', 'no lense', 'soft']
#测试---使用决策树对a进行预测 a = np.array([0,1,1,0]) result = clf.predict(a.reshape(1,-1)) print(result)Graphviz 是 AT&T Labs Research 开发的图形绘制工具, 其可以很方便的用来绘制结构化的图形网络,支持多种格式输出,且生成图片的质量和速度都不错。它的输入是一个用dot语言编写的绘图脚本,它通过对输入脚本的解析, 分析出其中的点、边以及子图,然后根据属性进行绘制。
Sklearn生成的决策树就是 dot 格式的,因此我们可以直接利用Graphviz将决策树可视化。
3.1 安装pydotplus
要使用其画图,首先要安装好pydotplus。可以从国内的镜像网站下载,速度比较快。我使用的是豆瓣。pip install pydotplus -i http://pypi.douban.com/simple --trusted-host=pypi.douban.com3.2 安装Graphviz
Graphviz的下载地址:https://graphviz.gitlab.io/_pages/Download/Download_windows.html我下载的是zip文件,下载后直接解压即可。然后将其安装路径下的bin文件夹添加到环境变量的Path里,例如:
3.3 添加代码
完成了以上两步后,按理说应该没什么问题,但我在运行时还是出现 “Graphviz Model not found” 这类的问题,后来找到了解决方法,就是在程序的最开始添加两行代码,好像作用也是修改环境变量。具体的我也不太清楚,反正可以用了。# 要使用 pydotplus 画 出决策树,则要在 代码开始运行时 先运行如下代码---即:添加环境变量import osos.environ['PATH'] += os.pathsep + 'D:\Python\graphviz-2.38\release\bin'
一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)