
机器学习(一) MNIST数据集的数字识别
机器学习(一) MNIST数据集的数字识别一、基础概念1.监督学习(supervised learning)与无监督学习(unsupervised learning)监督学习需要标签数据,无监督学习不需要标签数据2.机器学习与深度学习(deep learning)监督与无监督学习,着眼点在于数据本身。机器学习与深度学习着眼点在解决问题的方法。把层数较多,结构较为复杂的神经网络的机器学习技术叫做深度
机器学习(一) MNIST数据集的数字识别
一、基础概念
1.监督学习(supervised learning)与无监督学习(unsupervised learning)
监督学习需要标签数据,无监督学习不需要标签数据
2.机器学习与深度学习(deep learning)
监督与无监督学习,着眼点在于数据本身。机器学习与深度学习着眼点在解决问题的方法。把层数较多,结构较为复杂的神经网络的机器学习技术叫做深度学习,如卷积神经网络(CNN),循环神经网络(RNN)
3.强化学习(reinforcement learning)
强化学习是智能体如何基于环境做出行动反应,以取得最大化的累积奖励。监督学习是从数据中学习,而强化学习是从环境给它的奖励中学习。监督学习中数据标签就是答案,有明确的对错。而强化学习得到惩罚后(比如下棋输了),没人告诉它具体哪里做错了,所以它不一定每次都明确选择最优,而是要在探索(未知)和利用(已知)之间寻找平衡
4.机器学习应用场景
机器学习两大应用场景:分类(classification)与回归(regression)。
回归问题通常来预测一个值,其标签的值是连续的,例如预测房价,天气等任何连续性的走势,数值。
分类问题是将事物标记为一个类别的标签,结果为离散值,也就是类别中的一个选项,例如判断一幅图片上的动物是猫还是狗。
5.数据的预处理
- 可视化
- 向量化 将原始数据变得机器可读,例如将原始图片转化为数字矩阵,将文字转换为one-hot编码
- 处理坏数据和缺失值
- 特征缩放 包括数据标准化和规范化。标准化是对数据特征分布的转换,目标是使其符合正态分布,标准化的一种变体是归一化,即将数据压缩到给定的最大值与最小值之间,通常是0~1。规范化是将样本缩放为具有单位范数的过程
6. k折验证(K-fold validation)
可以用于样本数量过少,重用同一个数据集进行多次验证的方法。将数据划分为大小相同的k个分区,对于每个分区,都在剩余的k-1个分区上训练模型,然后在留下的分区上评估模型。最后分数为k个分数的平均值。
二、MNIST数据集的数字识别
import numpy as np
import pandas as pd
from keras.datasets import mnist #从keras导入MNIST数据集
(X_train_image,y_train_lable),(X_test_image,y_test_lable)=mnist.load_data()
#X_train_image-训练集特征-图片
#y_train_lable-训练集标签-图片对应的数字
print("数据集张量形状:",X_train_image.shape)
print("第一个数据样本:",X_train_image[0])
数据集张量形状: (60000, 28, 28)
第一个数据样本: [[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136
175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253
225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251
93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119
25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253
150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252
253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249
253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253
253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253
250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201
78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]
from keras.utils import to_categorical #导入keras.utils工具库的类型转换工具
X_train = X_train_image.reshape(60000,28,28,1) #给标签增加一个维度
X_test = X_test_image.reshape(10000,28,28,1)
y_train = to_categorical(y_train_lable,10) #特征转换为one-hot编码
y_test = to_categorical(y_test_lable,10)
print("训练集张量形状:",X_train.shape)
print("第一个数据标签:",y_train[0])
训练集张量形状: (60000, 28, 28, 1)
第一个数据标签: [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
from keras import models
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D
model = models.Sequential() #用序贯方式建立模型
model.add(Conv2D(32,(3,3),activation='relu', #添加Con2D层
input_shape=(28,28,1))) #指定输入数据样本张量的类型
model.add(MaxPooling2D(pool_size=(2,2))) #添加MaxPooling2D层
model.add(Conv2D(64,(3,3),activation='relu')) #添加Conv2D层
model.add(MaxPooling2D(pool_size=(2,2))) #添加MaxPooling2D层
model.add(Dropout(0.25)) #添加Dropout层
model.add(Flatten()) #展平
model.add(Dense(128,activation='relu')) #添加全连接层
model.add(Dropout(0.5)) #添加Dropout层
model.add(Dense(10,activation='softmax')) #softmax分类激活,输出10维分类码
#编译模型
model.compile(optimizer='rmsprop', #指定优化器
loss='categorical_crossentropy', #指定损失函数
metrics=['accuracy']) #指定验证过程中的评估指标
#开始训练
model.fit(X_train,y_train, #指定训练特征集和训练标签集
validation_split=0.3, #部分训练集数据拆分为验证集
epochs=5, #训练轮次为5轮
batch_size=128) #以128为批量进行训练
Epoch 1/5
329/329 [==============================] - 18s 53ms/step - loss: 3.7156 - accuracy: 0.6613 - val_loss: 0.0970 - val_accuracy: 0.9710
Epoch 2/5
329/329 [==============================] - 18s 55ms/step - loss: 0.2050 - accuracy: 0.9441 - val_loss: 0.0712 - val_accuracy: 0.9794
Epoch 3/5
329/329 [==============================] - 17s 51ms/step - loss: 0.1327 - accuracy: 0.9637 - val_loss: 0.0705 - val_accuracy: 0.9830
Epoch 4/5
329/329 [==============================] - 17s 52ms/step - loss: 0.1030 - accuracy: 0.9724 - val_loss: 0.0536 - val_accuracy: 0.9857
Epoch 5/5
329/329 [==============================] - 17s 53ms/step - loss: 0.0909 - accuracy: 0.9736 - val_loss: 0.0555 - val_accuracy: 0.9864
<tensorflow.python.keras.callbacks.History at 0x1b30edab438>
#模型效率的验证
score = model.evaluate(X_test,y_test) #在验证集上进行模型评估
print("测试集预测准确率",score[1]) #输出测试集上的预测准确率
313/313 [==============================] - 1s 3ms/step - loss: 0.0470 - accuracy: 0.9881
0.988099992275238
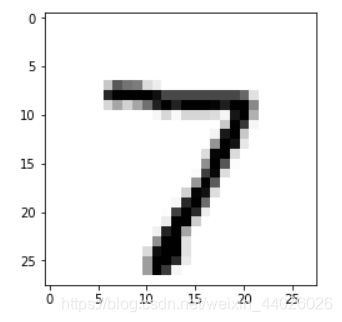
pred = model.predict(X_test[0].reshape(1,28,28,1)) #预测测试集第一个数据
print(pred[0],"转换以下格式得到:",pred.argmax())#one-hot编码转换为数字
import matplotlib.pyplot as plt
plt.imshow(X_test[0].reshape(28,28),cmap='Greys') #输出这个图片
[1.9084304e-17 2.7740785e-12 2.4868221e-10 3.5792529e-15 4.9112302e-18
8.3889978e-18 3.1887730e-25 1.0000000e+00 9.6427991e-17 1.7750986e-12] 转换以下格式得到: 7
<matplotlib.image.AxesImage at 0x1b311915080>

一站式 AI 云服务平台
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)