
【Python原创毕设|课设】基于Flask(机器学习)的水文数据采集预测与可视化分析系统-文末附下载方式以及往届优秀论文,原创项目其他均为抄袭
本项目旨在构建一套水文数据管理与预测系统,针对水文学领域的研究和实际应用需求。基于Python编程语言及相关技术,包括Flask框架、PyMySQL数据库连接工具、Echarts数据可视化库以及机器学习模块,我们成功打造了这一系统。通过Python及Flask框架搭建强大的Web服务器端应用程序,实现了水文数据的存储、管理、可视化和预测。系统提供了丰富的功能,包括数据获取、数据管理、数据可视化和数
一、项目简介
本项目旨在构建一套水文数据管理与预测系统,针对水文学领域的研究和实际应用需求。基于Python编程语言及相关技术,包括Flask框架、PyMySQL数据库连接工具、Echarts数据可视化库以及机器学习模块,我们成功打造了这一系统。通过Python及Flask框架搭建强大的Web服务器端应用程序,实现了水文数据的存储、管理、可视化和预测。
系统提供了丰富的功能,包括数据获取、数据管理、数据可视化和数据预测。使用Flask和PyMySQL,我们能够轻松连接和管理水文数据,确保数据的安全性和完整性。同时,通过Echarts库实现了水文数据的多维度可视化展示,帮助用户直观地了解水文数据的变化趋势。采用机器学习模型,如决策回归树模型,我们实现了对水文数据的预测功能,为未来的水文状况提供预测和参考依据。
然而,虽然系统已经具备了多项强大功能,仍存在改进空间。目前,我们仅选择了长江水文网作为主要数据源,未能覆盖更多的水文数据来源。系统的数据可视化功能还有提升的余地,尤其在数据分析和交互性方面。另外,水文数据预测功能尚可进一步改进,引入更先进的机器学习技术,提高预测的准确性和鲁棒性。
总体而言,本项目是一个涉及多项关键技术的水文数据处理与分析系统,虽然在功能和技术上已取得成就,但我们看到了进一步优化和扩展的潜力。未来,我们将不断完善数据源、提升数据可视化功能,并探索更先进的数据预测方法,以满足用户对水文数据处理与预测的更高需求,为水文学领域的研究和实践提供更为精确和有效的支持。
二、开发环境
| 开发环境 | 版本/工具 |
|---|---|
| PYTHON | 3.6.8 |
| 开发工具 | PyCharm |
| 操作系统 | Windows 10 |
| 内存要求 | 8GB 以上 |
| 浏览器 | Firefox (推荐)、Google Chrome (推荐)、Edge |
| 数据库 | MySQL 8.0 (推荐) |
| 数据库工具 | Navicat Premium 15 (推荐) |
| 项目框架 | FLASK |
三、项目技术
后端:Flask、PyMySQL、MySQL、urllib
前端:Jinja2、Jquery、Ajax、layui
四、功能结构
系统功能设计是指根据系统需求分析,对系统进行具体功能的设计和实现。在本系统中,主要包括数据分析功能、用户模块、公告模块、水文数据管理、水文数据采集五个部分。其功能结构图下图所示。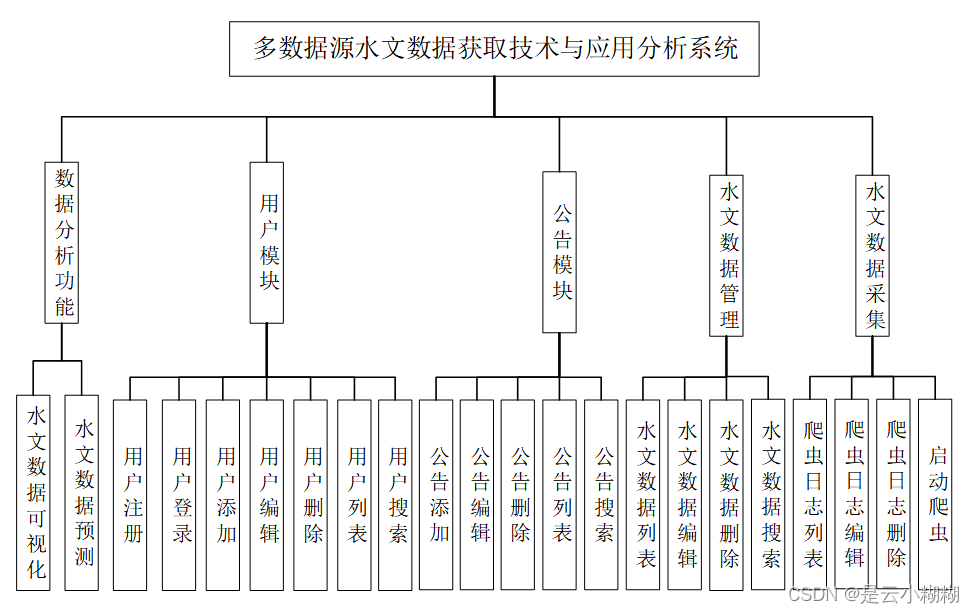
数据分析功能是系统的核心功能之一,包括水文数据可视化和水文数据预测两部分。水文数据可视化是指将大量的水文数据进行可视化展示,以便用户可以更直观、更方便地了解数据。水文数据预测则是通过分析历史水文数据,预测未来一段时间内的水文变化趋势,为决策提供参考依据。
用户模块包括用户登录、注册、列表、修改、添加、删除和搜索七个功能,为用户提供了一个完整的个人信息管理平台。用户登录和注册是用户使用系统的入口,用户列表则展示了系统中所有用户的信息。用户可以修改自己的个人信息,也可以添加和删除自己的数据。此外,还提供了搜索功能,用户可以快速查找需要的信息。
公告模块包括公告列表、添加、删除、修改、搜索五个功能。管理员可以在公告列表中添加公告,也可以对已有的公告进行修改和删除。用户可以通过搜索功能查找自己所需要的公告信息。
水文数据管理模块包括数据列表、修改、删除、搜索四个功能。管理员可以对系统中所有的水文数据进行管理,可以对数据进行修改和删除,也可以通过搜索功能查找需要的数据。
水文数据采集包括爬虫日志列表、爬虫日志编辑、爬虫日志删除以及启动爬虫等功能。该模块是整个系统的数据采集和处理核心,管理员可以通过爬虫日志列表查看系统的爬虫状态和日志信息,也可以编辑和删除日志信息,以及启动爬虫任务。
五、运行截图
后台登录:
后台注册:
后台管理首页:
用户管理: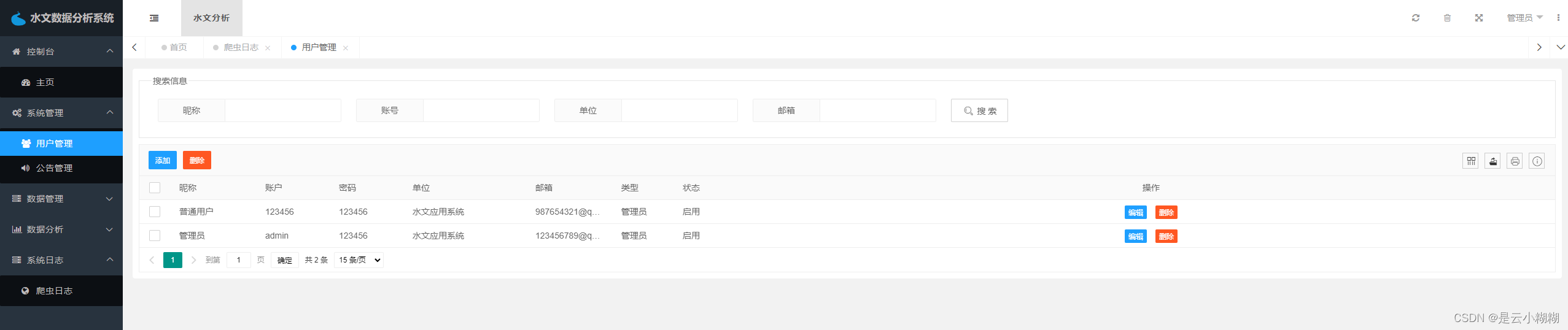
公告管理:
水文数据管理: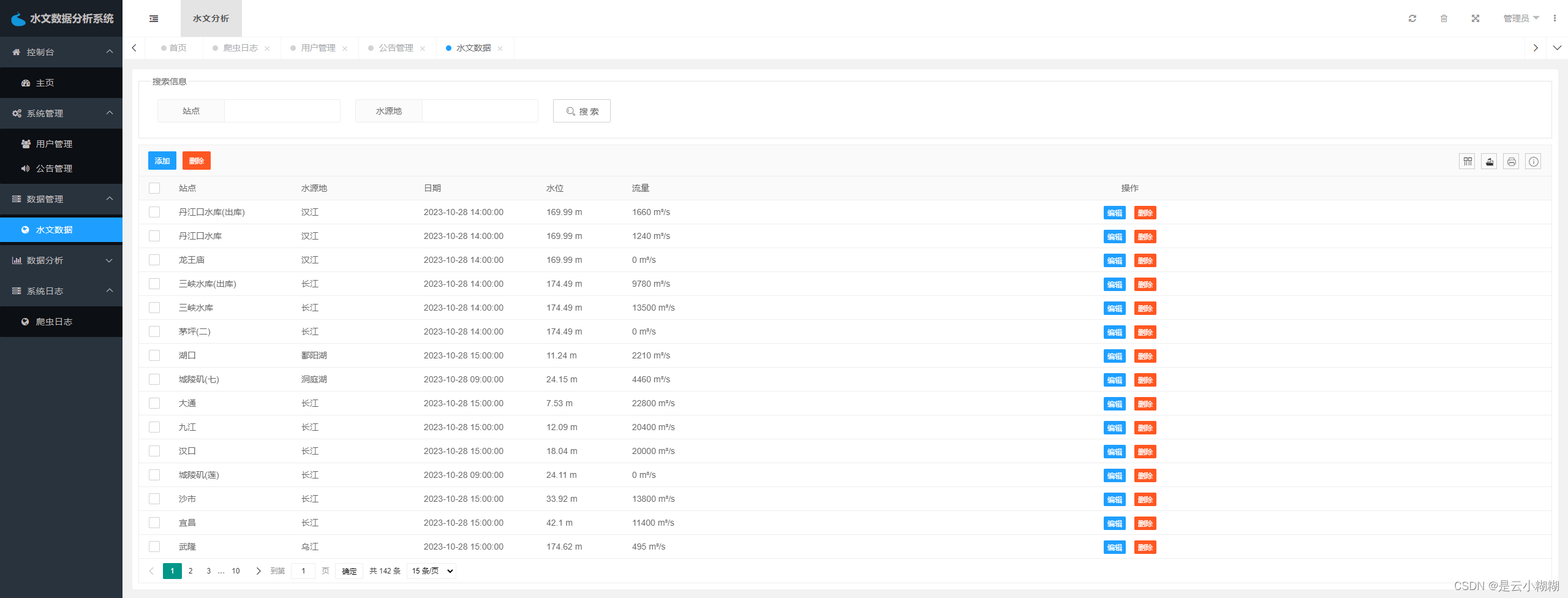
实时水文数据分析: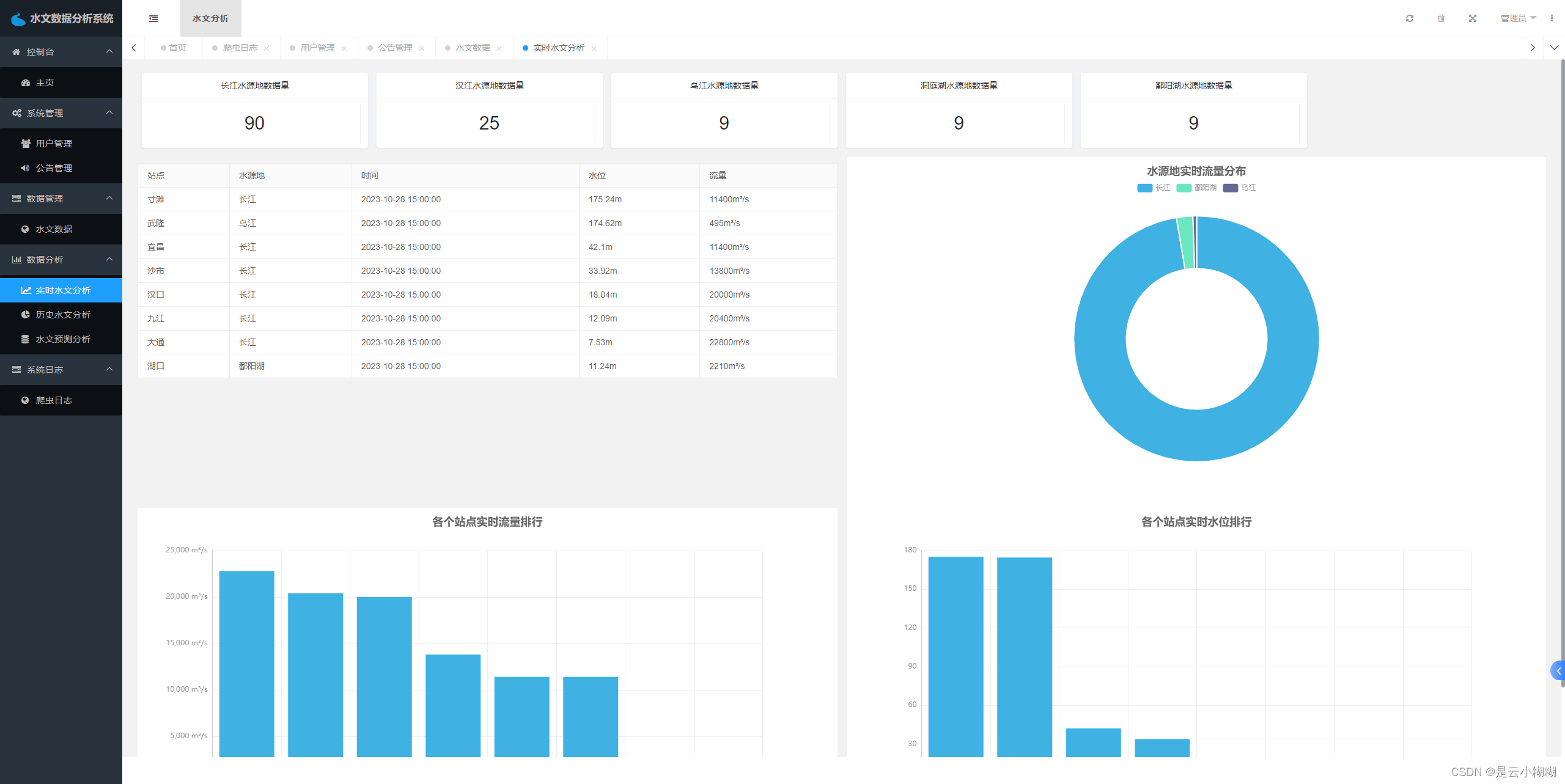
历史水文数据分析: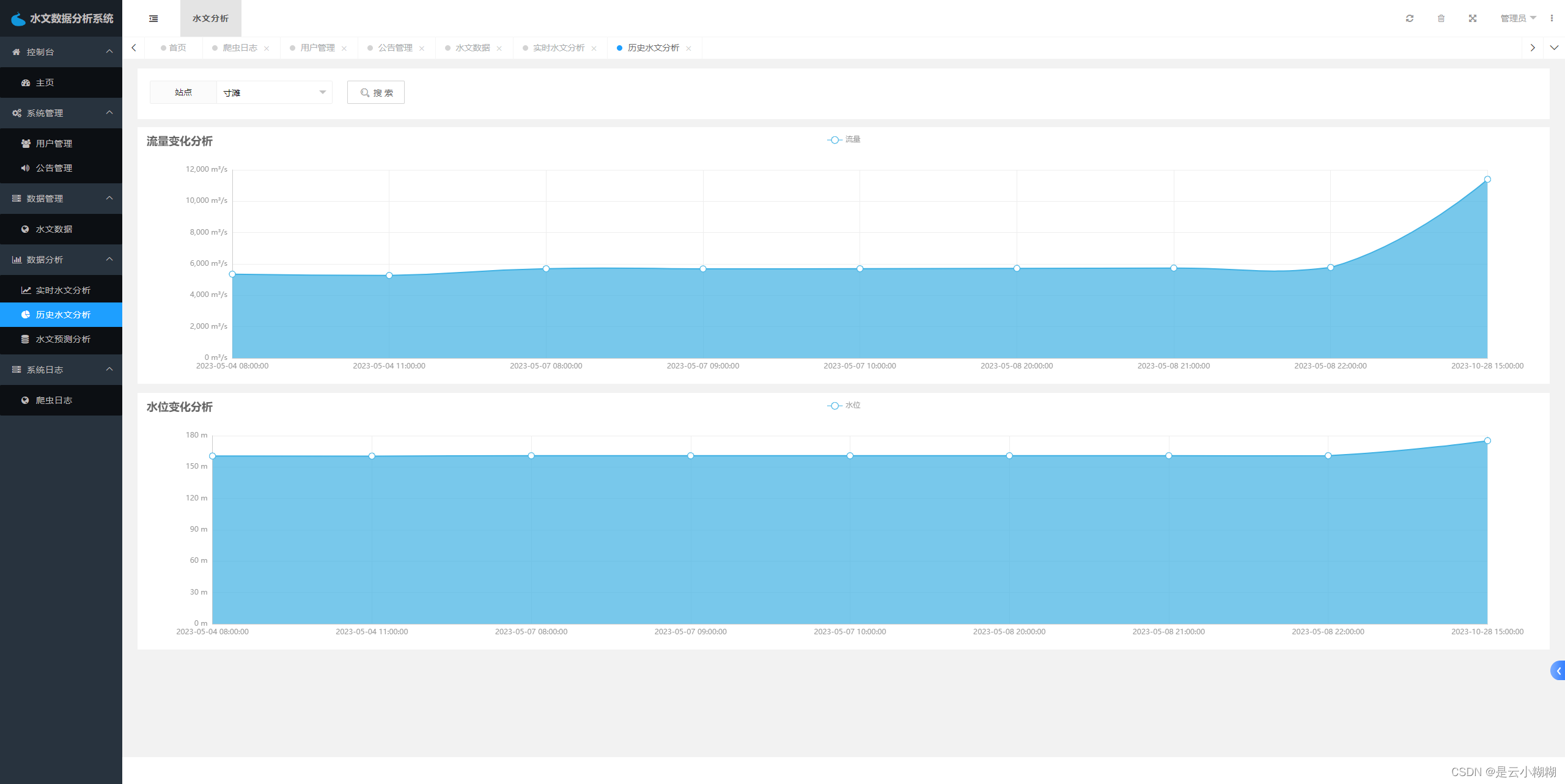
水文数据预测: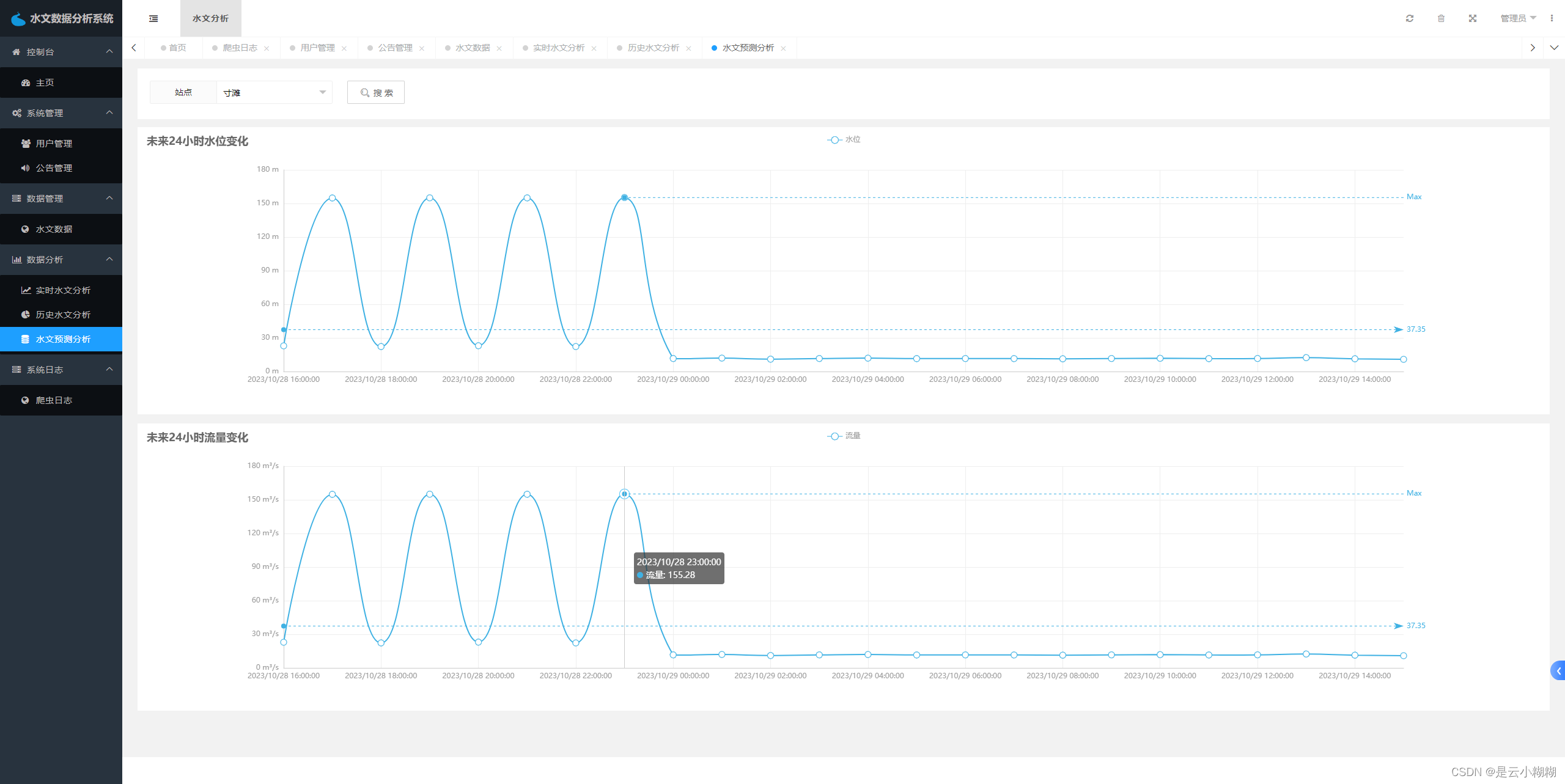
系统爬虫日志管理: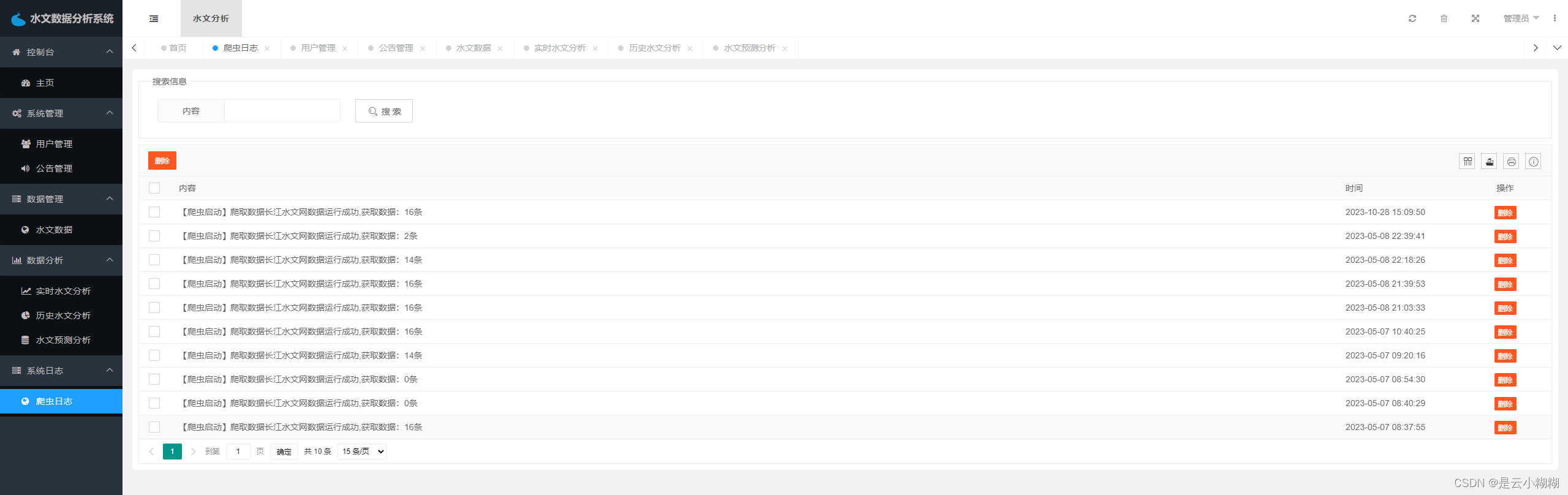
六、功能实现
水文数据爬虫构建
def flood_spider_main():
sqlManager = SQLManager()
count = 0
url = '长江水文网'
response = requests.get(url)
response.encoding = 'utf-8'
web_data = response.text
web_data = web_data[web_data.find('var sssq = ') + 11:]
web_data = web_data[: web_data.find(';')]
data = json.loads(web_data)
sql_template = "INSERT INTO `waterLevel` (`site`, `waterSource`, `datetime`, `waterLevel`, `flow`) \
VALUES ('%s', '%s', '%s', '%s', '%s')"
for record in data:
waterLevel = record['z'] if 'z' in record else 0 # 水位
in_flow = record['q'] if 'q' in record else 0 # 流入量
out_flow = record['oq'] if 'oq' in record else 0 # 留出量
site = record['stnm'] # 站点名
waterSource = record['rvnm'] # 水源地
datetime = time.localtime(int(record['tm']) // 1000) # 时间戳
datetime = format("%d-%02d-%02d %02d:%02d:%02d" %
(datetime.tm_year, datetime.tm_mon, datetime.tm_mday,
datetime.tm_hour, datetime.tm_min, datetime.tm_sec))
try:
if int(in_flow) > 0:
sql = format("SELECT MAX(`datetime`) as i FROM `waterLevel` WHERE site = '%s'" % site)
latest_date = sqlManager.get_one(sql)['i']
if latest_date is None or str(latest_date) < datetime:
sql = format(sql_template % (site, waterSource, datetime, waterLevel, in_flow))
sqlManager.moddify(sql)
count += 1
print("[INFO]插入 %s at %s" % (site, datetime))
if int(out_flow) > 0:
try:
sql = format("SELECT MAX(`datetime`) as i FROM `waterLevel` WHERE site = '%s'" % (site + '(出库)'))
latest_date = sqlManager.get_one(sql)['i']
except:
print('[ERROR] in select latest date')
if latest_date is None or str(latest_date) < datetime:
sql = format(sql_template % (site + '(出库)', waterSource, datetime, waterLevel, out_flow))
sqlManager.moddify(sql)
count += 1
print("[INFO]插入 %s at %s" % (site + '(出库)', datetime))
except:
sqlManager.rollback()
print('[ERROR] in insert date: ', record)
t = dt.now().strftime("%Y-%m-%d %H:%M:%S")
sql = "insert into slog VALUES (NULL, \"【爬虫启动】爬取数据长江水文网数据运行成功,获取数据:" + str(count) + "条\",\"" + t + "\")"
sqlManager.moddify(sql)
sqlManager.close()
水文数据模型训练核心代码构建
"""
多元线性回归
"""
# 读取数据
print("[INFO] 多元线性回归预测水文数据数据-训练开始")
data = deal_data.transformer_data()
# 分割数据集合
train_data = []
test_data = []
for index, item in enumerate(data):
if index % 5 == 0: # 每5条数据,第6条保留为测试集合,也就是训练集:测试集=5:1
test_data.append(item)
else:
train_data.append(item)
train_data = np.array(train_data)
test_data = np.array(test_data)
X = np.array(train_data[:, 0:4]).astype(float)
Y = np.array(train_data[:, 4:]).astype(float)
test_X = np.array(test_data[:, 0:4]).astype(float)
text_Y = np.array(test_data[:, 4:]).astype(float)
# 定义算法模型
model = DecisionTreeRegressor(max_depth=20, min_samples_leaf=1, random_state=None) # 决策回归树
# 喂入模型数据
model.fit(X, Y)
L_X = model.predict(X)
Lmodel = LinearRegression()
Lmodel.fit(L_X, Y)
joblib.dump(model, "./model.joblib")
joblib.dump(Lmodel, "./lmodel.joblib")
# 测试集上模型评分
print("[INFO] 模型EMS损失值(模型评分越低越好):", abs(model.score(test_X, text_Y)))
print("[INFO] 多元线性回归预测水文数据-训练完成")
水文数据可视化核心代码
# 流量分析
def flow_data(site):
sqlManager = SQLManager()
key_sql = "SELECT datetime,flow FROM `waterlevel` WHERE site='" + site + "' ORDER BY datetime desc limit 30"
key_data = sqlManager.get_list(key_sql)
x_data = [k['datetime'] for k in key_data]
value_data = [k['flow'] for k in key_data]
sqlManager.close()
return {'x': x_data[::-1], 'y': value_data[::-1]}
# 水位分析
def level_data(site):
sqlManager = SQLManager()
key_sql = "SELECT datetime,waterlevel FROM `waterlevel` WHERE site='" + site + "' ORDER BY datetime desc limit 30"
key_data = sqlManager.get_list(key_sql)
x_data = [k['datetime'] for k in key_data]
value_data = [k['waterlevel'] for k in key_data]
sqlManager.close()
return {'x': x_data[::-1], 'y': value_data[::-1]}
# 实时水文数据分析数据
def top_page_data():
sqlManager = SQLManager()
key_sql = "select waterSource,count(id) as n from waterlevel group by waterSource order by count(id) desc"
key_data = sqlManager.get_list(key_sql)
num_data = [{k['waterSource']: k['n']} for k in key_data]
table_sql = "SELECT * FROM waterlevel WHERE datetime= (SELECT MAX(datetime) FROM waterlevel)"
table_data = sqlManager.get_list(table_sql)
flow_top_sql = "SELECT site,flow FROM waterlevel WHERE datetime= (SELECT MAX(datetime) FROM waterlevel) ORDER BY flow DESC;"
flow_list = sqlManager.get_list(flow_top_sql)
flow_data = [{'site': i['site'], '流量': i['flow'], } for i in flow_list]
level_top_sql = "SELECT site,waterlevel FROM waterlevel WHERE datetime= (SELECT MAX(datetime) FROM waterlevel) ORDER BY waterlevel DESC;"
level_list = sqlManager.get_list(level_top_sql)
level_data = [{'site': i['site'], '水位': float(i['waterlevel']), } for i in level_list]
source_top_sql = "SELECT waterSource,sum(flow) as n FROM waterlevel WHERE datetime= (SELECT MAX(datetime) FROM waterlevel) GROUP BY waterSource ORDER BY sum(flow) DESC;"
source_list = sqlManager.get_list(source_top_sql)
source_data = [{'name': i['waterSource'], 'value': i['n'], } for i in source_list]
sqlManager.close()
return {'num_data': num_data, 'table_data': table_data, 'source_data': source_data, 'level_data': level_data,
'flow_data': flow_data}
七、数据库设计
表名:notice
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(11) | 是 | |
| title | varchar(255) | 否 | 公告标题 |
| content | longtext | 否 | 公告内容 |
| user_name | varchar(50) | 否 | 发布人 |
| create_time | datetime | 否 | 发布时间 |
表名:slog
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(11) | 是 | |
| log | varchar(255) | 否 | |
| create_time | datetime | 否 |
表名:user
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(11) | 是 | |
| name | varchar(255) | 否 | 用户名称(供应商名称) |
| account | varchar(255) | 否 | 用户账号 |
| password | varchar(255) | 否 | 用户密码 |
| company | varchar(255) | 否 | 企业名称 |
| varchar(255) | 否 | 邮箱 | |
| type | int(11) | 否 | 0管理员,1普通用户 |
| status | int(11) | 否 | 0禁用1启用 |
表名:waterlevel
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int(10) unsigned | 是 | |
| site | varchar(31) | 是 | |
| waterSource | varchar(31) | 否 | |
| datetime | datetime | 否 | |
| waterlevel | decimal(11,2) | 否 | 单位:米 |
| flow | int(11) | 否 | 单位:立方米每秒 |
八、源码获取
源码、安装教程文档、项目简介文档以及其它相关文档已经上传到是云猿实战官网,可以通过下面官网进行获取项目!

一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)