
深度学习 | Attention与Transformer
Attention,又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
深度学习 | Attention技术
Attention is all you need
文章目录
一、Seq2Seq
Seq2Seq(sequence to sequence)模型是NLP中的一个经典模型,最初由Google开发,并用于机器翻译,主要指的是从序列A到序列B的一种转换。
主要是一个由编码器(encoder)和一个解码器(decoder)组成的网络。
编码器将输入项转换为包含其特征的相应隐藏向量。解码器反转该过程,将向量转换为输出项,解码器每次都会使用前一个输出作为其输入。
- Encoder将可变长度的输入序列编码成一个固定长度的向量;
- Decoder将固定长度的向量解码成一个可变长度的输出序列;
- Encoder-Decoder阶段的编码与解码的方式可以是CNN、RNN、LSTM、GRU等;
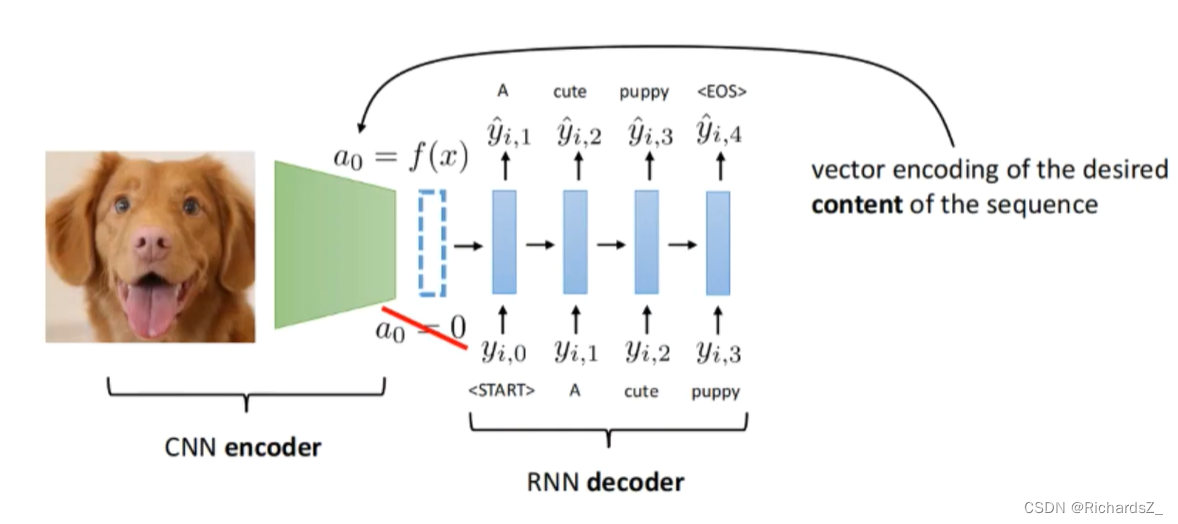
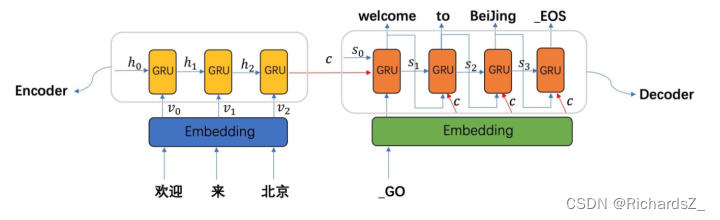
因此Seq2Seq解决的问题是由一个序列预测出另一个序列,而Encoder-Decoder是其具体的实现手段,二者实际一致。
Seq2Seq更强调目的,Encoder-Decoder更强调方法!
二、Attention
2.1 传统RNN/LSTM的限制
在Attention机制面世之前,Seq2Seq的Encoder-Decoder手段常用RNN或LSTM作为基学习器。
- Seq2Seq(RNN base)的限制:
- RNN或LSTM是一个时序模型,下一时刻的输入非常依赖上一时刻的输出,一旦序列过长,随着时序链条的增加,由于Encoder所有信息汇集的隐含层容量有限,即便是引入了遗忘更新机制的LSTM,还是会出现一定程度的长期信息损失的问题!
- 由于Decoder的架构,下一时刻的输入依赖上一时刻的输出,若解码过程中的第一个词出现偏差,则导致往后时刻的词也跟着出现偏差,即一步错步步错!
- 为了适当解决以上问题,对于encoder和decoder的结构适当在空间层面增加了隐层,但根本上还是无法避免长序列隐层的损失。
基于RNN/LSTM Base的Seq2Seq存在诸多限制,不依赖时序的,基于Attention的注意力机制应运而生!
2.2 什么是Attention

Attention,又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
2.3 机制原理
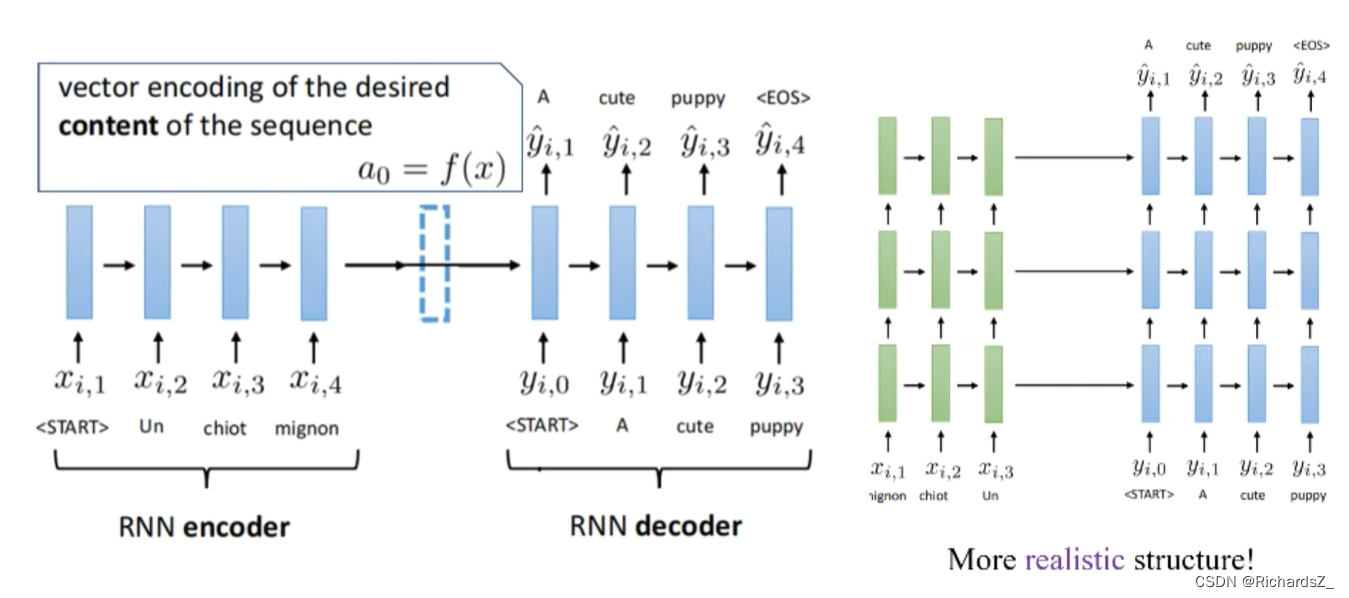
左图为典型的Seq2Seq(RNN base)的结构,右图则为Seq2Seq+Attention的结构。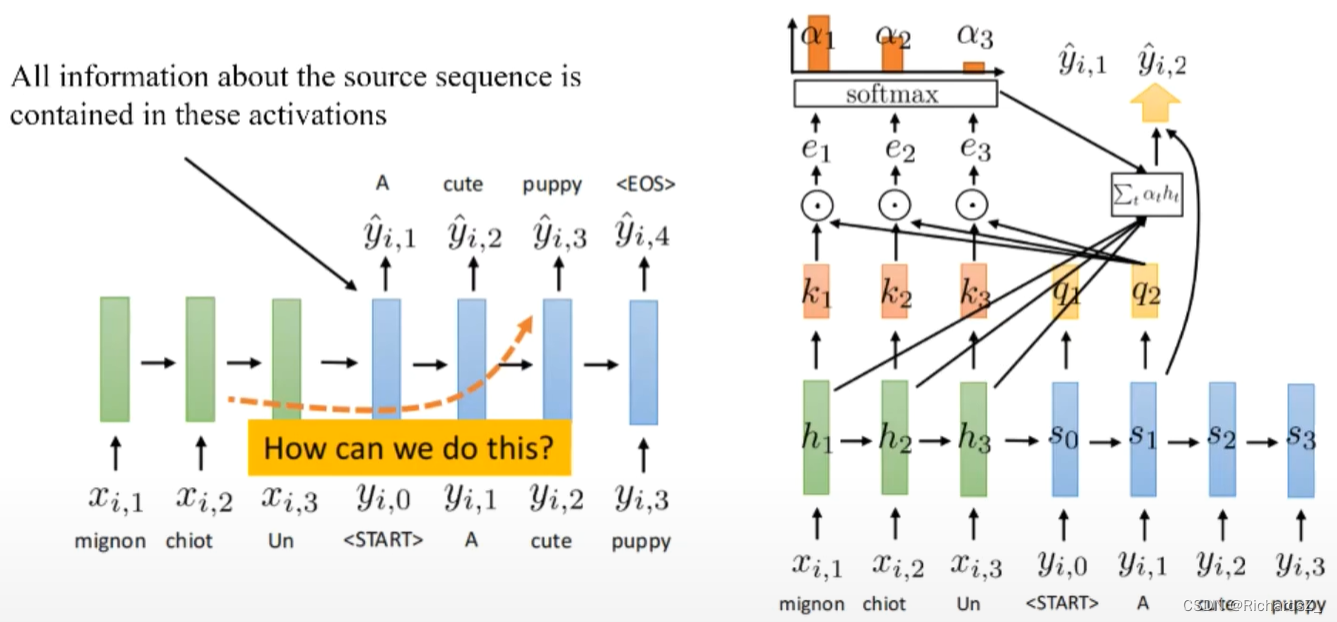
Seq2Seq训练的最终目标是:帮助decoder在生成词语时,有一个不同词语的权重参考。
在训练时,对于decoder而言是有训练目标的!
此时将decoder中的信息定义为一个query。而encoder中包含了所有可能出现的词语,我们将其作为一个字典key;
如右图所示:
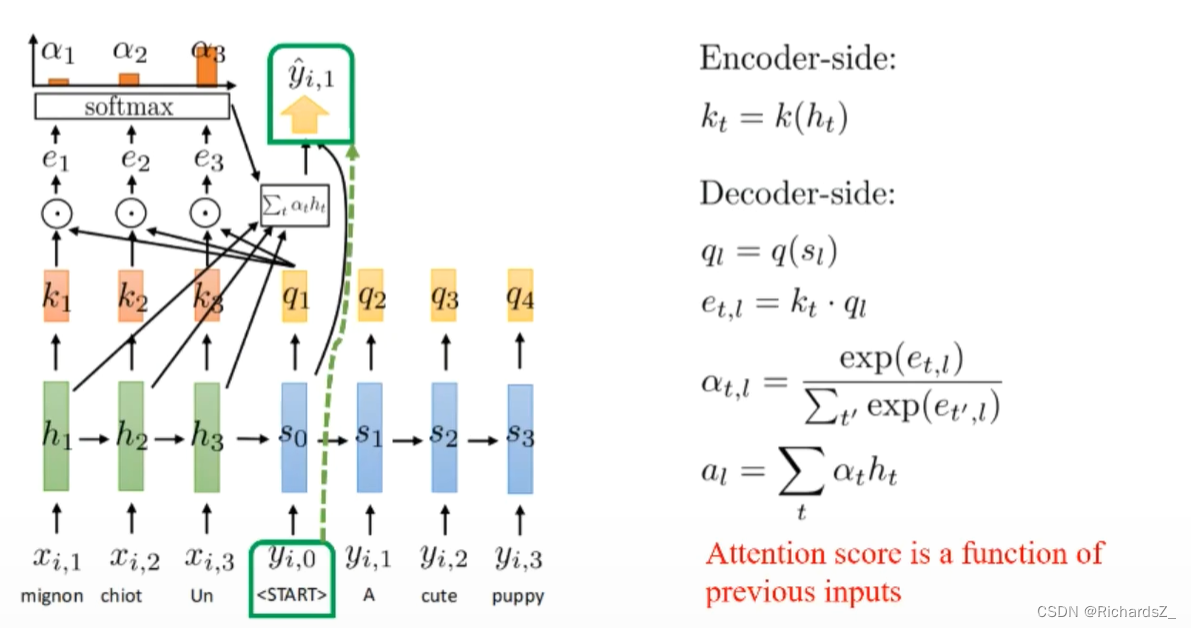
Encoder的每一输入序列x的隐层h,都会通过线性变换生成对应的 k n k_n kn(key), 即 k 1 k_1 k1的信息完全来自于 h 1 h_1 h1;
Decoder的每一输出序列y的隐层s,也会通过线性变换生产对应的 q n q_n qn(query),即 q 2 q_2 q2的信息完全来自于 y 1 y_1 y1,
将当前decoder所处的 q u e r y query query与Encoder字典中所有的 k e y key key分别与做点积 (q和k是等长的向量),则得到对应的 e 1 , e 2 , e 3 e_1, e_2, e_3 e1,e2,e3等值, 经softmax激活,转为概率分布 α 1 , α 2 , α 3 \alpha_1, \alpha_2, \alpha_3 α1,α2,α3,代表了当前query与各key之间的权重值。
此时,由于引入了权重,则原decoder的隐层信息,如 q 2 q_2 q2,则根据线性组合 Σ t α t ∗ h t \Sigma_t{\alpha_t*h_t} Σtαt∗ht 变为 y 2 ′ y'_2 y2′,而 y 2 ′ y'_2 y2′作为隐层继续送入到下一时刻得到 q 3 q_3 q3,周而复始。
2.4 本章小结
为了帮助decoder在生成词语时,有一个不同词语的权重参考。对每一时刻decoder带有的信息query,分别与该时刻下encoder字典的每一个key做点积运算得到 e e e,经softmax激活后得到了 α \alpha α权重,权重越大则代表该时刻下 q q q与该 k k k的关系越密切。
将权重与encoder输入词向量做线性求和,则得到了该时刻下该 q u e r y query query对应的隐层状态 y ′ y^{'} y′,而 y ′ y^{'} y′本身则作为部分信息继续送入到decoder的下一时刻,指导下一时刻的词输出。
尽管Seq2seq+Attention,仍然整体上保持着RNN(LSTM)的结构,即保留了时序上的关系。那么如果Attention机制从中发挥了主要作用,如果放弃RNN的时序关系,单纯利用Attention机制能达到什么效果?这就引出了Transformer的设计初衷!
经论证发现,只用Attention的效果要比Seq2seq+Attention的效果还要好!摒弃了RNN时序架构同时保留了attention机制的Transformer横空出世!
三、Transformer
Transformer结构完全通过self-attention机制来完成源语言序列和目标语言序列的依赖。
3.1 整体框架
Transformer整体仍属于Encoder+Decoder的结构,解决的仍然是Seq2Seq的场景问题,但与传统RNN(LSTM)+Seq2Seq结构有所不同,整体结构如下图所示。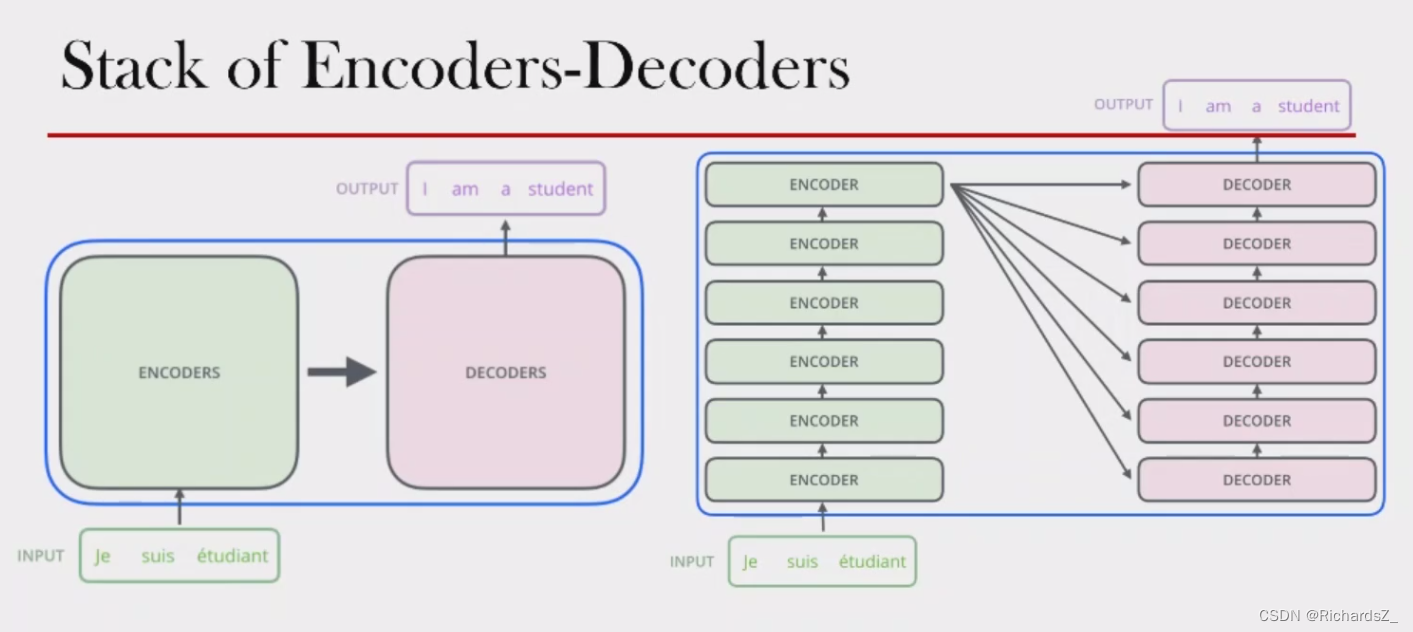
可见,Transformer的Encoder不在保留RNN原有的时序关联,而是由多个子Encoder以stack堆叠的形式构成,最后一层Encoder的输出包含了输入的所有信息,被后续的所有Decoder依赖!这一点与Seq2Seq(RNN)一致。
进一步研究Encoder/Decoder的内部结构,主要分为以下4种处理方法:
- Positional Encoding(位置编码,替代原来的时序表达)
- Multi-head Attention(多头注意力机制)
- Add&Normalization(残差与标准化)
- Masked decoding(decoder的mask机制)
上述4种处理方法也正是Transformer的精华所在!
3.2 Self-Attention
在传统Seq2Seq+Attention架构中,由于存在时序关系,则输出词与输入词通过query和key建立权重关系,输入词与权重关系做线性组合后,影响下一时刻的decoder输出。若抛弃了时序信息,只关注query和key的关系,即self-Attention的理念。
举个例子,下图中,假如把黄色框体cut-off后,人类通过图片给定的信息,很大概率能推测出来黄色缺失部分是狗的另一只耳朵,而这些信息主要来源于与黄色框体强关联的部分(如3个红色框体),同理黄色框体则很难通过弱关联部分(如灰框部分)的信息得以推测。
当然,若整体把狗头部分去掉,人类则根据现有信息,很难推测缺失的部分是一个狗头,也许是一个人头。因此,在一定程度上,某些信息的丢失或掩盖(mask),是可以通过其他现有信息的线性组合能够得以推测!
self-Attention就是找到各部分之间的关联关系,同理,如下图词序列所示,apple与eating, green具备强关联,而eating和green之间则存在弱关联,不依赖时序建立词与词的关联程度,则是self-Attention的主要目的。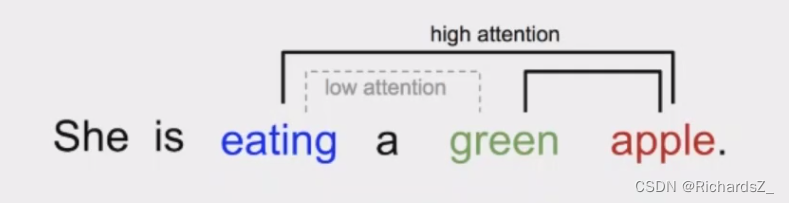
3.2.1 Encoder -> Positional Encoding位置编码
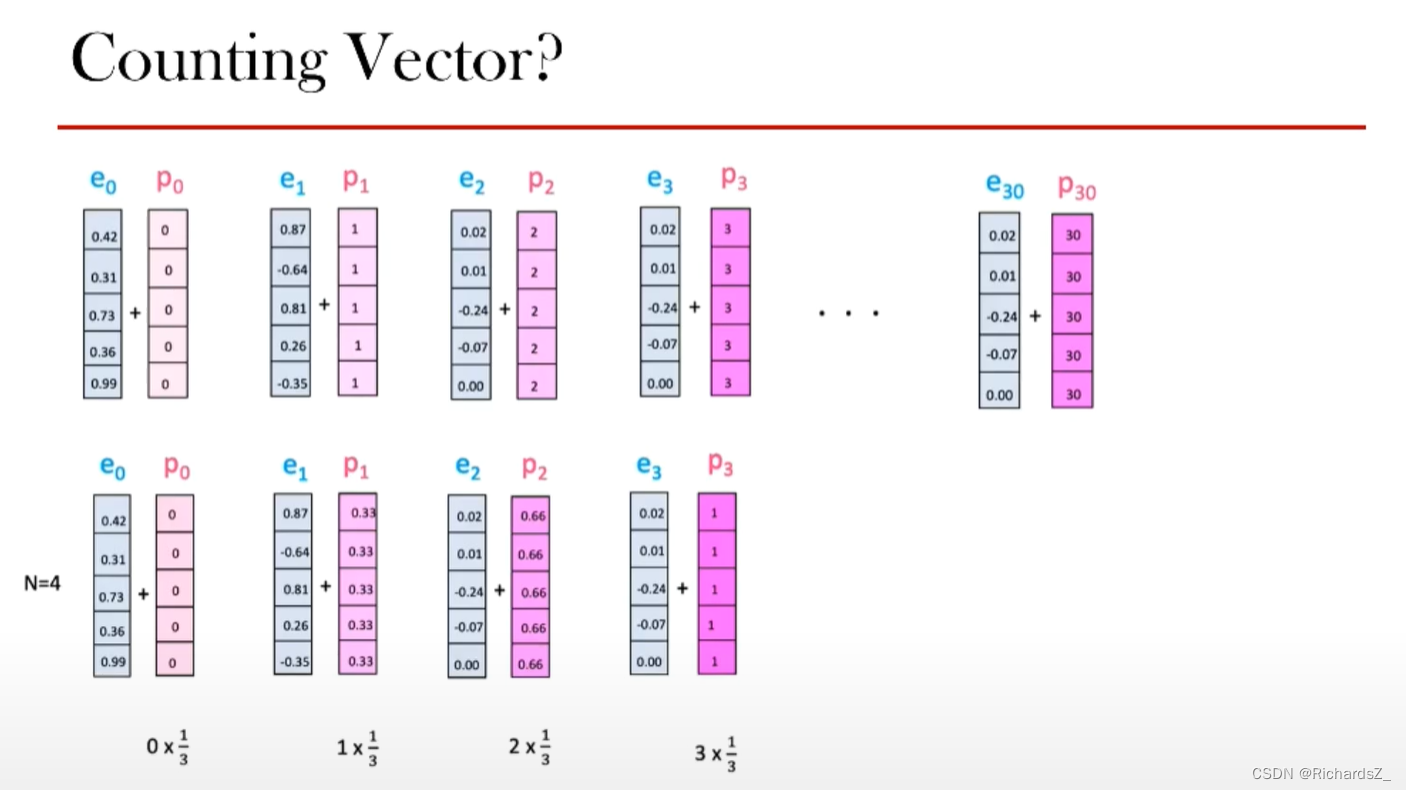
由于取消了时序/循环结构,模型该如何理解单词顺序?为了解决这个问题,Transformer为每个词向量都新添加了一个位置向量,如下图所示, e n e_n en代表词Embedding, p n p_n pn则代表新增的位置编码向量。那么位置编码该用什么原则填充呢?
- 单纯用count计数?由0开始,依次自增?这样会导致位置靠后的词向量与靠前的词向量差值过大
- 将位置编码结合词长度进行归一化?的确能适当解决差值过大的问题,但仍然存在词向量之间先天的差异。
后来,学者提出用sin和cos来反映每一词向量不同index下的位置编码,此方法一方面能保证各词向量的偏移在固定范围内(即正弦/余弦函数一个周期内),另一方面也能保证周期内的各时刻对应的值不同(即满足了位置编码的需求),即单词的绝对位置和相对位置都得到了保障。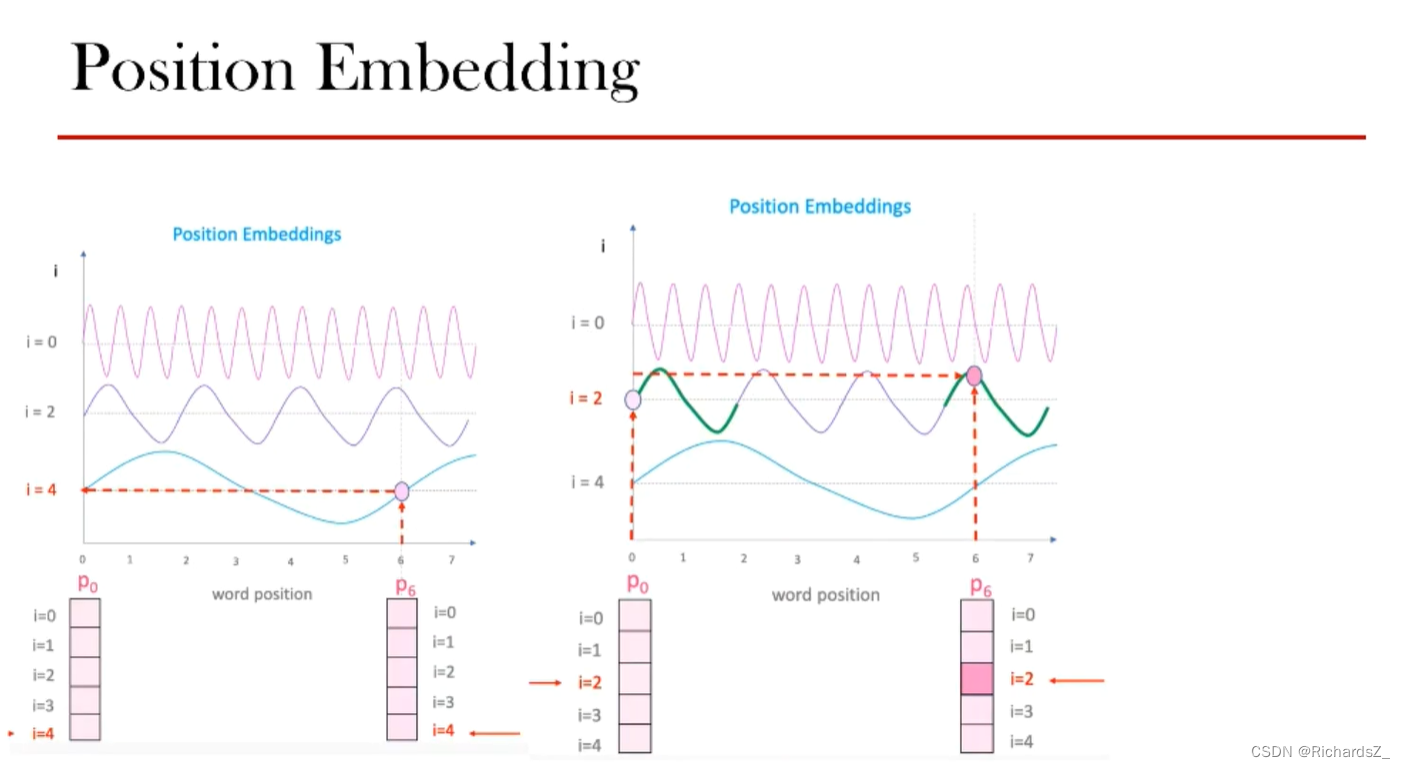
同时,可根据词所在的时序为奇数位或偶数位,分别选择sin()或cos(),公式如下图所示,pos代表源语言序列中的词的index,i代表该一个词向量embedding内对应的index,而d则代表词向量的Embedding维度。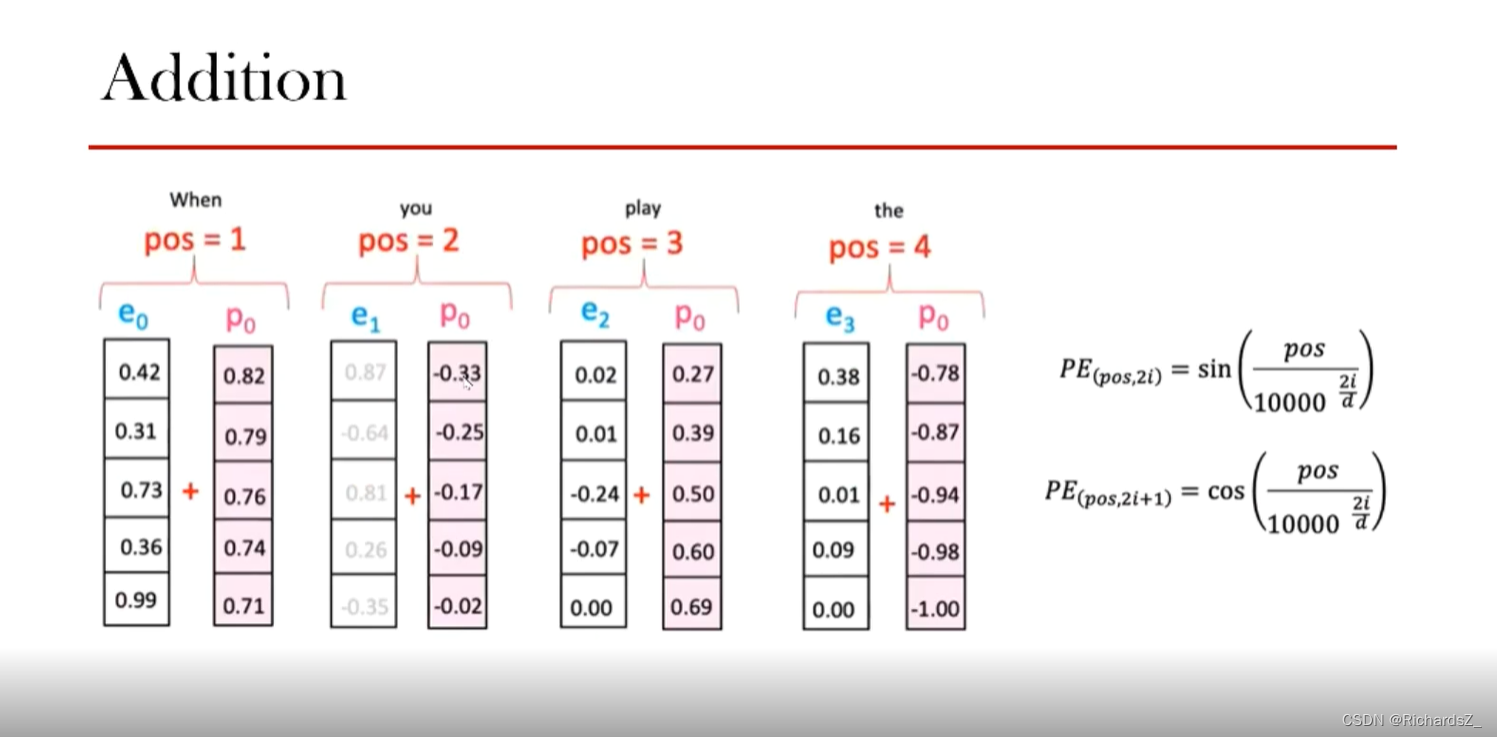
这样编码有几个好处:
首先,正余弦函数的范围控制在[-1,1],导出的位置编码向量先天不会存在偏离过远而破坏原有单词的语义信息。
其次,依据sin和cos的性质,可知第pos+k个位置编码是第pos个位置编码的线性组合,这就意味着位置编码中蕴含着单词之间的距离信息。
3.2.2 self-attention注意力层
位置编码后的词向量,与Seq2Seq+Attention相同的是,都需要通过线性变换可生成key和query,不同的是,Seq2Seq+Attention的query和key分别由Decoder和Encoder得出。而self-Attention则在Encoder内产生Q,K,V。如下图所示
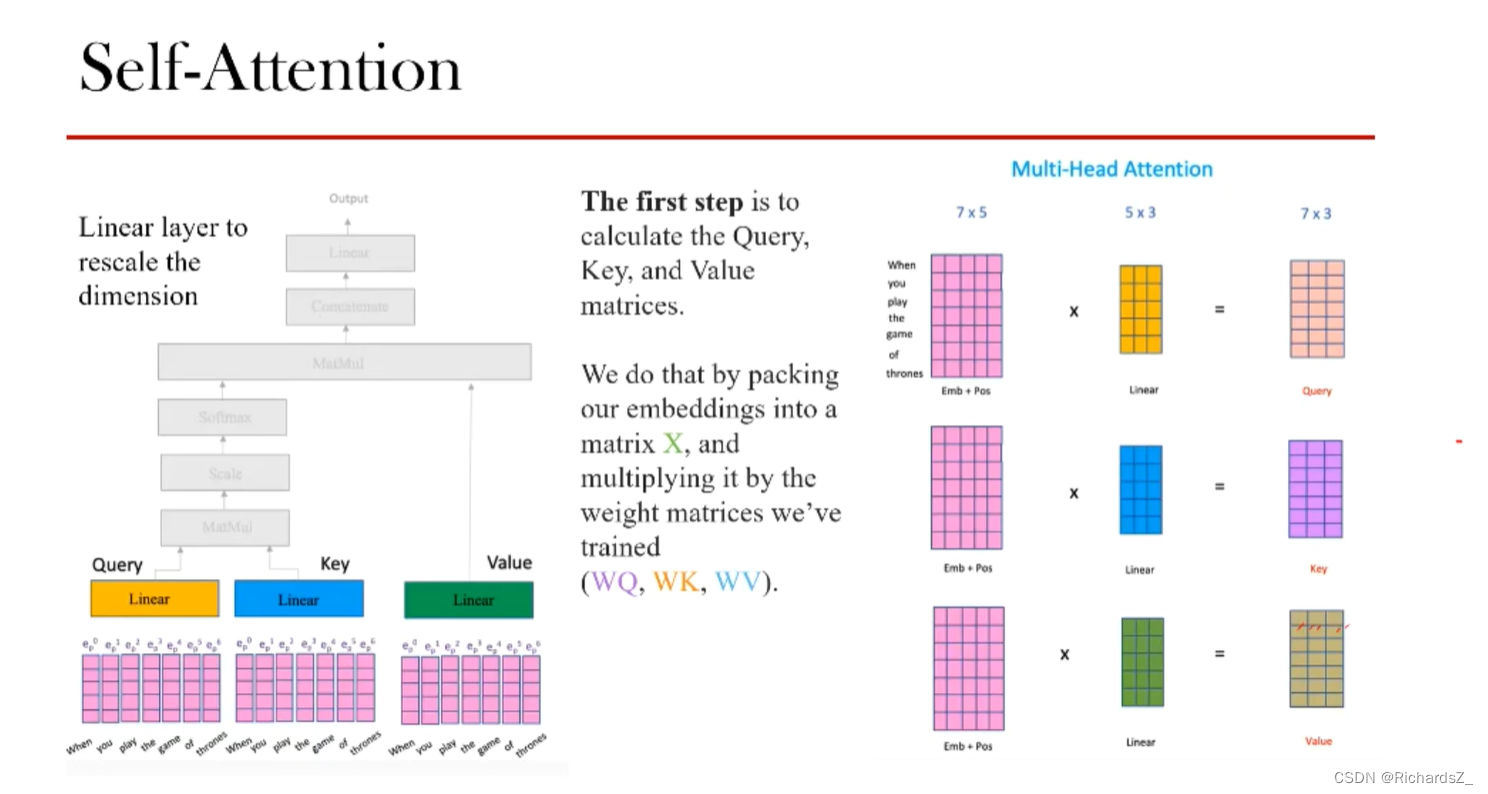
同样的信息(即带有位置编码的词向量 e p e_p ep)经过三个不同的线性变换分别得到了三个表述矩阵Q, K, V。
为了防止过大的匹配分数在后续softmax计算过程中导致梯度爆炸以及收敛慢的问题,我们将Q,K点积后的attention-score进行归一化 Q ∗ K T d k \frac{Q*K^T}{\sqrt{d_k}} dkQ∗KT,再通过softmax转为权重矩阵Attention Filter。这样,输入词之间的相似度得以体现,称之为匹配分数。
得到了Attention Filter后,得到了权重矩阵,再与V做内积,得到了自注意力的输出->Z值。
总结:
输入向量经位置编码组合得到 e p e_p ep后,通过三种线性组合构造出Q,K,V。
Q与K经矩阵乘法后经归一化+softmax得到Attention Filter后,再与V相乘得到了Z值,体现了输入词之间的相似程度。
3.2.2 Encoder -> Multi-head多头注意力机制
上节可知,一组线性组合得到的Q,K,V能产生一种Z值,那不同组的线性组合则能到不同的Z值,那什么样的线性组合才是最优组合?
多头处理(Multi-head)则代表用不同的线性组合得到的多组值 z 1 , z 2 , z 3 z_1, z_2,z_3 z1,z2,z3,最终的Z值做一个concat,以关注上下文的不同侧面。
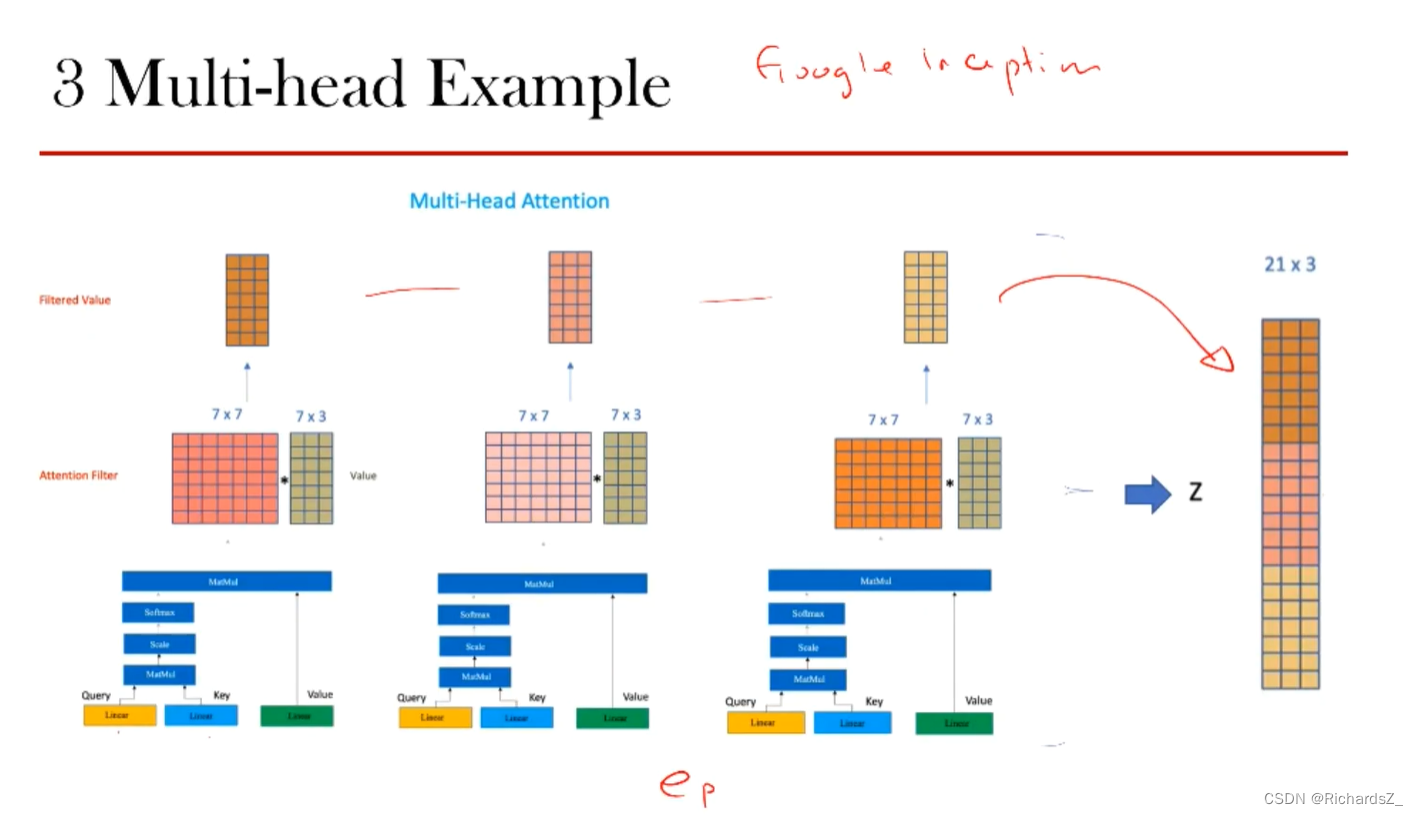
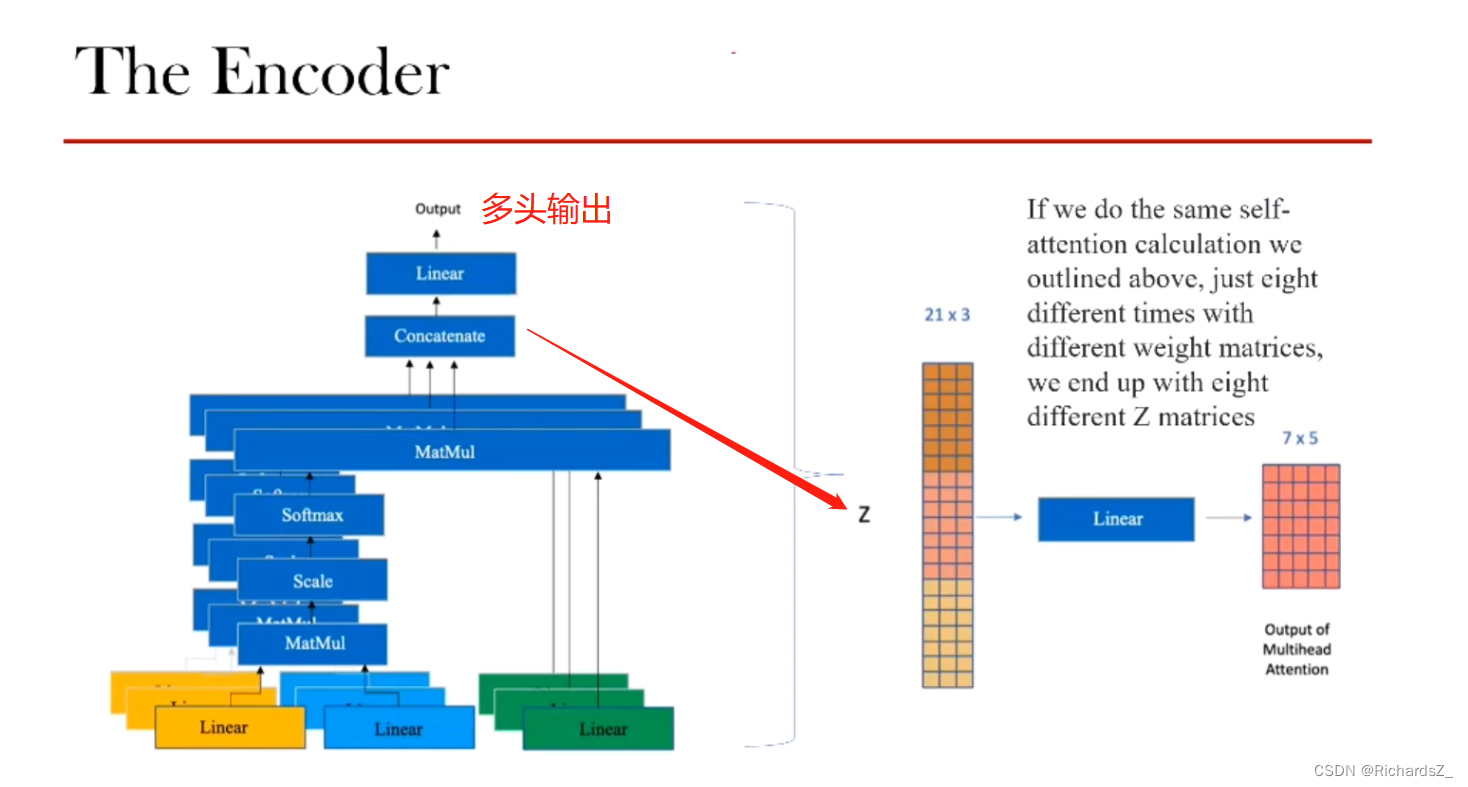
整个self-Attention通过多头concat后得到了Z值(21x3)后,通过Linear层的线性变换还原回词向量本身的维度(7*5),该向量称之为a

3.2.3 Encoder -> Add&Normalization(残差与标准化)
通过多头注意力机制,可以将带有位置编码线性变换而来的K,Q,V转为不同的z值,合并为Z后,通过Linear的线性变换得到了a值(shape与源语言序列embedding一致)。
借鉴了ResNet的残差思想,将输入的 e p e_p ep向量shortcut到多头输出与a相加,即Add操作,一定程度上解决了梯度消失的问题或退化问题。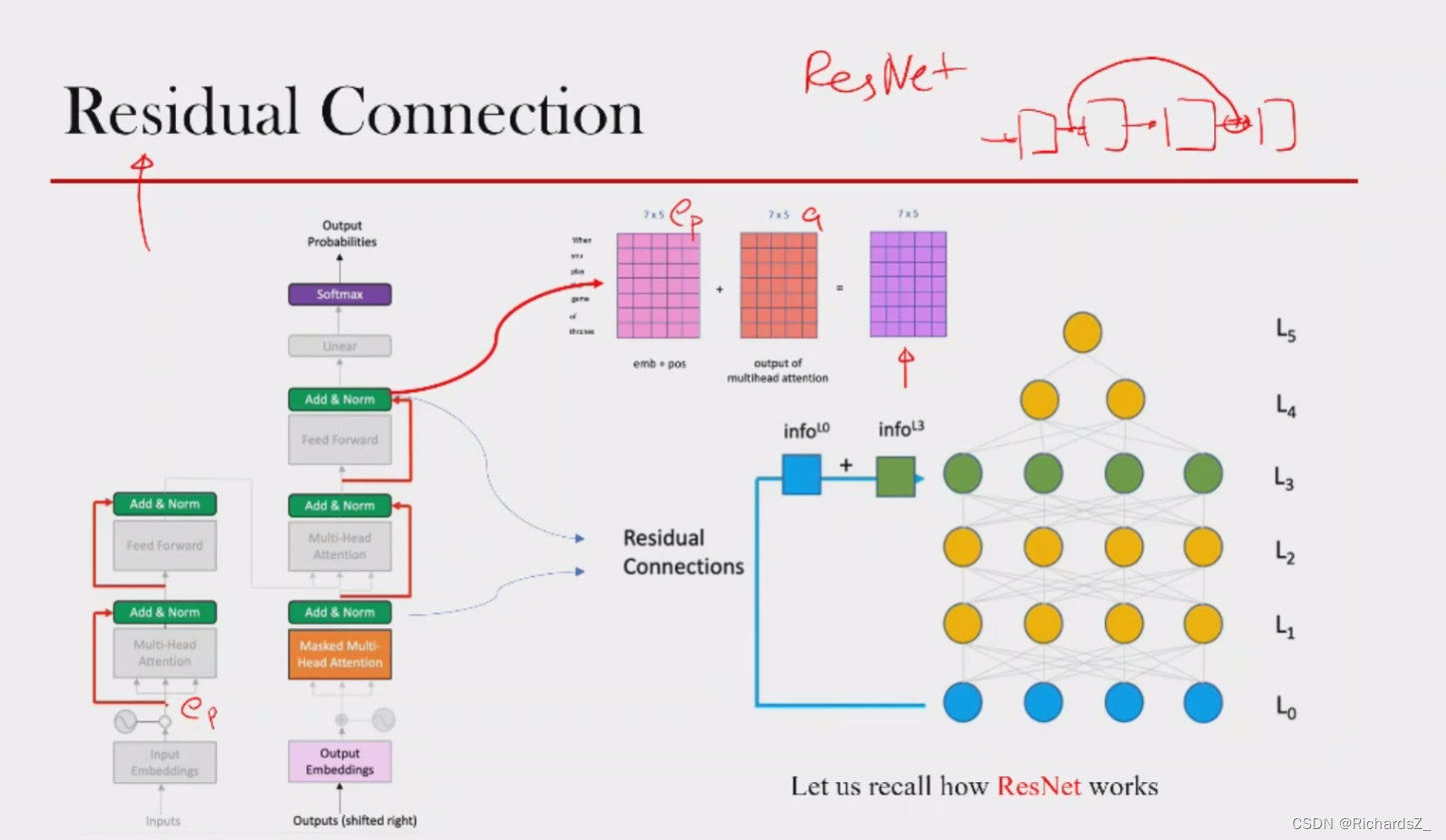
Add操作之后,为了使多个Encoder的连接避免梯度消失问题,对向量进行了层标准化操作,即Layer normalization,在每一个样本上计算均值和方差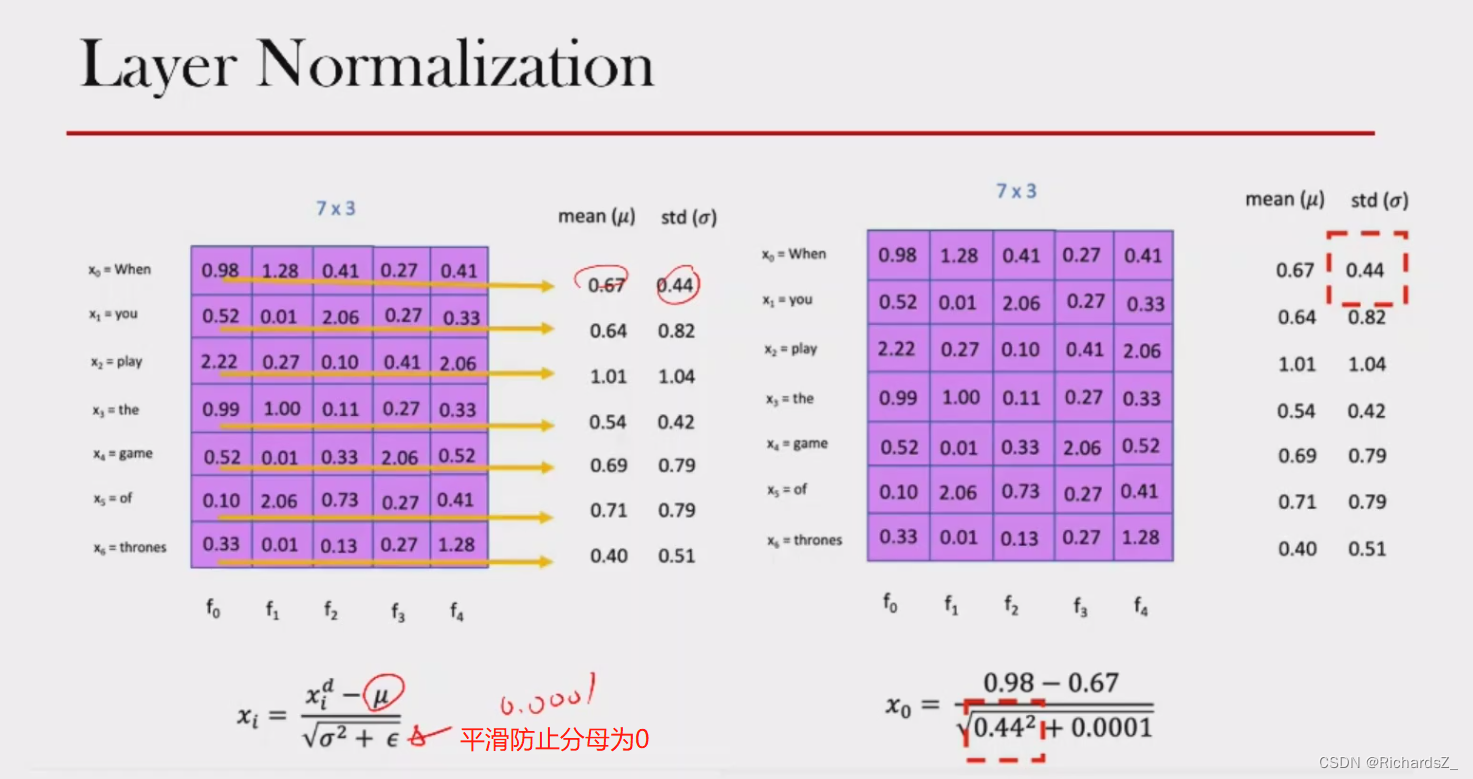
3.2.4 Encoder -> Feed Forward Neutrual Network前向传播层
多头输出的矩阵经linear,并与输入向量 e p e_p ep进行Add&Norm操作后,经过Linear->ReLU->Linear的层结构还原回词向量的原维度。实验证明,这一非线性变换会对模型最终性能产生非常重要的影响!
而Linear->ReLU->Linear的三层结构这里则称之为FFN层。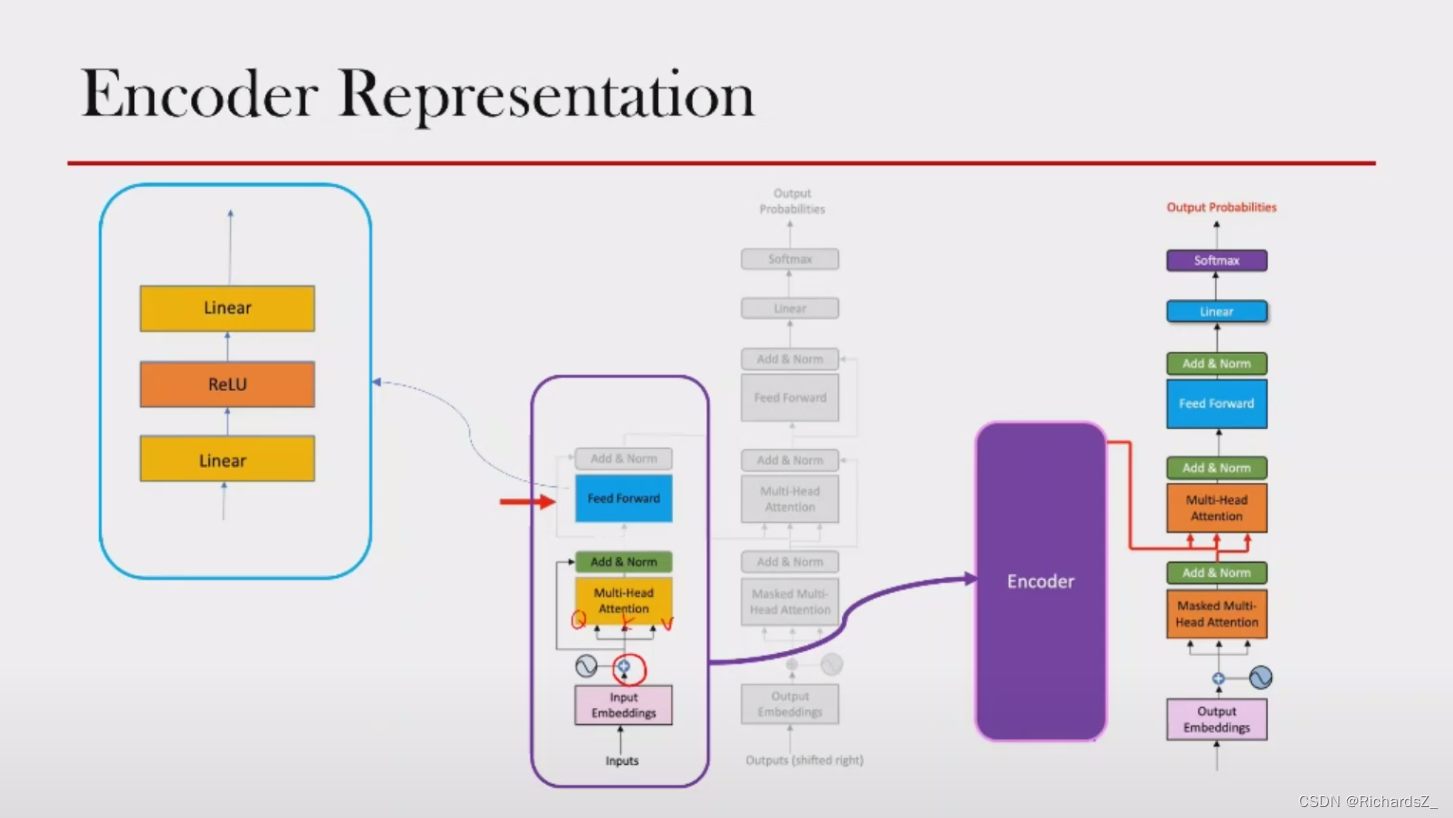
至此,就包括了encoder的全部内容了,多个encoder堆叠在一起后将隐层信息输出到decoder。
3.2.5 Decoder -> Masked Multi-head Attentions带掩码的多头注意力
Decoder的结构与Encoder大致相同,都具备位置编码,多头注意力机制,残差&标准化,前向传播层。不同的是,Decoder新增了Masked Multi-head Attentions带掩码的多头注意力模块,如下图所示: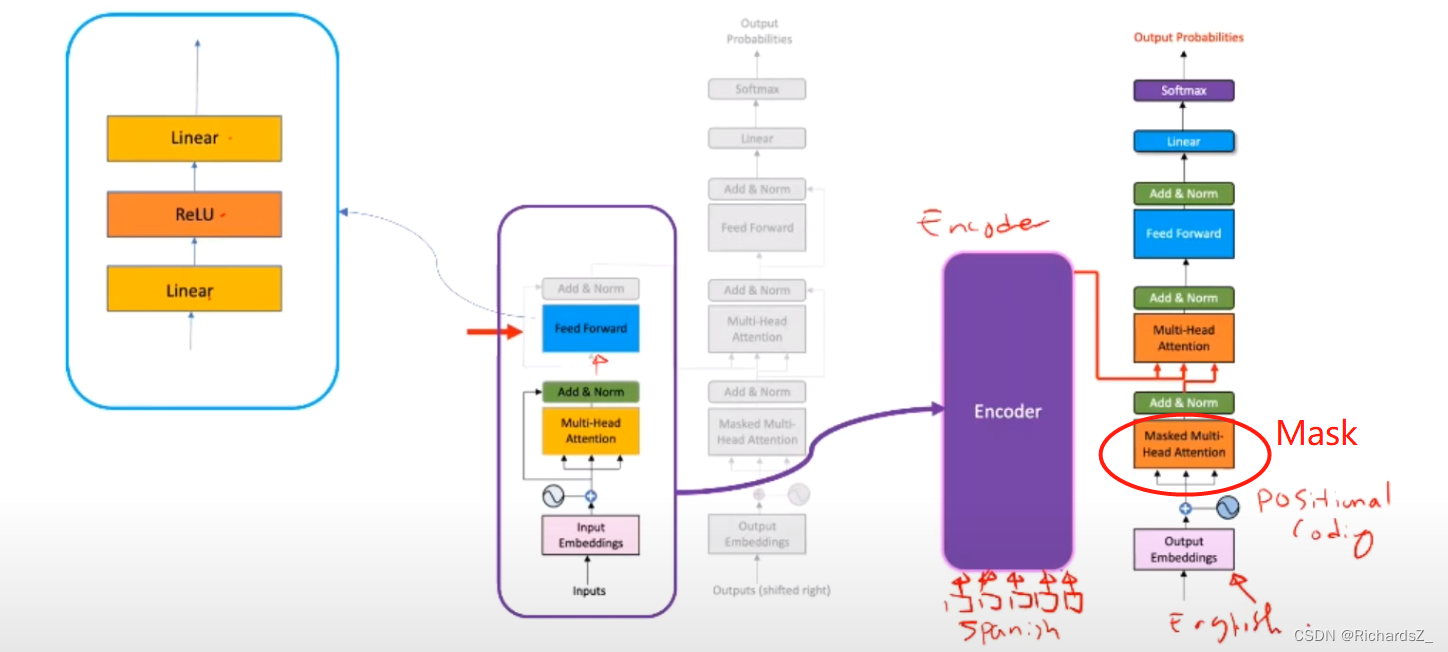
Decoder的输入经位置编码后同样的形成进入了带Mask的多头注意力结构,
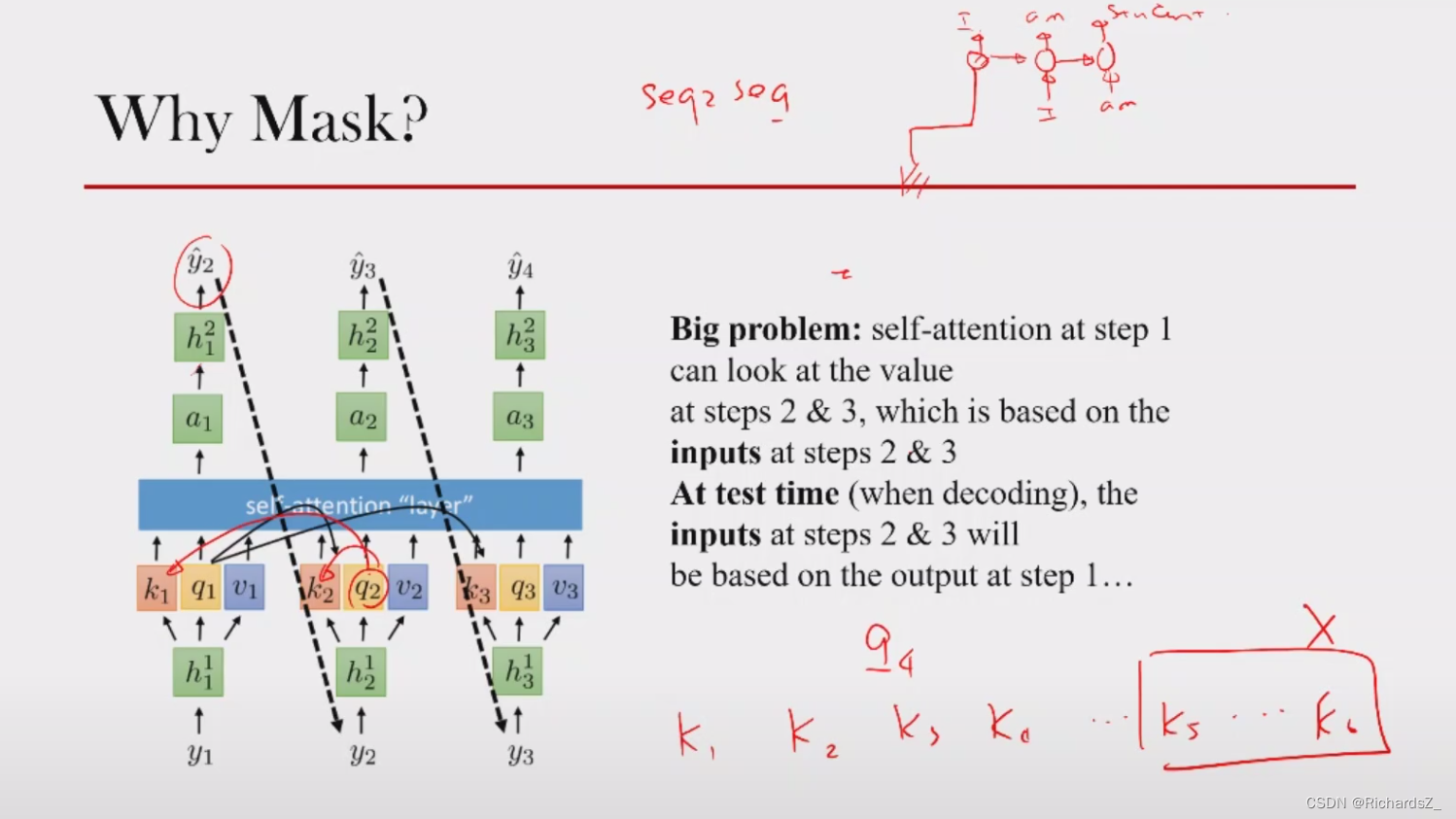
由于这种结构下缺少时序,若当前时刻是 q 2 q_2 q2,就Seq2Seq本身而言,Decoder的 q 2 q_2 q2状态的下一时刻 y 3 y_3 y3还未生成,输入的 y 3 y_3 y3属于未来的穿越信息。模型不应该引入穿越信息,不该让 q 2 q_2 q2与 k 3 k_3 k3做点积。
也就是对于一个序列,在t时刻,Decoder的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?在的Q,K产生的Attention Filter矩阵后,与一个Mask Filter矩阵(对角线以下全为0,对角线以上全为-inf,使其经softmax后概率几乎为0)相加。就可以达到我们的目的 => Decoder的词只能与前面时刻的词计算关联!
3.2.6 Decoder -> 与Encoder结果融合
Decoder侧经带Mask的多头注意力输出后,经Add&Norm产生了V,同Encoder最后一层Add&Norm产生的Q和K,一同送入Decoder的多头注意力模块。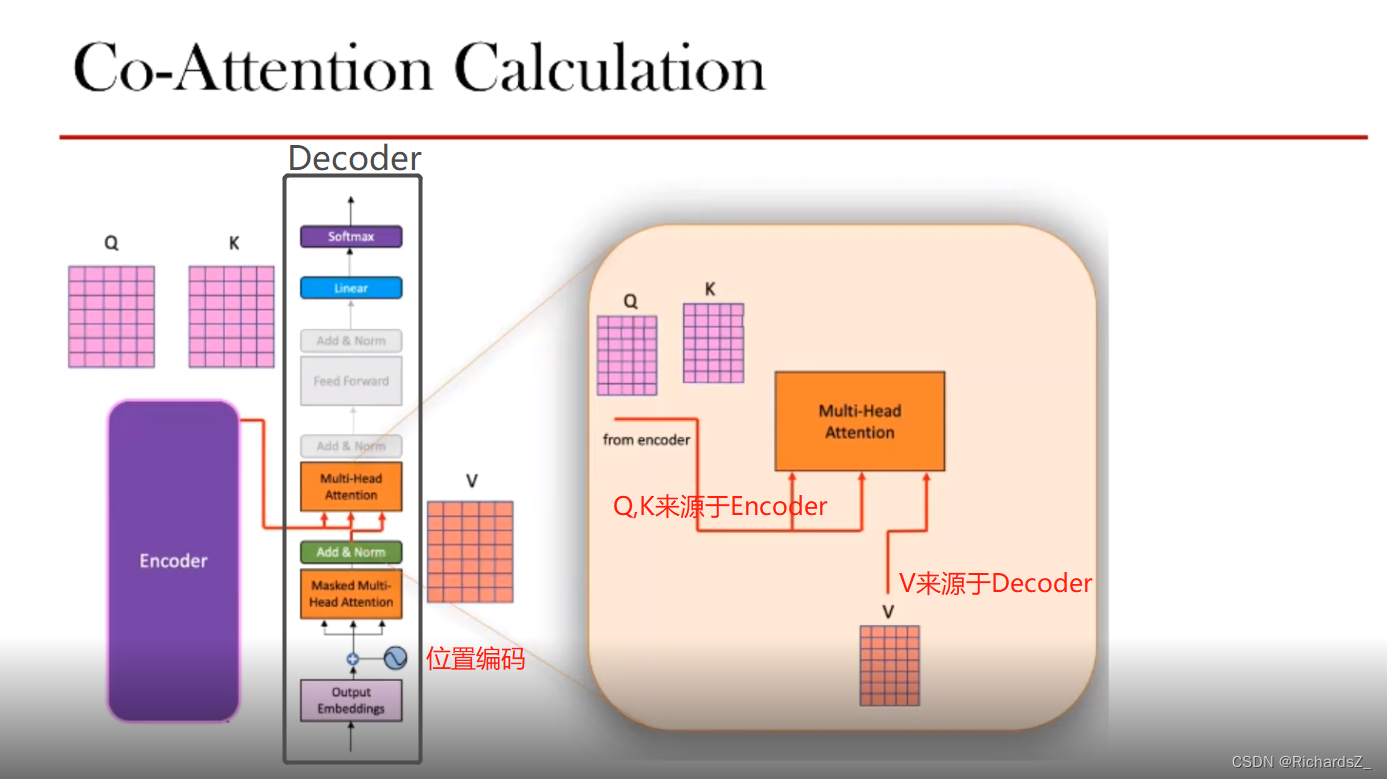
与最早Seq2Seq+Attention中,输出词与输入词的关系异曲同工,区别的是Attention是利用q与k建立点积+softmax建立关联,而self-attention中decoder则利用encoder的Q和K,与decoder的V建立送入多头注意力机制。
- Padding Mask(解决输入序列长度不一致)
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
3.3 交叉熵损失函数
Decoder输出经softmax产生概率分布,如右图所示,优化器经经交叉熵损失函数(Cross Entropy)不断优化,最终保证模型的训练。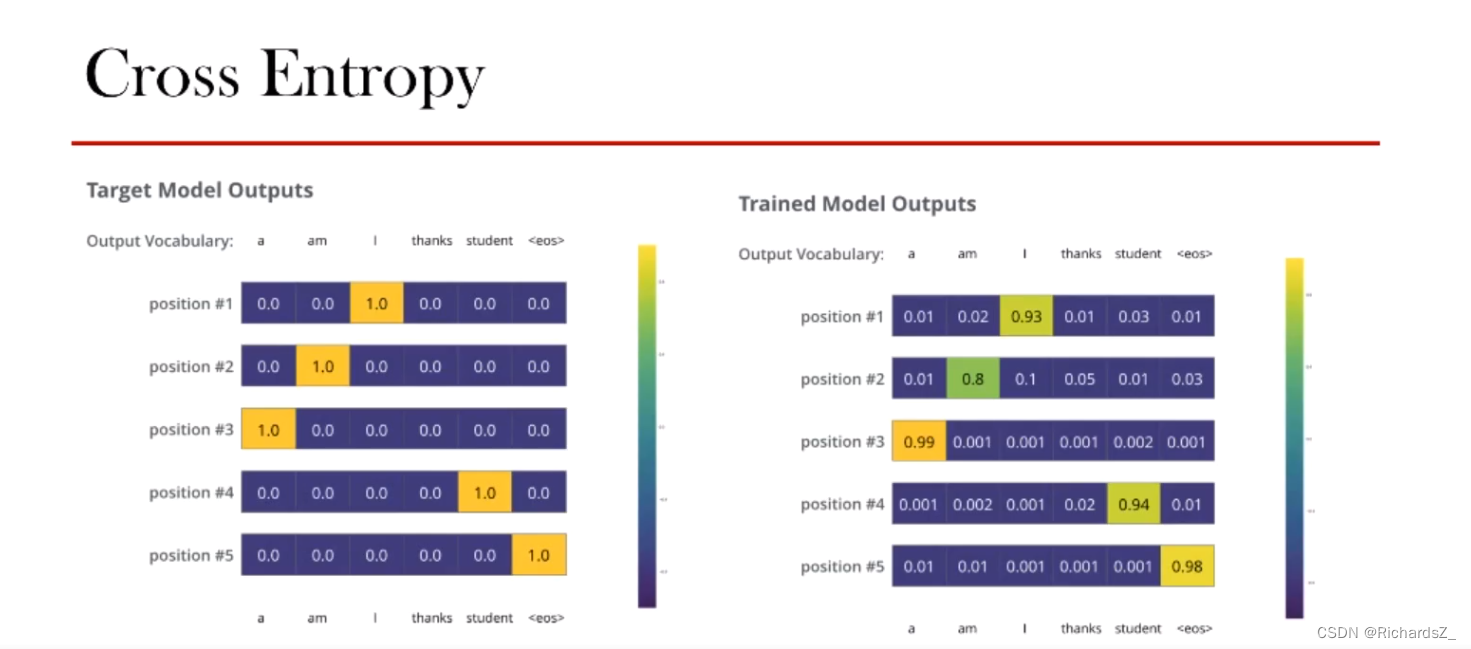
3.4 本章小结
优点:
(1)虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
(2)Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
(3)Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
(4)算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:
(1)粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
(2)Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
四. Bert(Bidirectional Encoder Representation From Transformer)
BERT的背景
从名称来看,是一种带有双向Encoder的Transformer表示。何为单向和双向?
单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token,即每一个Query只能和Decoder左侧的Key,Value做组合(Masked Multi-head attention机制)。
双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token,即所有的Query都要和encoder两侧所有的Key,Value做组合。
通俗点解释,单向Transformer就是一个常规的NLP任务,利用已有token,去预测未来的token,如GPT(GPT的出现是早于BERT的),训练的目标也是基于左边的词,去预测未来的词;而BERT的作者结合了ELMo(输入为双向信息,但架构为RNN)和GPT(Transformer结构,但只利用了单向信息,很难挖掘句子层面的信息)之所长,提出了双向Transformer的结构;
4.1 BERT的核心思想
BERT的出现是一个为了效仿CV领域预训练而生的语言预训练模型!
首先介绍BERT的核心思想。由于BERT利用到了双向的信息,那么预测下一时刻的训练方法将不具备所有下游NLP需求,因此,BERT的训练目标做出了改变!其一,是完形填空,即预测被盖住的词;其二是,句子与句子之间是否相邻预测;其三则是,通过无需标注的数据预训练模型,提取语句的双向上下文特征;
这种预训练模型再用于下游其他任务时,如实体命名识别,QA,机器翻译等,只需要微调就会获得极好的效果!
4.1 Bert结构
当隐藏了Transformer Encoder的详细结构后,我们就可以用一个只有输入和输出的黑盒子来表示它了: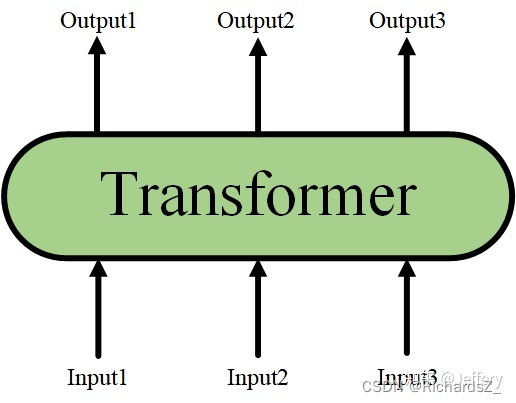
而Transformer又可以进行堆叠,形成一个更深的神经网络: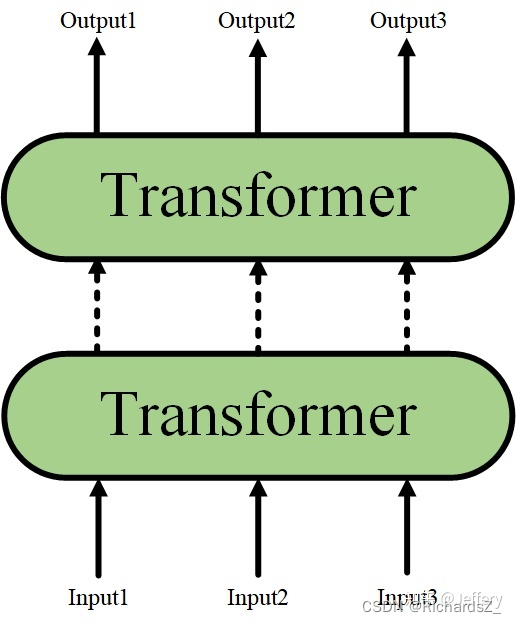
最终,经过多层Transformer结构的堆叠后,形成BERT的主体结构: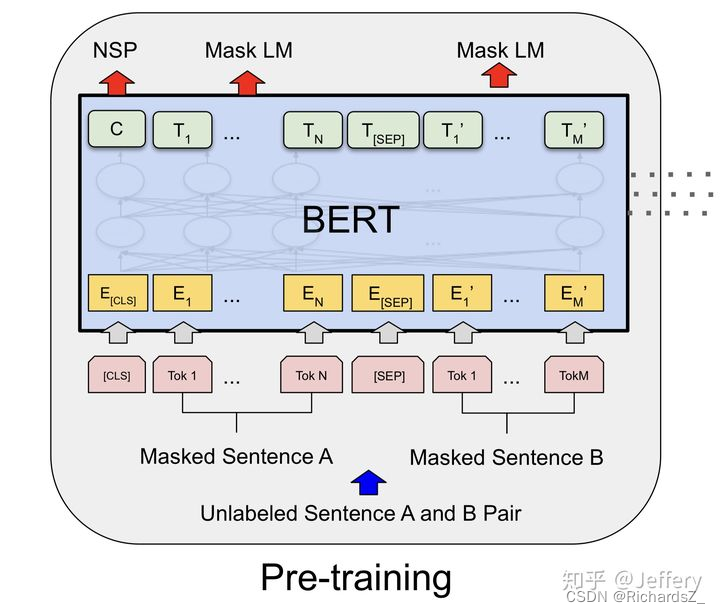
4.2 Bert输入输出
Transformer的特点就是有多少个输入就有多少个对应的输出
- 输入
BERT的输入为每一个token对应的表征(图中的粉红色块就是token,黄色块就是token对应的表征)
输入的每一个序列开头都插入特定的分类token([CLS]),该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用。
由于BERT是一个预训练模型,其必须要适应各种各样的自然语言任务,因此模型所输入的序列必须有能力包含一句话(文本情感分类,序列标注任务)或者两句话以上(文本摘要,自然语言推断,问答任务)。那么如何令模型有能力去分辨哪个范围是属于句子A,哪个范围是属于句子B呢?BERT采用了两种方法去解决:
在序列tokens中把分割token([SEP])插入到每个句子后,以分开不同的句子tokens。
为每一个token表征都添加一个可学习的分割embedding来指示其属于句子A还是句子B。
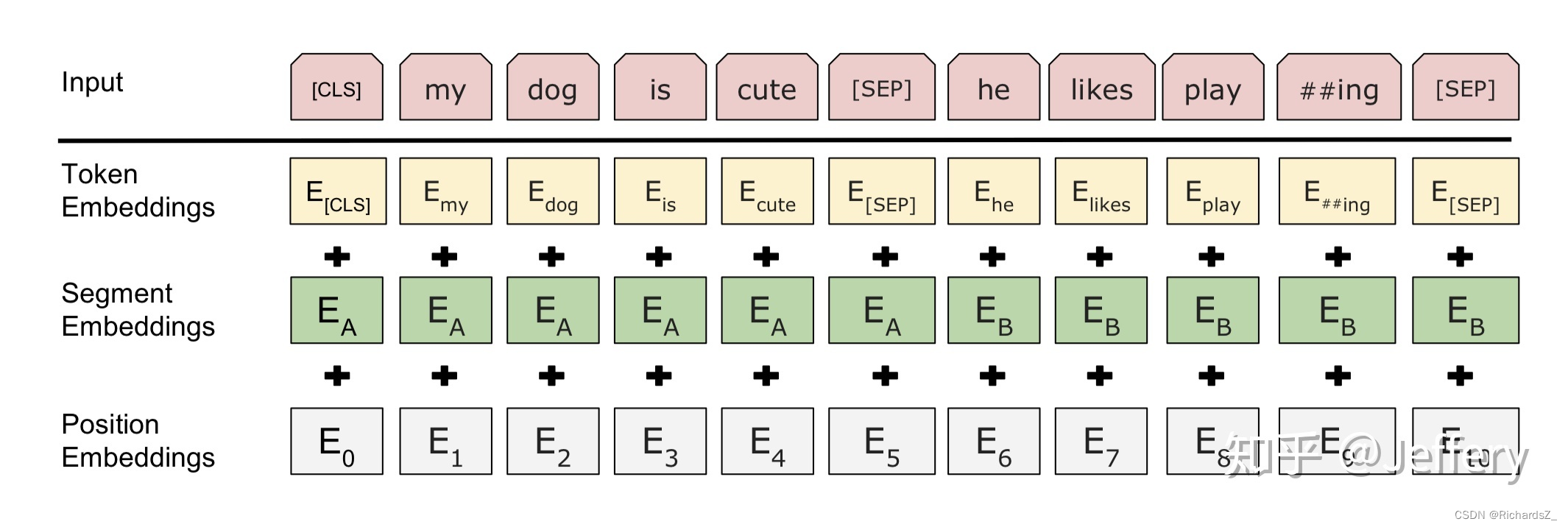
因此最后模型的输入序列tokens为下图(如果输入序列只包含一个句子的话,则没有[SEP]及之后的token):
- 输出

到此为止,BERT的输入输出都已经介绍完毕了,其设计的思路十分简洁而且有效。
4.3 Bert预训练任务
BERT构建了两个预训练任务,分别是Masked Language Model和Next Sentence Prediction。
4.3.1 Masked Language Model(MLM)
简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。
为了避免由于【MASK】产生的MLM阶段和Fine-tuning微调阶段之间产生的不匹配,若某个token被随机地选中作为MASK来预测,假如是第i个token被选中,则会被替换成以下三个token之一:
1)80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
2)10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
3)10%的时候是保持的token不变。如,my dog is hairy——>my dog is hairy
再用该位置对应的 T i T_i Ti去预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
4.3.2 Next Sentence Prediction(NSP)
简单来说就是预测两个句子是否连在一起。尚未完成TODO:
4.4 官方通用预训练模型
官网最开始提供了两个版本,L表示的是transformer的层数,H表示输出的维度,A表示mutil-head attention的个数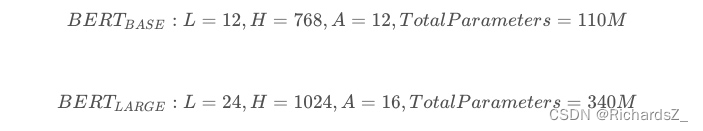
如今已经增加了多个模型,中文是其中唯一一个非英语的模型。
从模型的层数来说其实已经很大了,但是由于transformer的残差模块(Add&Norm),层数并不会引起梯度消失等问题,但是并不代表层数越多效果越好,有论点认为低层偏向于语法特征学习,高层偏向于语义特征学习。
代码


一站式 AI 云服务平台
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)