
pytesseract和tesseract-ocr安装过程
Python人工智能之图片识别,Python3一行代码实现图片文字识别编程小石头 2017-09-20 15:24:57 160318 收藏 163分类专栏: python 文章标签: python 人工智能 图片识别-Pytho python人工智能 python入门版权自学Python3第5天,今天突发奇想,想用Python识别图片里的文字。没想到Python实现图片文字识别这么简单,只需要一
Python人工智能之图片识别,Python3一行代码实现图片文字识别
编程小石头 2017-09-20 15:24:57 160318 收藏 163
分类专栏: python 文章标签: python 人工智能 图片识别-Pytho python人工智能 python入门
版权
自学Python3第5天,今天突发奇想,想用Python识别图片里的文字。没想到Python实现图片文字识别这么简单,只需要一行代码就能搞定
#作者微信:2501902696
from PIL import Image
import pytesseract
#上面都是导包,只需要下面这一行就能实现图片文字识别
text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim')
print(text)
1
2
3
4
5
6
我们以识别诗词为例
下面是我们要识别的图片
###先看下效果图
我们运行代码后识别的结果,有几个字没有正确识别,但是大多数字都能识别出来。
风急天高猿啸哀 渚芸胄芳少白鸟飞凤
无边落木萧萧下, 不尽长量工盲衮宕衮来
万里悲秋常1乍窨, 百年多病独登氤
艰难苦恨擎霜量 漂倒新停澍酉帆
1
2
3
4
##一行代码就能识别图片,我们背后要做些准备工作的
这里我们需要用到两个库:pytesseract和PIL
同时我们还需要安装识别引擎tesseract-ocr
###下面就来讲讲这几个库的安装,因为只有这几个库安装好以后Python才能实现一行代码实现图片文字识别
#一,pytesseract和PIL的安装
安装这两个包可以借助pip
1,命令行安装
pip install PIL
pip install pytesseract
2,如果你用的pycharm编辑器,就可以直接借助pycharm实现快速安装。
在pycharm的Settings设置页按照下面步骤操作
这样就能成功安装pytesseract,安装PIL只需要在上面第三步里搜索PIL并点击安装即可
这时我们安转好了库,运行下面代码
from PIL import Image
import pytesseract
text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim')
print(text)
1
2
3
4
会报下面错误,错误原因是:没有安装识别引擎tesseract-ocr
##二,安装识别引擎tesseract-ocr
1.下载下面的安装包,然后直接点击安装即可
tesseract-ocr安装包和中文语言包
解压安装tesseract-ocr后做如下操作,就可以支持中文识别了。因为tesseract-ocr默认不支持中文识别。
2,安装完成tesseract-ocr后,我们还需要做一下配置
在C:\Users\huxiu\AppData\Local\Programs\Python\Python35\Lib\site-packages\pytesseract找到pytesseract.py打开后做如下操作
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
#tesseract_cmd = 'tesseract'
tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
1
2
3
也可以通过pycharm快速打开pytesseract.py
至此我们所有的配置就完成了,运行下面代码就可以把杜甫的登高这首图片诗解析成文字了
————————————————
版权声明:本文为CSDN博主「编程小石头」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qiushi_1990/article/details/78041375
=================================================================================================================
tesseract-ocr安装和简单操作文档
Mr熊 2019-08-20 14:07:05 3149 收藏 4
分类专栏: 3-python
版权
1 下载
1.1 Tesseract-OCR 4.0版本下载地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w32-setup-v4.0.0-beta.1.20180608.exe
1.2 其他版本下载地址:
https://digi.bib.uni-mannheim.de/tesseract/
2安装
2.1 双击安装;
2.2 点击“运行”继续
2.3 点击“next”继续
2.4 选择下载包(在additional language data (download 下选择中数学公式库和中文库Chinese(simplified)(traditional)),点击“next”继续
2.5 选择安装路径(该演示文档里选择安装在C:\KFSofts\Tesseract-OCR目录下)
2.6 直接点击“install”,开始自动化安装,直到完成:
3环境配置
4.1 将Tesseract-OCR安装目录(C:\KFSofts\Tesseract-OCR)加入环境变量path中;
4.2 添加变量名TESSDATA_PREFIX 并赋值为C:\KFSofts\Tesseract-OCR\tessdata
4 简单使用
4.1 cmd命令使用
(命令格式:tesseract 目标图片 生成的box文件 语言包 makebox ):
比如:
C:/KFSofts/Tesseract-OCR/tesseract C:\Users\Administrator\Desktop\OCR\img\11.png C:\Users\Administrator\Desktop\OCR\img\resulit -l chi_sim makebox
######
4.2 python调用 PIL和pytesseract库,代码如下(该库都可以通过PIP安装):
###
from PIL import Image
import pytesseract
import os
def aaa():
path = "C:\\Users\\Administrator\\Desktop\\OCR\\img\\" #图片路径
path2 = "2.png"
text = pytesseract.image_to_string(Image.open(path+path2), lang="chi_sim")
print(text.replace(" ",''))
if __name__=="__main__":
aaa()
4.3有时候有需要修改***data\Lib\site-packages\pytesseract下的pytesseract.py)
5参考文档:https://www.cnblogs.com/wangkevin5626/p/9640165.html
————————————————
版权声明:本文为CSDN博主「Mr熊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41030861/article/details/99842001
====================================================================================
Pytesseract的安装与使用

起个名字好难阿关注
0.0782020.10.09 23:42:28字数 442阅读 1,696
一、安装pytesseract
通过cmd输入pip install pytesseract进行安装,但是安装后并不能直接使用,还需要下载Tesseract-OCR。
下载Tesseract-OCR
下载完双击打开,连续next,直到出现安装路径的时候,可以自定义安装路径也可以使用默认的安装路径,但是无论是哪一种一定要记住路径。
我的是自定义的安装路径
F:\Tesseract-OCR\tesseract.exe
然后通过cmd输入pip install pytesseract可以看到自己安装的pytesseract所在路径

image.png
根据路径找到pytesseract.py
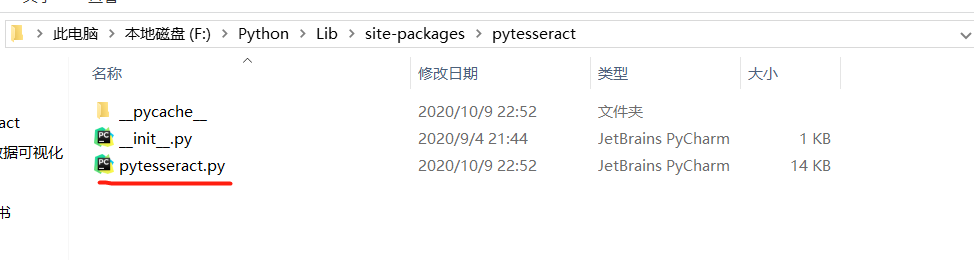
image.png
点开编辑,找到tesseract_cmd将它改为你刚刚安装的tesseract的路径。
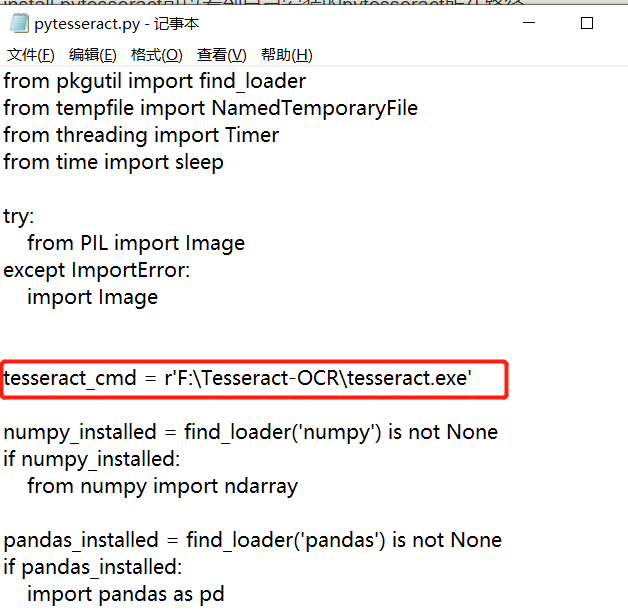
image.png
保存后去运行程序会发现没办法使用pytesseract库,它还是会报错,这是由于环境变量也要进行设置。
点开我的电脑—》属性—》高级系统设置—》环境变量,新建一个变量:
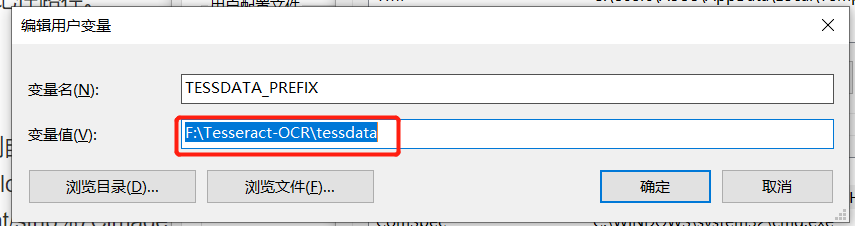
image.png
路径还是你刚刚安装的Tesseract-OCR路径,但是要将它定位到其中的tessdata,变量名也一定不能改。
然后在下面的path中加入的变量:

image.png
保存后,请一定要重启,然后在去运行程序就可以使用pytesseract库了。
二、pytesseract库的使用
我是以古诗文网的登录验证码为例,写的代码,运行后请对照图片与输出结果是否一致。
代码如下:
import requests
from lxml import etree
from PIL import Image
import pytesseract
if __name__ == '__main__':
#或缺页面数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
page_text = requests.get(url=url, headers=headers).text
#解析出页面中图片的地址
tree = etree.HTML(page_text)
cod_img_src ='https://so.gushiwen.cn' + tree.xpath('//*[@id="imgCode"]/@src')[0]
cod_data = requests.get(url=cod_img_src,headers=headers).content
with open('./code.jpg', 'wb') as fp:
fp.write(cod_data)
text = pytesseract.image_to_string(Image.open(r'./code.jpg'))
print(text)
运行结果
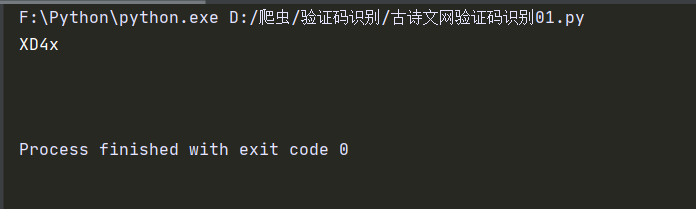
image.png
实际结果
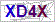
code.jpg
我运行了多次发现字母大部分都是能准确识别的,但是一旦数字经常识别错误。
参考:
https://blog.csdn.net/weixin_44010678/article/details/107818994
https://blog.csdn.net/qq_44314841/article/details/105602017?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)