
机器学习——P4 Basic Concept
误差误差来源——bias(偏差)和 variance(方差)偏差就是model里的所有function得到的y与y hat的差距,就像往靶子上射击,所有的射击到的点都离靶心很远 ,像下面的Large Bias图,那么偏差就大,而下面Small Bias射击的点离靶心有近有远,但平均值小,那么偏差就小。方差就是model里的所有的function得到的y之间的差距,就是射击在靶子上的点之间的差距,像
误差
误差来源——bias(偏差)和 variance(方差)
偏差就是model里的所有function得到的y与y hat的差距,就像往靶子上射击,所有的射击到的点都离靶心很远 ,像下面的Large Bias图,那么偏差就大,而下面Small Bias射击的点离靶心有近有远,但平均值小,那么偏差就小。
方差就是model里的所有的function得到的y之间的差距,就是射击在靶子上的点之间的差距,像Large bias图,射击的点之间距离都很小,那么方差就小,而Small Bias图则相反。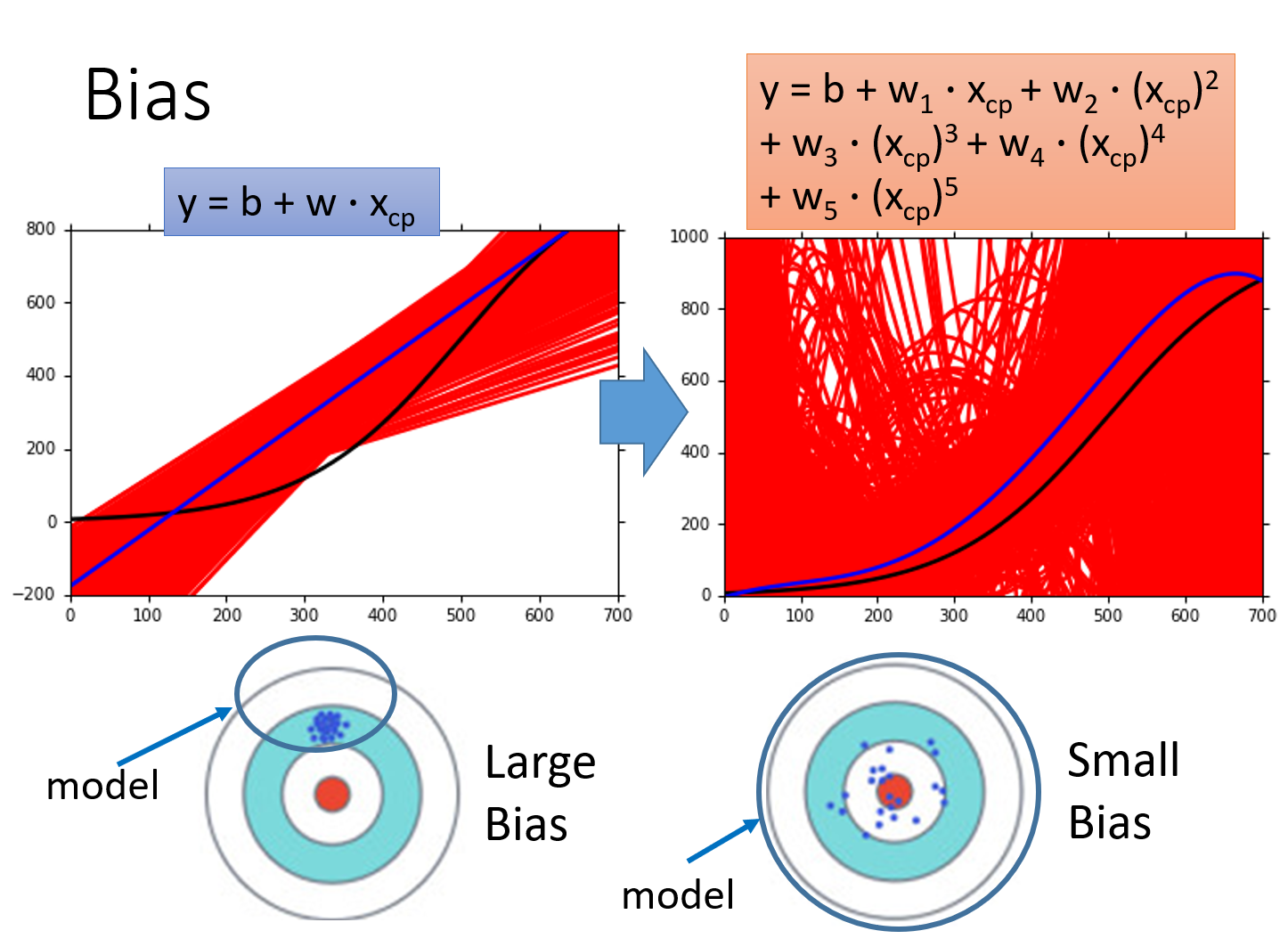
回归中,复杂的模型包含简单的模型(令高次项系数为0)。
模型在拟合数据时,越简单的模型,受到特殊的取样数据点的影响越小,所以方差越小。
一般来说,
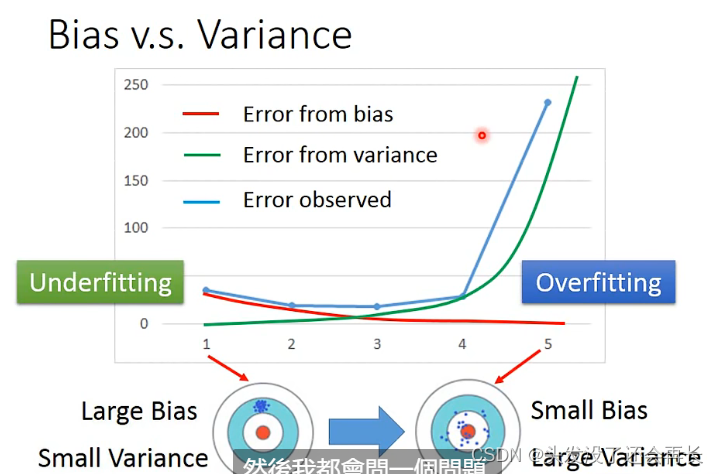
简单的模型(左侧)有大的
bias和小的variance
复杂的模型(右侧)有小的bias和大的variance【瞄得越来越准,但误差越来越大】
如何分析是哪种误差
在考虑优化一个model的时候,我们应该先知道,这个模型是bias大还是variance大
如何知道是那种误差呢?
- 当我们得到的
model离我们现在的一些training data都有点距离,不能完全匹配,那就是Underfitting,即有large bias - 当我们得到的
model在training data上能很好的拟合,但是在testing data上会有很大的误差,那就是overfitting,即有large variance
如何解决不同的误差
欠拟合(underfitting):误差来源于bias——模型不能很好地拟合训练数据。(也就是得到的所有的数据之间差距很小(variance),但是这些数据都离目标值很远,参考作图,那么再多的input都是没用的,因为model本身有问题)解决方法:重新设计模型(欠拟合时,采集更多数据是没用的)
- 增加更多的特征作为输入
- 选择更复杂的模型
过拟合(overfitting):误差来源于variance——模型拟合了训练数据,但在测试数据上有很大误差。(测试得到的数据,有的很靠近目标值了,但是有的离目标值非常远)解决方法:
- 更多数据——采集or生成
- 正则化
理想结果:平衡
bias和variance,得到一个较好的模型。
如何找到误差较小的model
训练集、验证集、测试集的划分,交叉验证(cross validation)和k折(k-fold)交叉验证。
将
training set分为两个,一个用来test,一个用来validate,先在training set上训练,得到error小的model,再在validation上验证
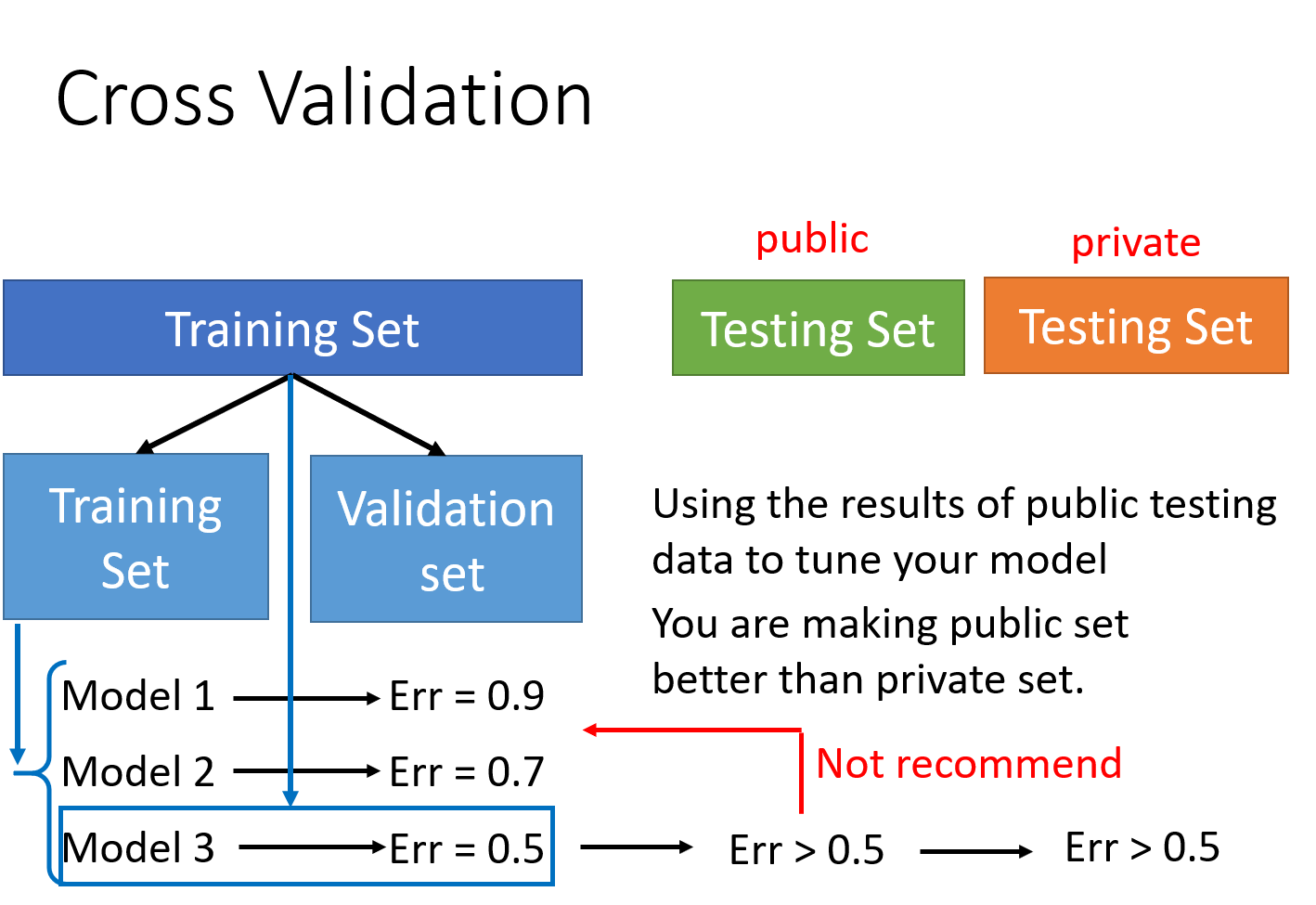
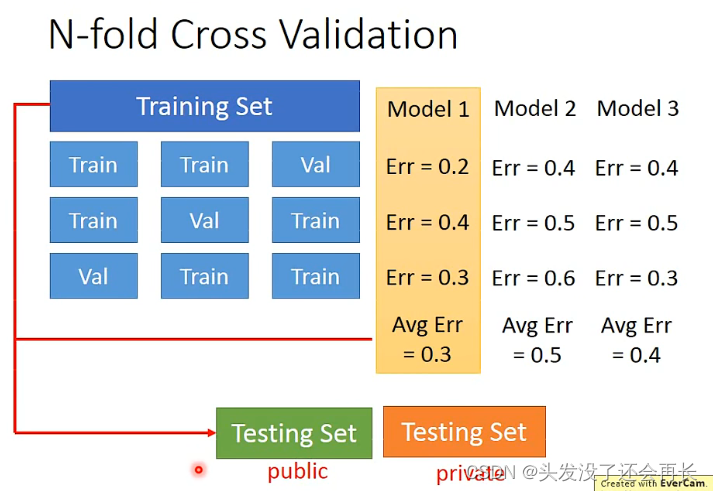
但如果担心分两种之后,在
validation set上面有不好的data,那么将training set分为N类,比如N=3,那么就分为3个,其中两个任选用来训练,剩下一个用来验证,就有是那种方式了,每一个model在三种方式上的error取平均值之后进行比较,得到error小的model

一站式 AI 云服务平台
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)