
深度学习中超参数介绍,过拟合、欠拟合、梯度消失及梯度爆炸的理解
超参数的设置对训练的影响(1)学习率(learning rate)学习率(learning rate)是指在优化算法中更新网络权重的幅度大小。学习率可以是恒定的、逐渐降低的,基于动量的或者是自适应的,不同的优化算法决定不同的学习率。为了能够使得梯度下降法有较好的性能,我们需要把学习率的值设定在合适的范围内。学习率过小,会极大降低收敛速度,增加训练时间;学习率过大,可能导致参数在最优解两侧来回振荡,
超参数的设置对训练的影响
(1)学习率(learning rate)
学习率(learning rate)是指在优化算法中更新网络权重的幅度大小。学习率可以是恒定的、逐渐降低的,基于动量的或者是自适应的,不同的优化算法决定不同的学习率。为了能够使得梯度下降法有较好的性能,我们需要把学习率的值设定在合适的范围内。学习率过小,会极大降低收敛速度,增加训练时间;学习率过大,可能导致参数在最优解两侧来回振荡,所以学习率对于算法性能的表现至关重要。
(2)学习率调整策略
一般情况下,初始参数所得目标值与要求的最小值距离比较远,随着迭代次数增加,会越来越靠近最小值。学习率调整策略的基本思想是学习率随着训练的进行逐渐衰减,即在开始的时候使用较大的学习率,加快靠近最小值的速度,随着迭代次数的增加使用较小的学习率,提高稳定性,避免因学习率太大跳过最小值,保证能够收敛到最小值。
(3)迭代次数
迭代次数是指整个训练集输入到神经网络进行训练的次数,当测试错误率和训练错误率相差较小时,可认为当前迭代次数合适;当测试错误率先变小后变大时则说明迭代次数过大,需要减小迭代次数,否则容易出现过拟合。
(4)批次大小(batch size)
批次大小是每一次训练神经网络时送入模型的样本数。在神经网络优化过程中,batch size过小代表着每次输入网络的数据样本数过少,统计量不具有代表性,噪声也相应的增加,导致网络难以收敛;batch size过大,会使得梯度方向基本稳定,容易陷入局部最优解,降低精度。
(5)数据增强方法
数据增强也叫数据扩增,指在不实质性地增加数据的情况下,采用预设的数据变换规则,在已有数据的基础上进行数据的扩增,让有限的数据产生等价于更多数据的价值。常见的用于医学影像数据增强的算法有旋转、平移、剪裁、缩放和灰度变换等。适当的数据增强操作可为模型增加更多训练数据,提升模型泛化性能,避免模型过拟合;不当的数据增强会破坏原有数据的一致性,导致网络无法收敛,或收敛到一个非最佳值。
(6)anchor设置
Anchor字面意思是锚,在计算机视觉中是锚点或锚框的意思,目标检测中常出现的Anchor box是指锚框,表示固定的参考框。Anchor技术首先预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个anchor负责检测与其交并比(IOU)大于阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将目标检测任务转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远"。Anchor box尺寸、形状、密度、数量等参数的设置至关重要,针对具体的检测目标,要采用合适的尺寸、形状、密度、数量的anchor,一般由于目标的尺寸形状多变,经常会采用多种尺寸和形状的anchor,尺寸或形状设置不当的anchor会导致无法将目标包含在内或包含过多背景区域,密度或数量设置不当会导致无法准确定位目标位置或浪费计算资源。
常见的深度学习问题
一、欠拟合和过拟合
神经网络模型在训练时常出现欠拟合和过拟合的情况。欠拟合是一种不能很好地拟合数据的现象,通常由网络层数不够多、不够深造成,会导致网络训练的准确度不高,不能很好地非线性拟合数据进行分类。过拟合是一种过度拟合训练样本的现象,通常由网络层数过深或训练样本数过少导致模型训练时陷入极小值点造成,会导致网络缺失泛化能力,无法对训练样本之外的样本进行准确分类。
1、过拟合和欠拟合的定义
无论在机器学习还是深度学习建模当中都可能会遇到两种最常见结果,一种叫过拟合(over-fitting )另外一种叫欠拟合(under-fitting)。
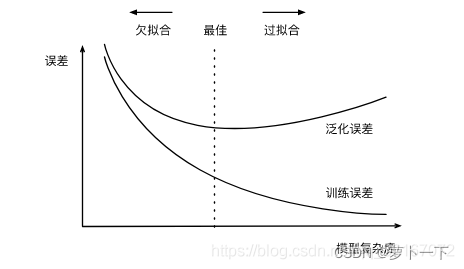
所谓过拟合(over-fitting)其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。如上图所示,即在训练过程中,在训练数据集上,训练误差较低,但是在验证集上,误差损失较大。也可以观察到,随着模型复杂度升高,过拟合情况越来越严重。
所谓欠拟合呢(under-fitting)?相对过拟合欠拟合还是比较容易理解。还是拿上图来说,可能模型复杂度不够,无法很好地拟合训练数据,导致训练和验证误差损失都比较大。
2、过拟合和欠拟合的解决方法
过拟合:根据上图可以得到,随着模型复杂度--模型参数--增高,过拟合的情况越来越严重,因此减少参数可以有效缓解过拟合。首先可以在损失函数里添加限制权重参数过大的正则项,在损失函数下降的过程中,使得权重参数逐渐趋向0(L2)甚至等于0(L1)。landa控制限制过拟合的程度。
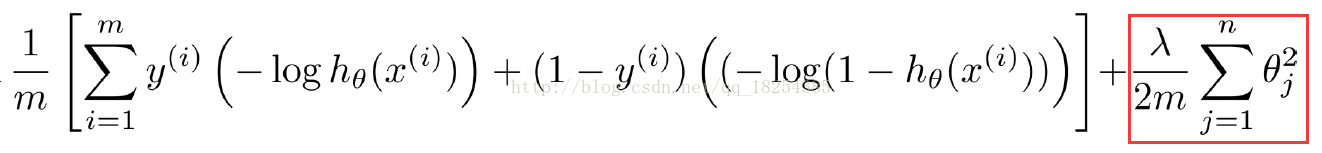
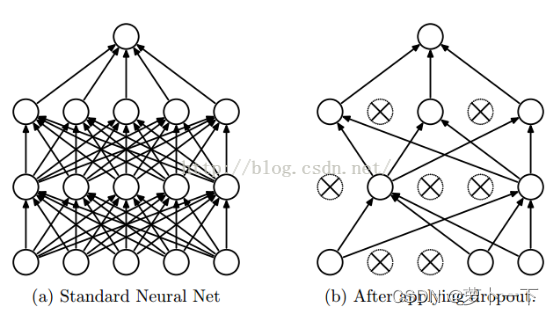
其次,可以在训练过程中随机失活部分神经元(参数)--某些参数不参与训练--减少训练参数,如下图所示。
再者,我们可以扩充数据集。当数据集较少时,可以采用K折交叉训练。 所谓K折交叉训练,即是将总的数据集分成K部分,每次选(K-1)为训练集,剩余的一部分为测试集,充分利用数据集。
最后,由图1可知,可以采用提前停止训练来防止过拟合。
欠拟合:其实个人觉得欠拟合基本上都会发生在训练刚开始的时候,经过不断训练之后欠拟合应该不怎么考虑了。但是如果真的还是存在的话,可以通过增加网络复杂度或者在模型中增加多点特征点,这些都是很好解决欠拟合的方法。而且在现实情况中,发生欠拟合的情况比较少。
二、梯度消失和梯度爆炸
层数较多的神经网络模型在训练时有时会出现梯度消失和梯度爆炸问题,梯度消失和梯度爆炸问题一般随着网络层数的增加会变得越来越明显。梯度消失和梯度爆炸问题本质上是由梯度反向传播过程中的连乘效应导致网络权值更新不稳定造成的,梯度消失和梯度爆炸都会导致网络模型训练的失败。
1、梯度消失和爆炸的定义
在介绍梯度消失以及爆炸之前,先简单说一说梯度消失和梯度爆炸的根源—–深度神经网络和反向传播。目前优化神经网络的方法都是基于反向传播的思想,即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化。这样做是有一定原因的,首先,深层网络由许多非线性层堆叠而来,每一层非线性层都可以视为是一个非线性函数 (非线性来自于非线性激活函数),因此整个深度网络可以视为是一个复合的非线性多元函数:
我们最终的目的是希望这个多元函数可以很好的完成输入到输出之间的映射,假设不同的输入,输出的最优解是 ,那么,优化深度网络就是为了寻找到合适的权值,满足
取得极小值点,对于这种数学寻找最小值问题,采用梯度下降的方法再适合不过了。
根据链式求导法则,可以知道梯度在从前往后传递的过程中,假如梯度小于1,则出现梯度消失,大于1,出现梯度爆炸。
2、梯度消失和爆炸的解决方法
(1)Batchnorm是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化保证网络的稳定性。batchnorm就是通过对每一层的输出规范为均值和方差一致的方法,消除了xxx带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
(2)选择合适的激活函数。
(3)残差结构。残差结构可以有效地防止梯度消失。因为短路链接可以无损的回传梯度,即使卷积线路梯度特别小,也可以保证梯度正常回传。

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)