
终于把深度学习中的知识蒸馏搞懂了!!
知识蒸馏是一种模型压缩技术,旨在将一个大规模的、性能较好的 “教师模型”(Teacher Model)所学到的知识迁移到一个小规模的 “学生模型”(Student Model)中,从而提高学生模型的性能,同时减少计算和存储需求。
知识蒸馏是一种模型压缩技术,旨在将一个大规模的、性能较好的 “教师模型”(Teacher Model)所学到的知识迁移到一个小规模的 “学生模型”(Student Model)中,从而提高学生模型的性能,同时减少计算和存储需求。
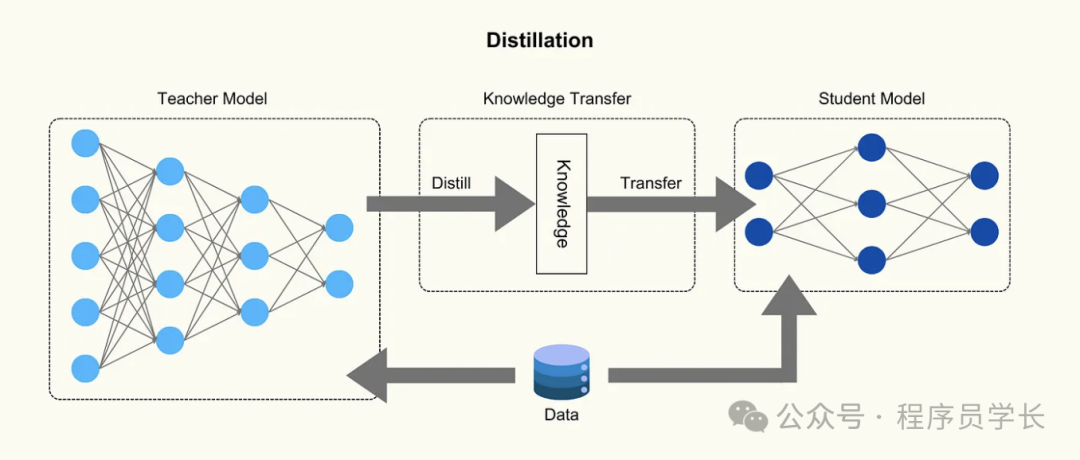
知识蒸馏的基本思想
知识蒸馏的核心思想是让学生模型(小模型)学习教师模型(大模型)的输出(软目标,Soft Targets),而不仅仅是传统的硬标签(Hard Labels)。软目标提供了关于样本的额外信息,例如类别之间的相关性和不确定性,从而提高学生模型的泛化能力。
教师模型的软目标(Soft Targets)
教师模型的输出通常是一个概率分布,其中每个类别的概率值反映了该类别的相对置信度。与硬标签(hard target,通常是一个one-hot向量)不同,软标签包含了类别之间的相似性信息。
-
硬标签
硬标签是指传统的标签形式,如图像分类任务中,给定一张图片,它的硬标签可能是 [0, 0, 1, 0],表示图像属于类别 2。
-
软标签
软标签是通过教师模型的输出获得的概率分布。
例如,在图像分类中,教师模型的输出可能是 [0.05, 0.1, 0.7, 0.15],表示该图像属于类别 2 的概率为 0.7。
软标签携带了更多的信息,比硬标签更细致。
对于学生模型来说,学习这些软标签能够帮助其在学习过程中获取更多的知识。
知识蒸馏的主要步骤
知识蒸馏通常包括以下几个步骤。
-
训练教师模型(Teacher Model)
首先,训练一个大型的、性能较优的教师模型。
教师模型通常是一个深度神经网络,如BERT、Transformer 等
-
生成软标签(Soft Targets)
使用训练好的教师模型对训练数据进行预测,获得每个样本的概率分布。
这些概率分布作为软标签,包含了类别之间的相对关系信息。
-
训练学生模型(Student Model)
学生模型是一个较小的神经网络,相比于教师模型,它有较少的参数和计算量。
训练学生模型时,不仅利用数据的真实标签(Hard Labels),还利用教师模型提供的软标签,以提高学生模型的学习能力。
知识蒸馏的损失函数
知识蒸馏的关键在于蒸馏损失(Distillation Loss),它由交叉熵损失(Cross-Entropy Loss)和 Kullback-Leibler 散度(KL 散度)共同作用。
软标签(Soft Targets)
在普通的分类任务中,模型输出的类别概率是通过 Softmax 函数计算得到的。
其中:
-
是模型对类别 i 的预测得分(logits)。
-
是最终的概率。
在知识蒸馏中,引入了温度参数 T 来调整 Softmax 计算,使类别间的概率分布更加平滑,从而保留更多的知识信息。
其中
-
是带有温度 的 Softmax 输出。
-
当 时,类别间的概率差异缩小,使模型关注更多的长尾信息(即低概率类别)。
-
时,分布趋近于原始 Softmax 计算。
蒸馏损失
学生模型的损失由两部分组成
-
真实标签的交叉熵损失(Hard Label Loss)
其中:
-
是真实标签
-
是学生模型的预测概率
-
-
KL 散度损失(蒸馏损失)
用于衡量教师模型的软标签分布与学生模型输出分布的相似性。
其中:
注意,软标签损失乘上了 ,用于平衡温度因子对梯度的影响。
-
是教师模型的带温度的 Softmax 输出。
-
是学生模型的带温度的 Softmax 输出。
-
组合损失
最终的知识蒸馏损失是两者的加权和:
其中 是一个超参数,用于调整交叉熵损失和蒸馏损失的权重。
知识蒸馏的变种
知识蒸馏技术被广泛应用,之后研究人员提出了多种改进和变种。
-
自蒸馏:让同一个模型不同训练阶段之间进行蒸馏。
-
多教师蒸馏:使用多个教师模型来为学生模型提供更丰富的知识。
-
特征蒸馏:不仅让学生学习最终的输出概率分布,还学习中间层特征。
知识蒸馏的优势
-
模型压缩
通过蒸馏,学生模型在较少的参数量下,依然可以获得接近或甚至相当于教师模型的性能。
-
加速推理
小型的学生模型在推理时通常比大型教师模型更快,适用于资源有限的环境,如移动端、嵌入式设备等。
-
改善泛化能力
学生模型通过学习教师模型的软标签,能够获得更多类别之间的关系信息,提升其泛化能力。
案例分享
下面是一个知识蒸馏的完整示例代码。
首先,构建教师模型
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 设置设备(CUDA 优先)
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载 MNIST 数据集
train_dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root="./data", train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 定义教师模型(大模型)
class TeacherModel(nn.Module):
def __init__(self):
super(TeacherModel, self).__init__()
self.fc1 = nn.Linear(28 * 28, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) # 这里不加 softmax,PyTorch 的 CrossEntropyLoss 里包含 softmax
return x
构建学生模型
class StudentModel(nn.Module):
def __init__(self):
super(StudentModel, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
定义蒸馏损失函数
def distillation_loss(student_logits, teacher_logits, labels, T=3.0, alpha=0.5):
"""
计算知识蒸馏损失:
- 真实标签的交叉熵损失(Hard Labels)
- 软标签的交叉熵损失(Soft Labels)
"""
hard_loss = F.cross_entropy(student_logits, labels) # 硬标签损失
soft_targets = F.softmax(teacher_logits / T, dim=1) # 计算教师的温度 softmax
soft_loss = F.kl_div(F.log_softmax(student_logits / T, dim=1), soft_targets, reduction="batchmean") * (T**2)
return alpha * hard_loss + (1 - alpha) * soft_loss
训练教师模型
def train_teacher(model, train_loader, epochs=5, lr=0.01):
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(epochs):
model.train()
total_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
logits = model(images)
loss = loss_fn(logits, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss / len(train_loader):.4f}")
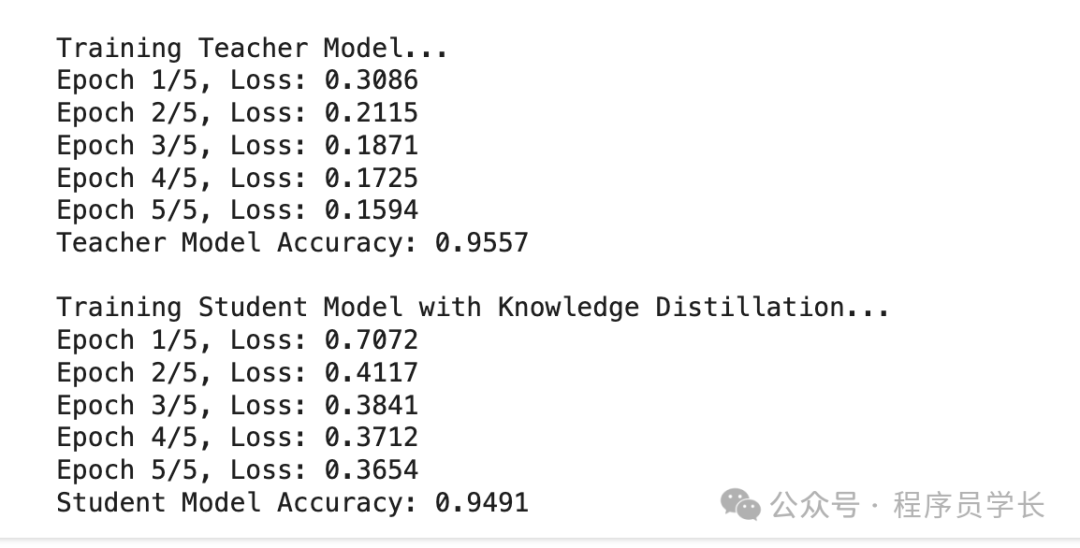
print("Training Teacher Model...")
teacher_model = TeacherModel()
train_teacher(teacher_model, train_loader, epochs=5)
用知识蒸馏训练学生模型
def train_student(student_model, teacher_model, train_loader, epochs=5, lr=0.01, T=3.0, alpha=0.5):
student_model.to(device)
teacher_model.to(device)
teacher_model.eval() # 固定教师模型
optimizer = optim.Adam(student_model.parameters(), lr=lr)
for epoch in range(epochs):
student_model.train()
total_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
# 获取学生和教师的 logits
student_logits = student_model(images)
with torch.no_grad():
teacher_logits = teacher_model(images)
# 计算知识蒸馏损失
loss = distillation_loss(student_logits, teacher_logits, labels, T=T, alpha=alpha)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss / len(train_loader):.4f}")
print("\nTraining Student Model with Knowledge Distillation...")
student_model = StudentModel()
train_student(student_model, teacher_model, train_loader, epochs=5, T=3.0, alpha=0.5)
对比学生模型和教师模型的准确率
def evaluate(model, test_loader):
model.to(device)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
predictions = outputs.argmax(dim=1)
correct += (predictions == labels).sum().item()
total += labels.size(0)
accuracy = correct / total
return accuracy
# 评估教师模型
teacher_acc = evaluate(teacher_model, test_loader)
print(f"Teacher Model Accuracy: {teacher_acc:.4f}")
# 评估学生模型
student_acc = evaluate(student_model, test_loader)
print(f"Student Model Accuracy: {student_acc:.4f}")

一站式 AI 云服务平台
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)