
毕设-基于深度学习的智能聊天机器人(含源码)
随着深度学习在自然语言处理领域的飞速发展,国内外针对于文本分析、信息检索、词性标注和问答系统等技术的研究已经愈发成熟。尤其是聊天机器人技术,正伴随着便携移动设备市场的拓展走向成熟,在客服、金融、医疗、教育和生活服务等方面应用广泛。由于基于中文语料的聊天机器人具有开放式交互的优良特点,该技术将会极大的改善人们的生活方式,成为新时代的科技增长点。本文主要基于深度学习的Seq2Seq模型对构建的语料库做
随着深度学习在自然语言处理领域的飞速发展,国内外针对于文本分析、信息检索、词性标注和问答系统等技术的研究已经愈发成熟。尤其是聊天机器人技术,正伴随着便携移动设备市场的拓展走向成熟,在客服、金融、医疗、教育和生活服务等方面应用广泛。由于基于中文语料的聊天机器人具有开放式交互的优良特点,该技术将会极大的改善人们的生活方式,成为新时代的科技增长点。本文主要基于深度学习的Seq2Seq模型对构建的语料库做词向量转换和模型训练得到智能聊天机器人系统。
一、模型分析
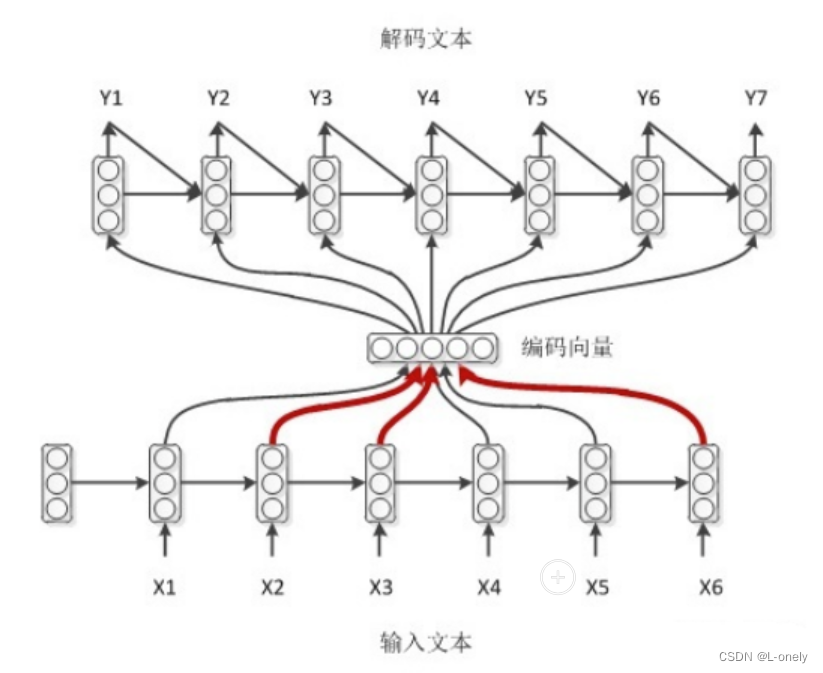
seq2seq属于encoder-decoder结构的一种,这里看看常见encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码。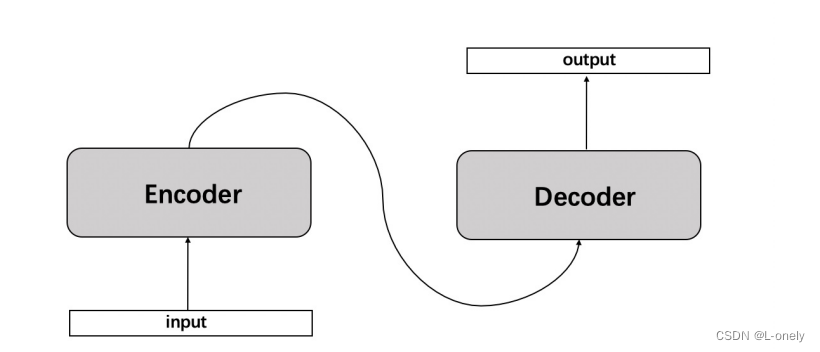
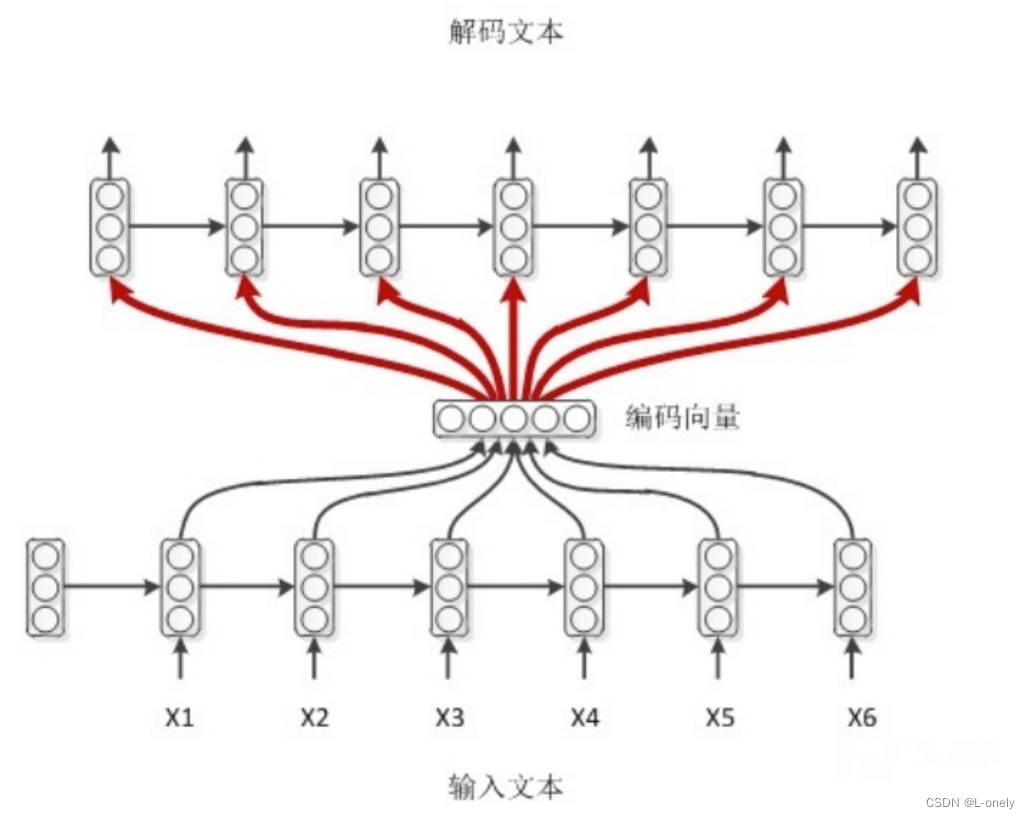
输入 x 通过encoder编码,即RNN结构(这里以RNN结构为例,但不仅限于RNN结构)通过隐藏状态,h1,h2......ht的不断传播,在传播过程中同时会产生输出 y1,y2......yt,后形成编码向量[y1,y2......yt]在解码过程中编码向量每一步都会输入给decoder。
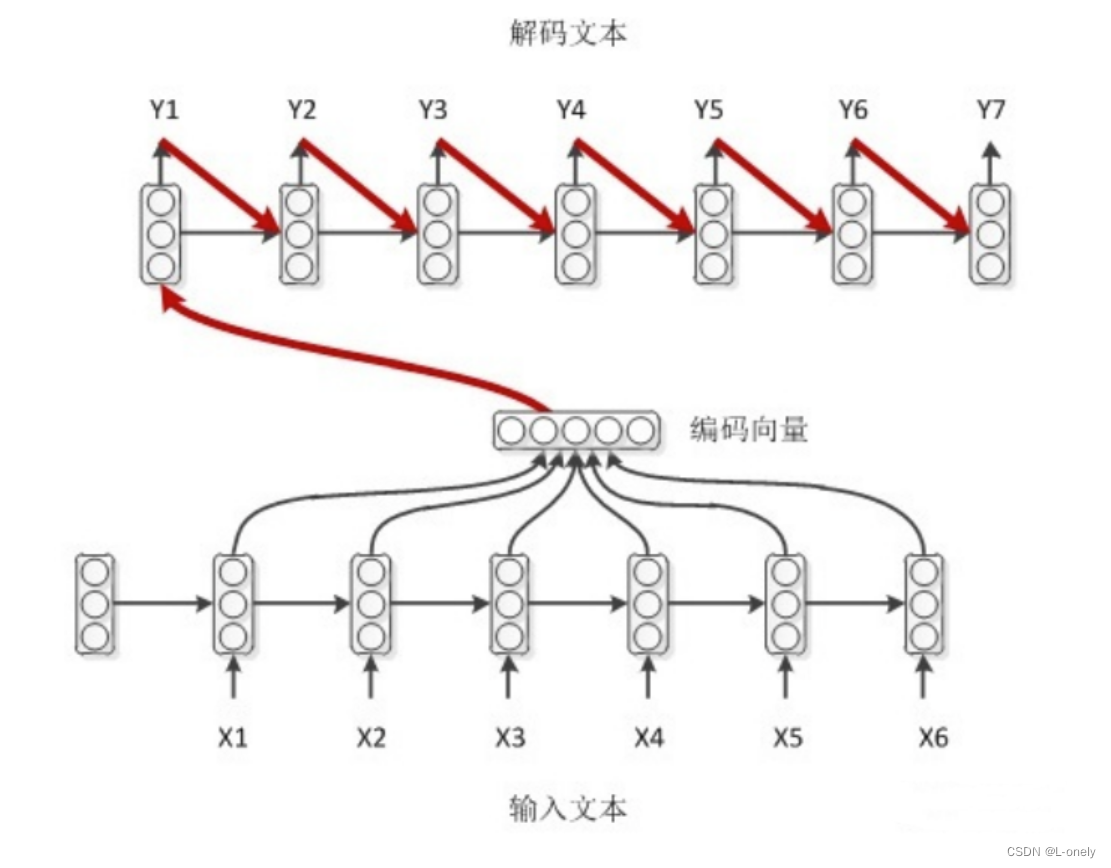
如果decoder同样也是个RNN结构的话,那么可以利用上一时刻的输出来帮助预测。encoder的编码赋值给了decoder的初始hidden。decoder的初始标签是<SOS>特色的开始标签,对应着词表中这个标签的embedding。
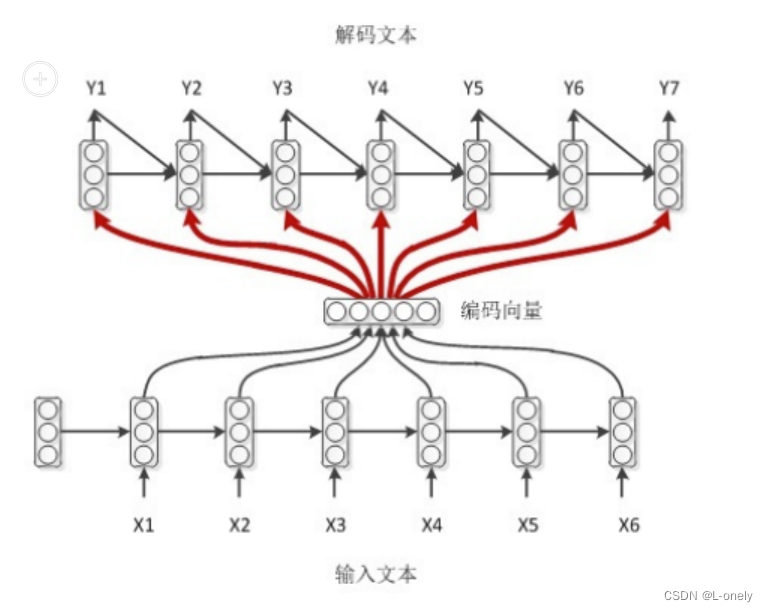
结合了前两种模式,decoder每一时刻的输入不仅有来自encoder的编码向量,还有上一时刻的输出,同时还有上一时刻的hidden。
带有attention机制的编解码,encoder的RNN每一步都有一个输出 hi ,给每一个 hi一个权重,计算带权求和的向量。这样做的好处是,每预测一个词都和原文本的部分最相关。
二、实现思路
- 获取数据集
- 将数据集中的文本数据分词
- 把对话分成问和答两个部分
- 构造Dataset
- 搭建Seq2seq模型
- 训练模型
- 模型测试
- 基于Falsk实现部署和可视化
三、详细实现
1.解压小黄鸡语料数据集后,对数据集整理并使用jieba分词得到对应的问和答两个部分

2.构造对应的Dataset,并使用TensorFlow2.0搭建Seq2seq网络模型
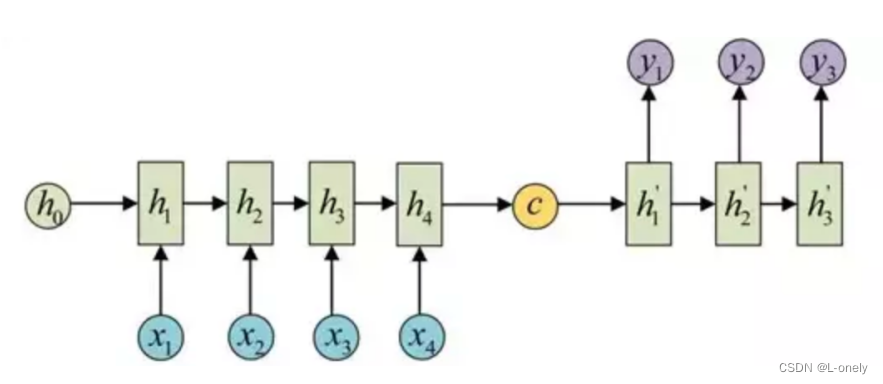
通过输入数据encode得到分词的向量,将得到的向量作为下一个输出得到相关的序列
3.通过加载预训练的模型进行训练
4.对训练得到的模型进行预测,通过预测结果调整相关参数并优化模型
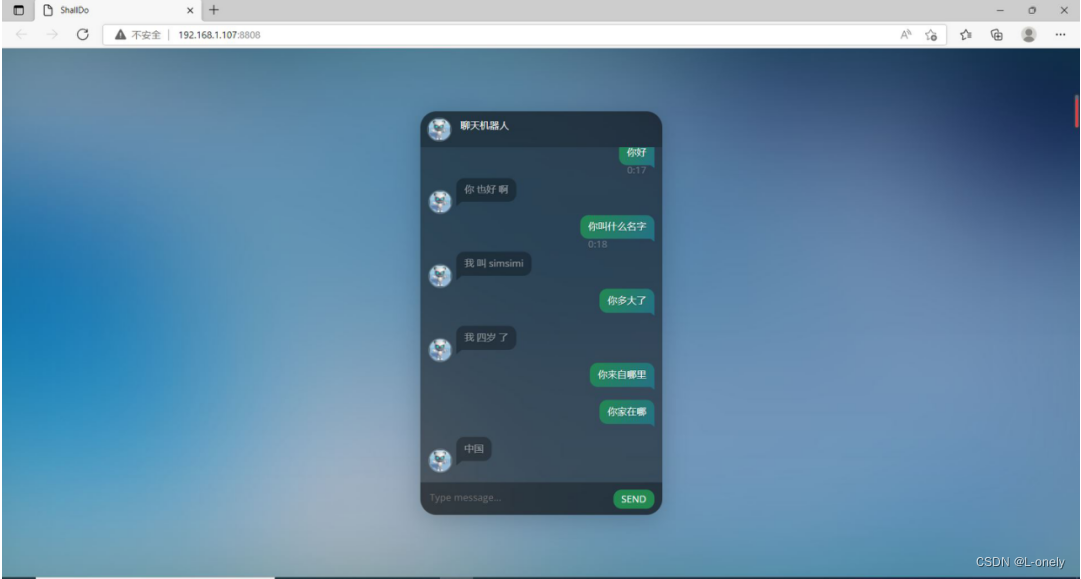
5.通过python的flask框架搭建一个聊天平台
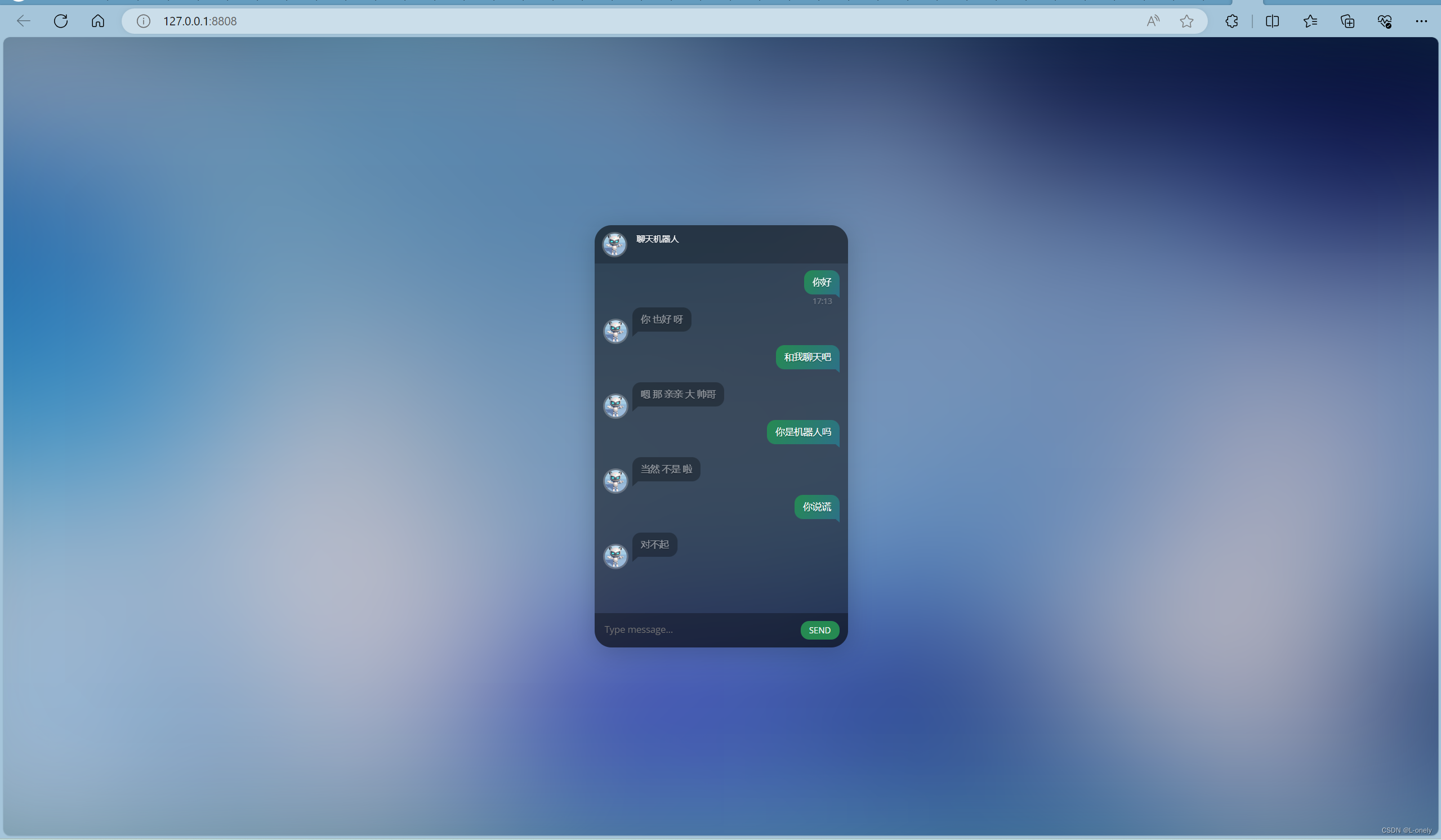
源码私可分享

一站式 AI 云服务平台
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)