
深度学习_图像分割_图像数据可视化分析全流程(EDA)(以钢铁缺陷图像为例)
一.导入相应的Modules下面的代码只是举个例子:import numpy as np # linear algebraimport pandas as pdpd.set_option("display.max_rows", 101)import osprint(os.listdir("../input"))import cv2import jsonimport matplot...
·
一.导入相应的Modules
下面的代码只是举个例子:
import numpy as np # linear algebra
import pandas as pd
pd.set_option("display.max_rows", 101)
import os
print(os.listdir("../input"))
import cv2
import json
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams["font.size"] = 15
import seaborn as sns
from collections import Counter
from PIL import Image
import math
import seaborn as sns
from collections import defaultdict
from pathlib import Path
import cv2
from tqdm import tqdm
2.阅读了解所有的数据文件
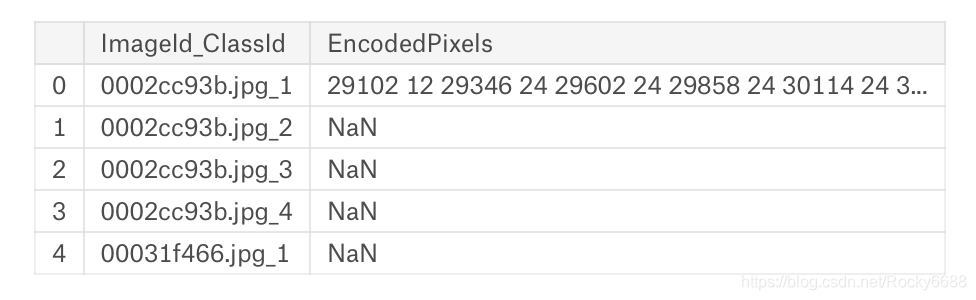
train_df = pd.read_csv("../input/train.csv")
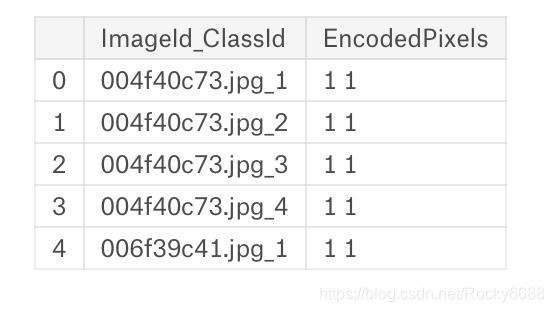
sample_df = pd.read_csv("../input/sample_submission.csv")
train_df.head()
sample_df.head()
三.图片数据缺陷分析
首先,我们看看有缺陷的图片和无缺陷的图片各有几张:
class_dict = defaultdict(int)
kind_class_dict = defaultdict(int)
no_defects_num = 0
defects_num = 0
for col in range(0, len(train_df), 4):
img_names = [str(i).split("_")[0] for i in train_df.iloc[col:col+4, 0].values]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
labels = train_df.iloc[col:col+4, 1]
if labels.isna().all():
no_defects_num += 1
else:
defects_num += 1
kind_class_dict[sum(labels.isna().values == False)] += 1
for idx, label in enumerate(labels.isna().values.tolist()):
if label == False:
class_dict[idx+1] += 1
print("the number of images with no defects: {}".format(no_defects_num))
print("the number of images with defects: {}".format(defects_num))

我们发现有缺陷的图片由6666张,但是无缺陷的图片也很多。
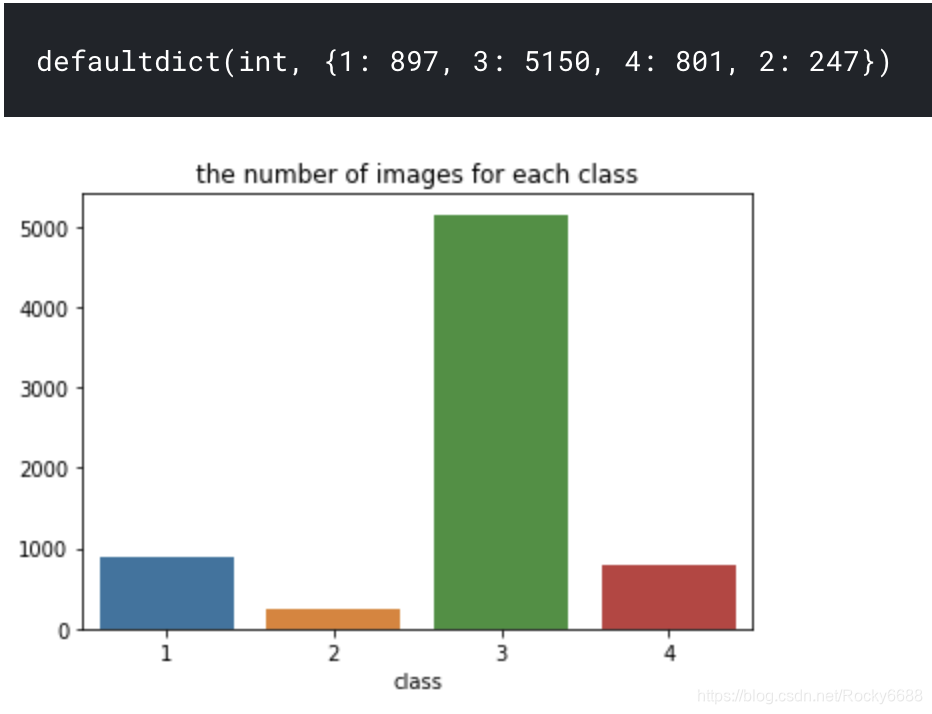
接下来,我们再看看各个缺陷的图片各有几张:
fig, ax = plt.subplots()
sns.barplot(x=list(class_dict.keys()), y=list(class_dict.values()), ax=ax)
ax.set_title("the number of images for each class")
ax.set_xlabel("class")
class_dict
我们总结一下:
- 有缺陷的图片和无缺陷的图片数量相差不大。
- 各个类别的样本分布不均衡。
那么一张图片上会有几种缺陷呢?
fig, ax = plt.subplots()
sns.barplot(x=list(kind_class_dict.keys()), y=list(kind_class_dict.values()), ax=ax)
ax.set_title("Number of classes included in each image");
ax.set_xlabel("number of classes in the image")
kind_class_dict
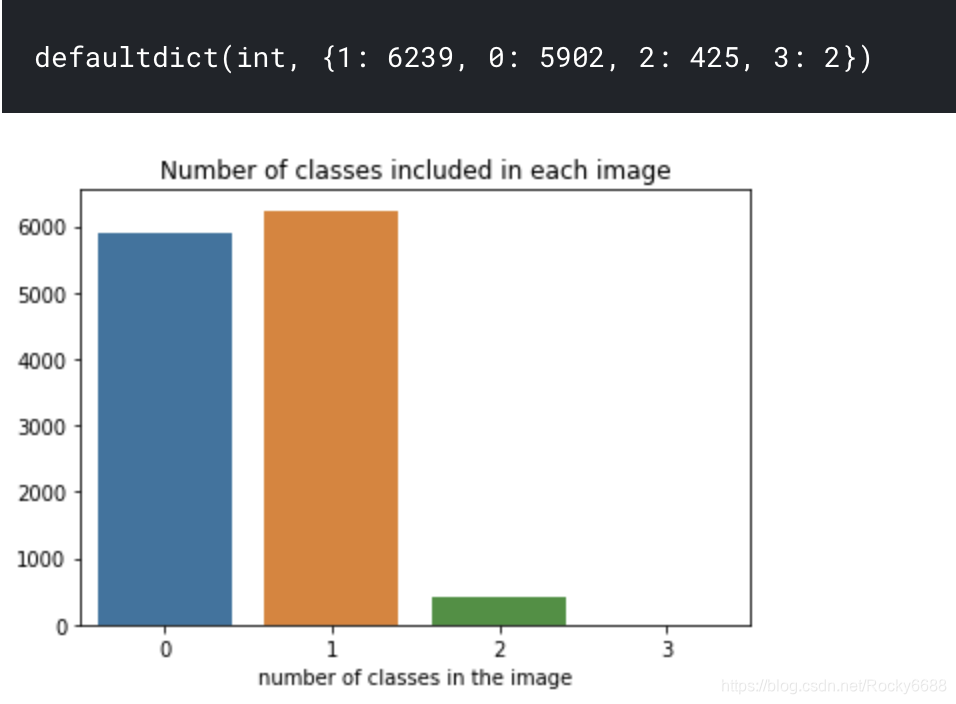
总结一下:这还是一个多标签数据。
四.图片可视化
首先我们来看看训练集图片的大小:
train_size_dict = defaultdict(int)
train_path = Path("../input/train_images/")
for img_name in train_path.iterdir():
img = Image.open(img_name)
train_size_dict[img.size] += 1
train_size_dict

结合我们看看测试集图片的大小:
test_size_dict = defaultdict(int)
test_path = Path("../input/test_images/")
for img_name in test_path.iterdir():
img = Image.open(img_name)
test_size_dict[img.size] += 1
test_size_dict

总结一下:
- 所有的图片都是一样的大小:(1600 * 256)
- 训练集和测试集的比例约为7:1
接下来我们尽心图片可视化分析:
palet = [(249, 192, 12), (0, 185, 241), (114, 0, 218), (249,50,12)]
def name_and_mask(start_idx):
col = start_idx
img_names = [str(i).split("_")[0] for i in train_df.iloc[col:col+4, 0].values]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
labels = train_df.iloc[col:col+4, 1]
mask = np.zeros((256, 1600, 4), dtype=np.uint8)
for idx, label in enumerate(labels.values):
if label is not np.nan:
mask_label = np.zeros(1600*256, dtype=np.uint8)
label = label.split(" ")
positions = map(int, label[0::2])
length = map(int, label[1::2])
for pos, le in zip(positions, length):
mask_label[pos-1:pos+le-1] = 1
mask[:, :, idx] = mask_label.reshape(256, 1600, order='F')
return img_names[0], mask
def show_mask_image(col):
name, mask = name_and_mask(col)
img = cv2.imread(str(train_path / name))
fig, ax = plt.subplots(figsize=(15, 15))
for ch in range(4):
contours, _ = cv2.findContours(mask[:, :, ch], cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE)
for i in range(0, len(contours)):
cv2.polylines(img, contours[i], True, palet[ch], 2)
ax.set_title(name)
ax.imshow(img)
plt.show()
fig, ax = plt.subplots(1, 4, figsize=(15, 5))
for i in range(4):
ax[i].axis('off')
ax[i].imshow(np.ones((50, 50, 3), dtype=np.uint8) * palet[i])
ax[i].set_title("class color: {}".format(i+1))
fig.suptitle("each class colors")
plt.show()

我们将不同的类别用不同的颜色表示。
首先我们看看没有缺陷的图片:
idx_no_defect = []
idx_class_1 = []
idx_class_2 = []
idx_class_3 = []
idx_class_4 = []
idx_class_multi = []
idx_class_triple = []
for col in range(0, len(train_df), 4):
img_names = [str(i).split("_")[0] for i in train_df.iloc[col:col+4, 0].values]
if not (img_names[0] == img_names[1] == img_names[2] == img_names[3]):
raise ValueError
labels = train_df.iloc[col:col+4, 1]
if labels.isna().all():
idx_no_defect.append(col)
elif (labels.isna() == [False, True, True, True]).all():
idx_class_1.append(col)
elif (labels.isna() == [True, False, True, True]).all():
idx_class_2.append(col)
elif (labels.isna() == [True, True, False, True]).all():
idx_class_3.append(col)
elif (labels.isna() == [True, True, True, False]).all():
idx_class_4.append(col)
elif labels.isna().sum() == 1:
idx_class_triple.append(col)
else:
idx_class_multi.append(col)
for idx in idx_no_defect[:5]:
show_mask_image(idx)


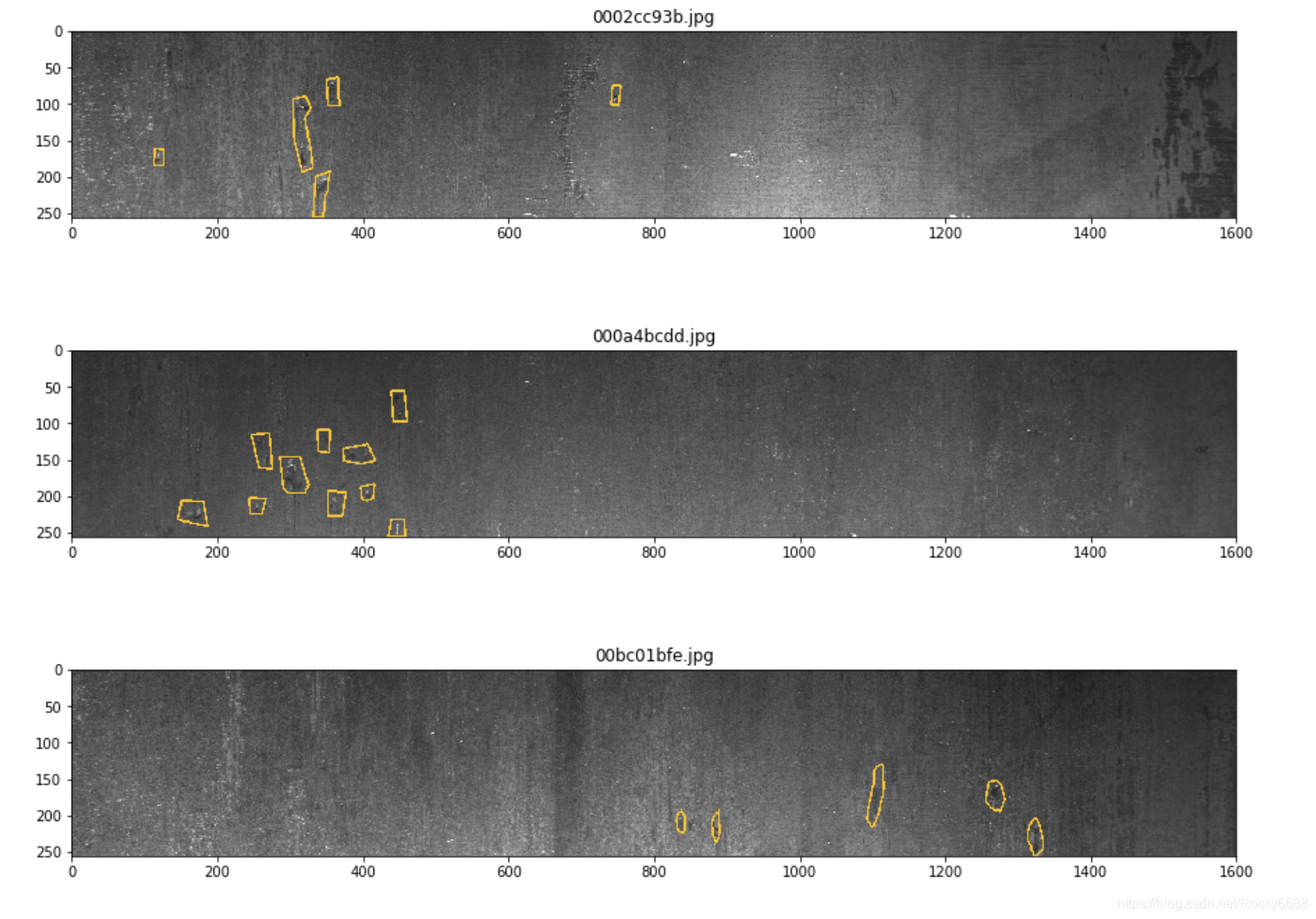
第一种缺陷类别:
for idx in idx_class_1[:5]:
show_mask_image(idx)
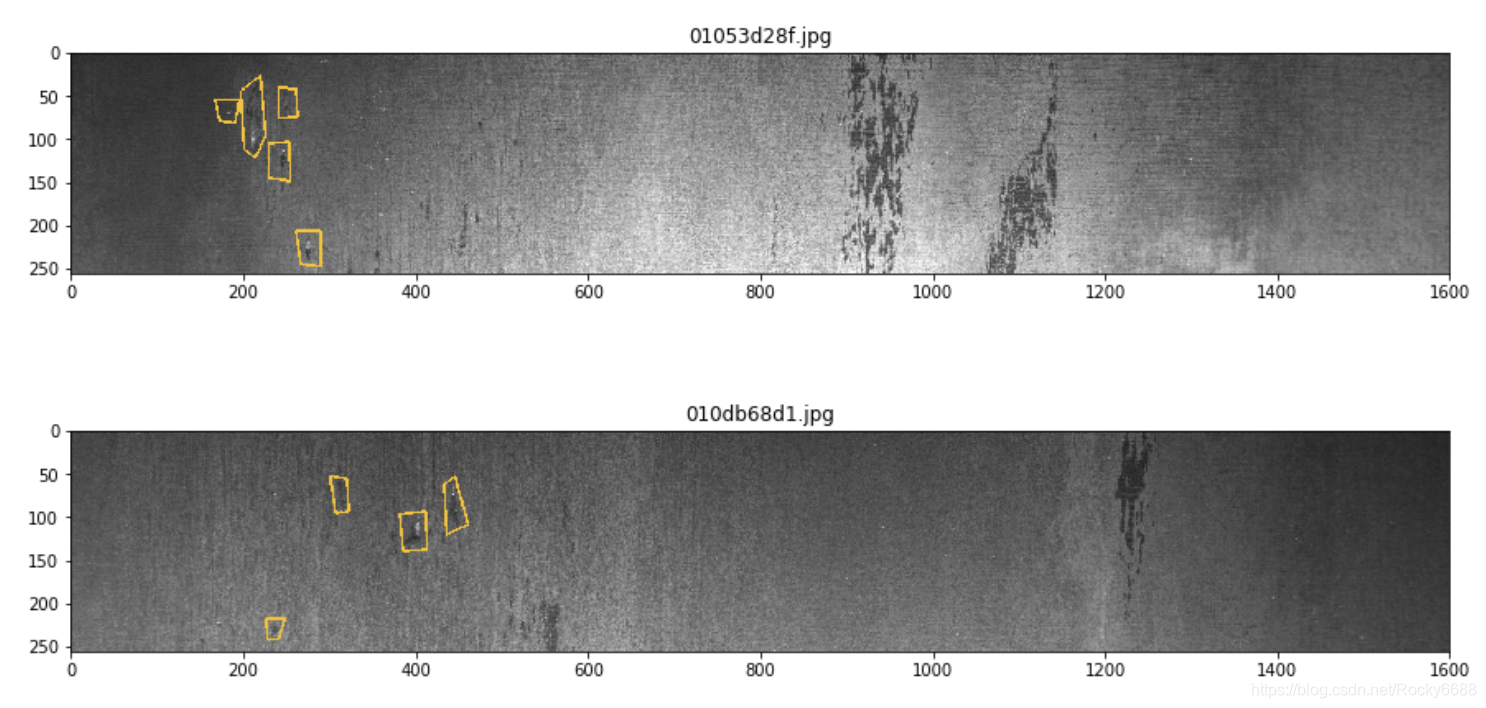
第二种缺陷类别:
for idx in idx_class_2[:5]:
show_mask_image(idx)
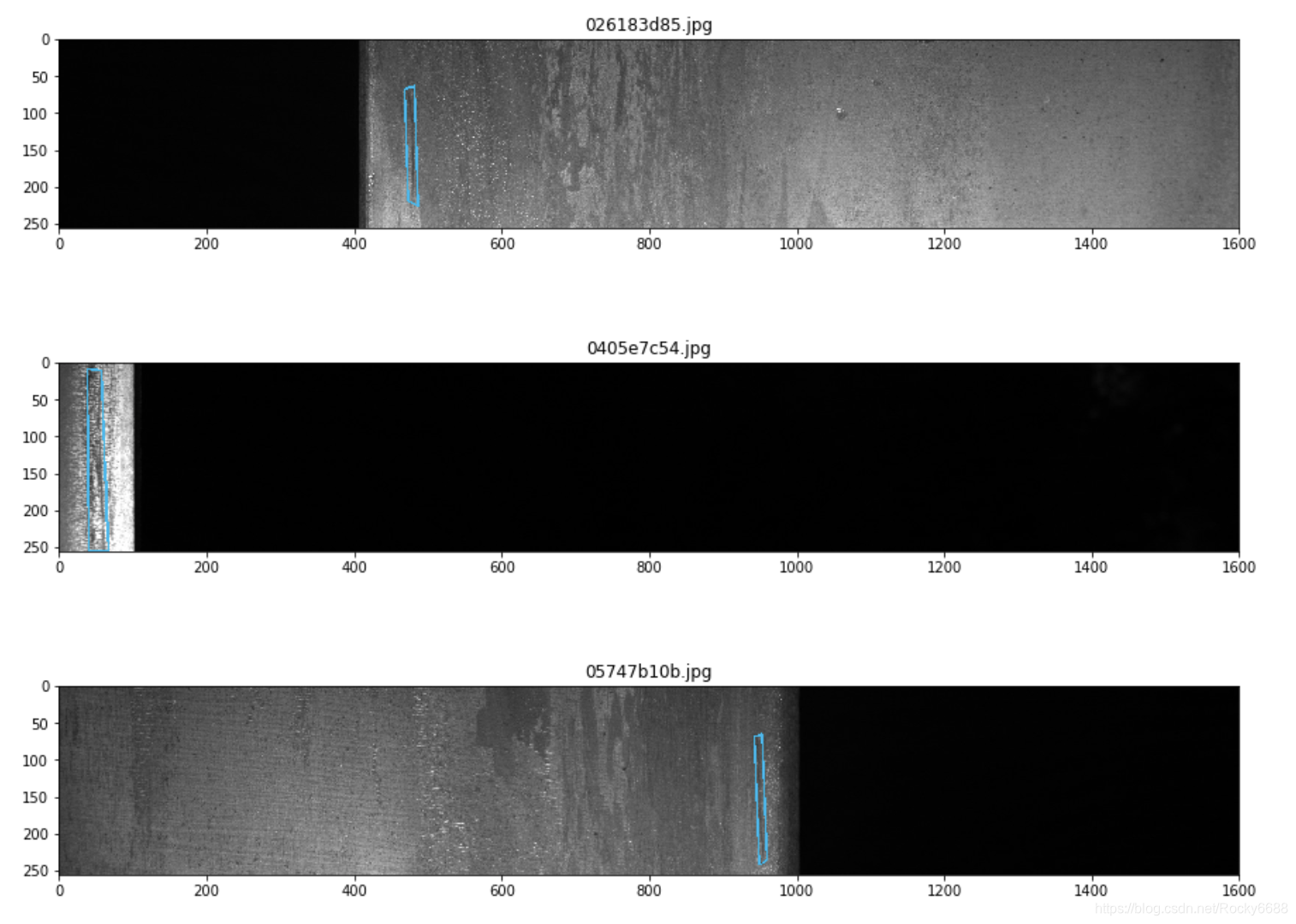

第三种缺陷类别:
for idx in idx_class_3[:5]:
show_mask_image(idx)
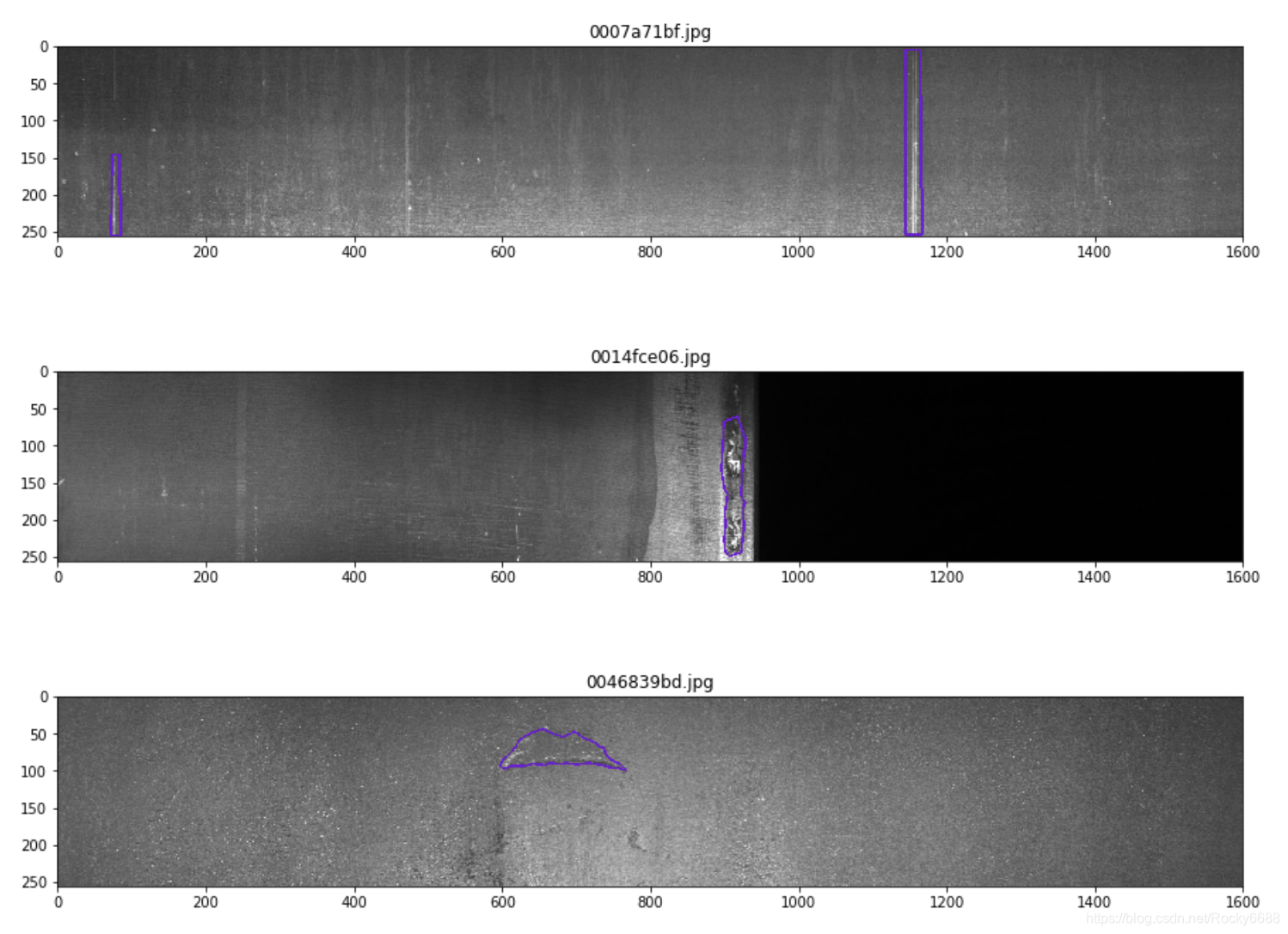

第四种缺陷类别:
for idx in idx_class_4[:5]:
show_mask_image(idx)


含有两种缺陷类别:
for idx in idx_class_multi[:5]:
show_mask_image(idx)
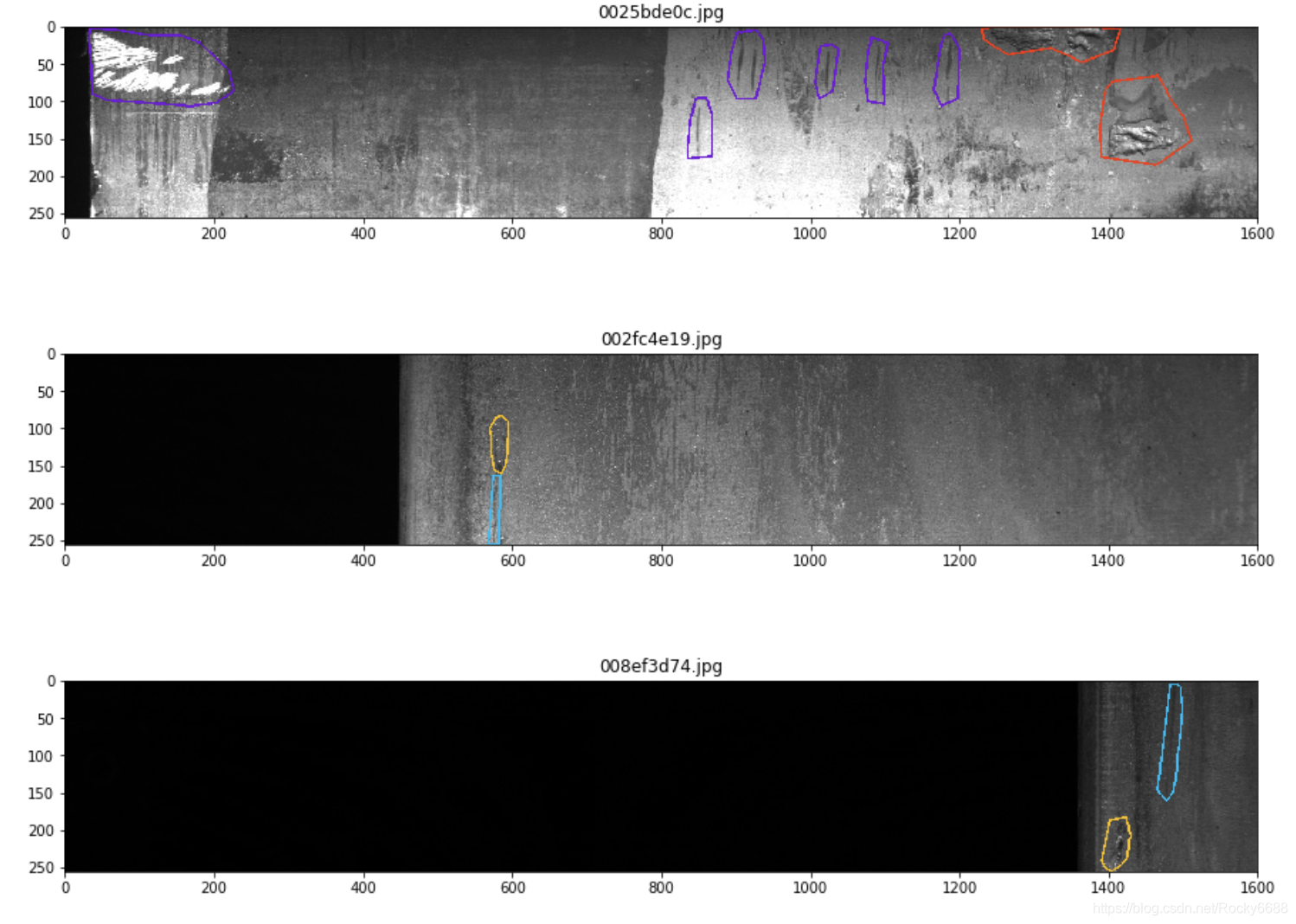
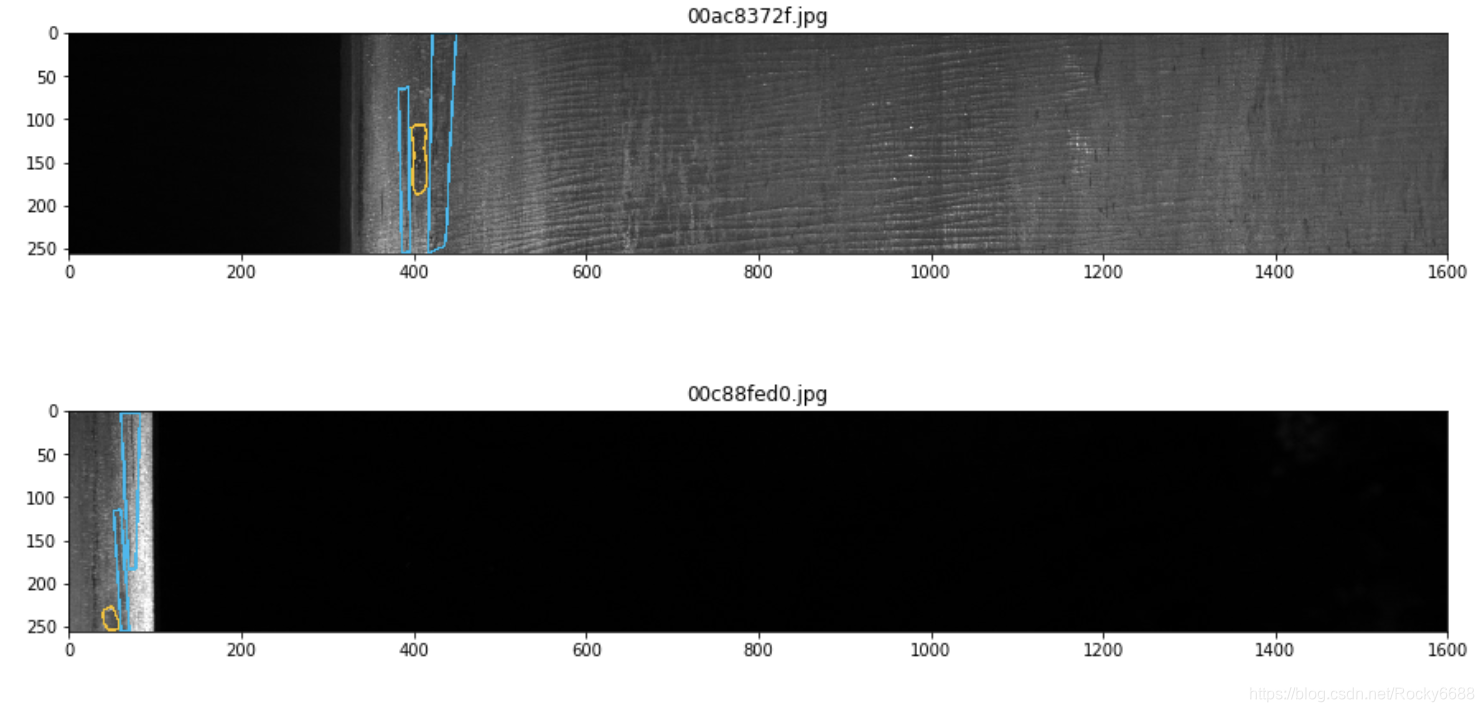
含有三种类别缺陷:
for idx in idx_class_triple:
show_mask_image(idx)
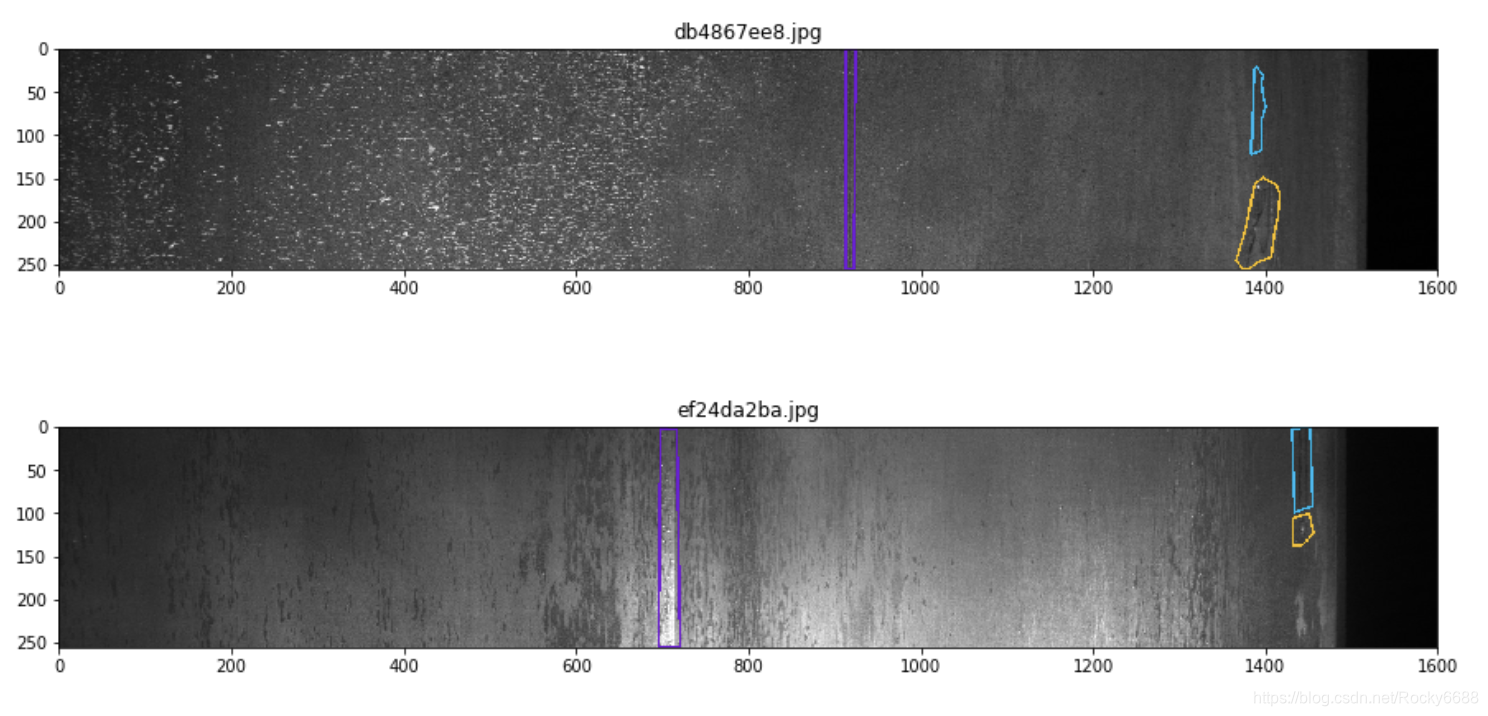
最后我们来看一下每张图片是否每个像素都有标注:
for col in tqdm(range(0, len(train_df), 4)):
name, mask = name_and_mask(col)
if (mask.sum(axis=2) >= 2).any():
show_mask_image(col)

确实,每个像素都有标注。

一站式 AI 云服务平台
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)