
如何利用大模型进行孟德尔随机化研究
在进行此类研究时,应遵循科学研究的伦理原则,确保数据的隐私和安全,并获取适当的伦理批准。同时,应考虑到数据的代表性,避免偏见,并确保研究结果的透明度和可重复性。遗传数据:获取相关遗传变异的GWAS(全基因组关联研究)数据,这些数据通常来自大型生物数据库,如UK Biobank。因果估计:应用大模型进行因果估计,例如,使用深度学习模型来估计遗传暴露与结局之间的关联,同时控制可能的混杂因素。利用大模型
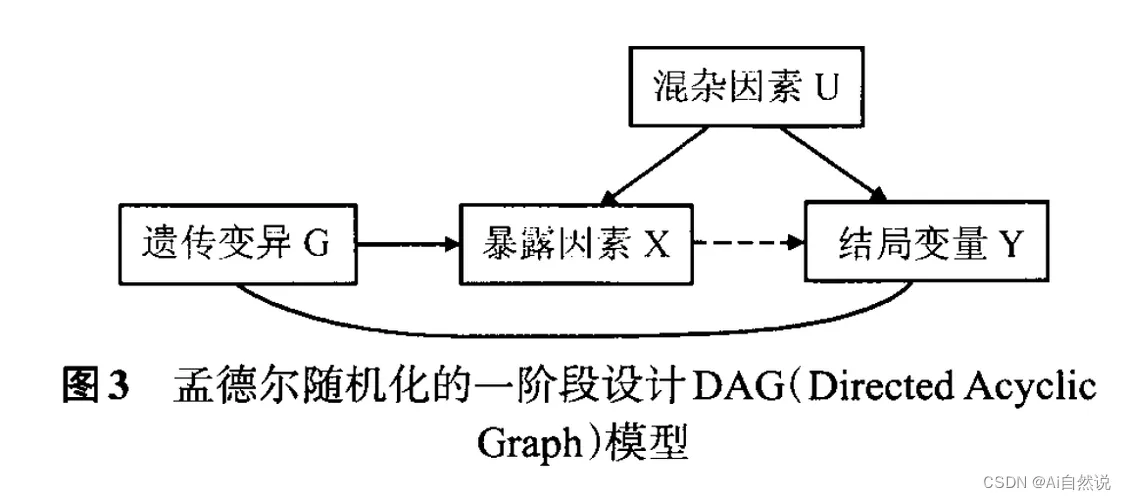
孟德尔随机化(Mendelian Randomization, MR)是一种利用遗传变异作为工具变量,来研究某一暴露因素(如血清胆固醇水平)与某一结局(如心血管疾病风险)之间因果关系的分析方法。大模型,如大型神经网络,在处理和分析大数据方面的能力为孟德尔随机化研究提供了新的可能性。以下是如何利用大模型进行孟德尔随机化研究的一些步骤和考虑因素:
1. 数据收集与预处理:
遗传数据:获取相关遗传变异的GWAS(全基因组关联研究)数据,这些数据通常来自大型生物数据库,如UK Biobank。
暴露数据:收集与感兴趣暴露相关的数据,这可能包括医疗记录、生命体征、实验室检测结果等。
结局数据:收集与感兴趣结局相关的数据,例如疾病诊断、生存数据等。
协变量数据:可能需要收集其他协变量数据,如年龄、性别、种族等,以控制混杂因素。
2. 遗传暴露评分(Genetic Risk Score, GRS):
使用大模型来计算个体的遗传暴露评分,这通常涉及到对多个遗传变异进行加权并求和。
3. 数据整合与处理:
利用大模型处理和整合不同来源和格式的数据,确保数据的一致性和可比性。
应用大模型进行缺失数据插补、异常值检测和处理等数据清洗步骤。
4. 孟德尔随机化分析:
工具变量选择:利用大模型选择与暴露因素相关的遗传变异作为工具变量。
因果估计:应用大模型进行因果估计,例如,使用深度学习模型来估计遗传暴露与结局之间的关联,同时控制可能的混杂因素。
5. 结果解释与验证:
解释模型的结果,并考虑可能的混杂和反向因果关系。
进行敏感性分析,例如,检查工具变量的有效性假设是否满足。
如果可能,使用独立的数据集对结果进行外部验证。
6. 报告与共享:
详细报告研究方法、分析过程和结果。
考虑共享分析代码和模型,以便其他研究者能够复制和验证研究结果。
在进行此类研究时,应遵循科学研究的伦理原则,确保数据的隐私和安全,并获取适当的伦理批准。同时,应考虑到数据的代表性,避免偏见,并确保研究结果的透明度和可重复性。在中国,这样的研究还应符合国家有关数据管理和隐私保护的法律法规。
作者个人简介:
💐大厂多年AI算法经验,创业中,兼任算法/产品/工程
🍎持续分享aigc干货
❤️提供人工智能相关岗位简历优化和技能辅导服务,欢迎骚扰。
💐提供几匹提4成品账号售卖和几匹提4账号代充服务
🌺提供aigc产品推广服务
微信公众号:
Ai自然说
个人微信:

这是我的个人微信,欢迎添加,找我讨论AI相关的内容。
微信群:
攒了一个微信群,大家可以在里面讨论AI相关的技术、产品、运营、商业知识和资讯,欢迎扫码加入。
知识星球:

运营了一个知识星球,我在里面会定期分享一些关于ai的高质量干货,欢迎扫码加入。

一站式 AI 云服务平台
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)