
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
SIMVLM:基于弱监督的简单视觉语言模型预训练《SIMVLM:Simple Visual Language Model Pre-training with Weak Supervision》论文地址:https://arxiv.org/pdf/2108.10904.pdf?ref=https://githubhelp.com一、简介基于Transformer\text{Transformer}
论文地址:https://arxiv.org/pdf/2108.10904.pdf?ref=https://githubhelp.com
相关博客:
【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习
【自然语言处理】【多模态】VinVL:回顾视觉语言模型中的视觉表示
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
【自然语言处理】【多模态】Zero&R2D2:大规模中文跨模态基准和视觉语言框架
一、简介
基于 Transformer \text{Transformer} Transformer的自监督文本表示学习已经在广泛的 NLP \text{NLP} NLP任务上取得了state-of-the-art。成功的方法是应用masked language modeling(MLM)目标函数在大规模无标注文本语料上先预训练模型,然后在下游任务上进行微调。这种预训练-微调范式被广泛使用,近期像 GPT-3 \text{GPT-3} GPT-3这样的自回归语言模型 LM \text{LM} LM展示了不使用微调,仅利用few-shot prompt就能有很好的表现,表明了文本指导的zero-shot泛化是很有前途的。
受文本表示预训练成功的启发,各种工作已经应用在多模态上。一系列工作已经探索了视觉语言预训练 (VLP,vison-language pretraining) \text{(VLP,vison-language pretraining)} (VLP,vison-language pretraining),其联合学习两种模态的表示并在视觉语言( VL,vision-language \text{VL,vision-language} VL,vision-language)基准上进行微调。为了能够捕获图像和文本间的对齐信息,先前的方法从多个源中广泛的利用两种类型的人工标注数据,其通常由下列的步骤组成。首先,目前检测数据集被用来训练有监督目标检测器,其能够从图像中进一步抽取 ROI(region-of-interest) \text{ROI(region-of-interest)} ROI(region-of-interest)特征。接下来,对齐的image-text对数据集被用于在混合模型中的 MLM \text{MLM} MLM预训练,该模型会将抽取的 ROI \text{ROI} ROI特征和成对文本进行拼接作为输入。此外,由于人工标注数据规模的限制,各种任务相关的辅助函数被用来改善表现。这些设计使得 VLP \text{VLP} VLP预训练协议更加复杂,为进一步改进带来了瓶颈。此外,预训练-微调方法通常缺乏zero-shot能力。相比之下,另一系列工作利用从网络上爬取的弱标注/对齐数据进行预训练,实现了更好的表现,以及在图像分类和图像-文本检索上的zero-shot学习能力。尽管如此,这些方法主要专注则特定的任务上,并且不能作为 VL \text{VL} VL基准的一般性预训练-微调表示。
鉴于现有技术的缺点,作者有兴趣建立一个 VLP \text{VLP} VLP模型:(1) 能够无缝地插入预训练-微调范式,并在标准 VL \text{VL} VL基准上实现有竞争力的表现;(2) 不需要像先前方法那样复杂的预训练协议;(3) 在跨模态设置中,具有文本指导zero-shot泛化的潜力。为了这个目标,提出了 SimVLM \text{SimVLM} SimVLM,代表 Simple Visual Language Model,其通过在弱对齐image-text数据上单利利用language modeling目标函数显著的简化为 VLP \text{VLP} VLP。简而言之, SimVLM \text{SimVLM} SimVLM有下面的组件构成:
-
Objective
其使用 Prefix Language Modeling,PrefixLM \text{Prefix Language Modeling,PrefixLM} Prefix Language Modeling,PrefixLM这个单独目标函数以端到端的方式从头训练模型,该模型不但能像 GPT-3 \text{GPT-3} GPT-3那样自然的执行文本生成,也能够像 BERT \text{BERT} BERT那样以双向的方式处理上下文本信息。
-
Architecture
框架采用 ViT/CoAtNet \text{ViT/CoAtNet} ViT/CoAtNet并直接使用原始图像作为输入。这些模型能够拟合大规模数据,并且很容易与 Prefix \text{Prefix} Prefix目标函数兼容。
-
Data
这些设置减去了对目标检测的需求,并且允许模型利用大规模的弱标注数据,这对于
zero-shot泛化来说具有更好的潜力。
SimVLM \text{SimVLM} SimVLM不仅简单,不需要预训练的目标检测以及辅助损失函数,而且具有比先前工作更好的效果。根据经验, SimVLM \text{SimVLM} SimVLM始终优于现有的 VLP \text{VLP} VLP模型,并且在不使用任何外部数据或者任务相关定制的情况下在6个 VL \text{VL} VL基准上实现state-of-the-art。此外,其在视觉语言理解中获得了更强的泛化性能,使zero-shot图像captioning和开发域 VQA \text{VQA} VQA成为可能。特别地, SimVLM \text{SimVLM} SimVLM学习到了具有zero-shot交叉模态迁移能力的统一多模态表示,模型在纯文本数据上进行微调并直接在image-text数据集上评估,不需要进一步的训练。
二、 SIMVLM \text{SIMVLM} SIMVLM
1. 背景
双向的Masked Language Modeling(MLM)已经是文本表示学习领域最流行的自监督训练目标函数。正如 BERT \text{BERT} BERT所证明的,该损失函数的想法是来自于降噪自编码器,即模型被训练来恢复文档中被破坏的tokens。特别地,给定一个文本序列 x \textbf{x} x,随机采样一个tokens子集 x m \textbf{x}_m xm,然后通过将 x m \textbf{x}_m xm中的tokens替换为特定的[MASK]来构造一个损坏的序列 x ∖ m \textbf{x}_{\setminus m} x∖m。训练目标是通过最小化负对数似然来从 x ∖ m \textbf{x}_{\setminus m} x∖m中重构 x m \textbf{x}_m xm
L MLM ( θ ) = − E x ∼ D [ log P θ ( x m ∣ x ∖ m ) ] (1) \mathcal{L}_{\text{MLM}(\theta)}=-\mathbb{E}_{\textbf{x}\sim D}[\text{log}\;P_\theta(\textbf{x}_m|\textbf{x}_{\setminus m})] \tag{1} LMLM(θ)=−Ex∼D[logPθ(xm∣x∖m)](1)
其中, θ \theta θ是模型的可训练参数, D D D是预训练数据 。这个方法能够学习到用于进一步下游任务微调的上下文表示。 MLM \text{MLM} MLM风格的预训练被广泛的应用在各种 VLP \text{VLP} VLP模型中,其输入是image-text对,并且模型需要利用图像的 ROI \text{ROI} ROI特征来预测被遮蔽的tokens。
另一个可选方案是单向Language Modeling(LM),其直接最大化序列 x \textbf{x} x的前向自回归分解公式:
L L M ( θ ) = − E x ∼ D [ log P θ ( x ) ] = − E x ∼ D [ ∑ t = 1 T log P θ ( x t ∣ x < t ) ] (2) \mathcal{L}_{LM}(\theta)=-\mathbb{E}_{\textbf{x}\sim D}[\text{log}\;P_\theta(\textbf{x})]=-\mathbb{E}_{\textbf{x}\sim D}\Big[\sum_{t=1}^T\text{log}\;P_\theta(\textbf{x}_t|\textbf{x}_{<t})\Big] \tag{2} LLM(θ)=−Ex∼D[logPθ(x)]=−Ex∼D[t=1∑TlogPθ(xt∣x<t)](2)
相比于 MLM \text{MLM} MLM, LM \text{LM} LM也在多个 NLP \text{NLP} NLP任务上展现了有效性。更重要的是,其能够使模型具有强大的生成能力,能够使模型在不进行微调情况下具有zero-shot泛化能力。尽管 MLM \text{MLM} MLM已经成为 VLP \text{VLP} VLP模型中的标准方法,但是生成式 LM \text{LM} LM还没有被充分研究。
2. 前缀语言建模
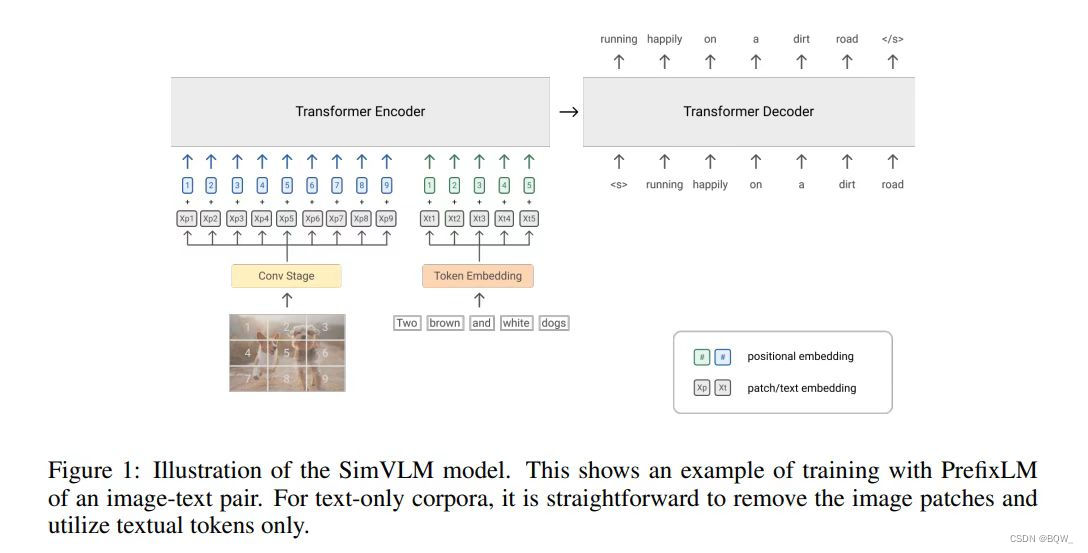
受使用 LM \text{LM} LM损失函数预训练具有zero-shot能力的启发,作者提出使用 PrefixLM \text{PrefixLM} PrefixLM预训练视觉语言表示。 PrefixLM \text{PrefixLM} PrefixLM不同于标准的 LM \text{LM} LM,其能够对前缀序列进行双向注意力(例如等式 ( 3 ) (3) (3)中的 x < T p \textbf{x}_{<T_p} x<Tp),并在仅能在余下的tokens上执行自回归分解(例如等式 ( 3 ) (3) (3)中的 x ≥ T p \textbf{x}_{\geq T_p} x≥Tp)。在预训练过程中,一个长度为 T p T_p Tp的tokens前缀序列是从输入序列中截断获得的,并且训练目标函数为:
L PrefixLM ( θ ) = − E x ∼ D [ log P θ ( x ≥ T p ∣ x < T p ) ] = − E x ∼ D [ ∑ t = T p T P θ ( x t ∣ x [ T p , t ] , x < T p ) ] (3) \mathcal{L}_{\text{PrefixLM}}(\theta)=-\mathbb{E}_{\textbf{x}\sim D}[\text{log}\;P_\theta(\textbf{x}_{\geq T_p}|\textbf{x}_{<T_p})]=-\mathbb{E}_{\textbf{x}\sim D}\Big[\sum_{t=T_p}^T P_\theta(\textbf{x}_t|\textbf{x}_{[T_p,t]},\textbf{x}_{<T_p})\Big] \tag{3} LPrefixLM(θ)=−Ex∼D[logPθ(x≥Tp∣x<Tp)]=−Ex∼D[t=Tp∑TPθ(xt∣x[Tp,t],x<Tp)](3)
直觉上,图像可以被看作是文本描述的前缀,因为在web文档中图像通常出现在文本之前。因此,对于给定的image-text对,会将长度为 T i T_i Ti的图像特征序列追加到文本序列前,并采样长度为 T p ≥ T i T_p\geq T_i Tp≥Ti的前缀来在纯文本数据上计算 LM \text{LM} LM损失函数。相比于先前 MLM \text{MLM} MLM风格的 VLP \text{VLP} VLP方法,本文的 PrefixLM \text{PrefixLM} PrefixLM模型在sequence-to-sequence框架下不仅能够具有 MLM \text{MLM} MLM中的双向上下文表示,而且能够像 LM \text{LM} LM那么执行文本生成。
3. 架构
这里采用 Transformer \text{Transformer} Transformer作为模型的骨干,因为其在视觉和语言任务上都成功了。不同于标准的 LM \text{LM} LM, PrefixLM \text{PrefixLM} PrefixLM能够在前缀序列上应用双向注意力机制,因此其能应用在纯解码器和编码器-解码器架构的sequence-to-sequence语言模型。在作者的初步实验中发现,从编码器-解码器模型中引入的诱导偏差,从生成中解耦了编码,有利于下游任务的改善。
整个模型的结构如上图所示。对于视觉模态,受 ViT \text{ViT} ViT和 CoAtNet \text{CoAtNet} CoAtNet启发,本文的模型接收原始图像 x ∈ R H × W × C \textbf{x}\in\mathbb{R}^{H\times W\times C} x∈RH×W×C,并将其映射为扁平的一维patches序列 x p ∈ R T i × D \textbf{x}_p\in\mathbb{R}^{T_i\times D} xp∈RTi×D,将其作为 Transformer \text{Transformer} Transformer的输入,其中 D D D是 Transformer \text{Transformer} Transformer层的固定hidden size,并且 T i = H W P 2 T_i=\frac{HW}{P^2} Ti=P2HW给定patch尺寸 P P P情况下的图像tokens的长度。遵循Dai et al.工作,使用 ResNet \text{ResNet} ResNet前三个块组成卷积阶段来抽取上下文patches,作者发现其优于 ViT \text{ViT} ViT中的朴素线性投影。对于文本模态,遵循标准实践将输入训练转换为sub-word tokens,并且嵌入向量从固定词典中学习。为了保留位置信息,为图像和文本输入分别添加可训练一维位置嵌入向量,并在 Transformer \text{Transformer} Transformer层内的图像patches上添加二维的相对注意力。注意,这里不会添加额外的模态类型嵌入向量,因为实验发现并没有改善效果。
4. 数据集
因为本文方法不依赖于目标检测模块,并且仅在原始图像patches输入上操作,因此使用大规模噪音image-text数据来从头训练所有模型参数,其具有更好的zero-shot泛化潜力。特别地,使用 ALIGN \text{ALIGN} ALIGN中的image-text数据,该数据是从web上爬取并仅使用最小的预处理。另一方面, PrefixLM \text{PrefixLM} PrefixLM的形式是模态不可知的,因此可以添加额外的纯文本语料来补充图像对于文本中的噪音。实验显示,统一 PrefixLM \text{PrefixLM} PrefixLM减少了模态的差异并改善模型的质量。相比于先前 VLP \text{VLP} VLP方法由两个预训练阶段组成,并多个辅助目标函数,本文提出了方法以端到端的方法使用单个语言模型损失函数进行单次预训练,因此命名为 SimVLM,Simple Visual Language Model \text{SimVLM,Simple Visual Language Model} SimVLM,Simple Visual Language Model。
三、实验
暂无

一站式 AI 云服务平台
更多推荐



 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)