
大模型_alpaca-lora微调及推理部署
大模型_alpaca-lora微调及推理部署
文章目录
Llama
官方、论文、模型网址
官方: https://ai.meta.com/llama/
论文:Llama 2: Open Foundation and Fine-Tuned Chat Models
模型:https://huggingface.co/meta-llama
github:https://github.com/facebookresearch/llama
Llama1与Llama2对比
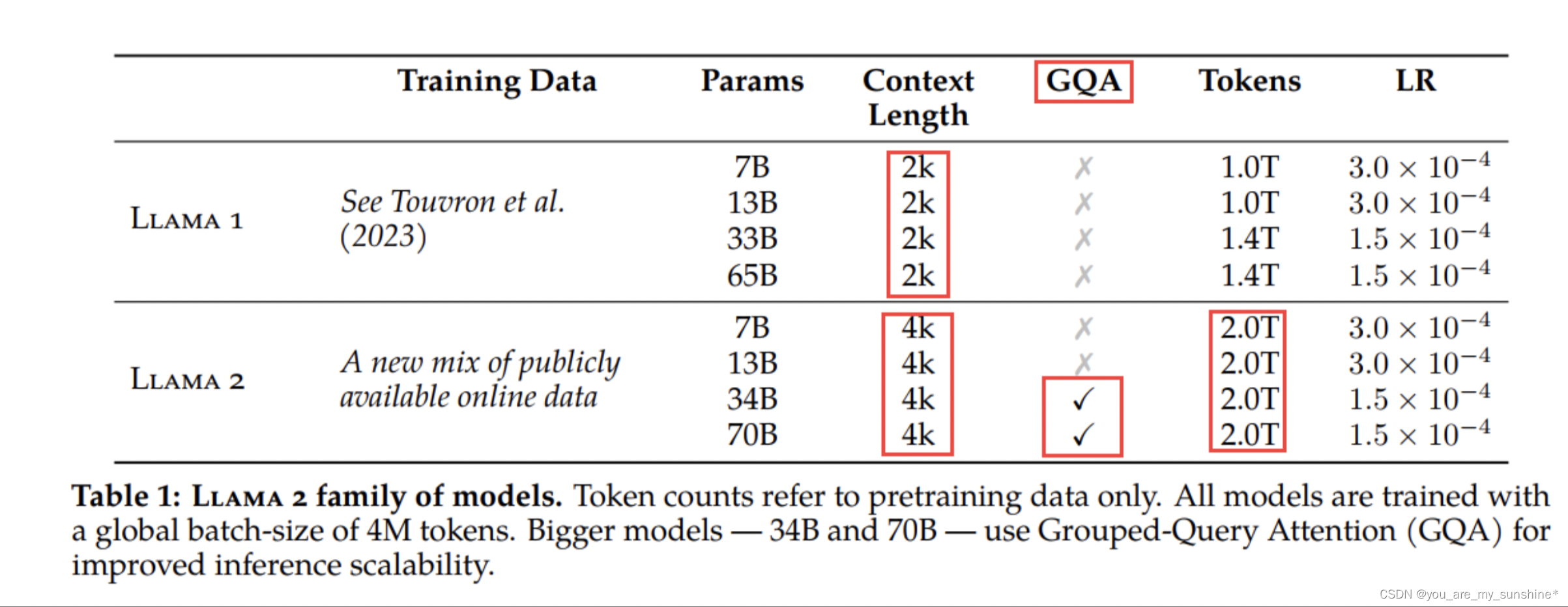
Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构、使用 RMSNorm 的预归一化、SwiGLU 激活函数和旋转位置嵌入。
与Llama 1的主要区别包括增加的上下文长度(由2048变为4096)和分组查询注意力(GQA)。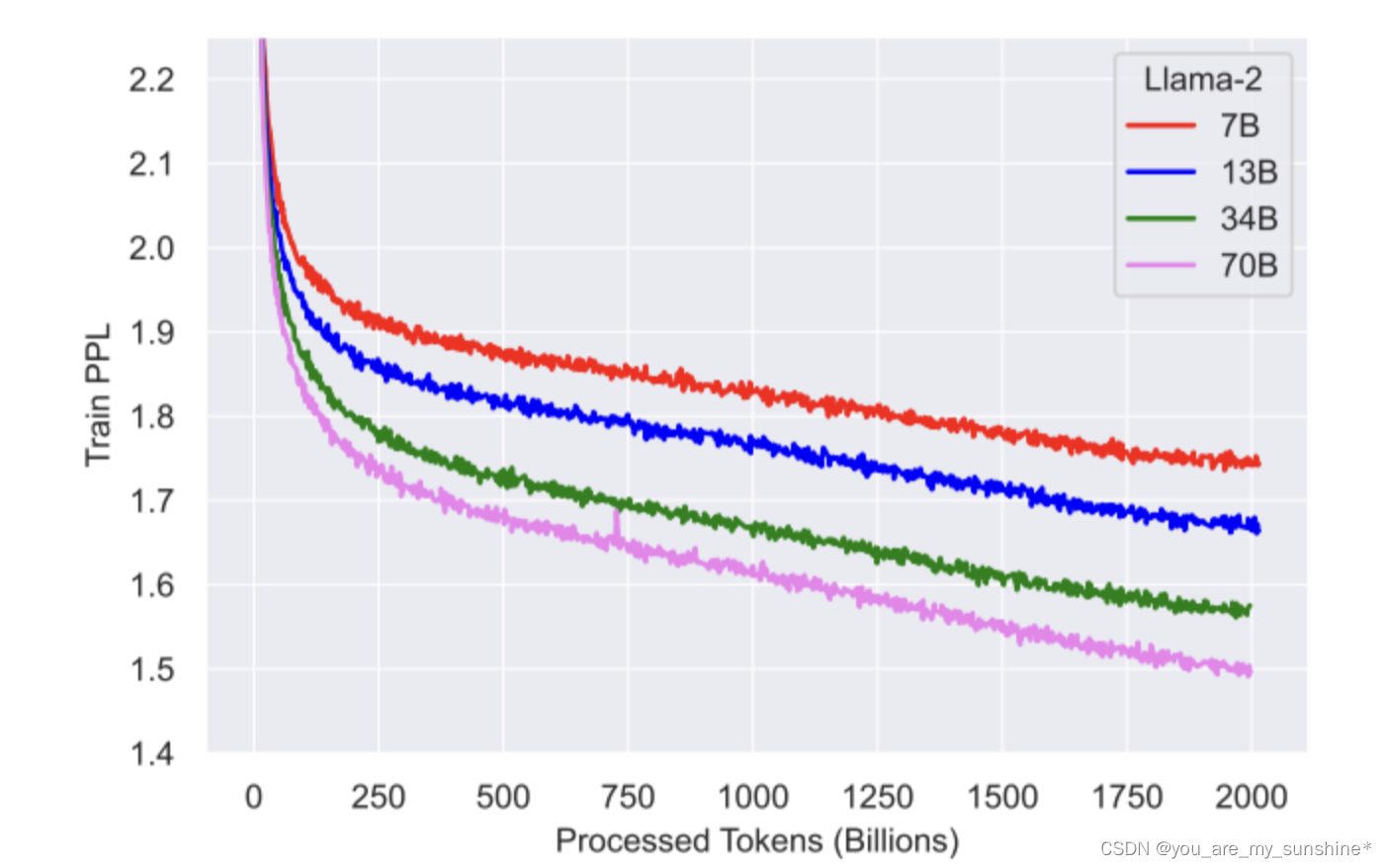
可以看出,对2T的tokens进行预训练后,模型仍然没有出现饱和现象。
GQA、MHA 和 MQA三者区别
关于GQA
论文:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
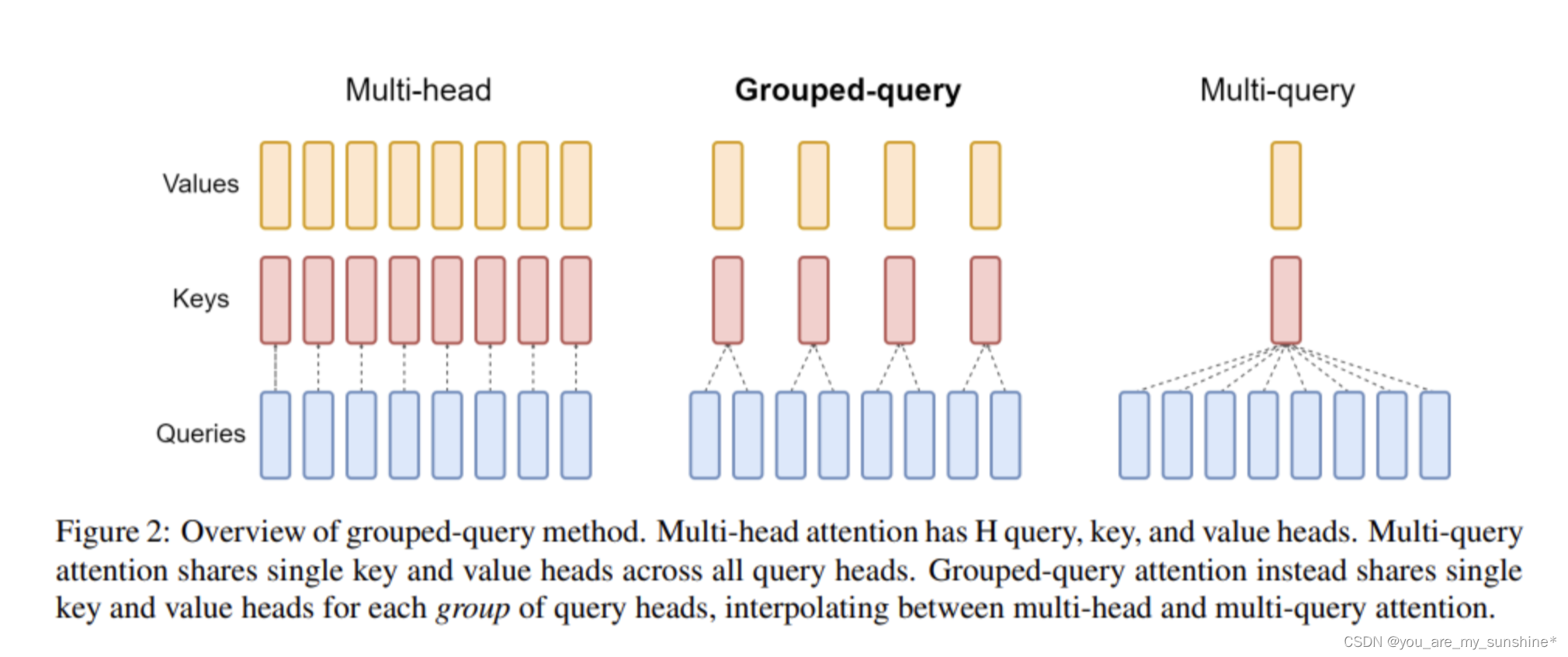
GQA是2023年5月谷歌提出来的一种注意力方法。了解GQA前,要先知道 MHA 和 MQA。
- MHA就是Transformer中的多头注意力,如果头数是8的话,就会有8个Q,8个K,8个V(Q是查询向量,K是键向量,V是值向量);
- MQA是多查询注意力,是对MHA的一种改进,将K和V都只保留一个,相当于是用8个Q,1个K,1个V进行注意力的计算,这种方式的优点是可以加速解码器的推理速度(因为K和V的计算量少了),缺点就是性能下降;
- GQA的提出,则是将K和V的数量设置为大于1,小于Q的一个值(如设置为4,介于1到8之间),这种方式以较小的计算成本将多头注意力模型转换为多查询模型,从而实现快速的多查询和高质量的推理,实现了性能和速度的平衡。
GQA在推理速度上几乎和MQA持平,在效果上几乎和MHA持平。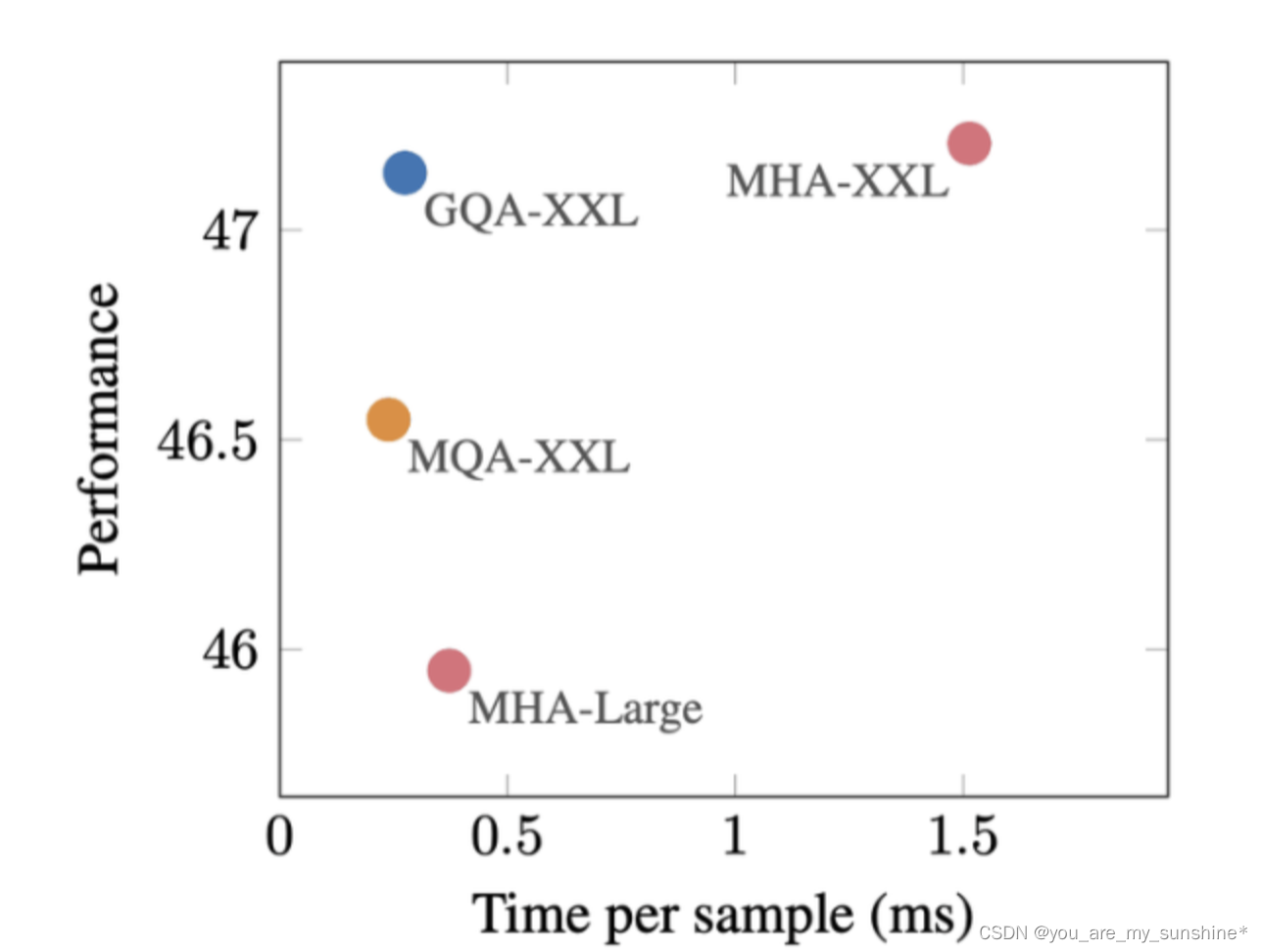
Lora
论文、github等网址
论文:LoRA: Low-Rank Adaptation of Large Language Models
论文地址:https://arxiv.org/abs/2106.09685
官方代码github:https://github.com/microsoft/LoRA
HuggingFace封装的peft库:https://github.com/huggingface/peft
微软实现的lora:https://github.com/microsoft/LoRA
Lora是什么
LoRA的本质是在原模型的基础上插入若干新的参数,称之为adapter。在训练时,冻结原始模型的参数,只更新adapter的参数。对于不同的基座模型,adapter的参数量一般为几百万~几千万。
具体来讲,Lora方法指的是在大型语言模型上对指定参数增加额外的低秩矩阵,也就是在原始PLM旁边增加一个旁路,做一个降维再升维的操作。并在模型训练过程中,固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。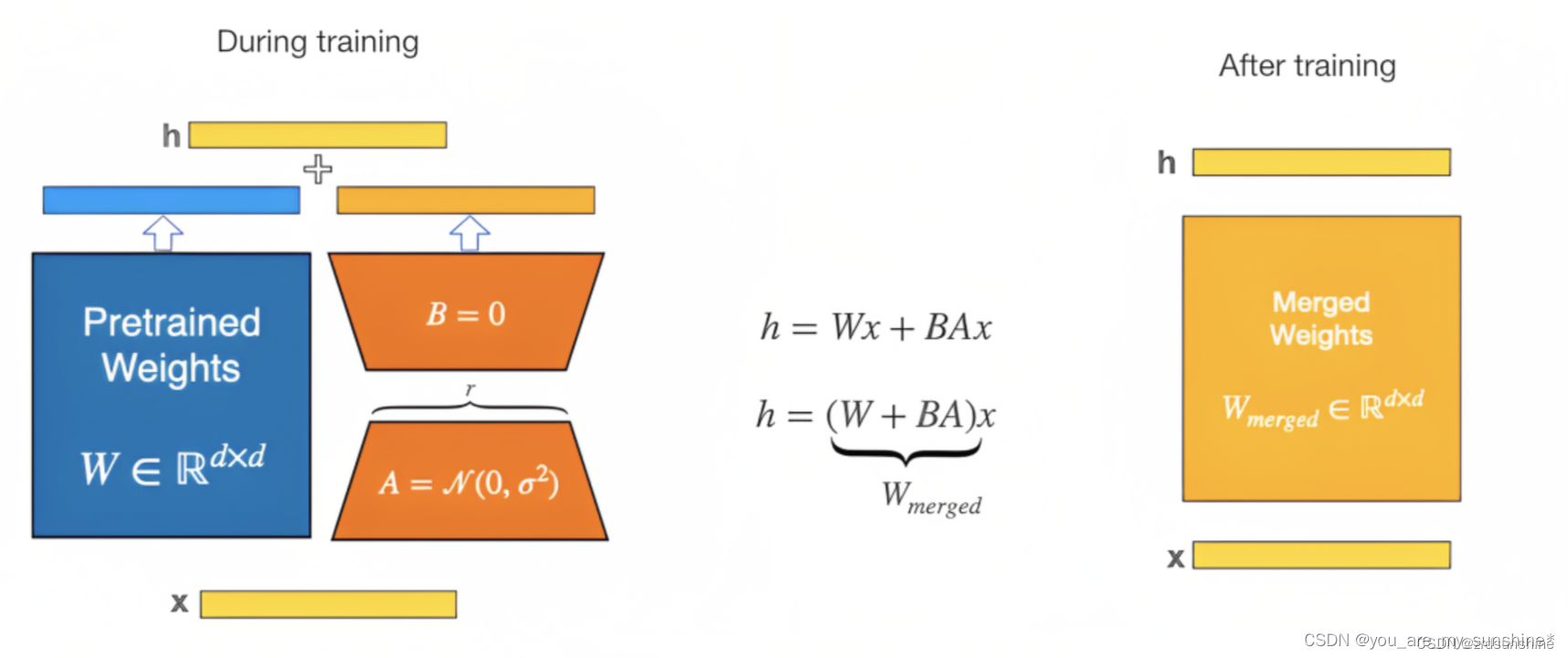
具体来看,假设预训练的矩阵为  ,它的更新可表示为:
,它的更新可表示为: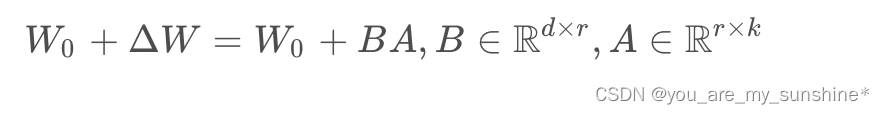
训练与推理
- 在训练过程中,原模型固定,只训练降维矩阵A和升维矩阵B,训练完成后得到两个矩阵的参数;
- 在推理时,可将两个矩阵的参数加到原参数上,进行推理。
重要相关参数
- lora_rank(int,optional): LoRA 微调中的秩大小。
- lora_alpha(float,optional): LoRA 微调中的缩放系数。
- lora_dropout(float,optional): LoRA 微调中的 Dropout 系数。
LoRA 的优势
LoRA 的最大优势是速度更快,使用的内存更少,因此可以在消费级硬件上运行。
在多卡训练时,Lora也是效率很高的,在多卡训练中,LoRA的速度优势主要体现在两个方面:
- 计算效率:由于LoRA只需要计算和优化注入的低秩矩阵,因此它的计算效率比完全微调更高。在多卡训练中,LoRA可以将注入矩阵的计算和优化分配到多个GPU上,从而加速训练过程。
- 通信效率:在多卡训练中,通信效率通常是一个瓶颈。由于LoRA只需要通信注入矩阵的参数,因此它的通信效率比完全微调更高。在多卡训练中,LoRA可以将注入矩阵的参数分配到多个GPU上,从而减少通信量和通信时间。 因此,LoRA在多卡训练中通常比完全微调更快。具体来说,LoRA可以将硬件门槛降低多达3倍,从而提高训练的效率。
微调部署
下载项目
git clone https://github.com/tloen/alpaca-lora.git

切换到项目目录下
cd alpaca-lora
切换conda环境
source activate
conda activate alpaca-lora
模型下载
https://huggingface.co/decapoda-research/llama-7b-hf
模型放在:/data/sim_chatgpt/llama-7b-hf
微调数据集下载
该数据基于斯坦福alpca数据进行了清洗,但至于具体清洗流程并不知
https://huggingface.co/datasets/yahma/alpaca-cleaned
微调数据放在:/data/datasets/alpaca-cleaned
启动微调
nohup python -u finetune.py \
--base_model '/data/sim_chatgpt/llama-7b-hf' \
--data_path '/data/datasets/alpaca-cleaned' \
--output_dir './lora-alpaca' \
>> log.out 2>&1 &
失败1
原因
Some modules are dispatched on the CPU or the disk. Make sure you have enough GPU RAM to fit the quantized model.
查看log.out日志,发现是GPU不够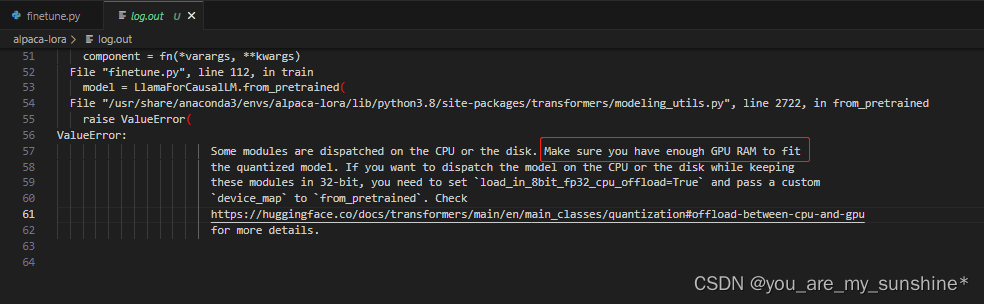
分析
nvidia-smi,查看内存使用情况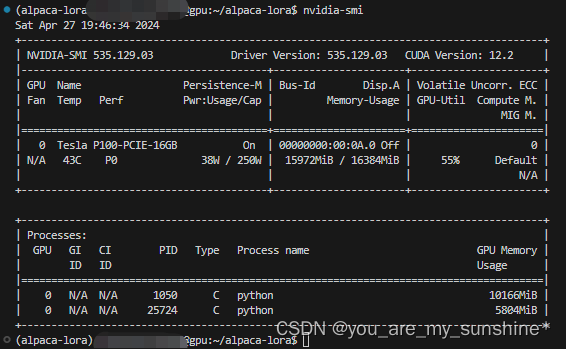
失败2
RuntimeError:expected scaler type Half but found Float
修改前
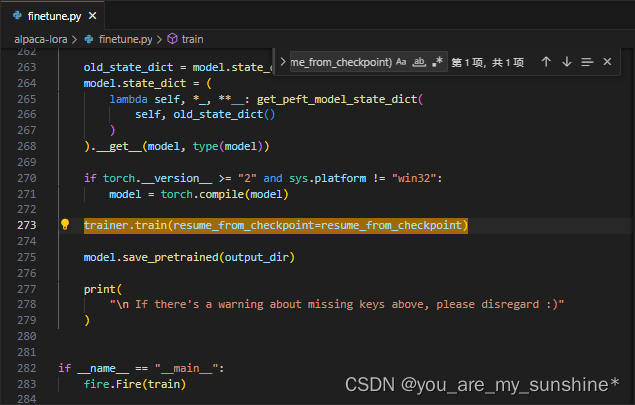
修改后
在finetune.py文件上,加上"with torch.autocast(“cuda”):",并注意下一行缩进问题
with torch.autocast("cuda"):
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
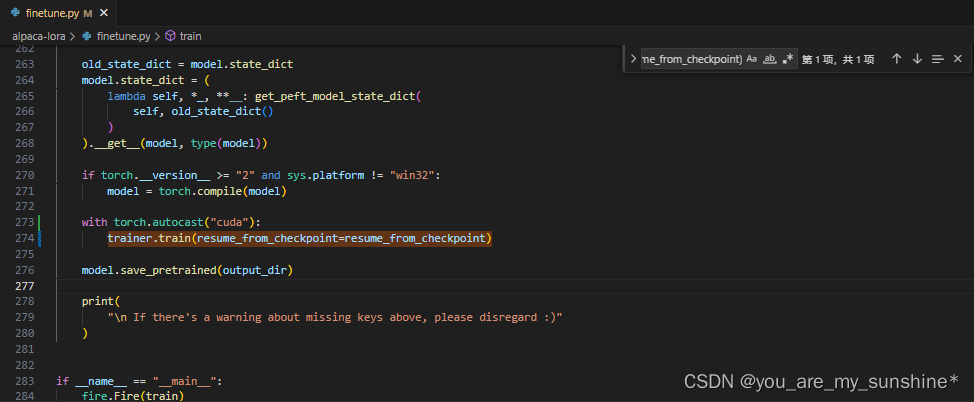
再次启动微调即可
注:微调时间很长,需要等待,具体微调日志可见log.out文件
推理部署
在generate.py文件,将share=True,便于公网访问。
python generate.py \
--load_8bit \
--base_model '/data/sim_chatgpt/llama-7b-hf' \
--lora_weights './lora-alpaca/checkpoint-2000'
注意:/lora-alpaca文件有,比如checkpoint-800、checkpoint-1000、checkpoint-2000,可自由选择
如果报错,不能创建链接,降低下gradio版本即可,如:pip install gradio==3.13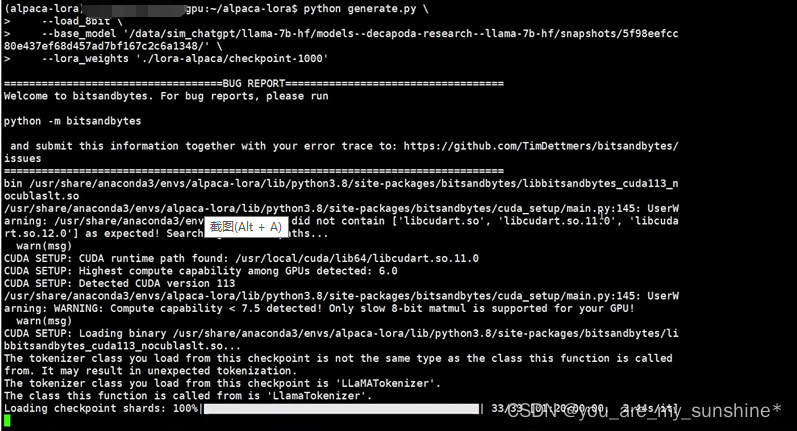
一两分钟后看到公网网址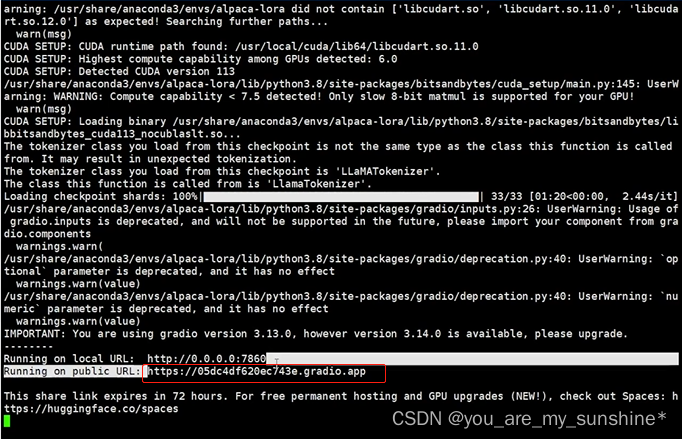
将公网网址放到浏览器上提问:
根据"https://huggingface.co/datasets/yahma/alpaca-cleaned",instruction(string)里的一个问题"Give three tips for staying healthy."进行提问,发现网页输出的结果跟output差不多,说明模型进行微调学习得不错。
学习的参考资料:
Instruct-tune LLaMA on consumer hardware
alpaca-lora微调
LLM模型微调方法及经验总结
Meta 最新发布 LLaMA 2(允许商业化)

一站式 AI 云服务平台
更多推荐



 24
24 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)