
JCR1区Top算法应用:(SMA-CNN-BiGRU-Attention)黏菌优化深度学习-融合注意力机制预测程序代码!包含特征可视化,数据Excel导入,直接运行!
SMA 黏菌优化算法,于2020年发表在SCI的1区Top期刊《Future Generation Computer Systems》上。利用该计算机1区Top算法对对我们的CNN-BiGRU-Attention时序和空间特征结合-融合注意力机制的回归预测程序代码中的超参数如:卷积核大小、BiGRU单元个数、学习率等进行优化。
适用平台:Matlab2023版及以上
SMA 黏菌优化算法,于2020年发表在SCI的1区Top期刊《Future Generation Computer Systems》上。
利用该计算机1区Top算法对对我们的CNN-BiGRU-Attention时序和空间特征结合-融合注意力机制的回归预测程序代码中的超参数如:卷积核大小、BiGRU单元个数、学习率等进行优化。
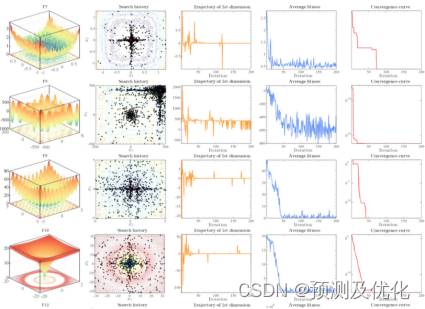
该论文进行了一系列实验,包括定性分析、定量分析测试。定性分析包括
①接近食物: 黏菌通过空气中的气味接近食物,黏菌接近食物时呈圆形与扇形结构运动。②包围食物: 黏菌静脉接触的食物浓度越高,生物振荡的传播波越强,细胞质流动越快。
③抓取食物: 黏菌在食物浓度低时更慢地接近食物,找到优质食物时更快接近食物。
实验结果表明:SMA通过模拟黏菌对多个食物来源的利用,引入了多源信息融合的思想。黏菌能够同时利用多个资源,这使得算法更具鲁棒性,能够更好地处理多目标优化和多模态问题。
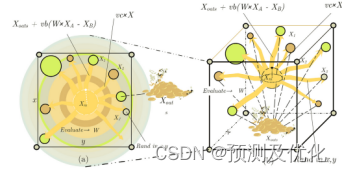
黏菌算法的背景:
论文提到的黏菌是指多头黏菌(Physarum polycephalum),黏菌是一种生活在寒冷湿润地方的真核生物。它的主要营养阶段是黏菌体,也是该文的主要研究阶段。在这个阶段,黏菌体会寻找食物,并将食物包围起来,分泌酶来消化食物。在迁移过程中,前端会延伸成扇形,形成一个相互连接的血管网络,使细胞质能够流动。由于它们独特的形态和特征,它们可以同时利用多个食物来源形成连接它们的血管网络。
黏菌算法SMA的创新点:
模拟生物行为:
SMA模拟了黏菌在寻找食物时的行为,将生物的智能行为引入优化算法。这种生物行为模拟的方式可以使算法更适应复杂和动态的问题领域。
自适应性和灵活性:
SMA具有自适应性和灵活性,能够根据环境的变化调整搜索策略。算法可以动态地调整离开当前位置的概率、搜索模式和资源利用策略,使其更适应不同的问题和环境。
多源信息融合:
SMA通过模拟黏菌对多个食物来源的利用,引入了多源信息融合的思想。黏菌能够同时利用多个资源,这使得算法更具鲁棒性,能够更好地处理多目标优化和多模态问题。
动态搜索模式调整:
SMA根据食物来源的质量动态调整搜索模式,类似于黏菌在高质量食物区域采用更集中的搜索方法,而在低质量食物区域进行更广泛的探索。这种动态搜索模式调整可以提高算法在不同问题场景中的适应性。
全局-局部搜索融合:
SMA在算法中融合了全局和局部搜索策略,类似于黏菌在高质量食物区域进行局部集中搜索,而在整体区域进行全局探索。这种全局-局部搜索融合使得算法更有可能跳出局部最优解,同时能够更精细地搜索潜在的最优解。
综上,SMA通过模拟黏菌的智能行为,引入了生物启发的优化思想,使得算法在解决复杂问题时更具有自适应性、灵活性和多样性。这些特点使得SMA在一些问题领域表现出色,相较于传统的优化算法,更能有效地搜索问题的解空间。
CNN-BiGRU-Attention模型的创新性:
①结合卷积神经网络 (CNN) 和双向门控循环单元 (BiGRU):CNN 用于处理多变量时间序列的多通道输入,能够有效地捕捉输入特征之间的空间关系。BiGRU 是一种能够捕捉序列中长距离依赖关系的递归神经网络。通过双向性,BiGRU 可以同时考虑过去和未来的信息,提高了模型对时间序列动态变化的感知能力。
②引入自注意力机制 (Self-Attention): Self-Attention 机制使得模型能够更灵活地对不同时间步的输入信息进行加权。这有助于模型更加集中地关注对预测目标有更大影响的时间点。
自注意力机制还有助于处理时间序列中长期依赖关系,提高了模型在预测时对输入序列的全局信息的感知。
优化套用:基于黏菌优化算法(SMA)、卷积神经网络(CNN)和双向门控循环单元 (BiGRU)融合注意力机制的超前24步多变量时间序列回归预测算法。
功能:
1、多变量特征输入,单序列变量输出,输入前一天的特征,实现后一天的预测,超前24步预测。
2、通过SMA优化算法优化学习率、卷积核大小、神经元个数,这3个关键参数,以最小MAPE为目标函数。
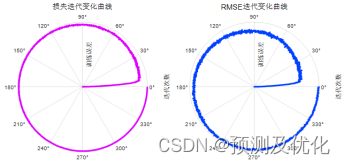
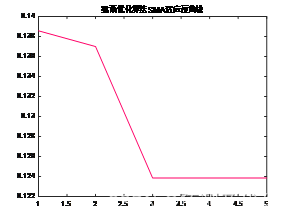
3、提供损失、RMSE迭代变化极坐标图;网络的特征可视化图;测试对比图;适应度曲线(若首轮精度最高,则适应度曲线为水平直线)。
4、提供MAPE、RMSE、MAE等计算结果展示。
适用领域:风速预测、光伏功率预测、发电功率预测、碳价预测等多种应用。
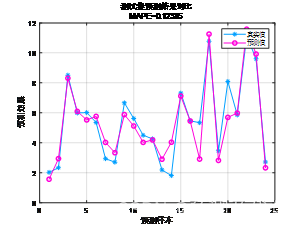
预测值与实际值对比:
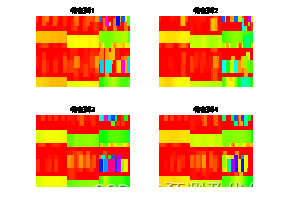
训练特征可视化:
训练曲线的极坐标形式(误差由内到外越来越接近0)
适应度曲线:
SMA优化完整代码:
% 黏菌优化算法(SMA)
% max _ iter:最大迭代次数,N:种群大小,收敛曲线:收敛曲线,
function [Destination_fitness,Best_Pos,Convergence_curve, bestPred, bestNet, bestInfo ]=SMA(SearchAgents,Max_iterations,lb,ub,dim,fobj)
% SearchAgents,Max_iterations,lowerbound,upperbound,dimension,fitness
%% 初始化位置
bestPositions=zeros(1,dim);
Destination_fitness=inf;%将此更改为 -inf 以解决最大化问题
AllFitness = inf*ones(SearchAgents,1);%记录所有粘菌的适应度
weight = ones(SearchAgents,dim);%每个粘菌的适应度权重
%% 初始化随机解集
X=ceil(rand(SearchAgents, dim) .* (ub - lb) + lb);
Convergence_curve=zeros(1,Max_iterations);
it=1; %迭代次数
lb=ones(1,dim).*lb; % 变量下限
ub=ones(1,dim).*ub; % 变量上限
z=0.5; % 参数
%% 主循环
while it <= Max_iterations
%=====适应度排序======
for i=1:SearchAgents
% 检查解决方案是否超出搜索空间并将其带回
Flag4ub=X(i,:)>ub;
Flag4lb=X(i,:)<lb;
X(i,:)=(X(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
[AllFitness(i),Value{i},Net{i},Info{i}] = fobj(X(i,:));
end
[SmellOrder,SmellIndex] = sort(AllFitness);
worstFitness = SmellOrder(SearchAgents);
bestFitness = SmellOrder(1);
S=bestFitness-worstFitness+eps; %加上 eps 以避免分母为零
%====计算每个粘菌的适应度权重=====
for i=1:SearchAgents
for j=1:dim
if i<=(SearchAgents/2)
weight(SmellIndex(i),j) = 1+rand()*log10((bestFitness-SmellOrder(i))/(S)+1);
else
weight(SmellIndex(i),j) = 1-rand()*log10((bestFitness-SmellOrder(i))/(S)+1);
end
end
end
%====更新最佳适应度值和最佳位置=====
if bestFitness < Destination_fitness
bestPositions=X(SmellIndex(1),:);
Destination_fitness = bestFitness;
bestPred = Value{SmellIndex(1)};
bestNet = Net{SmellIndex(1)};
bestInfo = Info{SmellIndex(1)};
end
a = atanh(-(it/Max_iterations)+1);
b = 1-it/Max_iterations;
%====更新搜索代理的位置=====
for i=1:SearchAgents
if rand<z
X(i,:) = (ub-lb)*rand+lb;
else
p =tanh(abs(AllFitness(i)-Destination_fitness));
vb = unifrnd(-a,a,1,dim);
vc = unifrnd(-b,b,1,dim);
for j=1:dim
r = rand();
A = randi([1,SearchAgents]); % 从总体中随机选择两个位置
B = randi([1,SearchAgents]);
if r<p
X(i,j) = bestPositions(j)+ vb(j)*(weight(i,j)*X(A,j)-X(B,j));
else
X(i,j) = vc(j)*X(i,j);
end
end
end
end
Convergence_curve(it)=Destination_fitness;
% 除了学习率其它位置均为整数
for i = 1:size(bestPositions,2)
if i ==1
Best_Pos(i) = bestPositions(i);
else
Best_Pos(i) = round(bestPositions(i));
end
end
display(['At iteration ', num2str(it), ' the best solution fitness is ', num2str(Destination_fitness)]);
it=it+1;
end
end
%% SMA-CNN-Bi-GRU-Attention预测完整代码:https://mbd.pub/o/bread/ZZacl5Zu部分图片来源于网络,侵权联系删除!
欢迎感兴趣的小伙伴关注并后台留言获得完整版代码,小编会继续推送更有质量的学习资料、文章和程序代码!

一站式 AI 云服务平台
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)