
使用TensorFlow训练深度学习模型实战指南(上)
使用TensorFlow进行深度学习模型训练,学习如何使用MNIST数据集从头开始实现一个神经网络,重点是将真实世界的数据重塑为TensorFlow对象。
使用TensorFlow进行深度学习模型训练,学习如何使用MNIST数据集从头开始实现一个神经网络,重点是将真实世界的数据重塑为TensorFlow对象。
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
尽管大多数关于神经网络的文章都强调数学,而官方TensorFlow文档则强调使用现成数据集进行快速实现,但将这些资源应用于真实世界数据集是很有挑战性的,很难将数学概念和现成数据集与我的具体用例联系起来。本文旨在提供一个实用的、逐步的教程,介绍如何使用TensorFlow训练深度学习模型,并重点介绍如何将数据集重塑为TensorFlow对象,以便TensorFlow框架能够识别。
本文主要内容包括:
-
将DataFrame转换为TensorFlow对象
-
从头开始训练深度学习模型
-
使用预训练的模型训练深度学习模型
-
评估、预测和绘制训练后的模型。
第一步:安装TensorFlow和其他必需的库
首先,你需要安装TensorFlow。你可以通过在终端或Anaconda中运行以下命令来完成:
# 安装所需的软件包
!pip install tensorflow
!pip install tensorflow-datasets
安装TensorFlow之后,导入其他必需的库,如Numpy、Matplotlib和Sklearn。
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Dropout
第二步:加载数据集
一旦导入了所有必需的库,下一步是获取数据集来搭建模型。TensorFlow允许使用各种输入格式,包括CSV、TXT和图像文件,有些数据集可以从TensorFlow-dataset中导入。这些数据集已准备好用作深度学习模型的输入。然而,在许多情况下,数据集是以DataFrame格式而不是TensorFlow对象格式存在的。在本教程中,我们将使用Sklearn中的MNIST数据集,其格式为Pandas DataFrame。MNIST数据集广泛用于图像分类任务,包括70000个手写数字的灰度图像,每个图像大小为28x28像素。该数据集被分为60000个训练图像和10000个测试图像。
from sklearn.datasets import fetch_openml
# 加载MNIST数据集
# mnist = fetch_openml('mnist_784')
# 输出MNIST数据集
print('Dataset type:', type(mnist.data))
# 浏览一下加载的数据集
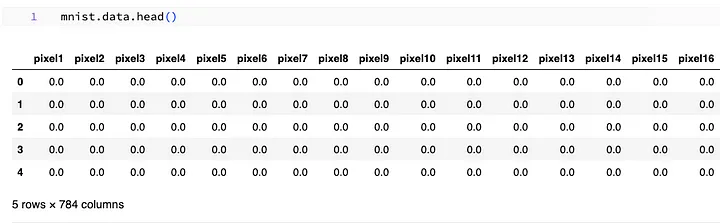
mnist.data.head()
通过输出DataFrame的前部,我们可以观察到它包含784列,每列代表一个像素。
第三步:将DataFrame转换为TensorFlow数据集对象
加载了Pandas DataFrame,注意到TensorFlow不支持Pandas DataFrame作为模型的输入。因此,必须将DataFrame转换为可以用于训练或评估模型的张量。这个转换过程确保数据以与TensorFlow API兼容的格式存在。为了将MNIST数据集从DataFrame转换为tf.data.Dataset对象,可以执行以下步骤:
-
将数据和目标转换为NumPy数组并对数据进行归一化处理
-
使用scikit-learn中的
train_test_split将数据集拆分为训练集和测试集 -
将训练和测试数据重塑为28x28x1的图像
-
使用
from_tensor_slices为训练集和测试集创建tf.data.Dataset对象
def get_dataset(mnist):
# 加载MNIST数据集
# mnist = fetch_openml('mnist_784')
# 将数据和目标转换成numpy数组
X = mnist.data.astype('float32')
y = mnist.target.astype('int32')
# 将数据归一化,使其数值在0和1之间
X /= 255.0
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将训练数据重塑为28x28x1的图像
X_train = X_train.values.reshape((-1, 28, 28, 1))
X_test = X_test.values.reshape((-1, 28, 28, 1))
# 为训练和测试集创建TensorFlow数据集对象
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
# 输出训练和测试集的形状
print('Training data shape:', X_train.shape)
print('Training labels shape:', y_train.shape)
print('Testing data shape:', X_test.shape)
print('Testing labels shape:', y_test.shape)
return X_test, y_test, X_train, y_train
再来看一下我们的训练和测试TensorFlow对象:

经过这个过程,原始数据集已经成功转换为形状为(5600,28,28,1)的TensorFlow对象。
第四步:定义深度学习模型
数据准备完成后,下一步是使用TensorFlow搭建神经网络模型。搭建模型有两个选项:
你可以使用各种层,包括Dense、Conv2D和LSTM,从头开始搭建模型。这些层定义了模型的架构及数据流经过它的方式。你可以基于TensorFlow Hub提供的预训练模型搭建模型。这些模型已经在大型数据集上进行了训练,并可以在特定数据集上进行微调,以达到在较短的训练时间内达到较高的准确度。
你可以根据TensorFlow Hub中的预训练模型来建立模型。这些模型已经在大型数据集上进行了训练,并且可以在你的特定数据集上进行微调,以达到较少的训练时间,达到较高的准确性。
我们分别讨论这两个选项。
选项1:从头开始定义深度学习模型
TensorFlow中的tf.keras.Sequential函数允许我们逐层定义神经网络模型。我们可以选择各种层,如Dense、Conv2D和LSTM,来搭建定制的模型架构。以下是示例:
# 定义模型架构
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10)
])
在这个示例中,我们定义了一个模型,包含以下六个层(4个隐藏层):
-
Conv2D层,具有32个过滤器,3x3的内核大小和ReLU激活。此层以形状为(28,28,1)的输入图像作为输入。
-
MaxPooling2D层,具有默认的2x2池大小。此层对从上一层获得的特征映射进行下采样。
-
Flatten层,将2D特征映射展平为1D向量。
-
Dense层,具有128个神经元和ReLU激活。此层对展平的特征映射执行完全连接操作。
-
Dropout层,在训练期间随机丢弃50%的连接以防止过拟合。
-
Dense层,具有十个神经元,无激活函数。此层表示模型的输出层,神经元的数量对应于分类任务中的类别数目。
这个模型遵循典型的卷积神经网络架构,包括多个卷积层和池化层,以及一个或多个全连接层。
推荐书单

《TensorFlow深度学习应用开发实战》
随着人工智能技术的发展,深度学习成为最受关注的领域之一。在深度学习的诸多开发框架中,TensorFlow 是最受欢迎的开发框架。
本书以培养人工智能编程思维和技能为核心,以工作过程为导向,采用任务驱动的方式组织内容。全书共分为8 个任务,任务1 介绍深度学习的发展历程、应用领域以及开发环境的搭建过程;任务2 介绍TensorFlow 框架的基本原理、计算图、会话、张量等概念;任务3 和任务4 阐述全连接神经网络模型、神经网络优化方法及反向传播算法;任务5 和任务6 讨论卷积神经网络、卷积、池化的原理;任务7 和任务8演示网络模型可视化操作步骤及制作与解析数据集的方法。
本书既可作为大数据、人工智能等相关专业应用型人才的教学用书,也可以作为TensorFlow初学者的学习参考书。
京东安全 https://item.jd.com/12707477.html
https://item.jd.com/12707477.html

精彩回顾
《使用TensorFlow和Keras创建猫狗图片深度学习分类器》
微信搜索关注《Python学研大本营》,加入读者群
访问【IT今日热榜】,发现每日技术热点

一站式 AI 云服务平台
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)