
深度学习之keras入门学习笔记(三)猫狗图像分类
学习笔记来源:https://www.bilibili.com/video/BV1zk4y1y7aP猫狗—图像分类文章目录1 数据预处理2 猫狗分类-简单CNN3 VGG16-bottleneck实现猫狗分类4 VGG16-Finetune实现猫狗分类1 数据预处理需要把训练数据和测试数据分类放置到image下面不同目录文件夹下。例如image/train/dogs/dog001.jpgdog00
学习笔记来源:https://www.bilibili.com/video/BV1zk4y1y7aP
猫狗—图像分类
学习之前:卷积神经网络VGG16详解
1 数据预处理
需要把训练数据和测试数据分类放置到image下面不同目录文件夹下。例如
image/
train/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001/jpg
cat002.jpg
...
test/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001/jpg
cat002.jpg
...
# coding: utf-8
# 链接:https://pan.baidu.com/s/1i4SKqWH 密码:d8mt
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
# * rotation_range是一个0~180的度数,用来指定随机选择图片的角度。
# * width_shift和height_shift用来指定水平和竖直方向随机移动的程度,这是两个0~1之间的比
# * rescale值将在执行其他处理前乘到整个图像上,我们的图像在RGB通道都是0~255的整数,这样的操作可能使图像的值过高或过低,所以我们将这个值定为0~1之间的数。
# * shear_range是用来进行剪切变换的程度,参考剪切变换
# * zoom_range用来进行随机的放大
# * horizontal_flip随机的对图片进行水平翻转,这个参数适用于水平翻转不影响图片语义的时候
# * fill_mode用来指定当需要进行像素填充,如旋转,水平和竖直位移时,如何填充新出现的像素
datagen = ImageDataGenerator(
rotation_range = 40, # 随机旋转角度
width_shift_range = 0.2, # 随机水平平移
height_shift_range = 0.2, # 随机竖直平移
rescale = 1./255, # 数值归一化
shear_range = 0.2, # 随机裁剪
zoom_range =0.2, # 随机放大
horizontal_flip = True, # 水平翻转
fill_mode='nearest') # 填充方式
##用一张图片测试一下图片处理效果
# 载入图片
img = load_img('image/train/cat/cat.1.jpg')
x = img_to_array(img)
print(x.shape)
x = x.reshape((1,) + x.shape) #加个维度的目的是生成图片的时候需要传入4维的格式,第一个维度指批次,最后维度指的是通道数
print(x.shape)
i = 0
# 生成21张图片
# flow 随机生成图片
for batch in datagen.flow(x, batch_size=1, save_to_dir='temp', save_prefix='cat', save_format='jpeg'):
# 执行21次
i += 1
if i > 20:
break
由同一张图片,进行随机的变换,如上述平移、放大、旋转等等,通过这样的方式可以对数据集进行扩大,从而提升模型效果
2 猫狗分类-简单CNN
使用keras要将需要的层、优化器等先进行定义。就如下,需要用到卷积层、池化层、激活函数、优化器等等。
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.optimizers import Adam
from keras.preprocessing.image import ImageDataGenerator
import os
模型搭建思路:
参考:https://www.it610.com/article/1280168264202207232.htm
开始定义网络模型,要先再前面加Sequential(),先进行卷积的操作,卷积需要传入的参数是(图片的长、图片的宽、图片的通道数),再设置filters滤波器的个数(32)和大小(3*3),用samepadding的方法,可以理解为输入图像和输出图像的大小都相同,再进行一次卷积,再进行一次2x2的池化操作,随后再进行卷积和池化操作,最后用到flatten,就是打平,让数据成1维的,这里要定义一个dropout为0.5,就是一半的神经元不进行工作,因为是二分类问题,最后输出是两个,激活函数用到softmax。再定义优化器,在训练过程中以accuracy为指标计算准确率。


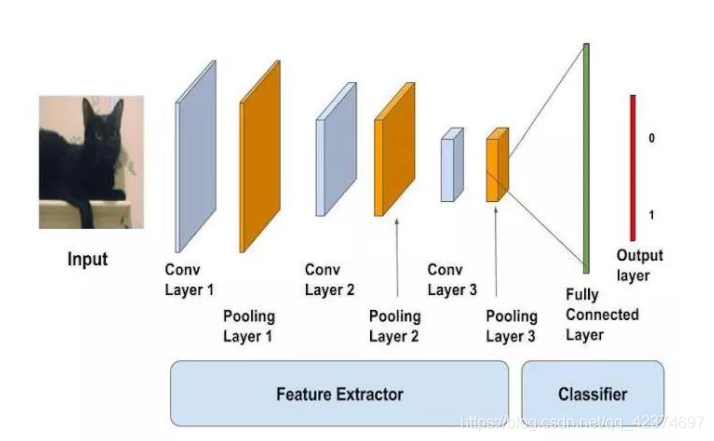


# 定义模型
#定义第一个卷积层
#input_shape输入平面
#filters 卷积核/滤波器个数
#kernel_size 卷积窗口的大小
#strides步长
#padding padding方式same/valid
#activation激活函数
# 卷积->卷积->池化->卷积->卷积->池化->卷积->卷积->池化->Flatten(打平)->Dropout(参数正则化方法)->全连接->全连接
model = Sequential()
model.add(Convolution2D(input_shape=(150,150,3), filters=32, kernel_size=3, strides=1, padding='same', activation = 'relu'))
model.add(Convolution2D(filters=32, kernel_size=3, strides=1, padding='same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=2, strides=2, padding='valid'))
model.add(Convolution2D(filters=64, kernel_size=3, strides=1, padding='same', activation = 'relu'))
model.add(Convolution2D(filters=64, kernel_size=3, strides=1, padding='same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=2, strides=2, padding='valid'))
model.add(Convolution2D(filters=128, kernel_size=3, strides=1, padding='same', activation = 'relu'))
model.add(Convolution2D(filters=128, kernel_size=3, strides=1, padding='same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=2, strides=2, padding='valid'))
model.add(Flatten())
model.add(Dense(64,activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(2,activation = 'softmax'))
# 定义优化器
adam = Adam(lr=1e-4)
# 定义优化器,loss function,训练过程中计算准确率
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()

参考:
随后再对训练数据进行一系列数据增加的操作,因为本身图片就不是很多,可以通过一些旋转、平移这样的操作使训练的数据更多一点。而测试集就用训练就只用进行归一化操作就可以了。
# 训练集数据生成,训练需要图片更加的多样,所以可以进行随机变换
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 测试集数据处理,测试集不需要随机变换,做归一化进行
test_datagen = ImageDataGenerator(rescale=1./255)
# flow_from_directory:
# * directory: 目标文件夹路径,对于每一个类,该文件夹都要包含一个子文件夹.子文件夹中任何JPG、PNG、BNP、PPM的图片都会被生成器使用.详情请查看此脚本
# * target_size: 整数tuple,默认为(256, 256). 图像将被resize成该尺寸
# * color_mode: 颜色模式,为"grayscale","rgb"之一,默认为"rgb".代表这些图片是否会被转换为单通道或三通道的图片.
# * classes: 可选参数,为子文件夹的列表,如['dogs','cats']默认为None. 若未提供,则该类别列表将从directory下的子文件夹名称/结构自动推断。每一个子文件夹都会被认为是一个新的类。(类别的顺序将按照字母表顺序映射到标签值)。通过属性class_indices可获得文件夹名与类的序号的对应字典。
# * class_mode: "categorical", "binary", "sparse"或None之一. 默认为"categorical. 该参数决定了返回的标签数组的形式, "categorical"会返回2D的one-hot编码标签,"binary"返回1D的二值标签."sparse"返回1D的整数标签,如果为None则不返回任何标签, 生成器将仅仅生成batch数据, 这种情况在使用model.predict_generator()和model.evaluate_generator()等函数时会用到.
# * batch_size: batch数据的大小,默认32
# * shuffle: 是否打乱数据,默认为True
# * seed: 可选参数,打乱数据和进行变换时的随机数种子
# * save_to_dir: None或字符串,该参数能让你将提升后的图片保存起来,用以可视化
# * save_prefix:字符串,保存提升后图片时使用的前缀, 仅当设置了save_to_dir时生效
# * save_format:"png"或"jpeg"之一,指定保存图片的数据格式,默认"jpeg"
# * flollow_links: 是否访问子文件夹中的软链接
# 批次,32张图片
batch_size = 32
# 生成训练数据
# flow_from_directory从哪一个文件中获取文件
train_generator = train_datagen.flow_from_directory(
'image/train', # 训练数据路径
target_size=(150, 150), # 获取图片的时候,可以设置图片大小,统一大小
batch_size=batch_size # 批次大小
)
# 测试数据
test_generator = test_datagen.flow_from_directory(
'image/test', # 训练数据路径
target_size=(150, 150), # 设置图片大小
batch_size=batch_size # 批次大小
)
'''
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
'''
# 统计文件个数
totalFileCount = sum([len(files) for root, dirs, files in os.walk('image/train')])
totalFileCount
# 训练模型
model.fit_generator(
train_generator, # 生成的训练数据,每一次拿32张图片来训练,图片的大小是统一的
steps_per_epoch=totalFileCount/batch_size, # 每一次迭代有多少个小的步骤
epochs=50, # 迭代次数,即所有的数据需要循环多少次
validation_data=test_generator, # 测试数据,一遍训练一遍测试
validation_steps=1000/batch_size,
)
# 保存模型
# 注意要保存模型必须要先 pip install h5py
model.save('CNN1.h5')
模型结果
Epoch 1/50
63/62 [==============================] - 32s - loss: 0.6924 - acc: 0.5149 - val_loss: 0.6914 - val_acc: 0.5015
Epoch 2/50
63/62 [==============================] - 26s - loss: 0.6904 - acc: 0.5278 - val_loss: 0.6943 - val_acc: 0.5036
Epoch 3/50
63/62 [==============================] - 25s - loss: 0.6836 - acc: 0.5580 - val_loss: 0.6701 - val_acc: 0.6240
Epoch 4/50
63/62 [==============================] - 25s - loss: 0.6472 - acc: 0.6181 - val_loss: 0.6147 - val_acc: 0.6804
Epoch 5/50
63/62 [==============================] - 26s - loss: 0.6037 - acc: 0.6835 - val_loss: 0.6105 - val_acc: 0.6438
Epoch 6/50
63/62 [==============================] - 26s - loss: 0.5839 - acc: 0.7004 - val_loss: 0.5730 - val_acc: 0.6880
Epoch 7/50
63/62 [==============================] - 26s - loss: 0.5630 - acc: 0.7088 - val_loss: 0.5991 - val_acc: 0.6657
Epoch 8/50
63/62 [==============================] - 26s - loss: 0.5660 - acc: 0.7108 - val_loss: 0.5501 - val_acc: 0.7073
Epoch 9/50
63/62 [==============================] - 25s - loss: 0.5365 - acc: 0.7326 - val_loss: 0.5334 - val_acc: 0.7205
Epoch 10/50
63/62 [==============================] - 26s - loss: 0.5426 - acc: 0.7287 - val_loss: 0.5647 - val_acc: 0.7033
Epoch 11/50
63/62 [==============================] - 25s - loss: 0.5241 - acc: 0.7460 - val_loss: 0.5187 - val_acc: 0.7353
Epoch 12/50
63/62 [==============================] - 25s - loss: 0.5303 - acc: 0.7346 - val_loss: 0.5285 - val_acc: 0.7302
Epoch 13/50
63/62 [==============================] - 26s - loss: 0.5014 - acc: 0.7564 - val_loss: 0.5305 - val_acc: 0.7215
Epoch 14/50
63/62 [==============================] - 26s - loss: 0.4936 - acc: 0.7560 - val_loss: 0.5051 - val_acc: 0.7485
Epoch 15/50
63/62 [==============================] - 26s - loss: 0.5121 - acc: 0.7490 - val_loss: 0.5169 - val_acc: 0.7353
Epoch 16/50
63/62 [==============================] - 25s - loss: 0.4966 - acc: 0.7698 - val_loss: 0.5030 - val_acc: 0.7480
Epoch 17/50
63/62 [==============================] - 25s - loss: 0.4938 - acc: 0.7599 - val_loss: 0.5422 - val_acc: 0.7246
Epoch 18/50
63/62 [==============================] - 25s - loss: 0.4897 - acc: 0.7718 - val_loss: 0.5224 - val_acc: 0.7327
Epoch 19/50
63/62 [==============================] - 26s - loss: 0.4770 - acc: 0.7679 - val_loss: 0.4940 - val_acc: 0.7520
Epoch 20/50
63/62 [==============================] - 25s - loss: 0.4715 - acc: 0.7718 - val_loss: 0.4982 - val_acc: 0.7464
Epoch 21/50
63/62 [==============================] - 25s - loss: 0.4626 - acc: 0.7768 - val_loss: 0.5061 - val_acc: 0.7414
Epoch 22/50
63/62 [==============================] - 25s - loss: 0.4636 - acc: 0.7912 - val_loss: 0.4913 - val_acc: 0.7515
Epoch 23/50
63/62 [==============================] - 25s - loss: 0.4629 - acc: 0.7818 - val_loss: 0.5016 - val_acc: 0.7419
Epoch 24/50
63/62 [==============================] - 25s - loss: 0.4483 - acc: 0.8001 - val_loss: 0.4811 - val_acc: 0.7536
Epoch 25/50
63/62 [==============================] - 25s - loss: 0.4518 - acc: 0.7867 - val_loss: 0.5112 - val_acc: 0.7444
Epoch 26/50
63/62 [==============================] - 25s - loss: 0.4482 - acc: 0.7852 - val_loss: 0.4830 - val_acc: 0.7581
Epoch 27/50
63/62 [==============================] - 25s - loss: 0.4361 - acc: 0.8046 - val_loss: 0.4781 - val_acc: 0.7602
Epoch 28/50
63/62 [==============================] - 25s - loss: 0.4280 - acc: 0.8090 - val_loss: 0.4886 - val_acc: 0.7546
Epoch 29/50
63/62 [==============================] - 25s - loss: 0.4279 - acc: 0.7981 - val_loss: 0.4700 - val_acc: 0.7724
Epoch 30/50
63/62 [==============================] - 25s - loss: 0.4392 - acc: 0.8016 - val_loss: 0.4788 - val_acc: 0.7607
Epoch 31/50
63/62 [==============================] - 25s - loss: 0.4114 - acc: 0.8100 - val_loss: 0.4757 - val_acc: 0.7647
Epoch 32/50
63/62 [==============================] - 26s - loss: 0.4011 - acc: 0.8199 - val_loss: 0.4643 - val_acc: 0.7729
Epoch 33/50
63/62 [==============================] - 25s - loss: 0.4005 - acc: 0.8189 - val_loss: 0.4648 - val_acc: 0.7688
Epoch 34/50
63/62 [==============================] - 26s - loss: 0.3971 - acc: 0.8155 - val_loss: 0.4813 - val_acc: 0.7729
Epoch 35/50
63/62 [==============================] - 25s - loss: 0.4074 - acc: 0.8100 - val_loss: 0.4759 - val_acc: 0.7642
Epoch 36/50
63/62 [==============================] - 25s - loss: 0.3927 - acc: 0.8205 - val_loss: 0.4515 - val_acc: 0.7851
Epoch 37/50
63/62 [==============================] - 25s - loss: 0.3911 - acc: 0.8363 - val_loss: 0.4660 - val_acc: 0.7652
Epoch 38/50
63/62 [==============================] - 25s - loss: 0.3686 - acc: 0.8294 - val_loss: 0.4506 - val_acc: 0.7820
Epoch 39/50
63/62 [==============================] - 25s - loss: 0.3826 - acc: 0.8239 - val_loss: 0.4664 - val_acc: 0.7663
Epoch 40/50
63/62 [==============================] - 25s - loss: 0.3718 - acc: 0.8358 - val_loss: 0.4859 - val_acc: 0.7693
Epoch 41/50
63/62 [==============================] - 26s - loss: 0.3571 - acc: 0.8393 - val_loss: 0.5383 - val_acc: 0.7546
Epoch 42/50
63/62 [==============================] - 25s - loss: 0.3616 - acc: 0.8358 - val_loss: 0.4610 - val_acc: 0.7658
Epoch 43/50
63/62 [==============================] - 25s - loss: 0.3520 - acc: 0.8418 - val_loss: 0.4869 - val_acc: 0.7800
Epoch 44/50
63/62 [==============================] - 25s - loss: 0.3470 - acc: 0.8428 - val_loss: 0.4718 - val_acc: 0.7739
Epoch 45/50
63/62 [==============================] - 25s - loss: 0.3396 - acc: 0.8438 - val_loss: 0.4563 - val_acc: 0.7983
Epoch 46/50
63/62 [==============================] - 25s - loss: 0.3557 - acc: 0.8472 - val_loss: 0.4882 - val_acc: 0.7581
Epoch 47/50
63/62 [==============================] - 25s - loss: 0.3536 - acc: 0.8378 - val_loss: 0.4922 - val_acc: 0.7739
Epoch 48/50
63/62 [==============================] - 25s - loss: 0.3374 - acc: 0.8512 - val_loss: 0.4647 - val_acc: 0.7851
Epoch 49/50
63/62 [==============================] - 25s - loss: 0.3285 - acc: 0.8571 - val_loss: 0.4582 - val_acc: 0.7815
Epoch 50/50
63/62 [==============================] - 25s - loss: 0.3189 - acc: 0.8646 - val_loss: 0.4819 - val_acc: 0.7830
最后,可以通过一张图片,再次测试一下分类效果
from keras.models import load_model
import numpy as np
label = np.array(['cat','dog'])
# 载入模型
model = load_model('CNN1.h5')
# 导入图片
image = load_img('image/test/cat/cat.1002.jpg')
image
对图片进行重置大小、归一化、再转成np.array类型,添加一个维度,放到网络中进行预测,得到结果。
image = image.resize((150,150))
image = img_to_array(image)
image = image/255
image = np.expand_dims(image,0)
print(label[model.predict_classes(image)])
3 VGG16-bottleneck实现猫狗分类
使用 VGG16 来完成猫狗分类
VGG16网络在图片分类中效果不错
卷积神经网络VGG16详解
深度学习笔记(六)–VGG16网络

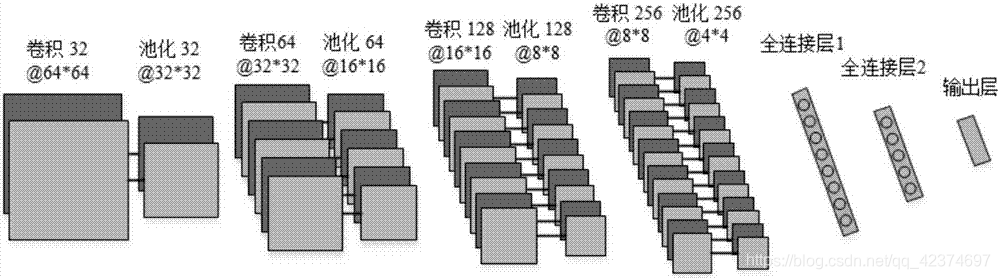
VGG16模型是用imagenet数据集训练出来的模型,保证了图像分类的效果,我们可以在这个模型的基础上,来训练我们自己的网络。
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense
from keras.optimizers import Adam
# 载入预训练的VGG16模型,不包括全连接层
model = VGG16(weights='imagenet', include_top=False)
导入VGG16的模型,只是这里include_top是false,就是不会用到全连接,而且全连接上参数很多。
也就是说
载入预训练的VGG16模型,不包括全连接层,只要卷积层和池化层。include_top 里面的top指这个网络的全连接层,如果是True则包含全连接层,
这里前面的卷积层和池化层部分参数是由imagenet数据集训练出来的,主要是对图像进行特征抽取,可以认为其图像特征抽取的效果是不错的,可以拿过来应用到自己的应用中,但是其训练出来的全连接层参数众多,且imagenet数据集中分类数较多,而这里只有两个种类,所以对于全连接层的部分不适用这里的应用,因此可以自己设计全连接成,重新训练。
总的来说,就是图形特征抽取部分使用VGG16的模型中卷积层和池化层,图像分类部分使用自定义全连接层,重新训练
参考:https://www.it610.com/article/1280168264202207232.htm
既然用不到vgg的全连接,就只有自己写一个全连接,全连接就是将vgg16模型最后输出的维度的最后三个,不取第一个batch拿出来,打平,加上激活函数,dropout,最后网络还是二分类,再用softmax。我们的模型是采用vgg16的前面几层,和最后几层自己定义的全连接层。
model.summary()
用summary看一下网络结构
两个卷积层+池化层
两个卷积层+池化层
三个卷积层+池化层
三个卷积层+池化层
三个卷积层+池化层
就是卷积层和池化层的组合

数据量较小,可以进行 数据增强
datagen = ImageDataGenerator(
rotation_range = 40, # 随机旋转角度
width_shift_range = 0.2, # 随机水平平移
height_shift_range = 0.2, # 随机竖直平移
rescale = 1./255, # 数值归一化
shear_range = 0.2, # 随机裁剪
zoom_range =0.2, # 随机放大
horizontal_flip = True, # 水平翻转
fill_mode='nearest') # 填充方式
batch_size = 32
#
train_steps = int((2000 + batch_size - 1)/batch_size)*10
test_steps = int((1000 + batch_size - 1)/batch_size)*10
generator = datagen.flow_from_directory(
'image/train',
target_size=(150, 150),
batch_size=batch_size,
class_mode=None, # 不生成标签
shuffle=False) # 不随机打乱
# 得到预测集数据
bottleneck_features_test = model.predict_generator(generator, test_steps)
print(bottleneck_features_test.shape)
'''
Found 2000 images belonging to 2 classes.
(20000, 4, 4, 512)
Found 1000 images belonging to 2 classes.
(10000, 4, 4, 512)
'''
# 保存测试集bottleneck结果
np.save(open('bottleneck_features_test.npy', 'wb'), bottleneck_features_test)
generator 得到很多图片,将得到的图片放到VGG16的模型中进行处理,即用该模型的卷积层和池化层进行图形特征抽取,因为我们没有要全连接层,所以最后输出的是池化层的结果,不是最后分类的结果,如下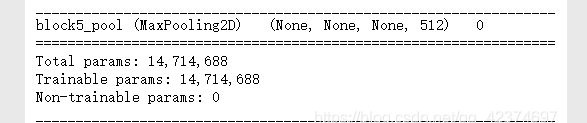
每一张图片经过处理都会得到一个新的结果,将最后一个池化层的结果保存下来,作为一个新的训练数据
载入新的数据,并定义标签
train_data = np.load(open('bottleneck_features_train.npy','rb'))
#the features were saved in order, so recreating the labels is easy
labels = np.array([0] * 1000 + [1] * 1000)
train_labels = np.array([])
for _ in range(10):
train_labels=np.concatenate((train_labels,labels))
test_data = np.load(open('bottleneck_features_test.npy','rb'))
labels = np.array([0] * 500 + [1] * 500)
test_labels = np.array([])
for _ in range(10):
test_labels=np.concatenate((test_labels,labels))
train_labels = np_utils.to_categorical(train_labels,num_classes=2) # 分类问题需要编码
test_labels = np_utils.to_categorical(test_labels,num_classes=2)
接下来,用自己搭建的连接层来训练这个新的数据
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:])) # 扁平化
model.add(Dense(256, activation='relu')) # 256个神经元
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax')) #两个分类
# 定义优化器
adam = Adam(lr=1e-4)
# 定义优化器,loss function,训练过程中计算准确率
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
# 迭代20次
model.fit(train_data, train_labels,
epochs=20, batch_size=batch_size,
validation_data=(test_data, test_labels))
model.save_weights('bottleneck_fc_model.h5')
这里训练只有全连接层,没有卷积层和池化层,所以训练时间较快
训练的准确率也较高

len(model.layers) # 19
4 VGG16-Finetune实现猫狗分类
和上一个思路大同小异,载入预训练的VGG16模型时,不包括全连接层,只要卷积层和池化层
前面的是固定卷积层和池化层,不做调整
这里是可以对卷积层和池化层进行微调
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense
from keras.optimizers import SGD
import os
# 载入预训练的VGG16模型,不包括全连接层
vgg16_model = VGG16(weights='imagenet', include_top=False, input_shape=(150,150,3))
# 搭建全连接层
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# 载入前面训练过的权值
top_model.load_weights('bottleneck_fc_model.h5')
model = Sequential()
model.add(vgg16_model) # 模型前面部分依然使用Vgg16中的卷积层和池化层
model.add(top_model) # 模型后面部分使用自己训练好的全连接层
# 训练集数据生成
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 测试集数据处理
test_datagen = ImageDataGenerator(rescale=1./255)
batch_size = 32
# 生成训练数据
train_generator = train_datagen.flow_from_directory(
'image/train', # 训练数据路径
target_size=(150, 150), # 设置图片大小
batch_size=batch_size # 批次大小
)
# 测试数据
test_generator = test_datagen.flow_from_directory(
'image/test', # 训练数据路径
target_size=(150, 150), # 设置图片大小
batch_size=batch_size # 批次大小
)
'''
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
'''
# 编译
model.compile(loss='categorical_crossentropy',
optimizer=SGD(lr=1e-4, momentum=0.9), #随机梯度下降
metrics=['accuracy'])
# 统计文件个数
totalFileCount = sum([len(files) for root, dirs, files in os.walk('image/train')])
model.fit_generator(
train_generator,
steps_per_epoch=totalFileCount/batch_size,
epochs=10,
validation_data=test_generator,
validation_steps=1000/batch_size,
)
因为同时训练了卷积层、池化层、全连接层,所以训练时间很长




最后得到的准确率有94.21%
还可参考:
CNN神经网络猫狗分类经典案例,画出count个预测结果和图像,把整个过程封装为函数

一站式 AI 云服务平台
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)