
【深度学习语义分割常用数据集介绍】--ADE20K
ADE20k拥有超过25,000张图像(20K for train,2K for val,3K for test),这些图像用开放字典标签集密集注释。
·

之前在文章深度学习语义分割常用数据集介绍中介绍了常用的语义分割数据集,本文将详细介绍其中ADE20K的详细内容及使用方法:=
ADE20K 数据集是 2016 年 MIT 开放的场景理解的数据集,可用于实例分割,语义分割和零部件分割。利用图像信息进行场景理解 scene understanding 和 scene parsing。
本文目录
1. 数据集简介
数据集体量:
ADE20k拥有超过25,000张图像(20K for train,2K for val,3K for test),这些图像用开放字典标签集密集注释。
数据集类别:
150个类别,前20%的类别占比80%: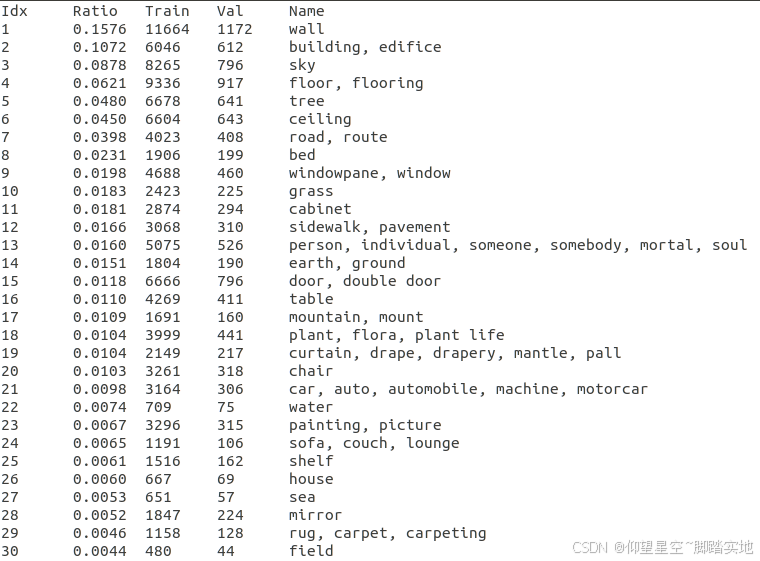
2. 数据集下载
官网下载链接:ADE20K官网
3. 数据集结构解析

ADE20K数据集结构比较简单:
包含:
原图(images文件夹)
标签(annotations文件夹)
类别列表及所占比例(objectInfo150.txt)
场景目录(sceneCateglories.txt)
其他链接:
https://github.com/CSAILVision/semantic-segmentation-pytorch
Scene Parsing web demo

一站式 AI 云服务平台
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)