
计算机视觉课程设计:基于SSD、Dlib多进程目标检测的对比研究
计算机视觉课程设计
1. 需求分析
(1)系统的输入为含有人类活动的原始视频文件,格式为mp4;
(2)系统的输出为经过算法处理检测出的视频文件(在窗口中对比显示并保存到本地),包括用原始算法处理和用多进程处理之后的视频文件,同时输出各个视频在处理时所用的时间和帧率。
(3)系统实现的功能:通过训练好的模型,检测识别出视频文件的识别目标,并随着目标的移动实现跟踪功能。并通过多进程实现算法效率上的提升。
2. 概要设计
2.1 基本要求
2.1.1 界面设计方案
UI设计通过Tkinter库实现,系统的主界面主要包括三个部分:3个视频播放的小窗口,1个打开文件的输入按钮,以及记录视频文件地址、视频读取时间和帧率的7个Entry文本框。
通过打开按钮选择需要处理的视频文件,然后在界面的窗口上分别显示原视频,经过算法处理的视频,以及通过多进程实现算法的处理之后的视频。在文本框中分别显示各个视频的处理时间和帧率,并显示出所处理的视频文件的地址。最后通过不同方法对比分析出各自方法的优缺点以及原因。
2.1.2 算法方案及原理
SSD算法,英文全名是Single Shot MultiBox Detector。主要采用的是one-stage方法:其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本不均衡,导致模型准确度稍低。
SSD是单阶段的目标检测算法,通过卷积神经网络进行特征提取,取不同的特征层进行检测输出,所以SSD是一种多尺度的检测方法。在需要检测的特征层,直接使用一个3*3卷积,进行通道的变换。SSD采用了anchor的策略,预设不同长宽比例的anchor,每一个输出特征层基于anchor预测多个检测框(4或者6)。采用了多尺度检测方法,在浅层用于检测小目标,深层用于检测大目标。不同算法的性能如图1所示。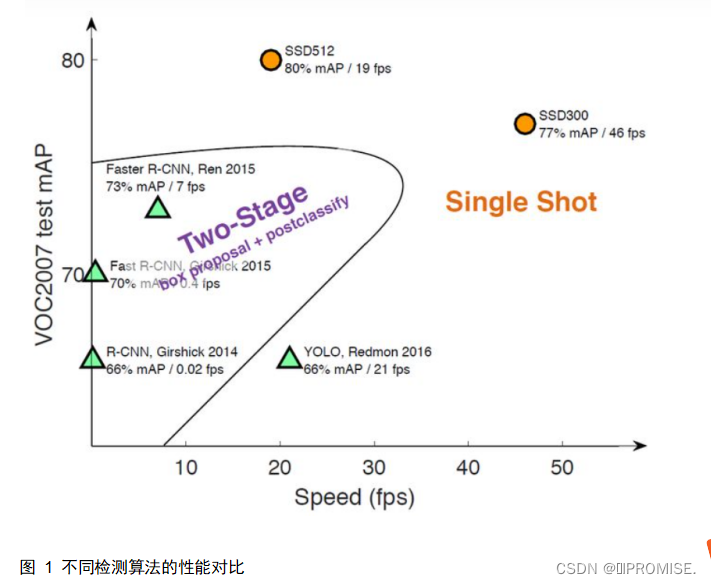
(1)网络结构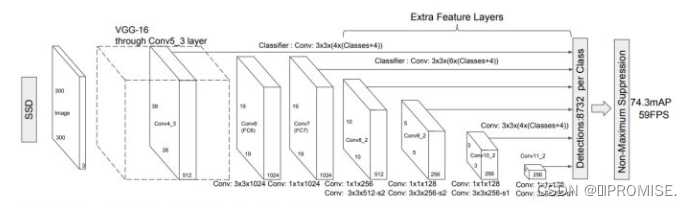
- SSD先通过卷积不断进行特征提取,在需要检测物体的网络,直接通过一个33卷积得到输出,卷积的通道数由anchor数量和类别数量决定,具体为(anchor数量(类别数量+4))。
- SSD对比了YOLO系列目标检测方法,不同的是SSD通过卷积得到最后的边界框,而YOLO对最后的输出采用全连接的形式得到一维向量,对向量进行拆解得到最终的检测框。
(2)核心思想
-
多尺度检测
在SSD的网络结构图中我们可以看到,SSD使用了多个特征层,特征层的尺寸分别是3838,1919,1010,55,33,11,一共6种不同的特征图尺寸。大尺寸特征图,使用浅层信息,预测小目标;小尺寸特征图,使用深层信息,预测大目标。多尺度检测的方式,可以使得检测更加充分(SSD属于密集检测),更能检测出小目标。 -
预设anchor
在SSD中,采用预设边界框,我们习惯称它为anchor(在SSD论文中叫default bounding boxes),预测框的尺寸在anchor的指导下进行微调。
如下图所示,两个网格上分别生成4个预测框,预测框的比例是基于anchor的,而anchor的比例又是在网络训练前预设定的。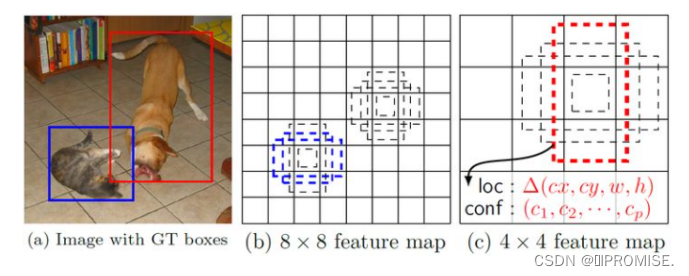
-
anchor的尺寸和长宽比
在SSD中,对于尺寸,文中计算的是相对于原图的缩放比例,称“scale”,scale的计算公式如下: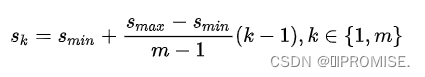
其中Smin 为0.2,Smax为0.9,m是使用的特征图个数6。将各个k值带入,即可求得各个特征图的缩放比例 Sk ,分别是0.2,0.34,0.48,0.62,0.76,0.9,将此缩放比例乘以输入图片的尺寸,即可得到anchor的尺寸。
对于长宽比,anchor设了5个比例,分别是 ar ∈ {1, 2, 3, 1/2, 1/3},由长宽比数值到anchor相对于原图的比例时,SSD是这样计算的 w = Sk a r \sqrt{ar} ar,h = Sk a r \sqrt{ar} ar,显然w/h就等于ar,这里的w和h就是anchor的长宽相对于原图的比例。除了5个长宽比例的anchor外,还会设置一个ar = 1,但是尺寸是S’k = S k S k + 1 \sqrt{SkSk+1} SkSk+1,也就是尺寸有变换,长宽比为1。
根据上面所论述,每个特征层有6种anchor,它们的长宽比分别是{1, 2, 3, 1/2, 1/3},但是在实现时,Conv4_3,Conv10_2和Conv11_2层(即第1、5、6特征层)仅使用4个先验框,它们不使用长宽比为1,1/3 的先验框。
6个特征层+4/6的先验框,那么能预测的框的个数为:
38 x 38 x 4 + 19 x 19 x 6 + 10 x 10 x 6 + 5 x 5 x 6 + 3 x 3 x 4 + 1 x 1 x 4 = 8752,所以SSD应该算是密集检测算法。 -
基于anchor的预测框尺寸计算
我们对每一个特征层建立了anchor,那么基于anchor如何计算预测框呢?简单来说,anchor怎么用到神经网络上去呢?
首先,根据原文,假设anchor的四个坐标值分别为{dcx, dcy, dw, dh} (注意上标不是指数的意思),分别表示anchor的中心点x坐标、y坐标、宽度w和高度h,真实框的坐标值是{gcx, gcy, gw, gh} ,那么anchor和真实框的偏移值计算公式是: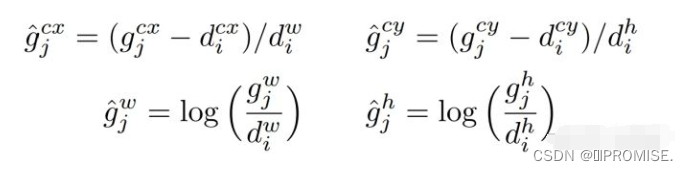
那么得到的四个 g’ ,就是真实框的偏移值,也就是ground truth,神经网络预测的四个坐标值 {lcx, lcy, lw, lh} 也是偏移值,在预测时,要通过以下公式从预测偏移值得到预测框: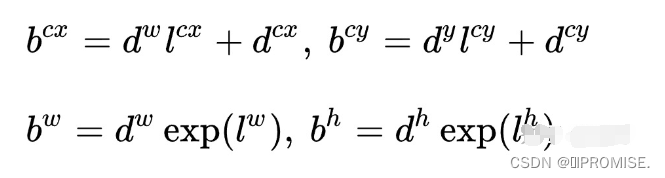
此外,每个单元grid的先验框中心分布在其中心,计算时,预测框的位置和尺寸是相对于先验框中心进行偏移。 -
数据增强
数据增强可以提高算法的鲁棒性,SSD算法中采用了以下几种数据增强的方法:
随机裁剪:随机裁剪一个部分,每个采样部分的大小为原图的[0.1,1],长宽比在1/2和2之间。如果真实标签框的中心位于采样部分内,则保留真实框与图片重叠的部分。
水平翻转:对采样后的小图片进行0.5概率的随机水平翻转
色域扭曲:对图片做一些光度扭曲方面的改变。
(3)训练策略
-
先验框匹配
在SDD中,是根据IOU的大小关系进行正负样本匹配的。下面介绍SSD的匹配方法。
SSD中先验框匹配有两个原则,要先满足原则一再满足原则二。
原则一: 对于每一个ground truth,选择所有先验框中IOU最大作为当前gt框的匹配框,也就是正样本。这种方式,保证每一个gt框都有先验框与之对应。
原则二: 对于剩余的未匹配先验框,若与某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配,如果有多个大于阈值,先验框只与IOU最大的那个gt框匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的,而先验框最多只能与一个gt框匹配。
经过原则一与二,若一个先验框依然没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。 -
难负例挖掘
尽管有了先验框匹配算法,但是先验框实在太多了,会存在过多的对梯度没有帮助的样本。因此,文中以Confidence_Loss对负样本排序,选择合适数量的负样本,以使得正负样本的比例是1:3。 -
损失函数
SSD的损失函数包括两部分的加权:位置损失函数和置信度损失函数。
总的损失函数是: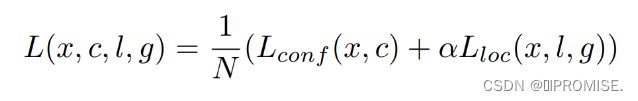
其中损失函数的第一部分是类别损失,第二部分是位置损失。N是匹配的先验框个数。
对于类别损失: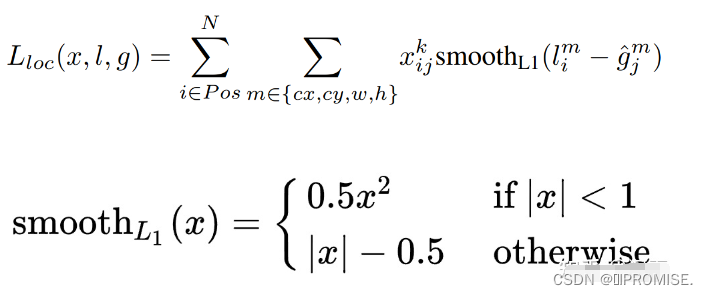
注意,其中的l和g都是相对位置编码值,而不是真实位置坐标。
对于置信度损失: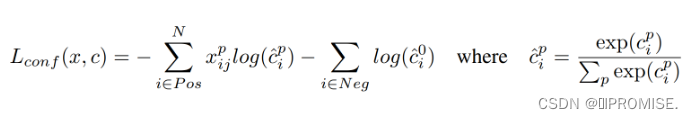
Xijp是指示函数,表示第i个先验框是否与真实框匹配,若匹配则为1,否则为0。
(4)训练过程总结
从一张300*300的图送入网络开始,整个网络的流程:
1.图片进入SSD算法。在数据预处理阶段,会对图片进行如随机裁剪、随机翻转、光度扭曲等变换,以提高数据集多样性。(一张变多张)
2.进入VGG主干网络进行特征提取。
3.在网络的末尾,也就是检测head部分,利用6个特征层进行预测。具体地,将6个特征层分别进行33卷积,通道数根据特征层顺序、anchor数、类别数进行变换。
4.将每一个特征层进行正负样本匹配。以shape是1441919的特征层为例,144是6(20+4),20是voc数据集类别种数,4是坐标偏移预测值,19是特征层的尺寸。也就是说,一张1919的grid的特征层中,每一个grid预测6个边界框,每个边界框的尺寸由4个预测值和anchor进行决定。每一个anchor的中心点在grid中心,尺寸大小有Sk缩放比例决定,对于1919特征层,S2为0.34,由S2求得6个anchor的长宽,再乘以图片尺寸300即可得到实际的长宽。
5.19*19特征层可以预测2166个边界框。根据匹配策略,将这2166个anchor(不是边界框)与gt框进行匹配,若匹配上则为正样本,否则为负样本。负样本还是太多,通过难负例挖掘,保留负样本中置信度损失较大的,使得正负样本比为1:3。
6.最后,正样本计算定位损失和类别损失,负样本计算类别损失。将得到的损失进行参数更新。最终,使得正样本的坐标不断接近gt坐标,类别置信率不断接近真实类别分布。
以上大部分转自https://zhuanlan.zhihu.com/p/33544892
3. 详细设计
使用SSD算法首先要用其已经训练好的模型,并把相应参数添加到pycharm中。
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--prototxt", required=True,
help="path to Caffe 'deploy' prototxt file")
ap.add_argument("-m", "--model", required=True,
help="path to Caffe pre-trained model")
ap.add_argument("-c", "--confidence", type=float, default=0.2,
help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
SSD的训练模型和python3.6以及python3.10的Dlib库的安装文件已上传到百度网盘:https://pan.baidu.com/s/1dvM6HEiCqe_QTqdE3UiScQ
提取码:L592
3.1 读取视频文件
传入参数分别表示视频地址,追踪时间变量,追踪帧率变量。
def origin_video(video_path, time_num1, fps_num1):
r_video = cv2.VideoCapture(video_path)
fourcc = cv2.VideoWriter_fourcc(*'XVID') # 视频编解码器
fps = r_video.get(cv2.CAP_PROP_FPS) # 帧数
width, height = int(r_video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(r_video.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 宽高
origin_out = cv2.VideoWriter('result1.mp4v', fourcc, fps, (width, height)) # 写入视频
print("reading origin video...")
start_origin = time.time()
fps = FPS().start()
while True:
ref, frame = r_video.read()
if ref == True:
origin_out.write(frame) #写入帧
else:
break
fps.update()
end_origin = time.time()
fps.stop()
time_origin = end_origin - start_origin
print("read successful...")
print("time_origin is :", time_origin)
time_num1.value = time_origin
fps_num1.value = float(format(fps.fps()))
cv2.destroyAllWindows()
r_video.release()
3.2 主进程与子进程之间的数据共享
Tkinter中通过StringVar()函数来对变量进行跟踪,因为使用多进程,一般情况下主进程与子进程不能进行数据共享。也就意味着即使我们在子进程中计算出来程序的运行时间以及处理帧率,我们写在主函数上的UI界面获取不到子进程的变量数值导致不能在UI上显示出来。
来看一个例子:
from multiprocessing import Process
import tkinter as tk
from tkinter import ttk
import cv2
def run_A():
num1 = "dog"
track1.set(num1)
p1 = Process(target=run_B)
p1.start()
p1.join()
def run_B():
num2 = 99.9
track2.set(num2)
if __name__ == '__main__':
win = tk.Tk()
track1 = tk.StringVar()
track2 = tk.StringVar()
ttk.Button(win, text='start', command=run_A, width=10).grid(row=0, column=0)
ttk.Entry(win, textvariable=track1, width=50).grid(row=0, column=1)
ttk.Entry(win, textvariable=track2, width=50).grid(row=0, column=2)
win.mainloop()
cv2.destroyAllWindows()
该代码中,我们用Tkinter创建了一个窗口,track1,track2分别为文本框Entry中的textvariable值,表示检测文本框值的变化,按钮用于触发函数执行代码。点击按钮,运行run_A函数,可以使用track1的set方法将num1的值填入文本框。同时创建并运行进程p1同步执行run_B函数,我们希望将num2的值填入第二个文本框。如图所示,第二个文本框并没有出现num2的值。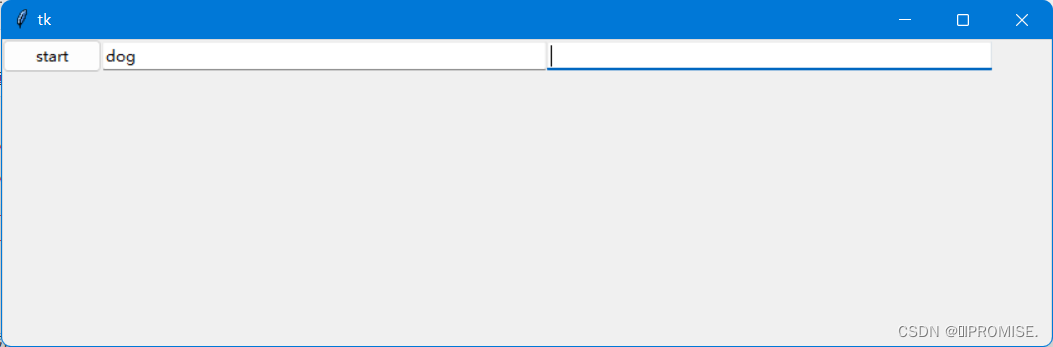
报错信息: NameError: name ‘track2’ is not defined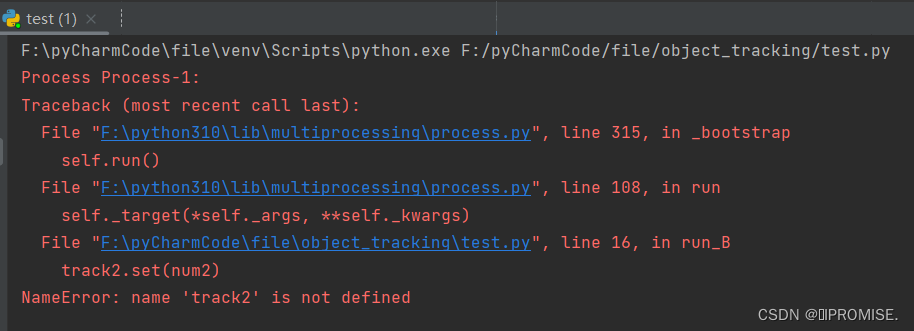
原因如上所说,就是主进程与子进程的数据共享问题。解决办法就是使用多进程 multiprocessing.Value() 的方法。该方法一般有两个参数,第一个参数为类型,为‘d’时表示为浮点型数字,第二个参数为该值的初始默认值。
上述代码改为:
import multiprocessing
from multiprocessing import Process
import tkinter as tk
from tkinter import ttk
import cv2
def run_A():
num1 = "dog"
track1.set(num1)
midnum = multiprocessing.Value("d", 0.0)
p1 = Process(target=run_B, args=(midnum, ))
p1.start()
p1.join()
track2.set(midnum.value)
def run_B(midnum):
num2 = 99.9
midnum.value = num2
if __name__ == '__main__':
win = tk.Tk()
track1 = tk.StringVar()
track2 = tk.StringVar()
ttk.Button(win, text='start', command=run_A, width=10).grid(row=0, column=0)
ttk.Entry(win, textvariable=track1, width=50).grid(row=0, column=1)
ttk.Entry(win, textvariable=track2, width=50).grid(row=0, column=2)
win.mainloop()
cv2.destroyAllWindows()
在run_A函数中使用multiprocessing.Value()定义一个中间值midnum,并在运行进程p1时将该变量作为参数传入,并将run_B中的num2赋值给midnum,注意用.value接收。此时就实现了主进程中的midnum与子进程中的num2的数据共享,然后在p1进程结束后使用track2的set方法将数值插入到文本框中(注意括号中是 .value )。
3.3 通过按钮打开本地文件选择视频
# 打开文件对话框
def getfile():
file_path = filedialog.askopenfilename()
fpath.set(file_path)
3.4 通过SSD算法处理视频
读取训练好的数据模型,将传入的视频文件一帧一帧的读取,如读取第一帧视频。
(1)先预处理视频:
先判断是否为最后一帧视频,确保最后能退出循环:if frame is None:break;
通过cv2处理视频的颜色通道,将BGR格式转化为RGB格式:cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)。
(2)检测追踪
定义列表trackers为空,检测每一帧图片判断该列表是否为空,为空时做处理:
获取该帧图像的宽高 (h, w) = frame.shape[:2] ,使用函数cv2.dnn.blobFromImage进行减均值,比例缩放,裁剪,交换通道等,返回一个4通道的blob(blob可以简单理解为一个N维的数组,用于神经网络的输入)。
在输入的该帧图像中通过循环判断检测出的物体的置信度是否大于我们设定的阈值,此步骤称为过滤。检测出之后将该项物体的id值与模型训练出的标签相对应。这里可以判断是否是我们需要的标签,不需要可以舍弃。
if confidence > args["confidence"]:
idx = int(detections[0, 0, i, 1])
label = CLASSES[idx]
# 只保留人的标签
if CLASSES[idx] != "person":
continue
然后获取该物体相对于图像在x,y上的距离以便用框进行追踪:
box = detections[] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
接下来利用dlib库实现追踪,将转换后的当前帧图像和位置信息(框)传入相应API函数:
t = dlib.correlation_tracker()
rect = dlib.rectangle(int(startX), int(startY), int(endX), int(endY))
t.start_track(rgb, rect)
这样就可以画出检测出的物体所在位置的矩形框了。
同时将当前的追踪对象填入初始时的trackers列表中并保存该对象的标签。
labels.append(label)
trackers.append(t)
在第一帧之后,算法已经检测出了很多个对象,接下来不再检测,而是进行跟踪。
首先需要更新当前帧的图像信息,然后获取每一个追踪对象在当前帧的位置,然后更新矩形框的位置从而实现追踪。
for (t, l) in zip(trackers, labels):
t.update(rgb)
pos = t.get_position()
# 得到位置
startX = int(pos.left())
startY = int(pos.top())
endX = int(pos.right())
endY = int(pos.bottom())
画出更新后的矩形框:
cv2.rectangle(frame, (startX, startY), (endX, endY),(0, 255, 0), 2)
cv2.putText(frame, l, (startX, startY - 15),cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 255, 0), 2)
3.5 使用多进程对比单进程算法的效率
在使用了SSD算法的前提下,我们知道每次检测某一帧图像时,要先判断其是否属于我们要检测的类别,然后通过Dlib库实现对每一帧的跟踪。通过使用多进程,或许我们可以提高代码运行的速率。
首先读取第一帧图像,检测出其类别和追踪器总数之后将其加入列表,通过循环我们可以得到第一帧图像的目标踪数n,并同时开启n个进程对目标进行检测,在接下来读入的每一帧中,不断的更新位置,n个进程同时不断的对目标进行跟踪。
3.5.1 创建输入q和输出q
iq = multiprocessing.Queue()
oq = multiprocessing.Queue()
inputQueues.append(iq)
outputQueues.append(oq)
3.5.2 多核
p = multiprocessing.Process(target=start_tracker, args=(bb, label, rgb, iq, oq))
p.daemon = True #主进程运行完不会检查子进程的状态是否执行完,直接结束进程
p.start()
3.5.3 多个追踪器处理的都是相同输入
for iq in inputQueues:
iq.put(rgb)
for oq in outputQueues:
# 得到更新结果
(label, (startX, startY, endX, endY)) = oq.get()
3.6 使用跟踪变量计算两种算法的时间以及帧率
在tkinter中使用tk.StringVar()对某些值进行跟踪,如定义原始视频地址跟踪变量file=tk.StringVar(),在按钮事件中绑定函数,并在文本框中传入该跟踪变量,在得到地址之后可以通过set方法将地址显示在UI界面的文本框中。在该项目中时间和帧率的显示也是通过该方法得到的。
fpath = tk.StringVar()ttk.Button(win, text='打开', command=getfile, width=10).grid(row=0, column=0)
ttk.Entry(win, textvariable=fpath, width=50).grid(row=0, column=1)
file_path = filedialog.askopenfilename()
fpath.set(file_path)
同时,原视频的读取,通过SSD算法处理的目标跟踪以及多进程实现的目标检测三个函数也是通过多进程一起执行的,这就大大提高了代码的速率了。
p1 = Process(target=origin_video, args=(file_path, time_num1,fps_num1))
p3 = Process(target=track_slow, args=(file_path, time_num3, fps_num3))
p4 = Process(target=track_fast, args=(file_path, time_num4, fps_num4))
p3.start()
p3.start()
p4.start()
3.7 界面布局
window_width = 1000
window_height = 750
image_width = int(960 * 0.5)
image_height = int(720 * 0.5)
imagepos_x = 0
imagepos_y = 0
butpos_x = 450
butpos_y = 450
'''布局'''
win = tk.Tk()
win.title('基于Dlib的视频目标检测')
win.geometry(str(window_width) + 'x' + str(window_height))
canvas1 = Canvas(win, bg='white', width=image_width, height=image_height)
canvas1.place(x=imagepos_x, y=30)
canvas2 = Canvas(win, bg='white', width=image_width, height=image_height)
canvas2.place(x=480, y=30)
canvas3 = Canvas(win, bg='white', width=image_width, height=image_height)
canvas3.place(x=imagepos_x, y=390)
canvas4 = Canvas(win, bg='white', width=image_width, height=image_height)
canvas4.place(x=480, y=390)
4. 实验结果与分析
4.1 实验结果
(1)视频文件的打开与地址的获取
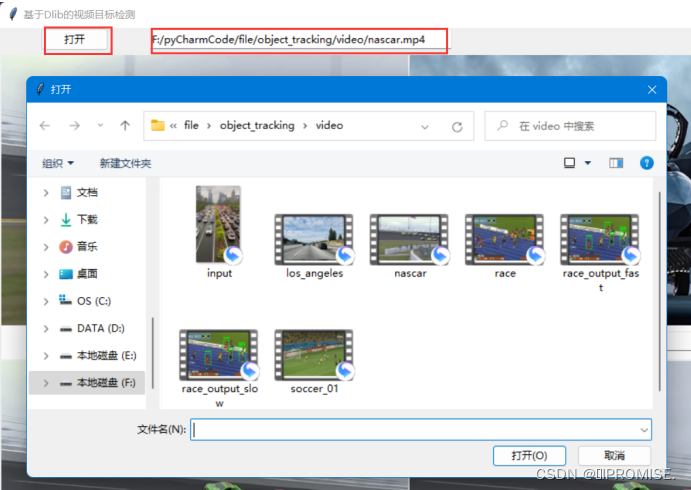
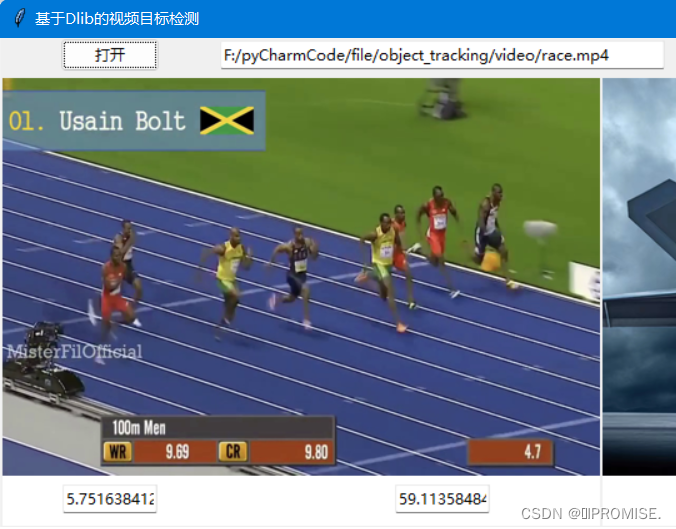
(2)原始视频的读取、显示以及时间率的统计
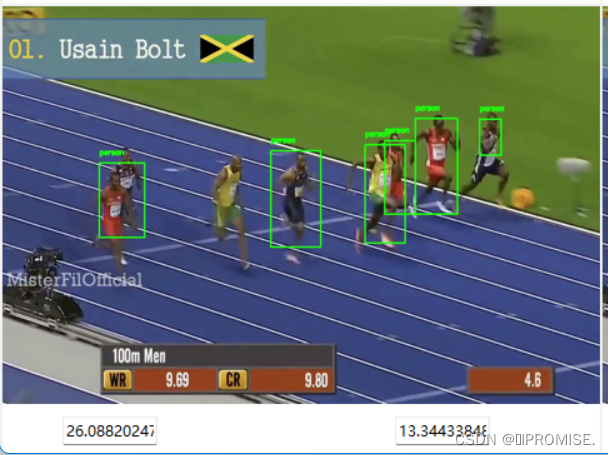
(3)通过SSD算法处理后视频的检测跟踪以及时间、帧率的统计
(4)通过多进程实现的视频目标跟踪以及时间帧率的统计

(5)整体效果
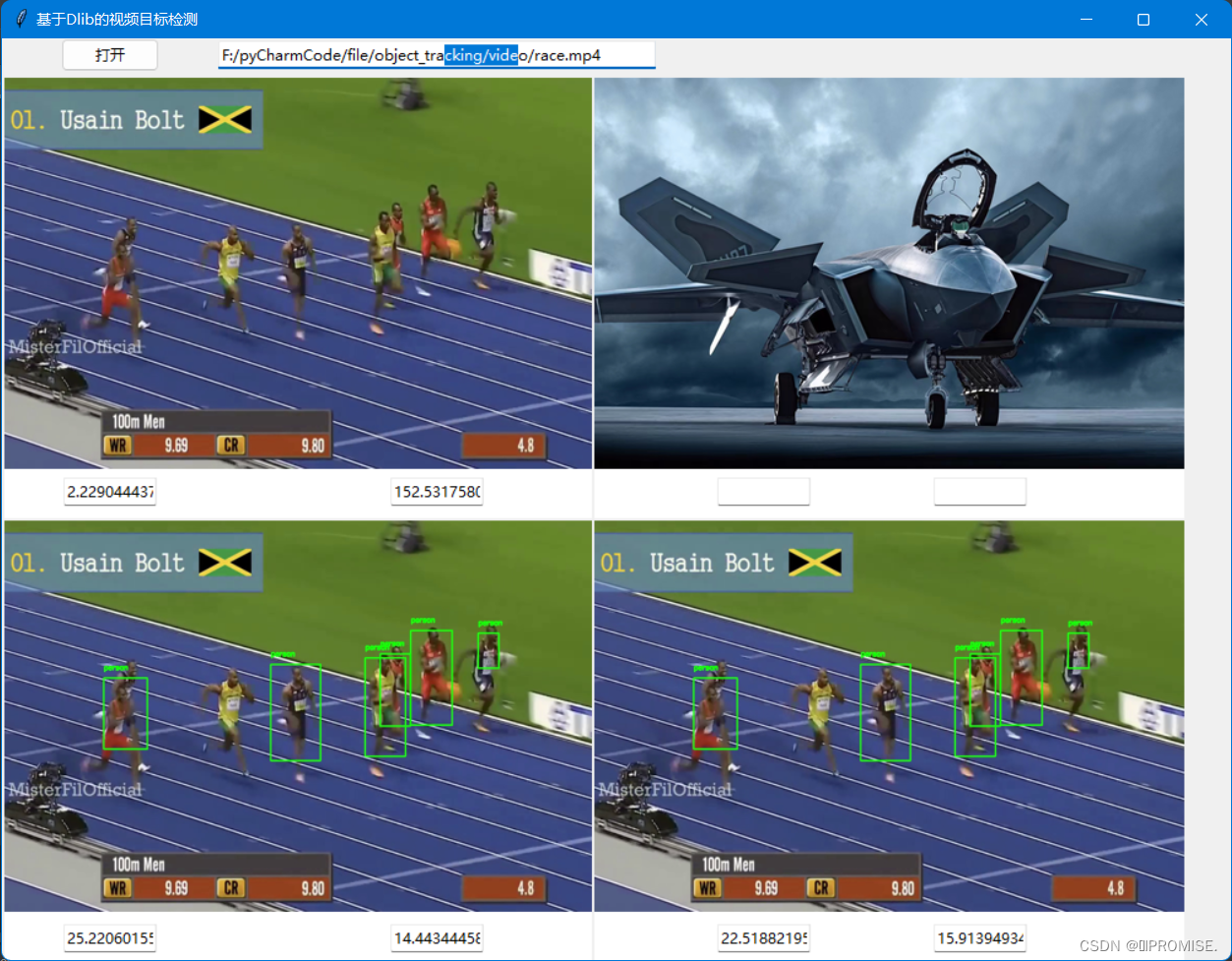
4.2 实验分析
通过多进程与单进程处理同一时长的视频的时间以及帧率的比较,发现多进程并没有明显提高时间效率以及帧率。当输入时间较长的视频文件时,多进程反而变得更慢了。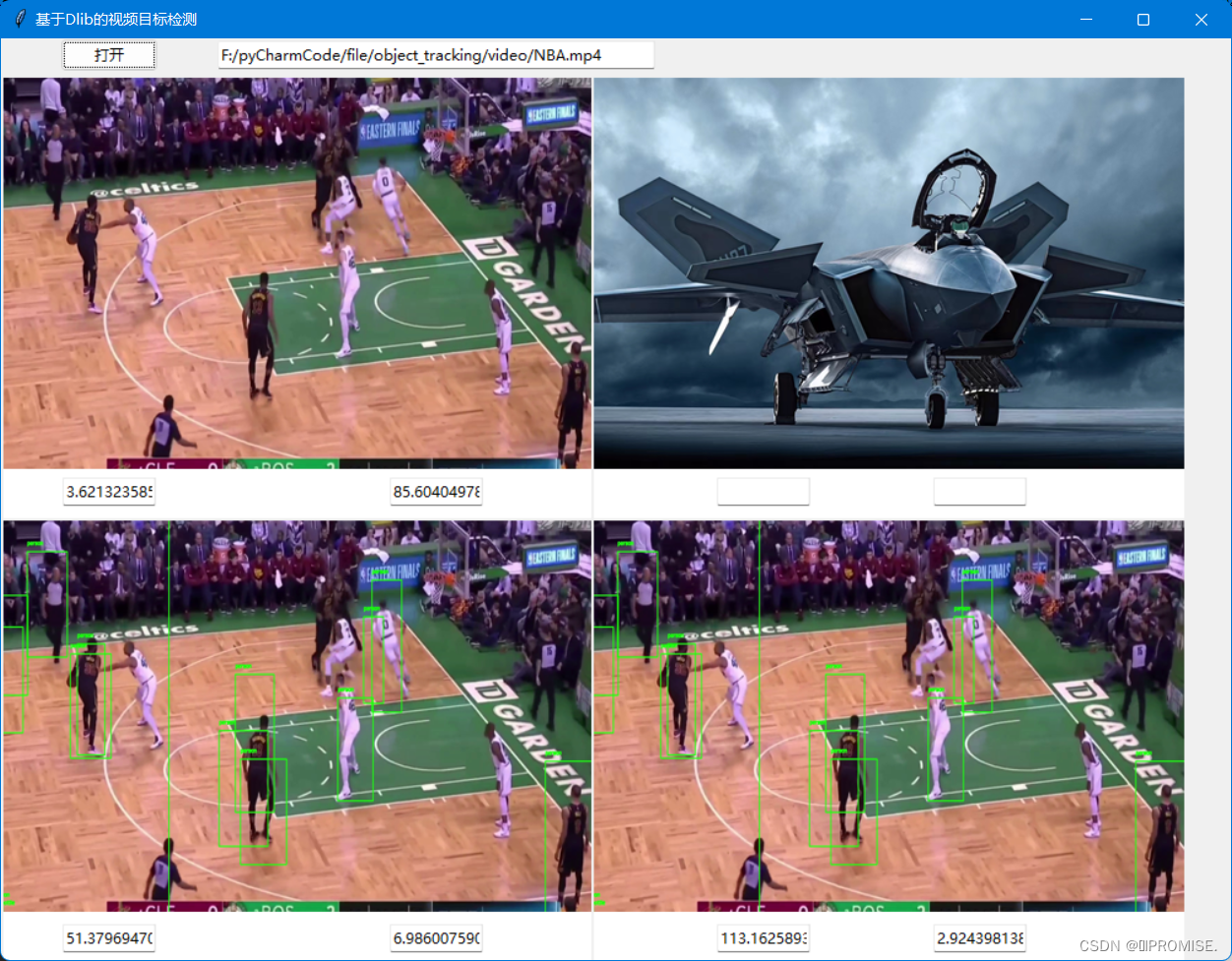
同时对同一视频的进行不同的尺度缩放(放大缩小),多进程处理算法后的效率也没有明显提高。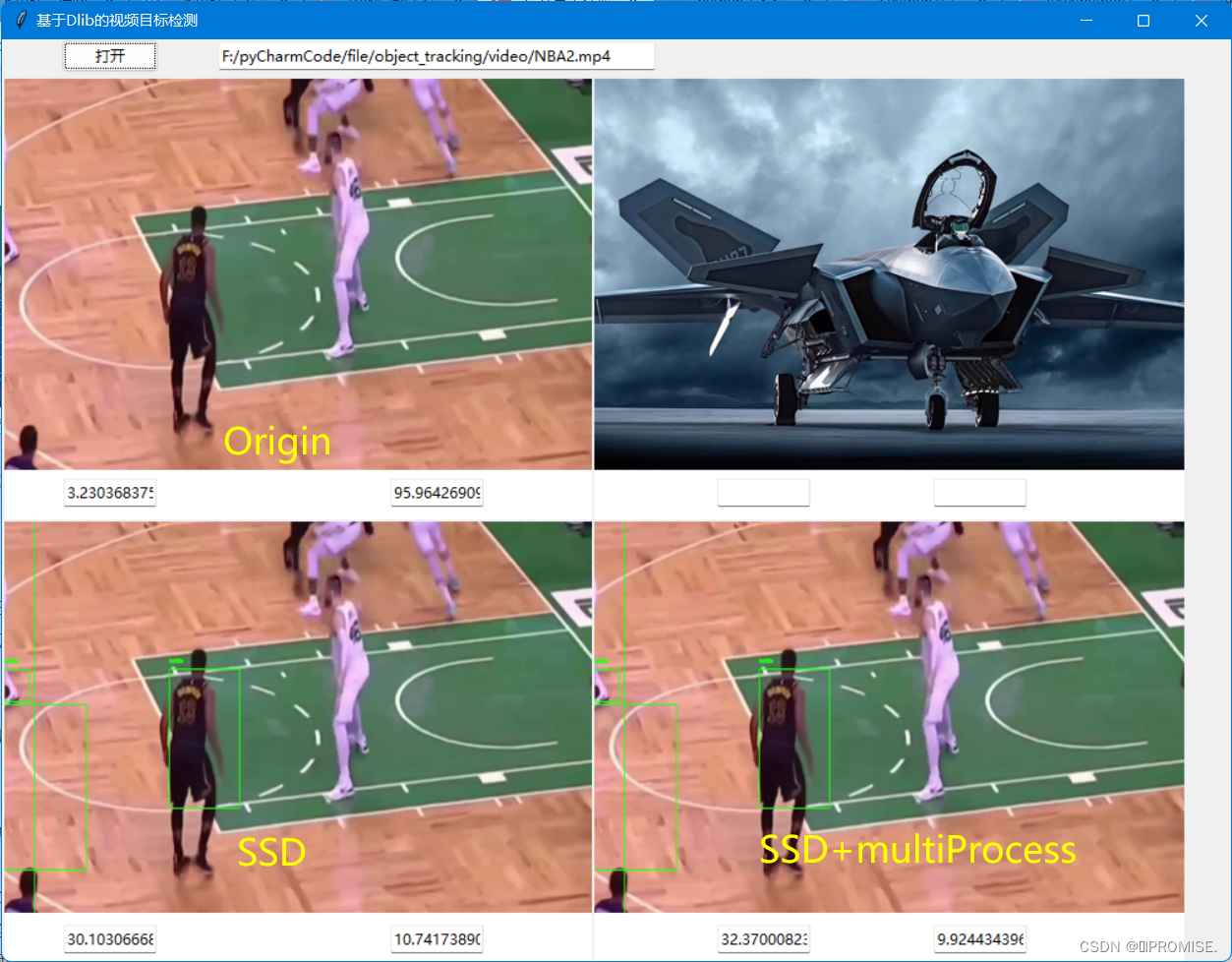
分析: 是否采用多任务需要考虑要处理任务的类型,一般有两种类型:计算密集型(CPU密集型)和 IO密集型。计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。计算密集型任务由于主要消耗CPU资源,因此代码运行效率至关重要。Python的脚本语言运行效率很低,不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。IO密集型任务执行期间,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
对于本项目而言,使用的是运行效率较低python语言,另外播放视频以及对视频处理等需要做解码等操作,不适合使用多进程来提升代码和算法的运行效率。处理视频需要重复循环多次的对视频进行逐帧的读取,可能属于IO密集型任务,使用多线程的方法可能会更好。同时,运行效率也与电脑的当前状态有很大关系。
总结:计算密集型任务适合使用多进程,IO密集型适合使用多线程。
5. 遇到的问题:
5.1 EOFError: Ran out of input.

在网上查了很多博客,有很多博主分析说是pickle.load()读取的文件为空导致,按照他们的改了也没有解决。最后看到一个博主说是Windows系统下python和多进程multiprocessing的一个Bug。所以说为什么很多博主说multiprocessing的代码要加在main()函数下。但是我在用pycharm开发项目时即使将multiprocessing的代码放在main里面依然发生了这个错误。
解决方法: 运行->编辑配置->使用python控制台运行(取消勾选)

5.2 No module named ‘dlib’.
解决方法: 安装dlib库
一般情况下,直接用pip命令导入该库会导致错误。
一般步骤:先安装cmake、boost 再安装dlib
- pip install cmake
- pip install boost
- pip install dlib
推荐方法: 到网上下载对应python版本的.whl文件,然后进行安装。
官网地址: http://dlib.net/#githubhttps://github.com/davisking/dlib
例如我是python3.10版本的,下载文件地址:https://github.com/jloh02/dlib/releases/download/v19.22/dlib-19.22.99-cp310-cp310-win_amd64.whl
下载完成后,cmd到下载.whl文件的目录:
安装命令 pip install + 文件全名(包括后缀):
pip install dlib-19.22.99-cp310-cp310-win_amd64.whl


一站式 AI 云服务平台
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)