
项目快过:MARCONet | 适用于文字识别的图像盲超分修复
论文地址:https://arxiv.org/pdf/2303.14726项目地址:https://github.com/csxmli2016/MARCONet发布时间:2023年4月22日盲文本图像超分辨率(SR)是一个挑战,因为人们需要应对不同的字体风格和未知的退化。为了解决这一问题,。尽管如此,。这个问题进一步复杂化了复杂结构的汉字,例如,。在这部工作中,我们提出了一个新颖的模型,更关注文字

论文地址:https://arxiv.org/pdf/2303.14726
项目地址:https://github.com/csxmli2016/MARCONet
发布时间:2023年4月22日
盲文本图像超分辨率(SR)是一个挑战,因为人们需要应对不同的字体风格和未知的退化。为了解决这一问题,现有的方法通过损失约束或中间特征条件,并行执行字符识别,以规范SR任务。尽管如此,当遇到严重的退化时,高水平的先验仍然可能失败。这个问题进一步复杂化了复杂结构的汉字,例如,将多个象形符号或表意符号组合成一个字符的汉字。在这部工作中,我们提出了一个新颖的模型,更关注文字结果。特别是,我们学会了在一个StyleGAN中封装丰富和多样的结构,并利用这种生成结构的先验进行恢复。
根据论文效果查看,属于效果较好的方法,但没有公布速度或flops信息。根据其网络结构图查看,含unet+resnt+transfoer block,应是属于推理较慢的模型
1、算法背景
1.1 盲图像超分
由于未知降解的复杂混合物,盲图像SR具有挑战性。最近的研究从退化估计和建立更现实的训练数据[两个方面来解决了这一问题。
前一种模式主要是估计退化模型参数,然后应用非盲SR方法,如ZSSR 等,基于退化模型将HR图片生成SR图片。
后者通过捕获真实世界的LR和HR对[4,70]或设计模仿真实世界的退化[28,33,66,75]的复杂的退化模型来构建训练对。
由于文本图像中的字符具有特定的语义结构,作者证明了仅仅使用精心设计的退化模型是无法实现良好的恢复性能。
1.2 文本图像超分
文本图像的SR已经被研究了多年。在传统的方法中,利用最大后验(MAP)[5]和贝叶斯框架[9]进行超解析文本图像。这些早期的方法无法产生高质量的结果。
1、Dong等[13]采用cnn(即SRCNN [12])进行文本图像SR,并在ICDAR 2015竞赛[49]中取得了良好的效果。
2、Xu等人[72]采用生成对抗网络(GAN)[17]来学习人脸和文本图像SR的类别特定先验,以及对多类GAN损失进行监督。
3、Mou等[44]提出将SR单元插入到退化文本图像的识别过程中。
4、Wang等人。[64]介绍了第一个真实世界的文本SR对(即,文本缩放),这是从RealSR [4]和SRRAW [77]中裁剪出来的。他们还通过合并双向LSTM来提出一个序列残差块来捕获序列信息,用于低水平重建。
…
上述许多方法要么将识别信息作为SR结果[7,8,50,79]上的损失函数,要么作为中间SR特征来提供高级指导[40,41]。虽然高级识别先验有助于提高文本的识别能力,但它在提供准确的结构和风格指导方面仍然有限,特别是对于某些结构复杂的文本。
在本研究中,我们发现生成结构先验有利于高质量的指导来恢复LR性状的忠实结构。
RealSR和SRRAW都被不同焦距的不同数码相机捕获,目的是在现实场景中收集自然的LR/HR对。该设置不是专门为文本图像而设计的
TextZoom数据集中的大多数HR文本图像的清晰度有限,这可能限制了SR性能,以他们的真相。
1.3 图像SR中的生成结构先验
图像结构先验在许多低层次的视觉任务中被证明是有效的,如深度图像增强[21,27,37]、图像嵌入绘画[11,46,52]和图像恢复[10,35,36,47]。最近,通过使用从预先训练的style[6,22,34,65,69,73][30,31]或码本[15]中获得的生成结构先验,盲脸修复取得了巨大的改进[6,22,34,65,69,73],这表明这种先验在生成逼真纹理方面比其他方法具有明显的优势。我们的研究是受到了这些方法的成功的启发。然而,为文本图像制作一个合适的结构先验比人脸图像更难。这是因为每个字符都有其独特的笔画,但可能有各种不同的字体样式。任何扭曲的、缺失的或额外的笔画都很容易改变它们很容易察觉的语义布局,并恶化了它们的实际含义(见图1)。
所有这些挑战都加剧了在文本SR任务之前学习生成结构的困难。在本研究中,我们展示了一种有效的先验学习方法,即用离散码本替换StyleGAN的恒定输入,同时通过W空间控制字体样式。
2、算法设计
GAN模型可以通过对同一类别的丰富图像进行训练,很好地捕获一个类别的内在结构。许多图像恢复任务[6,20,42,48,65,73]已经显示了使用这种生成先验从LR输入恢复真实细节的好处,尽管存在严重和复杂的退化。以往的研究主要使用先验进行面部修复,而其在文本SR中的应用尚未不足。
在本文中,我们提出了MARCONet,首次尝试建立盲文本SR的通用方法。所提议的管道如图3所示。它主要包括三个部分:
1)基于给定的LR输入对码本中字体样式、字符边界框及其索引的预测,
2)每个字符的结构先验生成,
3)以生成结构为指导的SR框架。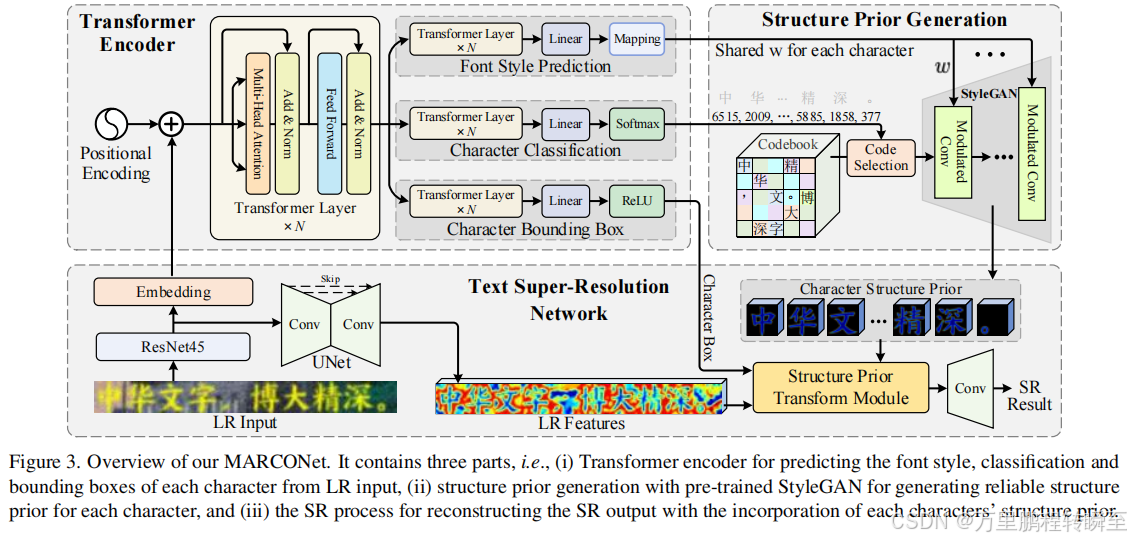
2.1 生成结构前期的预训练
StyleGAN采用一个可学习常数作为输入来控制输出图像的样式,还引入了层噪声来支持细粒度细节的随机变化。为了更好地捕捉文本图像的结构,我们删除了层级噪声,并用表示不同字符的离散代码替换了单个常数 (详见图2)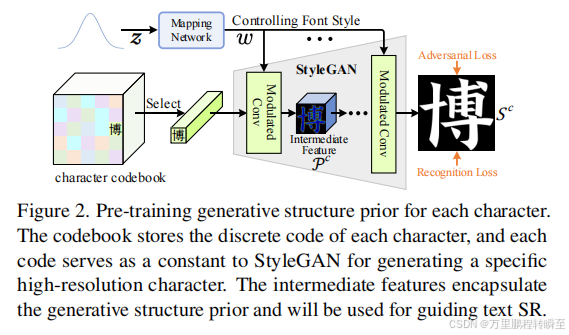
StyleGAN的训练可以在合成图像上完成,但对真实文本具有令人满意的泛化能力。特别是,PIL软件包1用于合成具有数百种字体样式的高分辨率字符图像(参见附录中的示例)。我们还通过随机翻译、字体大小和轻微的仿射变换来增加了多样性。与只采用对抗性损失[17]的原始样式[17]不同,我们引入了一个额外的识别损失,来自一个预先训练的基于变压器的识别器作为正则化。一旦学习完毕,每个可学习的代码∈都能很好地捕获每个字符的独特特征,w∈W可以控制输出图像的字体样式。在下面,我们将描述为给定的LR文本图像中的每个字符提取先验结构的方法。
2.2 Transformer Encoder
一个LR文本图像通常由几个字符组成。为了推导每个字符的生成结构,我们需要获得LR字符的字体样式w。其次,码本中每个字符的索引及其边界框对于调整每个LR字符也是必要的。为此,我们采用了一个基于变压器的编码器来联合预测所需的信息。选择Transformer [61]是为了更好地捕获输入图像中不同字符之间的依赖性。
学习预测字体样式w类似于基于学习的GAN反演[2,54,60,63],其中Transformer 网络作为一个编码器。结果表明,基于Transformer 的编码器实现了令人满意的反演,实现了低失真和高质量[25]的重构。请注意,一个文本图像中的字符通常具有相同的字体样式。因此,我们使用一个线性层来将所有字符的特征映射到一个单一的预测(w),该预测与同一LR图像中的所有字符共享。我们还使用与w预测类似的结构来对边界框和代码索引进行回归和分类。这三个子任务共享相同的Transformer 编码器(即ViT [14])和一个CNN主干(即ResNet45 [24])。结合位置编码,在序列中注入特征的位置。
字体样式通过StyleGAN的渐变预测分支进行优化。由于输入文本图像的字符数不受限制,我们采用CTC损失[18]进行识别。该方法被提出用于解决预测标签与目标标签之间的对齐问题,并被广泛应用于场景文本识别任务中。对于字符边界盒回归的学习,我们采用了光滑L1损失[16]和广义IoU损失[53]的线性组合。当用PIL软件包合成训练图像时,可以得到每个字符的地面真值盒。来自后一种文本SR网络的梯度可以进一步有利于整个Transformer 编码器的学习过程。
2.3 Text Super-resolution Network
Network Architecture 使用Transformer 编码器,我们可以获得字体样式w、分类标签(即码本中的索引),以及LR输入中每个字符的边界框。然后,得到相应的高质量的生成功能。首先,在最小的ResNet45上堆叠一个简单的UNet [55]来提取LR特征。然后,通过一个结构先验变换模块,将每个字符的生成结构先验嵌入到其LR字符中。这个过程如图4所示(更多的细节可以在附录中找到)。对于LR特性,我们采用检测到的边界框,通过RoIAlign操作[23]来裁剪和对齐每个LR字符。对于每个特征,采用AdaIN [26]对先验分布进行归一化,然后采用空间特征变换[67]预测仿射参数,并应用于LR特征特征。最后使用反向RoIAlign将增强的特性粘贴到原来的位置。采用结构先验变换模块的∈{32,64},允许我们的MARCONet在不同的退化下保持高保真度。将一个基于Conv-ReLU-ResBlock的CNN模块堆叠起来,生成最终的SR结果。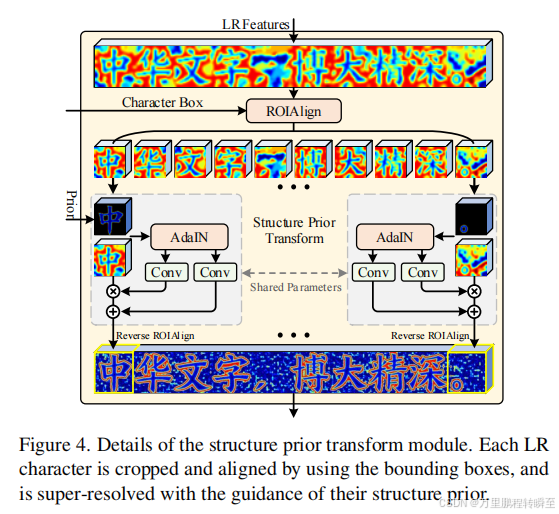
3、项目使用
3.1 基本准备
1、下载MARCONet项目, https://github.com/csxmli2016/MARCONet
2、下载预训练模型 ,https://github.com/csxmli2016/MARCONet/releases/tag/v1
3、安装编译BasicSR-master库及其插件,https://github.com/XPixelGroup/BasicSR
下载项目后,如果是liunx环境,通过命令:BASICSR_EXT=True pip install -e .即可
如果是window环境,则通过以下命令,编译插件
然后在通过命令: python setup.pu install,安装BasicSR
如果出现报错,可以参考以下方案
报错一:Error checking compiler version for cl
Error checking compiler version for cl: [WinError 2] 系统找不到指定的文件。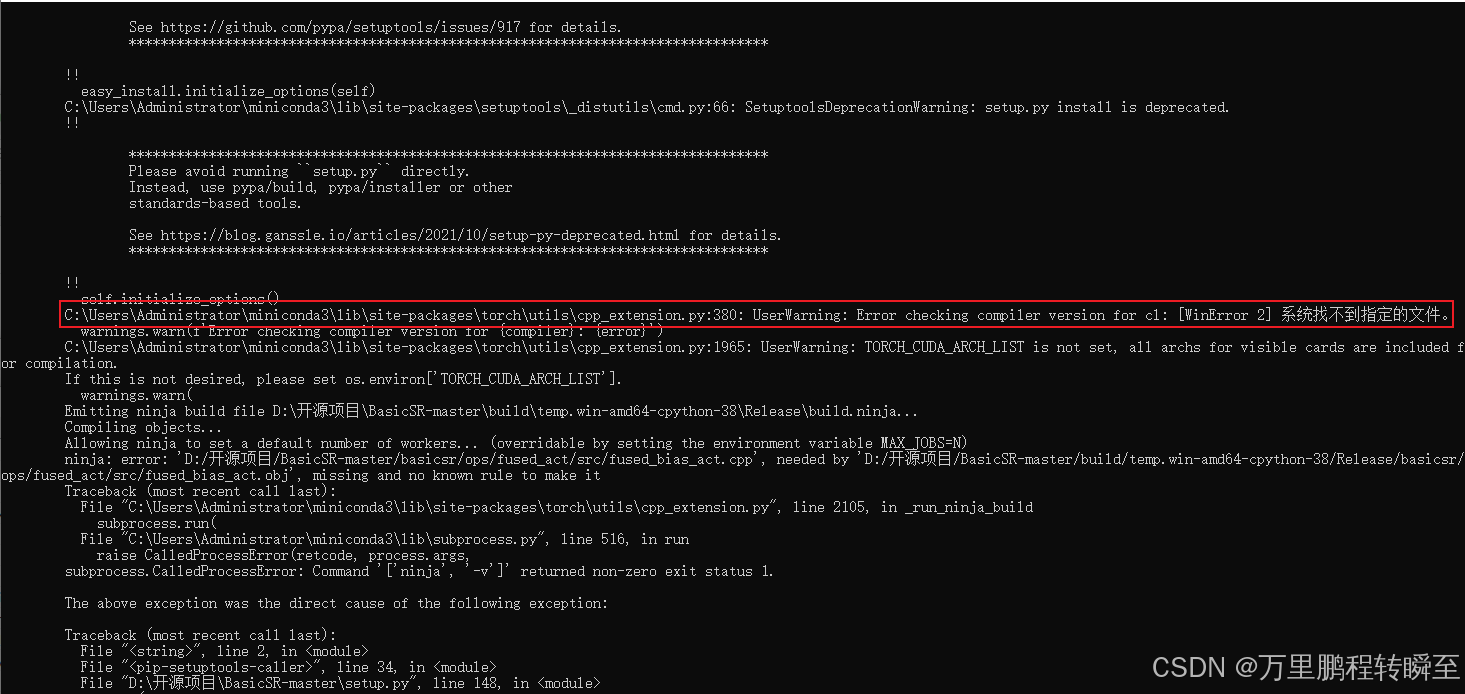
参考:https://blog.csdn.net/wangmengmeng99/article/details/118719322
在vs中安装设置MSVC插件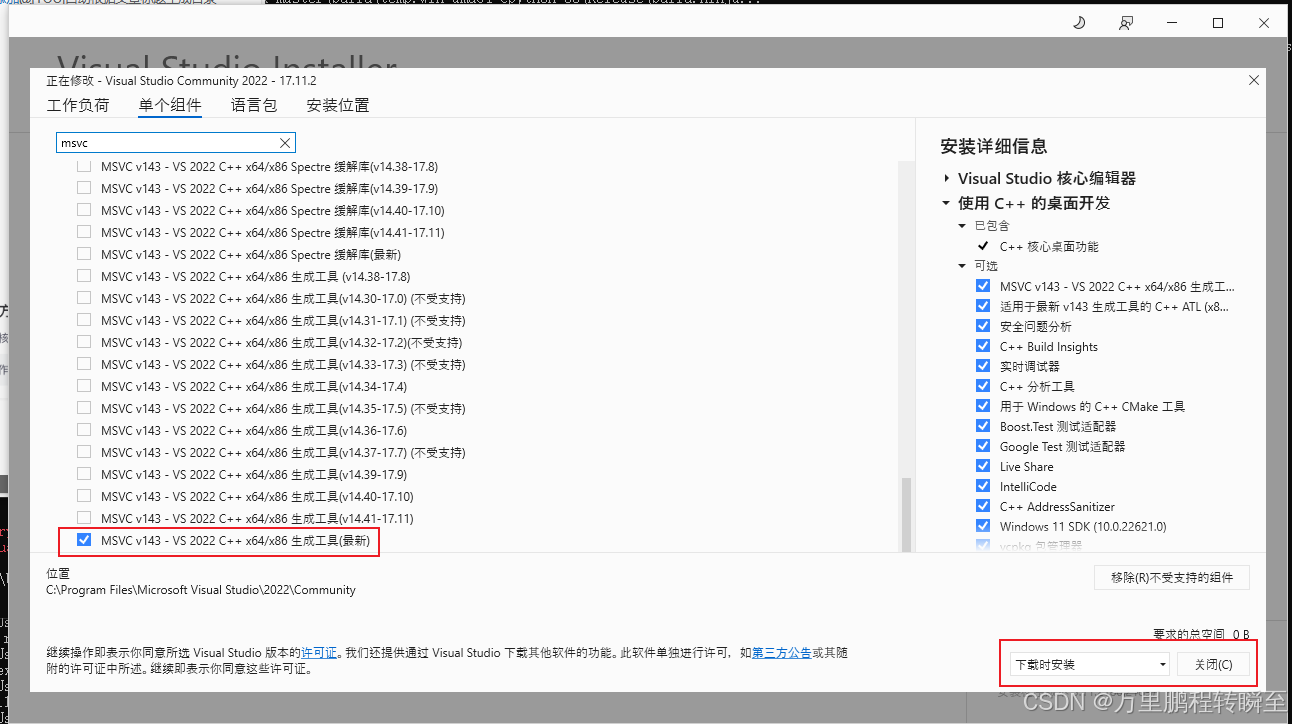
并环境变量,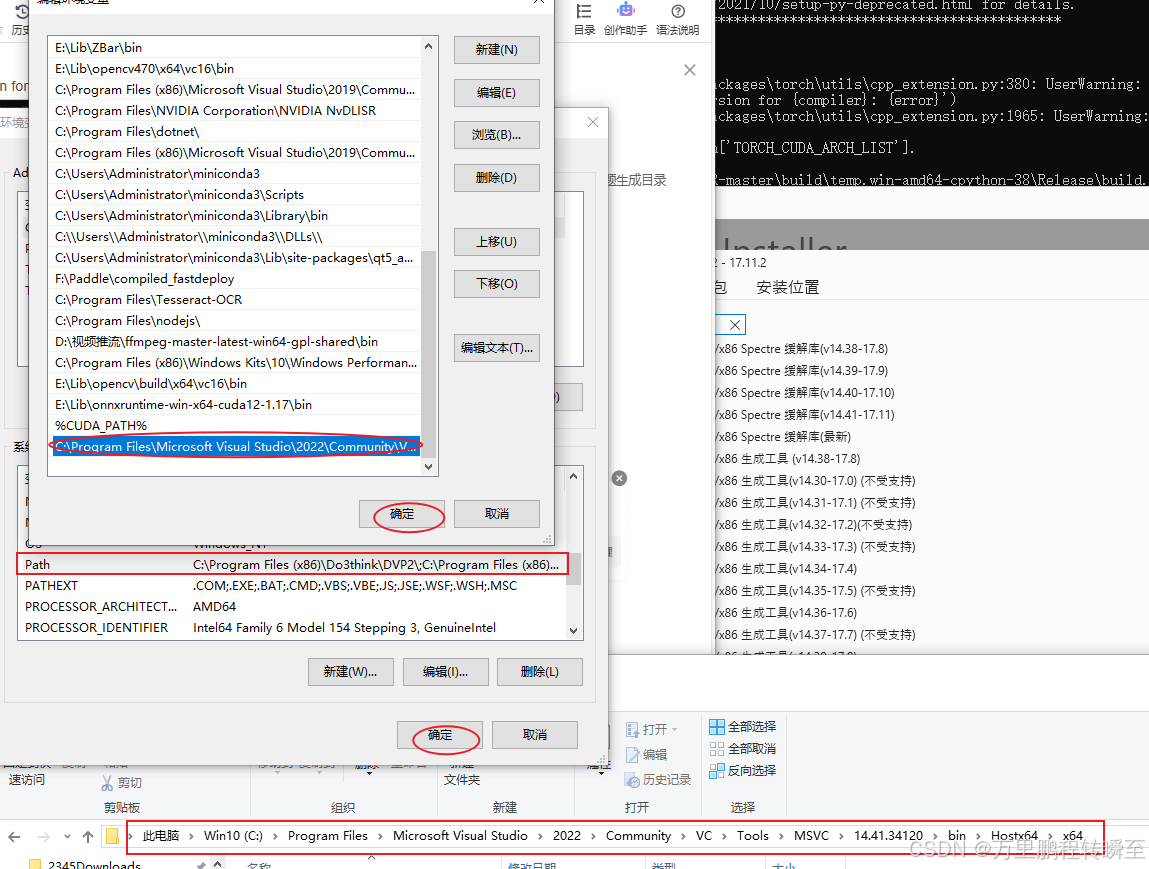
报错二 missing and no known rule to make it
ninja: error: ‘fused_bias_act.cpp’, needed by fused_bias_act.obj’, missing and no known rule to make it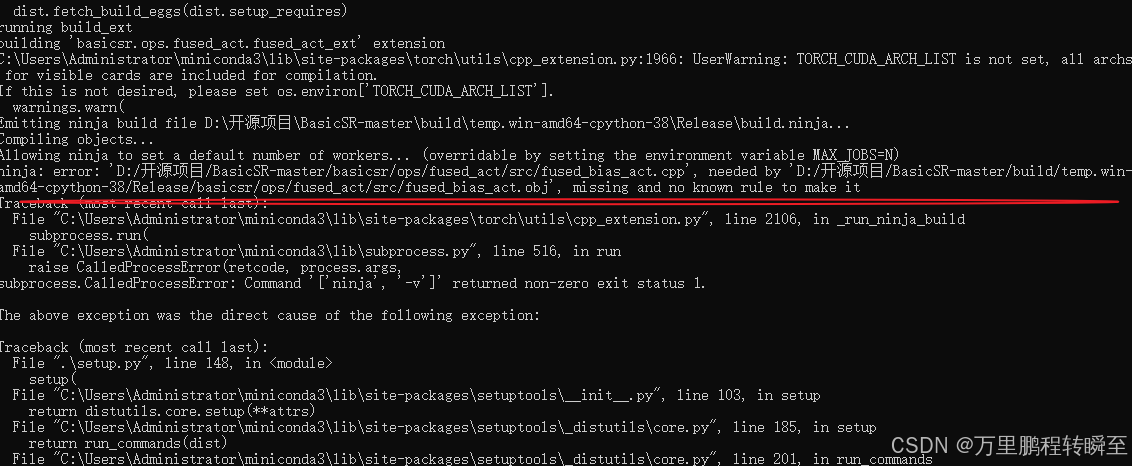
修改一:vs版本从2019改为2022
修改二:重装conda,选用了python310版本
3.2 测试效果
运行test_sr.py


文字校正的识别过程,运行test_w.py即可

一站式 AI 云服务平台
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)