
深度学习入门——基于Python的理论与实现
阶跃函数和sigmoid函数还有其他共同点,就是两者均为非线性函数。神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使 用线性函数。线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。
<p>PS:写这篇博客主要是记录下自己认为重要的部分以及阅读中遇到的些问题,加深自己的印象。<br> <strong>附上电子书及源代码:</strong><br> 链接:<a href="https://pan.baidu.com/s/1f2VFcnXSSK-u3wuvgjZ_7Q" rel="nofollow">https://pan.baidu.com/s/1f2VFcnXSSK-u3wuvgjZ_7Q</a><br> 提取码:uvbv</p>
《深度学习入门——基于Python的理论与实现》
第1章 Python入门
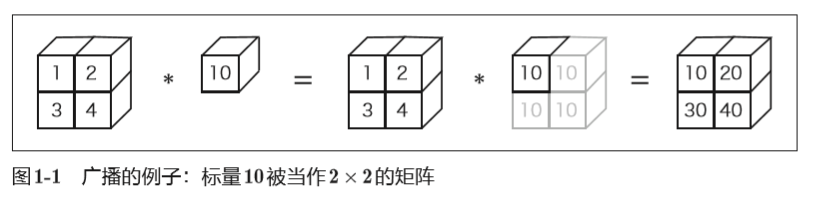
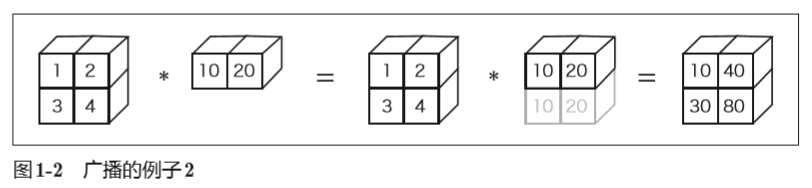
1.5.5 广播
第2章 感知机
2.1 感知机是什么
感知机的定义:感知机接收多个输入信号,输出一个信号。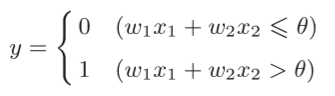
(y:输出 ,x:输入 ,θ:阈值)
2.2 简单逻辑电路
①与门(AND gate)
与门仅在两个输入均为1时输出1,其他时候则输出0。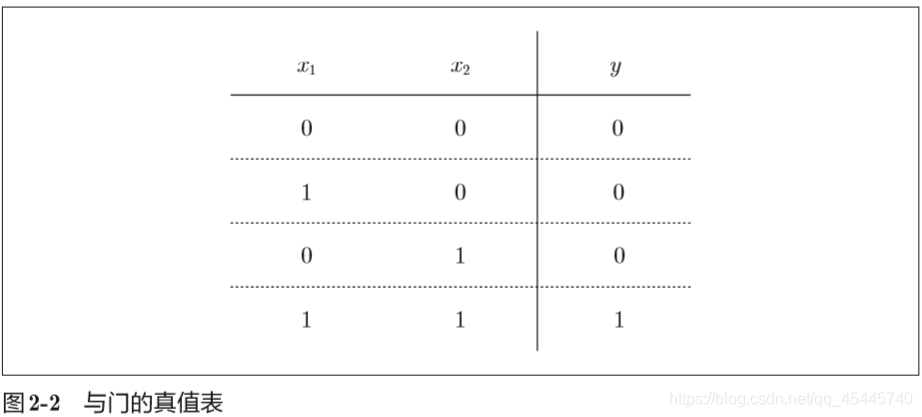
②与非门(NAND gate)
与非门仅当x1和x2同时为1时输出0,其他时候则输出1。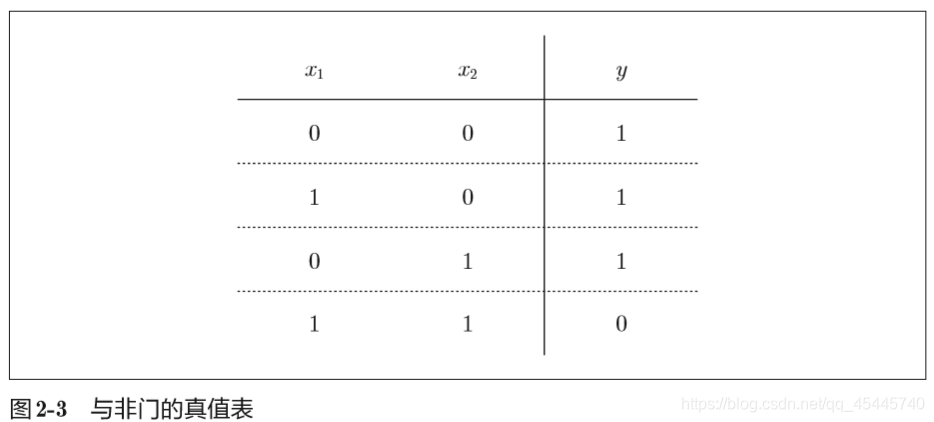
③或门(OR gate)
或门是只要有一个输入信号是1,输出就为1。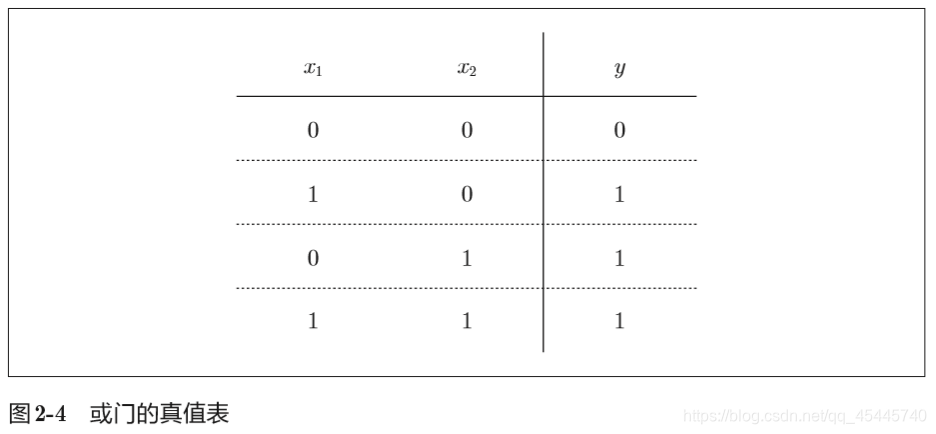
2.3 感知机的实现
把2.1公式中的θ换成-b,则可表示为: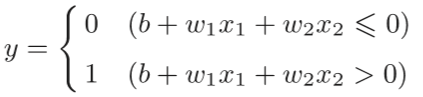
(w1和w2称为权值,b称为偏置)
w1和w2是控制输入信号的重要性的参数,偏置的值决定了神经元被激活的容易程度,而偏置b是调整神经元被激活的容易程度(输出信号为1的程度)的参数。
2.4 感知机的局限性
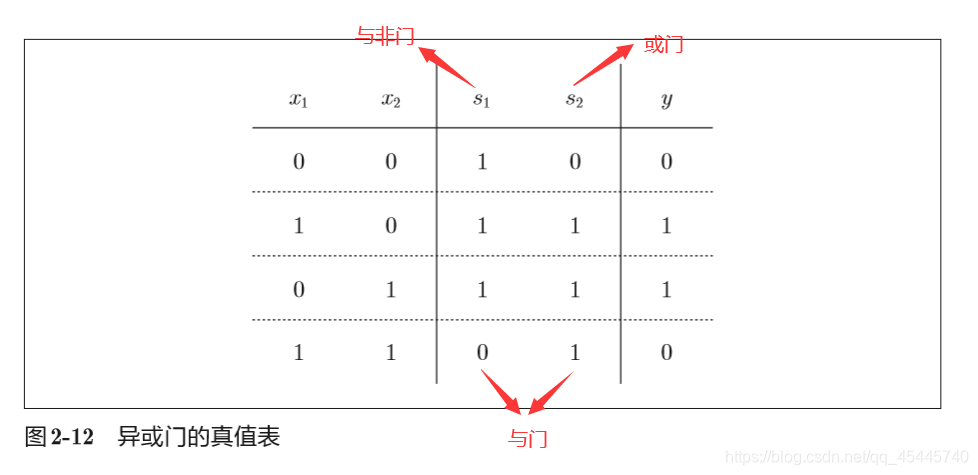
①先补充异或门的知识:异或门仅当x1和x2中的一方为1时,才会输出1(“异或”是拒绝其他的意思)。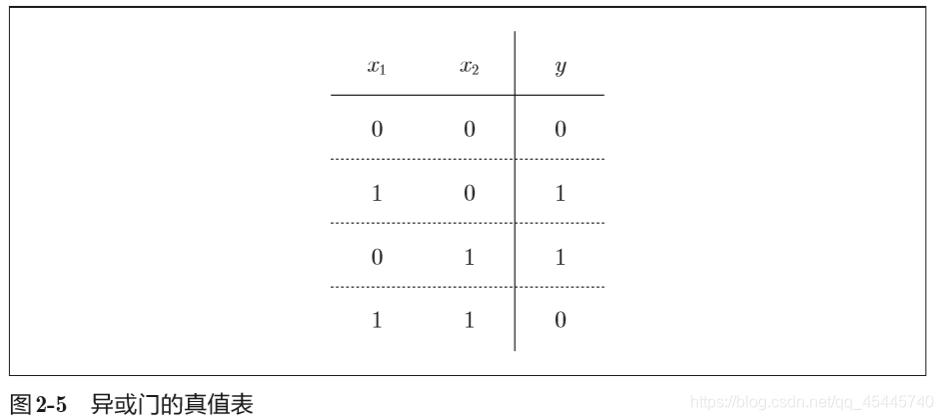
②发现问题:通过画图可知,因为与门、或门和与非门表现的区域可以用一条直线分割,而异或门表现的区域只能用曲线分割。所以用感知机可以实现与门、与非门、或门,却无法实现异或门。
感知机的局限性就在于它只能表示由一条直线分割的空间。
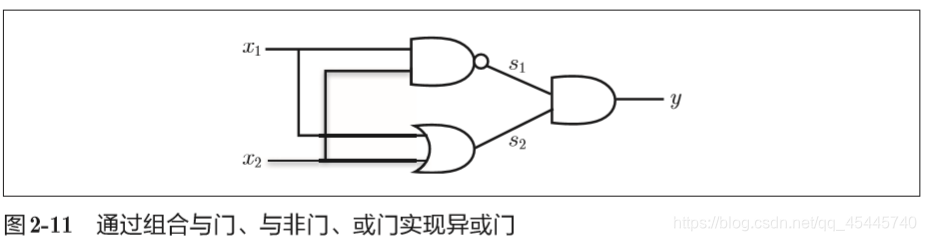
2.5 多层感知机
感知机可以通过”叠加层“来表示异或。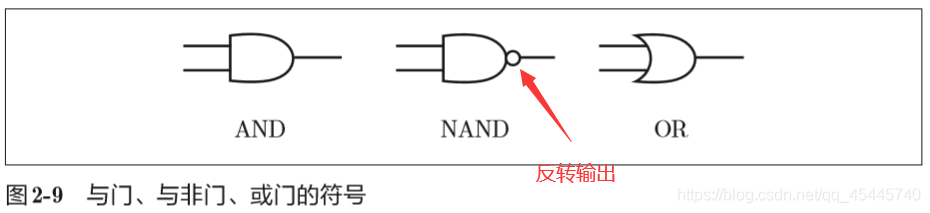
第3章 神经网络
3.1从感知机到神经网络
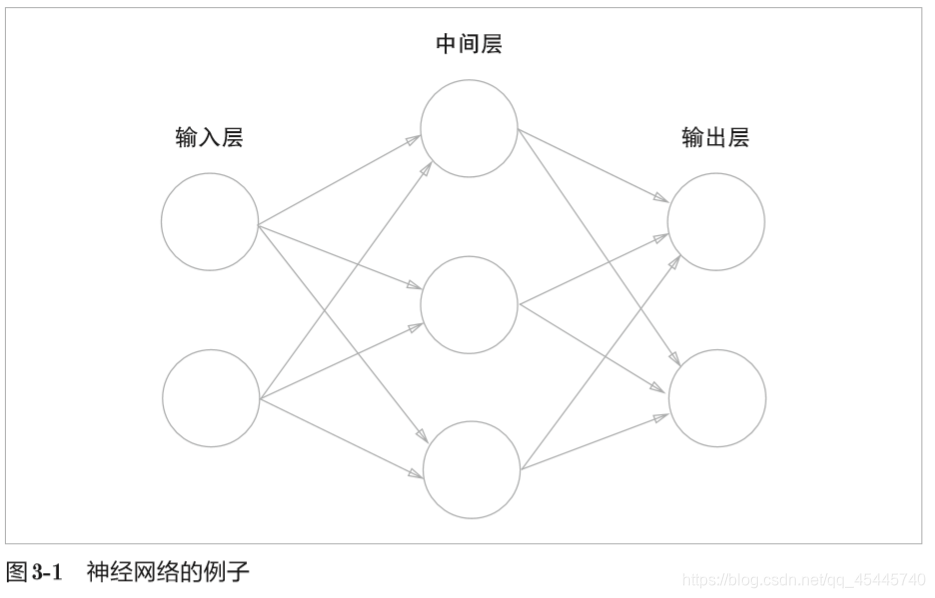
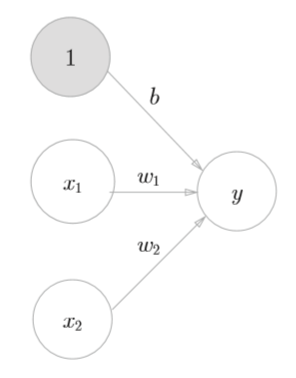
上图添加了权重为b的输入信号1。这个感知机将x1、x2、1三个信号作为神经元的输入,将其和各自得权重相乘后,传送至下一个神经元。在下一个神经元中,计算这些加权信号的总和。如果这个总和超过0,则输出1,否则输出0。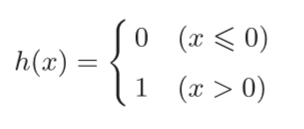
3.1.3 激活函数登场
激活函数的定义:像上面的h(x)函数会将输入信号的总和转换为输出信号,这种函数 一般称为激活函数(activation function)。如“激活”一词所示,激活函数的作用在于决定如何来激活输入信号的总和。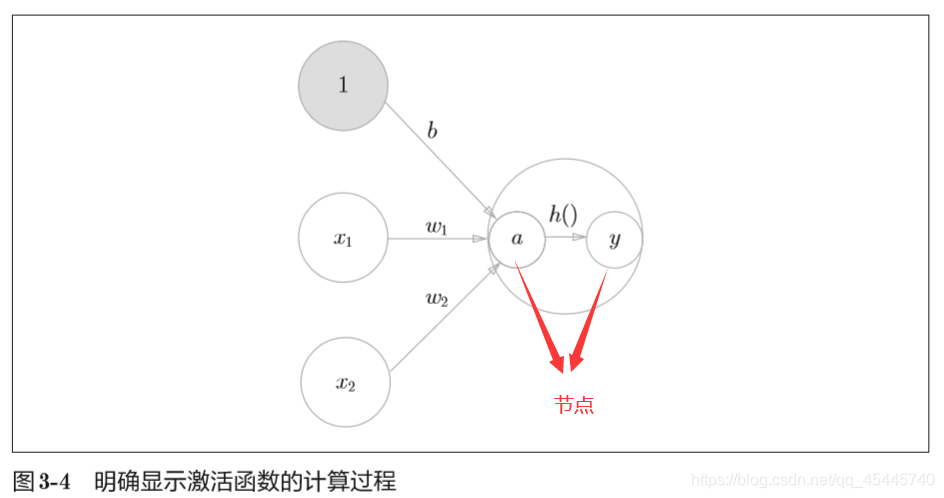
3.2 激活函数
3.2.1 sigmoid函数
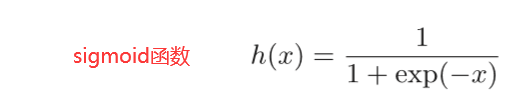
(式中的 exp(−x)表示e−x的意思)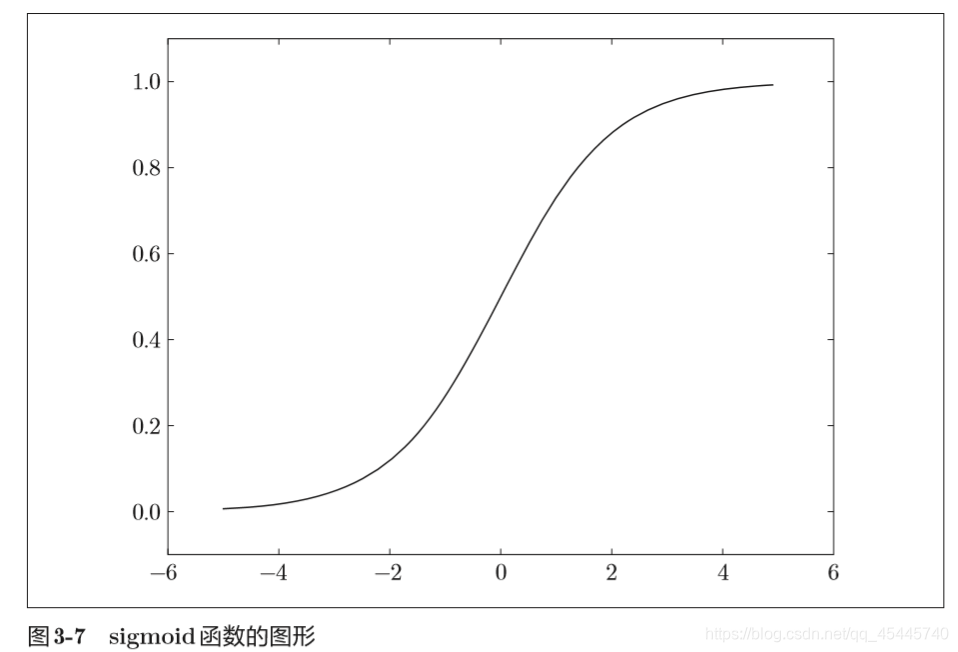
"""sigmoid函数"""
def sigmoid(x):
return 1 / (1 + np.exp(-x))
- 1
- 2
- 3
3.2.2 阶跃函数
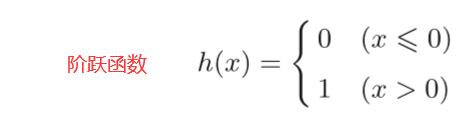
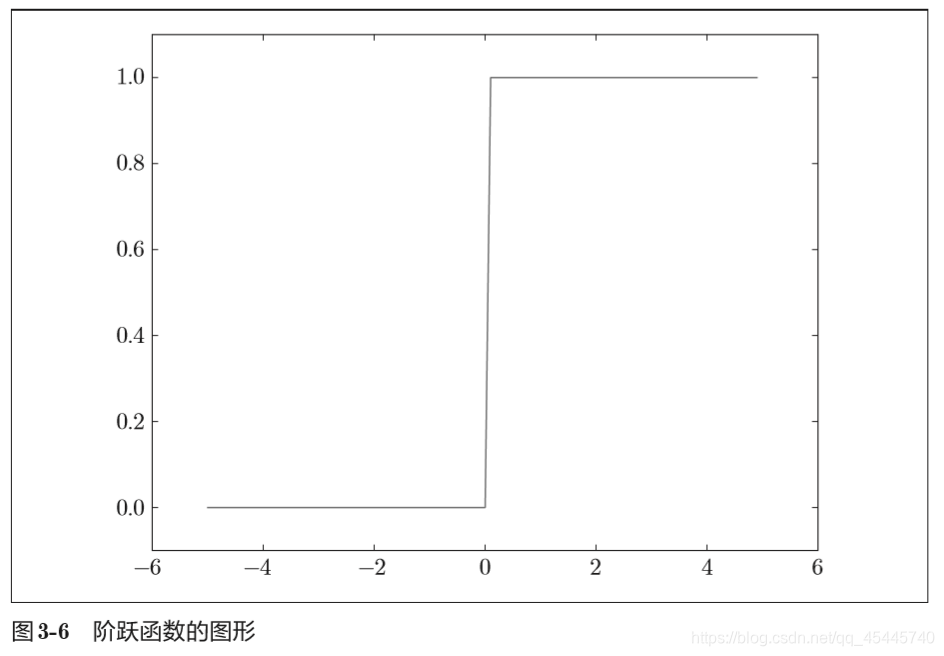
"""阶跃函数"""
def step_function(x):
y = x > 0
return y.astype(np.int)
- 1
- 2
- 3
- 4
PS:用astype()方法转换NumPy数组的类型。astype()方法通过参数指定期望的类型,这个例子中是np.int型。Python中将布尔型转换为int型后,True会转换为1,False会转换为0。
总结:阶跃函数和sigmoid函数还有其他共同点,就是两者均为非线性函数。 神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使 用线性函数。线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。
3.2.7 ReLU函数
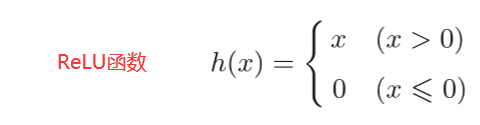
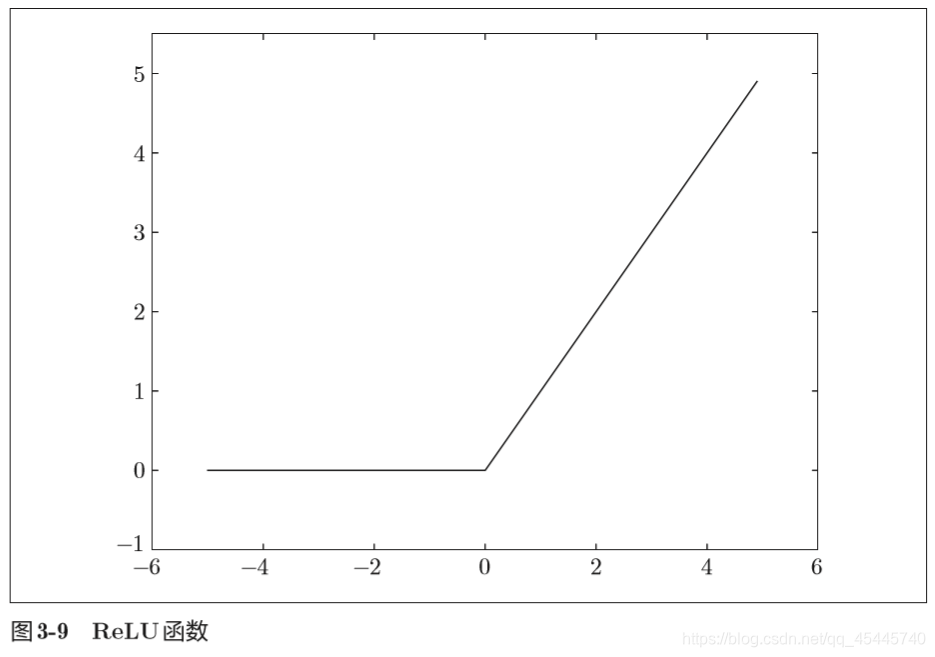
"""ReLU函数"""
def relu(x):
return np.maximum(0, x)
- 1
- 2
- 3
3.3 多维数组的运算
import numpy as np
np.ndim(A):获得数组A的维数
A.shape:获得数组的形状
np.dot(A,B):返回A与B数组的乘积
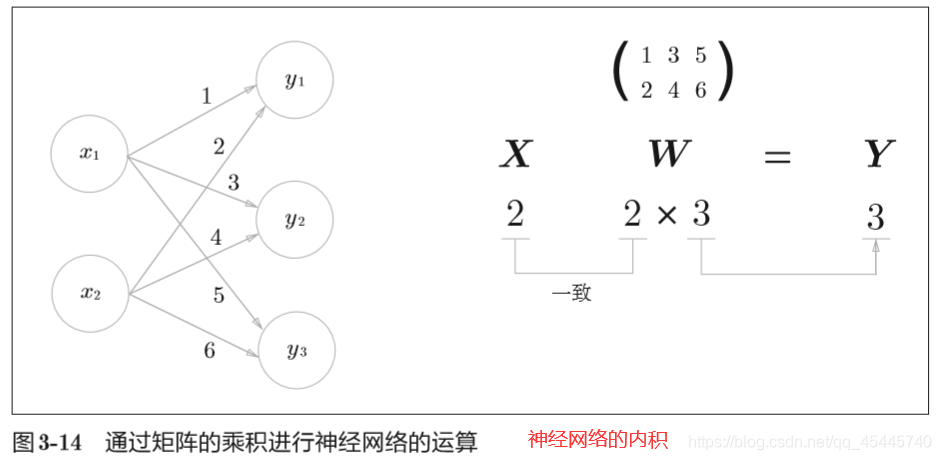
3.4 3层神经网络的实现
这里书中的图解讲的很详细,P56
3.4.2 恒等函数
"""恒等函数"""
def identity_function(x):
return x
- 1
- 2
- 3
**PS:**见书中P62,输出层所用的激活函数,要根据求解问题的性质决定。一般地,回归问题可以使用恒等函数,二元分类问题可以使用sigmoid函数, 多元分类问题可以使用softmax函数。
3.5.1 softmax函数
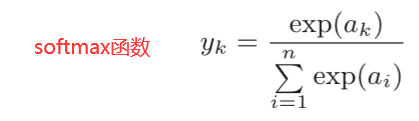
exp(x)是表示ex的指数函数。上表示假设输出层共有n个神经元,计算第k个神经元的输出yk。 softmax函数的分子是输入信号ak的指数函数,分母是所有输入信号的指数函数的和。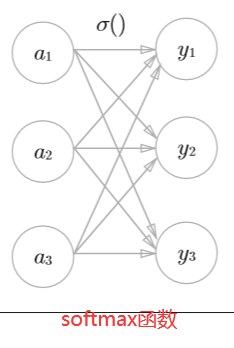
(softmax函数的输出通过箭头与所有的输入信号相连。这是因为,从公式中可以看出, 输出层的各个神经元都受到所有输入信号的影响。)
"""softmax激活函数""" def softmax(x): if x.ndim == 2: x = x.T x = x - np.max(x, axis=0) y = np.exp(x) / np.sum(np.exp(x), axis=0) return y.Tx <span class="token operator">=</span> x <span class="token operator">-</span> np<span class="token punctuation">.</span><span class="token builtin">max</span><span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># 溢出对策,见书P66</span> <span class="token keyword">return</span> np<span class="token punctuation">.</span>exp<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token operator">/</span> np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>exp<span class="token punctuation">(</span>x<span class="token punctuation">)</span><span class="token punctuation">)</span>
3.5.3 softmax函数的特征

①softmax函数的输出是0.0到1.0之间的实数。
②softmax 函数的输出总和为1是softmax函数的一个重要性质,正因为有了这个性质,可以把softmax函数的输出解释为“概率”。
③数组a中元素的大小关系和输出y中元素的大小关系一致,即使用了softmax函数,各个元素之间的大小关系也不会改变。
3.5.4 输出层的神经元数量
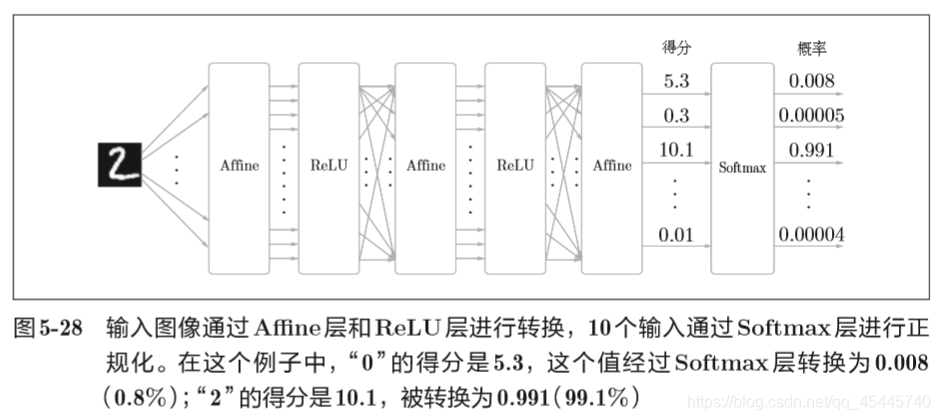
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。比如,对于手写数字识别,即某个输入图像,预测是图中的数字0到9中的哪一个的问题(10类别分类问题),可以如下图所示, 将输出层的神经元设定为10个。 其中神经元y2颜色最深,输出的值最大。这表明这个神经网络预测的是y2对应的类别,也就是“2”。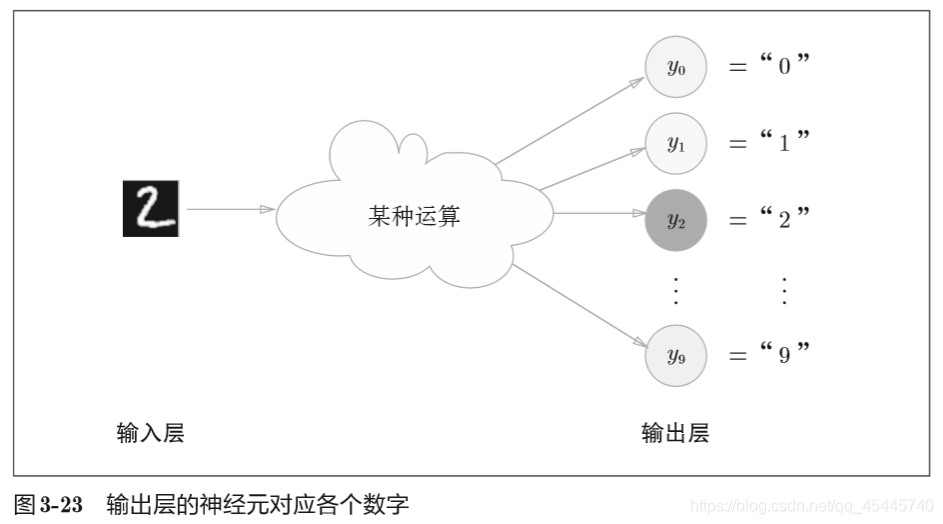
3.6手写数字识别
①下载MNIST数据集,源代码在dataset/mnist.py中,有详细的注解
如若运行太慢,建议直接去http://yann.lecun.com/exdb/mnist/网上下载
"""
像load_mnist(normalize=True, flatten=True, one_hot_label=False) 这 样,设 置 3 个 参 数。
第 1 个参数 normalize设置是否将输入图像正规化为0.0~1.0的值。如果将该参数设置 为False,则输入图像的像素会保持原来的0~255。
第2个参数flatten设置 是否展开输入图像(变成一维数组)。如果将该参数设置为False,则输入图 像为1×28×28的三维数组;若设置为True,则输入图像会保存为由784个元素构成的一维数组。
第3个参数one_hot_label设置是否将标签保存为onehot表示(one-hot representation)。 one-hot表示是仅正确解标签为1,其余 皆为0的数组,就像[0,0,1,0,0,0,0,0,0,0]这样。
当one_hot_label为False时, 只是像7、2这样简单保存正确解标签;当one_hot_label为True时,标签则 保存为one-hot表示
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
②ch03/mnist_show.py,预测测试集中图片的结果
③ch03/neuralnet_mnist.py,打印出所有测试集中的准确率
④ch03/neuralnet_mnist_batch.py,进行批处理
第4章 神经网络的学习
4.2 损失函数
定义:损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
4.2.1 均方误差
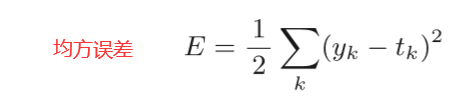
yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数。
比如,在 3.6节手写数字识别的例子中,yk、tk是由如下10个元素构成的数据。
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
"""均方误差"""
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
4.2.2 交叉熵误差
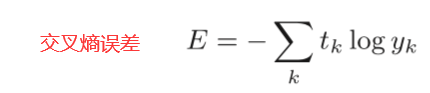
这里,log表示以e为底数的自然对数(loge)。 yk是神经网络的输出,tk是正确解标签。并且, tk中只有正确解标签的索引为1,其他均为0(one-hot表示)。 因此,上式实际上只计算对应正确解标签的输出的自然对数。
比如,假设正确解标签的索引是“2”,与之对应的神经网络的输出是0.6,则交叉熵误差是−log 0.6 = 0.51;若“ 2”对应的输出是0.1,则交叉熵误差为−log0.1 = 2.30。 也就是说,交叉熵误差的值是由正确解标签所对应的输出结果决定的。
(PS:在机器学习中,log默认就是In)
"""损失函数,交叉熵误差"""
def cross_entropy_error(y, t):
delta = 1e-7 # 添加一个微小值可以防止负无限大的发生
return -np.sum(t * np.log(y + delat))
- 1
- 2
- 3
- 4
4.2.3 mini-batch学习(小批量数据)
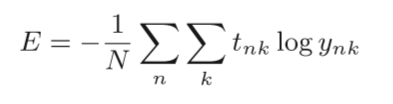
这里,假设数据有N个,tnk表示第n个数据的第k个元素的值(ynk是神经网络的输出,tnk是监督数据)。式子虽然看起来有一些复杂,其实只是把求单个数据的损失函数的式子扩大到了N份数据,不过最后还要除以N 进行正规化。通过除以N,可以求单个数据的“平均损失函数”。通过这样的平均化,可以获得和训练数据的数量无关的统一指标。
比如,即便训练数据 有1000个或10000个,也可以求得单个数据的平均损失函数。
4.2.4 mini-batch版交叉熵误差的实现
"""损失函数,交叉熵误差""" def cross_entropy_error(y, t): if y.ndim == 1: t = t.reshape(1, t.size) y = y.reshape(1, y.size)<span class="token comment"># 监督数据是one-hot-vector的情况下,转换为正确解标签的索引</span> <span class="token keyword">if</span> t<span class="token punctuation">.</span>size <span class="token operator">==</span> y<span class="token punctuation">.</span>size<span class="token punctuation">:</span> t <span class="token operator">=</span> t<span class="token punctuation">.</span>argmax<span class="token punctuation">(</span>axis<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span> batch_size <span class="token operator">=</span> y<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token keyword">return</span> <span class="token operator">-</span>np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>log<span class="token punctuation">(</span>y<span class="token punctuation">[</span>np<span class="token punctuation">.</span>arange<span class="token punctuation">(</span>batch_size<span class="token punctuation">)</span><span class="token punctuation">,</span> t<span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">7</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token operator">/</span> batch_size
# size()函数是返回分组大小的Series,是numpy模块中才有的函数。
# size():计算数组和矩阵中所有数据的个数
# size既可以作为函数,也可以作为ndarry的属性
# eg.a = np.array([[1,2,3],[4,5,6]])
# np.size(a) -> 6
# a.size -> 6
# eg.t = np.array([0,0,1,0,0])
# t = t.reshape(1,t.size) -> array([[0,0,1,0,0]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
4.2.5 为何要设定损失函数
见书P92
4.3 数值微分
4.3.1 导数
利用微小的差分求导数的过程称为数值微分(numerical differentiation)。
"""数值微分求导"""
def numerical_diff(f,x):
h = 1e-4 # 0.001
return (f(x+h) - f(x-h)) / (2*h)
- 1
- 2
- 3
- 4
4.4 梯度
定义:全部变量的偏导数汇总而成的向量称为梯度。
"""求梯度,相当于对数组x的各个元素求数值微分""" def numerical_gradient(f, x): h = 1e-4 # 0.0001 grad = np.zeros_like(x) # np.zeros_ like(x)会生成一个形状和x相同、所有元素都为0的数组<span class="token keyword">for</span> idx <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span>x<span class="token punctuation">.</span>size<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># 如x[3,4],idx=0,1 </span> tmp_val <span class="token operator">=</span> x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token comment"># tmp_val=x[0]=3</span> <span class="token comment"># f(x+h)的计算 </span> x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> tmp_val <span class="token operator">+</span> h <span class="token comment"># x[0]=3+h,x变为[3+h,4] </span> fxh1 <span class="token operator">=</span> f<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># 算[3+h,4]对应的函数值f</span> <span class="token comment"># f(x-h)的计算 </span> x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> tmp_val <span class="token operator">-</span> h <span class="token comment"># x[0]=3-h,x为[3-h,4] </span> fxh2 <span class="token operator">=</span> f<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># 算[3-h,4]对应的函数值f</span> grad<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token punctuation">(</span>fxh1 <span class="token operator">-</span> fxh2<span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token punctuation">(</span><span class="token number">2</span><span class="token operator">*</span>h<span class="token punctuation">)</span> <span class="token comment"># 算出梯度 </span> x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> tmp_val <span class="token comment"># 还原x为[3,4]</span> <span class="token keyword">return</span> grad
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
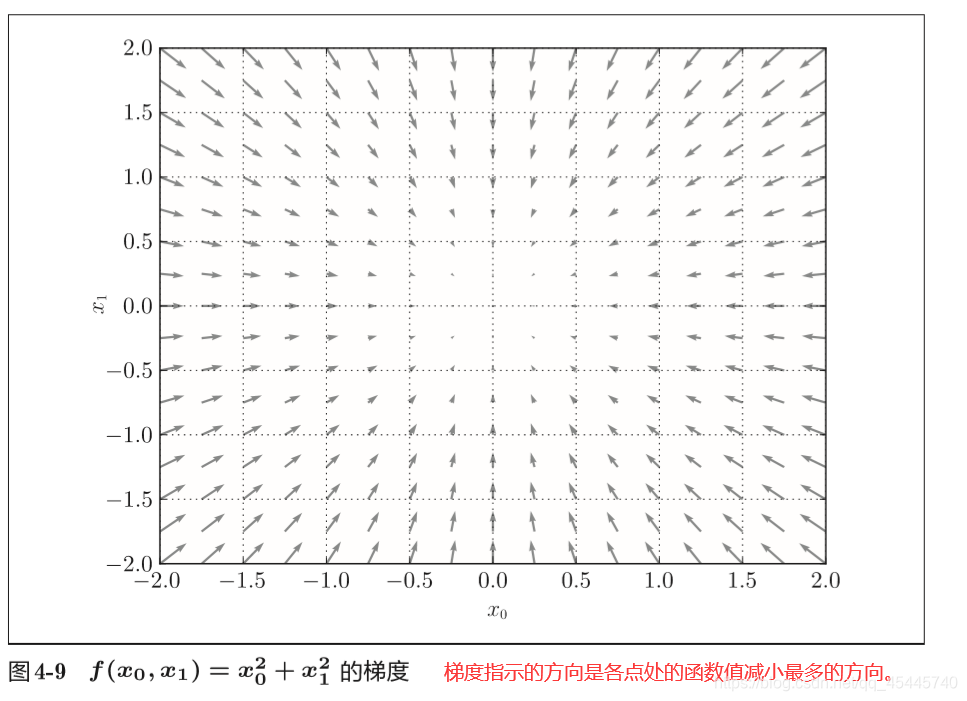
4.4.1 梯度法
机器学习的主要任务是在学习时寻找最优参数。同样地,神经网络也必须在学习时找到最优参数(权重和偏置)。这里所说的最优参数是指损失函数取最小值时的参数。但是,一般而言,损失函数很复杂,参数空间庞大,我们不知道它在何处能取得最小值。而通过巧妙地使用梯度来寻找函数最小值 (或者尽可能小的值)的方法就是梯度法。
严格地讲, 寻找最小值的梯度法称为梯度下降法(gradient descent method),寻找最大值的梯度法称为梯度上升法(gradient ascent method)。一般来说,神经网络(深度学习)中,梯度法主要是指梯度下降法。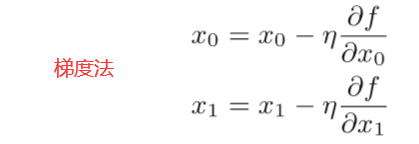
上式中的η表示更新量,在神经网络的学习中,称为学习率(learning rate)。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。
"""梯度下降法""" def gradient_descent(f, init_x, lr=0.01, step_num=100): x = init_x<span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span>step_num<span class="token punctuation">)</span><span class="token punctuation">:</span> grad <span class="token operator">=</span> numerical_gradient<span class="token punctuation">(</span>f<span class="token punctuation">,</span> x<span class="token punctuation">)</span> x <span class="token operator">-=</span> lr <span class="token operator">*</span> grad <span class="token keyword">return</span> x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(参数f是要进行最优化的函数,init_x是初始值,lr是学习率learning rate,step_num是梯度法的重复次数。numerical_gradient(f,x)会求函数的梯度,用该梯度乘以学习率得到的值进行更新操作,由step_num指定重复的 次数。
学习率过大或者过小都无法得到好的结果。)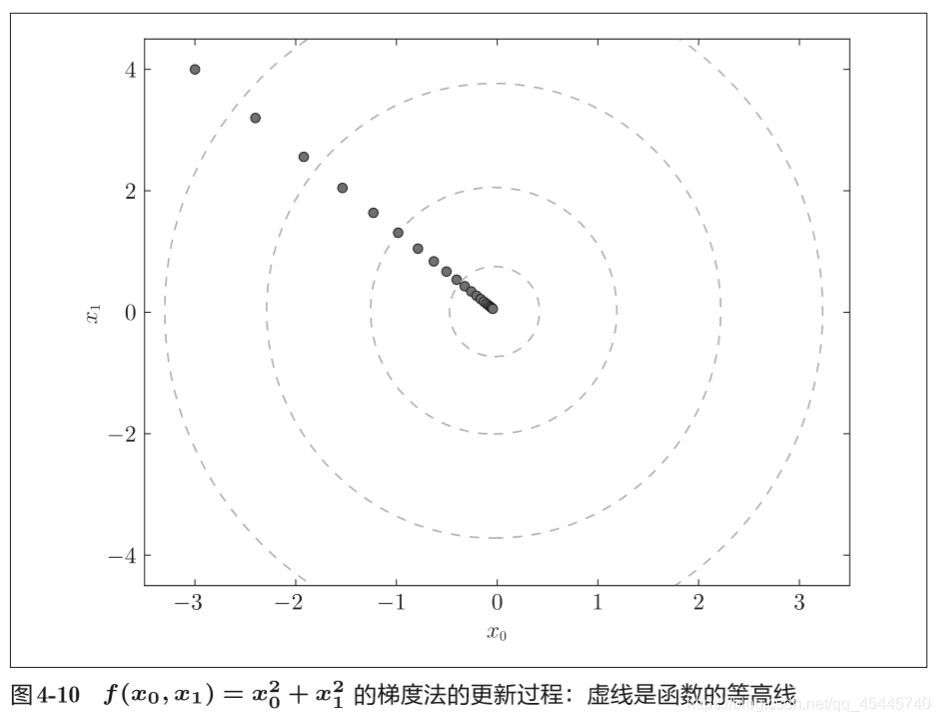
4.4.2 神经网络的梯度(损失函数关于权重参数的梯度)
比如,有一个只有一个形状为2×3的权重W的神经网络,损失函数用L表示,梯度用∂L/∂W表示,用数学式表示的话:
# 根据书上的思路,可以理解为:
# 1.定义x(输入):1*2,t(标签):1*3,W(权重):2*3 ,y(输出):1*3
# 2.x,W点积求得y
# 3.通过softmax函数处理y
# 4.求损失函数,交叉熵误差
# 5.定义匿名函数,将W变为损失函数的参数
# 6.求损失函数关于W的梯度
# PS:求出来的梯度大小就可以知道权重W如何调整
# 则按照上述步骤编写程序如下:
import numpy as np
“”“激活函数”“”
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x <span class="token operator">=</span> x <span class="token operator">-</span> np<span class="token punctuation">.</span><span class="token builtin">max</span><span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># 溢出对策</span>
<span class="token keyword">return</span> np<span class="token punctuation">.</span>exp<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token operator">/</span> np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>exp<span class="token punctuation">(</span>x<span class="token punctuation">)</span><span class="token punctuation">)</span>
“”“损失函数,交叉熵误差”“”
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
<span class="token comment"># 监督数据是one-hot-vector的情况下,转换为正确解标签的索引</span>
<span class="token keyword">if</span> t<span class="token punctuation">.</span>size <span class="token operator">==</span> y<span class="token punctuation">.</span>size<span class="token punctuation">:</span>
t <span class="token operator">=</span> t<span class="token punctuation">.</span>argmax<span class="token punctuation">(</span>axis<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span>
batch_size <span class="token operator">=</span> y<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span>
<span class="token keyword">return</span> <span class="token operator">-</span>np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>log<span class="token punctuation">(</span>y<span class="token punctuation">[</span>np<span class="token punctuation">.</span>arange<span class="token punctuation">(</span>batch_size<span class="token punctuation">)</span><span class="token punctuation">,</span> t<span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">7</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token operator">/</span> batch_size
“”“求一维的梯度”“”
def _numerical_gradient_1d(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
<span class="token keyword">for</span> idx <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span>x<span class="token punctuation">.</span>size<span class="token punctuation">)</span><span class="token punctuation">:</span>
tmp_val <span class="token operator">=</span> x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span>
x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token builtin">float</span><span class="token punctuation">(</span>tmp_val<span class="token punctuation">)</span> <span class="token operator">+</span> h
fxh1 <span class="token operator">=</span> f<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># f(x+h)</span>
x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> tmp_val <span class="token operator">-</span> h
fxh2 <span class="token operator">=</span> f<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># f(x-h)</span>
grad<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token punctuation">(</span>fxh1 <span class="token operator">-</span> fxh2<span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token punctuation">(</span><span class="token number">2</span> <span class="token operator">*</span> h<span class="token punctuation">)</span>
x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> tmp_val <span class="token comment"># 还原值</span>
<span class="token keyword">return</span> grad
“”“求二维的梯度”“”
def numerical_gradient_2d(f, X):
if X.ndim == 1:
return _numerical_gradient_1d(f, X)
else:
grad = np.zeros_like(X)
<span class="token keyword">for</span> idx<span class="token punctuation">,</span> x <span class="token keyword">in</span> <span class="token builtin">enumerate</span><span class="token punctuation">(</span>X<span class="token punctuation">)</span><span class="token punctuation">:</span>
grad<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> _numerical_gradient_1d<span class="token punctuation">(</span>f<span class="token punctuation">,</span> x<span class="token punctuation">)</span>
<span class="token keyword">return</span> grad
# 1.定义x,t,W
x = np.array([0.6,0.9]) # 输入数据
t = np.array([0,0,1]) # 正确结果
W = np.random.randn(2,3) # 2*3的权重
# 2.x,W点积求得y
y = np.dot(x,W)
print(“y:{}”.format(y))
# 3.通过softmax函数处理y
y_sm = softmax(y)
print(“y_sm:{}”.format(y_sm))
# 4.求损失函数,交叉熵误差
loss = cross_entropy_error(y_sm,t)
print(“loss:{}”.format(loss))
# 5.定义匿名函数,将W变为损失函数的参数
f = lambda W:cross_entropy_error(y_sm,t)
# 用匿名函数将W变为参数
print(f(W))
print(f(1))
print(W)
# 6.求损失函数关于W的梯度
dW = numerical_gradient_2d(f,W)
print(dW)
# 输出:
# y:[-0.54321364 -0.37949175 -1.06371615]
# y_sm:[0.36073623 0.42490641 0.21435736]
# loss:1.5401102895993706
# 1.5401102895993706
# 1.5401102895993706
# [[ 1.60980903 -0.27800492 -1.67564275]
# [-1.67677673 -0.23632088 -0.06481167]]
# [[0. 0. 0.]
# [0. 0. 0.]]
# 可以发现,该程序输出的梯度为0,说明这个方法是错误的。
# 而书上的程序是把simpleNet写成类
# 猜测在第五步,这种形式,W并没有成为函数f真正的变量,W值改变(权重需要不断更新),f值并不会改变。由于f的值不变,
# f(W+h) - f(W-h) = 0,所以梯度都为0。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
下面来看看书上给的源码(源代码在ch04/gradient_simplenet.py 中),这里为了方便查看程序,我把头文件中引入的函数也写出来:
# coding: utf-8
import numpy as np
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x <span class="token operator">=</span> x <span class="token operator">-</span> np<span class="token punctuation">.</span><span class="token builtin">max</span><span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># 溢出对策</span>
<span class="token keyword">return</span> np<span class="token punctuation">.</span>exp<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token operator">/</span> np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>exp<span class="token punctuation">(</span>x<span class="token punctuation">)</span><span class="token punctuation">)</span>
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
<span class="token comment"># 监督数据是one-hot-vector的情况下,转换为正确解标签的索引</span>
<span class="token keyword">if</span> t<span class="token punctuation">.</span>size <span class="token operator">==</span> y<span class="token punctuation">.</span>size<span class="token punctuation">:</span>
t <span class="token operator">=</span> t<span class="token punctuation">.</span>argmax<span class="token punctuation">(</span>axis<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span>
batch_size <span class="token operator">=</span> y<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span>
<span class="token keyword">return</span> <span class="token operator">-</span>np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>np<span class="token punctuation">.</span>log<span class="token punctuation">(</span>y<span class="token punctuation">[</span>np<span class="token punctuation">.</span>arange<span class="token punctuation">(</span>batch_size<span class="token punctuation">)</span><span class="token punctuation">,</span> t<span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">7</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token operator">/</span> batch_size
def numerical_gradient(f, x): # n维数组求梯度
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 梯度的形状与x的形状相同
it <span class="token operator">=</span> np<span class="token punctuation">.</span>nditer<span class="token punctuation">(</span>x<span class="token punctuation">,</span> flags<span class="token operator">=</span><span class="token punctuation">[</span><span class="token string">'multi_index'</span><span class="token punctuation">]</span><span class="token punctuation">,</span> op_flags<span class="token operator">=</span><span class="token punctuation">[</span><span class="token string">'readwrite'</span><span class="token punctuation">]</span><span class="token punctuation">)</span>
<span class="token comment"># multi_index将元素索引(0,0) (0,1)等取出来</span>
<span class="token comment"># readwrite,使用可读可写的格式,我们需要改变x的值来计算f,所以需要用此方式</span>
<span class="token keyword">while</span> <span class="token keyword">not</span> it<span class="token punctuation">.</span>finished<span class="token punctuation">:</span>
idx <span class="token operator">=</span> it<span class="token punctuation">.</span>multi_index
tmp_val <span class="token operator">=</span> x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token comment"># 取出某个元素</span>
x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token builtin">float</span><span class="token punctuation">(</span>tmp_val<span class="token punctuation">)</span> <span class="token operator">+</span> h
fxh1 <span class="token operator">=</span> f<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># f(x+h)</span>
x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> tmp_val <span class="token operator">-</span> h
fxh2 <span class="token operator">=</span> f<span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token comment"># f(x-h)</span>
grad<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token punctuation">(</span>fxh1 <span class="token operator">-</span> fxh2<span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token punctuation">(</span><span class="token number">2</span> <span class="token operator">*</span> h<span class="token punctuation">)</span>
x<span class="token punctuation">[</span>idx<span class="token punctuation">]</span> <span class="token operator">=</span> tmp_val <span class="token comment"># 还原值</span>
it<span class="token punctuation">.</span>iternext<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">return</span> grad
class simpleNet:
def init(self):
self.W = np.random.randn(2,3) #用高斯分布进行初始化,返回一个从[0,1)均匀分布的数组
<span class="token keyword">def</span> <span class="token function">predict</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">return</span> np<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>x<span class="token punctuation">,</span> self<span class="token punctuation">.</span>W<span class="token punctuation">)</span>
<span class="token keyword">def</span> <span class="token function">loss</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">,</span> t<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># 求损失函数的值</span>
z <span class="token operator">=</span> self<span class="token punctuation">.</span>predict<span class="token punctuation">(</span>x<span class="token punctuation">)</span>
y <span class="token operator">=</span> softmax<span class="token punctuation">(</span>z<span class="token punctuation">)</span>
loss <span class="token operator">=</span> cross_entropy_error<span class="token punctuation">(</span>y<span class="token punctuation">,</span> t<span class="token punctuation">)</span>
<span class="token keyword">return</span> loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet() # W = np.random.randn(2,3)
print(“net.W:{}”.format(net.W))
p = net.predict(x)
print(“p:{}”.format(p))
print(“net.loss(x,t):{}”.format(net.loss(x,t)))
f = lambda w: net.loss(x, t) # 这里的f是一个函数,不是一个值
print(type(f))
dW = numerical_gradient(f, net.W)
print(dW)
# 输出:
# net.W:[[-1.22317556 -0.02853916 -0.24033821]
# [-1.62537437 -1.27039753 0.84045948]]
# p:[-2.19674227 -1.16048127 0.6122106 ]
# net.loss(x,t):0.2071304284027996
# <class ‘function’>
# [[ 0.02939563 0.08285624 -0.11225188]
# [ 0.04409345 0.12428437 -0.16837781]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
问题:程序每次运行时,都会产生不同的梯度值,因为W设置的是随机生成的数组,然而x和t是固定的,在源码中f =lambda w: net.loss(x, t)并未对W进行改变。那么这种结构的W到底能不能被改变,从结果来看是被改变了,它的本质是在用函数调用改变全局变量W。
思路:已知x,正确标签t,权重W有初始值,预测值y = W*x + b,损失值loss = |y - t|,求loss对W的偏导,核心问题在于,loss的参数是W,但我们定义的函数里面,W并不是loss的直接参数,我们输入的就是x和t,结果就是loss对W的梯度。
为什么要用lambda:我们想要求梯度,求梯度的这个函数有两个参数,numerical_gradient(损失函数,W初始值),注意第一个参数是损失函数,是一个函数,如果不定义一个新的函数,直接用loss,loss(x,t)这时你又必须把参数输进去,这样函数只会返回一个值,并不会保留函数关系,所以必须用lambda定义一个过渡的函数,只保留函数关系,但不会去运行loss。
补充知识:
函数参数传递机制:函数参数传递机制问题的本质上是调用函数(过程)和被调用函数(过程)在调用发生时进行通信的方法问题。基本的参数传递机制有两种:值传递和引用传递
值传递(passl-by-value)过程中,被调函数的形式参数作为被调函数的局部变量处理,即在堆栈中开辟了内存空间以存放由主调函数放进来的实参的值,从而成为了实参的一个副本。值传递的特点是被调函数对形式参数的任何操作都是作为局部变量进行,不会影响主调函数的实参变量的值。
引用传递(pass-by-reference)过程中,被调函数的形式参数虽然也作为局部变量在堆栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。被调函数对形参的任何操作都被处理成间接寻址,即通过堆栈中存放的地址访问主调函数中的实参变量。正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量。
具体参考:http://c.biancheng.net/view/2258.html
Python中:
如果是可变对象,如字典或者列表,就能修改对象的原始值,相当于引用传递;
如果是不可变对象,如数字、字符或者元组,就不能直接修改原始对象,相当于值传递。
id(a) # 表示查看a的地址
- 1
总结:
在一开始按照步骤写的程序中,定义的随机数是一个整数,所以在传进函数里的时候是值传递,但是在书里面的例子,生成的随机数是个array,所以在数组求梯度那两个函数里面属于引用传递,在函数里面修改,同样相当于全局修改。(来自大佬的解答)
4.5 学习算法的实现
具体内容见书上,源代码中也有详细的注释。
第5章 误差反向传播法
5.1 计算图 & 5.2 链式法则
书上的图解很清楚
5.3 反向传播
5.3.1 加法节点的反向传播
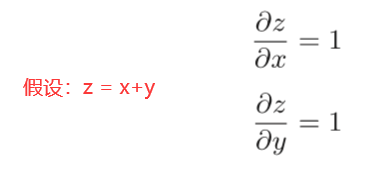
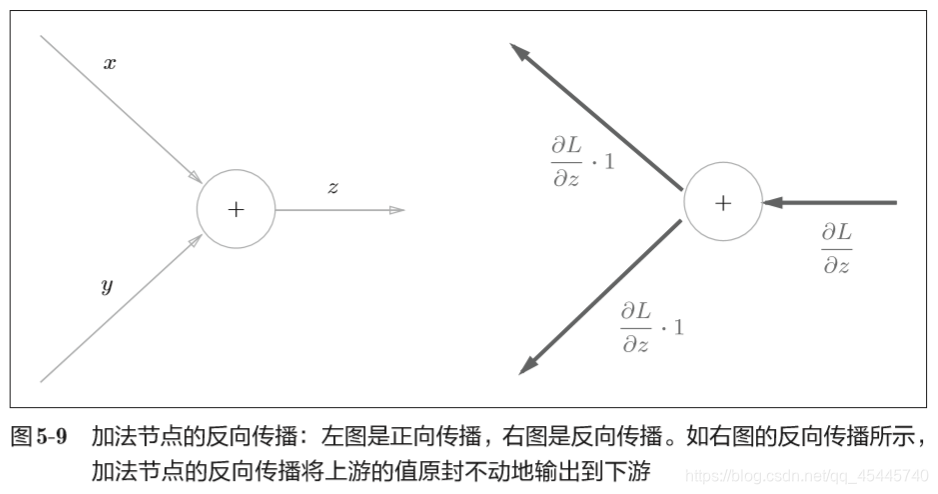
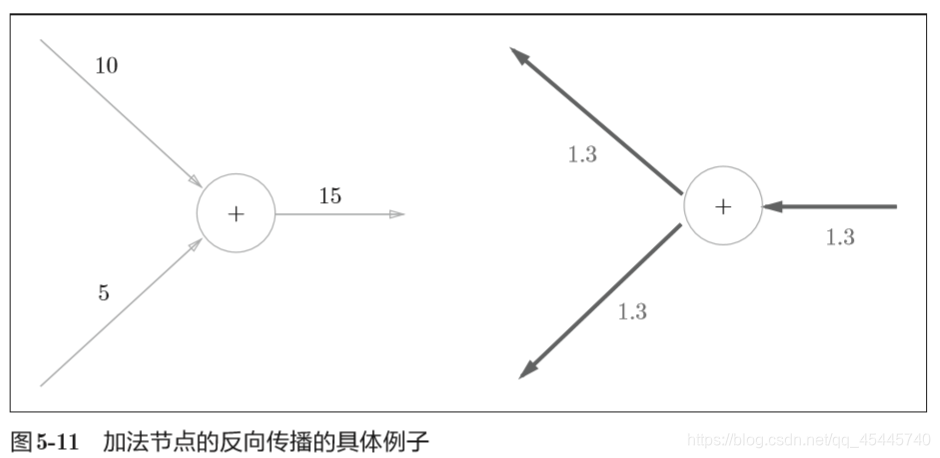
加法的反向传播只是将上游的值传给下游, 并不需要正向传播的输入信号。
# P137 加法层的实现 class AddLayer: def __init__(self): pass<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">,</span> y<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># 正向传播</span> out <span class="token operator">=</span> x <span class="token operator">+</span> y <span class="token keyword">return</span> out <span class="token keyword">def</span> <span class="token function">backward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> dout<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># 反向传播</span> dx <span class="token operator">=</span> dout <span class="token operator">*</span> <span class="token number">1</span> dy <span class="token operator">=</span> dout <span class="token operator">*</span> <span class="token number">1</span> <span class="token keyword">return</span> dx<span class="token punctuation">,</span> dy
# 加法层不需要特意进行初始化,所以__init__()中什么也不运行(pass 语句表示“什么也不运行”)。
#加法层的forward()接收x和y两个参数,将它们相加后输出。backward()将上游传来的导数(dout)原封不动地传递给下游。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5.3.2 乘法节点的反向传播
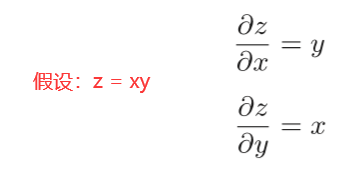
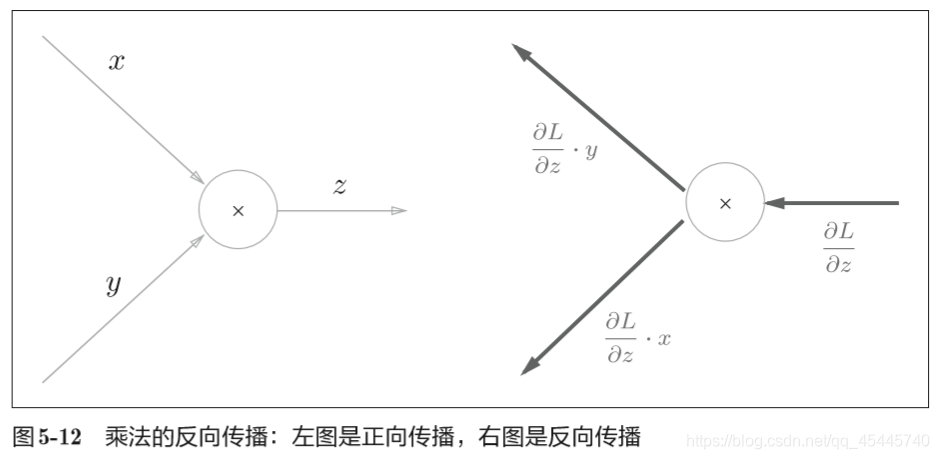
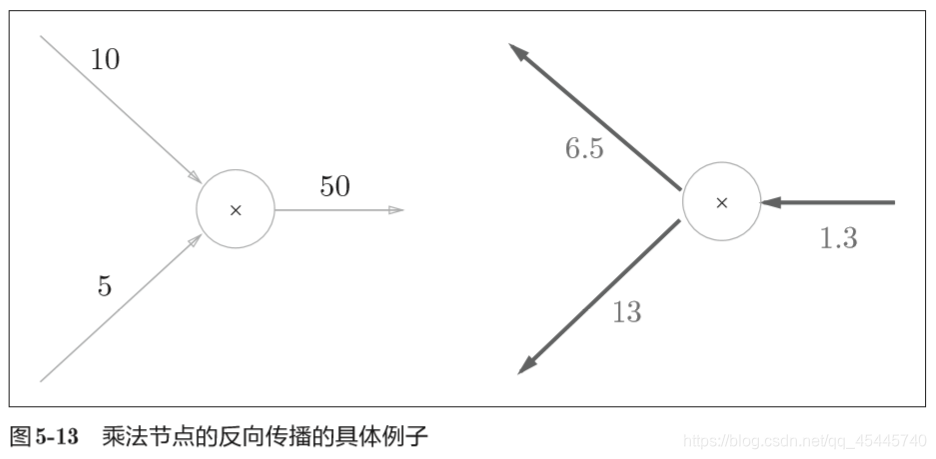
乘法的反向传播会将上游的值乘以正向传播时的输入信号的”翻转值“后传递给下游翻转值表示一种翻转关系,如上面假设的函数z = xy,正向传播时信号是x的话,反向传播时则是y;正向传播时信号是y的话,反向传播时则是x。
乘法的反向传播需要正向传播时的输入信号值,因此,实现乘法节点的反向传播时,要保存正向传播的输入信号。
"""乘法层的实现""" class MulLayer: def __init__(self): self.x = None self.y = None<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">,</span> y<span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>x <span class="token operator">=</span> x self<span class="token punctuation">.</span>y <span class="token operator">=</span> y out <span class="token operator">=</span> x <span class="token operator">*</span> y <span class="token keyword">return</span> out <span class="token keyword">def</span> <span class="token function">backward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> dout<span class="token punctuation">)</span><span class="token punctuation">:</span> dx <span class="token operator">=</span> dout <span class="token operator">*</span> self<span class="token punctuation">.</span>y dy <span class="token operator">=</span> dout <span class="token operator">*</span> self<span class="token punctuation">.</span>x <span class="token keyword">return</span> dx<span class="token punctuation">,</span> dy
# init()中会初始化实例变量x和y,它们用于保存正向传播时的输入值。
# forward()接收x和y两个参数,将它们相乘后输出。backward()将从上游传 来的导数(dout)乘以正向传播的翻转值,然后传给下游。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
5.5 激活函数层的实现
5.5.1 ReLU层
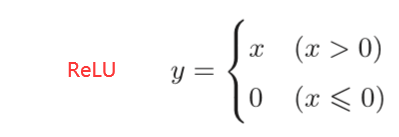
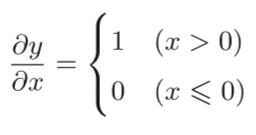
(由上式可知:如果正向传播时的输入x大于0,则反向传播会将上游的值原封不动地传给下游。反过来,如果正向传播时的x小于等于0,则反向传播中传给下游的信号将停在此处。)
"""激活函数是ReLU时的正向与反向传播""" class Relu: def __init__(self): self.mask = None # mask:由True/False构成的NumPy数组<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>mask <span class="token operator">=</span> <span class="token punctuation">(</span>x <span class="token operator"><=</span> <span class="token number">0</span><span class="token punctuation">)</span> <span class="token comment"># 正向传播时,x≤0时,设为True</span> out <span class="token operator">=</span> x<span class="token punctuation">.</span>copy<span class="token punctuation">(</span><span class="token punctuation">)</span> out<span class="token punctuation">[</span>self<span class="token punctuation">.</span>mask<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token number">0</span> <span class="token comment"># 将True的地方设为0</span> <span class="token keyword">return</span> out <span class="token keyword">def</span> <span class="token function">backward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> dout<span class="token punctuation">)</span><span class="token punctuation">:</span> dout<span class="token punctuation">[</span>self<span class="token punctuation">.</span>mask<span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token number">0</span> dx <span class="token operator">=</span> dout <span class="token keyword">return</span> dx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
PS:ReLU层的作用就像电路中的开关一样。正向传播时,有电流通过的话,就将开关设为ON;没有电流通过的话,就将开关设为OFF。 反向传播时,开关为ON的话,电流会直接通过;开关为OFF的话, 则不会有电流通过。
5.5.2 Sigmoid层
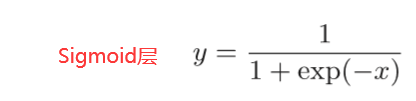
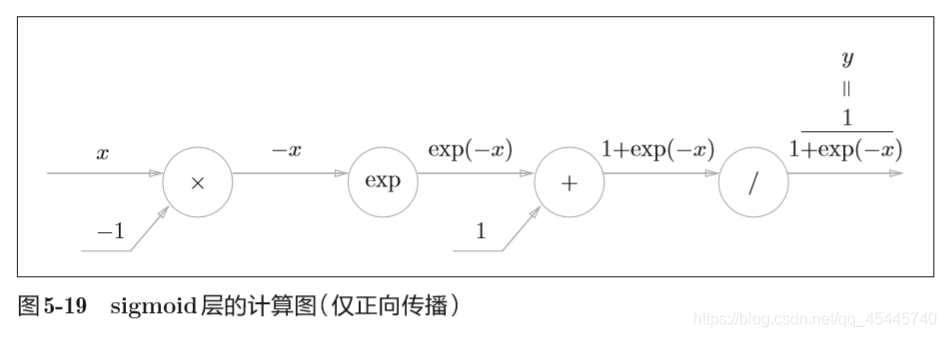
除了“×”和“ +”节点外,还出现了新的“exp”和“ /”节点。 “exp”节点会进行y = exp(x)的计算,“/”节点会进行 的计算。
关于Sigmoid的反向传播见书P142
"""激活函数是Sigmoid时的正向与反向传播""" class Sigmoid: def __init__(self): self.out = None<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span> out <span class="token operator">=</span> sigmoid<span class="token punctuation">(</span>x<span class="token punctuation">)</span> self<span class="token punctuation">.</span>out <span class="token operator">=</span> out <span class="token keyword">return</span> out <span class="token keyword">def</span> <span class="token function">backward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> dout<span class="token punctuation">)</span><span class="token punctuation">:</span> dx <span class="token operator">=</span> dout <span class="token operator">*</span> <span class="token punctuation">(</span><span class="token number">1.0</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>out<span class="token punctuation">)</span> <span class="token operator">*</span> self<span class="token punctuation">.</span>out <span class="token keyword">return</span> dx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5.6 Affine/Softmax层的实现
5.6.1 Affine层
定义:神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换” 。因此,这里将进行仿射变换的处理实现为“Affine层”。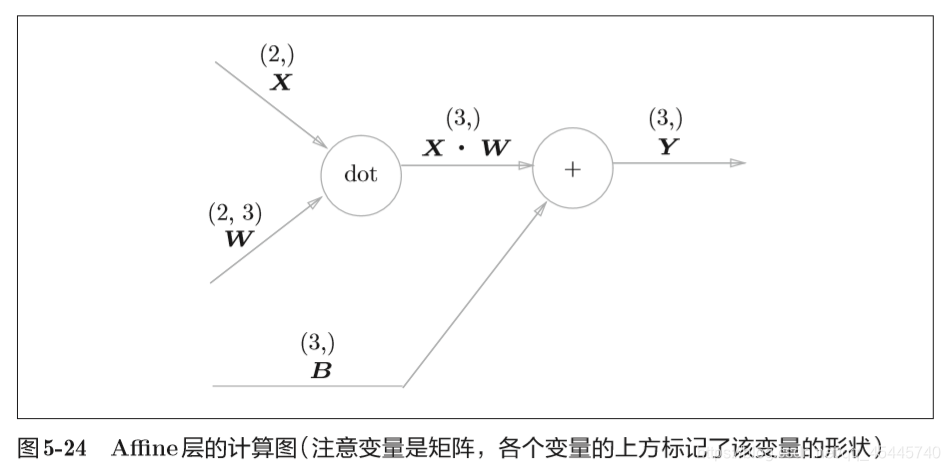
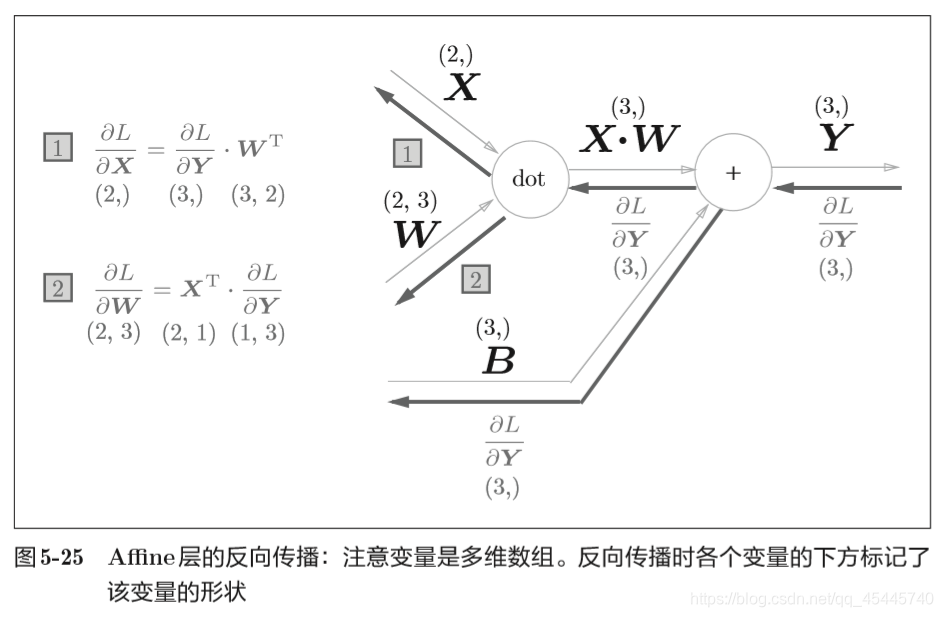
5.6.2 批版本的Affine层
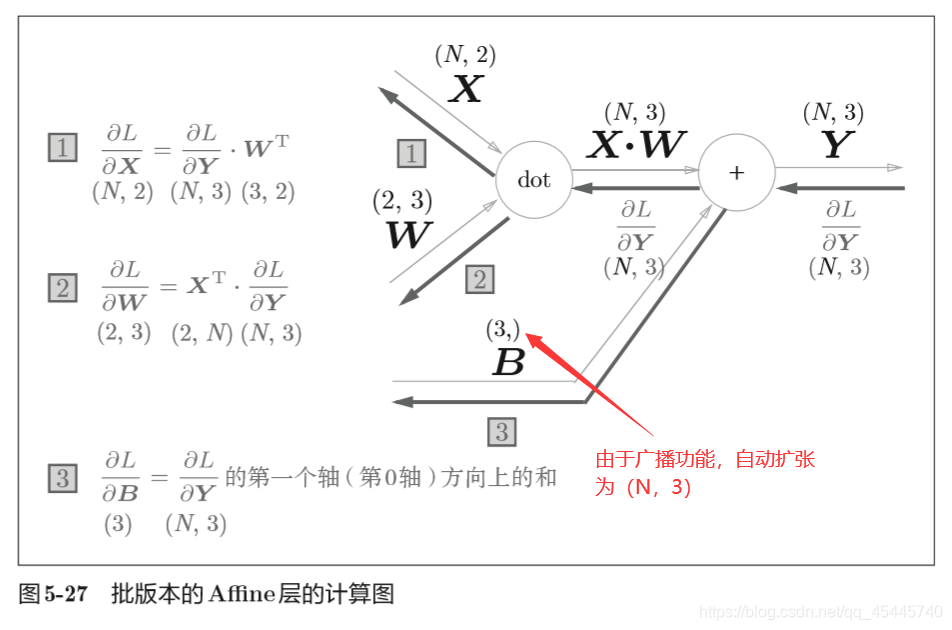
"""批版本的Affine层""" class Affine: def __init__(self, W, b): self.W =W self.b = bself<span class="token punctuation">.</span>x <span class="token operator">=</span> <span class="token boolean">None</span> self<span class="token punctuation">.</span>original_x_shape <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token comment"># 权重和偏置参数的导数</span> self<span class="token punctuation">.</span>dW <span class="token operator">=</span> <span class="token boolean">None</span> self<span class="token punctuation">.</span>db <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment"># 对应张量</span> self<span class="token punctuation">.</span>original_x_shape <span class="token operator">=</span> x<span class="token punctuation">.</span>shape x <span class="token operator">=</span> x<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span>x<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span> self<span class="token punctuation">.</span>x <span class="token operator">=</span> x out <span class="token operator">=</span> np<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>self<span class="token punctuation">.</span>x<span class="token punctuation">,</span> self<span class="token punctuation">.</span>W<span class="token punctuation">)</span> <span class="token operator">+</span> self<span class="token punctuation">.</span>b <span class="token comment"># out = x*w + b</span> <span class="token keyword">return</span> out <span class="token keyword">def</span> <span class="token function">backward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> dout<span class="token punctuation">)</span><span class="token punctuation">:</span> dx <span class="token operator">=</span> np<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>dout<span class="token punctuation">,</span> self<span class="token punctuation">.</span>W<span class="token punctuation">.</span>T<span class="token punctuation">)</span> self<span class="token punctuation">.</span>dW <span class="token operator">=</span> np<span class="token punctuation">.</span>dot<span class="token punctuation">(</span>self<span class="token punctuation">.</span>x<span class="token punctuation">.</span>T<span class="token punctuation">,</span> dout<span class="token punctuation">)</span> self<span class="token punctuation">.</span>db <span class="token operator">=</span> np<span class="token punctuation">.</span><span class="token builtin">sum</span><span class="token punctuation">(</span>dout<span class="token punctuation">,</span> axis<span class="token operator">=</span><span class="token number">0</span><span class="token punctuation">)</span> dx <span class="token operator">=</span> dx<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span><span class="token operator">*</span>self<span class="token punctuation">.</span>original_x_shape<span class="token punctuation">)</span> <span class="token comment"># 还原输入数据的形状(对应张量)</span> <span class="token keyword">return</span> dx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
5.6.3 Soft-with-Loss层
推导过程见书中附录A
"""Soft-with-Loss层""" # x:输入 y:softmax的输出 t:监督标签 class SoftmaxWithLoss: def __init__(self): self.loss = None self.y = None # softmax的输出 self.t = None # 监督数据<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">,</span> t<span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>t <span class="token operator">=</span> t self<span class="token punctuation">.</span>y <span class="token operator">=</span> softmax<span class="token punctuation">(</span>x<span class="token punctuation">)</span> self<span class="token punctuation">.</span>loss <span class="token operator">=</span> cross_entropy_error<span class="token punctuation">(</span>self<span class="token punctuation">.</span>y<span class="token punctuation">,</span> self<span class="token punctuation">.</span>t<span class="token punctuation">)</span> <span class="token keyword">return</span> self<span class="token punctuation">.</span>loss <span class="token keyword">def</span> <span class="token function">backward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> dout<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span><span class="token punctuation">:</span> batch_size <span class="token operator">=</span> self<span class="token punctuation">.</span>t<span class="token punctuation">.</span>shape<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span> <span class="token comment"># eg.t是二维,t.shape[0]表示行的个数</span> <span class="token keyword">if</span> self<span class="token punctuation">.</span>t<span class="token punctuation">.</span>size <span class="token operator">==</span> self<span class="token punctuation">.</span>y<span class="token punctuation">.</span>size<span class="token punctuation">:</span> <span class="token comment"># 监督数据是one-hot-vector的情况</span> dx <span class="token operator">=</span> <span class="token punctuation">(</span>self<span class="token punctuation">.</span>y <span class="token operator">-</span> self<span class="token punctuation">.</span>t<span class="token punctuation">)</span> <span class="token operator">/</span> batch_size <span class="token keyword">else</span><span class="token punctuation">:</span> dx <span class="token operator">=</span> self<span class="token punctuation">.</span>y<span class="token punctuation">.</span>copy<span class="token punctuation">(</span><span class="token punctuation">)</span> dx<span class="token punctuation">[</span>np<span class="token punctuation">.</span>arange<span class="token punctuation">(</span>batch_size<span class="token punctuation">)</span><span class="token punctuation">,</span> self<span class="token punctuation">.</span>t<span class="token punctuation">]</span> <span class="token operator">-=</span> <span class="token number">1</span> dx <span class="token operator">=</span> dx <span class="token operator">/</span> batch_size <span class="token keyword">return</span> dx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
5.7 误差反向传播法的实现
代码思路见P162,源代码中已标了详细注释。
第6章 与学习相关的技巧
6.1 参数的更新
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为最优化(optimization)。
深度学习中的常用数学算法
推荐一个网站:https://www.tensorinfinity.com/viewlab.html
里面可以直观得观察你输入函数的图像,方便理解。
优化器算法比较:
https://www.cnblogs.com/guoyaohua/p/8542554.html
6.1.2 SGD
SGD:随机梯度下降法(stochastic gradient descent)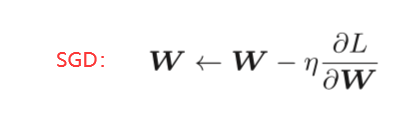
(这里把需要更新的权重参数记为W,把损失函数关于W的梯度记为∂L/∂W。η表示学习率,实际上会取0.01或0.001这些事先决定好的值。式子中的←表示用右边的值更新左边的值。SGD是朝着梯度方向只前 进一定距离的简单方法。)
class SGD: """随机梯度下降法(Stochastic Gradient Descent)"""<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> lr<span class="token operator">=</span><span class="token number">0.01</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>lr <span class="token operator">=</span> lr <span class="token keyword">def</span> <span class="token function">update</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> params<span class="token punctuation">,</span> grads<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">for</span> key <span class="token keyword">in</span> params<span class="token punctuation">.</span>keys<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> params<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-=</span> self<span class="token punctuation">.</span>lr <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token comment">#grads[key]:字典型变量</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
SGD的缺点:
1)由于梯度下降法向目标函数梯度为零的点收敛,因此迭代可能停止在鞍点处。例如,目标函数y2-x2存在鞍点(0, 0),当x轴的初始位置为0时,梯度下降法会停止在鞍点。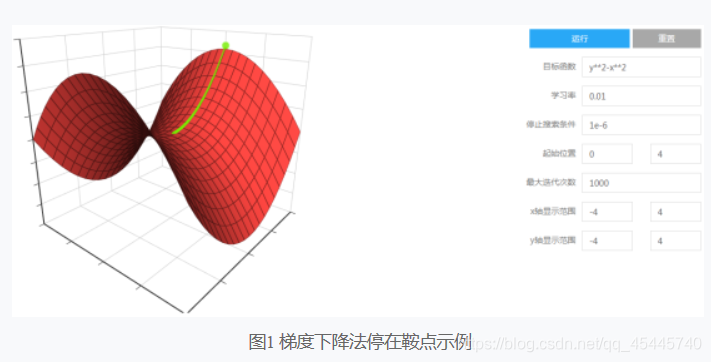
2)梯度下降法只会收敛到极小值点,而不一定是最小值点。当目标函数存在多个极小值点时,初始位置的选择十分重要。例如,目标函数 y4 + 3x4 +8x3- 48*x2存在两个极小值,在默认参数下,梯度下降法会收敛到极小值点而非最小值点。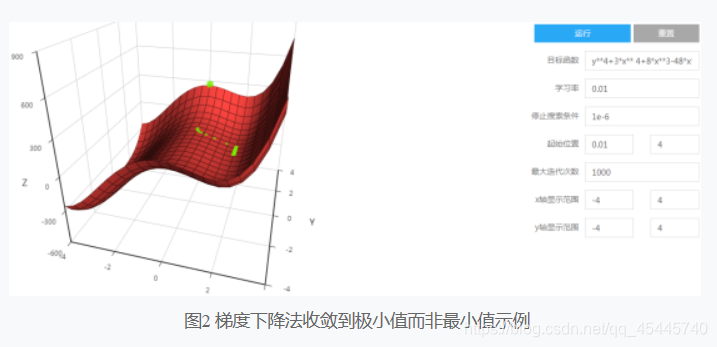
3)梯度下降法的学习率是人为设置的一个参数,当学习率较小时,达到收敛的迭代次数较大。当学习率较大时,会存在极小值点处震荡甚至无法收敛的情况。例如,目标函数为y2+x2,当学习率大于0.5时开始出现震荡现象,当学习率大于等于1时则无法收敛。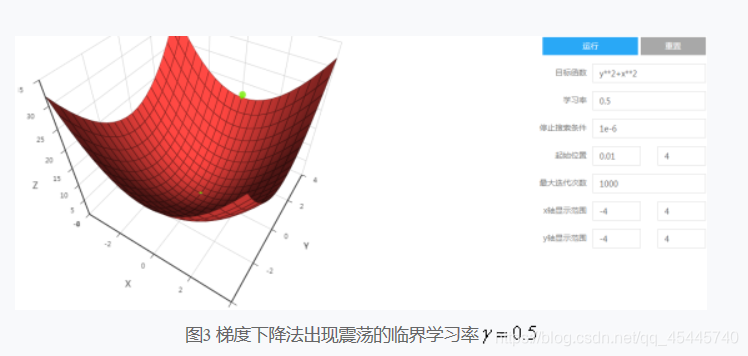


4)在书上那个例子中,SGD的缺点是,如果函数的形状非均向(anisotropic),比如呈延伸状,搜索的路径就会非常低效。因此SGD低效的根本原因是,梯度的方向并没有指向最小值的方向。
6.1.4 Momentum
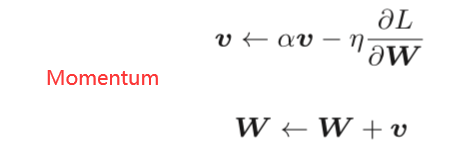
(W表示要更新的权重参数,∂L/∂W表示损失函数关于W的梯度,η表示学习率。这里新出现了一个变量v,对应物理上的速度。 上式表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则。)
class Momentum: """Momentum SGD""" def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None<span class="token keyword">def</span> <span class="token function">update</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> params<span class="token punctuation">,</span> grads<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">if</span> self<span class="token punctuation">.</span>v <span class="token keyword">is</span> <span class="token boolean">None</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>v <span class="token operator">=</span> <span class="token punctuation">{<!-- --></span><span class="token punctuation">}</span> <span class="token keyword">for</span> key<span class="token punctuation">,</span> val <span class="token keyword">in</span> params<span class="token punctuation">.</span>items<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros_like<span class="token punctuation">(</span>val<span class="token punctuation">)</span> <span class="token keyword">for</span> key <span class="token keyword">in</span> params<span class="token punctuation">.</span>keys<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">=</span> self<span class="token punctuation">.</span>momentum<span class="token operator">*</span>self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>lr<span class="token operator">*</span>grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> params<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">+=</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
理解:当我们将一个小球从山上滚下来时,没有阻力的话,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。加入了αv这一项,可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
超参数设定值: 一般 α 取值 0.9 左右。
Momentum缺点:
这种情况相当于小球从山上滚下来时是在盲目地沿着坡滚,如果它能具备一些先知,例如快要上坡时,就知道需要减速了的话,适应性会更好。
牛顿法
https://www.tensorinfinity.com/lab_22.html
BFGS
https://www.tensorinfinity.com/lab_57.html
6.1.5 AdaGrad
在神经网络的学习中,学习率(数学式中记为η)的值很重要。学习率过小, 会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能 正确进行。 在关于学习率的有效技巧中,有一种被称为学习率衰减(learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。实际上,一开始“多” 学,然后逐渐“少”学的方法,在神经网络的学习中经常被使用。 逐渐减小学习率的想法,相当于将“全体”参数的学习率值一起降低。 而AdaGrad进一步发展了这个想法,针对“一个一个“的参数,赋予其“定制”的值。 AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习 (AdaGrad的Ada来自英文单词Adaptive,即“适当的”的意思)。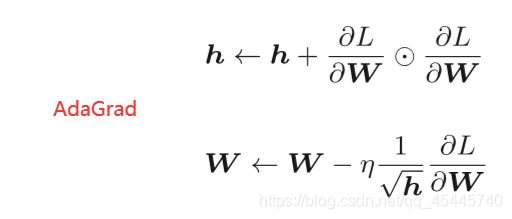
(W表示要更新的权重参数,∂L/∂W表示损失函数关于W的梯度,η表示学习率。这里新出现了变量h,它保存了以前的所有梯度值的平方和。然后,在更新参数时,通过乘以1/根号下h ,就可以调整学习的尺度。这意味着, 参数的元素中变动较大(被大幅更新)的元素的学习率将变小。也就是说, 可以按参数的元素进行学习率衰减,使变动大的参数的学习率逐渐减小。)
class AdaGrad: """AdaGrad"""<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> lr<span class="token operator">=</span><span class="token number">0.01</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>lr <span class="token operator">=</span> lr self<span class="token punctuation">.</span>h <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token keyword">def</span> <span class="token function">update</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> params<span class="token punctuation">,</span> grads<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">if</span> self<span class="token punctuation">.</span>h <span class="token keyword">is</span> <span class="token boolean">None</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>h <span class="token operator">=</span> <span class="token punctuation">{<!-- --></span><span class="token punctuation">}</span> <span class="token keyword">for</span> key<span class="token punctuation">,</span> val <span class="token keyword">in</span> params<span class="token punctuation">.</span>items<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>h<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros_like<span class="token punctuation">(</span>val<span class="token punctuation">)</span> <span class="token keyword">for</span> key <span class="token keyword">in</span> params<span class="token punctuation">.</span>keys<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>h<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">+=</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> params<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-=</span> self<span class="token punctuation">.</span>lr <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">/</span> <span class="token punctuation">(</span>np<span class="token punctuation">.</span>sqrt<span class="token punctuation">(</span>self<span class="token punctuation">.</span>h<span class="token punctuation">[</span>key<span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">7</span><span class="token punctuation">)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
AdaGrad总结:
1)AdaGrad算法可以对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性。
2)Adagrad 的优点是减少了学习率的手动调节;超参数设定值:一般η选取0.01;缺点是它的缺点是分母会不断积累,这样学习率就会收缩并最终会变得非常小。
3)AdaGrad考虑了从开始到当前迭代时的所有梯度值,随着迭代次数的增加学习率逐渐下降,与标准梯度下降法相比,需要更多的迭代次数才能达到相同的效果,训练速度较慢。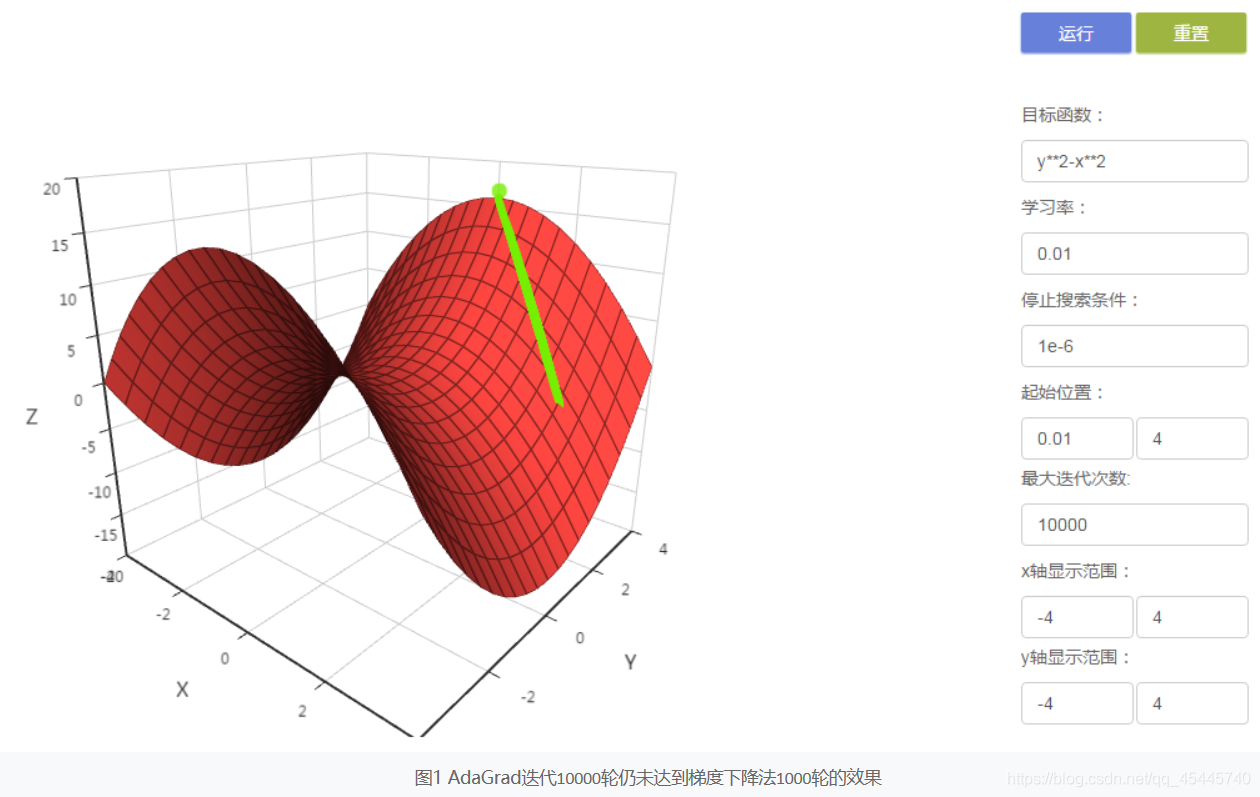 4)与标准梯度下降法相比,Adagrad算法收敛性较好,不易出现震荡现象。
4)与标准梯度下降法相比,Adagrad算法收敛性较好,不易出现震荡现象。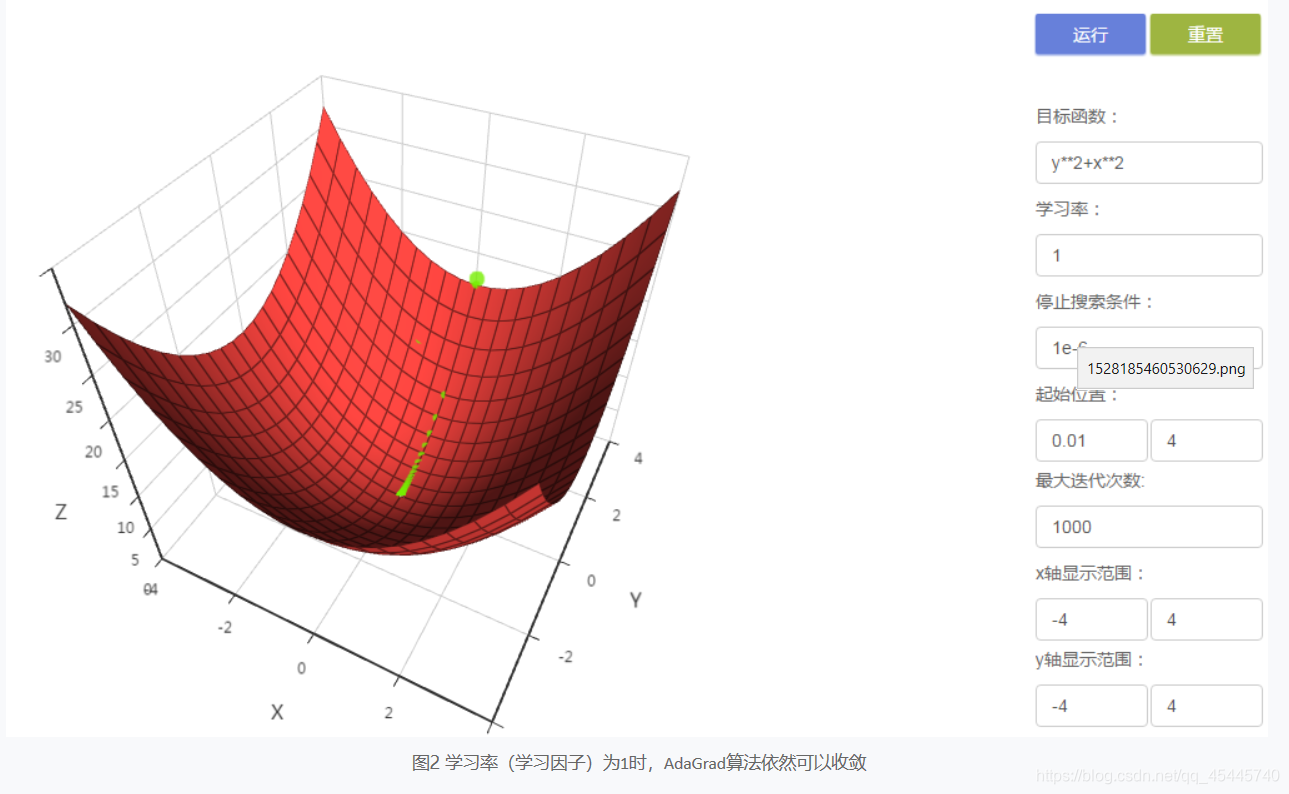
5)AdaGrad算法存在停止在鞍点处的情况。例如,目标函数y2-x2存在鞍点(0, 0),当x轴的初始位置为0时,迭代会停止在鞍点。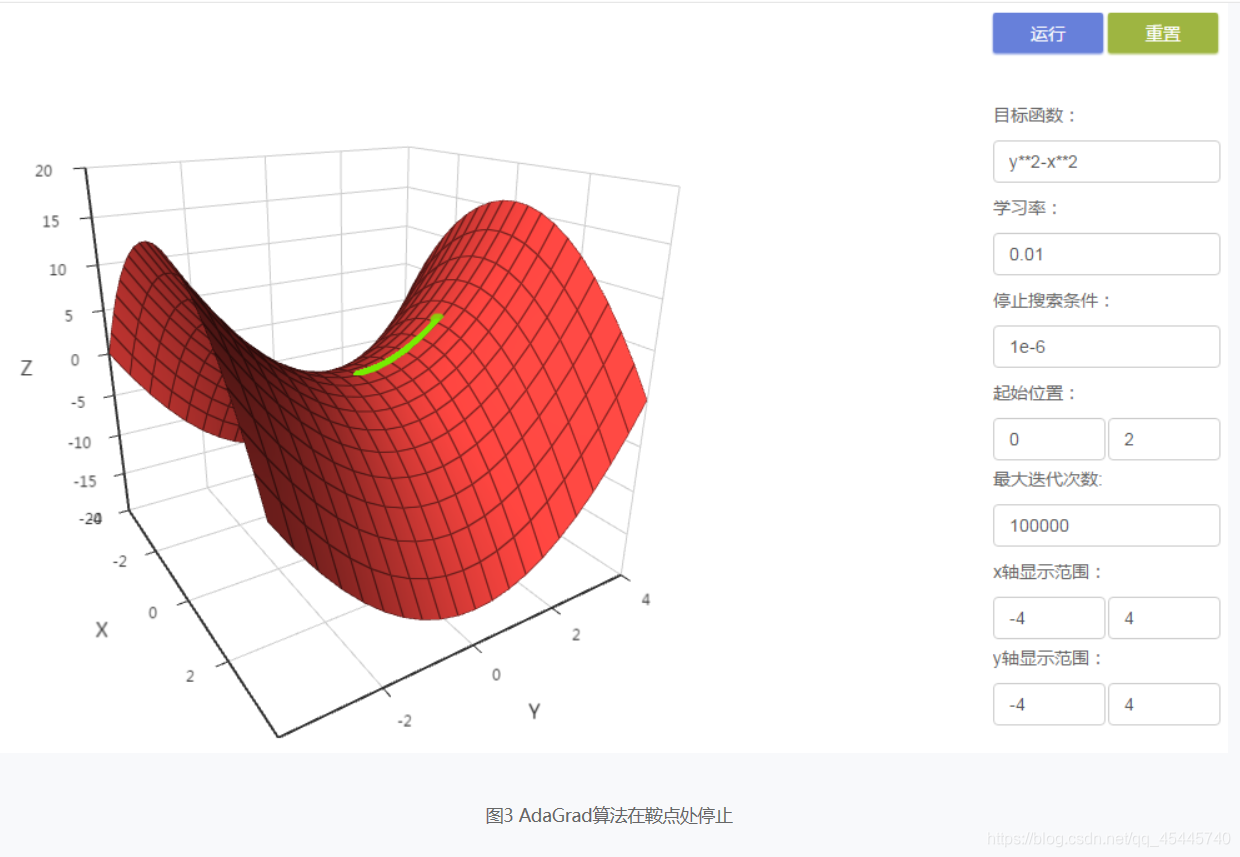
6)AdaGrad算法只会收敛到极小值点,而不一定是最小值点。当目标函数存在多个极小值点时,初始位置的选择十分重要。例如,目标函数y4+3x4+8x3-48*x2存在两个极小值,在默认参数下,AdaGrad算法会收敛到极小值点而非最小值点。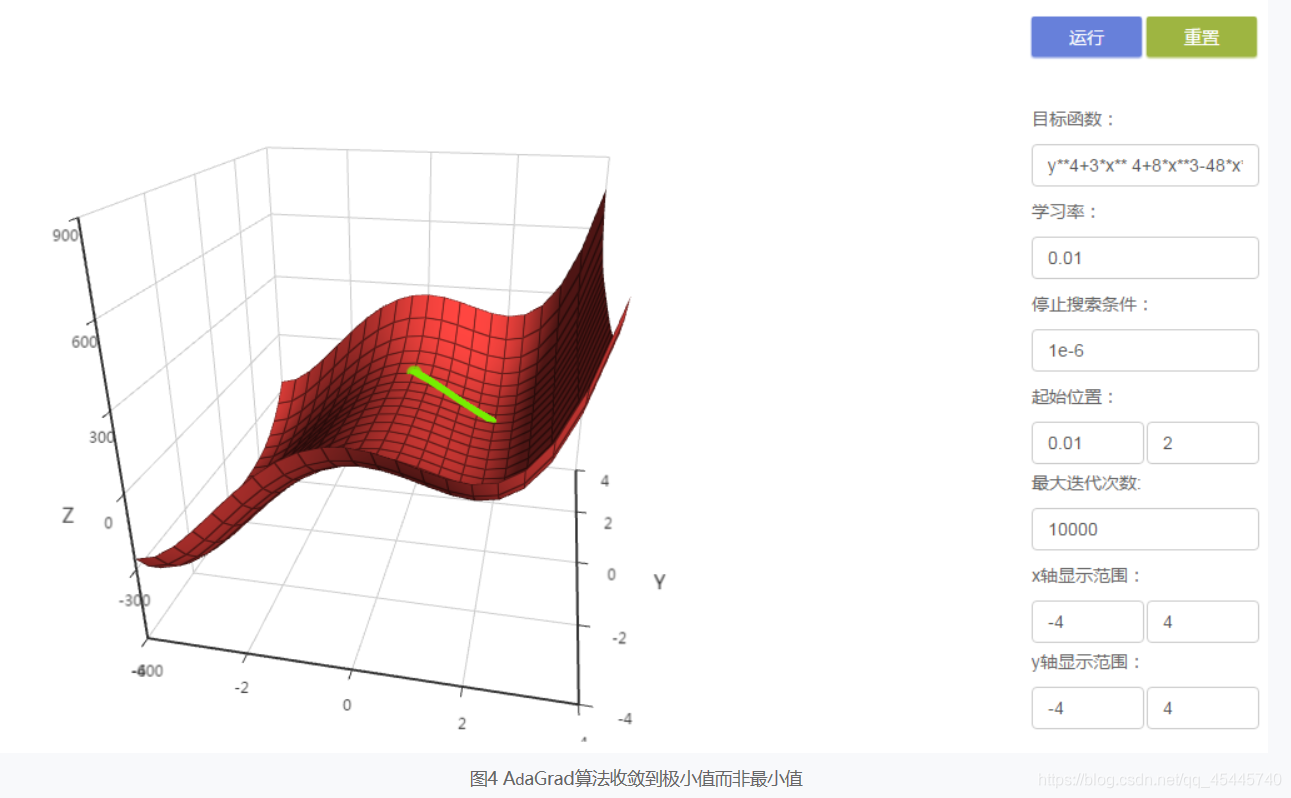
AdaDelta
https://www.tensorinfinity.com/lab_23.html
RMSprop
RMSprop 和 Adadelta 都是为了解决 Adagrad 学习率急剧下降问题的。
AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。实际上,如果无止境地学习,更新量就会变为0, 完全不再更新。为了改善这个问题,可以使用RMSProp方法。 RMSProp方法并不是将过去所有的梯度一视同仁地相加,而是逐渐地遗忘过去的梯度,在做加法运算时将新梯度的信息更多地反映出来。 这种操作从专业上讲,称为“指数移动平均”,呈指数函数式地减小过去的梯度的尺度。
https://www.tensorinfinity.com/lab_63.html
class RMSprop: """RMSprop"""<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> lr<span class="token operator">=</span><span class="token number">0.01</span><span class="token punctuation">,</span> decay_rate <span class="token operator">=</span> <span class="token number">0.99</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>lr <span class="token operator">=</span> lr self<span class="token punctuation">.</span>decay_rate <span class="token operator">=</span> decay_rate self<span class="token punctuation">.</span>h <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token keyword">def</span> <span class="token function">update</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> params<span class="token punctuation">,</span> grads<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">if</span> self<span class="token punctuation">.</span>h <span class="token keyword">is</span> <span class="token boolean">None</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>h <span class="token operator">=</span> <span class="token punctuation">{<!-- --></span><span class="token punctuation">}</span> <span class="token keyword">for</span> key<span class="token punctuation">,</span> val <span class="token keyword">in</span> params<span class="token punctuation">.</span>items<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>h<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros_like<span class="token punctuation">(</span>val<span class="token punctuation">)</span> <span class="token keyword">for</span> key <span class="token keyword">in</span> params<span class="token punctuation">.</span>keys<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>h<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">*=</span> self<span class="token punctuation">.</span>decay_rate self<span class="token punctuation">.</span>h<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">+=</span> <span class="token punctuation">(</span><span class="token number">1</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>decay_rate<span class="token punctuation">)</span> <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> params<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-=</span> self<span class="token punctuation">.</span>lr <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">/</span> <span class="token punctuation">(</span>np<span class="token punctuation">.</span>sqrt<span class="token punctuation">(</span>self<span class="token punctuation">.</span>h<span class="token punctuation">[</span>key<span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">7</span><span class="token punctuation">)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Nesterov
https://www.tensorinfinity.com/lab_61.html
Nesterov Accelerated Gradient(NAG)
梯度更新规则:
用 θ−γv_t−1 来近似当做参数下一步会变成的值,则在计算梯度时,不是在当前位置,而是未来的位置上。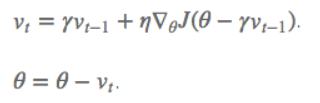
超参数设定值: 一般 γ 仍取值 0.9 左右。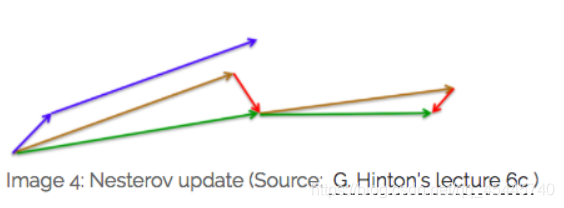
蓝色是 Momentum 的过程,会先计算当前的梯度,然后在更新后的累积梯度后会有一个大的跳跃。而Nesterov会先在前一步的累积梯度上(brown vector)有一个大的跳跃,然后衡量一下梯度做一下修正(red vector),这种预期的更新可以避免我们走的太快。
Nesterov可以使 RNN 在很多任务上有更好的表现。
目前为止,我们可以做到,在更新梯度时顺应 loss function 的梯度来调整速度,并且对 SGD 进行加速。我们还希望可以根据参数的重要性而对不同的参数进行不同程度的更新。
class Nesterov: """Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> lr<span class="token operator">=</span><span class="token number">0.01</span><span class="token punctuation">,</span> momentum<span class="token operator">=</span><span class="token number">0.9</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>lr <span class="token operator">=</span> lr self<span class="token punctuation">.</span>momentum <span class="token operator">=</span> momentum self<span class="token punctuation">.</span>v <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token keyword">def</span> <span class="token function">update</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> params<span class="token punctuation">,</span> grads<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">if</span> self<span class="token punctuation">.</span>v <span class="token keyword">is</span> <span class="token boolean">None</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>v <span class="token operator">=</span> <span class="token punctuation">{<!-- --></span><span class="token punctuation">}</span> <span class="token keyword">for</span> key<span class="token punctuation">,</span> val <span class="token keyword">in</span> params<span class="token punctuation">.</span>items<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros_like<span class="token punctuation">(</span>val<span class="token punctuation">)</span> <span class="token keyword">for</span> key <span class="token keyword">in</span> params<span class="token punctuation">.</span>keys<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">*=</span> self<span class="token punctuation">.</span>momentum self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-=</span> self<span class="token punctuation">.</span>lr <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> params<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">+=</span> self<span class="token punctuation">.</span>momentum <span class="token operator">*</span> self<span class="token punctuation">.</span>momentum <span class="token operator">*</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> params<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-=</span> <span class="token punctuation">(</span><span class="token number">1</span> <span class="token operator">+</span> self<span class="token punctuation">.</span>momentum<span class="token punctuation">)</span> <span class="token operator">*</span> self<span class="token punctuation">.</span>lr <span class="token operator">*</span> grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
6.1.6 Adam
Adam算法全称为adaptive moment estimation自适应矩估计。
Adam直观介绍
class Adam: """Adam (http://arxiv.org/abs/1412.6980v8)"""<span class="token keyword">def</span> <span class="token function">__init__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> lr<span class="token operator">=</span><span class="token number">0.001</span><span class="token punctuation">,</span> beta1<span class="token operator">=</span><span class="token number">0.9</span><span class="token punctuation">,</span> beta2<span class="token operator">=</span><span class="token number">0.999</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>lr <span class="token operator">=</span> lr self<span class="token punctuation">.</span>beta1 <span class="token operator">=</span> beta1 self<span class="token punctuation">.</span>beta2 <span class="token operator">=</span> beta2 self<span class="token punctuation">.</span><span class="token builtin">iter</span> <span class="token operator">=</span> <span class="token number">0</span> self<span class="token punctuation">.</span>m <span class="token operator">=</span> <span class="token boolean">None</span> self<span class="token punctuation">.</span>v <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token keyword">def</span> <span class="token function">update</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> params<span class="token punctuation">,</span> grads<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">if</span> self<span class="token punctuation">.</span>m <span class="token keyword">is</span> <span class="token boolean">None</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>m<span class="token punctuation">,</span> self<span class="token punctuation">.</span>v <span class="token operator">=</span> <span class="token punctuation">{<!-- --></span><span class="token punctuation">}</span><span class="token punctuation">,</span> <span class="token punctuation">{<!-- --></span><span class="token punctuation">}</span> <span class="token keyword">for</span> key<span class="token punctuation">,</span> val <span class="token keyword">in</span> params<span class="token punctuation">.</span>items<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> self<span class="token punctuation">.</span>m<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros_like<span class="token punctuation">(</span>val<span class="token punctuation">)</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros_like<span class="token punctuation">(</span>val<span class="token punctuation">)</span> self<span class="token punctuation">.</span><span class="token builtin">iter</span> <span class="token operator">+=</span> <span class="token number">1</span> lr_t <span class="token operator">=</span> self<span class="token punctuation">.</span>lr <span class="token operator">*</span> np<span class="token punctuation">.</span>sqrt<span class="token punctuation">(</span><span class="token number">1.0</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>beta2<span class="token operator">**</span>self<span class="token punctuation">.</span><span class="token builtin">iter</span><span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token punctuation">(</span><span class="token number">1.0</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>beta1<span class="token operator">**</span>self<span class="token punctuation">.</span><span class="token builtin">iter</span><span class="token punctuation">)</span> <span class="token keyword">for</span> key <span class="token keyword">in</span> params<span class="token punctuation">.</span>keys<span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token comment">#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]</span> <span class="token comment">#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)</span> self<span class="token punctuation">.</span>m<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">+=</span> <span class="token punctuation">(</span><span class="token number">1</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>beta1<span class="token punctuation">)</span> <span class="token operator">*</span> <span class="token punctuation">(</span>grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>m<span class="token punctuation">[</span>key<span class="token punctuation">]</span><span class="token punctuation">)</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">+=</span> <span class="token punctuation">(</span><span class="token number">1</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>beta2<span class="token punctuation">)</span> <span class="token operator">*</span> <span class="token punctuation">(</span>grads<span class="token punctuation">[</span>key<span class="token punctuation">]</span><span class="token operator">**</span><span class="token number">2</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span><span class="token punctuation">)</span> params<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">-=</span> lr_t <span class="token operator">*</span> self<span class="token punctuation">.</span>m<span class="token punctuation">[</span>key<span class="token punctuation">]</span> <span class="token operator">/</span> <span class="token punctuation">(</span>np<span class="token punctuation">.</span>sqrt<span class="token punctuation">(</span>self<span class="token punctuation">.</span>v<span class="token punctuation">[</span>key<span class="token punctuation">]</span><span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token number">1e</span><span class="token operator">-</span><span class="token number">7</span><span class="token punctuation">)</span> <span class="token comment">#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias</span> <span class="token comment">#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias</span> <span class="token comment">#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
6.1.7 使用哪种更新方法
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
6.2 权重的初始值
6.2.1 可以将权重初始值设为0吗
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上, 在这之前的权重初始值都是像0.01 * np.random.randn(10, 100)这样,使用 由高斯分布生成的值乘以0.01后得到的值(标准差为0.01的高斯分布)。
6.2.2 Xavier初始值
比如,Caffe框架中,通过在设定权重初始值时赋予xavier参数, 就可以使用Xavier初始值。
如果前一层的节点数为n,则初始 值使用标准差为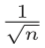 的分布。
的分布。
tanh函数
tanh是双曲函数中的一个,tanh()为双曲正切。在数学中,双曲正切“tanh”是由基本双曲函数双曲正弦和双曲余弦推导而来。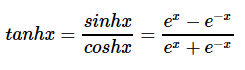
6.2.3 ReLU的权重初始值——He初始值

Batch Normalization
Batch Norm的思路是调整各层的激活值分布使其拥有适当 的广度。为此,要向神经网络中插入对数据分布进行正规化的层,即Batch Normalization层(简称Batch Norm层)。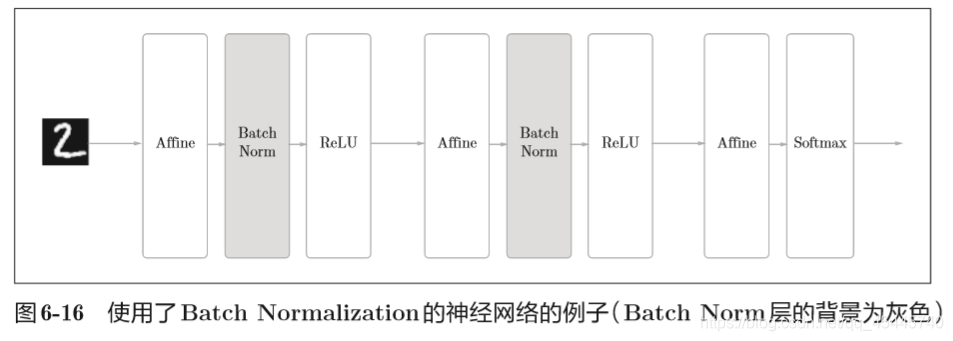

(这里对mini-batch的m个输入数据的集合B ={x1,x2,…,xm}求均值 µB和方差σ2B。然后,对输入数据进行均值为0、方差为1(合适的分布)的正规化。其中的 ε是一个微小值(比如,10e-7等),它是为了防止出现除以0的情况。
上式所做的是将mini-batch的输入数据{x1,x 2,…,xm}变换为均值为0、方差为1的数据 ,非常简单。通过将这个处理插入到激活函数的前面(或者后面),可以减小数据分布的偏向。 )
6.4 正则化
6.4.1 过拟合
定义:过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。
发生过拟合的原因:
①模型拥有大量参数、表现力强。
② 训练数据少。
6.4.2 权值衰减(L1、L2、L∞范数)
权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。很多过拟合原本就是因为权重参数取值过大才发生的。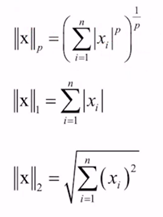
||x||1也称为L1范数,是各个元素的绝对值之和
||x||2也称为L2范数
||x||∞也称为L∞范数,或Max范数
6.4.3 Dropout
上节说到抑制过拟合的方法,为损失函数加上权重的L2范数的权值衰减方法。该方法可以在某种程度上能够抑制过拟合。 但是,如果网络的模型变得很复杂,权值衰减就难以应对。在这种情 况下,经常会使用Dropout方法。 Dropout是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递。如下图所示: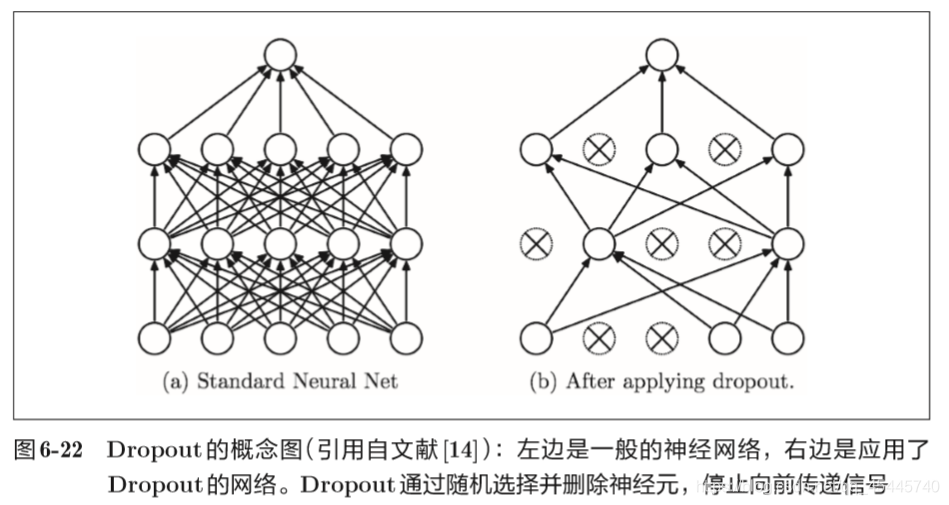
class Dropout: def __init__(self, dropout_ratio=0.5): self.dropout_ratio = dropout_ratio self.mask = None<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">,</span> train_flg<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">if</span> train_flg<span class="token punctuation">:</span> self<span class="token punctuation">.</span>mask <span class="token operator">=</span> np<span class="token punctuation">.</span>random<span class="token punctuation">.</span>rand<span class="token punctuation">(</span><span class="token operator">*</span>x<span class="token punctuation">.</span>shape<span class="token punctuation">)</span> <span class="token operator">></span> self<span class="token punctuation">.</span>dropout_ratio <span class="token keyword">return</span> x <span class="token operator">*</span> self<span class="token punctuation">.</span>mask <span class="token keyword">else</span><span class="token punctuation">:</span> <span class="token keyword">return</span> x <span class="token operator">*</span> <span class="token punctuation">(</span><span class="token number">1.0</span> <span class="token operator">-</span> self<span class="token punctuation">.</span>dropout_ratio<span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">backward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> dout<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">return</span> dout <span class="token operator">*</span> self<span class="token punctuation">.</span>mask
# 每次正向传播时,self.mask中都会以False的形式保 存要删除的神经元。
# self.mask会随机生成和x形状相同的数组,并将值比dropout_ratio大的元素设为True。
# 反向传播时的行为和ReLU相同。也就是说, 正向传播时传递了信号的神经元,
#反向传播时按原样传递信号;正向传播时没有传递信号的神经元,
#反向传播时信号将停在那里。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
6.5 超参数的验证
之前对于数据集,是将其分为训练集和测试集,训练数据用于学习,测试数据用于评估泛化能力。现在,还要分出一个验证集,训练数据用于参数(权重和偏置)的学习,验证数据用于超参数的性能评估。为了确认泛化能力,要在最后使用(比较理想的是只用一次) 测试数据。
import numpy as np
np.random.shuffle # 现场修改序列,改变自身内容(类似洗牌,打乱顺序)
- 1
- 2
第7章 卷积神经网络
7.1 整体结构
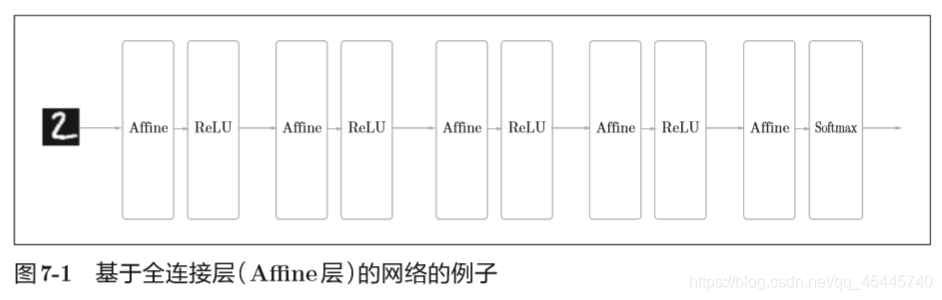
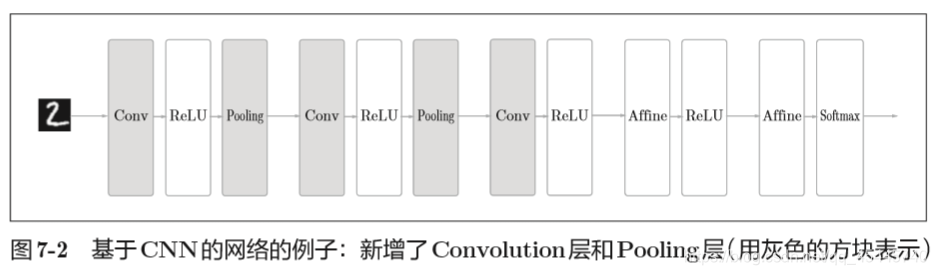
除了之前介绍的Affine层(也称全连接层:相邻层的所有神经元之间都有连接),新增加了卷积层(Convolution层)和池化层(Pooling层)。
7.2 卷积层
7.2.1 全连接层存在的问题
输入数据是图像时,图像通常是高、长、通道方向上的3维形状。但是,向全连接层输入时,需要将3维数据拉平为1维数据。就像前面的手写数字识别例子中,输入图像就是1通道、高28像素、长28像素 的(1, 28, 28)形状,但却被排成1列,以784个数据的形式输入到最开始的 Affine层。
而卷积层可以保持形状不变。当输入数据是图像时,卷积层会以3维数据的形式接收输入数据,并同样以3维数据的形式输出至下一层。因此, 在CNN中,可以(有可能)正确理解图像等具有形状的数据。
7.2.2 卷积运算 & 7.2.3 填充 & 7.2.4 步幅 & 7.2.5 3维数据的卷积运算
书上的图解讲的很明白。
7.3 池化层
池化是缩小高、长方向上的空间的运算,池化层就是下采样,且对微小的位置变化具有鲁棒性(健壮) 。
7.4 卷积层和池化层的实现
7.4.2 基于im2col的展开
如果老老实实地实现卷积运算,要重复好几层的for语句。这样的实现有点麻烦,而且,NumPy中存在使用for语句后处理变慢的缺点(NumPy 中,访问元素时最好不要用for语句)。这里,我们不使用for语句,而是使用im2col这个便利的函数进行简单的实现。 im2col是一个函数,将输入数据展开以适合滤波器(权重)。如下图所示, 对3维的输入数据应用im2col后,数据转换为2维矩阵(正确地讲,是把包含批数量的4维数据转换成了2维数据)。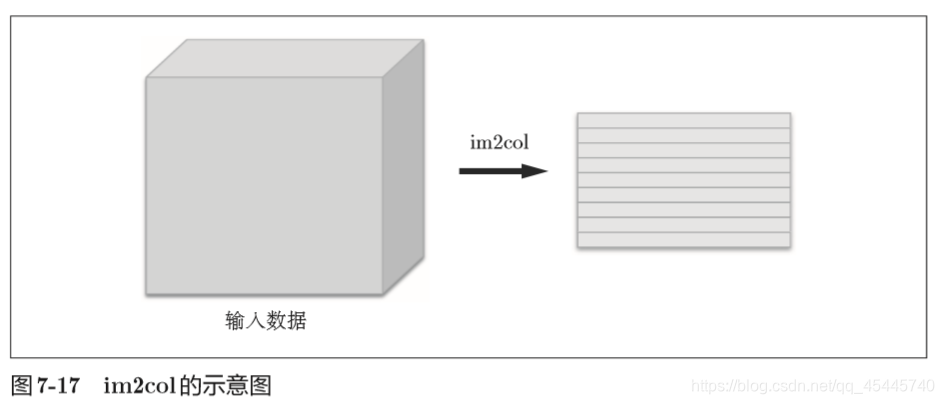
im2col这个名称是“image to column”的缩写,翻译过来就是“从图像到矩阵”的意思。Caffe、Chainer等深度学习框架中有名为 im2col的函数,并且在卷积层的实现中,都使用了im2col。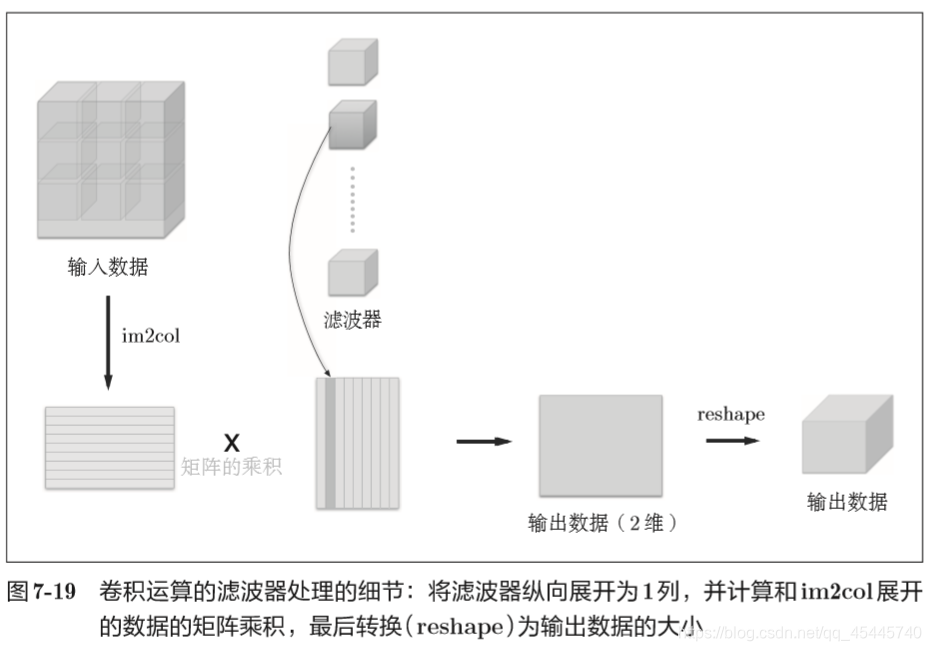
def im2col(input_data, filter_h, filter_w, stride=1, pad=0): """Parameters ---------- input_data : 由(数据量, 通道, 高, 长)的4维数组构成的输入数据 filter_h : 滤波器的高 filter_w : 滤波器的长 stride : 步幅 pad : 填充 Returns ------- col : 2维数组 """</span> N<span class="token punctuation">,</span> C<span class="token punctuation">,</span> H<span class="token punctuation">,</span> W <span class="token operator">=</span> input_data<span class="token punctuation">.</span>shape out_h <span class="token operator">=</span> <span class="token punctuation">(</span>H <span class="token operator">+</span> <span class="token number">2</span><span class="token operator">*</span>pad <span class="token operator">-</span> filter_h<span class="token punctuation">)</span><span class="token operator">//</span>stride <span class="token operator">+</span> <span class="token number">1</span> out_w <span class="token operator">=</span> <span class="token punctuation">(</span>W <span class="token operator">+</span> <span class="token number">2</span><span class="token operator">*</span>pad <span class="token operator">-</span> filter_w<span class="token punctuation">)</span><span class="token operator">//</span>stride <span class="token operator">+</span> <span class="token number">1</span> img <span class="token operator">=</span> np<span class="token punctuation">.</span>pad<span class="token punctuation">(</span>input_data<span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span><span class="token number">0</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span><span class="token number">0</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token punctuation">(</span>pad<span class="token punctuation">,</span> pad<span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token punctuation">(</span>pad<span class="token punctuation">,</span> pad<span class="token punctuation">)</span><span class="token punctuation">]</span><span class="token punctuation">,</span> <span class="token string">'constant'</span><span class="token punctuation">)</span> col <span class="token operator">=</span> np<span class="token punctuation">.</span>zeros<span class="token punctuation">(</span><span class="token punctuation">(</span>N<span class="token punctuation">,</span> C<span class="token punctuation">,</span> filter_h<span class="token punctuation">,</span> filter_w<span class="token punctuation">,</span> out_h<span class="token punctuation">,</span> out_w<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">for</span> y <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span>filter_h<span class="token punctuation">)</span><span class="token punctuation">:</span> y_max <span class="token operator">=</span> y <span class="token operator">+</span> stride<span class="token operator">*</span>out_h <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span><span class="token punctuation">(</span>filter_w<span class="token punctuation">)</span><span class="token punctuation">:</span> x_max <span class="token operator">=</span> x <span class="token operator">+</span> stride<span class="token operator">*</span>out_w col<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">,</span> y<span class="token punctuation">,</span> x<span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">]</span> <span class="token operator">=</span> img<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span> <span class="token punctuation">:</span><span class="token punctuation">,</span> y<span class="token punctuation">:</span>y_max<span class="token punctuation">:</span>stride<span class="token punctuation">,</span> x<span class="token punctuation">:</span>x_max<span class="token punctuation">:</span>stride<span class="token punctuation">]</span> col <span class="token operator">=</span> col<span class="token punctuation">.</span>transpose<span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">4</span><span class="token punctuation">,</span> <span class="token number">5</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">2</span><span class="token punctuation">,</span> <span class="token number">3</span><span class="token punctuation">)</span><span class="token punctuation">.</span>reshape<span class="token punctuation">(</span>N<span class="token operator">*</span>out_h<span class="token operator">*</span>out_w<span class="token punctuation">,</span> <span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">)</span> <span class="token keyword">return</span> col
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
7.4.4 池化层的实现
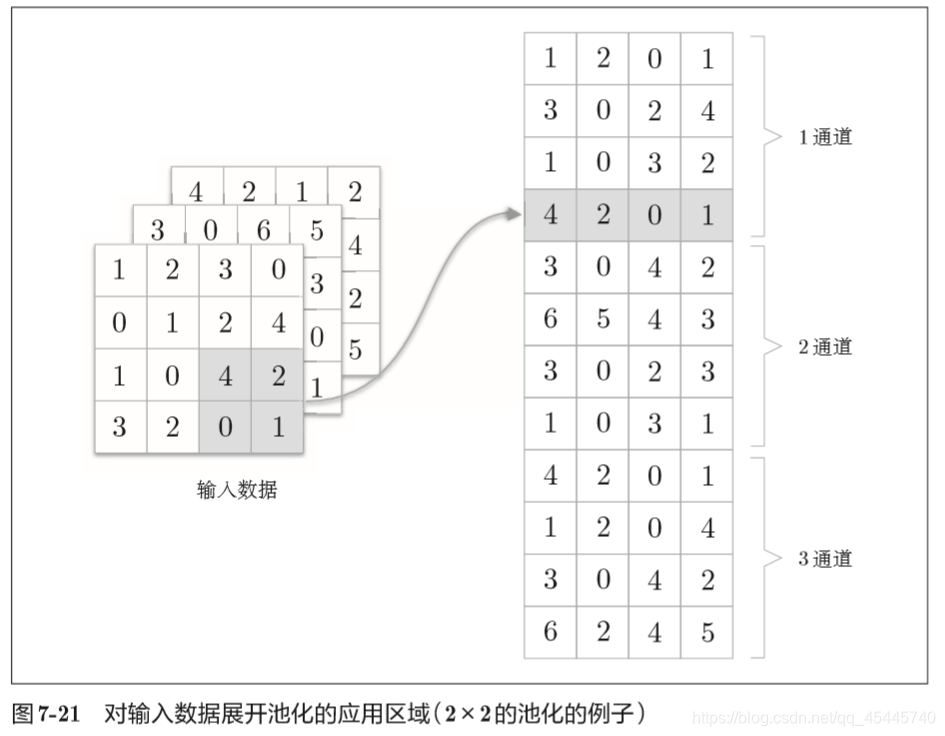
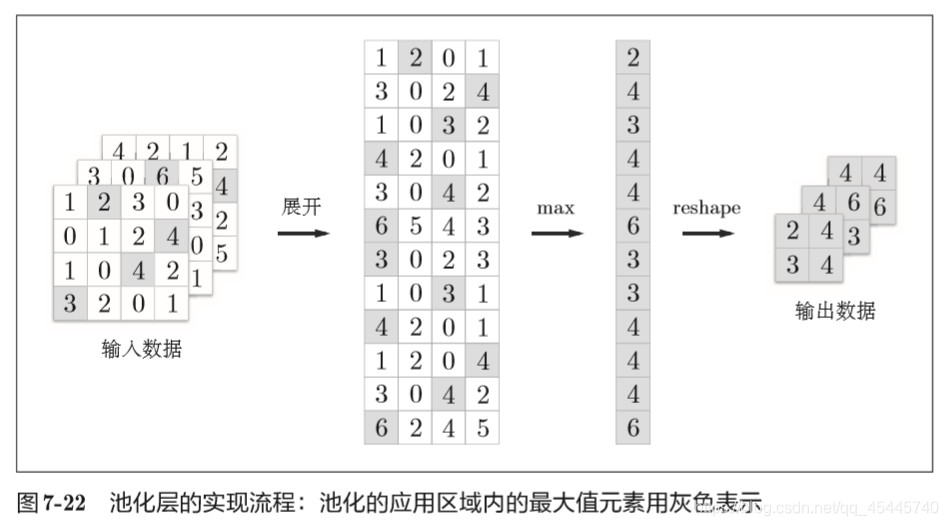
class Pooling: def __init__(self, pool_h, pool_w, stride=1, pad=0): self.pool_h = pool_h self.pool_w = pool_w self.stride = stride self.pad = pad<span class="token keyword">def</span> <span class="token function">forward</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> x<span class="token punctuation">)</span><span class="token punctuation">:</span> N<span class="token punctuation">,</span> C<span class="token punctuation">,</span> H<span class="token punctuation">,</span> W <span class="token operator">=</span> x<span class="token punctuation">.</span>shape out_h <span class="token operator">=</span> <span class="token builtin">int</span><span class="token punctuation">(</span><span class="token number">1</span> <span class="token operator">+</span> <span class="token punctuation">(</span>H <span class="token operator">-</span> self<span class="token punctuation">.</span>pool_h<span class="token punctuation">)</span> <span class="token operator">/</span> self<span class="token punctuation">.</span>stride<span class="token punctuation">)</span> out_w <span class="token operator">=</span> <span class="token builtin">int</span><span class="token punctuation">(</span><span class="token number">1</span> <span class="token operator">+</span> <span class="token punctuation">(</span>W <span class="token operator">-</span> self<span class="token punctuation">.</span>pool_w<span class="token punctuation">)</span> <span class="token operator">/</span> self<span class="token punctuation">.</span>stride<span class="token punctuation">)</span> <span class="token comment"># 展开(1) </span> col <span class="token operator">=</span> im2col<span class="token punctuation">(</span>x<span class="token punctuation">,</span> self<span class="token punctuation">.</span>pool_h<span class="token punctuation">,</span> self<span class="token punctuation">.</span>pool_w<span class="token punctuation">,</span> self<span class="token punctuation">.</span>stride<span class="token punctuation">,</span> self<span class="token punctuation">.</span>pad<span class="token punctuation">)</span> col <span class="token operator">=</span> col<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span><span class="token operator">-</span><span class="token number">1</span><span class="token punctuation">,</span> self<span class="token punctuation">.</span>pool_h<span class="token operator">*</span>self<span class="token punctuation">.</span>pool_w<span class="token punctuation">)</span> <span class="token comment"># 最大值(2) </span> out <span class="token operator">=</span> np<span class="token punctuation">.</span><span class="token builtin">max</span><span class="token punctuation">(</span>col<span class="token punctuation">,</span> axis<span class="token operator">=</span><span class="token number">1</span><span class="token punctuation">)</span> <span class="token comment"># 转换(3) </span> out <span class="token operator">=</span> out<span class="token punctuation">.</span>reshape<span class="token punctuation">(</span>N<span class="token punctuation">,</span> out_h<span class="token punctuation">,</span> out_w<span class="token punctuation">,</span> C<span class="token punctuation">)</span><span class="token punctuation">.</span>transpose<span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">,</span> <span class="token number">3</span><span class="token punctuation">,</span> <span class="token number">1</span><span class="token punctuation">,</span> <span class="token number">2</span><span class="token punctuation">)</span> <span class="token keyword">return</span> out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
第8章 深度学习
8.1.2 进一步提高识别精度——Data Augmentation
Data Augmentation基于算法“人为地”扩充输入图像(训练图像)。具体地说,对于输入图像,通过施加旋转、垂直或水平方向上的移动等微小变化,增加图像的数量。这在数据集的图像数量有限时尤其有效。除了旋转、平移,Data Augmentation还可以通过其他各种方法扩充图像,比如裁剪图像的 “crop处理”、将图像左右翻转的“flip 处理” 等(flip 处理只在不需要考虑图像对称性的情况下有效)。对于一般的图像,施加亮度等外观上的变化、放大缩小等尺度上 的变化也是有效的。不管怎样,通过Data Augmentation巧妙地增加训练图像, 就可以提高深度学习的识别精度。
8.1.3 加深层的动机
加深层的好处:
①可以减少网络的参数数量。说得详细一点,就是与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。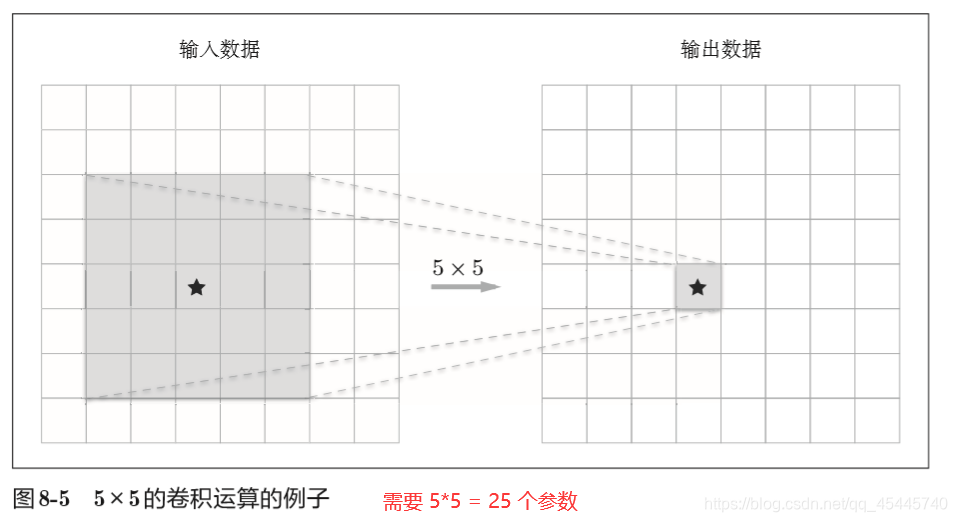
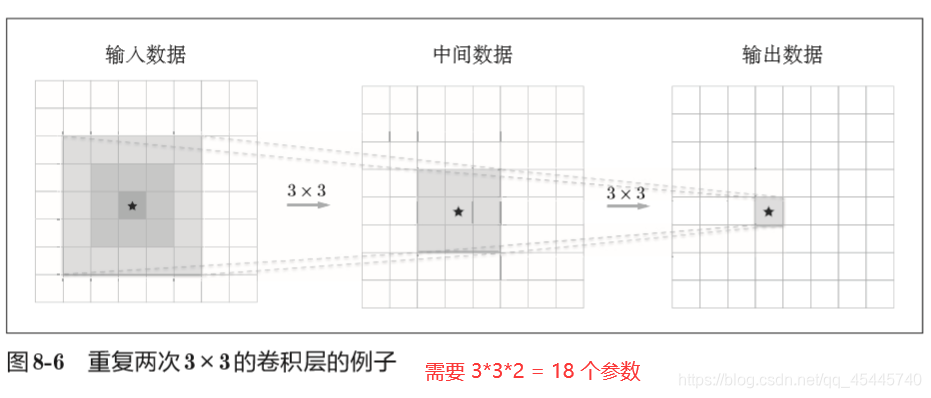
②使学习更加高效。与没有加深层的网络相比, 通过加深层,可以减少学习数据,从而高效地进行学习。为了直观地理解这 一点,参考书上的7.6节的内容。7.6节中介绍了CNN的卷积层会分 层次地提取信息。具体地说,在前面的卷积层中,神经元会对边缘等简单的形状有响应,随着层的加深,开始对纹理、物体部件等更加复杂的东西有响应。

一站式 AI 云服务平台
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)