
测评几个本地代码模型:零一万物、千问、deepseek、llama
测评几个本地代码模型:零一万物、千问、deepseek、llama
文章目录
🍃作者介绍:双非本科大四网络工程专业在读,阿里云专家博主,前三年专注于Java领域学习,擅长web应用开发,目前专注于人工智能领域相关知识,欢迎订阅系列专栏🌹
🦅个人主页:@逐梦苍穹(6000+粉丝;60万+访问量)
😊需要帮忙部署模型(如deepseek)可私信联系。
✈ 您的一键三连,是我创作的最大动力🌹
1、前言
1.1、环境
今天测评的是本地模型,有时候一些简单的需求,在选择符合硬件水平的前提下,肯定是更加方便的。
测试环境:
- 设备:Mac mini
Apple M4(10 + 10)16G+256G- 平台:ollama
- GUI界面:ChatWise
非常基础的一款电脑。最高能本地运行14B的模型,15B和16B就已经相对卡顿了,超过16B完全不可用的状态。
1.2、模型
今天使用的模型分别是:
- 零一万物:yi-coder:9b
- 千问:qwen2.5-coder:14b
- llama:
- codellama:7b
- codellama:13b
- 深度求索:
- deepseek-r1:1.5b
- deepseek-r1:14b
ollama模型: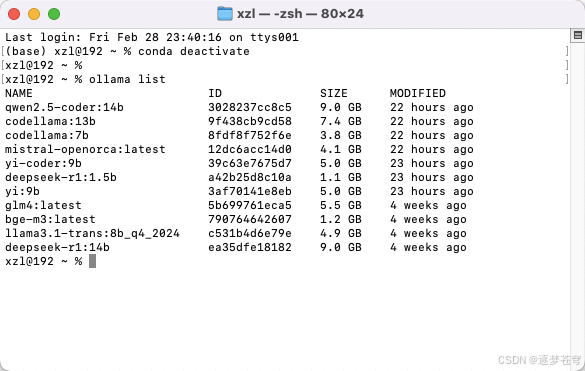
下面进行代码能力测评,主要从几个方面:
- 网页前端小游戏:设计一个人机对弈的五子棋网页版,使用html,css和js
- 代码解释:
- 解释这段代码:
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 4, # 增加数据加载进程数
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 16, # 批次大小增大
gradient_accumulation_steps = 4, # 增加梯度累积步数
warmup_steps = 5,
num_train_epochs = 5, # 设置更多训练轮次
learning_rate = 2e-5,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 10,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to="none",
),
)
看模型的表现情况如何。
先说结论:
- 网页前端小游戏:都不能用,deepseek-r1:1.5b综合表现还行,毕竟模型小速度快;deepseek-r1:14b的效果是最好的
- 代码解释:deepseek-r1:14b > qwen2.5-coder:14b > deepseek-r1:1.5b
所以综合表现,deepseek-r1:14b、qwen2.5-coder:14b、deepseek-r1:1.5b三个模型本地部署都能满足一定的需求。
- 需要更为精细的回答:
deepseek-r1:14b,推理模型的时间会长一些。 - 需要解释参数:
qwen2.5-coder:14b(qwen2.5-coder:14b速度会比deepseek-r1:14b要快,因为qwen没有“思考”过程) - 只需要“总揽全局”:
deepseek-r1:1.5b一定是最佳选择,速度非常快(测试有70tokens/s),能够快速了解代码中每一个大部分基本是实现什么功能。
2、网页前端小游戏
2.1、零一万物
网页前端小游戏:设计一个人机对弈的五子棋网页版,使用html,css和js
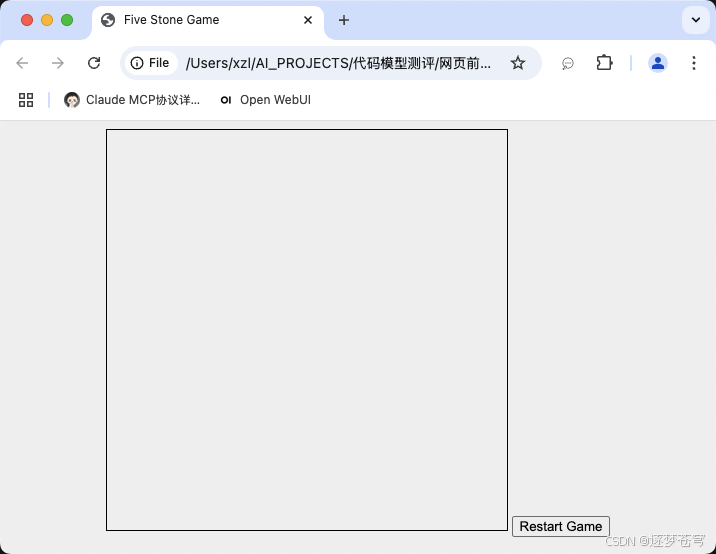
不行!

中规中矩,比较一般
2.2、千问

比零一好很多,但是黑白都需要自己下。
2.3、llama
codellama:7b
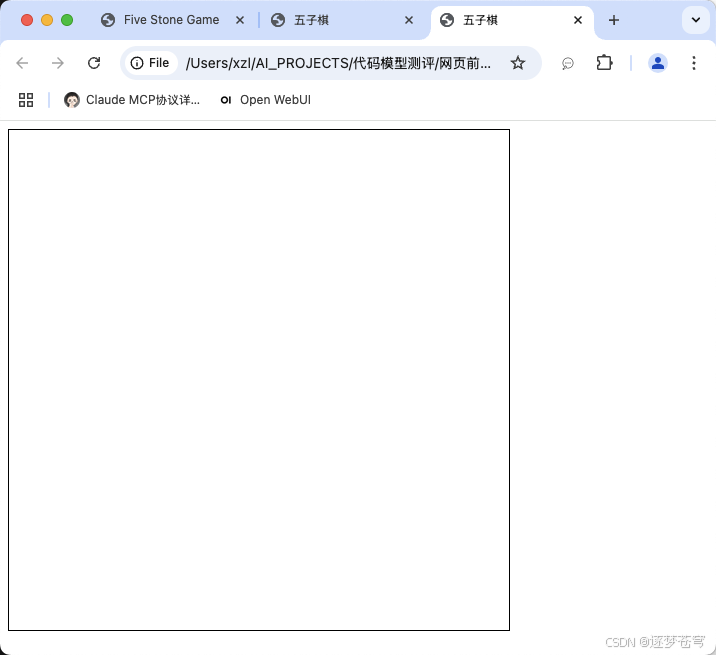
不行
codellama:13b
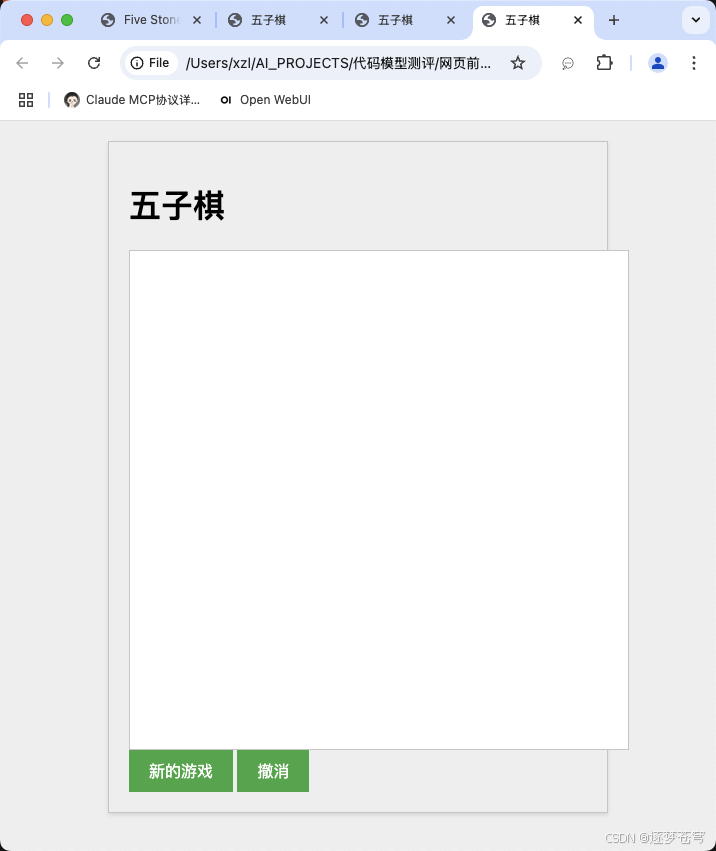
界面好了点,但是不能下。
2.4、深度求索
deepseek-r1:1.5b
代码生成数量是截至目前来说最多的,但是不能用。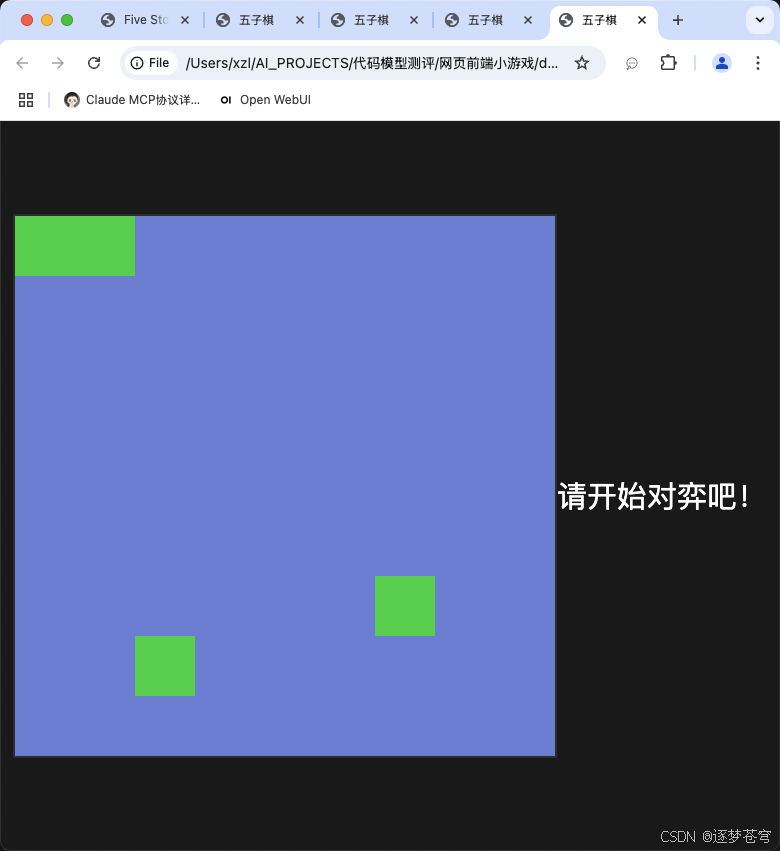
deepseek-r1:14b


这已经是目前最好的了,但是只能执黑。
3、代码解释
3.1、零一万物
中规中矩,比较一般
3.2、千问
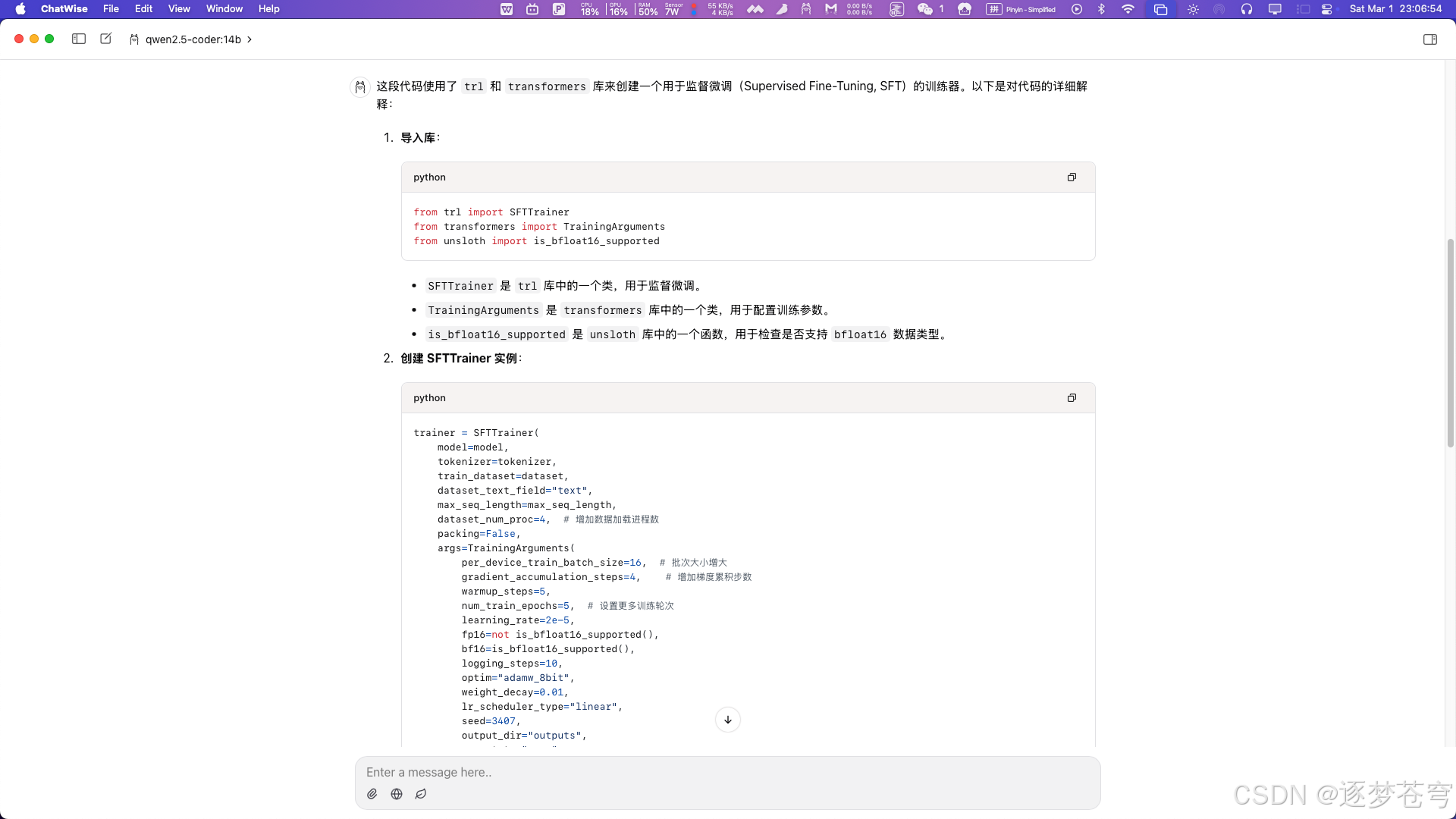
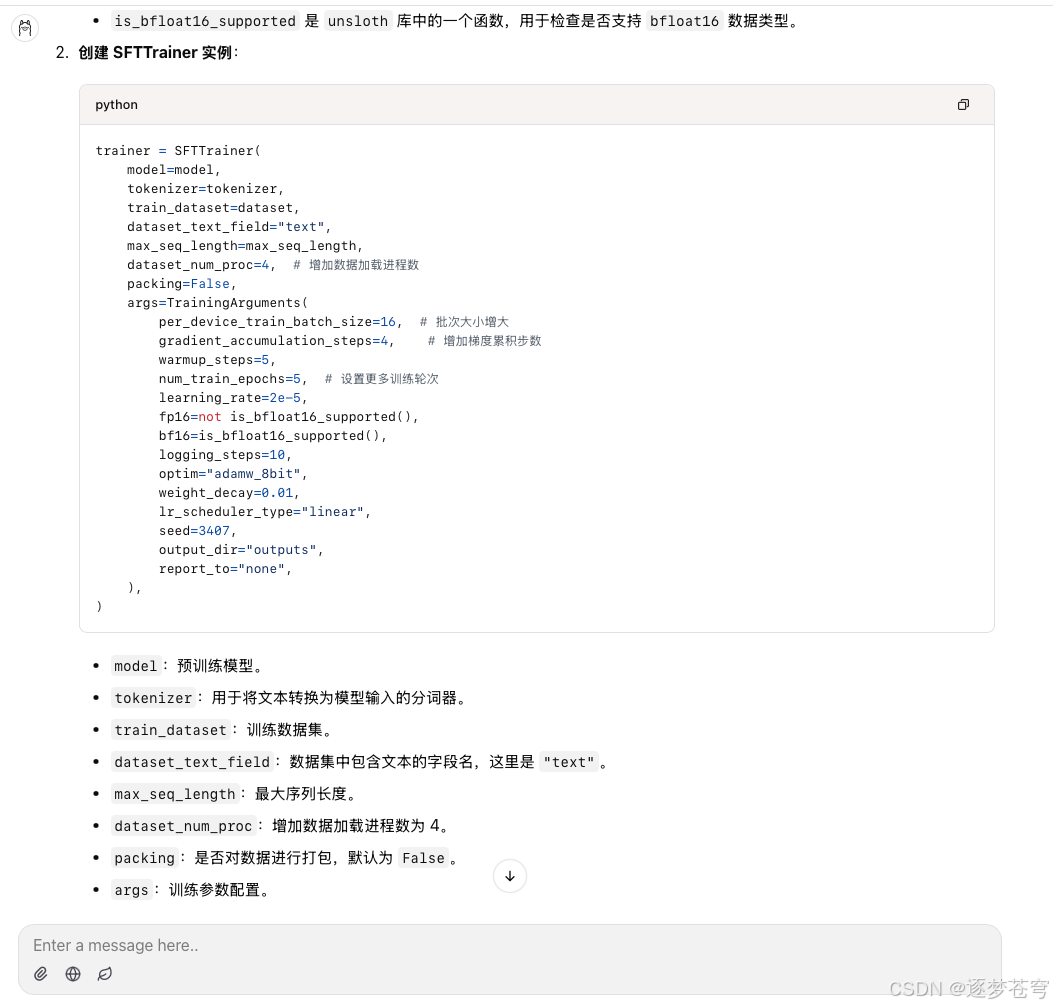
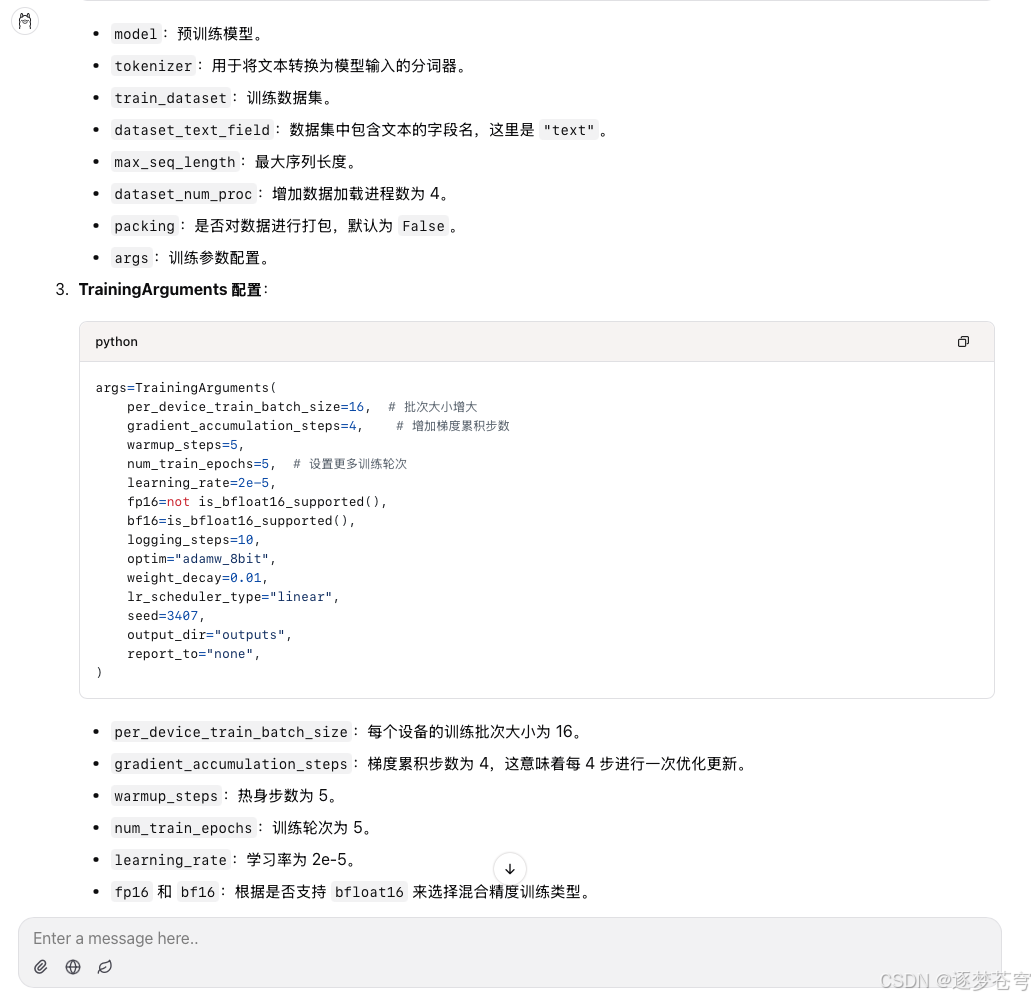

对参数给出了注释,总体来说还不错。
3.3、llama
codellama:7b

不如千问。
看看13B的codellama咋样。
codellama:13b

跟刚才的7B大差不差
3.4、深度求索
deepseek-r1:1.5b
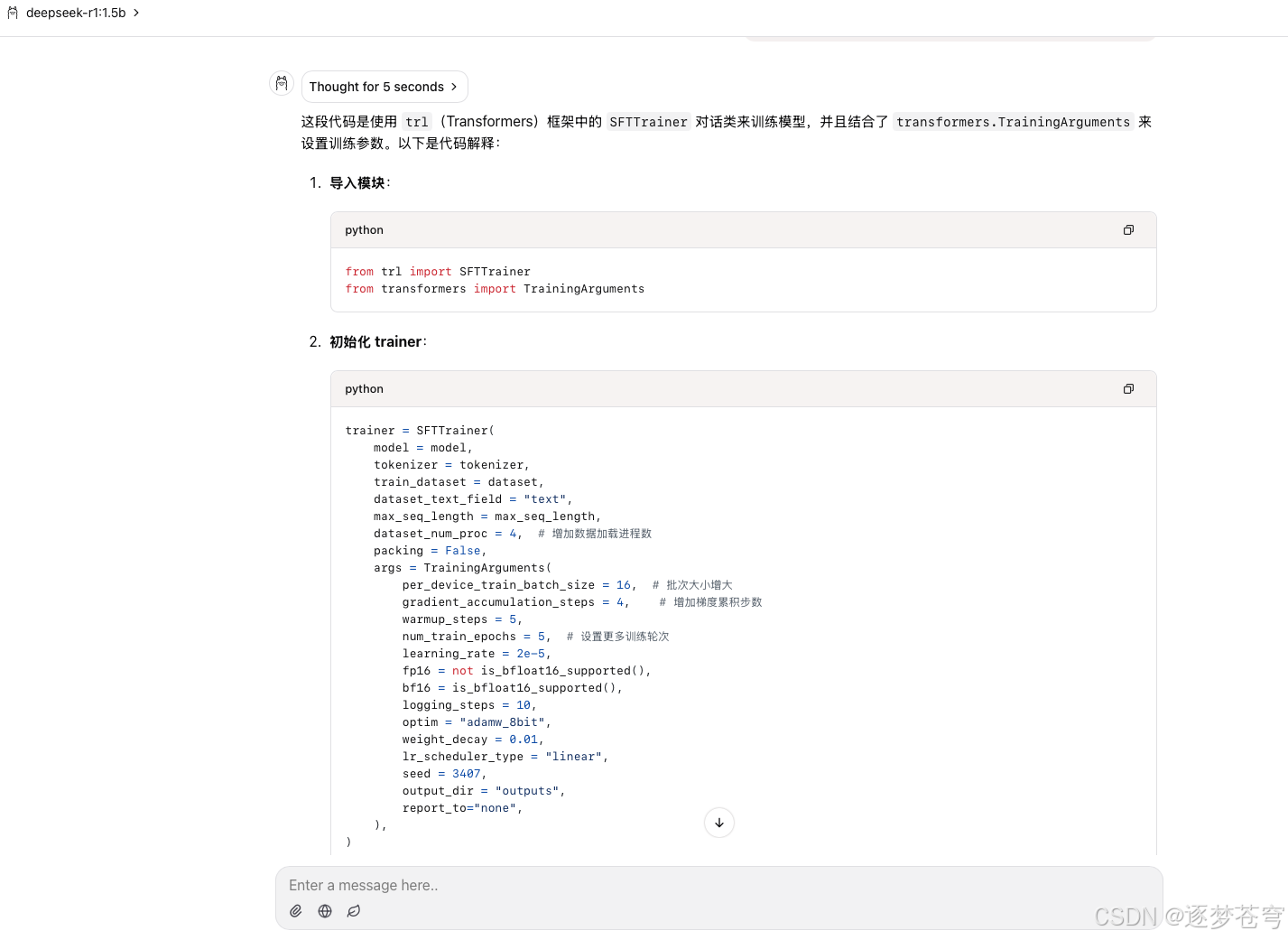


解释的比较简单,跟刚才的千问模型大差不差,虽然这个是蒸馏后的千问模型,但是这只有1.5B的参数,综合表现还是不错的。
deepseek-r1:14b

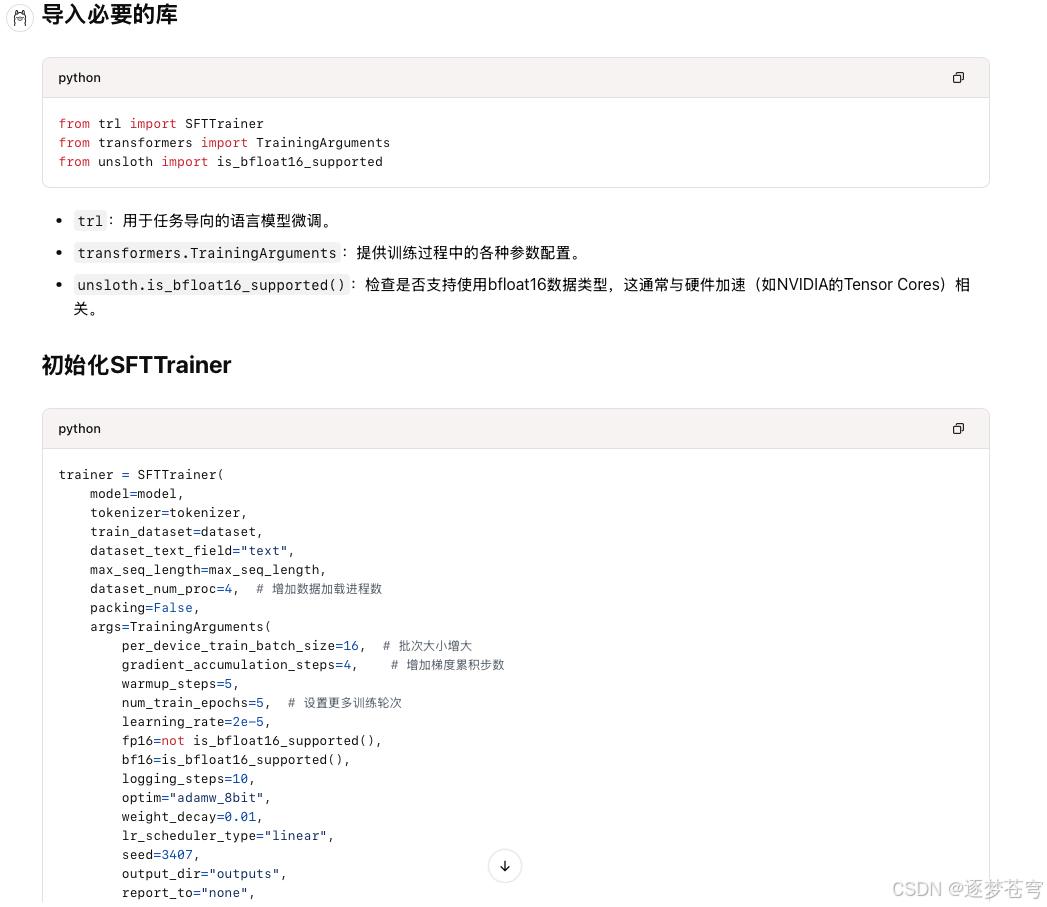


4、测评过程的代码
通过网盘分享的文件:代码模型测评.rar
链接: https://pan.baidu.com/s/13ztbOsfNZdBoeY-Px4it_Q?pwd=3s3d 提取码: 3s3d

一站式 AI 云服务平台
更多推荐



 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)