
大模型从基础到入门——大模型文件
本文以DeepSeek-R1-Distill-Qwen-7B大模型为例,详细解析了大模型文件的结构及其参数意义。主要文件包括config.json(模型架构配置)、generation_config.json(生成控制配置)、tokenizer_config.json(分词器配置)及model.safetensors(模型权重文件)等。文章对比了不同模型文件的差异,如DeepSeek与Qwen系列
随着DeepSeek大模型的出现,大模型发展浪潮又一次抵达高峰,现在我们可以去Hugging Face、魔塔社区等平台获取大模型源文件,甚至可以在显存8G的笔记本上运行、微调大模型。
本文将主要从DeepSeek大模型文件中各参数意义出发,逐步剖析有关大模型技术原理,方便后续工作学习(除了我自己截图外,引用的我尽量标注来源,有些忘记来源了请告诉我orz)。

一、大模型文件
这里以魔塔社区中DeepSeek-R1-Distill-Qwen-7B为例子,从每个文件的作用开始说明,我们可以看见,一个大模型的文件主要有以下几个文件:
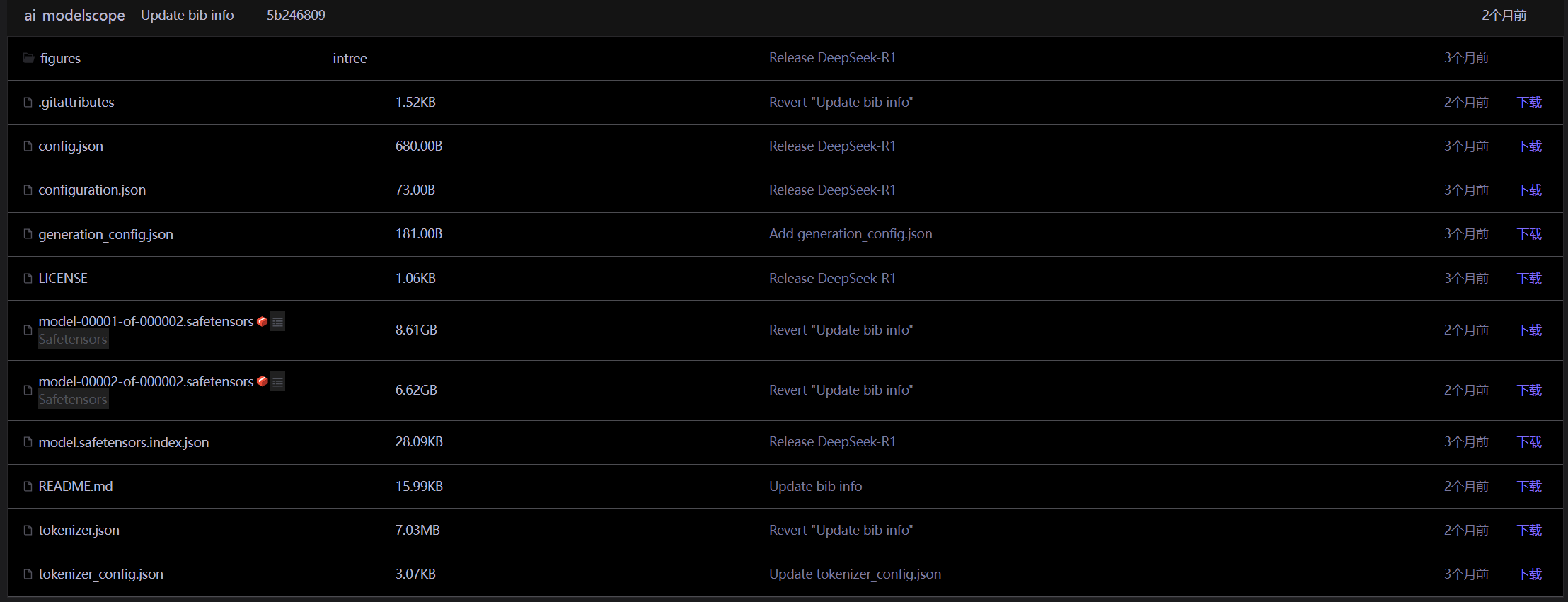
从上到下一个个看:
- .gitattributes:git仓库中文件处理规则,用于版本控制和工程管理(非重点);
- config.json:模型架构配置文件,定义模型超参数与结构设计;
- configuration.json:模型运行时配置文件;
- generation_config.json:生成控制配置文件;
- LICENSE:许可证文件(非重点);
- xxx.safetensors:模型权重文件;
- model.safetensors.index.json:模型权重文件索引文件,用于指导框架按需求从模型权重文件中加载权重到不同网络结构层次中;
- README.md:说明文件(非重点);
- tokenizer_config.json:分词器配置文件;
- tokenizer.json:分词器文件;
1.1文件整体对比
先不急着了解他们的具体作用,我们再多看几个大模型的文件做一下对比,最左边为第一个模型DeepSeek-R1-Distill-Qwen-7B,后两个分别为通义千问2.5-7B-Instruct和deepseek-llm-7b-chat模型做对比:
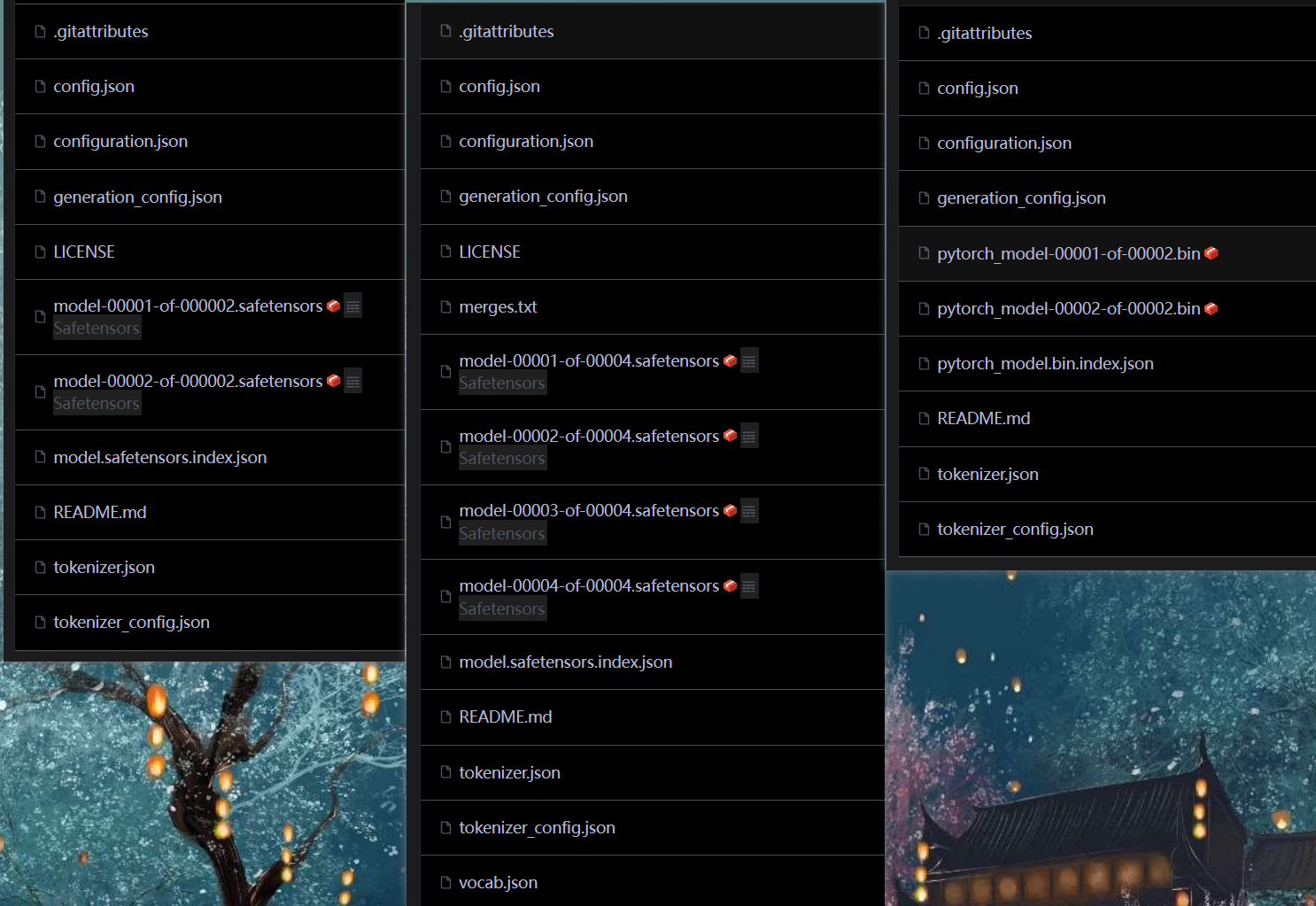
可以清晰看出区别,先看看同为deepseek系列的两个模型,他们区别不大,重点是模型权重文件从bin换到了safetensors文件,safetensors是一种替代传统bin格式的权重保存格式,它是专为安全、快速加载而设计的。
再看看deepseek系统与qwen系列模型的区别,主要是qwen系列模型多了两个文件:merges.txt,vocab.json,这两个文件是词汇表文件,vocab文件包含模型所用的词汇表,即词与编码的映射关系;merges.txt文件则是用于字节对编码(BPE, Byte Pair Encoding)分词算法的文件,BPE有关知识后续再详细说明。
简单说明就是,deepseek模型针对中文场景进行优化,直接复用BERT式单字分词,避免子词拆分带来的额外计算开销,从而省略BPE所需的两个额外文件,只依赖于单一分词器文件tokenizer;而qwen模型则需要考虑多语言支持,以子词拆分方式捕捉复合词语义,引入BPE技术,需要维护两个配置文件。
1.2文件具体对比
1.2.1 config.json
我们再来看看文件内部细节有哪些不同,从config文件开始,还是一样的顺序,以左边第一个为例子:
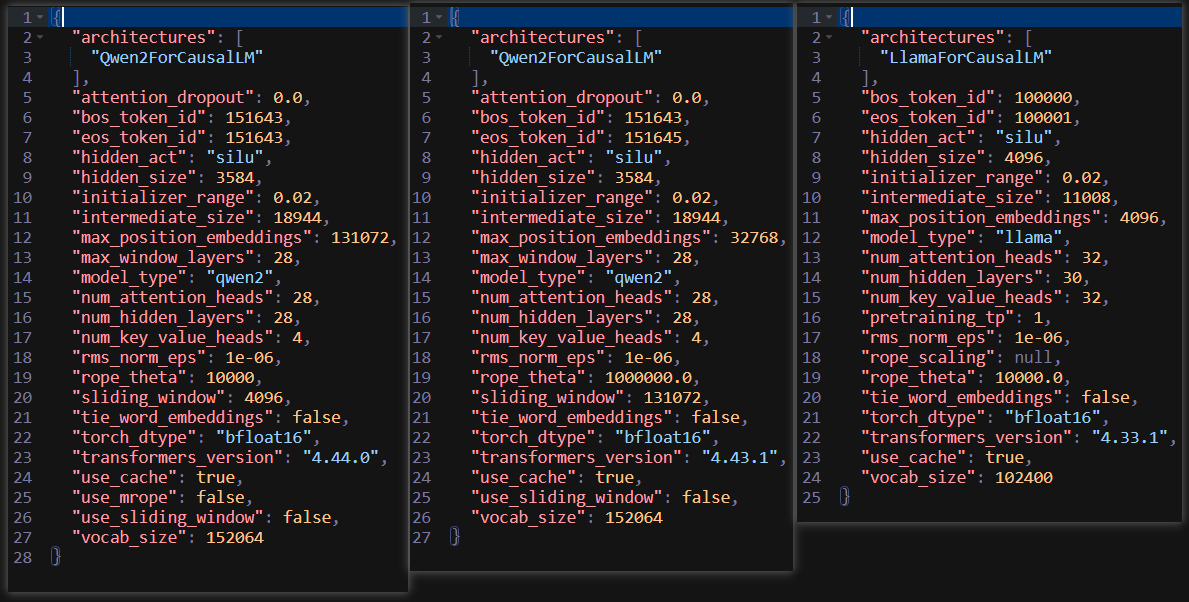
- architectures:指定模型架构为因果语言模型,这里分为qwen和llama两种架构;
- attention_dropout:注意力机制层随机丢弃参数;
- bos_token_id、eos_token_id:标识文本开始、结束的特殊标记;
- hidden_act:隐藏层的激活函数(目前最火的就是silu,SiLU(x) = x * sigmoid(x));
- hidden_size:隐藏层状态维度(每个注意力头的维度 = 3584 / 28(heads) = 128);
- initial_range:模型参数初始化截断正态分布标准差;
- intermediate_size:前馈神经网络\MLP层维度(通常为hidden_size的4倍左右,增强非线性拟合能力);
- max_position_embeddings:支持最大上下文长度;
- max_window_layers:局部注意力机制中应用窗口注意力的最大层数(Longformer思想);
- model_type:模型类型标识;
- num_attention_heads:多头注意力的头数(每个头处理子维度为3584 / 28 = 128);
- num_hidden_layers:Transformer层的总数;
- num_key_value_heads:分组查询注意力机制中KV头数(一个KV对应7个Q);
- rms_norm_eps:RMS归一化操作中,防止分母为0的常数;
- rope_theta:RoPE位置编码的基数;
- sliding_window:滑动窗口注意力机制中,滑动窗口的大小;
- tie_word_embeddings:是否绑定输入输出词嵌入权重(false时,输出层参数增加,152,064 × 3584 ≈ 520M额外参数);
- torch_dtype:模型权重存储的数据类型;
- transformers_version:transformers库版本;
- use_cache:是否开启kvcache;
- use_mrope:是否使用动态线性插值RoPE;
- use_sliding_window:是否使用滑动窗口注意力;
- vocab_size:分词器词表大小。
其中重点不同在于:qwen系列模型选择3584维度,也就是将注意力机制中32头数降低到28头,减少参数总量,增加计算效率;支持最大上下文长度也有区别;模型结构中层数也有差距。
1.2.2 generation_config.json
再来看看下一个重要的文件,以参数最多的qwen2.5为例吧:
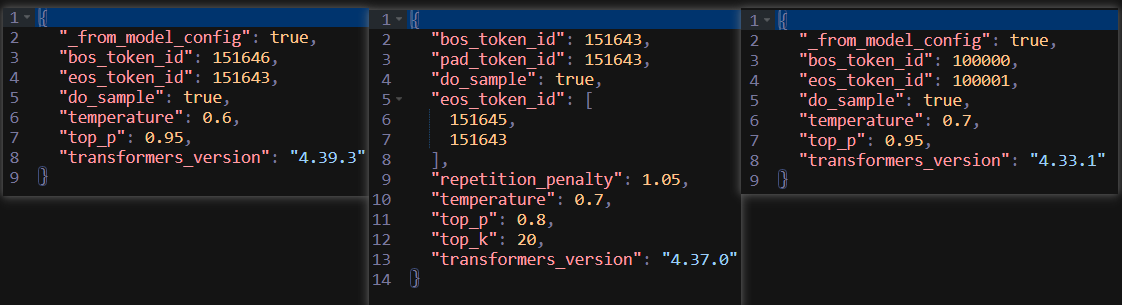
- _from_model_config:表示生成配置继承于config.json文件;
- bos_token_id、pad_token_id:设置为同一个特殊ID,简化处理逻辑,后者用于批量推理时统一输入尺寸;
- do_sample:启用概率采样,增加生成多样性(非贪婪);
- eos_token_id:结束符号ID,一个为正常结束,一个为异常终止;
- repetition_penality:重复惩罚,
;
- temperature:温度系数,越低,输出越固定;
- top_p:概率采样机制参数;
- top_k:数量采样机制参数。
这个文件涉及的参数都是生成时对输出进行操作的参数,其基本原理后续再详细说明。
1.2.3 tokenizer_config.json
再看看最后一个差距较大的配置文件,qwen2.5的文件太长了,这里我做了一下拼接:
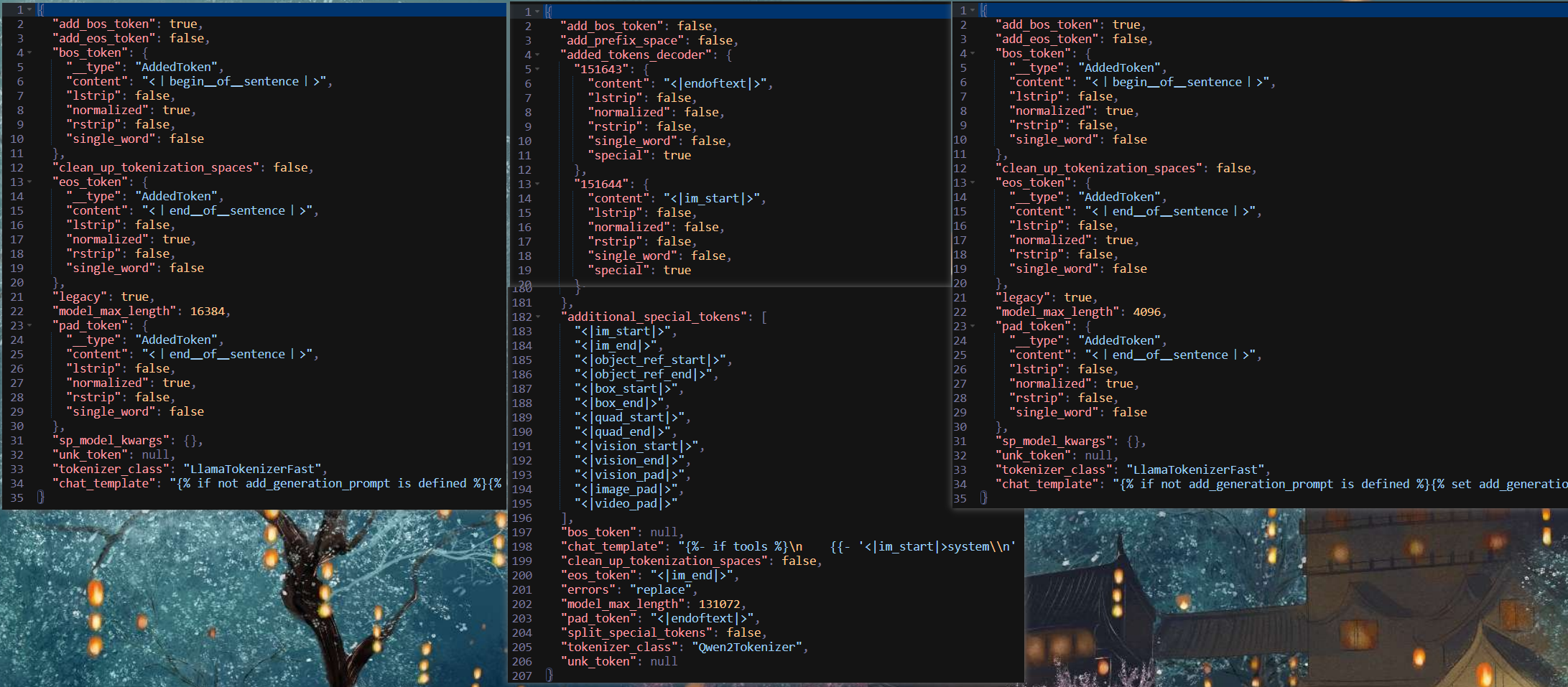
- add_bos_token:自动在序列开头添加BOS标记;
- add_eos_token:自动在序列结尾添加EOS标记;
- bos_token、eos_token、pad_token:配置开始、结束、填充字符的标记;
- unk_token:未知词标记,防止不在词表中词引发崩溃;
- clean_up_tokenization_spaces:是否清除多余空格
- chat_template:对话模板设置;
1.2.4 tokenizer.json
这个文件其实差距不大,这里以deekseek系列模型为例,说明一下文件的结构:
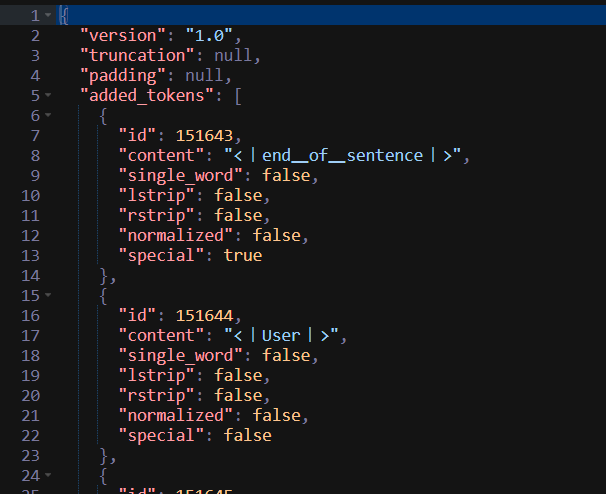
文件开头标明了配置文件格式版本version、长文本截断策略truncation、填充策略padding,后接自定义标记added_tokens,以id对应content,并记录是否为特殊功能标记;
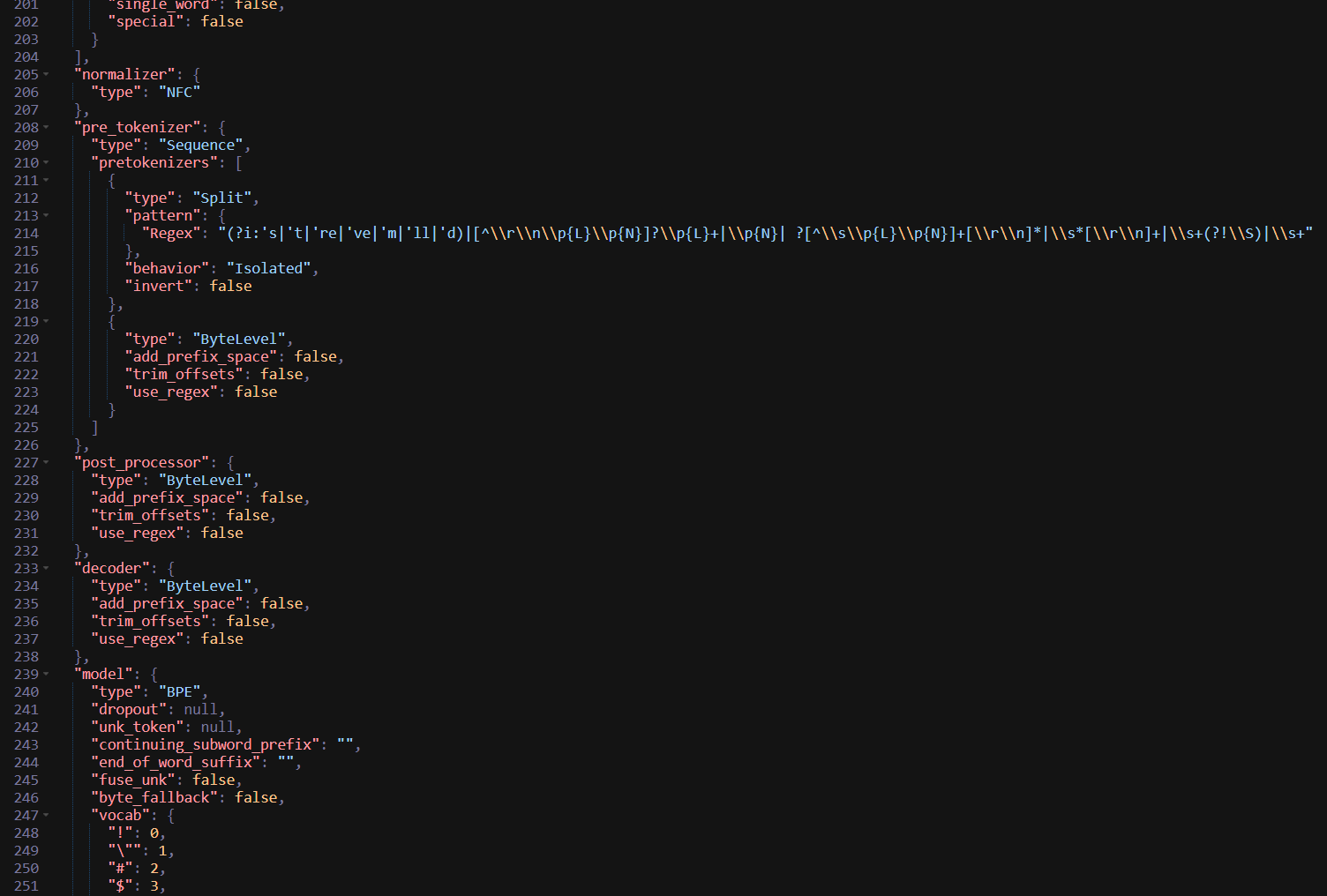
- 后接文本规范化normalization,表示将文本统一为Unicode单字符形式NFC;
- 定义预分词器pre_tokenizer,有两种:split和bytelevel,前者用正则表达式切分为独立单元,后者用于处理特殊字符的字节表示(比如\n转化为Ċ);
- 后处理器post_processor、解码器decoder用于处理生成后分词结果(Ċ转化为\n);
- 模型架构定义model,表示使用BPE算法,其中需要包含两个元素:vocab和merges,前者为基础词汇表,后者为子词合并规则。
二、大模型入门
(好像内容太多了,写在新贴里面吧还是orz)
参考:
大模型文件夹中的各种文件都是些啥?_大模型文件里面有什么-CSDN博客
大模型LLM的定位器Attention自注意力|兼看Qwen2参数构成 - 53AI-AI知识库|大模型知识库|大模型训练|智能体开发

一站式 AI 云服务平台
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)