
通过python连接Ollama服务,调用本地部署Deepseek模型的API接口,方法步骤详细教学,简单实用,一起来学习吧!!!
本篇文章我将教会大家如何使用python代码调用Deepseek的API接口,实现AI模型的自动化启动,并进行交互式对话。windows使用Ollama本地部署Deepseek详细教学检查Ollama服务是否运行确认防火墙允许本地11434端口通信验证模型名称是否正确调整temperature参数(0.3-0.7适合技术问答)增加num_predict获取更长回复在system_prompt中明确
前言
本篇文章我将教会大家如何使用python代码调用Deepseek的API接口,实现AI模型的自动化启动,并进行交互式对话。通过该方法大家可以搭建属于自己的AI问答网站或开发AI软件,当然在教学前,我们首先需要在本地部署Deepseek模型,操作非常简单,大家都能学会,这里可以参考下面这篇文章:
windows使用Ollama本地部署Deepseek详细教学
1、基础API调用方法及演示
1.1 环境准备
-
1、启动Ollama服务
在运行代码前,我们需要保证Ollma处于运行状态,可以通过任务栏图标或任务管理器查看Ollama是否正在运行,若Ollama服务未启动,打开CMD命令行窗口,随意输入一个Ollama命令即可,如下:ollama list # 查看已下载模型 -
2、安装requests模块
pip install requests
1.2 同步请求方法
该方法通过同步请求的方式获取模型响应信息,运行代码后程序会暂停,这是因为模型正在生成回答,根据所提问题难度,模型生成回答的时间有所不同,程序运行完毕后,才会显示回答信息。
# 调用模块
import requests
def deepseek_chat(prompt, model):
# deepseek的API接口链接
url = "http://localhost:11434/api/generate"
# 基本请求参数
payload = {
"model": model, # 调用的AI模型
"prompt": prompt, # 输入的对话文本或指令
"stream": False # 非流式响应
}
print('模型正在生成回复,请稍等...')
# 向Deepseek模型的API接口发起请求
response = requests.post(url, json=payload)
# 获取响应信息,得到模型回复的答案
answer = response.json()["response"]
return answer
# 1、向AI进行提问,写出需要询问的问题
prompt = "如何学习Python编程?"
# 2、需要调用的AI模型,根据本地下载的模型,写入模型名称即可
model = 'deepseek-r1:1.5b'
# 3、调用函数,与Deepseek建立响应
answer = deepseek_chat(prompt,model)
# 4、输出模型回复的答案
print("模型回复:\n", answer)
效果演示: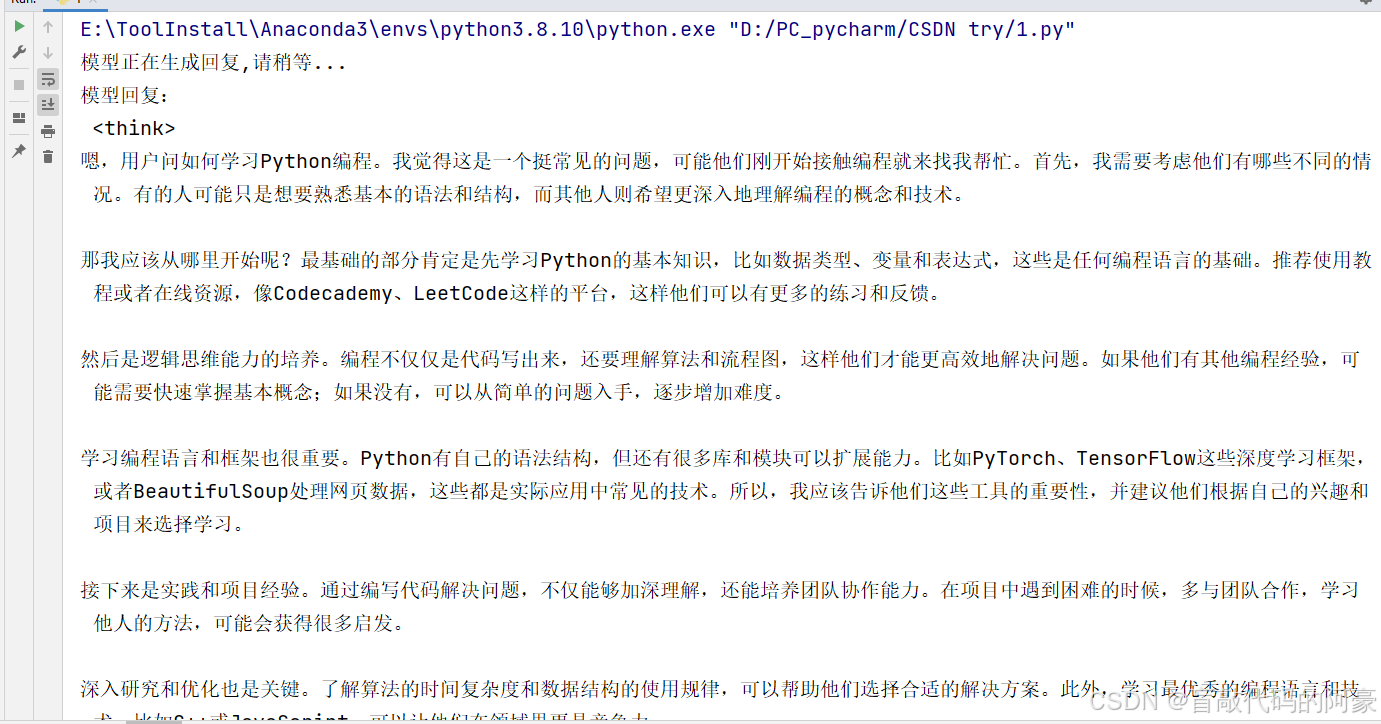
1.2 流式响应方法
该方法的好处就是在运行程序后,可以实时显示模型回复的信息,可以给用户更好的体验。
# 调用模块
import requests
import json
def deepseek_chat(prompt, model):
# # deepseek的API接口链接
url = "http://localhost:11434/api/generate"
# 基本请求参数
payload = {
"model": model, # 调用的AI模型
"prompt": prompt, # 输入的对话文本或指令
"stream": True # 启用流式响应
}
# 向Deepseek模型的API接口发起请求,并实时显示回复信息
with requests.post(url, json=payload, stream=True) as res:
for line in res.iter_lines():
if line:
chunk = json.loads(line.decode('utf-8'))
print(chunk.get("response",""),end="", flush=True)
# 1、向AI进行提问,写出需要询问的问题
prompt = "如何学习Python编程?"
# 2、需要调用的AI模型,根据本地下载的模型,写入模型名称即可
model = 'deepseek-r1:1.5b'
# 3、调用函数,与Deepseek建立响应
deepseek_chat(prompt,model)
效果演示: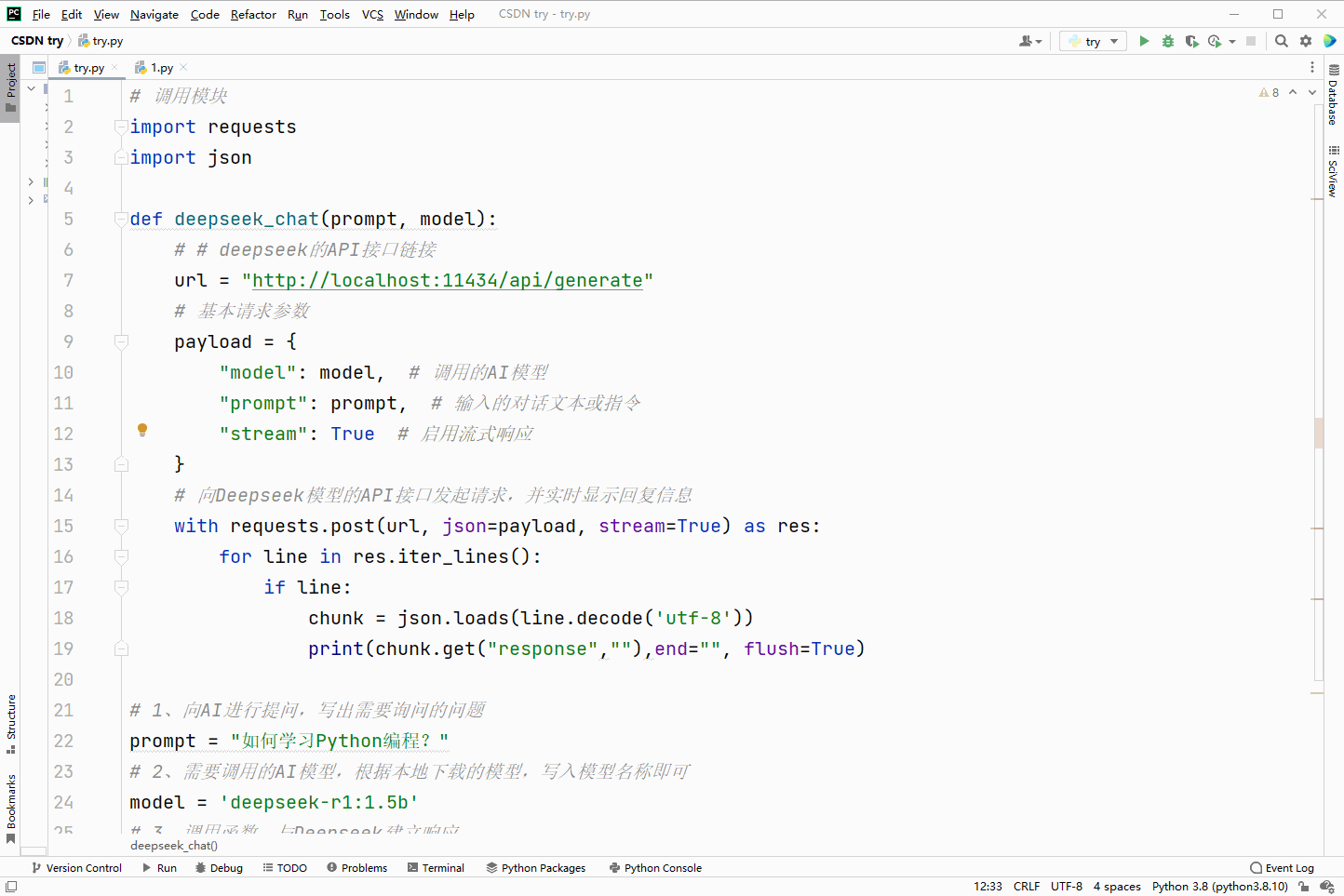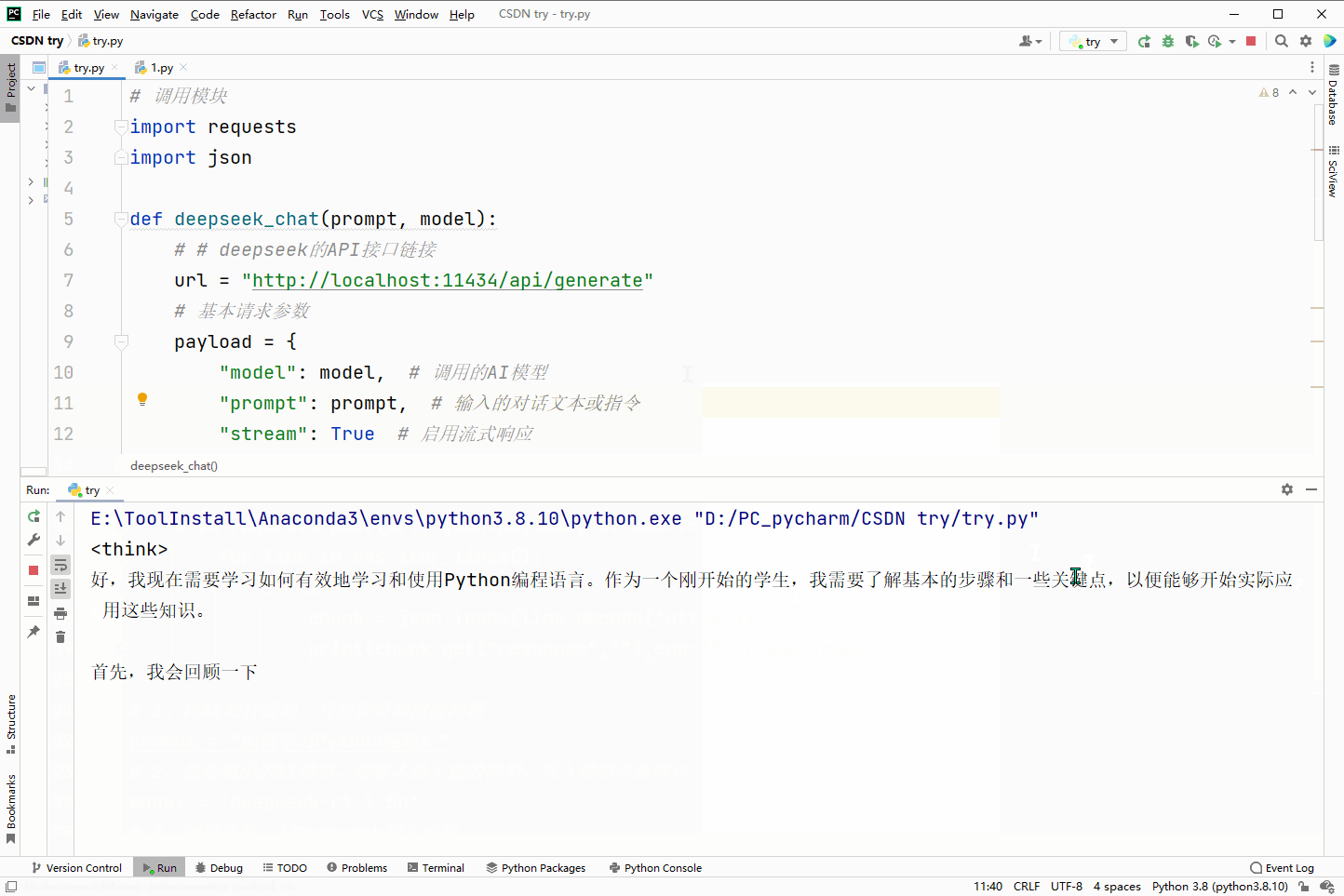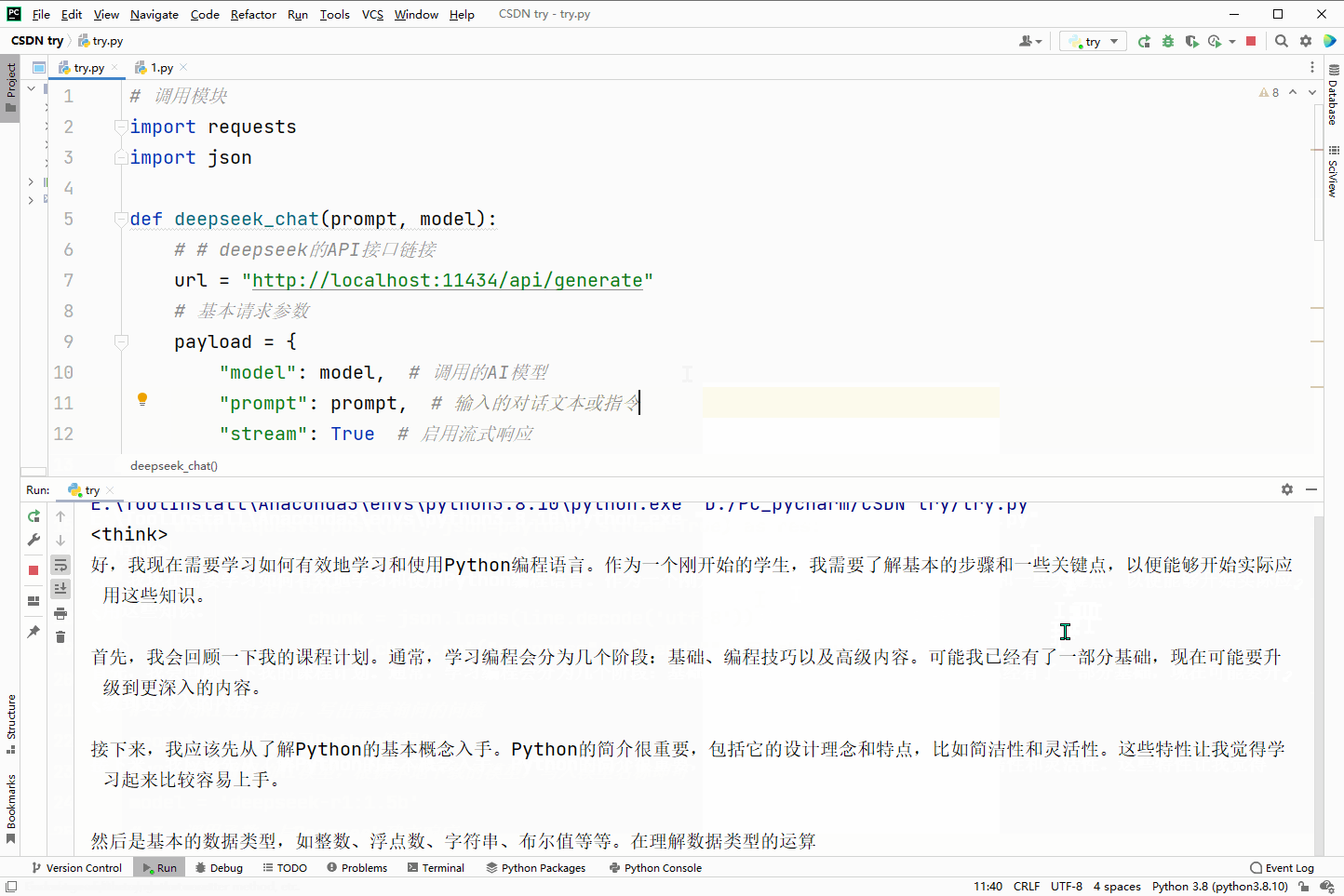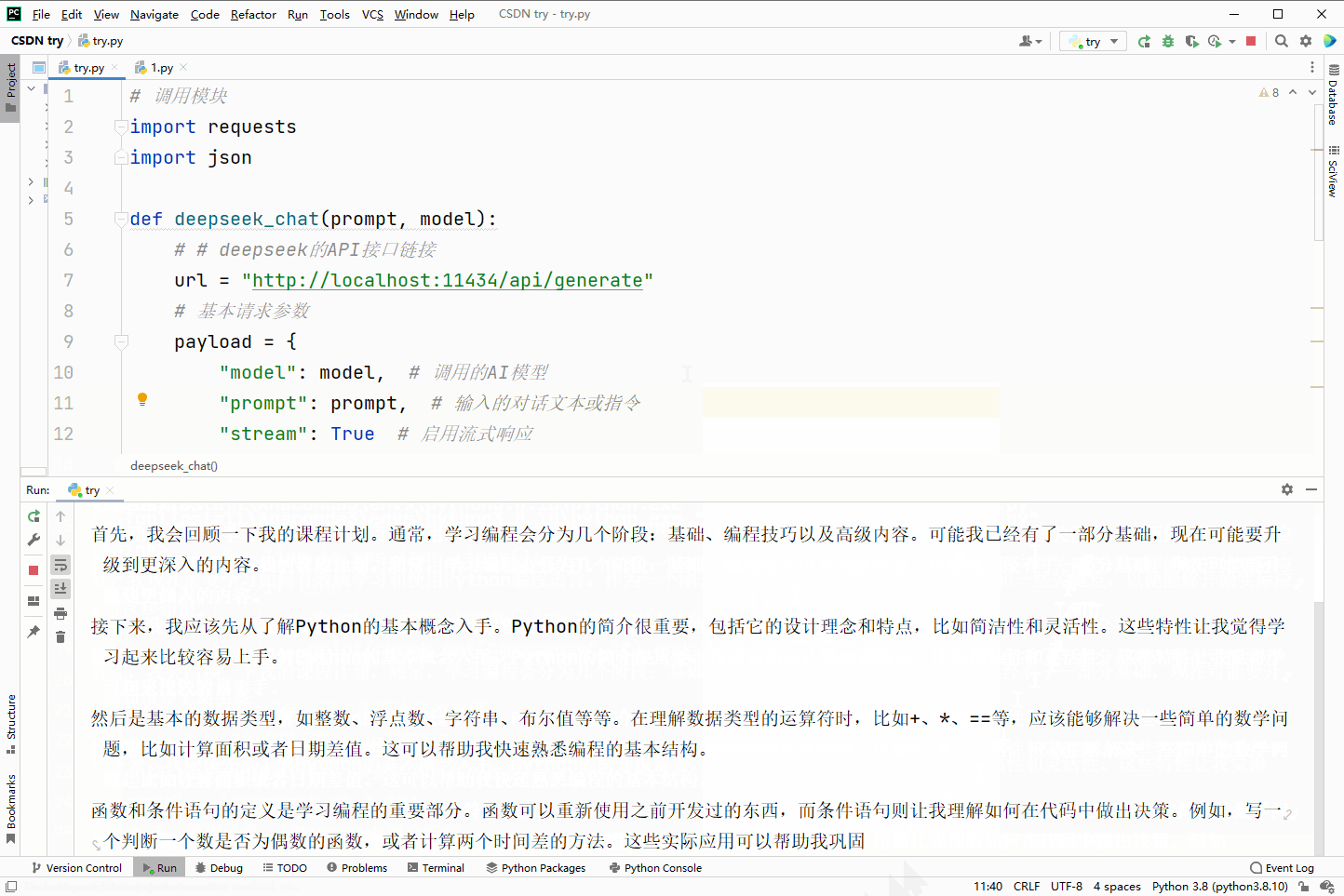
1.3 文件分析处理
本地部署好 DeepSeek 模型后,通过 Python API 读取本地文件内容并向模型提问,核心思路是:读取文件内容并将其作为提示词(prompt)的一部分发送给模型。
1、思路分析:
整个过程大致分为三步:
-
读取本地文件:使用 Python 读取你指定文件的内容。
-
构建提示词:将文件内容和你想要问的问题组合成一个完整的提示词。
-
调用 API 提问:通过 Python 请求库将构建好的提示词发送给本地运行的 DeepSeek 模型 API,并获取返回结果。
2、代码示例:
# -*- coding: utf-8 -*-
"""
Author: @CSDN盲敲代码的阿豪
Time: 2025/9/5 1:42
Project: python调用deepseek API接口
BLog homepage: https://blog.csdn.net/m0_59470317?spm=1011.2124.3001.5343
"""
import requests
import json
# 1. 读取本地文件内容
def read_file_content(file_path):
"""
根据文件类型读取内容,支持 txt、pdf(需安装PyPDF2)、docx(需安装python-docx)等。
默认按文本读取。
"""
try:
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
return content
except UnicodeDecodeError:
# 尝试其他编码,如gbk
with open(file_path, 'r', encoding='gbk') as file:
content = file.read()
return content
except Exception as e:
print(f"读取文件时出错: {e}")
return None
# 指定你要读取的文件路径
file_path = "文档.txt" # 请替换为你的实际文件路径
file_content = read_file_content(file_path) # 文档内容
if file_content is None:
exit("文件读取失败,请检查文件路径和格式。")
# 2. 构建你的问题
your_question = "分析文档中的内容,并进行总结" # 请替换为你的具体问题
# 将文件内容和你的问题组合成最终的提示词
combined_prompt = f"{your_question}\n\n文档内容:\n{file_content}"
# 3. 配置Ollama API参数(确保Ollama服务正在运行)
api_url = "http://127.0.0.1:11434/api/generate" # Ollama的generate接口,deepseek模型
model_name = "deepseek-r1:.5b" # 请替换为你实际部署的模型名称
# 基本请求参数
payload = {
"model": model_name, # 调用的AI模型
"prompt": combined_prompt, # 输入的对话文本或指令
"stream": True # 启用流式响应
}
# 向Deepseek模型的API接口发起请求,并实时显示回复信息
with requests.post(api_url, json=payload, stream=True) as res:
for line in res.iter_lines():
if line:
chunk = json.loads(line.decode('utf-8'))
print(chunk.get("response",""),end="", flush=True)
3、核心步骤说明
-
读取文件:
read_file_content函数会尝试用 UTF-8 编码读取文本文件。如果遇到编码错误,它会尝试使用 GBK。对于 PDF、Word 等特殊格式,你需要使用额外的库(如 PyPDF2 读取 PDF,python-docx 读取 Word)来提取文本。 -
组合提示词:这是关键一步。将你的问题(例如“请总结这篇文档”)和读取到的文件内容拼接成一个字符串 (combined_prompt),然后将其放入 API 请求的 “prompt” 字段中。
-
API 请求:代码向本地 Ollama 服务的 API 端点(如 http://localhost:11434/api/generate)发送一个 POST 请求。请求体中以 JSON 格式包含了模型名称和组合好的提示词。
4、处理不同文件类型
上面的例子主要针对文本文件。对于其他常见格式,你需要先安装相应的库来提取文本:
| 文件类型 | 推荐库 | 安装命令 | 简要代码示例 |
|---|---|---|---|
TXT |
内置 | - | with open(file_path, ‘r’, encoding=‘utf-8’) as f: content = f.read() |
PDF |
PyPDF2 |
pip install PyPDF2 | from PyPDF2 import PdfReader reader = PdfReader(file_path); content = “\n”.join([page.extract_text() for page in reader.pages]) |
DOCX |
python-docx |
pip install python-docx | from docx import Document; doc = Document(file_path); content = “\n”.join([paragraph.text for paragraph in doc.paragraphs]) |
MD |
内置 - 同 TXT | ||
CSV |
pandas |
pip install pandas | import pandas as pd; df = pd.read_csv(file_path); content = df.to_string() |
注意:从PDF、Word等格式中提取的文本有时可能格式混乱或包含无关字符,这可能会影响模型的理解效果。
5、重要提示和技巧
-
确保模型服务在线:在运行脚本前,请确保你的 DeepSeek 模型已通过 Ollama 在本地正常运行。通常使用命令 ollama run deepseek-r1:5b (以你使用的模型名为准)。
-
处理长文件:模型能处理的文本长度(上下文窗口)有限制。如果文件很长,你需要:
-
只提取相关部分发送给模型。
-
或将长文件分块(Chunking),分别提问后再综合答案。
-
-
优化提示词(Prompt):清晰具体的指令能获得更好的回答。例如:
-
“请基于以下文档内容,回答这个问题:…[你的问题]…”
-
“总结以下文档的三个要点:…”
-
“分析以下文本的情感倾向:…”
-
1.4 核心参数说明及效果演示
在前面两个方法中我们使用了三个基本请求参数:
model、prompt、stream,这三个参数是必须携带的。除此之外,我们还可以携带一些其它参数,通过调整携带的参数信息,可以使模型的回复富有多样性。
1、参数展示及说明:
| 参数 | 类型 | 说明 |
|---|---|---|
model |
str | Ollama 中加载的模型名称(必须与部署时使用的名称一致) |
prompt |
str | 输入的提示文本/问题 |
stream |
bool | 是否启用流式传输(默认为False,为True 时逐块返回结果,适合实时显示) |
temperature |
float | 控制生成随机性:(0.1-2.0) |
num_predict |
int | 限制生成内容的最大长度(根据模型上下文窗口调整) |
top_p |
float | 核采样参数:(0-1)仅保留累计概率超过此值的候选词(影响输出多样性) |
system |
str | (可选) 系统级提示,用于定义模型行为(如角色设定) |
2、核心参数组合效果
| 参数组合 | 适用场景 | 示例值 |
|---|---|---|
| 低temperature + 低num_predict | 事实性回答 | temp=0.3, num_predict=512 |
| 高temperature + 高num_predict | 创意写作 | temp=1.2, num_predict=2048 |
| 中temperature + 流式传输 | 实时对话 | temp=0.7, stream=True |
3、案例演示
案例1:添加高级参数进行对话:
# 调用模块
import requests
import json
def deepseek_chat(prompt, model):
# # deepseek的API接口链接
url = "http://localhost:11434/api/generate"
# 基本请求参数
payload = {
"model": model, # 调用的AI模型
"prompt": prompt, # 输入的对话文本或指令
"stream": True , # 启用流式响应
# 高级参数(可选)
"options": {
"temperature": 1.2, # 生成随机性
"num_predict": 100, # 最大生成长度
"top_p": 0.1 # 核采样概率阈值
},
}
# 向Deepseek模型的API接口发起请求,并实时显示回复信息
with requests.post(url, json=payload, stream=True) as res:
for line in res.iter_lines():
if line:
chunk = json.loads(line.decode('utf-8'))
print(chunk.get("response",""),end="", flush=True)
# 1、向AI进行提问,写出需要询问的问题
prompt = "如何学习Python编程?"
# 2、需要调用的AI模型,根据本地下载的模型,写入模型名称即可
model = 'deepseek-r1:1.5b'
# 3、调用函数,与Deepseek建立响应
deepseek_chat(prompt,model)
效果展示:(可以看到模型回复的长度限制为了100字)
案例2:添加角色设定,进行对话
# 调用函数
import requests
import json
def deepseek_chat(prompt, system_role):
# deepseek的API请求链接,注意这里链接相比前面的案例有所不同,后缀为chat
url = "http://localhost:11434/api/chat"
# 请求参数
data = {
"model": "deepseek-r1:1.5b", # 调用的AI模型
# 存放角色设定信息的参数
"messages": [
{"role": "system", "content": system_role}, # system:表示系统角色,content为角色设定信息
{"role": "user", "content": prompt} # user:表示用户自己,content为用户输入的问题
],
"stream": False, # 非流式响应
}
print('模型正在生成回复,请稍等...')
# 发送请求,获取响应信息
response = requests.post(url,headers={"Content-Type": "application/json"},data=json.dumps(data))
# 得到响应结果
result = response.json()
# 返回模型回复的答案
return result['message']['content']
if __name__ == "__main__":
# 1、定义角色设定(示例:程序员角色)
system_prompt = """你是一个资深程序员,回答需要满足以下要求:
1. 使用中文回复
2. 保持专业但易懂的语气
3. 包含具体实现步骤
4. 必要时给出代码示例"""
# 2、用户输入问题
user_input = "请详细解释如何在Python中实现异步网络请求"
# 3、调用函数,返回答案
answer = deepseek_chat(prompt=user_input,system_role=system_prompt,)
print("模型回复:\n",answer)
效果演示: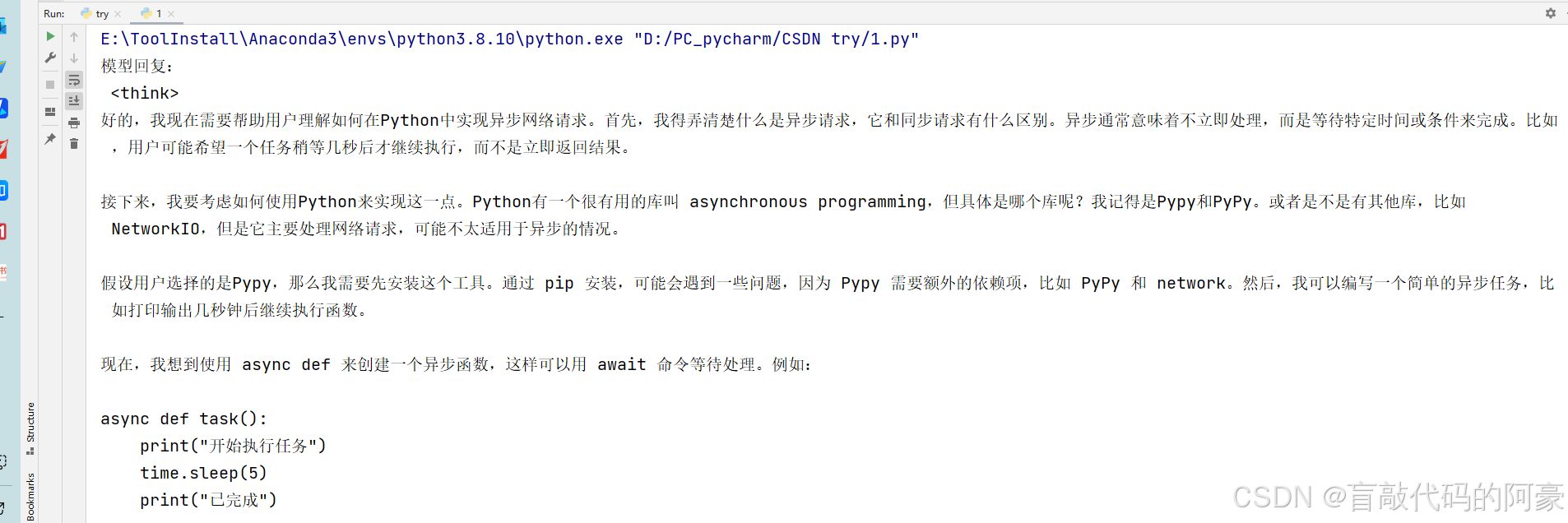
2、常见问题处理及总结
-
连接失败:
-
检查Ollama服务是否运行
-
确认防火墙允许本地11434端口通信
-
验证模型名称是否正确
-
-
响应质量优化:
-
调整temperature参数(0.3-0.7适合技术问答)
-
增加num_predict获取更长回复
-
在system_prompt中明确格式要求
-
-
模型未找到
-
现象:Error: model ‘deepseek’ not found
-
解决:确认模型已下载,执行 ollama pull deepseek模型名称
-
-
中文输出不稳定
- 在system_prompt中明确要求:“请始终使用中文回答,避免使用其他语言”
总结:
通过以上方法,您可以灵活调用本地DeepSeek模型,建议从简单查询开始逐步尝试高级功能。实际使用时请注意硬件资源限制,复杂任务建议设置num_predict参数控制输出长度。

一站式 AI 云服务平台
更多推荐



 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)