
最常用的Python库--机器学习和数据科学必备神器
机器学习和数据科学领域有无数多优秀的工具和资源可供使用,令人眼花缭乱,有时会让我们很难弄清楚该学习什么技能,该使用哪种工具。本文对机器学习和数据科学领域最常用的Python开源库做一个罗列和极简介绍(当然仅限于我所知道、用过且喜欢的),仅作抛砖引玉之用。另外,此列表会不断增长。
目录
0. 前言
机器学习和数据科学领域有无数多优秀的工具和资源可供使用,令人眼花缭乱,有时会让我们很难弄清楚该学习什么技能,该使用哪种工具。本文对机器学习和数据科学领域最常用的Python开源库做一个罗列和极简介绍(当然仅限于我所知道、用过且喜欢的),仅作抛砖引玉之用。另外,此列表会不断增长。
1. 基础库
1.1 Numpy:多维数组

NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 的前身 Numeric 最早是由 Jim Hugunin 与其它协作者共同开发,2005 年,Travis Oliphant 在 Numeric 中结合了另一个同性质的程序库 Numarray 的特色,并加入了其它扩展而开发了 NumPy。NumPy 为开放源代码并且由许多协作者共同维护开发。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
其它很多库都以NumPy作为基础,比如说Tensorflow利用NumPy作为张量处理后端。
基于Numpy,你可以定义任意数据类型并很方便地与任意数据库打交道。Numpy也可以用作任意通用数据的多维容器。
1.2 Pandas:数据分析

Pandas 是 Python 语言的一个扩展程序库,用于数据分析。Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。
Pandas 以Numpy为基础,提供了一个强大的分析结构化数据的工具集,广泛应用于学术、金融、统计学等各个数据分析领域。
特征:
- 丰富的语法和功能,让用户可以自由地处理丢失的数据
- 能够帮助创建自己的函数并在一系列数据中运行它
- 包含高级数据结构和操作工具
- 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据
- 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征
1.3 Matplotlib:绘图
Matplotlib 是 Python 中最受欢迎的数据可视化软件包之一,支持跨平台运行,它是 Python 常用的 2D 绘图库,同时它也提供了一部分 3D 绘图接口。Matplotlib 通常与 NumPy、Pandas 一起使用,是数据分析中不可或缺的重要工具之一,可视化效果绝佳,它还提供了一个面向对象的 API,可用于将这些绘图嵌入到应用程序中。
Matplotlib is a data visualization library that is used for 2D plotting to produce publication-quality image plots and figures in a variety of formats. The library helps to generate histograms, plots, error charts, scatter plots, bar charts with just a few lines of code.
It provides a MATLAB-like interface and is exceptionally user-friendly. It works by using standard GUI toolkits like GTK+, wxPython, Tkinter, or Qt to provide an object-oriented API that helps programmers to embed graphs and plots into their applications.
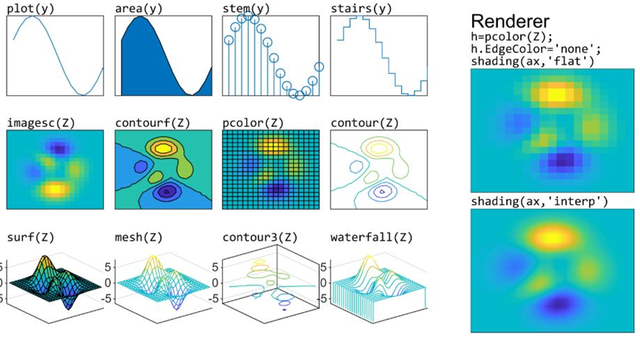
1.4 SciPy:科学计算

其实Scipy与其说是一个库,还不如说是一个库的集合(a stack of libraries),包括Numpy, Matplotlib, Pandas, SymPy, 以及其它形形色色的科学计算工具包。
Scipy以Numpy作为其底层数据结构,包括线性代数、数值积分、插值、特殊函数、滤波、最优化、统计、FFT、信号与图像处理、常微分方程求解等科学计算工具,广泛用于数学、科学、工程学等领域,很多有一些高阶抽象和物理模型也有Scipy用武之地。
5. Scikit-learn:机器学习
Scikit-learn项目始于scikits.learn,这是David Cournapeau的Google Summer of Code项目。它的名称源于它是“ SciKit”(SciPy工具包)的概念,它是SciPy的独立开发和分布式第三方扩展。作为专门面向机器学习的Python开源框架,Scikit-learn可以在一定范围内为开发者提供非常好的帮助。它内部实现了各种各样成熟的算法,容易安装和使用,样例丰富,而且教程和文档也非常详细。另一方面,Scikit-learn也有缺点。例如它不支持深度学习和强化学习,这在今天已经是应用非常广泛的技术。此外,它也不支持图模型和序列预测,不支持Python之外的语言,不支持PyPy,也不支持GPU加速。当然,如果不考虑多层神经网络的相关应用,Scikit-learn的性能表现是非常不错的。究其原因,一方面是因为其内部算法的实现十分高效,另一方面或许可以归功于Cython编译器;通过Cython在Scikit-learn框架内部生成C语言代码的运行方式,Scikit-learn消除了大部分的性能瓶颈。
Scikit-learn的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。此外,还有模型融合和辅助工具板块。
- Preprocessing 预处理:转换输入数据,规范化、编码化。包括preprocessing,feature_extraction,transformer(转换器)等模块
- Dimensionality reduction 降维:用于Visualization(可视化),Increased efficiency(提高效率)。典型算法有主成分分析(PCA)、非负矩阵分解(NMF),feature_selection(特征选择)等
- Classification 分类:二元分类问题、多分类问题、Image recognition 图像识别等。典型算法有逻辑回归、SVM,最近邻,随机森林,Naïve Bayes,神经网络等
- Regression 回归:典型算法有线性回归、SVR,ridge regression,Lasso,最小角回归(LARS)等
- Clustering 聚类: 典型算法有k-Means,spectral clustering(谱聚类),mean-shift(均值漂移)等
- Model selection 模型选择:通过参数调整提高精度,包括pipeline(流水线),grid_search(网格搜索),cross_validation( 交叉验证),metrics(度量),learning_curve(学习曲线)等模块
- 模型融合:ensemble(集成学习)、
- 辅助工具:exceptions(异常和警告)、dataset(自带数据集)、utils、sklearn.base
6. Statsmodels:统计模型

Statsmodels是用于拟合多种统计模型,执行统计测试以及数据探索和可视化的Python库。statsmodels包含更多的“经典”频率学派统计方法,而贝叶斯方法和机器学习模型可在其他库中找到。
包含在statsmodels中的一些模型:
- 线性模型,广义线性模型和鲁棒线性模型
- 线性混合效应模型
- 方差分析(ANOVA)方法
- 时间序列过程和状态空间模型
- 广义的矩量法
- Linear Regression
- Correlation
- Ordinary Least Squares (OLS) for the economist in you!
- Survival analysis
- Generalized linear models and Bayesian model
- Uni-variate & bi-variate analysis, Hypothesis Testing (basically, whatever R can do!)
7. 可视化
7.1 Plotly
Plotly绝对是构建可视化的必备工具,它非常强大,易于使用,并且能够与可视化交互。
与Plotly一起使用的还有Dash,它是能使用Plotly可视化构建动态仪表板的工具。Dash是基于web的Python接口,它解决了这类分析web应用程序中对JavaScript的需求,并让你能在线和离线状态下进行绘图。
Plotly 的 Python 软件包是一个开源的代码库,它基于 plot.js,而后者基于 d3.js。我们实际使用的则是一个对 plotly 进行封装的库,名叫 cufflinks,它能让你更方便地使用 plotly 和 Pandas 数据表协同工作。
7.2 Seaborn
Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。应该把Seaborn视为matplotlib的补充,而不是替代物。同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
8. 机器学习
8.1 XGBoost
XGBoost is an optimized distributed gradient boosting library that implements highly efficient parallel tree boosting algorithms such as Gradient boosting decision trees (GBDT). They typically perform really well and can be often seen on Kaggle where they dominate other algorithms. Definitely give this a shot if you need an efficient and powerful model.
8.2 imbalanced-learn
Another great library is imbalanced-learn. This is a super helpful library when you have to deal with imbalanced data, e.g., if you have a lot of samples from the negative class but not from the positive class. You should address this problem in your preprocessing steps and imbalanced-learn offers a lot of different algorithms to do this, for example different under- and oversampling methods.
8.3 LightGBM
LightGBM is a gradient boosting framework mainly popular because it lets developers build algorithms using decision trees. A few features of this library are, quick training of models and higher efficiency, low memory usage, and capability to handle large-scale data & support of parallel, distributed, and GPU learning.
8.4 gym

Gym库(https://gym.openai.com)是OpenAI推出的强化学习实验环境库,最广泛使用的强化学习实验环境。它用Python语言实现了离散之间智能体-环境接口中的环境部分。其中包含上百种 常见的实验“环境”,其中每个环境代表着一类强化学习问题,用户通过设计和训练自己的智能体来解决这些强化学习问题。
8.5 Gradio
Gradio是MIT的开源项目使用gradio,只需在原有的代码中增加几行,就能自动化生成交互式web页面,并支持多种输入输出格式,比如图像分类中的图>>标签,超分辨率中的图>>图等。同时还支持生成能外部网络访问的链接,能够迅速让你的朋友,同事体验你的算法。
总结起来,它的优势有:
- 自动生成页面且可交互
- 支持自定义多种输入输出
- 允许进一步的模型验证。具体来说,可以用交互方式测试模型中的不同输入
- 易于进行演示
- 易于实现和分发,支持生成可外部访问的链接进行分享,任何人都可以通过公共链接访问web应用程序。
9. Deep Learning:深度学习
9.1 TensorFlow and Keras

TensorFlow 是一个开源的、基于 Python 的机器学习框架,它由 Google 开发,并在图形分类、音频处理、推荐系统和自然语言处理等场景下有着丰富的应用,是目前最热门的机器学习尤其是深度学习框架。除了 Python,TensorFlow 也提供了 C/C++、Java、Go、R 等其它编程语言的接口。
Keras是一个高层的神经网络构建API,已经与 TensorFlow 整合。
TensorFlow提供Python语言下的四个不同版本:CPU版本(tensorflow)、包含GPU加速的版本(tensorflow-gpu),以及它们的每日编译版本(tf-nightly、tf-nightly-gpu)。
9.2 PyTorch

PyTorch由Facebook人工智能研究院(FAIR)基于Torch 推出的一个针对深度学习, 并且使用 GPU 和 CPU 来优化的 tensor library (张量库)。目前与Tensorflow并列两个最为广泛使用的深度学习框架。
10. Computer Vision:计算机视觉
10.1 OpenCV
For Computer Vision the number 1 most important library is OpenCV. It offers powerful algorithms for real time image and video processing. Some techniques could be used for preprocessing or labelling the data and then combine it with TensorFlow or PyTorch, but it also has algorithms for full pipelines, e.g., for object detection, object segmentation, and face recognition algorithms .
10.2 Pillow
Pillow is Python Imaging Library. This also offers image processing algorithms and is a little bit more light weight. You can use it to load and convert images, and also for some image displaying and drawing tasks.
11. NLP:自然语言处理
11.1 HuggingFace
The HuggingFace Transformers library, which offers many pretrained State-of-the-art Natural Language Processing models and algorithms that can be combined directly with both PyTorch and TensorFlow. It’s one of the most popular NLP frameworks in Python right now.
11.2 NLTK
NLTK, the Natural Language Toolkit, is another essential library when working with language data. It offers algorithms for text classification, tokenization, stemming, tagging, and many more text processing techniques.
11.3 spaCy
spaCy also contains powerful NLP algorithms and is designed to build production ready systems real fast. They provide a great free course on their website that you can check out if you want to get started with it.
12. Miscellaneous:其它
12.1 Scrapy
Scrapy 是用 Python 编写的最流行的、快速的、开源的网络爬虫框架之一。它通常用于借助基于 XPath 的选择器从网页中提取数据。
应用:
- Scrapy 有助于构建可以从网络检索结构化数据的爬虫程序(蜘蛛机器人)
- Scrappy 还用于从 API 收集数据,并在其界面设计中遵循“不要重复自己”的原则,帮助用户编写可用于构建和扩展大型爬虫的通用代码
12.2 BeautifulSoup
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.BeautifulSoup会帮你节省数小时甚至数天的工作时间。BeautifulSoup以网络爬取和数据抓取而闻名。
用户可以在没有适当的 CSV 或 API 的情况下收集某些网站上可用的数据,BeautifulSoup 可以帮助他们抓取这些数据并将其排列成所需的格式。

一站式 AI 云服务平台
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)