
Mindful-RAG:大模型 + 知识图谱增强问答框架,更重视对问题意图和约束的理解,不仅是浅层的关键词匹配,解决 RAG 八大问题
整体解法(Mindful-RAG)旨在利用 LLM 的内置(参数化)知识与外部知识图谱(非参数化)相结合,增强在复杂问答任务中的准确度和可解释性。核心思路是:通过“意图识别 + 上下文对齐 + 约束处理 + 验证反馈”的一系列步骤,减少 LLM 产生的推理错误和不必要的“幻觉”。与传统的 KG-RAG 方法相比,更强调在检索过程中的“意图理解”与“上下文对齐”,而不仅仅依赖语义相似度来检索知识图谱
Mindful-RAG:大模型 + 知识图谱增强问答框架,更重视对问题意图和约束的理解,不仅是浅层的关键词匹配,解决 RAG 八大问题
- 论文大纲
- 理解
- RAG 八大问题
- 解法拆解
- 数据分析
- 提问
- 1. 为什么 Mindful-RAG 要将意图识别与上下文对齐作为其核心设计,而不是单纯依赖现有的语义相似度匹配?
- 2. Mindful-RAG 提出的 "意图驱动" 的检索和对齐方式,是否会增加计算复杂度,从而使其在处理大规模图谱时变得不可扩展?
- 3. Mindful-RAG 依赖于 LLM 的内在参数知识,而 LLM 本身是否可能在面对特定领域的低资源数据时存在知识缺口?
- 4. 在子解法 5 中提到基于意图的关系排序,若查询中的关系不止一个或不明确,如何避免“歧义”问题导致的错误?
- 5. Mindful-RAG 在处理多跳推理时能否保证其结果的准确性?如果一个查询涉及到长链的多跳推理,如何评估其推理路径是否正确?
- 6. 在子解法 3 中提到的上下文提取方法,是否能够有效处理包含隐性条件的复杂查询?
- 7. Mindful-RAG 引入的“反馈验证”机制是否会带来较高的延迟,特别是在实时系统中?
- 8. 在子解法 6 的“约束对齐”步骤中,如果知识图谱缺乏某些特定的时间或地理信息,如何处理这种缺失数据的情况?
- 9. Mindful-RAG 是否可以适应不断变化的外部知识图谱,尤其是在图谱频繁更新的情况下?
- 10. 如果用户查询的知识图谱没有相关信息,Mindful-RAG 会如何应对?是否会回退到纯粹的生成模型?
论文:Mindful-RAG: A Study of Points of Failure in Retrieval Augmented Generation
Mindful-RAG:
- “用心”就是“mindful”的一种形象化表达
- “检索增强式生成”对应 RAG
论文大纲
├── 1 引言【背景与研究动机】
│ ├── 1.1 LLM 的优势与局限【知识密集型问答的挑战】
│ │ ├── 优势【生成流畅文本】
│ │ └── 局限【易产生幻觉、难以应对专业领域问题】
│ └── 1.2 RAG 的出现【结合外部知识】
│ ├── 将知识库或知识图(KG)与 LLM 结合【强化事实性】
│ └── 存在问题【在复杂或特定领域场景下仍会失败】
├── 2 KG-based RAG 失败分析【识别并归纳错误类型】
│ ├── 2.1 八大关键失败点【分类基础】
│ │ ├── 【推理错误 Related】
│ │ │ ├── 1) 问题上下文误解【未准确理解问题意图】
│ │ │ ├── 2) 关系映射错误【选择了不匹配问题需求的 KG 关系】
│ │ │ ├── 3) 歧义处理失败【无法正确区分多重含义或要素】
│ │ │ ├── 4) 特殊性/精确性错误【无法处理聚合或时间等精确约束】
│ │ │ └── 5) 约束识别失败【忽视问题中暗含的限制条件】
│ │ └── 【结构限制 Related】
│ │ ├── 6) 编码问题【复合值类型等复杂结构节点误读】
│ │ ├── 7) 不恰当的评估指标【过度依赖 Exact Match 导致遗漏部分正确答案】
│ │ └── 8) 有限查询处理【模型需要额外信息时无法交互式请求】
│ └── 2.2 主要发现【推理能力不足与结构问题并存】
│ └── 关注点【深层次意图识别与上下文对齐尤为重要】
├── 3 Mindful-RAG【针对性改进框架】
│ ├── 3.1 核心思路【结合 LLM 内在记忆与外部 KG】
│ ├── 3.2 步骤概述【更好地匹配意图并对齐上下文】
│ │ ├── Step 1: 识别关键信息【实体 + 重要词】
│ │ ├── Step 2: 明确意图【让 LLM 提炼问题目标】
│ │ ├── Step 3: 提取上下文【聚焦题意背景】
│ │ ├── Step 4: 候选关系抽取【从子图中筛出可能的 KG 关系】
│ │ ├── Step 5: 基于意图的过滤与排序【选出与问题最匹配的关系】
│ │ ├── Step 6: 约束对齐【结合时间、地点等额外条件聚合答案】
│ │ └── Step 7: 意图校验反馈【验证生成答案是否吻合意图,若否则回溯修正】
│ └── 3.3 与现有方法对比【强调对“意图”与“约束”的关注度更高】
├── 4 实验与结果【证明方法有效性】
│ ├── 4.1 数据集【WebQSP 与 MetaQA】
│ │ ├── WebQSP【Freebase KG,多跳问答】
│ │ └── MetaQA【电影领域 3-hop 问答】
│ ├── 4.2 结果对比【Hits@1 指标显著提升】
│ │ ├── Mindful-RAG 在 WebQSP 上可达 84%【高于基线 StructGPT 等】
│ │ └── 在 MetaQA 上可达 82%【凸显减少推理类错误】
│ └── 4.3 影响分析【主要源于“意图识别”和“上下文对齐”的改进】
├── 5 相关工作【拓展与对比】
│ ├── 5.1 其他 RAG 增强方法【如自我检验、自适应检索等】
│ ├── 5.2 不同领域知识图构造【医疗、法律等领域】
│ └── 5.3 未来趋势【大规模多模态、与向量检索结合】
└── 6 讨论与结论【总结与展望】
├── 6.1 主要贡献【明晰 KG-RAG 系统失效点 + 提出 Mindful-RAG】
├── 6.2 局限与改进【结构限制可通过反馈或部分答案机制改善】
└── 6.3 展望【结合向量搜索 + 子图检索、交互式 RAG、人类校验等新方向】
理解
RAG 让 LLM 可以从外部知识库(如知识图谱)中检索到事实或背景信息,从而增加回答的准确性。
然而,目前常规的 RAG 方法中仍存在以下问题:
- 对用户问题的意图(intent)把握不够精准,导致检索到的知识与问题真正所需的信息不一致。
- 在多跳推理、多约束条件或需要上下文限定的场景下,LLM 时常选错关系或忽略关键信息,产生错误。
- 知识图谱的结构和信息没有被模型充分利用(结构缺陷或处理方法失当)。
- 对复杂问题的约束(如时间、地点、聚合需求等)没有很好地执行。
传统 RAG 的局限:单纯根据语义相似度做检索,或者对知识图谱的查询过程缺乏准确的多跳关系推理,经常会选错关系、理解错问题意图。
-
多约束、多跳特征:现实问题往往包含时间、地点、聚合、歧义消解等多重信息,如果只做简单的语义检索(semantic match)就容易遗漏关键上下文或选错路径。
-
对错误回答的关注:因为传统 RAG 容易在检索环节或回答环节遗漏意图或上下文,所以需要更“有意识”的流程来显式地处理“意图→检索→对齐→回答→再校验”。
“Mindful-RAG” 作为一种改进思路,旨在强化对问题意图和上下文的理解,并“有意识地(mindful)”将检索到的知识与问题对齐,从而减轻或避免上述失败点。
- 本质:一种改进型的检索增强式生成框架,突出“先理解意图,再做检索,并在回答时进行多轮校验”的特性。
- 核心思想:利用大语言模型自身的语义理解能力(参数化记忆)来识别用户问题的意图和关键约束,然后将问题与外部知识图谱精准对齐,最终生成回答。
正例
- 问题: “Who is Niall Ferguson’s wife?”(奈尔·弗格森的妻子是谁?)
- Mindful-RAG 流程:
- 识别到关键实体
Niall Ferguson,并分析到关键词wife代表的是“当前配偶”。 - LLM 对问题意图进行分析:要找的是“现任妻子”,而不是前妻或其他关系。
- 在知识图谱中找与
Niall Ferguson相关的关系,如people.person.spouse_s。 - 结合约束“当前妻子”,进行排序过滤,最终得到 “Ayaan Hirsi Ali”。
- 最终回答与意图一致:Niall Ferguson 现任妻子为 Ayaan Hirsi Ali。
- 识别到关键实体
反例(常规 RAG 或结构化查询但无意图过滤)
- 同一问题:“Who is Niall Ferguson’s wife?”
- 传统做法:仅根据
Niall Ferguson的 spouse 关系找到第一条婚姻信息,出现Sue Douglas。- 这是他曾经的妻子,却不是当前配偶。
- 因为没有考虑到问题实际上要的可能是“现任”妻子,也没有对检索到的多条 spouse 关系进行时间或状态过滤,导致答案错误。
把 Mindful-RAG 的工作机制类比成一个“专业私人助理”为用户解决问题的过程。
- Intent(意图)识别就像你先跟这个助理说明:“我要找什么?我要的目标信息是什么?我的偏好是什么?”
- 助理会根据你的偏好和指令,从一个大文件柜(知识图谱)里翻找最相关的文件和资料。
- 助理并不会只机械地把所有含“关键词”的文件丢给你,而是会根据你的真实意图,先排除与“目标”不匹配或过时的文档,或者那些仅有表面相似度但跟你不太相关的内容。
- 最后,助理会用自己的理解能力核对一下资料和你的需求,看有没有遗漏或冲突,再告诉你一个更准确的答案。
传统 RAG 更像是:你说了几个关键词,助理就单纯地把能匹配关键词的资料全部扔给你,然后简单拼接成答案,可能导致信息不合意图或被不当过滤。
RAG 八大问题
A. 推理失败 (Reasoning Failures)
- 问题上下文误解
- 问题:LLMs无法准确理解医疗问询的具体诊断背景
- 示例案例:
- 问"糖尿病的治疗方案是什么?",模型只回答了口服降糖药,未考虑是1型还是2型糖尿病
- 询问"高血压用什么药?",未考虑患者年龄、并发症等关键上下文因素
- 关系映射错误
- 问题:LLMs选择了不恰当的医疗关系来回答问题
- 示例案例:
- 询问"头痛的原因"时,模型仅链接到"症状-疾病"关系,忽略了"生活方式-症状"的关联
- 查询某药物配伍禁忌时,错误地选择了"适应症"而非"药物相互作用"关系
- 问题或数据歧义
- 问题:LLMs无法处理医学术语的多重含义
- 示例案例:
- 无法区分"冠心病"是指急性还是慢性状态
- 混淆"心衰"是指急性心力衰竭还是慢性心力衰竭
- 特异性或精确度错误
- 问题:LLMs在处理需要精确剂量或综合治疗方案时出错
- 示例案例:
- 查询"阿司匹林用量",未区分预防性用药和治疗性用药的不同剂量
- 问"高血压标准",只给出单一数值,未考虑不同年龄段的差异化标准
- 约束识别错误
- 问题:LLMs无法正确识别医疗禁忌和限制条件
- 示例案例:
- 开具处方时未考虑患者的过敏史
- 推荐运动方案时未考虑患者的心肺功能状况
B. 结构限制 (Structural Limitation)
- 编码问题
- 问题:处理复杂的医疗检验数据关系时出错
- 示例案例:
- 解读血常规报告时,无法正确关联各项指标间的关系(如贫血分类)
- 处理心电图数据时,未能正确解读多导联间的关系
- 不当评估
- 问题:医疗答案格式与标准不匹配
- 示例案例:
- 开具处方时,药品名称正确但规格、用法用量格式不规范
- 血压读数表达不符合标准格式(收缩压/舒张压)
- 有限的查询处理
- 问题:需要额外医疗信息但无法获得反馈
- 示例案例:
- 问"胸痛是什么原因?",模型需要但无法获得更多症状描述
- 询问用药建议时,缺乏患者具体情况的反馈
解法拆解
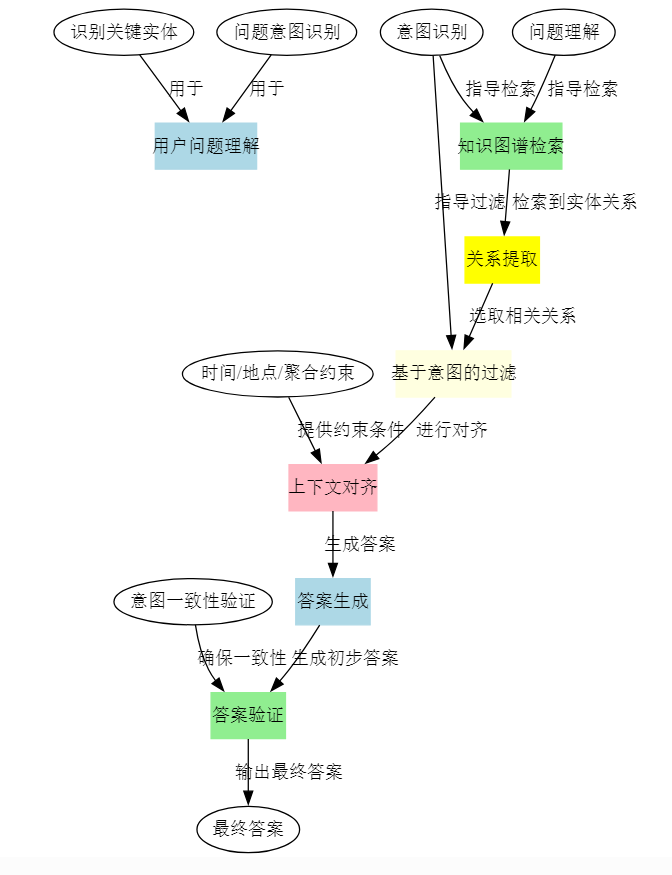
1.1 整体解法概述
- 整体解法(Mindful-RAG)
旨在利用 LLM 的内置(参数化)知识与外部知识图谱(非参数化)相结合,增强在复杂问答任务中的准确度和可解释性。核心思路是:- 通过“意图识别 + 上下文对齐 + 约束处理 + 验证反馈” 的一系列步骤,减少 LLM 产生的推理错误和不必要的“幻觉”。
- 与传统的 KG-RAG 方法相比,Mindful-RAG 更强调在检索过程中的“意图理解”与“上下文对齐”,而不仅仅依赖语义相似度来检索知识图谱节点或子图。
1.2 子解法拆解(根据特征逐步映射)
根据论文阐述,整个 Mindful-RAG 解法可以拆解为 7 个主要子解法(每个子解法对应一个重要特征,少数会彼此衔接):
子解法1:识别关键实体与重要词
之所以用“识别关键实体与重要词”,是因为系统需要在任何知识检索之前,先了解“谁”或“什么”是问题的核心对象(特征:LLM 若不明确主实体,后续步骤会出现关联错误或抓取错误关系)。
-
技术公式(简要表示):
KeyEntities = L L M _ p a r s e ( Q u e s t i o n ) \text{KeyEntities} = \mathrm{LLM\_parse}(Question) KeyEntities=LLM_parse(Question)
AuxTokens = L L M _ e x t r a c t ( Q u e s t i o n ) \text{AuxTokens} = \mathrm{LLM\_extract}(Question) AuxTokens=LLM_extract(Question) -
与同类算法区别:传统 RAG 方法里,这一步大多只是基于字符串匹配(如“话题实体检测”);Mindful-RAG 更强调让 LLM 主动输出除实体外的“相关关键词”,如时间、地理、限制性描述等,以便后续更精确地检索子图。
子解法2:明确问题意图
之所以用“明确问题意图”,是因为很多推理失误来自于 LLM 没有真正识别用户“想要的目标”,比如问题需要比较?需要聚合?还是只要单一答案?(特征:复杂问题往往包含多层意图,需通过 LLM 问答式提示来明确其深层次目标)。
-
技术公式(简要表示):
Intent = L L M _ i n t e n t _ d e t e c t i o n ( K e y E n t i t i e s , A u x T o k e n s ) \text{Intent} = \mathrm{LLM\_intent\_detection}(KeyEntities, AuxTokens) Intent=LLM_intent_detection(KeyEntities,AuxTokens) -
与同类算法区别:普通 KGQA 仅做“slot 填充”或“关系匹配”,对“问题类型/意图”处理不够细致。本方法要求 LLM 先输出“问题意图标签”,再进入检索与推理阶段。
子解法3:分析上下文语境
之所以用“分析上下文语境”,是因为部分问题有附加信息或上下文限制(如“2010 年之后”或“在美国”)。若不显式处理,LLM 往往会忽略时空或其他条件(特征:上下文的时空信息或其他限制条件需要先行识别)。
-
技术公式(简要表示):
Context = L L M _ c o n t e x t u a l _ a n a l y s i s ( Q u e s t i o n , H i s t o r y ) \text{Context} = \mathrm{LLM\_contextual\_analysis}(Question, History) Context=LLM_contextual_analysis(Question,History) -
与同类算法区别:一些 RAG 方法不充分利用上下文,或只用检索出的文档上下文;Mindful-RAG 强调“让 LLM 主动输出上下文维度(时间 / 地点 / 人物状态)”,从而后续可在 KG 中有针对性地检索与过滤。
子解法4:抽取候选关系
之所以用“抽取候选关系”,是因为在知识图谱中需要先找到与主实体“一跳或多跳”内所有相关联的边与节点,才能进行后续筛选(特征:KG 中通常有大量关系,仅少部分与问题意图直接相关)。
-
技术公式(简要表示):
CandidateRels = G r a p h _ n e i g h b o r s ( K e y E n t i t i e s , k ) \text{CandidateRels} = \mathrm{Graph\_neighbors}(KeyEntities, k) CandidateRels=Graph_neighbors(KeyEntities,k)
其中 ( k ) 为检索半径(1-Hop 或 2-Hop 等),再由 LLM 解析这些关系的含义。 -
与同类算法区别:传统方法用实体链接 +“一跳扩展”即可;Mindful-RAG 结合子解法 2 和 3 的结果,会让 LLM 对这些候选关系进行二次分析并标注与意图/上下文的关系度。
子解法5:基于意图的过滤与排序
之所以用“基于意图的过滤与排序”,是因为关系太多会导致噪声;需根据前面识别到的“问题意图”与“上下文条件”,对候选关系进行优先级排名,并只保留最相关的若干(特征:大规模知识图谱中往往能搜索到过多无关信息,需要根据意图过滤)。
-
技术公式(简要表示):
FilteredRels = L L M _ f i l t e r ( C a n d i d a t e R e l s , I n t e n t , C o n t e x t ) \text{FilteredRels} = \mathrm{LLM\_filter}(CandidateRels, Intent, Context) FilteredRels=LLM_filter(CandidateRels,Intent,Context)
选取分数最高或最符合意图上下文的 Top-k 关系。 -
与同类算法区别:一些方法或许只做相似度排序;Mindful-RAG 要求把意图标签显式纳入排序过程,并让 LLM 在回答前“说明”过滤理由。
子解法6:约束的上下文对齐
之所以用“约束的上下文对齐”,是因为复杂问题常包含时间、地点、人名歧义或数量约束(特征:LLM 如果忽略具体约束,就可能回答过时或不相干的答案)。
-
技术公式(简要表示):
ConstrainedEntities = A p p l y C o n s t r a i n t s ( F i l t e r e d R e l s , C o n t e x t ) \text{ConstrainedEntities} = \mathrm{ApplyConstraints}(FilteredRels, Context) ConstrainedEntities=ApplyConstraints(FilteredRels,Context)
通过对比上下文中可能出现的时间 / 地理 / 状态等限制条件,淘汰不匹配的实体或关系。 -
与同类算法区别:普通 KGQA 多数仅做简单 WHERE 过滤;Mindful-RAG 利用 LLM 的理解力执行“高阶约束对齐”,包括多重条件组合和歧义消解。
子解法7:意图验证反馈
之所以用“意图验证反馈”,是因为在生成答案前,需要检查其是否真正与一开始识别的意图相匹配,以免最终回答跑偏(特征:LLM 有时会“跑题”或输出额外无关内容)。
-
技术公式(简要表示):
( AnswerDraft = L L M _ g e n e r a t e A n s w e r ( C o n s t r a i n e d E n t i t i e s ) ) ( \text{AnswerDraft} = \mathrm{LLM\_generateAnswer}(ConstrainedEntities) ) (AnswerDraft=LLM_generateAnswer(ConstrainedEntities))
( FinalAnswer = L L M _ v e r i f y I n t e n t ( A n s w e r D r a f t , I n t e n t ) ) ( \text{FinalAnswer} = \mathrm{LLM\_verifyIntent}(AnswerDraft, Intent) ) (FinalAnswer=LLM_verifyIntent(AnswerDraft,Intent))
若不符合意图,可回到过滤与排序环节重新选择。 -
与同类算法区别:在一些传统方法中没有“第二轮检查”,或只做简单的评分判断;Mindful-RAG 明确让 LLM 再次输出验证理由并对不符意图的草稿做修正。
1.3 示例
以“Who is Niall Ferguson’s wife?”这一简单问题为例:
- 子解法1:识别出“主实体 = Niall Ferguson”,“关键词 = wife”。
- 子解法2:意图=“找到 Niall Ferguson 的配偶(特指当前或最著名)”。
- 子解法3:上下文=“个人关系、婚姻信息”。
- 子解法4:在知识图谱中检索与 Niall Ferguson 相关的所有关系;得到若干关系,如“出生地”“职业”“配偶列表”等。
- 子解法5:过滤与排序后,“配偶信息”优先级最高。
- 子解法6:对齐可能的多任配偶信息,若有时间约束则需要排除过往配偶,最终锁定“current spouse”。
- 子解法7:验证生成的答复与意图是否相符,若只想要“现任妻子”,最后输出“Ayaan Hirsi Ali”。
- 这些子解法的逻辑链:以决策树形式列出
下面采用类似 tree 命令的层级结构,示例如下:
解法: Mindful-RAG
├── 子解法1【识别关键实体与重要词】
├── 子解法2【明确问题意图】
├── 子解法3【分析上下文语境】
├── 子解法4【抽取候选关系】
├── 子解法5【基于意图的过滤与排序】
├── 子解法6【约束的上下文对齐】
└── 子解法7【意图验证反馈】
- 该过程是一个顺序链条:从 1 → 2 → 3 → … → 7,若第 7 步验证不通过,会回到 5~6 步再进行迭代。
- 分析是否有“隐性方法”(关键步骤但并非书本定义)
在逐行比对上述各子解法时,发现以下可能算作“隐性方法”或“隐藏的关键步骤”:
-
隐性方法 A:LLM 内部的自检与多轮修正
在子解法 5~7 中,Mindful-RAG 要求 LLM 对过滤结果和最终答案进行“自我验证”。传统 KGQA 并不会“显式二次生成”。这是一个非书本原生的“自我反思”手段,类似“Self-Check”或“Self-Critique”。- 我们可将其定义为关键方法“Self-Verification”,在子解法 7(意图验证反馈)时具体实现。
-
隐性方法 B:对歧义做局部递归提问
当 LLM 遇到模糊约束(例如不确定人物同名)、时间范围不明时,需要再多做一次问答以确认上下文,或者在检索子图时进行局部回溯。这往往不在传统教程里写明,而是依赖编排 Prompt 或程序逻辑。- 我们可将其定义为关键方法“Ambiguity-Resolution”,在子解法 3 与 6 之间穿插执行。
因此,可以把上述两个“隐性方法”抽出来列为“关键方法”,在实现 Mindful-RAG 时格外关注。
- 分析是否有“隐性特征”
- 在子解法 3(分析上下文语境)与子解法 6(约束对齐)中,“时空与歧义信息” 往往不是显式写在问题里,而是内嵌于后续多轮推理产生的步骤中。
- 例如:问题并没明说“只要现任妻子还是曾经所有妻子”,但在对齐时如果发现一个人物有多段婚姻,就需要 LLM 判断答案。这里“现任性”或者“最新时段”其实是一种隐性特征,需要在问答/子图分析中体现。
- 这类“时空/状态”的特征更接近语义信息,而非显式写在原问题的文字里,只能通过 LLM 的推断或用户额外提示来显式化。
如上,这些“隐性中间步骤”与“隐性特征”虽然在论文中被提及(如“对时间、地点等约束的考虑”),但往往不被标明为独立算法步骤。通过上面拆解,我们把它定义为:
- 关键方法:Time/Location-State 约束判断
- 关键特征:对“最新”“当前”“最近”等状态维度的理解
-
方法可能存在哪些潜在局限性
-
对 LLM 的依赖性过强
- Mindful-RAG 很多环节(如识别意图、上下文对齐)都依赖 LLM 的自我理解和输出,一旦 LLM 本身受限(理解出错或模型尺寸不足),则影响整体准确度。
-
复杂多轮迭代效率问题
- 需要多次调用 LLM(过滤、验证、回溯),在大规模知识图谱或高并发场景下开销较大。
-
仍可能出现“幻觉”
- 即便有了意图检查等手段,LLM 依然可能编造细节,如果检索到的知识在 KG 中不足以回答问题,或检索阶段存在噪声。
-
对 KG 本身质量的依赖
- 如果知识图谱更新不及时或关系不正确,“基于意图的过滤”也无法纠正底层错误数据,导致答复不准确。
-
隐性特征与上下文的边界问题
- 一些上下文(如对话历史、多轮交互的意图)并非都能写进一个明确的 Prompt;复杂情况下仍需更精细的对话管理策略。
通过以上拆解,可以看出 Mindful-RAG 在传统知识图谱问答的基础上增加了对于“意图”和“上下文”层面的多次对齐与验证,从而在多跳推理和歧义消解方面更为稳健。
不过也要注意对 LLM 的过度依赖、多次调用成本以及幻觉的残余风险。
对于隐性特征与隐性方法,尤其是多轮自检和歧义回溯,需要在实际实现时重点关注并进行 Prompt 设计或辅助模块编排。
这样才能最大化利用 Mindful-RAG 的优势,同时减少潜在局限性带来的负面影响。
数据分析
让我从论文中提取所有具体的数据点:
- 基准数据集规模与特征:
-
WebQSP数据集:
- 测试样本数:约1600个
- 知识图谱:基于Freebase KG
- 需要2-3跳推理来识别正确答案
- 使用Hits@k作为评估指标
-
MetaQA数据集:
- 领域:电影领域
- 基于OMDb构建的电影知识图谱
- 专注于3跳问题
- 模型性能数据:
- 基线性能:
- 无RAG的ChatGPT (GPT-3.5):61.2%准确率
- StructGPT + ChatGPT (GPT-3.5):72.6% Hits@1准确率
- 错误分析数据:
- 总错误案例:435个
- 初始手动分析样本:约10%(~44个样本)
- 识别出的错误类型:8种主要类型
- 错误分类:2大类(推理失败和结构限制)
- Mindful-RAG改进后的性能:
- WebQSP数据集:84% Hits@1
- MetaQA数据集:82%准确率
- 基线模型对比:
评估了多个基线方法在WebQSP上的表现:
- KAPING
- Retrieve-Rewrite-Answer (RRA)
- Reasoning on Graphs (RoG)
- StructGPT
- 研究团队:
- 来自亚利桑那州立大学计算和增强智能学院的4位研究者
- 研究得到国家科学基金会Grant No. 2335666的支持
这些数据点展示了研究的全面性,从数据集规模到模型性能的具体改进都有明确的量化指标。特别值得注意的是,从基线模型的61.2%到最终的84%,显示了显著的性能提升。
提问
1. 为什么 Mindful-RAG 要将意图识别与上下文对齐作为其核心设计,而不是单纯依赖现有的语义相似度匹配?
回答:现有的基于语义相似度的 RAG 系统在面对复杂、领域特定的查询时,经常会出现推理错误,尤其是多跳推理和复杂上下文理解上存在不足。
传统的 RAG 方法过于依赖关键词和图谱的表面结构,未能深刻理解问题的真正需求。
而 Mindful-RAG 通过将“意图识别”与“上下文对齐”作为核心,意图确保模型能够准确理解用户查询的核心目标,避免生成不相关或错误的答案。
2. Mindful-RAG 提出的 “意图驱动” 的检索和对齐方式,是否会增加计算复杂度,从而使其在处理大规模图谱时变得不可扩展?
回答:是的,Mindful-RAG 的多轮检索、意图分析和上下文对齐等步骤在大规模图谱上进行时,可能会导致计算复杂度增加,尤其是需要在每一轮中重新评估关系和上下文时。
如果图谱本身非常庞大,尤其是在没有高效索引和缓存机制的情况下,系统的扩展性可能受到限制。
不过,作者并未详细探讨这些挑战,且在实验部分只使用了小规模数据集,这在实际应用时可能成为一个问题。
3. Mindful-RAG 依赖于 LLM 的内在参数知识,而 LLM 本身是否可能在面对特定领域的低资源数据时存在知识缺口?
回答:的确如此,Mindful-RAG 依赖于 LLM 的内在参数知识,而当前的 LLM 模型存在对某些领域(如医疗、法律等特定领域)的知识缺失,尤其是对于较新的、特定领域的专业信息,LLM 的知识可能会过时或不完整。
该问题在作者的实验设计中没有得到充分讨论。
4. 在子解法 5 中提到基于意图的关系排序,若查询中的关系不止一个或不明确,如何避免“歧义”问题导致的错误?
回答:歧义问题是 RAG 系统中常见的挑战,特别是在关系模糊或查询不明确时。
尽管 Mindful-RAG 试图通过上下文对齐来解决这一问题,但其依赖 LLM 模型进行深度语义分析,可能依然存在歧义无法完全消解的情况。
例如,当“妻子”与“前妻”存在多个匹配时,可能因为上下文缺乏足够信息,导致模型选择错误的关系。
5. Mindful-RAG 在处理多跳推理时能否保证其结果的准确性?如果一个查询涉及到长链的多跳推理,如何评估其推理路径是否正确?
回答:Mindful-RAG 对多跳推理进行了优化,特别是在关系过滤和排序的阶段,通过结合意图判断和上下文对齐。
然而,当涉及到非常复杂的多跳推理时(例如跨越多个实体和关系的深层推理),该系统仍可能面临挑战。
作者并未提供足够的评估数据,特别是在长链推理任务中的准确性和稳定性。
6. 在子解法 3 中提到的上下文提取方法,是否能够有效处理包含隐性条件的复杂查询?
回答:对于包含隐性条件(例如时间跨度、地理限制等)的复杂查询,Mindful-RAG 在理论上通过“上下文对齐”步骤来捕获这些隐性条件。
然而,模型如何识别和处理这些隐性条件并未完全明确。
在实际应用中,处理这些隐性条件的效果可能因问题的复杂性和隐性条件的多样性而受到限制。
7. Mindful-RAG 引入的“反馈验证”机制是否会带来较高的延迟,特别是在实时系统中?
回答:是的,反馈验证机制可能会引入额外的延迟,特别是在高频查询的实时系统中。
每次答案生成后都要回溯并进行校验和验证,可能导致系统响应速度变慢,尤其是在需要进行多轮反馈时。
作者并未对该问题进行深入分析。
8. 在子解法 6 的“约束对齐”步骤中,如果知识图谱缺乏某些特定的时间或地理信息,如何处理这种缺失数据的情况?
回答:如果知识图谱本身存在缺失数据,特别是关键的时间或地理约束信息,Mindful-RAG 可能无法准确生成最终的答案。
作者并未讨论这种“数据缺失”情况下的处理机制。
如果图谱的某些关键节点不完整,系统的准确性将会下降,特别是在时间或地点敏感的查询中。
9. Mindful-RAG 是否可以适应不断变化的外部知识图谱,尤其是在图谱频繁更新的情况下?
回答:Mindful-RAG 在设计时并未显式说明如何适应动态变化的外部知识图谱。
对于一些快速变化的领域,知识图谱可能会频繁更新或调整,而系统是否能够快速同步并适应这些变化是一个值得关注的问题。
当前的方案似乎主要依赖静态知识图谱,因此在动态变化的场景下,可能存在一定的局限性。
10. 如果用户查询的知识图谱没有相关信息,Mindful-RAG 会如何应对?是否会回退到纯粹的生成模型?
回答:当知识图谱中缺乏相关信息时,Mindful-RAG 会如何应对并未在论文中得到明确说明。
如果知识图谱的相关实体或关系完全缺失,系统可能会选择回退到生成模型,但这种回退机制并不总是保证产生正确的答案。
作者没有深入探讨在没有有效外部知识支持的情况下,如何确保系统的准确性。

一站式 AI 云服务平台
更多推荐

 19
19 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)