
Ollama 安装教程(超详细!零基础也能快速上手)
Ollama 是一个强大的本地大模型运行平台,让你轻松在本地运行如 LLaMA、Mistral、Gemma 等 AI 大模型,无需配置繁琐的环境和推理框架,简洁到离谱!这篇教程手把手教你在 **Mac、Windows、Linux** 上安装 Ollama,附带中文命令说明和常见问题排查,让你轻松玩转本地 AI 模型!
Ollama 是一个强大的本地大模型运行平台,让你轻松在本地运行如 LLaMA、Mistral、Gemma 等 AI 大模型,无需配置繁琐的环境和推理框架,简洁到离谱!这篇教程手把手教你在 Mac、Windows、Linux 上安装 Ollama,附带中文命令说明和常见问题排查,让你轻松玩转本地 AI 模型!
🧠 什么是 Ollama?
Ollama 是一个用于运行本地大模型(如 LLaMA、Mistral、Gemma 等)的轻量级平台,支持通过命令行或 API 调用模型,非常适合做 AI 开发、本地 RAG 项目、AI 聊天助手等。它自带 Web UI,支持模型下载、聊天、推理等操作。

💻 安装 Ollama
根据你的操作系统,选择对应的安装方式👇
🍎 Mac 安装教程
✅ 系统要求:
- macOS 12.6+(推荐 macOS 13+)
- 支持 Intel 或 Apple Silicon(M1/M2/M3)
🛠 安装步骤:
-
打开终端,安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh -
启动 Ollama 服务:
ollama run llama3会自动下载模型并启动。如果没有该模型,会自动联网下载,首次较慢。
🪟 Windows 安装教程
✅ 系统要求:
- Windows 10/11,推荐 Windows 11
- 安装了 WSL2(子系统) 和 Ubuntu 20.04+
🛠 安装步骤:
-
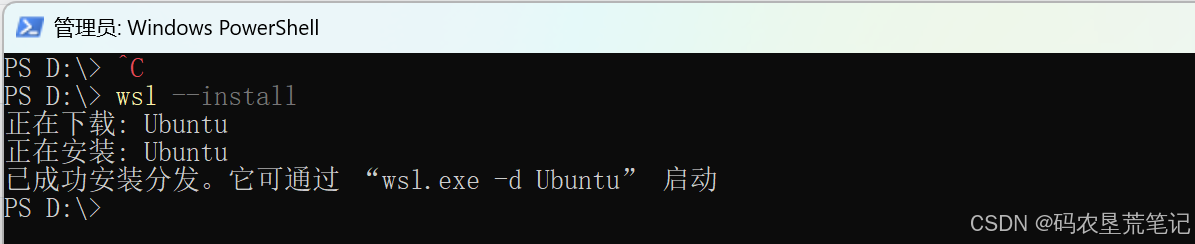
安装 WSL2(如果还未安装):
打开 PowerShell(以管理员身份打开),执行:wsl --install
-
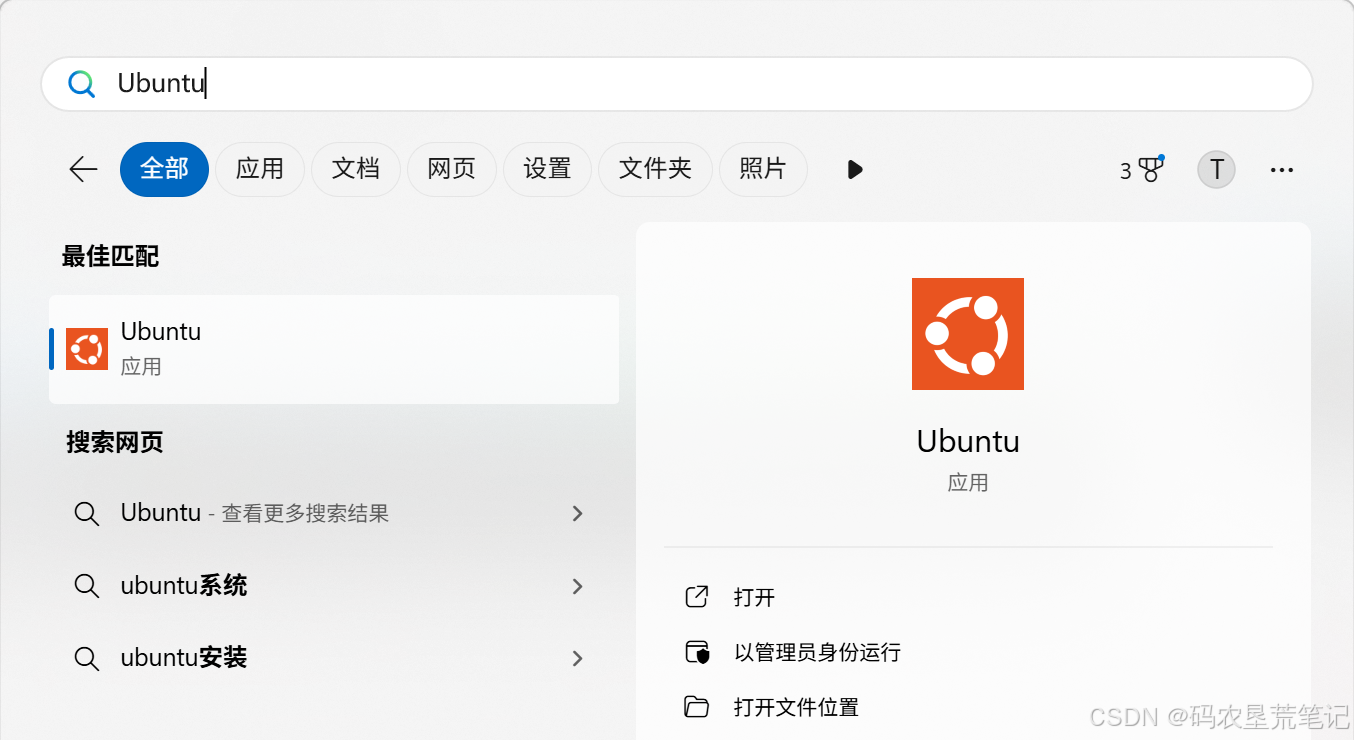
重启系统后,进入 WSL 的 Ubuntu 环境:
在开始菜单中打开“Ubuntu”
首次打开创建用户设置密码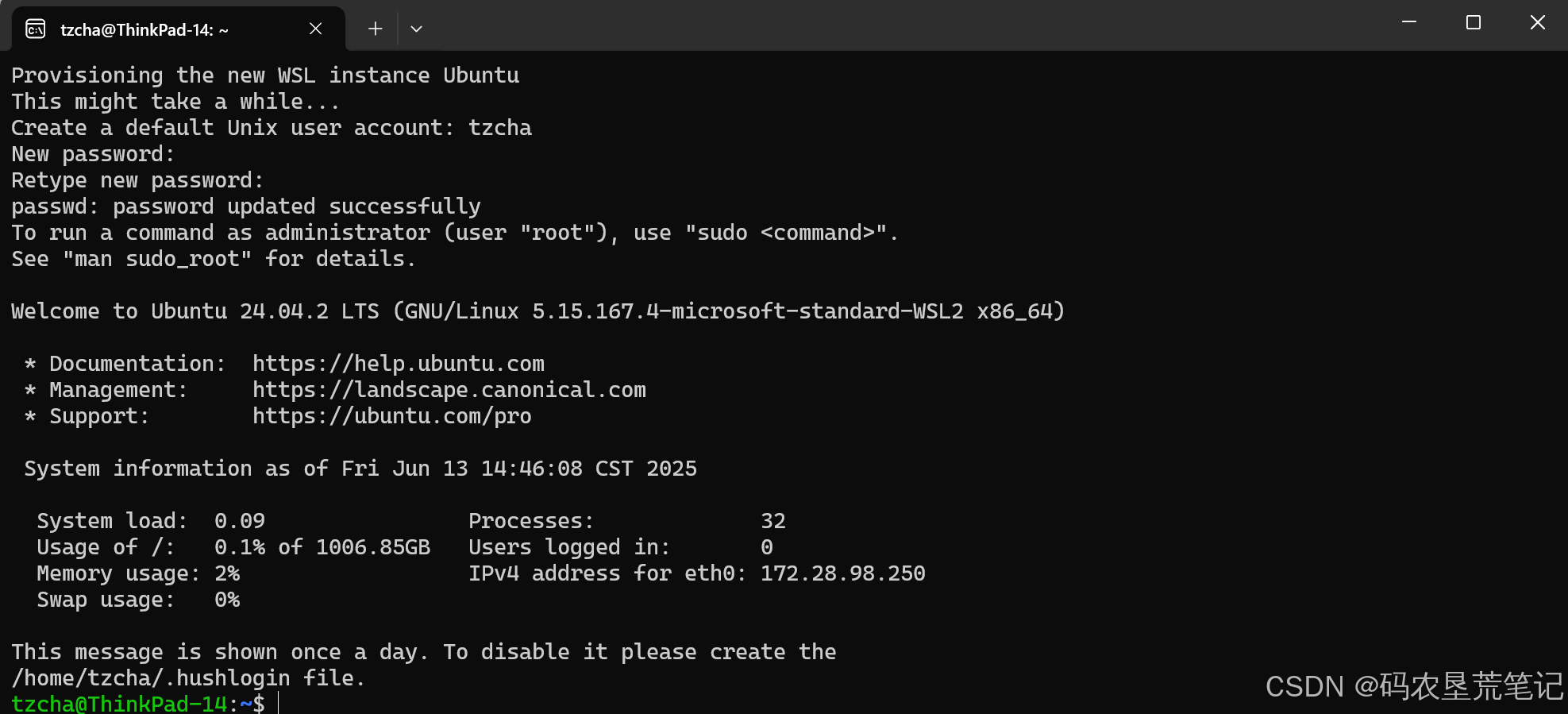
执行以下命令安装 Ollama:curl -fsSL https://ollama.com/install.sh | sh若因网络问题无法下载Ollama可以使用国内镜像源
国内镜像安装方法:
export OLLAMA_MIRROR="https://ghproxy.cn/https://github.com/ollama/ollama/releases/latest/download"
curl -fsSL https://ollama.com/install.sh | sed "s|https://ollama.com/download|$OLLAMA_MIRROR|g" | sh
- 原理:将脚本中的下载地址替换为国内可快速访问的镜像源(如
ghproxy.cn)
。 - 备用加速器:若
ghproxy.cn速度仍慢,可通过 Github 加速器网站 测试其他代理地址,替换OLLAMA_MIRROR值
-
运行模型:
ollama run llama3首次运行会下载模型,耗时视网速而定。
-
访问 Ollama:
默认在localhost:11434提供 REST API 接口,可以用于开发。
🐧 Linux 安装教程
✅ 系统要求:
- Ubuntu 20.04+ / Debian / Arch / Fedora 等主流发行版
- 建议使用现代内核(5.x+)
🛠 安装步骤:
-
下载并安装 Ollama:
curl -fsSL https://ollama.com/install.sh | sh -
运行模型:
ollama run llama3 -
后台运行(可选):
Ollama 默认以后台服务运行,你可以使用 REST API 进行调用。
🧪 测试是否安装成功
你可以运行下面的命令,测试是否正常启动:
ollama run llama3
然后输入任意问题,例如:
你是谁?
模型将开始响应,并持续对话,直到你按下 Ctrl+C 退出。
📦 常用模型推荐
| 模型名称 | 简介 | 推荐用途 |
|---|---|---|
llama3 |
Meta 发布的最新模型 | 通用聊天、问答 |
mistral |
开源强模型 | 快速响应、高性能 |
gemma |
Google 发布的模型 | 英文任务 |
codellama |
编程专用模型 | 代码补全、代码问答 |
🌐 Ollama api 访问(可选)
安装好后,访问:
http://localhost:11434
即可使用 Ollama 的本地 接口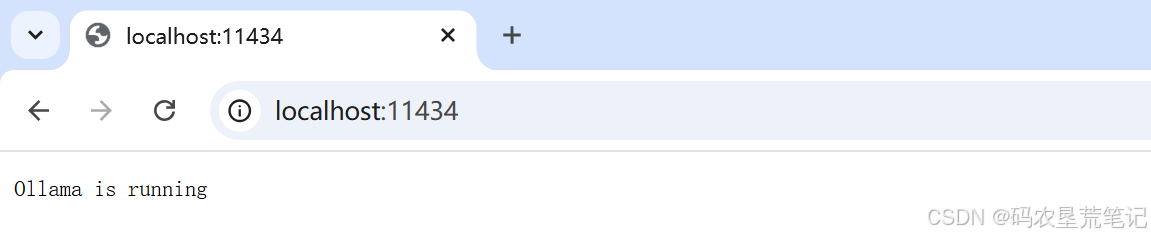
🚧 常见问题 FAQ
❓ Q: 模型下载太慢怎么办?
A: 你可以使用 VPN 加速或提前下载 GGUF 模型,放在 $HOME/.ollama/models 目录下。
❓ Q: 是否可以自定义模型?
A: 可以!你可以用 ollama create 自定义你的模型,支持融合你自己的微调模型或 embedding。
🧰 更多用法
查看所有可用模型:
ollama list
停止模型:
ollama stop llama3
删除模型:
ollama rm llama3
📝 写在最后
Ollama 的安装过程非常简单,是 AI 工程师和开发者体验本地大模型的最佳起点。不管你是玩 RAG、还是做 AI Agent,本地部署 Ollama 都是极具性价比的选择。
如果这篇教程对你有帮助,欢迎点赞👍、收藏⭐、转发📢支持我继续分享更多 AI 实战经验!

一站式 AI 云服务平台
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)