
零代码!手把手在 WorkBuddy 搭一个专属 GIS 数据处理助手
上一篇我提到,处理太原那 200 条乱格式坐标时,我用了一个在 WorkBuddy 里自己搭的 skill——coord-batch-toolkit,半小时搞定了。
然后有朋友私信问我:「你那个 skill 怎么搭的?」
今天就把整个搭建过程拆开讲。不只是坐标转换那一个,我昨天还搭了一个更通用的 GIS 处理助手,覆盖矢量分析、栅格分析、批量处理、可视化……我工作里高频用到的 GIS 操作,全都塞进去了。
先把这个搭建思路说清楚,以后你可以按这套方法搭自己的专属助手。
WorkBuddy 的 Skill 是什么,agent是什么
在正式讲怎么搭之前,先解释一下 Skill 是什么东西。
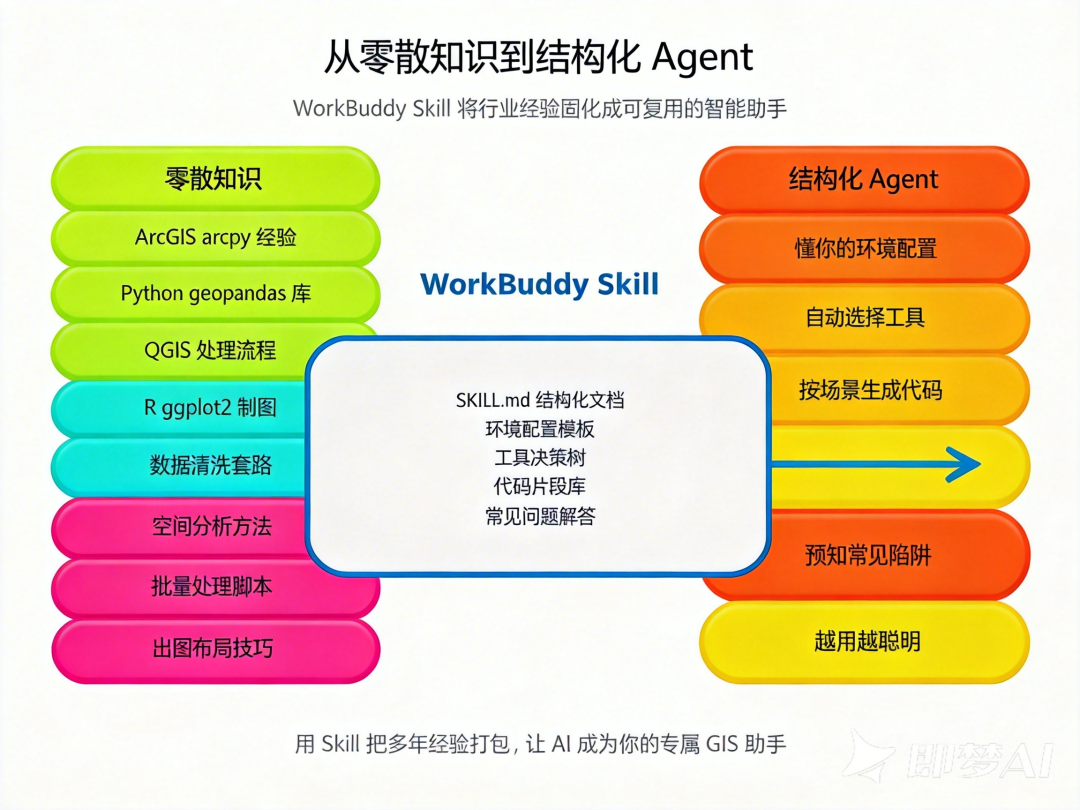
WorkBuddy 里的 Skill,本质上是一个文本文件——你用 Markdown 把某个领域的操作规范、代码模板、常见问题、决策逻辑写进去,AI 加载这个文件之后,就带着这套专业知识来跟你对话。
简单说:Skill = 给 AI 的行业手册 + 操作流程 + 代码库
它和直接问 AI 的区别在于:普通对话里,你每次都得重复交代背景("我用的是 ArcGIS Pro 3.5,环境是 arcgispro-py3……");有了 Skill,这些信息已经固化在里面,每次调用直接用,不用反复说。
更重要的是:Skill 是活的。你用得越多,发现新坑、新场景、新套路,直接往 Skill 里补——它就跟着你一起成长。用上三个月,它已经懂了你工作里 80% 的细节。
Agent 是一个有自主意识的执行者,它具备:
1. 身份(Identity)
我是谁?我叫什么?我的立场是什么?
就像你现在跟我对话——我有 SOUL.md、IDENTITY.md,这些就是在定义我这个 Agent 是谁。
2. 工具权限(Tools)
我能操作什么?
不同 Agent 可以有不同的权限——比如只能读文件、不能执行命令;或者可以联网但不能写磁盘。
3. 行为规则(Instructions)
我遇到 X 情况怎么办?
比如"回答只用中文"、"遇到地理数据优先用 arcpy"、"给用户报价前必须先确认需求"。
两者的区别:
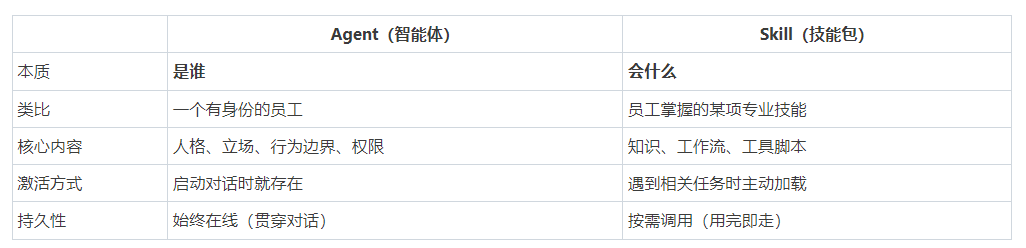
故,本篇文章先将skills将讲清楚,后续根据需求,进一步封装为agent,具体封装过程,后面分享。
我搭了哪些东西
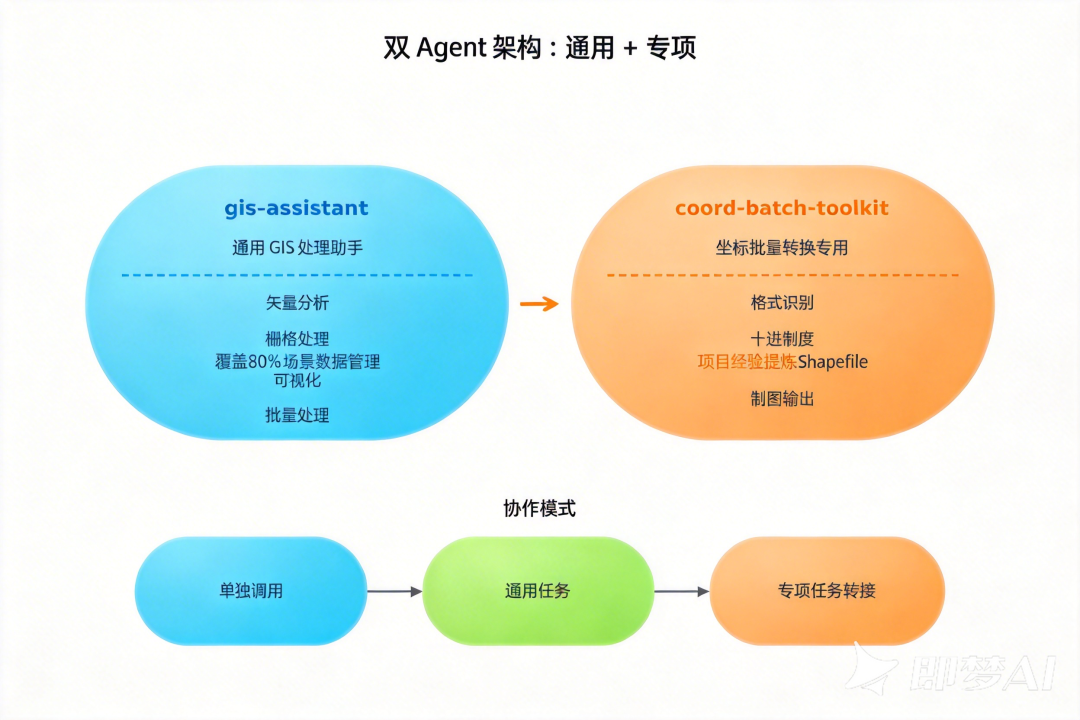
昨天我一共建了两个 Skill:
|
Skill 名称 |
定位 |
覆盖范围 |
|---|---|---|
gis-assistant |
通用 GIS 处理助手 |
集中 ArcGIS Pro、QGIS、Python、R 所有优势,覆盖矢量/栅格/数据管理/可视化/批量处理 |
coord-batch-toolkit |
坐标批量转换专用 |
格式识别 → 十进制度 → Shapefile → 制图 |
gis-assistant 是主力,覆盖了我日常工作 80% 的场景;coord-batch-toolkit 是从一个具体项目里提炼出来的专项工具,可以单独调用,也可以由 gis-assistant 转给它处理。
800
第一步:整理工作流程
搭 Skill 之前,先想清楚:要它帮你做什么?
我做的方式是把自己做 GIS 工作的常见场景列出来,然后按类型归组:
我的 GIS 工作场景
├── 数据处理
│ ├── 格式转换(shp/gpkg/geojson/kml 互转)
│ ├── 坐标系检测与转换
│ ├── 属性表增删改
│ └── 坐标格式清洗(这次的主角)
│
├── 空间分析
│ ├── 矢量叠加(缓冲/裁剪/融合)
│ ├── 栅格分析(DEM/插值/NDVI)
│ └── 水文分析(流域划定)
│
├── 数据质量
│ ├── 几何有效性检查
│ ├── 坐标范围合法性检查
│ └── 属性空值排查
│
└── 可视化
├── 交互式地图(Folium/Plotly)
├── 专题地图(R + ggplot2)
└── 统计图表(matplotlib)
归完类,我发现最高频的就这几块,重点放进 Skill 里,不常用的后续再加。
800
第二步:搭 gis-assistant(通用 GIS 助手)
这个是主力 Skill,我从三个维度来写:
一、本机环境配置
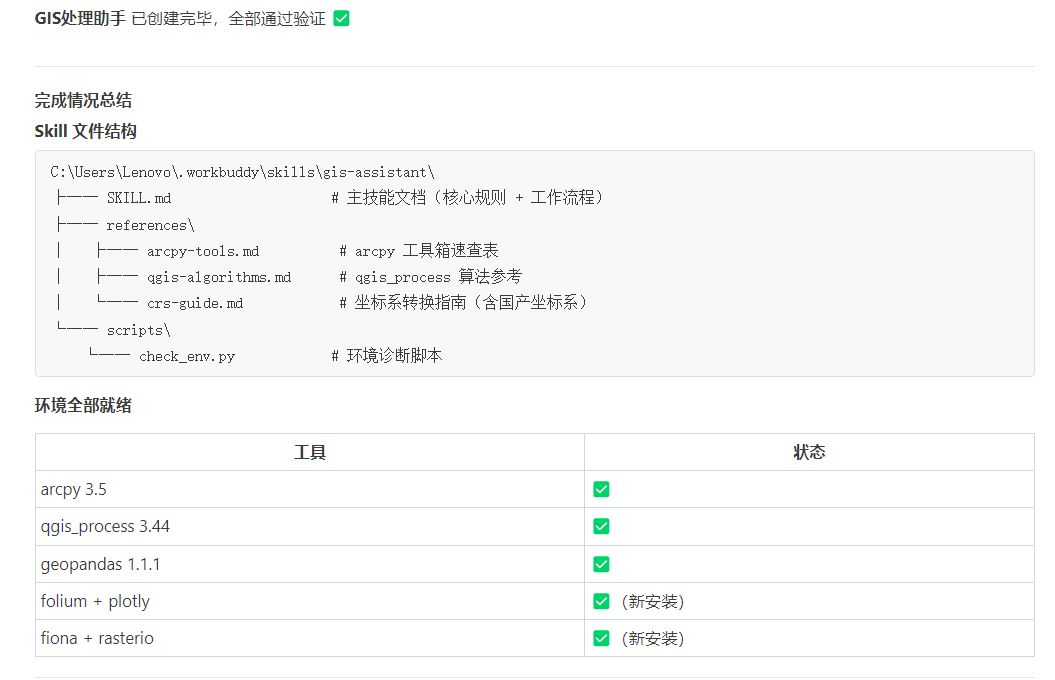
GIS 工具链比较复杂,不同电脑上的安装路径、版本都不一样。我把自己这台机器上已验证可用的配置全部写进去:
## 本机环境(已验证)
| 软件 | 版本 | 调用路径 |
|------|------|----------|
| ArcGIS Pro | 3.5 | C:\Program Files\ArcGIS\Pro\bin\Python\envs\arcgispro-py3\python.exe |
| QGIS | 3.44.0 | C:\Program Files\QGISQT6 3.44.0\bin\qgis_process-qgis-qt6.bat |
| Python | 3.11.11 | arcgispro-py3 环境 |
| geopandas | 1.1.1 | ✅ |
| folium | 0.20.0 | ✅ |
| rasterio | 1.4.3 | ✅ |
有了这段,AI 生成代码时会自动用我机器上的路径,不会生成一堆需要自己改的占位符。
二、工具选择决策树
这是我觉得最值钱的部分。
GIS 里同一件事通常有三四种做法(arcpy / geopandas / QGIS / GDAL / R),到底用哪个?有时候选错了要么跑不起来,要么性能很差。我把这套决策逻辑写成树状结构,把各大软件和编程语言的优势全揉进去——arcpy 的稳定、geopandas 的内存效率、QGIS 的算法丰富、R 语言的制图质量,按场景自动挑:

任务类型?
├── 栅格分析
│ ├── 水文分析(流域/汇水/河网)→ arcpy Spatial Analyst(优先)
│ ├── DEM 衍生产品(坡度/坡向)→ arcpy SA / gdal
│ └── 影像分类 → arcpy Image Analyst
│
├── 矢量分析
│ ├── 缓冲/叠加/裁剪 → arcpy(稳定)
│ ├── 大数据量(>50万要素)→ geopandas(内存效率更高)
│ └── 空间统计(热点/聚类)→ arcpy Spatial Statistics
│
└── 可视化
├── 交互式地图(HTML)→ folium / plotly(优先)
└── 静态地图出图 → R + ggplot2(出版质量优于 Python,别不服)→ arcpy Layout
AI 拿到这个之后,每次分析前会先判断任务类型,选对工具,而不是随机给你一段可能跑不通的代码。
有点题外话:静态专题图这件事,R + ggplot2 确实比 Python 强。配色、图例、版式、字体、图面元素……R 一套下来就是出版级,Python 得拼半天才能接近。我以前死磕 Python,后来老老实实用 R,节省的时间用来喝咖啡都够了。
三、领域专业知识
我主要做环境,可能涉及生态、水文方向,还有一些土地利用和人口数据。这些领域有自己的数据规范、常用算法、关键参数——这些东西不写进去,AI 生成的代码往往差那么一口气。
比如水文分析,必须先填洼(Fill),否则河网会断裂;比例尺分析必须用投影坐标系,不能用地理坐标(单位是度,结果会错)。这类「老手才知道的坑」,我都整理进了 Skill 里。
三调地类码对照表、行政区划代码规范这些查起来麻烦、但又用得很频繁的东西,也都放进去了,以后直接问就有。
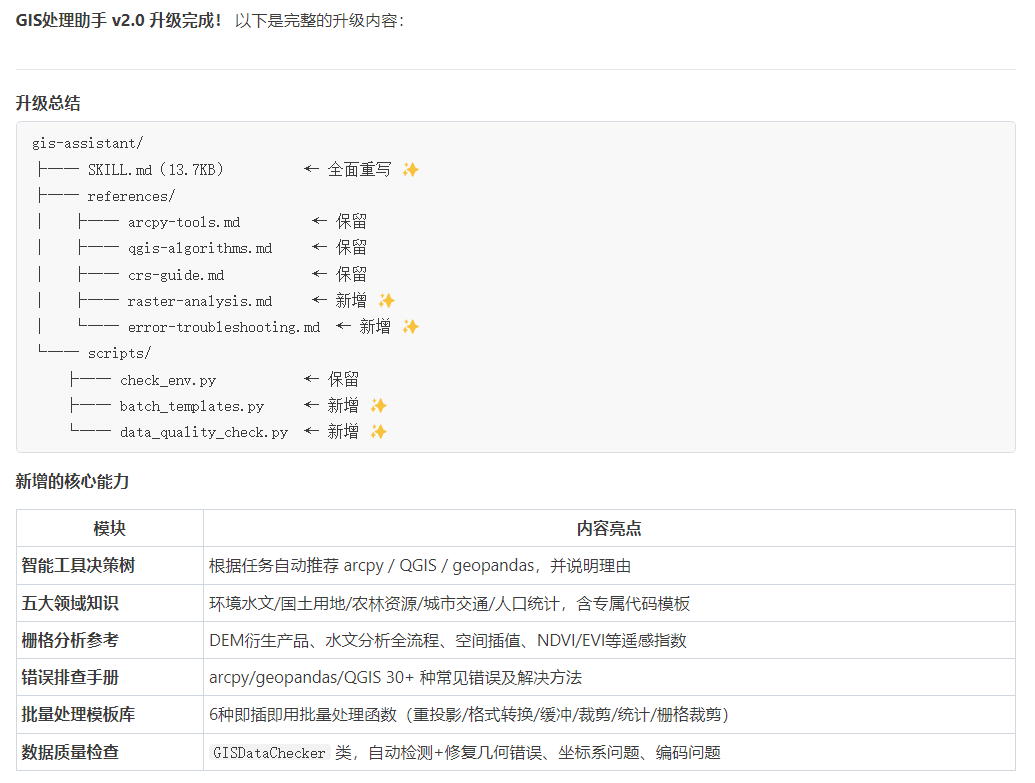
第三步:搭 coord-batch-toolkit(坐标转换专项)
这个 Skill 更具体,就是针对坐标格式混乱这一类问题。
为什么单独建一个,而不是直接塞进 gis-assistant?
原因很简单:代码量太大,全塞进去 Skill 文件会变得臃肿,而且坐标转换是一个高频独立场景,单独一个更清爽。
这个 Skill 的核心是三步标准流程:
① 格式识别与转换
输入:混乱格式 CSV(DMS/DM/DD 混杂)
输出:统一十进制度 CSV
② 转为矢量 Shapefile
输入:十进制度 CSV
输出:点 Shapefile(EPSG:4326)
③ 专题制图
方式一:Folium 交互地图(HTML)
方式二:R 语言专题图(A4/300DPI JPG)
800
Skill 里写了 parse_coord() 函数的调用规范,能识别的格式包括:
|
格式名 |
示例 |
|---|---|
|
度分秒(DMS) |
112°29′46.40″E |
|
度分(DM) |
112°29.7734′E |
|
十进制度(DD) |
112.711151E |
|
空格分隔 |
112 29 46.40 |
|
异常格式 |
112.29.46
(小数点分隔度分秒) |
还有一些关键的工程细节也写进去了——比如 Shapefile 字段名不能超过 10 个字符,中文字段会被截断,需要用英文字段名;比如底图 Shapefile 如果是 GBK 编码,要先用 Python 转成 UTF-8 再给 R 读。这些都是踩坑总结,写进 Skill 就再也不用踩第二遍。
第四步:安装到 WorkBuddy
写完 Skill 之后,安装很简单:
1. 建文件夹结构
~/.workbuddy/skills/
├── gis-assistant/
│ ├── SKILL.md ← 主文件,AI 读这个
│ ├── scripts/ ← 代码模板(可选)
│ └── references/ ← 参考文档(可选)
│
└── coord-batch-toolkit/
├── SKILL.md
├── scripts/
│ ├── coord_converter.py
│ ├── coords_to_shp.py
│ └── map_points_r.R
└── references/
└── coord-formats.md
2. 把内容写进 SKILL.md
就是一个 Markdown 文件,按照上面我说的三个维度来写:环境配置 → 决策逻辑 → 领域知识 → 代码模板。
3. 放到指定目录
WorkBuddy 的 Skill 目录是固定的:C:\Users\你的用户名\.workbuddy\skills\
把建好的文件夹放进去,WorkBuddy 重启之后就能识别。

4. 调用
@skill://gis-assistant
帮我检查这份 Shapefile 的数据质量
或者:
@skill://coord-batch-toolkit
帮我转换这份经纬度数据:
- 输入:G:/data/太原坐标.csv
- 经度列:经度
- 纬度列:纬度
搭完之后的实际感受
搭这两个 Skill 大概花了我两个多小时。
前期整理工作流程、写决策树、翻出以前踩过的坑——这部分花时间最多,但这些东西本来就应该整理。其实写 Skill 的过程,就是一次对自己工作方法的梳理。
搭完之后的变化:
- 省去了大量重复交代背景的时间
:以前每次都要说「我用的是 ArcGIS Pro,Python 在这个路径……」,现在 AI 直接知道
- 代码生成质量明显高了
:因为有了工具决策树,给的代码不再是「凑合能跑」,而是适合我场景的最优选择
- 坑踩少了
:领域知识写进去了,水文分析自动提醒先填洼,比例尺计算自动提醒要投影,这种事 AI 会主动说而不是等你踩完再说
你也可以搭自己的助手
GIS 领域很宽,每个人的工作场景都不一样。我的 Skill 是按我自己的工作定制的——环境/生态/水文为主,ArcGIS Pro 环境,Python + R 技术栈。
你如果是做城市规划的,决策树里的优先项就会不一样;如果主要用 QGIS,环境那块也要换。
搭建思路是通的,内容得根据自己的实际情况填。
搭的时候有几个建议:
- 从最高频的场景开始
,别一上来就想做全覆盖,先把用得最多的 20% 场景做好
- 把踩过的坑写进去
,这比什么都值钱
- 代码模板要带路径变量
,修改起来方便
- 决策逻辑要写清楚为什么
,不只是「用哪个工具」,还要说「什么情况下用哪个」
福利:我的两个 Skill 源码开放
既然写到这里,我把我搭的两个 Skill 的源码整理好了,包括:
gis-assistant/SKILL.md—— GIS 通用处理助手完整配置
coord-batch-toolkit/SKILL.md—— 坐标转换专项助手完整配置
coord-batch-toolkit/scripts/—— 坐标转换 Python 脚本 + R 制图模板
安装方法:解压后放到 ~/.workbuddy/skills/ 目录下,重启 WorkBuddy 即可。
获取方式:点赞 + 关注本号,私信发送「GIS助手」,我把完整源码发给你。
写在最后
搭一个专属 GIS 助手,本质上是在把你多年积累的工作经验结构化,让 AI 能理解、能用。
这件事花的时间不多,但带来的复利是长期的——以后每次处理 GIS 数据,都是站在这套经验积累上往前走。
当然,这都是刚开始弄,过程中有很多做的可能不是很对的地方,在咱们的交流过程中后续逐步改正,最终肯定会越来越完善。
👇 你用什么工具做 GIS 数据处理?有没有高频但烦人的重复操作?留言聊聊。
扫码关注公众号
获取【GIS与AI】实战经验、源码模板、避坑指南

GIS+AI 系列 | 专注实战经验分享
封面和摘要
上一篇我提到,处理太原那 200 条乱格式坐标时,我用了一个在 WorkBuddy 里自己搭的 skill——
修改封面和摘要

一站式 AI 云服务平台
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)