
Python 应用实现 APM 自动注入(Kubernetes 篇)
本文面向 Kubernetes 与观测云 APM 用户,提供一套零代码侵入、可直接落地的 Python 容器应用全链路监控方案,为微服务问题定位、性能调优提供可靠数据支撑。
前言
本文面向 Kubernetes 与观测云 APM 的使用者,提供一套零代码侵入、可直接落地的 Python 容器应用全链路监控方案。你无需修改任何业务代码,只需跟着本文分步操作,即可快速实现 Python 应用的 HTTP 调用、数据库 / 缓存依赖等全链路数据采集,为微服务问题排查、性能优化提供数据支撑。
核心概念与架构
核心组件说明
先搞懂每个组件的作用,后续操作不迷茫:
| 组件 | 核心职责 | 新手一句话理解 |
|---|---|---|
| 观测云工作空间 | 链路数据的存储、可视化、分析平台 | 监控数据的 "后台管理系统" |
| DataKit | 观测云的数据采集核心,以 DaemonSet 形式运行在 K8s 集群每个节点,通过 ddtrace 采集器接收 Python 探针上报的链路数据,最终上报至观测云 | 集群里的 "数据采集快递员",负责把探针数据送到观测云 |
| DataKit Operator | 基于 K8s 准入控制机制,为目标 Pod 自动注入探针初始化容器和环境变量,无需修改业务代码 | 探针的 "自动安装机器人",不用你手动改应用配置,自动给符合条件的 Python 应用装监控探针 |
| ddtrace 探针 | Python 应用的链路埋点探针,自动采集应用调用链路数据 | 装在 Python 应用里的 "数据记录仪",自动记录应用的每一次调用 |
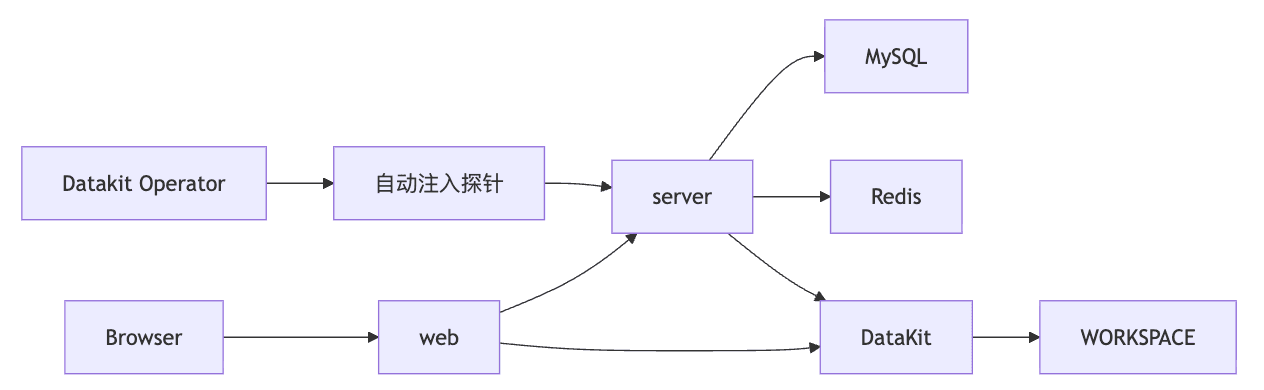
核心架构
本文示例为典型前后端分离场景,全链路数据流转架构如下:
前置准备
请先确认以下条件全部满足,再开始后续操作:
- 你有一个正常运行的 Kubernetes 集群,拥有集群管理员权限(可执行 kubectl apply、修改命名空间资源等操作)
- 你的 Python 容器应用已经正常部署在 K8s 集群中,且能正常对外提供服务
- 你已开通观测云工作空间,并获取到了对应工作空间的 Token(Dataway Token)
- 本地 kubectl 工具已配置好集群访问凭证,可正常连接并操作 K8s 集群
第一步:部署并配置 DataKit
1.1 部署 DataKit
执行官方清单快速部署 DataKit,默认以 DaemonSet 形式运行在所有节点:
# 部署 DataKit
kubectl apply -f https://static.guance.com/datakit/datakit.yaml
1.2 配置关键环境变量
执行以下命令,更新 DataKit 的环境变量,请务必替换尖括号内的参数为你自己的实际值:
kubectl -n datakit set env daemonset/datakit \
# 替换为实际的 Dataway 地址和 Token
ENV_DATAWAY="https://openway.guance.com?token=<YOUR-WORKSPACE-TOKEN>" \
# 自定义集群名称,便于多集群数据区分
ENV_CLUSTER_NAME_K8S="python-k8s-demo" \
# 必须包含 ddtrace,否则无法接收 Python 探针数据
ENV_DEFAULT_ENABLED_INPUTS="statsd,dk,cpu,disk,diskio,mem,swap,system,hostobject,net,host_processes,container,kubernetesprometheus,ddtrace"
可选方式:你也可以直接编辑 datakit.yaml 文件,修改对应环境变量后,重新执行 kubectl apply -f datakit.yaml 生效。

注意提示:
- ENV_DEFAULT_ENABLED_INPUTS 里必须包含
ddtrace,多个采集器之间只能用英文逗号分隔,不能有空格,否则采集器无法正常启用- Dataway 地址和 Token 必须填写正确,否则数据无法上报到观测云,Token 可在观测云工作空间的「管理」-「基本设置」中获取
- 确保集群节点能正常访问你的 Dataway 地址,无网络策略或防火墙拦截
1.3 验证 DataKit 部署状态
验证 Pod 运行状态
kubectl -n datakit rollout status daemonset/datakit
kubectl -n datakit get pods
预期结果:所有 DataKit Pod 状态为 Running,且分布在各节点。

第二步:部署并配置 DataKit Operator
2.1 部署 DataKit Operator
执行官方清单部署 Operator 组件(负责 Pod 探针注入):
kubectl apply -f https://static.guance.com/datakit-operator/datakit-operator.yaml
2.2 配置 Python 精准注入规则
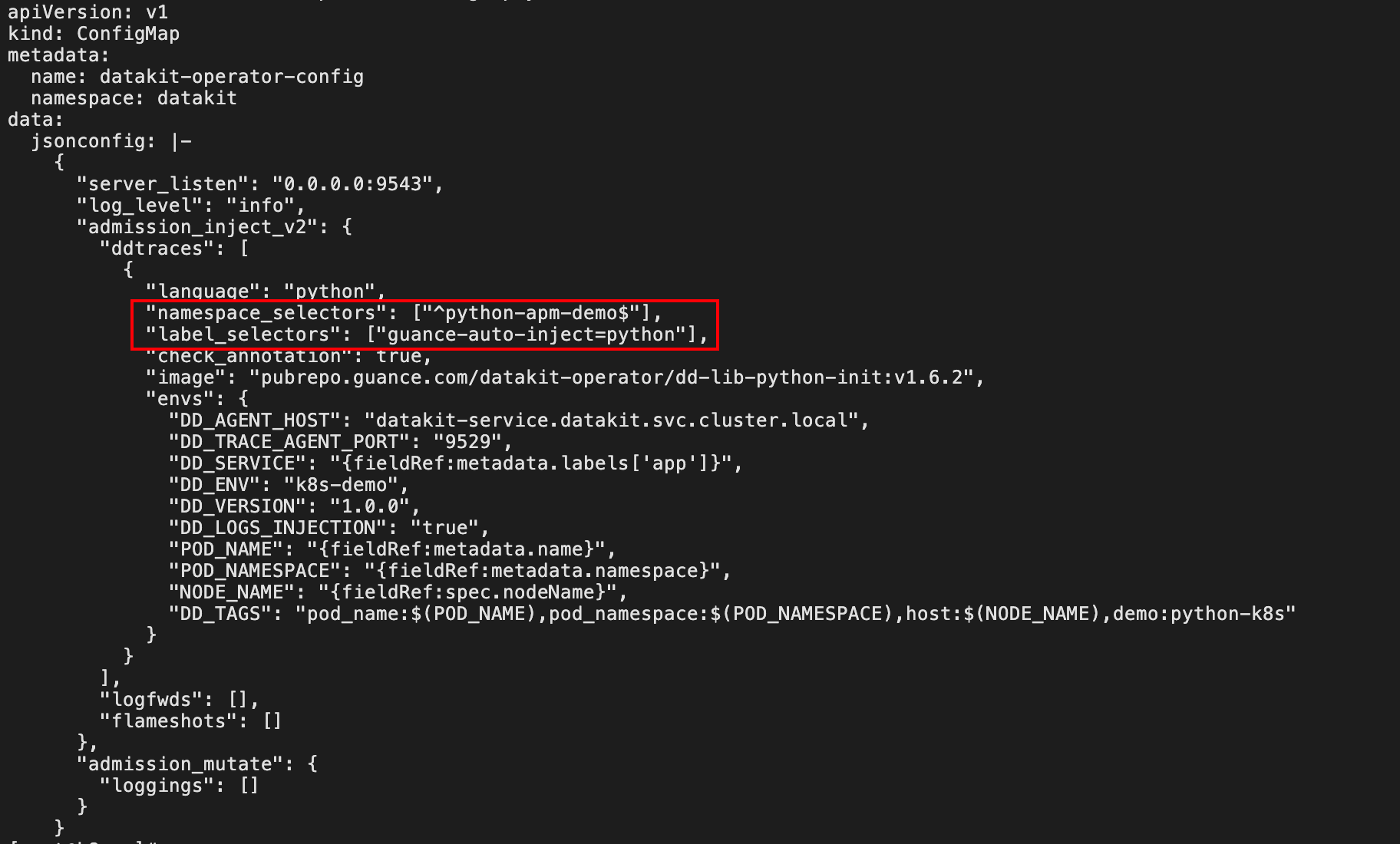
为避免全量注入,通过 ConfigMap 配置命名空间 + 标签双维度的精准注入规则,本案例仅对 python-apm-demo 命名空间(namespace)、带有 guance-auto-inject=python 标签(label)的 Pod 生效。
创建/更新注入配置
创建 datakit-operator-configmap.yaml 文件:
执行配置更新:
kubectl apply -f datakit-operator.yaml
# 重启 Operator 使配置生效
kubectl -n datakit rollout restart deployment/datakit-operator
kubectl -n datakit rollout status deployment/datakit-operator
新手提示:Operator 必须和 DataKit 部署在同一个
datakit命名空间下,否则会出现权限和配置读取异常。关键提醒:必须重启业务 Pod,Operator 才会在 Pod 创建时执行注入操作,已经运行的 Pod 不会被注入。
2.3 验证注入效果
验证 Operator 运行状态
kubectl -n datakit get pods -l app=datakit-operator -o wide
预期结果:datakit-operator Pod 状态为 Running.

验证业务 Pod 注入结果
kubectl -n python-apm-demo describe pod -l app=server
预期注入特征(关键验证点):
Env 中包含 DD_AGENT_HOST、DD_TRACE_AGENT_PORT 等环境变量

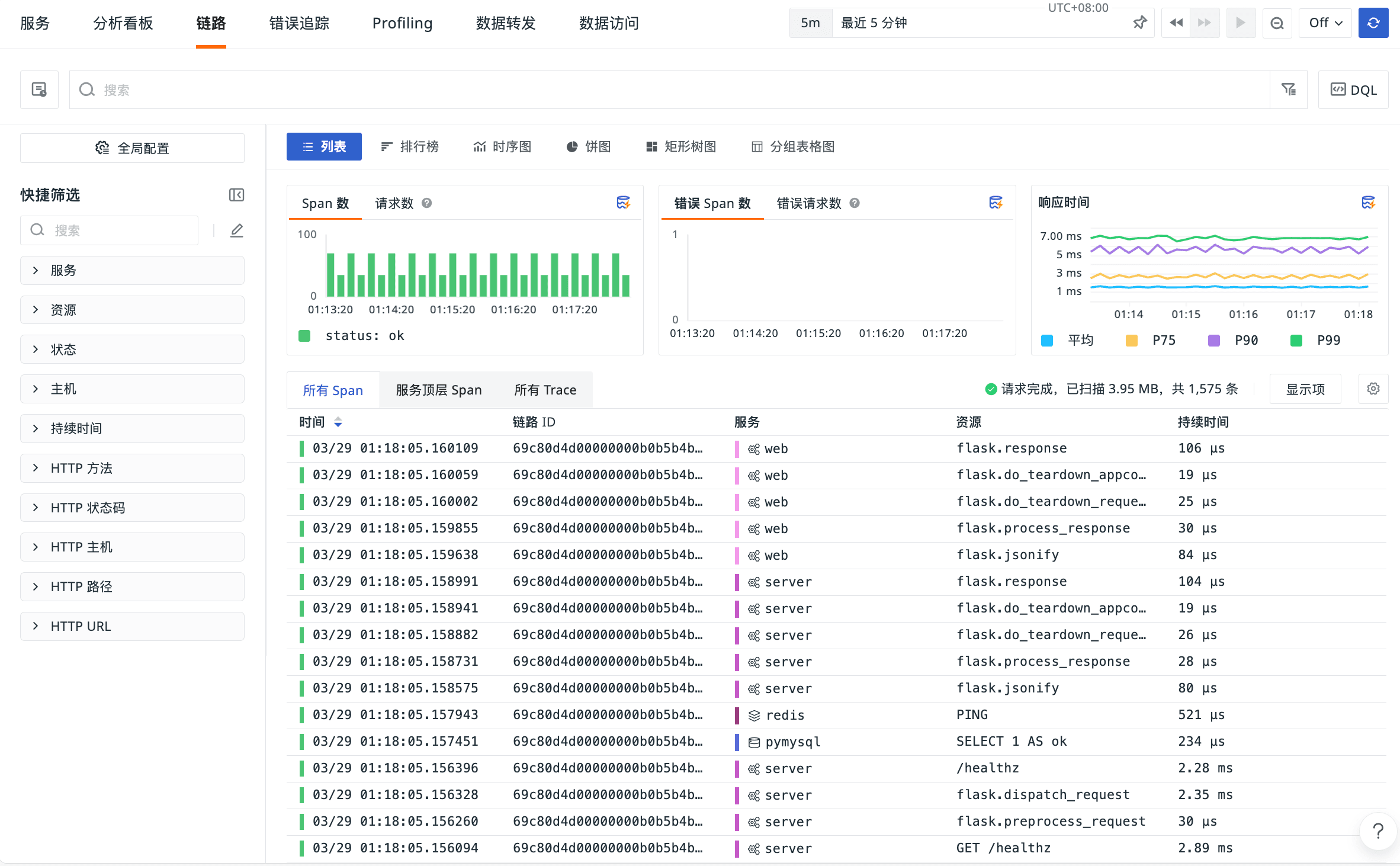
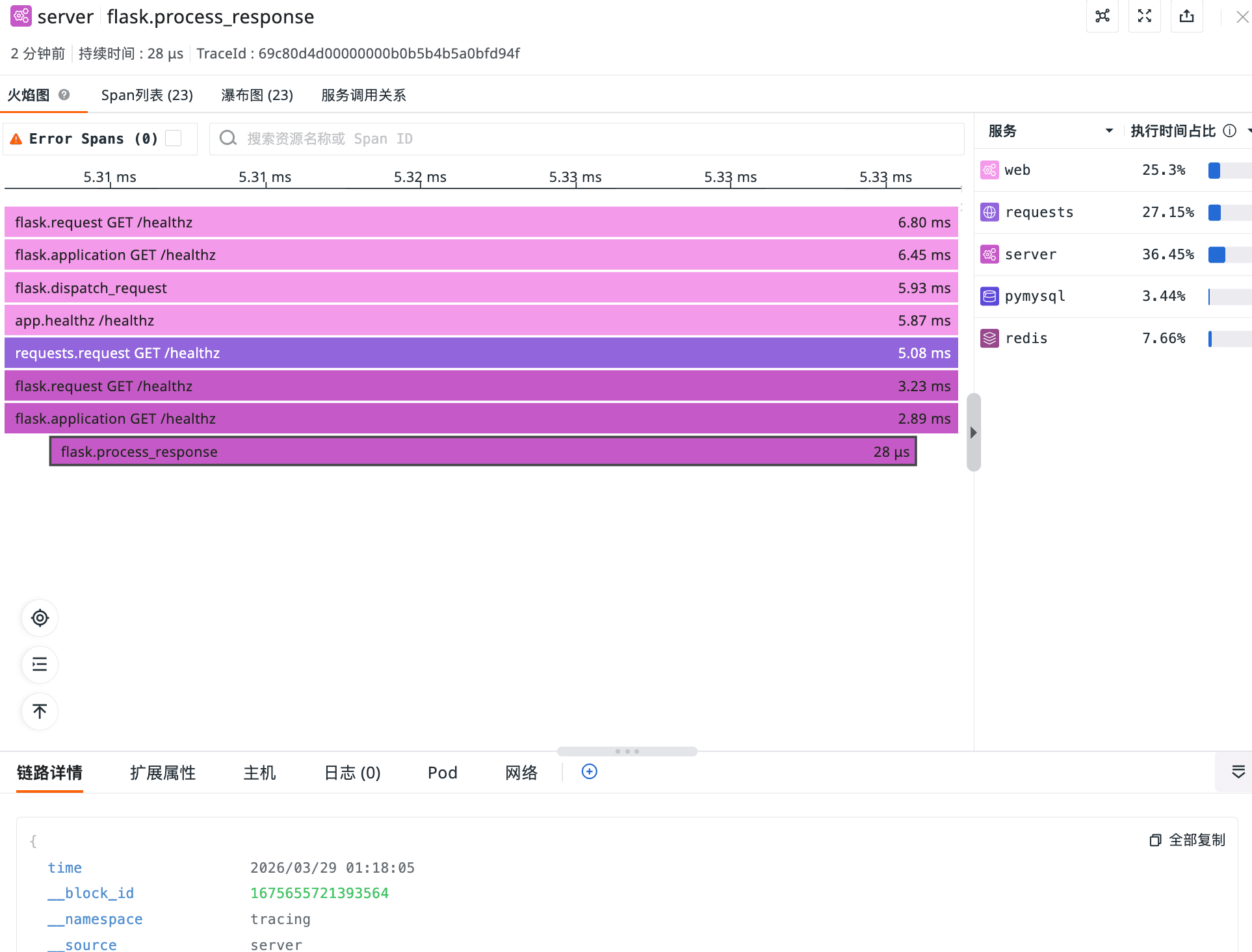
效果展示
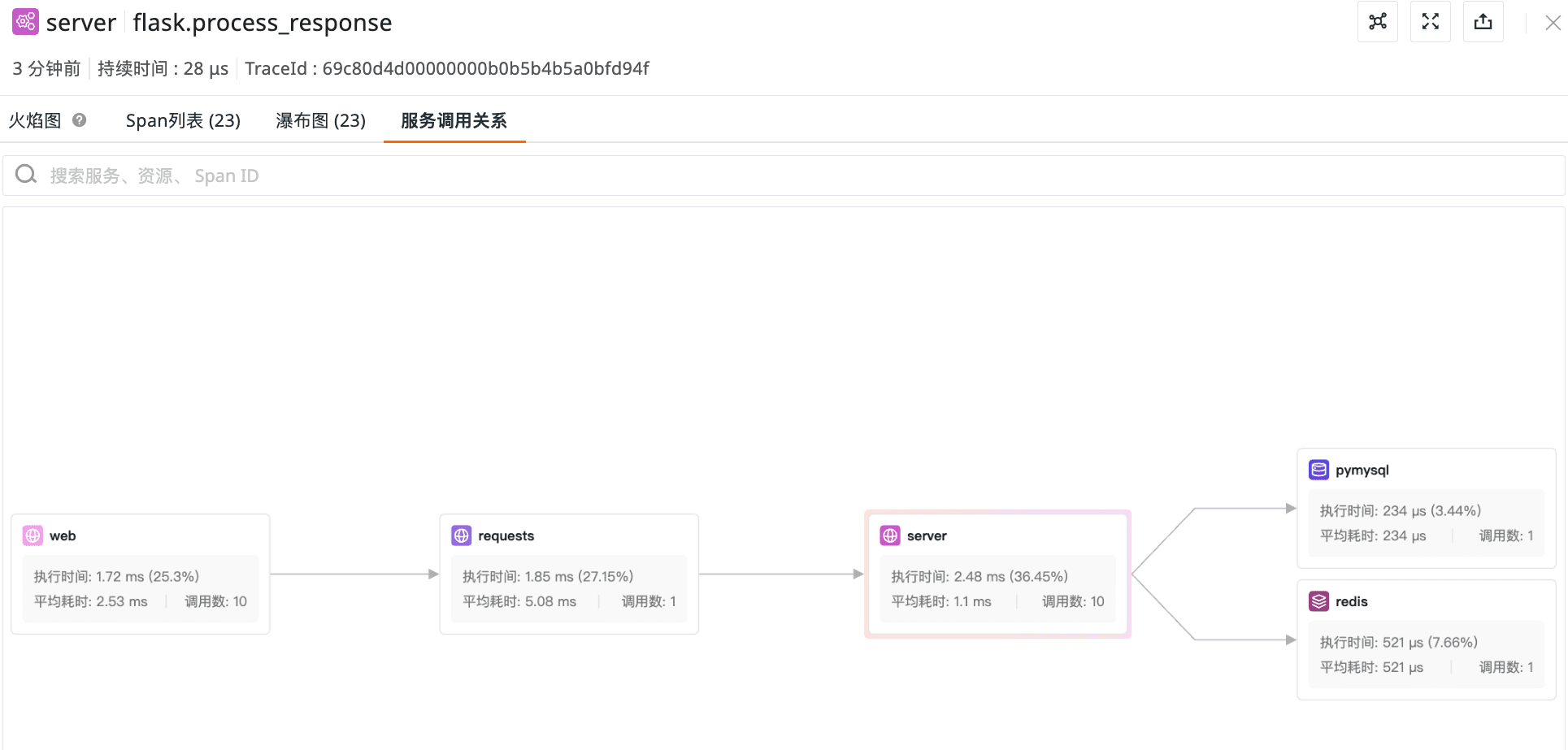
总结
本文基于观测云生态完成了 Python 容器应用的探针自动注入与全链路采集,核心价值在于:
- 无需修改业务代码,通过 Operator 实现无侵入式探针注入
- 精准控制注入范围,避免对集群内其他应用造成影响
- 完整采集 HTTP 调用、数据库/缓存依赖等全链路数据,满足可观测性需求
只要确保 DataKit 的 ddtrace 插件启用、Operator 注入规则配置正确,即可快速实现 Python 应用的全链路可观测性,为问题排查、性能优化提供数据支撑。

一站式 AI 云服务平台
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)