
Fay 全新图文知识库说明
和 Fay 的协作非常简单:把 .zip 直接放到 Fay 仓库下的 fay_player_knowledge/ 目录,Fay 启动时配套的 MCP 服务会自动扫描并加载它,整个对接过程零代码。图片处理上它做了一个很贴心的设计:启动时不提取图片,只有当某个章节实际被检索命中或者被读取时,才按需把图片从 zip 里提取到本地缓存目录,然后通过一个轻量 HTTP 服务把 images[].src 字段
Fay 全新图文知识库说明
- 课程ID:course-fay-kb-intro
- 作者:郭泽斌
- 版本:1.2.0
- 章节数:6
封面
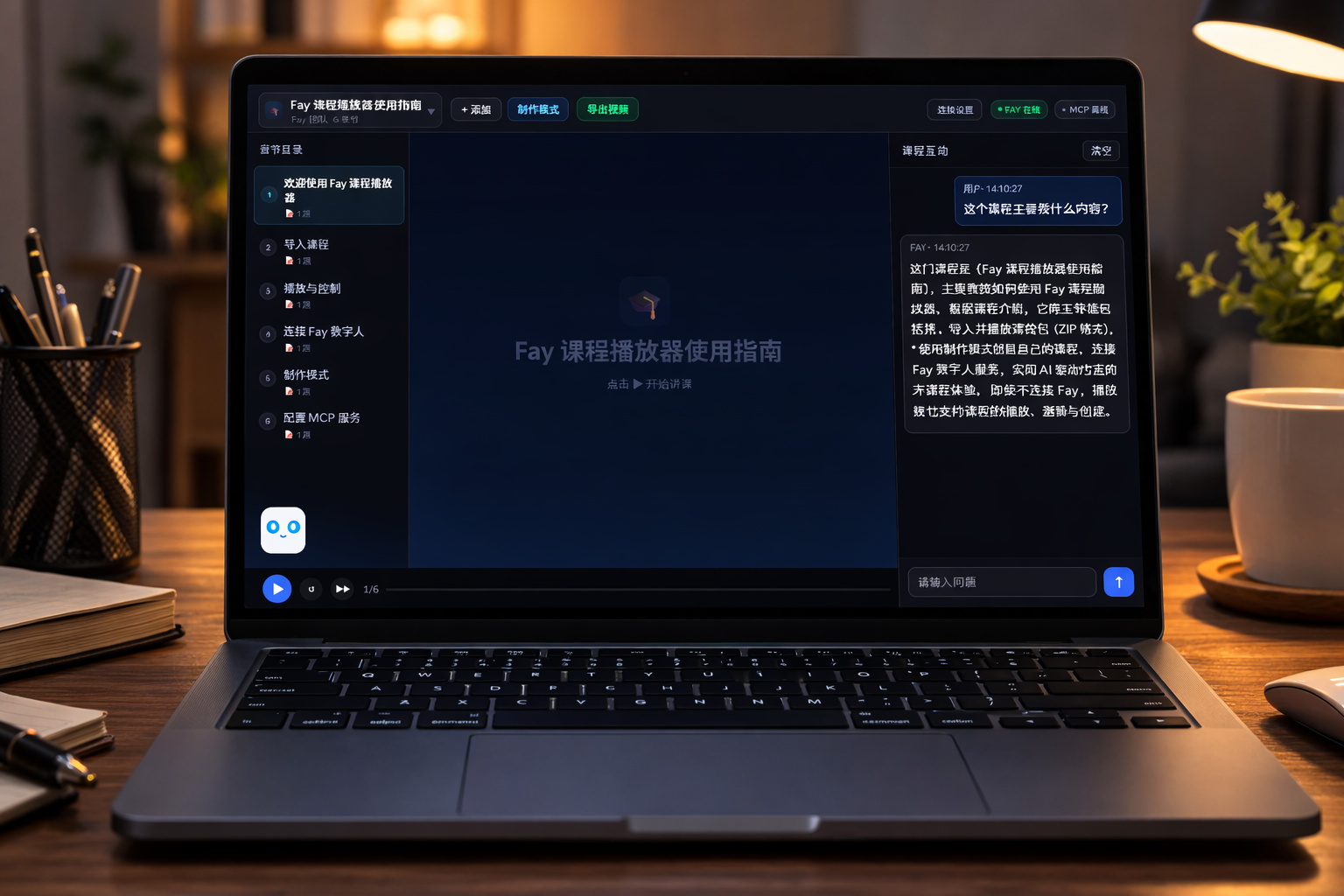
目录
- 为什么 Fay 需要图文知识库
- fay-player 一体化工具全景
- 课程包格式与目录结构
- 知识库 MCP 接入 Fay
- 工具列表与检索原理
- 一次编辑的完整工作流
第1节 为什么 Fay 需要图文知识库

欢迎来到《Fay 全新图文知识库说明》课程。
传统的 RAG 知识库基本都是纯文本:把 markdown 或者 PDF 切片之后丢进向量库,用户提问时检索若干段落塞回 LLM。这种方案在面对流程图、架构示意图、UI 截图、代码截图时非常吃力,因为图片要么被丢弃,要么只能用一段文字描述代替,原本最直观的信息反而最容易丢。
更尴尬的是同一份知识往往要走三个出口:内部知识库要给 Agent 检索,外部要发短视频要做讲解,落地交付又要导出 markdown 或者 PDF 文档。传统做法是三套内容分开维护,结果就是文档说一套、视频说一套、知识库又是另一套,口径经常对不齐。
Fay 在 4.4.x 版本里给出了一个新答案:把「课程包」作为图文知识的原生载体。一份 .zip 课程包内含 manifest、章节讲稿、讲义图、代码示例、题目,它既能被 MCP 知识库检索,也能在播放器里播放,还能一键导出为视频或者 markdown。
支撑这一切的是一个完全开源的工具叫 fay-player。本课程接下来会一层层拆开 fay-player 的能力边界、课程包的格式约定、MCP 接入方式、以及最重要的——「一次编辑、多形态产出」的完整工作流。
# 传统纯文本知识库 vs Fay 图文课程包
#
# 传统方案:
# docs/*.md → 切片 + embedding → 向量库 → RAG 检索
# videos/*.mp4 (单独剪辑)
# handouts/*.pdf (单独排版)
# ↑ 三套内容分别维护,口径漂移
#
# Fay 课程包方案:
# fay-player 编辑 → course.zip
# ├─ 输出1:MCP 知识库自动检索
# ├─ 输出2:在线播放 / 嵌入网页
# ├─ 输出3:一键导出讲解视频
# └─ 输出4:一键导出 markdown 文档第2节 fay-player 一体化工具全景

fay-player 是支撑整个图文知识库方案的一体化工具,地址是 player.fay-agent.com。它的定位非常清晰:一个网页端的「课程工厂」,从创建、编辑到分发,全流程都在浏览器里完成,不需要安装任何客户端。
它提供四个核心能力。 第一是浏览和创建。打开网站之后既可以浏览已有的公开课程包,也可以从零创建一个新的课程包,在线编辑章节标题、讲稿、配图、代码示例和章节小测。 第二是在线播放。每个课程包都可以直接在浏览器里以 PPT + 讲解的形式播放,方便对内培训或者对外演示。 第三是导出讲解视频。点一下导出按钮,fay-player 会基于讲稿和讲义图生成一段配音的 MP4 视频,省掉传统视频剪辑的所有工序。 第四是导出 markdown 文档。同样一键完成,把课程包还原成结构化的 md 文件,适合放进 Wiki、Notion 或者作为发版说明分发。
这里要特别强调一个常常被忽视的优势:无须算力。fay-player 是纯网页端的工具,不需要 GPU、不需要本地跑大模型、不需要部署任何推理服务,甚至连 Python 环境都不用准备。打开浏览器就能用,导出视频和 markdown 也不消耗你本地一分一毫的算力。这对于内容生产者来说意味着零门槛:无论你用的是轻薄本还是平板,都能完成完整的课程制作流程。
更关键的是 fay-player 完全开源,仓库在 gitee.com/xszyou/fay-player。这意味着你可以本地部署、二次开发、定制导出格式,整个工具链没有黑盒。
fay-player 的产物是一个标准 .zip 课程包,里面包含 manifest.json 和若干 sections 目录。和 Fay 的协作非常简单:把 .zip 直接放到 Fay 仓库下的 fay_player_knowledge/ 目录,Fay 启动时配套的 MCP 服务会自动扫描并加载它,整个对接过程零代码。
# fay-player 的四种产物对应的使用场景
#
# 1) 在线播放
# https://player.fay-agent.com/play/<course-id>
#
# 2) 导出讲解视频 (MP4)
# 适合短视频平台 / 内训复用
#
# 3) 导出 markdown 文档
# 适合 Wiki / 发版说明 / 团队知识沉淀
#
# 4) 导出 .zip 课程包 → 放入 Fay 知识库
#
# 关键优势:无须算力
# - 纯网页端运行,无需 GPU / 本地大模型 / 推理服务
# - 视频与 markdown 导出全部在云端完成
# - 轻薄本 / 平板均可完整完成课程制作流程
#
fay/
└── fay_player_knowledge/
├── README.md
├── Fay介绍(面向开发者).zip
├── Fay的think标签处理逻辑.zip
├── Fay的prestart标签处理逻辑.zip
├── Fay的多通道打断逻辑.zip
└── Fay全新图文知识库说明.zip ← 本课程第3节 课程包格式与目录结构

课程包是一个普通的 zip 文件,但是内部结构是约定好的,这样 fay-player、MCP 知识库、视频导出器和 markdown 导出器才能共用同一份内容。
顶层有一个 manifest.json,描述课程的元信息:id、title、author、version、cover_image,还有一个 sections 数组按顺序列出所有章节及其入口文件路径。
每个章节是一个独立的目录,命名规则是 sections/{两位序号}-{章节id},比如 sections/01-s01。章节目录里固定有几个文件: script.txt 是讲稿全文,用于视频配音和 markdown 正文; quiz.json 是章节小测,用于课程播放时的互动; assets/slide1.png 是讲义图,PNG 格式,1280×720,用于播放和视频画面; assets/demo.code.json 是代码示例,包含 code 字段和样式字段,用于代码高亮展示。
这种「每章一页 PPT」的设计带来一个非常关键的好处:检索粒度和播放粒度天然对齐。MCP 知识库内部按 chunk 检索召回更准,对外却按 section 返回完整章节,这样调用方一次拿到的就是一段自洽的知识单元,不会出现切片把上下文切碎的问题。
# 一份课程包的目录结构
course.zip
├── manifest.json
├── course-cover.png
├── robot/ # 讲解形象(可选)
│ ├── Normal.png
│ ├── Speaking.png
│ └── ...
└── sections/
├── 01-s01/
│ ├── script.txt
│ ├── quiz.json
│ └── assets/
│ ├── slide1.png
│ └── demo.code.json
├── 02-s02/
│ └── ...
└── 06-s06/
└── ...第4节 知识库 MCP 接入 Fay

fay-player 负责生产课程包,Fay 这边负责消费,承接消费的就是 fay_player_knowledge_base_mcp_server。
这个 MCP server 的设计目标是:不依赖播放器、不依赖 embedding,纯本地、零依赖、即装即用。它支持两种输入:直接指定一个 .zip 课程包,或者指定一个目录让它递归扫描所有 .zip。默认每 60 秒自动重新扫描一次,新增、删除、修改的课程包都会被实时同步到内存索引,你可以通过 --watch-interval 调整间隔,0 代表禁用。
图片处理上它做了一个很贴心的设计:启动时不提取图片,只有当某个章节实际被检索命中或者被读取时,才按需把图片从 zip 里提取到本地缓存目录,然后通过一个轻量 HTTP 服务把 images[].src 字段直接返回成可访问的 HTTP URL,调用方拿到结果后可以直接展示图片,不需要自己处理 zip。
接入 Fay 的步骤非常简单: 第一步,启动 Fay,打开 MCP 管理页 http://127.0.0.1:5010/Page3。 第二步,新增 MCP 服务,传输方式选 stdio,启动命令填 python,启动参数填 mcp_server/fay_player_knowledge_base_mcp_server.py --source ./fay_player_knowledge。 第三步,保存并连接,给 kb_search 工具配上 Prestart 参数模板。
Prestart 模板长这样:query 字段填 {{question}},limit 填 3 或 5,include_quizzes 通常打开。这样 Fay 会在每轮对话前先拉一次知识库命中结果,把相关章节注入上下文,再交给 LLM 生成回复。
# Fay MCP 管理页配置(http://127.0.0.1:5010/Page3)
{
"name": "fay_player_knowledge_base",
"transport": "stdio",
"command": "python",
"args": [
"mcp_servers/fay_player_knowledge/fay_player_knowledge_base_mcp_server.py",
"--source", "./fay_player_knowledge",
"--watch-interval", "60",
"--image-port", "18780"
]
}
# kb_search 的 Prestart 参数模板
{
"query": "{{question}}",
"limit": 3,
"include_quizzes": true,
"include_markdown": false
}第5节 工具列表与检索原理

MCP server 暴露的工具一共八个,记住四个高频的就够日常使用。
kb_list_sources 查看当前已加载的课程包;如果空就用 kb_add_source 加载新的;kb_get_catalog 看某个课程包的章节目录;最常用的 kb_search 直接拿用户原句搜索。
这里要特别强调一下 kb_search 的设计哲学:它不要求调用方先做 LLM 关键词提取。直接把用户的原句作为 query 传进去就行。原因是它内部用的是无依赖的轻量词法检索,而不是向量检索。具体逻辑是: 标题完全命中优先级最高; 标题包含查询短语次之; 正文包含查询短语再次之; 然后按英文 token 和中文 bigram/trigram 召回; 最后如果命中代码块或者题目块还会额外加权。
所有命中会按 section 聚合分数,最终返回的是若干完整章节,调用方拿到的就是「准、全、可直接用」的知识单元。
另外两个补充工具:kb_get_section 是已知章节 ID 时的精确读取,kb_read_document 是把整个 source 拉成 summary/markdown/text/json 四种格式之一,适合做全量同步或者完整 dump。kb_reload 和 kb_remove_source 是运维型工具,处理热更新和清理场景。
# 推荐调用顺序
1. kb_list_sources() # 看一眼已加载哪些课程包
2. kb_add_source(path=...) # 如果空,加载
3. kb_get_catalog(source_id=...) # 浏览章节目录
4. kb_search(query='用户原句') # 主力检索接口
5. kb_get_section(...) # 需要精确章节时再调
6. kb_read_document(...) # 需要全文时再调
# kb_search 返回结构
{
"score": 8.5,
"source_id": "course-fay-kb-intro",
"section_id": "s04",
"section_title": "知识库 MCP 接入 Fay",
"matched_in": ["title", "body", "code"],
"snippet": "...",
"section": { /* 完整章节内容 */ }
}第6节 一次编辑的完整工作流

把前面所有零件拼起来,就是 Fay 全新图文知识库的完整工作流。
第一步,在 player.fay-agent.com 创建一个新的课程包,填好课程元信息:标题、作者、版本、封面。
第二步,在浏览器里逐章编辑。每一章都包含讲稿、配图、代码示例和小测。fay-player 提供了一个所见即所得的编辑器,配图可以直接上传或者从图床引用,代码示例支持语法高亮,小测支持多选题和判断题。整个编辑过程不需要切换工具,也不需要本地搭建任何环境。
第三步是关键的「一次编辑、多形态产出」环节。同一份课程包可以走三个出口: 出口 A:导出 .zip,把它放进 Fay 仓库的 fay_player_knowledge/ 目录。Fay 配套的 MCP 服务会在 60 秒内自动检测到新文件并加载,对话时 kb_search 就能命中其中的内容。 出口 B:在 fay-player 里点击「导出视频」,工具会基于讲稿合成配音、把讲义图作为画面,生成一段完整的 MP4 讲解视频,可以直接发布到短视频平台或者用作内训资料。 出口 C:点击「导出 markdown」,把课程包还原成结构化的 md 文档,适合放进 Wiki、Notion 或者作为发版说明。
第四步是这套方案最大的价值所在:当内容需要更新时,作者只需要在 fay-player 上编辑一次原始课程包,然后重新导出三种形态。知识库、视频、文档三套交付物自动保持口径一致,再也不会出现「文档说一套、视频说一套、知识库又是一套」的漂移问题。
三句话总结:fay-player 是一体化课程工厂;课程包是图文知识的原生载体;Fay 通过 MCP 把课程包变成可检索的知识库。一次编辑,三种交付,全程开源,无须算力。
# 完整工作流示意
# ---------------------------------------------------------
# 作者侧:
# player.fay-agent.com
# └─ 创建课程包 → 编辑章节 → 保存
#
# 一次编辑后,三个出口同步产出:
# ┌──────────────────────────────────────────────┐
# │ 出口A:导出 .zip │
# │ → fay/fay_player_knowledge/your-course.zip │
# │ → MCP 自动加载 → kb_search 可检索 │
# ├──────────────────────────────────────────────┤
# │ 出口B:一键导出讲解视频 (MP4) │
# │ → 短视频平台 / 内训复用 │
# ├──────────────────────────────────────────────┤
# │ 出口C:一键导出 markdown │
# │ → Wiki / 发版说明 / Notion │
# └──────────────────────────────────────────────┘
#
# 内容更新时:
# 只需在 fay-player 编辑一次 → 三种交付同步重生成
# 彻底消除多套内容之间的口径漂移
#
# 开源地址:
# https://player.fay-agent.com
# https://gitee.com/xszyou/fay-player
一站式 AI 云服务平台
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)